欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
决策树
概述
通常,决策树会提出一个陈述,然后根据该陈述是真还是假来做出决定。当决策树将事物分类到不同类别时,称为分类树。当决策树预测数值时,称为回归树。

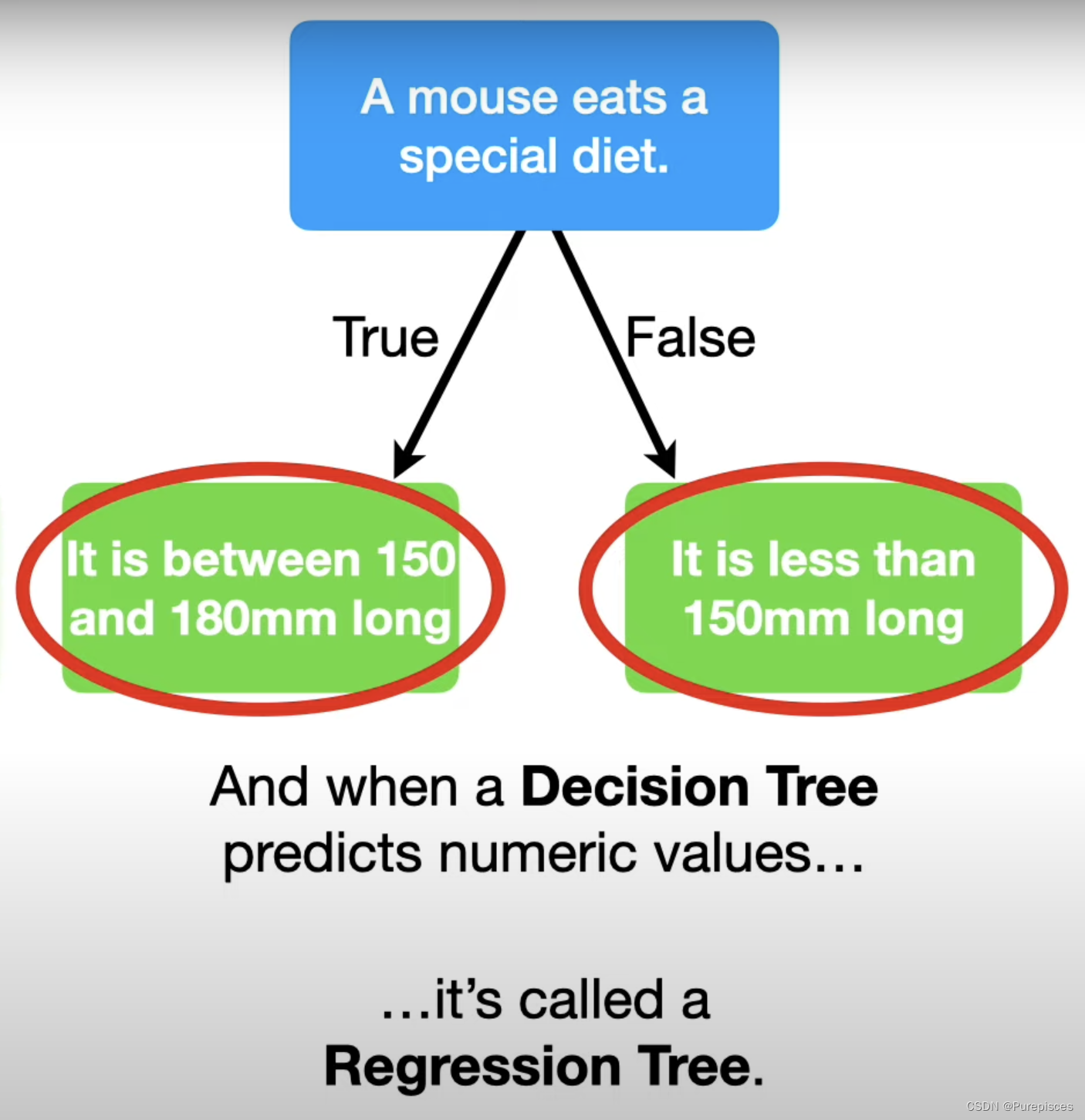
根节点
树的最顶端称为根节点或直接称为根。
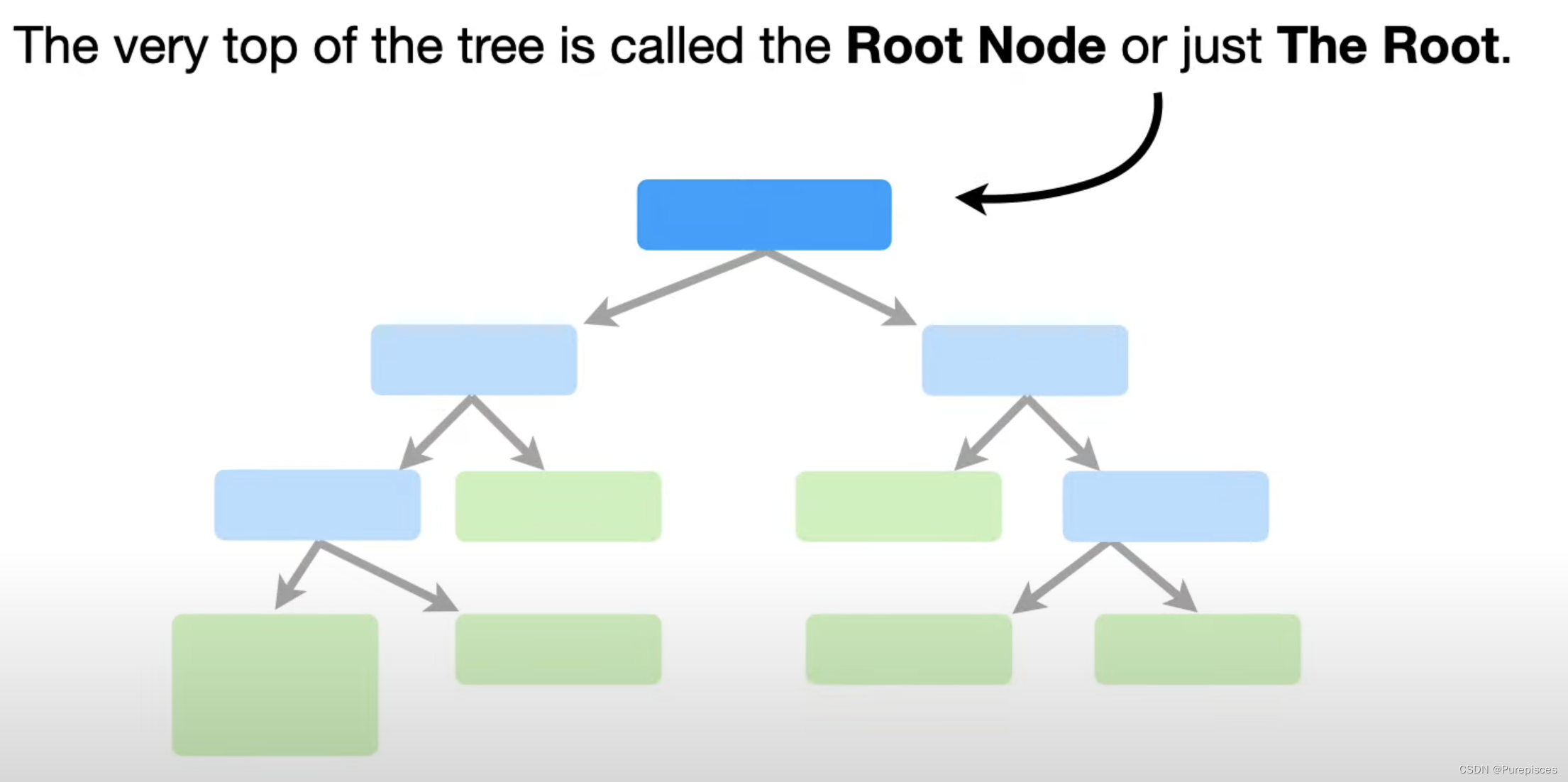
内部节点
这些称为内部节点,或分支。分支有指向它们和从它们指向的箭头。
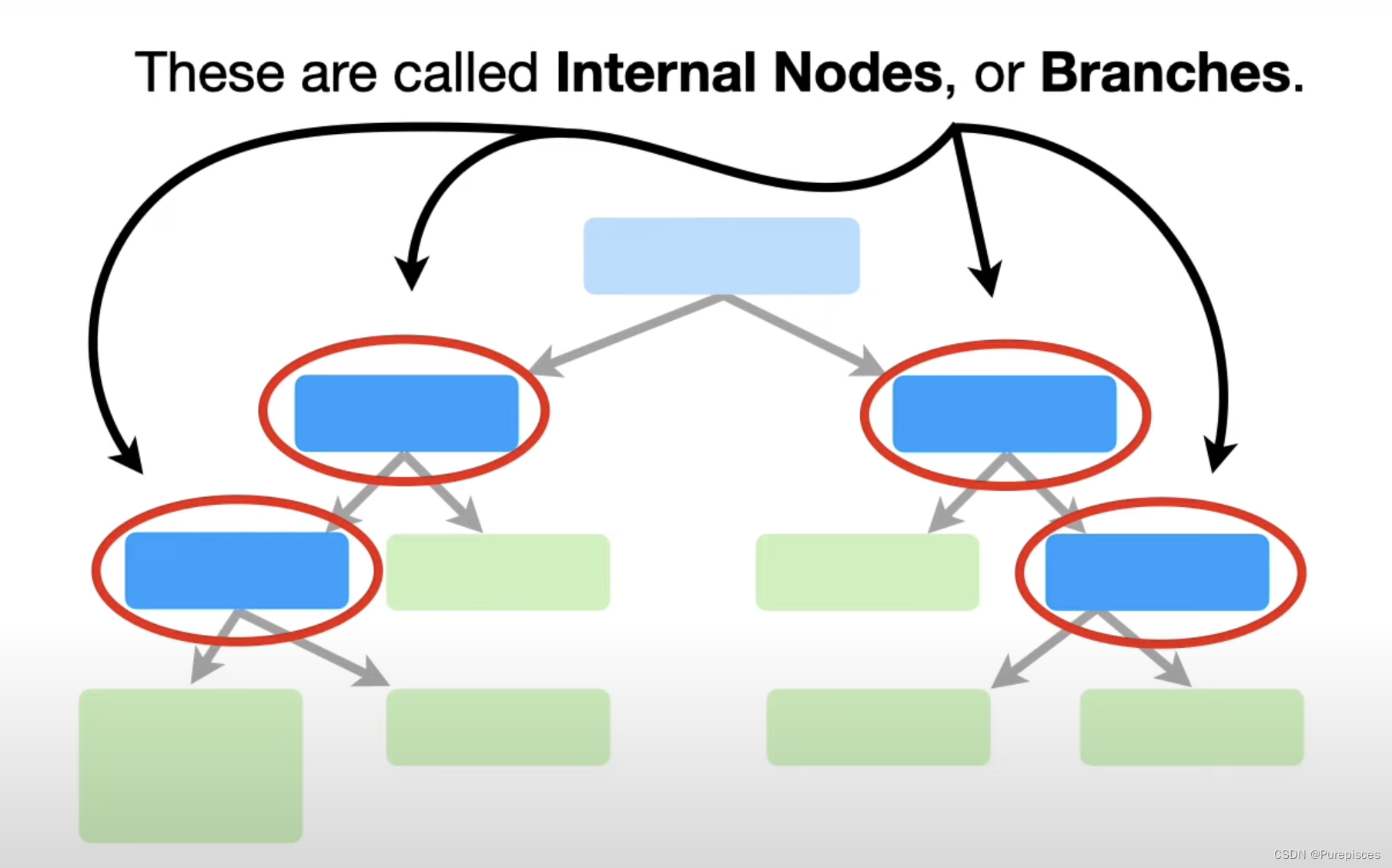
叶节点
最后,这些称为叶节点或直接称为叶子。叶子有指向它们的箭头,但没有离开它们的箭头。
示例:构建决策树
