在上一章中,我们讲述了TCP协议在传输过程中的可靠性http://t.csdnimg.cn/BsImO,这里衔接上一篇文章继续讲,TCP协议的特性,TCP协议写完之后就写,Http和Https等内容吧
1. 滑动窗口
这里的滑动窗口不是指算法里面的双指针那个滑动窗口,这个滑动窗口是为了在TCP协议传输过程中提高传输效率的。但是有了滑动窗口这个特性,也只是略微提高一下传输效率,因为TCP协议的可靠性已经注定了,TCP协议不可能比UDP协议快。所以也是一种亡羊补牢的特性。
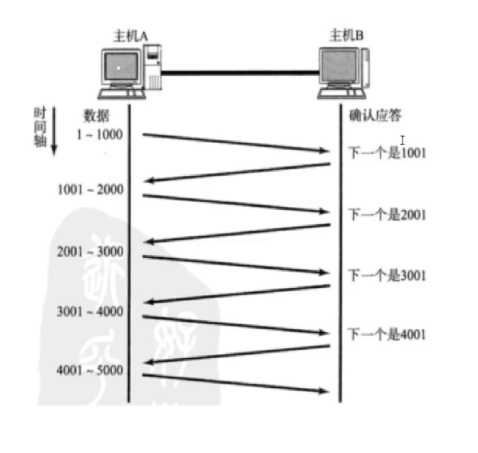
首先,这幅图上一篇文章中应该也提到了,服务端向客户端发送请求的时候,大部分时间会浪费在等待ACK上面。这一个非常浪费时间的操作。所以引入滑动窗口就是为了减少上述等待时间。这是使用了滑动窗口后的图

和刚刚不同的是,刚刚一条一条的发,变成了现在一组一组的发。也就和数据库中一条一条的查询,和一次性查询很多条是一个道理。也就是不需要等待ACK就一口气直接发,就等于就一份的等待时间等待4个ACK。这里我们把一次性发几个ACK不需要等待的大小称为“ 窗口 ”。 此时窗口越大效率越高,但是窗口不能无限大,要是无限大了,则滑动窗口就变成TCP协议了,而且服务器能不能处理的过来也是一个问题。所以窗口要设置合适的大小。这里讲解完了窗口。
那滑动的含义是什么捏。看下面这张图

下面这张图就是我们此时向服务器发送了
- 1001-2000
- 2001-3000
- 3001-4000
- 4001-5000
此时我们向服务器发送了4条请求。这里我们按照最理想的情况
服务器依次返回2001,3001,4001,5001这几条确认应答。这样在客户端收到了2001这条确认应答之后。会立即向服务端发送5001-6000这条数据,而不是等待4条确认应答都收到后再发送,是收到了一条就向后发送一条(服务器依次返回的情况下) ,所以这样看起来就和算法的滑动窗口很像,可以一直保持等待4个确认应答的状态。这就是滑动的含义。
滑动窗口的本质就是 批量发送数据
但是要是在滑动窗口机制下,丢包了怎么办,因为TCP协议的核心是可靠性,不能为了效率牺牲这个可靠性。
此时我们还是分为了2种情况
第一,请求已经发送成功了,但是ACK丢失

