Transformer介绍
word2vec
Word2Vec是一种用于将词语映射到连续向量空间的技术,它是由Google的Tomas Mikolov等人开发的。Word2Vec模型通过学习大量文本数据中的词语上下文信息,将每个词语表示为高维空间中的向量。在这个向量空间中,具有相似语境的词语通常被映射到彼此附近的位置,从而使得词语之间的语义关系得以保留。
Word2Vec有两种主要的模型结构:连续词袋模型(CBOW)和Skip-gram模型。CBOW模型试图根据上下文词语预测目标词语,而Skip-gram模型则相反,它试图根据目标词语预测上下文词语。这两种模型都使用了神经网络结构,通常是浅层的前馈神经网络。
通过Word2Vec技术,可以实现词语之间的语义相似度计算、词语之间的关系推断、词语的聚类和分类等任务,是自然语言处理领域中一个重要的基础工具。
RNN不足
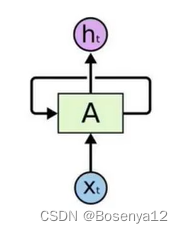
串行,无法并行,不能加速
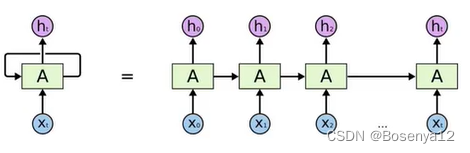
词向量的建模
Transformer是一种基于注意力机制的模型,最初用于机器翻译任务,但后来被证明在各种自然语言处理任务中都取得了巨大成功。在Transformer模型中,词向量的建模是通过自注意力机制(Self-Attention Mechanism)来实现的。
在Transformer中,输入的词语首先被转换成词向量(Word Embeddings),然后这些词向量被传递到多个Transformer层中进行处理。在每个Transformer层中,自注意力机制被用来捕捉输入序列中词语之间的关系。通过自注意力机制,模型可以计算每个词语在上下文中的重要性,并将这些重要性作为权重,对每个词语的表示进行加权求和,从而得到更丰富的上下文表示。
在自注意力机制中,每个词语的表示都会考虑到整个输入序列中的所有词语,这使得模型能够在不同位置之间进行信息交互,从而更好地捕捉上下文信息。通过多个Transformer层的堆叠,模型可以逐层地提炼和组织输入序列中的信息,最终得到更具有丰富语义信息的词向量表示。
总的来说,Transformer通过自注意力机制实现了对输入序列中词语的建模,使得模型能够更好地理解和处理自然语言文本。
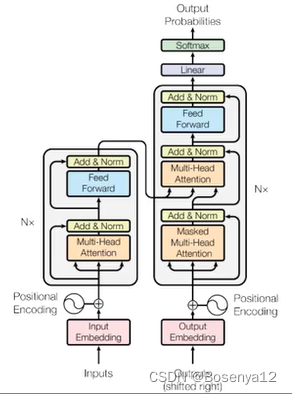
Transformer网络架构
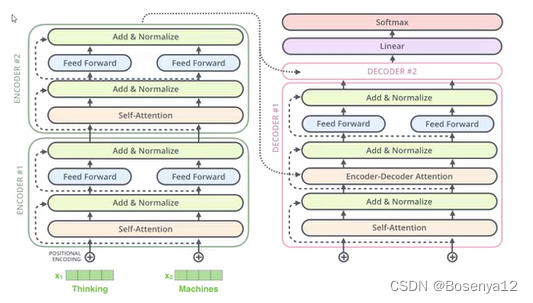
基本组件:seq2seq网络
核心架构是中间的网络设计
输入如何编码?
输出结果是什么?
self-attention
自注意力机制进行并行计算,输入和输入都相同。
计算方法
attention是什么?
让计算机关注到有价值的信息。

self-attention是什么?
关注到与自身相关的信息,融入上下文语境。

本质就是提取特征。(获取权重值)