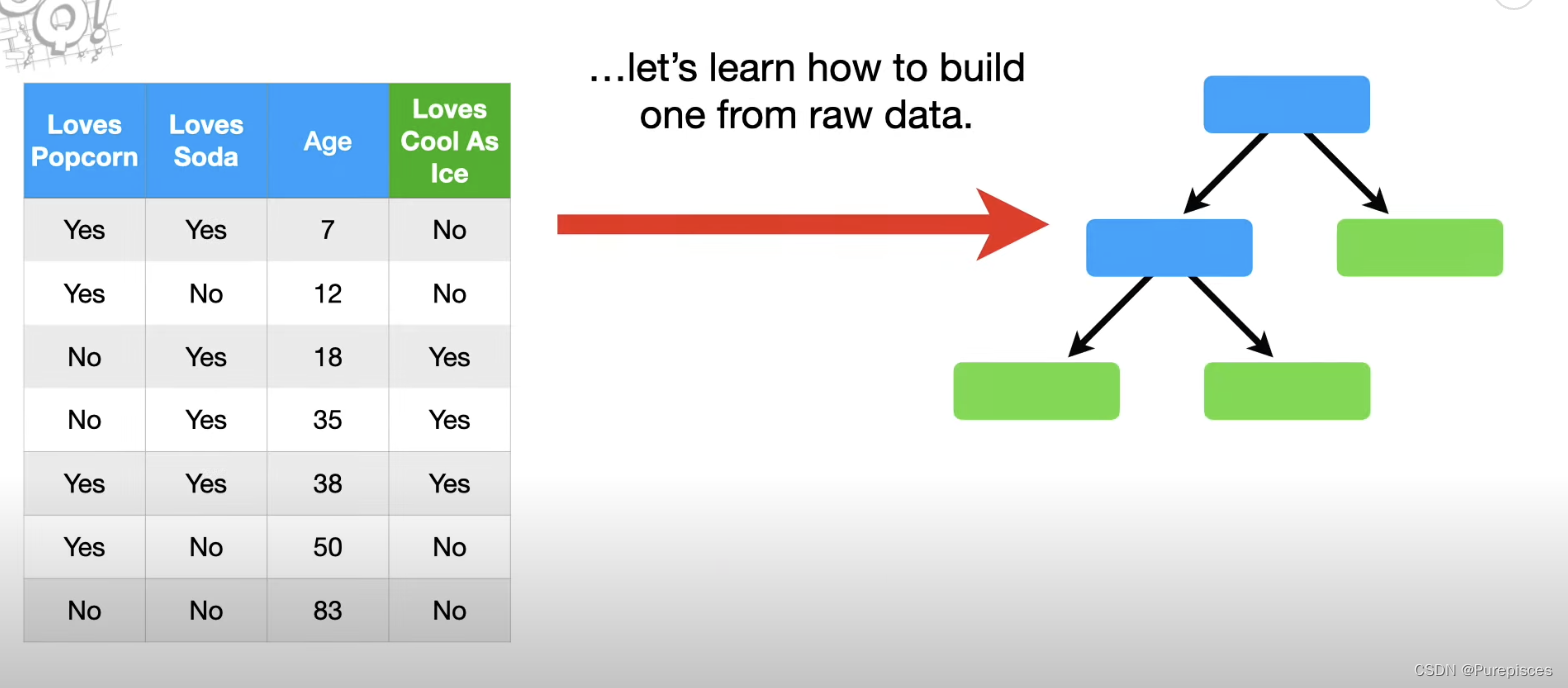
现在让我们学习如何从原始数据构建决策树。这个数据集包括关于某人是否喜欢爆米花、是否喜欢苏打水、他们的年龄以及是否喜欢《Cool as Ice》的信息。我们的目标是构建一个分类树,以预测某人是否喜欢《Cool as Ice》。
步骤1:找到根节点
第一步是决定哪个特征(喜欢爆米花、喜欢苏打水或年龄)应该是我们在树的最顶端提出的问题。为此,我们首先检查每个特征预测某人是否喜欢《Cool as Ice》的效果。
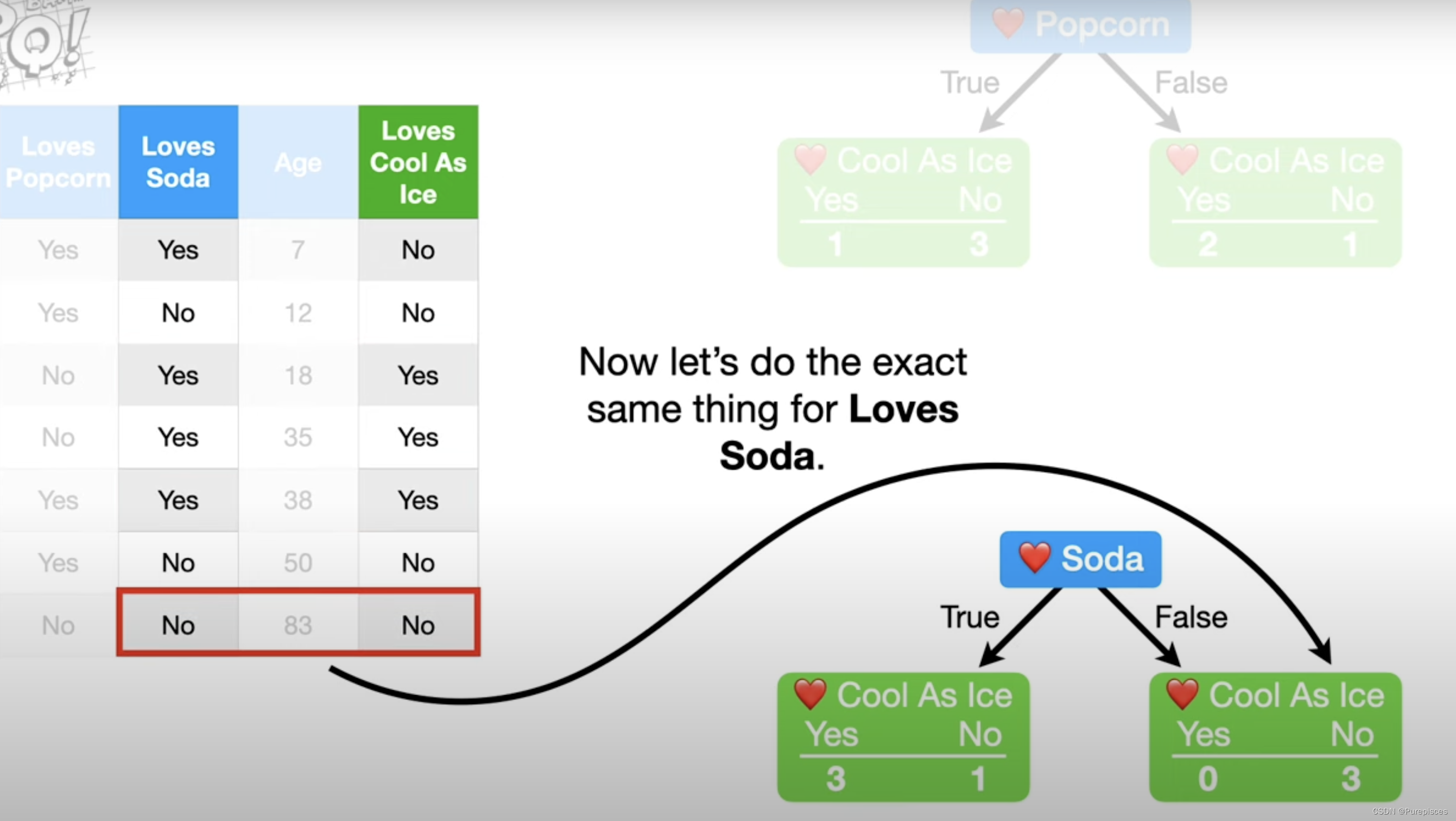
为了评估这一点,我们从检查喜欢爆米花如何预测某人是否喜欢《Cool as Ice》开始。我们将创建一个只问某人是否喜欢爆米花的简单树。例如,如果数据集中的第一个人喜欢爆米花,他们将进入左边的叶子。同样,我们创建一个只问某人是否喜欢苏打水的简单树。然后我们通过树运行数据,看看它预测结果的效果如何。