但其实仔细一想,其实ack丢了完全没有啥影响,因为确认应答返回的序列号的含义是比如此时返回1001,此时表示的含义就是1001之前的数据都收到了,所以要是3001丢失了,但是客户端收到了4001这条ACK的话,也就表示服务器3001也收到了。此时就会像客户端又发送几条请求,直到补齐"窗口"的大小。
第二,请求包丢失了
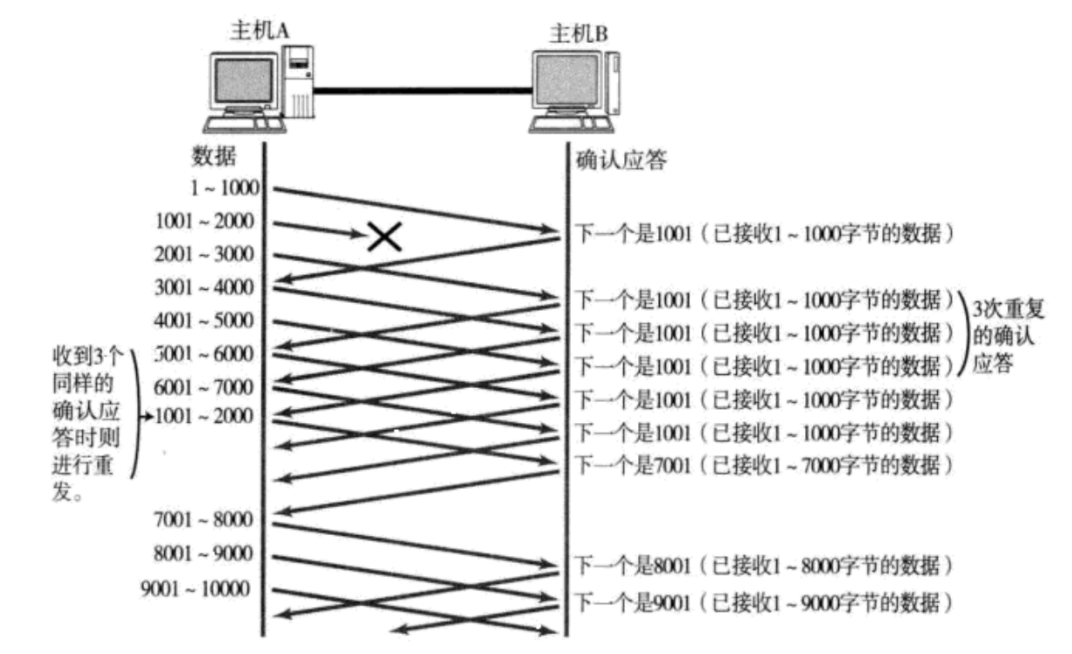
这个和上面就不同了,这里的话就必须要进行重传了,但要进行重传,就需要考虑2个特性
- 什么时候重传
- 改如何重传
这是确认序号的含义就发挥了尤为重要的作用。确认序号表示的为序号前的所有内容都收到了,所以当我们传上述1-1000 1001-2000 2001-3000 3001-4000 4001 - 5001 .....时,要是假设1001-2000这条数据丢失了。此时服务器每次收到请求之后,能返回的结果都只是1001,当客户端收到一定数量的1001这个确认序号的时候,就可以大概确定1001-2000这条数据大概率是丢了。所以此时就重新向服务器发送1001-2000这条请求,此时客户端收到请求之后,由于前面的2000-7000已经接收了,所以此时客户端直接返回7001,表示7001以前的数据都进行了接收。所以他只需要重传丢失的数据,已经发送的数据则无需再发。 这一操作也叫快速重传,本质还是超时重传的一种变形。
而且在使用TCP的过程中不一定会用到滑动窗口,当数据量特别大的时候,会使用到滑动窗口,此时数据丢失就叫快速重传,
但是数据量较少,隔很久才发一个请求的话,此时就不会使用滑动窗口,还是超时重传策略。
2. 流量控制
流量控制其实也算滑动窗口机制的一个补充,作用就是怕“ 窗口 ”太大,服务端接收不过来。适当的减少部分流量的。
这里我们用一个很常见的模型,生产者消费者模型,在很多地方都是可以使用的,比如在线程中有一个阻塞队列,在消息队列中也会经常使用到。
当我们客端户向服务器发送请求的时候也可以看做是一个生产者消费者模型。在服务器一般会有内核态和用户态,在内核态中会有一个接收缓冲区,就是一个类似于队列的结构。来接收客户端发送的请求,而此时用户态就会拿取接收缓存区中的内容进行使用,客户端向服务器发送请求的时候,要是发送的速度太快同时用户态来不及处理这些缓冲区内容,缓冲区就会被占满。 要是满了之后,客户端的请求服务器就接受不了了,就会发生丢包的情况。用户态的消费速度取决于代码的实现。所以一般我们不希望这种方式会引起丢包。
