第五章 深度学习
九、图像分割
3. 常用模型
3.2 U-Net(2015)
生物医学分割是图像分割重要的应用领域。U-Net是2015年发表的用于生物医学图像分割的模型,该模型简单、高效、容易理解、容易定制,能在相对较小的数据集上实现学习。该模型在透射光显微镜图像(相衬度和DIC)上获得了2015年ISBI细胞跟踪挑战赛的冠军。该图像分割速度较快,在512x512图像实现分割只需不到一秒钟的时间。
U-Net基本实现图像分割基本原理与FCN一致,先对原图进行若干层卷积、池化,得到特征图,再对特征图进行不断上采样,并产生每个像素的类别值。
3.2.1 网络结构
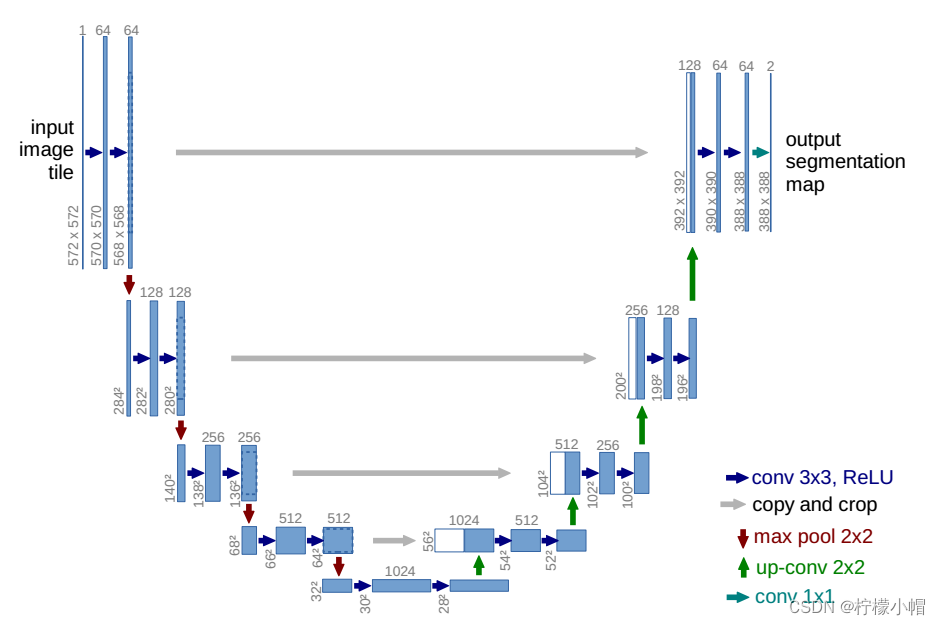
U-Net网络体系结构如下图所示,它由收缩路径(左侧)和扩展路径(右侧)组成,共包含23个卷积层。
- 收缩路径遵循卷积网络的典型结构,它包括重复应用两个3x3卷积(未相加的卷积),每个卷积后面都有一个ReLU和一个2x2最大合并操作,步长为2,用于下采样。在每个下采样步骤中,特征通道的数量加倍。
- 扩展路径中的每一步都包括对特征映射进行上采样,然后进行2x2向上卷积(up-convolution ),将特征通道数量减半,与收缩路径中相应裁剪的特征映射进行串联,以及两个3x3卷积,每个卷积后面都有一个ReLU。在最后一层,使用1x1卷积将每个64分量特征向量映射到所需数量的类。
3.2.2 训练细节
- 损失函数:采用像素级交叉熵作为损失函数
- 输入:单个大的图像,而不是大的批次图像
- 输出:得到的输出图像比输入图像小,边界宽度不变
- 优化方法:随机梯度下降
- 激活函数:ReLU
- 权重初始值:标准差为 2 N \sqrt{\frac{2}{N}} N2的高斯分布(N表示一个神经元的传入节点数)
- 采用数据增强策略
3.2.3 效果
(1)任务一:电子显微镜记录中分割神经元结构
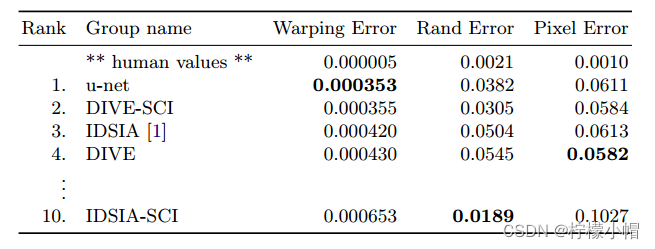
- 数据集:一组来自果蝇一龄幼虫腹侧神经索(VNC)的连续切片透射电镜图像(512x512像素)。每幅图像都有相应的完全注释的细胞(白色)和细胞膜(黑色)的真实分割图。测试集是公开的,但是它的分割图是保密的。通过将预测的膜概率图发送给组织者,可以得到评估。评估是通过在10个不同级别上对地图进行阈值化,并计算“扭曲误差”、“随机误差”和“像素误差”。