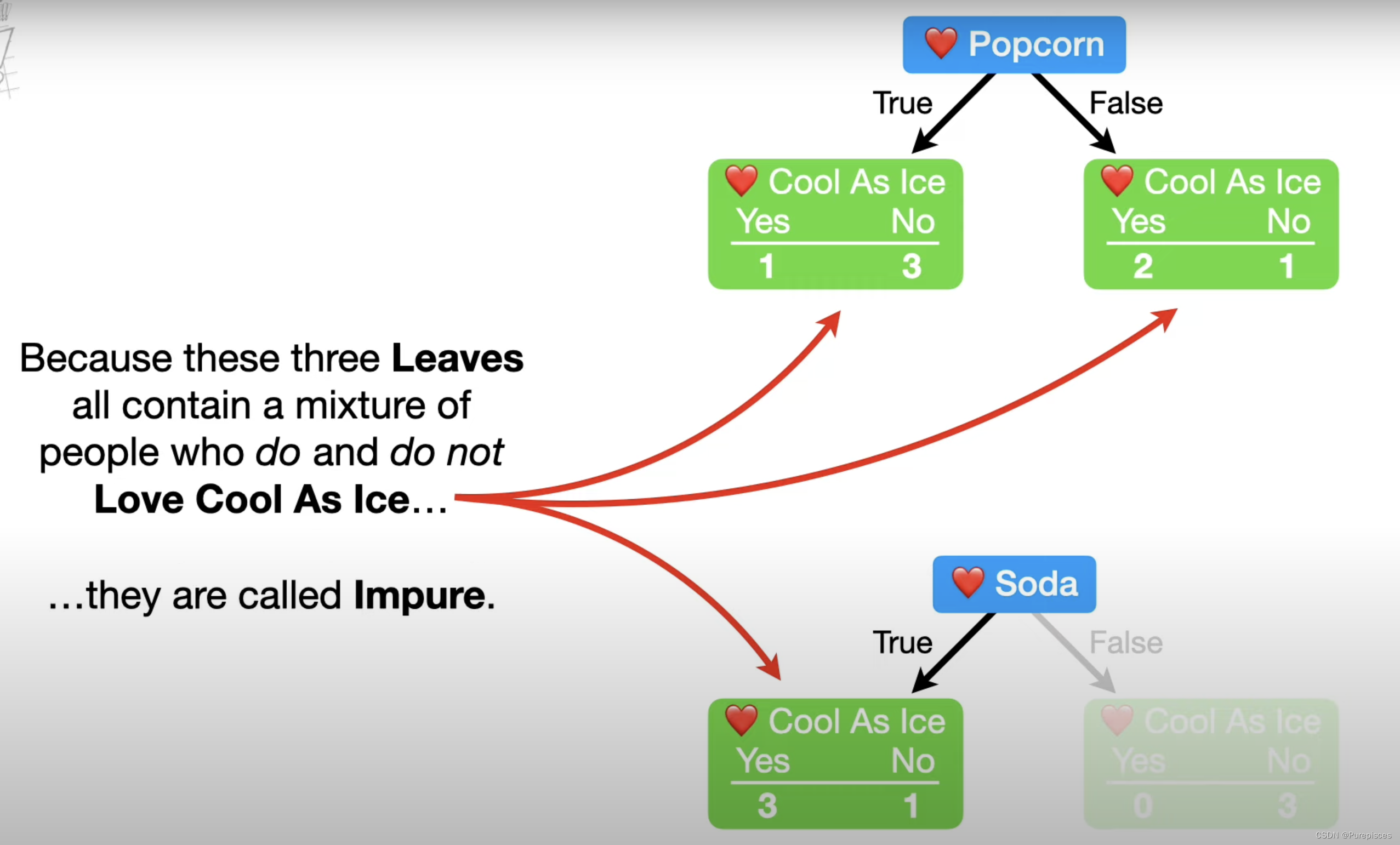
不纯度:由于这三个叶子都包含喜欢和不喜欢《Cool as Ice》的人,因此它们被称为不纯。
基尼不纯度:有几种方法可以量化叶子的不纯度。一种流行的方法称为基尼不纯度。其他方法包括熵和信息增益。数值上,这些方法相似,因此我们将重点放在基尼不纯度上,因为它很流行且直观。
1. 计算“喜欢爆米花”的基尼不纯度
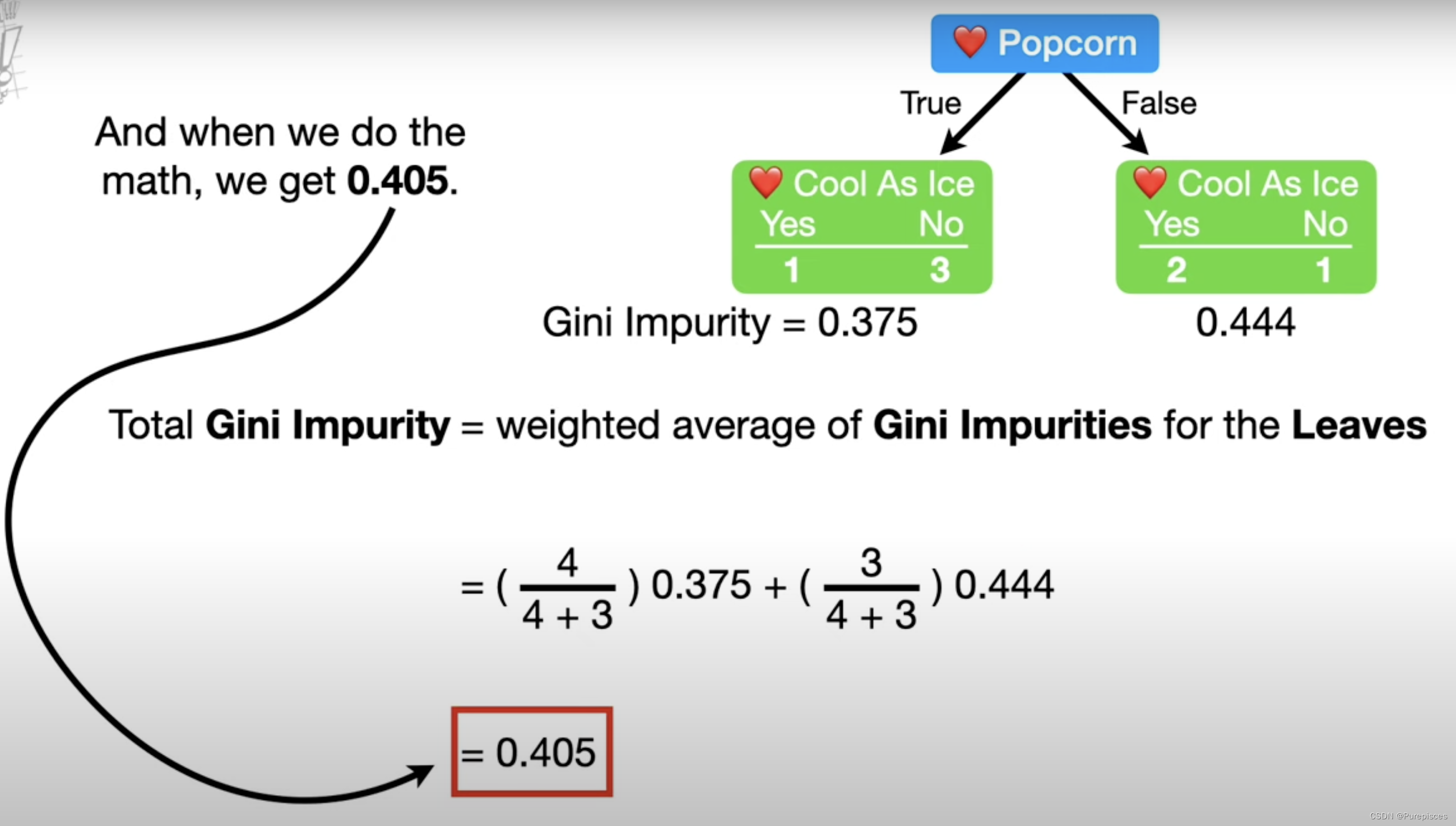
为了计算“喜欢爆米花”的基尼不纯度,我们从计算个别叶子的基尼不纯度开始。
左叶子的基尼不纯度:
左叶子的基尼不纯度 = 1 − ( "yes"的概率 ) 2 − ( "no"的概率 ) 2 = 1 − ( 1 1 + 3 ) 2 − ( 3 1 + 3 ) 2 = 0.375 \text{左叶子的基尼不纯度} = 1 - (\text{"yes"的概率})^2 - (\text{"no"的概率})^2 \\ = 1 - \left(\frac{1}{1+3}\right)^2 - \left(\frac{3}{1+3}\right)^2 \\ = 0.375 左叶子的基尼不纯度=1−("yes"的概率)2−("no"的概率)2=1−(1+31)2−(1+33)2=0.375
右叶子的基尼不纯度:
右叶子的基尼不纯度 = 1 − ( "yes"的概率 ) 2 − ( "no"的概率 ) 2 = 1 − ( 2 2 + 1 ) 2 − ( 1 2 + 1 ) 2 = 0.444 \text{右叶子的基尼不纯度} = 1 - (\text{"yes"的概率})^2 - (\text{"no"的概率})^2 \\ = 1 - \left(\frac{2}{2+1}\right)^2 - \left(\frac{1}{2+1}\right)^2 \\ = 0.444 右叶子的基尼不纯度=1−("yes"的概率)2−("no"的概率)2=1−(2+12)2−(2+11)2=0.444
由于左叶子中有4个人,而右叶子中只有3个人,因此这些叶子所代表的人数不同。因此,总基尼不纯度是这些叶子基尼不纯度的加权平均值。
总基尼不纯度 = ( 4 4 + 3 ) × 0.375 + ( 3 4 + 3 ) × 0.444 = 0.405 \text{总基尼不纯度} = \left(\frac{4}{4+3}\right) \times 0.375 + \left(\frac{3}{4+3}\right) \times 0.444 \\ = 0.405 总基尼不纯度=(4+34)×0.375+(4+33)×0.444=0.405