用内积计算两个向量的关系。内积的结果为相关度分数。内积越大,相关度越高。

softmax用于归一化求概率。
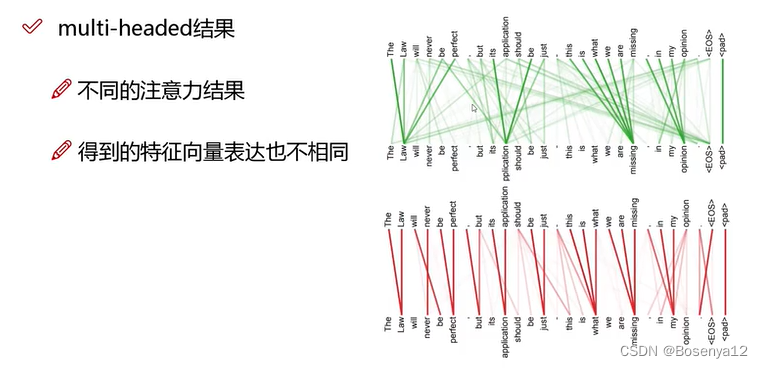
multi-headed
多头,提取多个特征。
通过不同的head得到多个特征表达。
将所有特征拼接在一起。
通过一层全连接来降维。
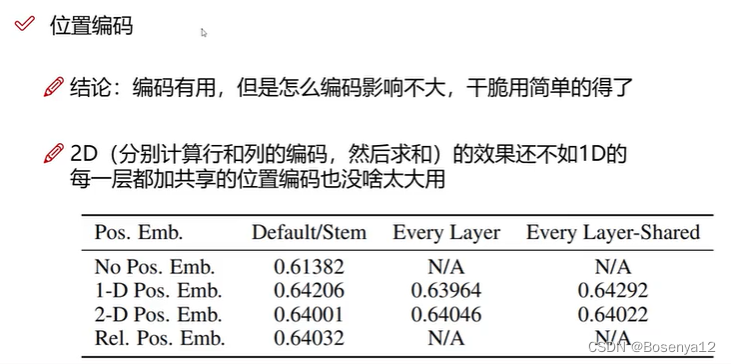
位置信息表达
position encoding
加入位置编码
以下结果针对分类任务,其他任务需要而外考虑。
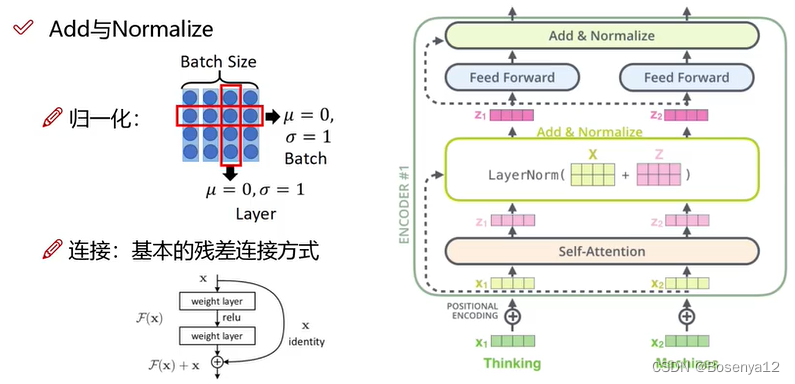
层归一化和残差连接
层归一化加速模型收敛,使得训练更稳定。
残差网络使得网络可以深层叠加。不同特征的融合(浅层特征和深层特征),防止模型退化。
mask机制
解决训练和测试的信息不对称。

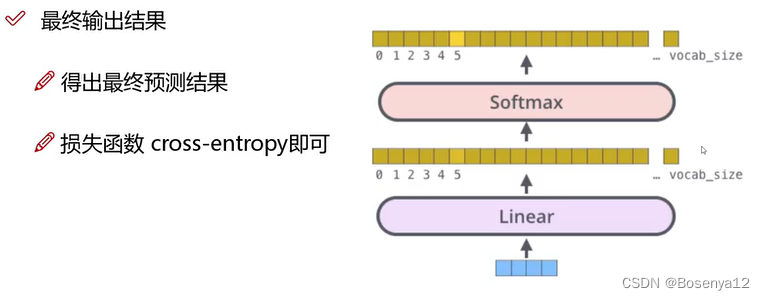
softmax 和 linear
模型梳理

BERT

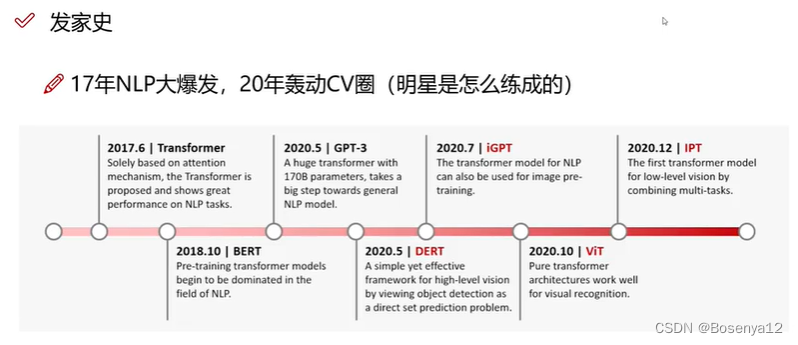
Transformer发家史
ViT(Vision Transformer)
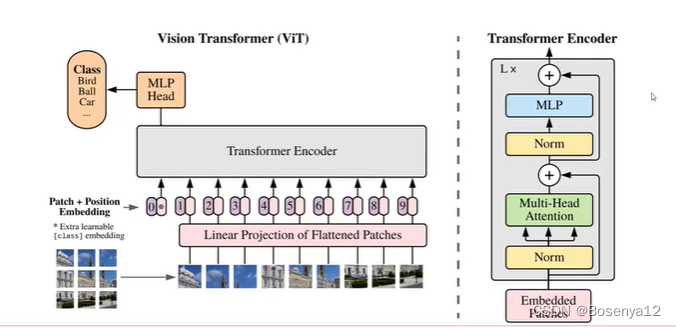
对图像数据构建patch序列
图像有空间位置信息,需要添加位置信息。
patch + position embedding
CNN缺陷
为了获得更大的感受野(获取全局信息),需要堆叠很深的卷积核(不断的卷积+池化)。
Transformer
对于训练数据要求很高(数据量大)。