- 效果:u-net(在输入数据的7个旋转版本上的平均值)在没有任何进一步的预处理或后处理的情况下实现了0.0003529的翘曲误差(新的最佳分数,见下表)和0.0382的随机误差。
(2)任务二:u-net应用于光镜图像中的细胞分割任务
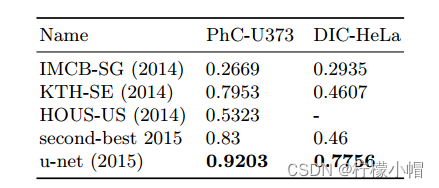
数据集:这个分离任务是2014年和2015年ISBI细胞追踪挑战赛的一部分,包含两个数据集。第一个数据集“PhC-U373”2包含由相差显微镜记录的聚丙烯腈基片上的胶质母细胞瘤星形细胞瘤U373细胞(见下图a,b),它包含35个部分注释的训练图像,该数据集下实现了92%的平均IOU;第二个数据集“DIC HeLa”3是通过差分干涉对比显微镜(DIC)记录在平板玻璃上的HeLa细胞(见下图c、d和补充材料)。它包含20个部分注释的训练图像。该数据集下实现了77.5%的平均IOU。
效果:见下表
3.3 Mask R-CNN(2017)
Mask R-CNN是一个小巧灵活的通用实例级分割框架,它不仅可对图像中的目标进行检测,还可以对每一个目标给出一个高质量的分割结果。它在Faster R-CNN基础之上进行扩展,并行地在bounding box recognition分支上添加一个用于预测目标掩模(object mask)的新分支。该网络具有良好的扩展性,很容易扩展到其它任务中,比如估计人的姿势。Mask R-CNN结构简单、准确度高、容易理解,是图像实例级分割的优秀模型。
3.3.1 主要思想
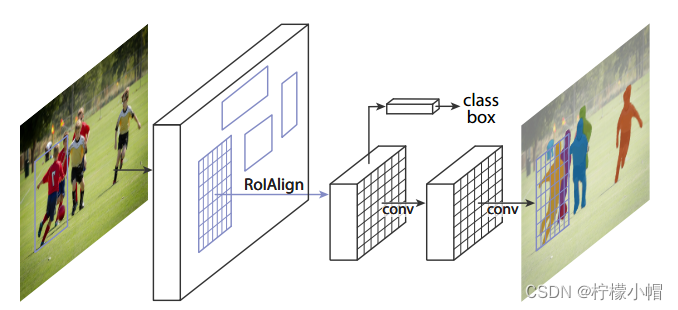
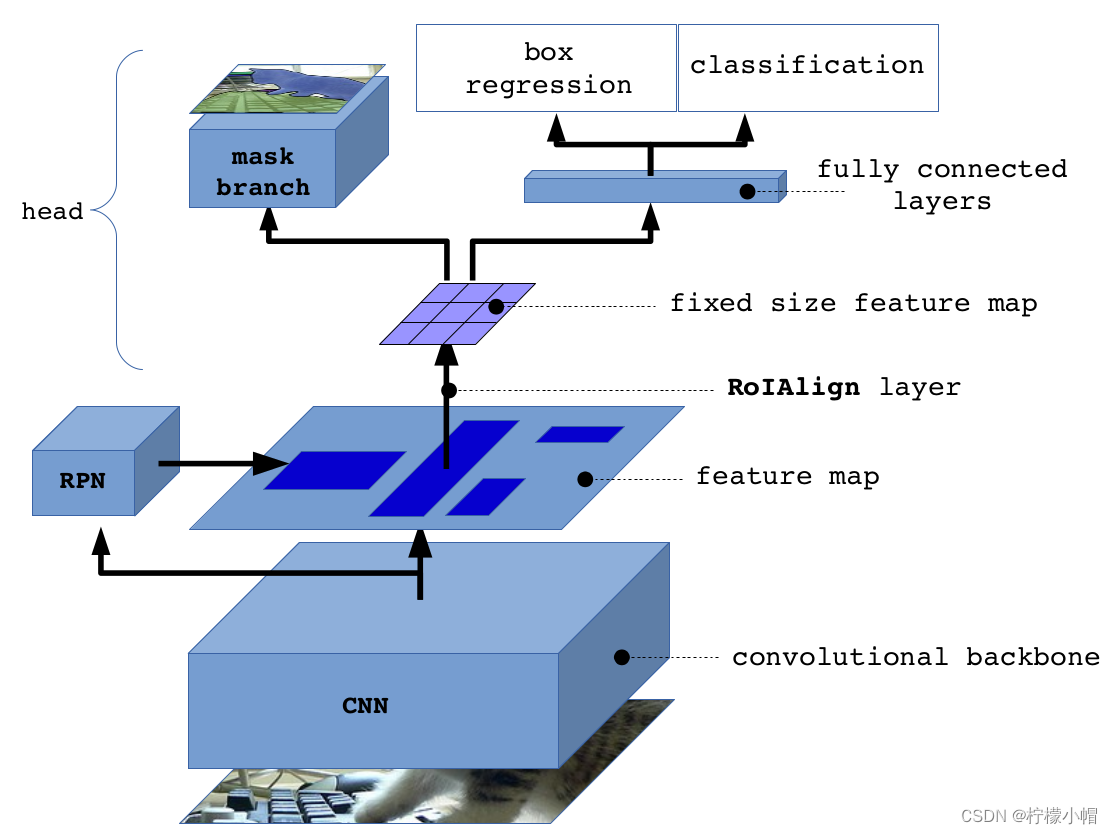
(1)分割原理。 Mask R-CNN是在Faster R-CNN基础之上进行了扩展。Faster R-CNN是一个优秀的目标检测模型,能较准确地检测图像中的目标物体(检测到实例),其输出数据主要包含两组:一组是图像分类预测,一组是图像边框回归。Mask R-CNN在此基础上增加了FCN来产生对应的像素分类信息(称为Mask),用来描述检测出的目标物体的范围,所以Mask R-CNN可以理解为Faster R-CNN + FCN。整体结构如下图所示。