而流量控制就是解决上诉问题,根据接受方的处理能力,来限制发送方的发送速率(窗口大小)
所以此时就根据就根据接收方的接收缓冲区的剩余空间大小来作为衡量的标准,要是剩余空间越大,发送就越快。 所以该怎么判断剩余缓冲区大小呢。 这里又请出了我们昨天的那张图
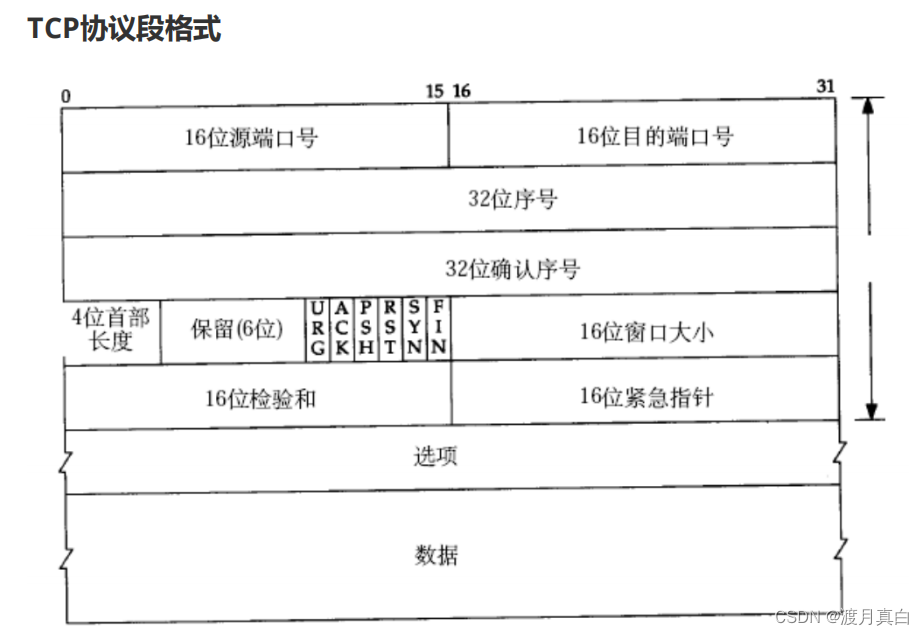
里面的16为窗口大小就表示了剩余缓存区的容量大小,同时这一字段也只针对应答报文ACK生效,通过16位窗口的大小来对传输速率进行调整。
那么这里的16位大小是否仅仅只能表示64kb的大小呢,不是的因为在协议中有一个选项这一个选项就是数据上面那一个,表示了扩展因子。实际大小为16位窗口大小位移选项位大小。所以可以表示的大小其实是非常大的,位移一位是*2 是指数级别的增加。
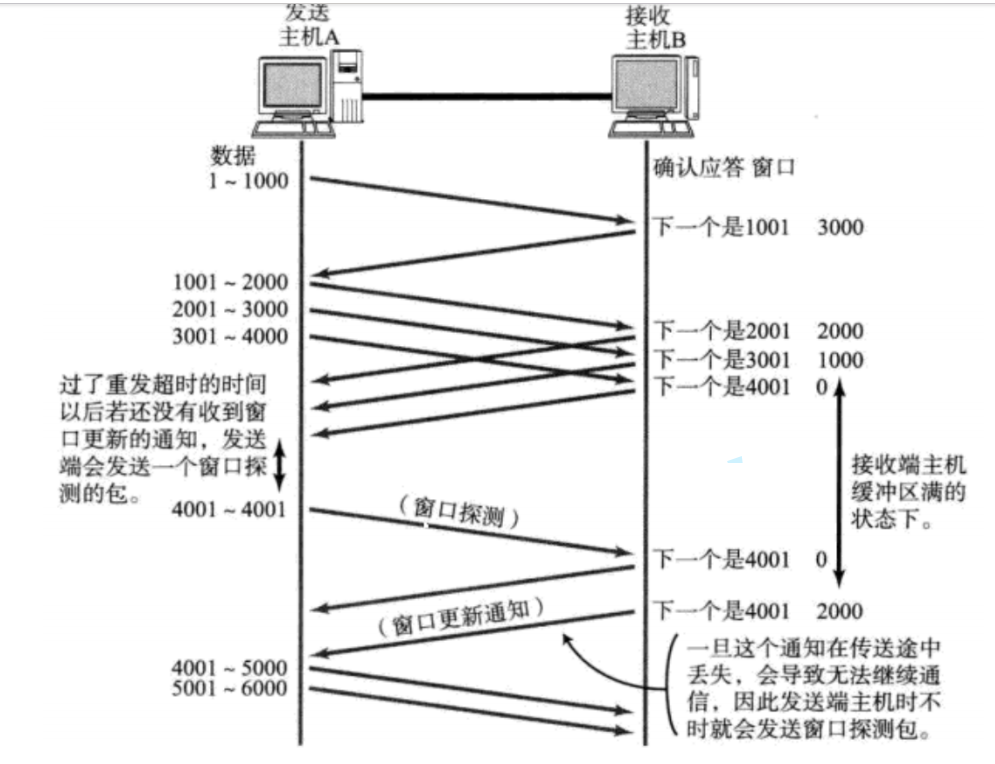
此时在每一条返回数据的过程中,除了会返回确认应答序号,还会返回 接收缓冲区剩余容量(16位窗口大小) 要是窗口大小为0的时候,也就表示窗口满了。 就会听着发送,反正发了也会丢包,就直接暂停发送等待窗口有大小之后进行发送。 但是发送方也不知道服务器什么时候会有空间,所以不定时会发一个窗口探测包来确定大小为多少。一旦发现大小不为0就可以继续发送了。
但是仅仅只考虑接收方是远远不够的,我们还需要考虑中间链路的处理能力。 这就涉及到TCP的下一个特性拥塞控制了。
3. 拥塞控制
在刚刚的过程中,我们只对接受方的性能进行了考虑,但是在实际网络通信的过程中,一个请求由客户端发送到服务器,可能是需要经过多次路由的,所以在路由的过程中是和木桶效应那样的。是取决于最低的那一个节点,如果转发过程中经过一个路由器的性能较差,此时请求的发送速度不会超过该路由的速率值,但是如何衡量中间路由设备的速率呢。
这里TCP协议在转发过程中不会去衡量中间设备的硬件能力,而是通过“实验”的形式,动态调整,最后产生出一个合适的窗口大小,期间,中间的所有设备都会看做为一个整体。
- 如果较小窗口传输通畅,就调大窗口。
- 如果较大窗口传输过程中丢包率变高,就调小窗口。
拥塞控制具体的展开过程:
1. 慢启动:在刚开始启动的时候,先使用一个非常小的窗口,先试试水。
2. 指数增长:在传输通畅的情况下,拥塞的窗口会以指数的形式成长(就是每次都*2)。但是不能一直增长,不然后面的值会非常的大。
3.线性增长:当窗口的大小到达了预设值之后,就会从指数增长,变为线性增长。就不是*2了而是每次+n。 线性增长也是一直在增长,到达一定程序,接近网络的极限之后,就可能会
出现丢包问题了。
4. 要是出现丢包了,就认为是网络达到阈值了,就会把大窗口变为最初的小窗口,同时也会根据阈值的大小去调整指数增长哪里的阈值(指数增长->线程增长)
1
而拥塞控制就是不断进行阈值动态变化和调整的一种机制,这样做的好处是,可以不断适应多变的一个网络环境。 当然也会存在性能损失,因为每次回到小窗口的时候速度会变慢。上述问题也是重点关注策略,而不是参数。
最后实际的窗口大小会取,拥塞控制和流量控制的较小值
4. 延迟应答
延迟应答也可以进行传输速率的优化,延迟应答其实也是围绕滑动窗口的一种模式,让我们在有限的条件下,尽可能的扩大窗口的大小,在返回ack的时候,拖延一点时间,利用拖延的这个时间,可以给应用数据程序更多消费数据的时间,此时接受缓冲区的空间就会更大了,具体来说就是比如我们此时有一个10kb大小的接收缓冲区收到了一个请求之后,此时接受缓冲区还有3kb了,如果立即返回ack的话,窗口大小的显示就该说明此时缓冲区还有3kb,但是如果我们等待500ms在进行ack的返回,在这500ms期间,应用程序又消耗掉了2kb数据呢,此时我们可以返回的窗口大小就为5kb了,所以延迟应答能提高多少速率还是取决于,应用程序对数据的消耗速度。
同时也不是所有的包都可以进行延迟应答
- 数量限制:每隔N个包就应答一次 (针对滑动窗口)
- 时间限制:超过最大延迟时间就应答一次 (针对非滑动窗口)
5. 捎带应答
捎带应答是在延迟应答的基础上引入的一个进一步提高速率的机制,捎带应答就是,在延时应答的基础上,让数据进行一个合并的机制。
就类似于在三次握手的过程中,对中间的数据进行和并一样,就是客户端向服务器发送一个请求之后,服务器延迟应答后返回一个ack,同时如果服务器本来就要向客户端返回数据的话,则会把这次数据和ack当成一个报文进行返回。
下一篇文章就写Http或者Https或者IP协议了 这里给大家推荐一本书《图解TCP/IP》,下一篇也有可能写一写蓝桥的题目。