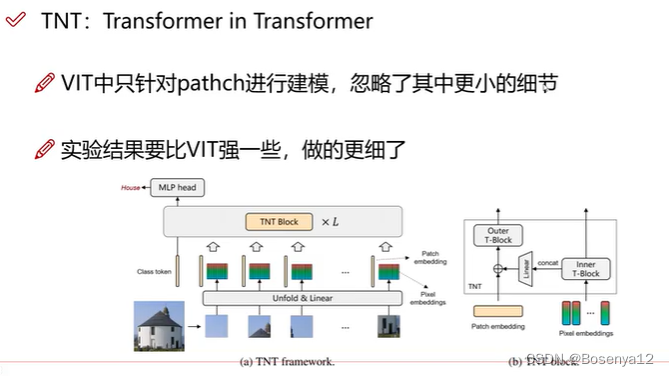
TNT
Swin Transformer

解决问题

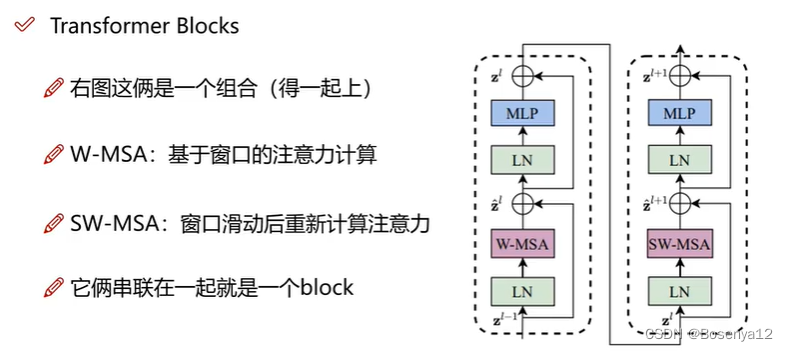
Transformer Blocks
整体网络架构
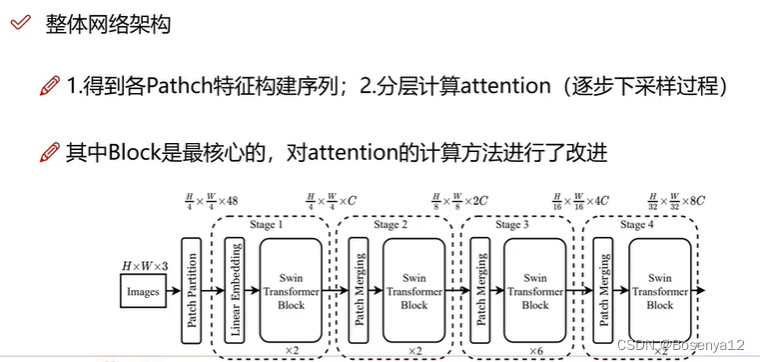
窗口和滑动窗口
W-MSA(Window Multi-head Self Attention)
学习窗口内部的信息
SW-MSA(Shift Window Multi-head Self Attention)
学习窗口之间的信息
Patch Merging
下采样,类似但不同于池化。
把不同维度进行间隔采样后拼接在一起。
DETR
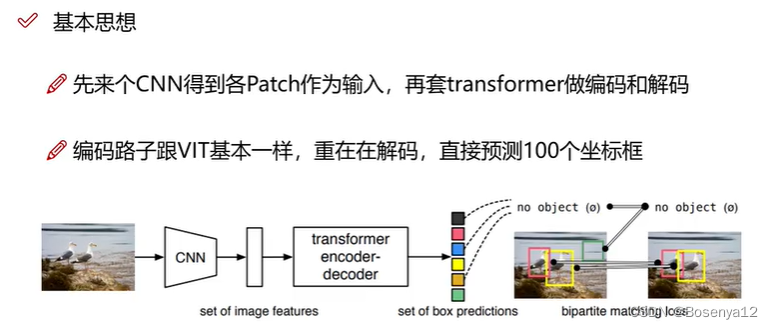
DETR(DEtection TRansformer)是一种基于Transformer架构的目标检测模型,它将目标检测任务转换为一个端到端的Transformer网络。这种方法消除了传统目标检测模型中需要使用特定的子网络(如R-CNN系列中的区域建议网络)的需求,取得了很好的性能。
以往的目标检测算法
Faster R-CNN
Faster R-CNN是一种流行的目标检测算法,它基于区域建议网络(RPN)生成区域建议,并对这些建议中的对象进行分类。它以在图像中检测对象的准确性和效率而闻名。
"proposal"的中文意思是“建议”或者“提议”,在Faster R-CNN中,指的是由Region Proposal Network (RPN) 生成的候选目标区域。
YOLO
YOLO(You Only Look Once)是一种流行的实时目标检测算法,它将目标检测任务视为一个回归问题,通过在单个神经网络中同时预测边界框和类别概率来实现目标检测。与传统的目标检测方法相比,YOLO具有更快的处理速度,因为它只需要在图像上运行一次网络,而不需要使用滑动窗口或区域提议。这使得它非常适合需要实时检测的应用场景,如视频分析和自动驾驶。
“Anchor”(锚点)在目标检测中通常指的是一种预定义的边界框形状和尺寸,在训练过程中用来作为参考,用于生成候选区域或者预测目标边界框的偏移量。在一些目标检测算法中,比如Faster R-CNN和YOLO,锚点被用来定义可能包含目标的区域。这些锚点可以根据数据集和目标的大小进行调整,以提高模型的准确性。
NMS
NMS是非极大值抑制(Non-Maximum Suppression)的缩写,它是一种常用的技术,在目标检测和边界框回归中用于过滤重叠的边界框。该技术通过保留具有最高置信度的边界框,并消除与其高度重叠的其他边界框来优化结果。这样可以确保在输出中每个检测到的目标只有一个边界框与之对应,从而提高检测结果的准确性和可靠性。
DETR基本思想
整体网络架构
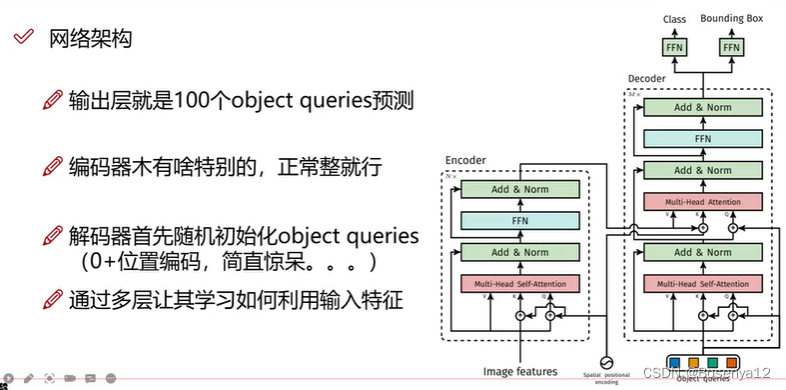
object queries
decoder中的查询是平行的,同时进行。