(2)算法步骤
- 输入待处理图片,进行预处理
- 将图片送入经过预训练的卷积神经网络,进行卷积运算获取图像的特征图
- 对特征图中的每个点产生ROI,从而获取多个候选区域
- 将候选区域送入RPN网络进行而分类回归(前景或背景)、边框回归,过滤掉一部分候选区域
- 对剩余的ROI进行ROIAlign操作(将原图中的像素和特征图中的点对应)
- 对这些ROI进行分类(N个类别)、边框回归、Mask生成
(3)数据表示方式。 Mask R-CNN为每个RoI生成K个m×m的mask,其中K表示类别数量,每个mask均为二值化的矩阵,用来描述目标物体的像素范围。如下图所示:

3.3.2 网络结构
Mask R-CNN构建了多种不同结构的网络,以验证模型的适应性。论文中将网络结构分为两部分:提取特征的下层网络和产生预测结果的上层网络。如下图所示:
对于下层网络,论文中评估了深度为50或101层的ResNet和ResNeXt网络。
对于上层网络,主要增加了一个全卷积的掩码预测分支。如下图所示:
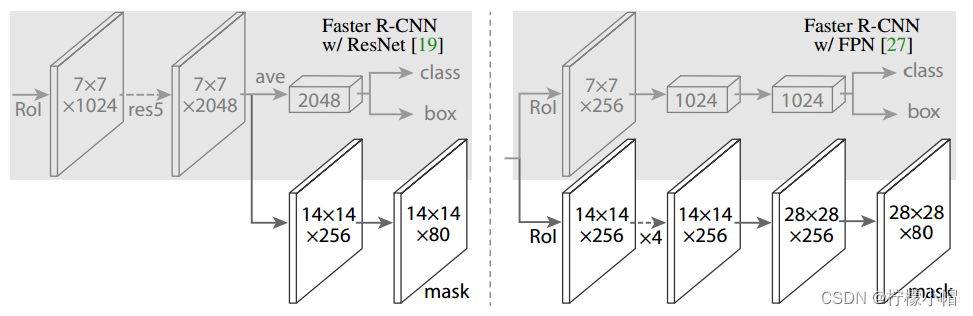
图中数字表示分辨率和通道数,箭头表示卷积、反卷积或全连接层(可以通过上下文推断,卷积减小维度,反卷积增加维度)。所有的卷积都是3×3的,除了输出层,是1×1的。反卷积是2×2的,步长为2,隐藏层中使用ReLU。左图中,“res5”表示ResNet的第五阶段,为了简单起见,修改了第一个卷积操作,使用7×7,步长为1的RoI代替14×14,步长为2的RoI。右图中的“×4”表示堆叠的4个连续的卷积。
3.3.3 损失函数
Mask R-CNN损失函数由三部分构成,分类、边框回归及二值掩码。公式如下所示:
L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask
分类损失 L c l s L_{cls} Lcls和检测框损失 L b o x L_{box} Lbox与Faster R-CNN中定义的相同。掩码分支对于每个RoI的输出维度为 K m 2 Km^2 Km2,即K个分辨率为m×m的二值掩码,每个类别一个,K表示类别数量。每个像素应用Sigmoid,并将 L m a s k L_{mask} Lmask定义为平均二值交叉熵损失。对于真实类别为k的RoI,仅在第k个掩码上计算 L m a s k L_{mask} Lmask(其他掩码输出不计入损失)。
3.3.4 训练细节
- 与Faster R-CNN中的设置一样,如果RoI与真值框的IoU不小于0.5,则为正样本,否则为负样本。掩码损失函数 L m a s k L_{mask} Lmask仅在RoI的正样本上定义;
- 图像被缩放(较短边)到800像素,批量大小为每个GPU上2个图像,每个图像具有N个RoI采样,正负样本比例为1:3;
- 使用8个GPU训练(如此有效的批量大小为16)160k次迭代,学习率为0.02,在120k次迭代时学习率除以10。使用0.0001的权重衰减和0.9的动量;
- RPN锚点跨越5个尺度和3个纵横比。为方便剥离,RPN分开训练,不与Mask R-CNN共享特征。
3.3.5 结果
① 检测速度:5FPS
② COCO数据集实验结果
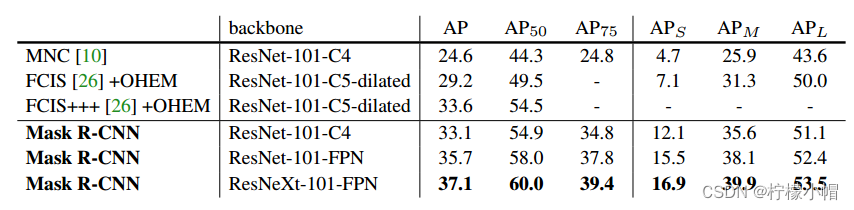
- AP:表示平均精度
- A P 50 AP_{50} AP50:IoU = 0.50(PASCAL VOC度量标准)
- A P 75 AP_{75} AP75:IoU = 0.75(严格度量标准)
- A P S AP_S APS:小对象平均准确率(面积 < 322)
- A P M AP_M APM:中等对象平均准确率(322 < 面积 < 962)
- A P L AP_L APL:中等对象平均准确率(面积 > 962)
分割效果:

下图是Mask R-CNN分割效果对比。FCIS在重叠对象上有问题,Mask R-CNN则没有。

③ 人体姿态估计效果
Mask R-CNN框架可以很容易地扩展到人类姿态估计。将关键点的位置建模为one-hot掩码,并采用Mask R-CNN来预测K个掩码,每个对应K种关键点类型之一(例如左肩,右肘)。实验结果如下:
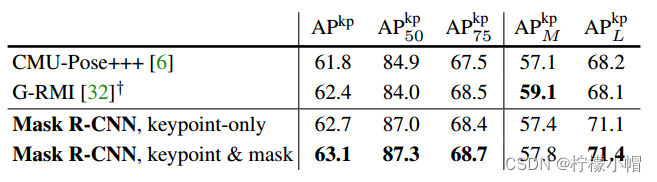
人体姿态估计效果图如下所示:
