思维导图
学习目标
学习Linux的文件系统。
一、Linux操作系统的文件的特点
文件内容和文件属性是分开进行存储的。
二、Linux操作系统的文件系统的框架
- Data Blocks(数据区)存放文件内容,4KB的数据块,值存储文件的内容
- Block Bitmap(块位图)Block Bitmap记录着Data Block中哪一个数据块已经被占用了,哪个数据块没有被占用,比特位的位置表示块号,比特位的内容表示该块是否被占用
- inode Table(i节点表)存放文件属性,如文件大小,所有者,最近修改时间
- inode Bitmap(inode位图)每一个比特位表示每一个inode是否空闲可用,比特位的位置表示第几个inode,比特位的内容表示是否被占用
- GDT(块组描述符)描述块组属性信息,起到管理的作用
- Super Block(超级块)存放文件系统本身的结构信息,记录的信息主要有:Block和inode的总量,未使用的Block和inode的数量,一个Block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息
inode Table(i节点表)的一些其他细节
inode Table(i节点表)是存放文件属性的,例如文件大小,所有者,最近修改时间……由于Linux中文件的属性是一个大小固定(128字节)的集合体,所以i节点表也是一个结构体组成的:
struct inode
{
int size; // 文件的大小
mode_t mode; // 文件的权限
int creater; // 文件创造者
int time; // 时间
...
int inode_number; // inode编号,用来表示文件
int datablocks[N]; // 记录数据在哪一块中存放
};datablock数组:
这个数组的大小一般为15,我们可以通过映射将数据存放到15个 datablock,但是这个含量还是比较低的,所以我们可以通过一个数组元素指向的datablock,将这块的内容中存放指针来指向其他datablock进行扩大存放数据的大小,我们不仅可以直接映射,也可以进行间接映射或者是二次映射。
如果一个组的容量只有10GB,但是文件需要有20GB的空间,可以进行存储这个文件吗??答案是可以的,但是对于磁盘来说,进行访问时,速度是比较慢的,所以不建议放在多个组中。
inode_number
在inode结构体内部,不包含文件名,在内核层面中,每一个文件都要有inode_number。我们可以通过inode_number标识文件。inode_num是以分区为单位整体分配,不是以分组为单位进行分配的,inode不能跨分区访问。每一个分组都有两个编号,文件中使用的inode是在一个特定的范围内申请的inode。
我们怎么拿到inode编号,我们用的是文件名进行工作的?目录是文件,目录有自己的inode和目的内容,而文件名及其inode是在目录内容中有映射关系,文件和目录的属性是相同的。
Super Block(超级块)的一些其他细节
存放文件系统本身的结构信息,记录的信息主要有:Block和inode的总量,未使用的Block和inode的数量,一个Block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。超级块不是每一个分组都有的,在整个分区中可能有2~3个,主要原因是防止超级块被破坏,导致磁盘信息被破坏,使文件系统更稳定。
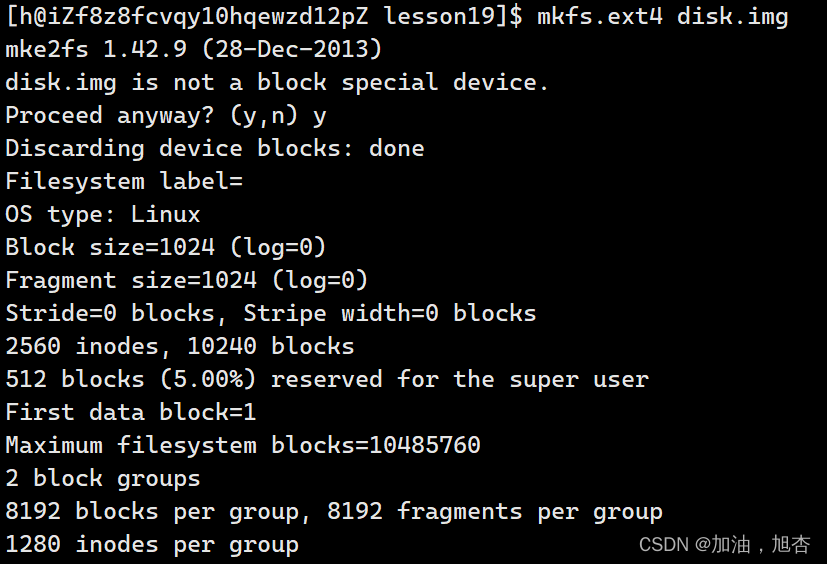
先分区,在一个分区中分组,然后写入文件系统的管理数据,就是格式化——在磁盘中写入文件系统。
三、如何找到一个文件
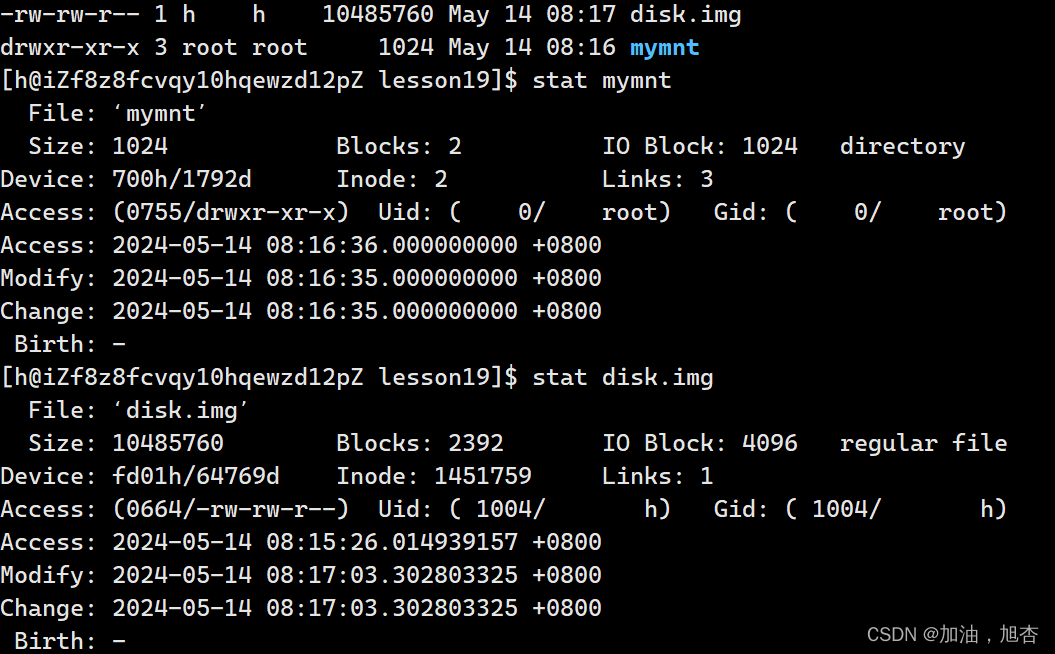
我们在寻找一个文件,必须要先拿到文件的inode编号。
找到指定的文件,需要先找到文件所在的目录,但是目录也是文件,目录也有目录名和inode的关系,但是根目录是在系统中是知道目录名和inode。所以我们先要进行逆向的路径解析(OS自己做的),Linux会缓存路径结构,这就是为什么我们在Linux中,定位一个文件,在任何时候,都要有路径的原因。
Linux内核在被使用的时候,一定存在大量解析完毕的路径,要不要对访问到的路径做管理呢??先描述在组织。

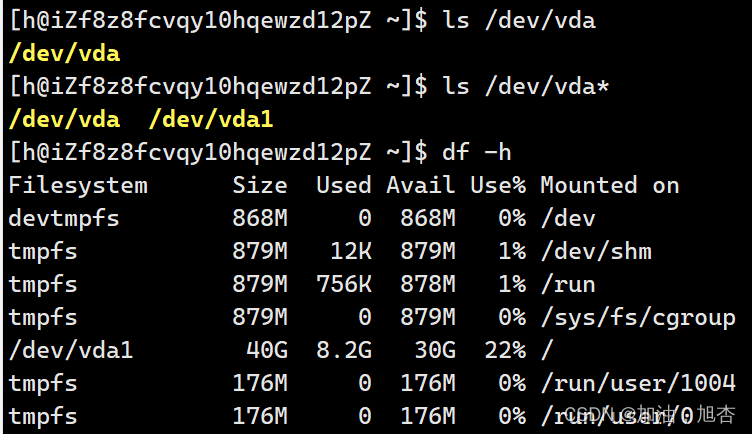
四、分区

![]()