初始化 object queries :0 + 位置编码
输出的匹配
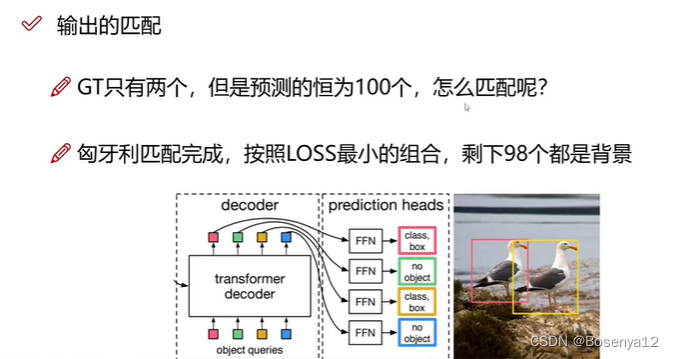
匈牙利匹配
匈牙利匹配是一个图论中的算法,用于解决二部图的最大匹配问题。在二部图中,顶点集合可以分为两个互不相交的子集,使得图中的每条边的一个端点属于一个子集,另一个端点属于另一个子集。
匈牙利匹配算法旨在找到一个最大的匹配,即图中能够相互连接的边的最大数量。它采用了增广路径的方法,在图中不断寻找增广路径并将其添加到匹配中,直到无法找到增广路径为止。增广路径是一条交替包含未匹配顶点和已匹配顶点的路径,通过不断寻找增广路径,可以不断增加匹配的边数,直到找到最大匹配。
匈牙利匹配算法的时间复杂度为 O(V^3),其中 V 是图中的顶点数量。尽管时间复杂度相对较高,但匈牙利匹配算法在实际应用中被广泛使用,例如在任务分配、资源分配等领域。
参考链接
太…完整了!同济大佬唐宇迪博士终于把【Transformer】入门到精通全套课程分享出来了,最新前沿方向均有涉猎!-人工智能/深度学习