引言
今天带来论文Language Modeling with Gated Convolutional Networks的笔记,该篇工作提出了GLU(Gated Linear Units,门控线性单元)。
注意该篇工作是2016年发表,是在Transformer论文发表之前。当时作者认为语言建模的主要方法是基于循环神经网络。它们在这个任务上的成功往往与其捕捉无限上下文的能力有关。
在本篇工作中,作者提出了一种新颖的简化门控机制。
总体介绍
统计语言模型通过建模给定前面单词的情况下下一个单词的概率来估计单词序列的概率分布,即
P ( w 0 , ⋯ , w N ) = P ( w 0 ) ∏ i = 1 N P ( w i ∣ w 0 , ⋯ , w i − 1 ) P(w_0,\cdots,w_N) = P(w_0) \prod_{i=1}^N P(w_i|w_0,\cdots,w_{i-1}) P(w0,⋯,wN)=P(w0)i=1∏NP(wi∣w0,⋯,wi−1)
在语料库中, w i w_i wi代表词汇表中的离散单词索引。语言模型是语音识别系统(Yu&Deng,2014)和机器翻译(Koehn,2010)中的重要组成部分。
在篇工作中,作者引入了新的门控卷积网络,并将其应用于语言建模。卷积网络可以堆叠以表示大的上下文大小,并提取越来越大的上下文中的层次化特征,具有更抽象的特征。这使得它们可以通过在大小为 N N N的上下文和内核宽度为 k k k的情况下应用 O ( N k ) O(Nk) O(Nk)次操作来建模长期依赖关系。相比之下,循环网络将输入视为链结构,因此需要线性数量的 O ( N ) O(N) O(N)次操作。
已经证明,门控是使循环神经网络达到最先进性能的关键因素。作者的门控线性单元通过提供梯度的线性路径同时保留非线性能力来减轻深度架构中的梯度消失问题。
方法
在本篇工作中,作者介绍了一种新的神经语言模型,将循环网络中通常使用的循环连接替换为门控时间卷积。神经语言模型为每个单词 w 0 , . . . , w N w_0,...,w_N w0,...,wN生成一个上下文表示 H = [ h 0 , . . . , h N ] \pmb H = [\pmb h_0,..., \pmb h_N] H=[h0,...,hN],以预测下一个单词 P ( w i ∣ h i ) P(w_i | \pmb h_i) P(wi∣hi)。
作者提出的方法使用函数 f f f对输入进行卷积,以获得 H = f ∗ w \pmb H = f * w H=f∗w,因此没有时间依赖性,因此更容易在句子的各个单词上并行化。这个过程将根据一定数量的前面单词计算每个上下文。与循环网络相比,上下文大小是有限的,但作者证明无限上下文并不是必要的,并且可以表示足够大的上下文以在实践中表现良好)。
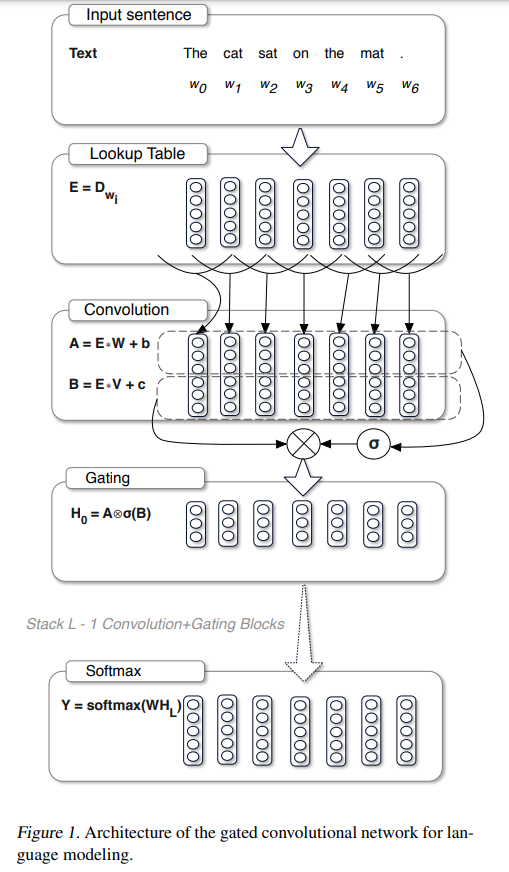
图1说明了模型架构。单词由存储在查找表 D ∣ V ∣ × e \pmb D ^{| \mathcal V |× e} D∣V∣×e中的向量嵌入表示,其中 ∣ V ∣ | \mathcal V | ∣V∣是词汇表中单词的数量, e e e是嵌入大小。模型的输入是一个单词序列 w 0 , . . . , w N w_0,...,w_N w0,...,wN,由单词嵌入 E = [ D w 0 , . . . , D w N ] \pmb E = [\pmb D_{w0},...,\pmb D_{w_N}] E=[Dw0,...,DwN]表示。计算隐藏层 h 0 , . . . , h L h_0,...,h_L h0,...,hL,如下:
h l ( X ) = ( X ∗ W + b ) ⊗ σ ( X ∗ V + c ) (1) h_l(X) = (X * W +\pmb b)⊗ \sigma(X * V + \pmb c) \tag 1 hl(X)=(X∗W+b)⊗σ(X∗V+c)(1)
其中, m m m和 n n n分别是输入和输出特征图的数量, k k k是补丁(patch)的大小 , X ∈ R N × m ,X ∈ \R^{N×m} ,X∈RN×m是层 h l h_l hl 的输入(可以是单词嵌入或前一层的输出), W ∈ R k × m × n W ∈ \R^{k×m×n} W∈Rk×m×n, b ∈ R n b ∈ \R^n b∈Rn, V ∈ R k × m × n V ∈ \R^{k×m×n} V∈Rk×m×n, c ∈ R n c ∈ \R^n c∈Rn 是学习的参数, σ σ σ是sigmoid函数, ⊗ ⊗ ⊗是矩阵之间的逐元素乘积。
每一层的输出是线性投影 X ∗ W + b X ∗ W +\pmb b X∗W+b 乘门控 σ ( X ∗ V + c ) σ(X ∗ V + \pmb c) σ(X∗V+c)。类似于LSTM,这些门控对矩阵 X ∗ W + b X∗W+\pmb b X∗W+b 的每个元素进行乘法,并控制在层次结构中传递的信息。作者称这种门控机制为门控线性单元(GLU)。
在输入 E \pmb E E的顶部堆叠多层,可以为每个单词提供上下文表示 H = h L ◦ ⋯ ◦ h 0 ( E ) \pmb H = h_L◦ \cdots ◦h_0(\pmb E) H=hL◦⋯◦h0(E)。
作将卷积和门控线性单元包装在一个预激活残差块中,将块的输入添加到输出中。
门控机制
门控机制控制信息在网络中流动的路径,已被证明对于循环神经网络非常有用。LSTM通过由输入门和遗忘门控制的单独单元实现了长期记忆。这使得信息可以在潜在的多个时间步中自由流动。如果没有这些门控,信息很容易在每个时间步的转换中消失。
相比之下,卷积网络不会遭受相同类型的梯度消失问题,作者通过实验证明它们不需要遗忘门。因此,考虑仅具有输出门的模型,这允许网络控制哪些信息应在层次结构中传播。作者证明这种机制在语言建模中非常有用,因为它允许模型选择哪些单词或特征对于预测下一个单词是相关的。
门控线性单元是一种简化的门控机制,基于Dauphin&Grangier的非确定性门控机制,通过将线性单元与门耦合来减少梯度消失问题。这保留了层的非线性能力,同时允许梯度在线性单元中传播而不进行缩放。具有LSTM风格的门控tanh单元(GTU)的梯度是
∇ [ tanh ( X ) ⊗ σ ( X ) ] = tanh ′ ( X ) ∇ X ⊗ σ ( X ) + σ ′ ( X ) ∇ X ⊗ tanh ( X ) (2) \nabla [\tanh(X) ⊗ \sigma(X)] = \tanh^\prime (X)\nabla X ⊗ \sigma(X) + \sigma^\prime (X) \nabla X ⊗ \tanh (X) \tag 2 ∇[tanh(X)⊗σ(X)]=tanh′(X)∇X⊗σ(X)+σ′(X)∇X⊗tanh(X)(2)
注意,由于缩放因子 tanh ′ ( X ) \tanh^\prime(X) tanh′(X)和 σ ′ ( X ) σ^\prime(X) σ′(X),它在堆叠层时逐渐消失。相比之下,门控线性单元的梯度:
∇ [ X ⊗ σ ( X ) ] = ∇ X ⊗ σ ( X ) + X ⊗ σ ′ ( X ) ∇ X (3) \nabla [X ⊗ \sigma(X)] =\nabla X ⊗ \sigma(X) + X ⊗ \sigma^\prime(X) \nabla X \tag 3 ∇[X⊗σ(X)]=∇X⊗σ(X)+X⊗σ′(X)∇X(3)
对于激活门控单元 σ ( X ) σ(X) σ(X)的梯度,门控线性单元具有路径 ∇ X ⊗ σ ( X ) ∇X ⊗ σ(X) ∇X⊗σ(X),而没有缩放因子。这可以看作是一种乘法跳跃连接(multiplicative skip connection),有助于梯度在层之间流动。
结论
作者引入了一种具有新颖门控机制的卷积神经网络用于语言建模。与循环神经网络相比,作者的方法构建了输入单词的分层表示,更容易捕捉长距离的依赖关系。
总结
⭐ 作者提出了门控线性单元,通过类似LSTM的门控机制,让每一层的输出在线性变换的基础上乘上门控来控制信息的传递。