任务
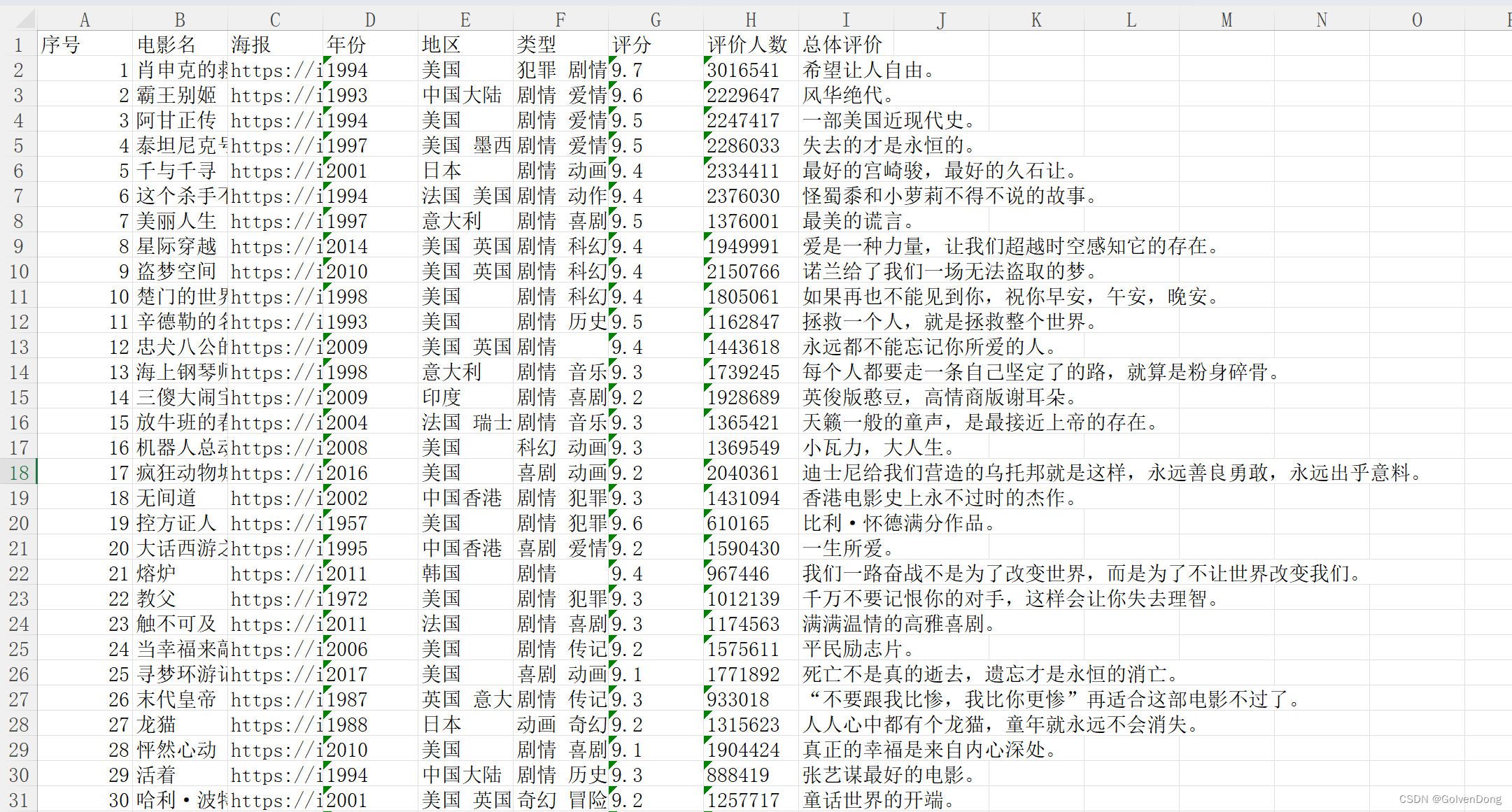
爬取豆瓣电影top250中的影片名称、影片海报、年份、地区、类型、评分、评价人数、总体评价,并输出到douban_top250.xlsx文件中
环境
Python 3.8
requests
bs4
openpyxl
源码
# 创建一个新的Excel工作簿
workbook = openpyxl.Workbook()
# 获取默认的工作表
sheet = workbook.active
# 写入数据
sheet['A1'] = '序号'
sheet['B1'] = '电影名'
sheet['C1'] = '海报'
sheet['D1'] = '年份'
sheet['E1'] = '地区'
sheet['F1'] = '类型'
sheet['G1'] = '评分'
sheet['H1'] = '评价人数'
sheet['I1'] = '总体评价'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
index = 1
for start_page in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_page}", headers=headers)
html = response.text
# html.parser表示使用html进行解析
soup = BeautifulSoup(html, "html.parser")
items = soup.find_all("div", attrs={"class": "item"})
for item in items:
# 海报
post = item.find("img").get('src')
# 名称
name = item.find('span', class_="title").text
# 年份
infos = item.find('p', class_='').text.split("\n")[2].split("/")
year = infos[0].strip()
location = infos[1].strip()
category = infos[2].strip()
rate = item.find('span', class_='rating_num').text
stars = item.find('div', class_='star')
rate_people = stars.contents[7].text[:-3]
review = ""
if item.find('span', class_='inq') is not None:
review = item.find('span', class_='inq').text
sheet.append([index, name, post, year, location, category, rate, rate_people, review])
index = index + 1
# 保存工作簿
workbook.save('./files/douban_top250.xlsx')
结果