所以,“喜欢爆米花”的基尼不纯度是0.405。
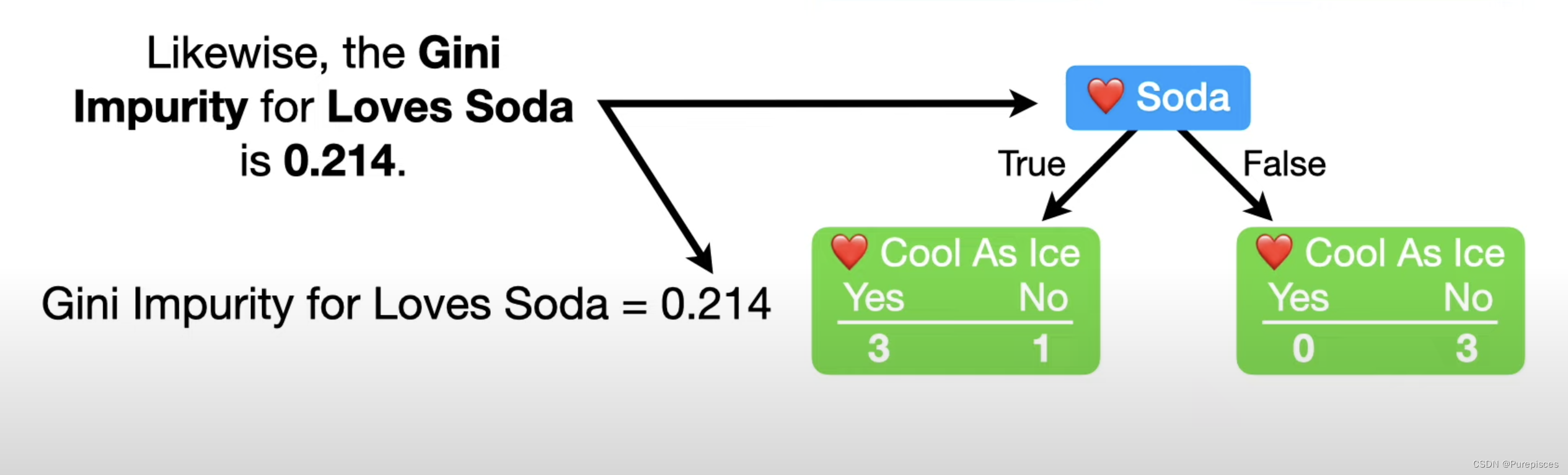
2. 计算“喜欢苏打水”的基尼不纯度
同样,"喜欢苏打水"的基尼不纯度是0.214。
3. 计算“年龄”的基尼不纯度
对于像“年龄”这样的数值数据,我们按年龄从低到高对行进行排序,然后计算相邻人之间的平均年龄。然后我们计算每个平均年龄的基尼不纯度。

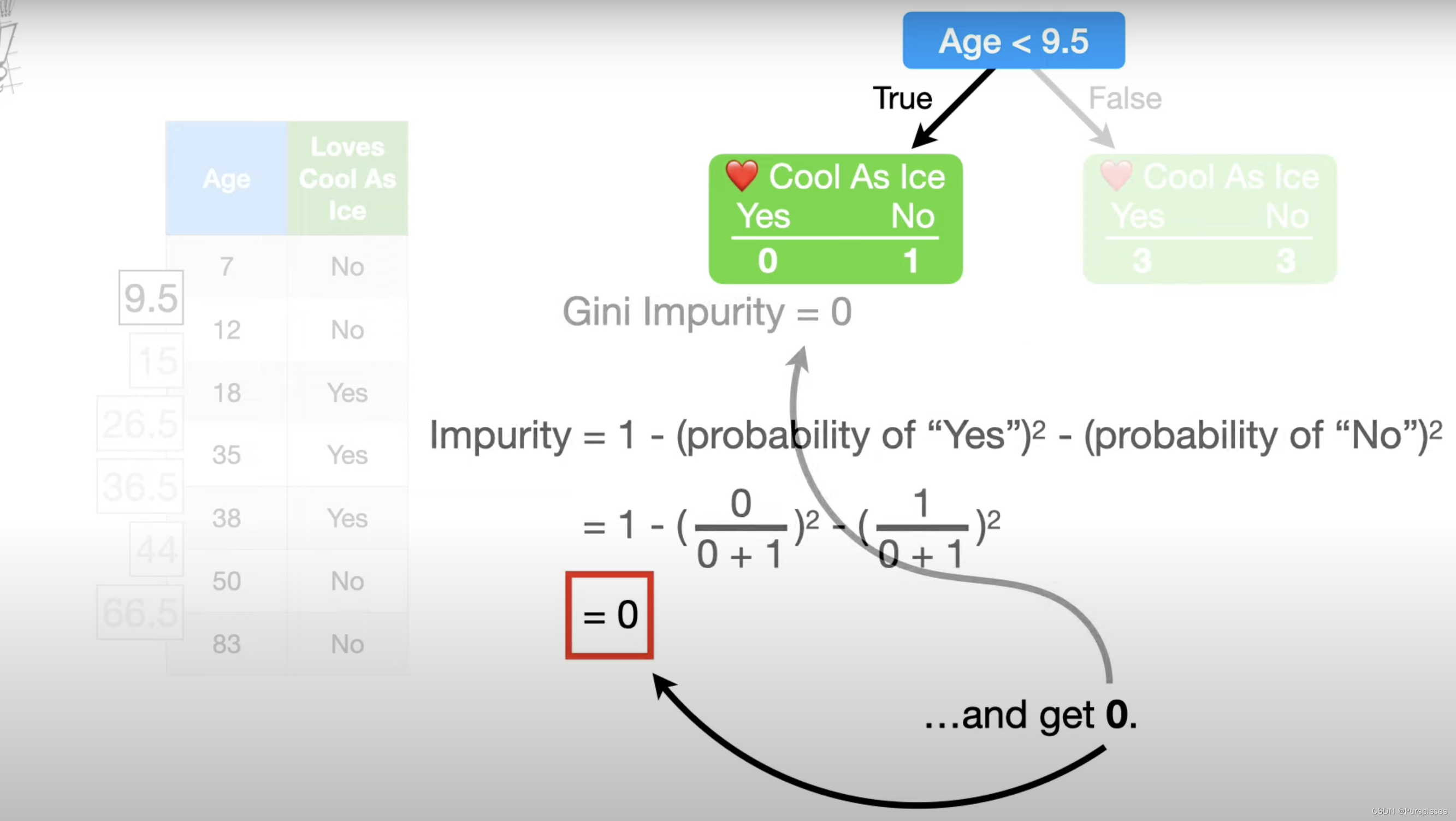
例如,为了计算第一个值的基尼不纯度,我们使用年龄<9.5作为根。
左叶子的基尼不纯度:
左叶子的基尼不纯度 = 1 − ( "yes"的概率 ) 2 − ( "no"的概率 ) 2 = 1 − ( 0 0 + 1 ) 2 − ( 1 0 + 1 ) 2 = 0 \text{左叶子的基尼不纯度} = 1 - (\text{"yes"的概率})^2 - (\text{"no"的概率})^2 \\ = 1 - \left(\frac{0}{0+1}\right)^2 - \left(\frac{1}{0+1}\right)^2 \\ = 0 左叶子的基尼不纯度=1−("yes"的概率)2−("no"的概率)2=1−(0+10)2−(0+11)2=0
这很有道理,因为这个叶子中的每个人都不喜欢《Cool as Ice》,所以没有不纯度。
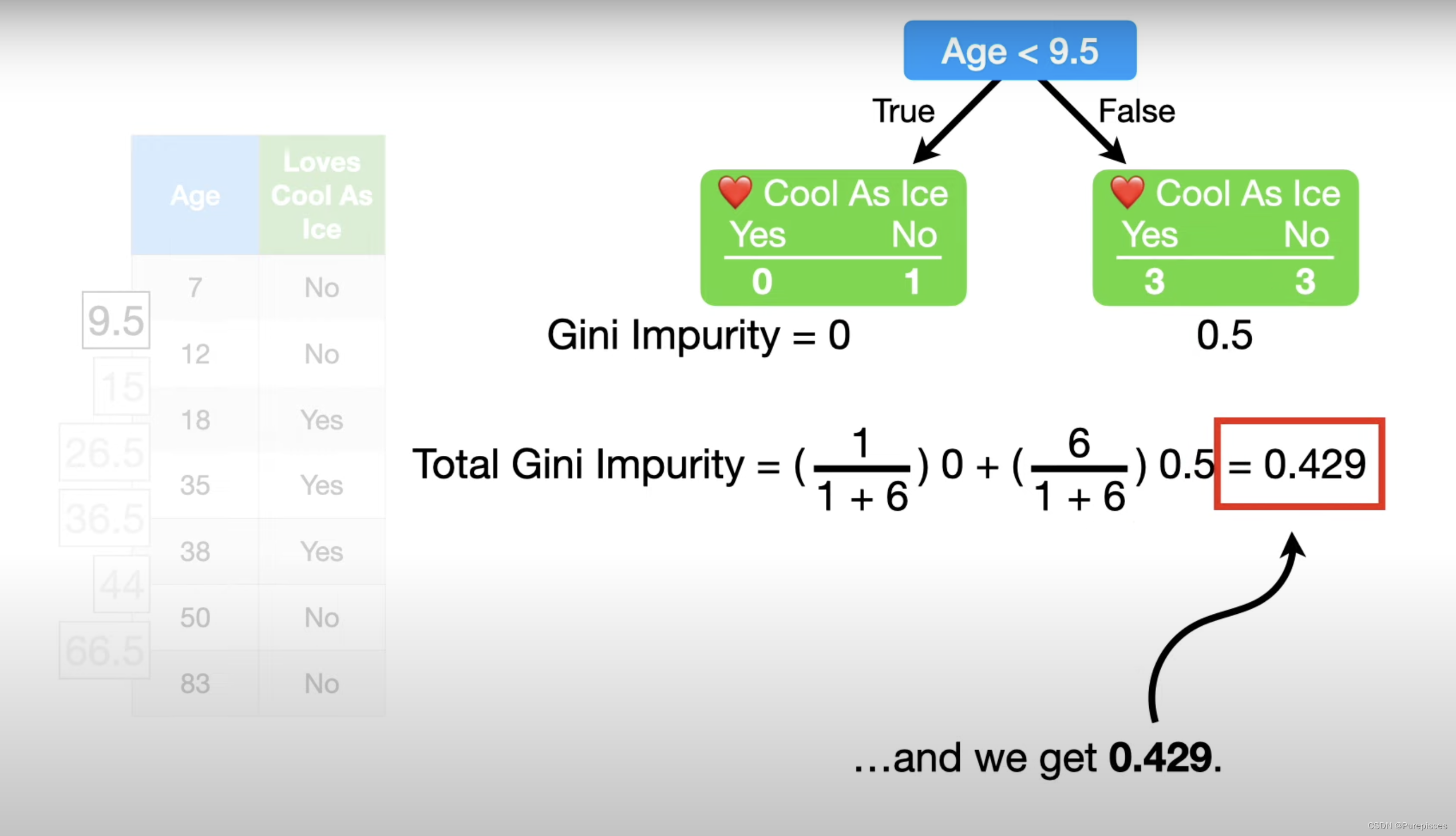
右叶子的基尼不纯度:
右叶子的基尼不纯度是0.5。现在我们计算两个不纯度的加权平均值以得到总基尼不纯度:
总基尼不纯度 = ( 1 1 + 6 ) × 0 + ( 6 1 + 6 ) × 0.5 = 0.429 \text{总基尼不纯度} = \left(\frac{1}{1+6}\right) \times 0 + \left(\frac{6}{1+6}\right) \times 0.5 \\ = 0.429 总基尼不纯度=(1+61)×0+(1+66)×0.5=0.429
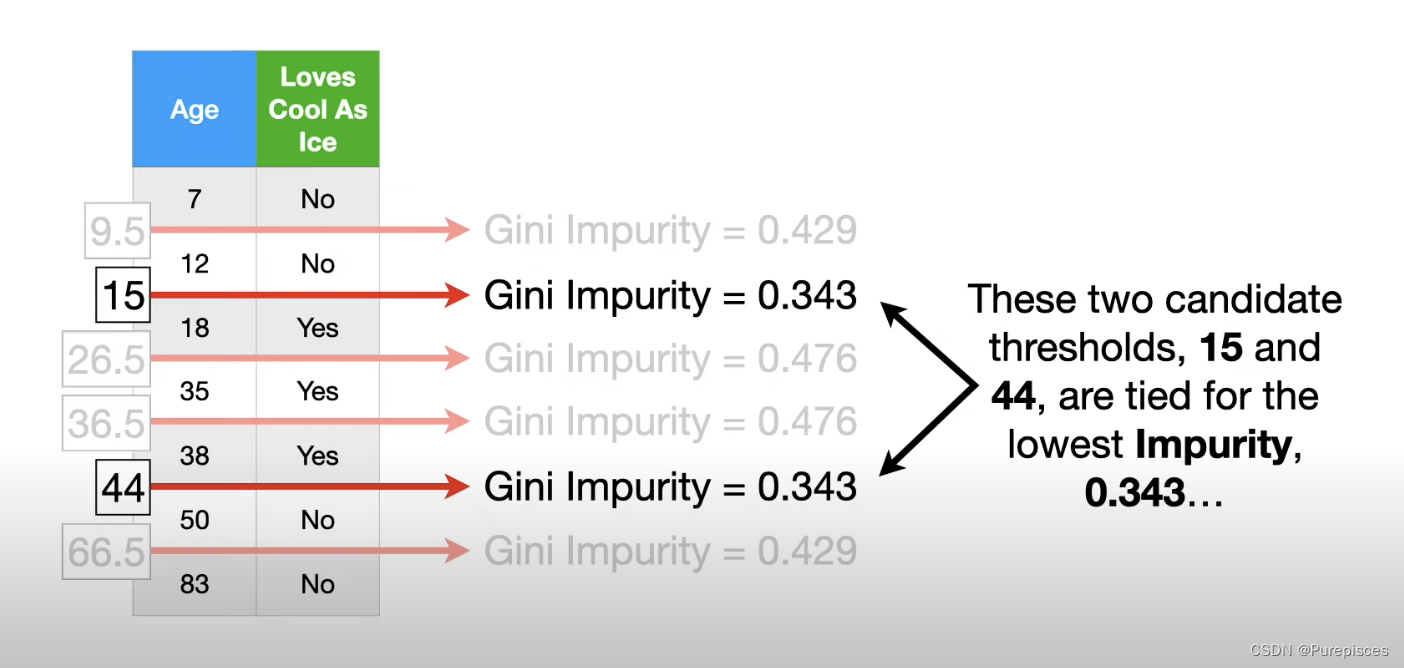
对于其他候选值,最低的不纯度是0.343,通过阈值15和44达到。我们将在此示例中选择15。
比较年龄、“喜欢爆米花”和“喜欢苏打水”的基尼不纯度(分别为0.343、0.405和0.214),"喜欢苏打水"具有最低的基尼不纯度,因此它位于树的顶部。
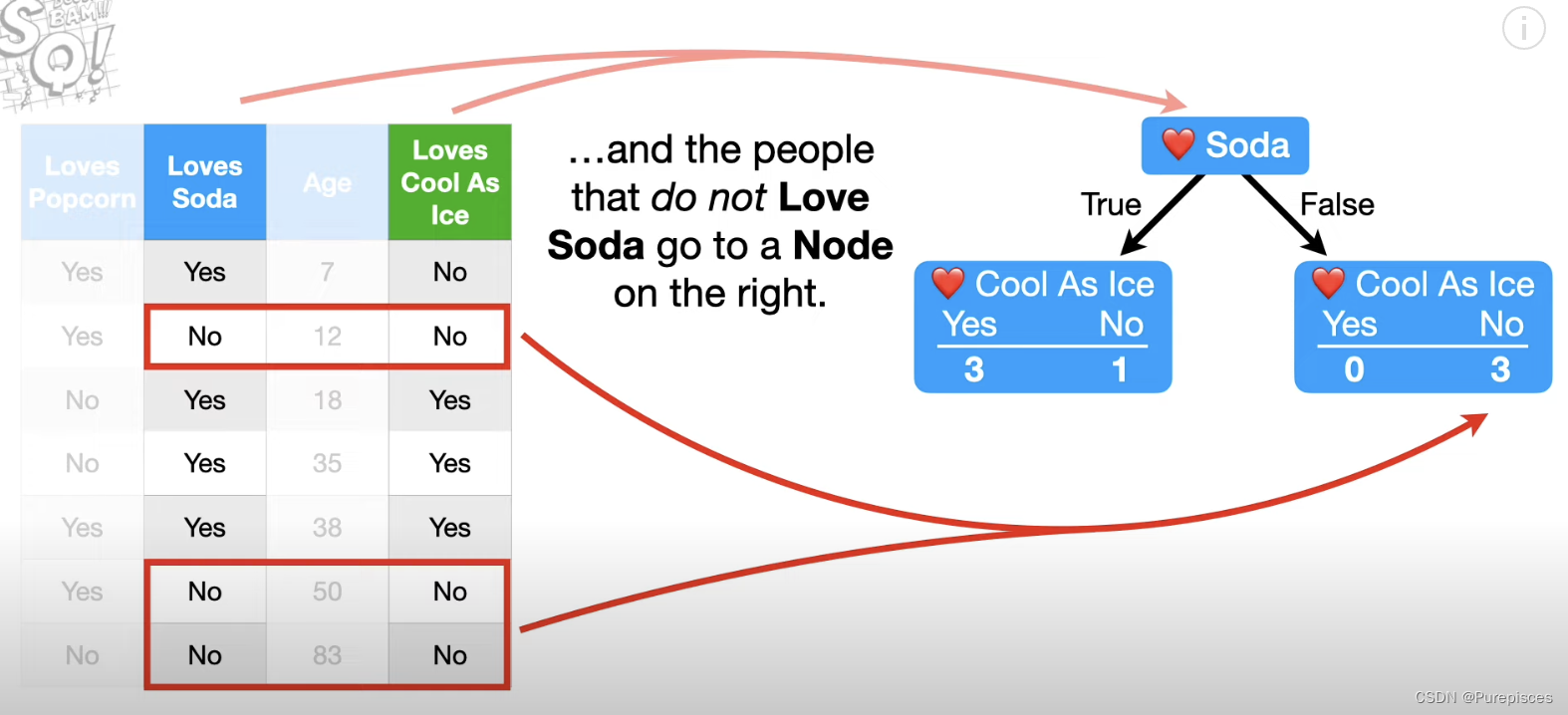
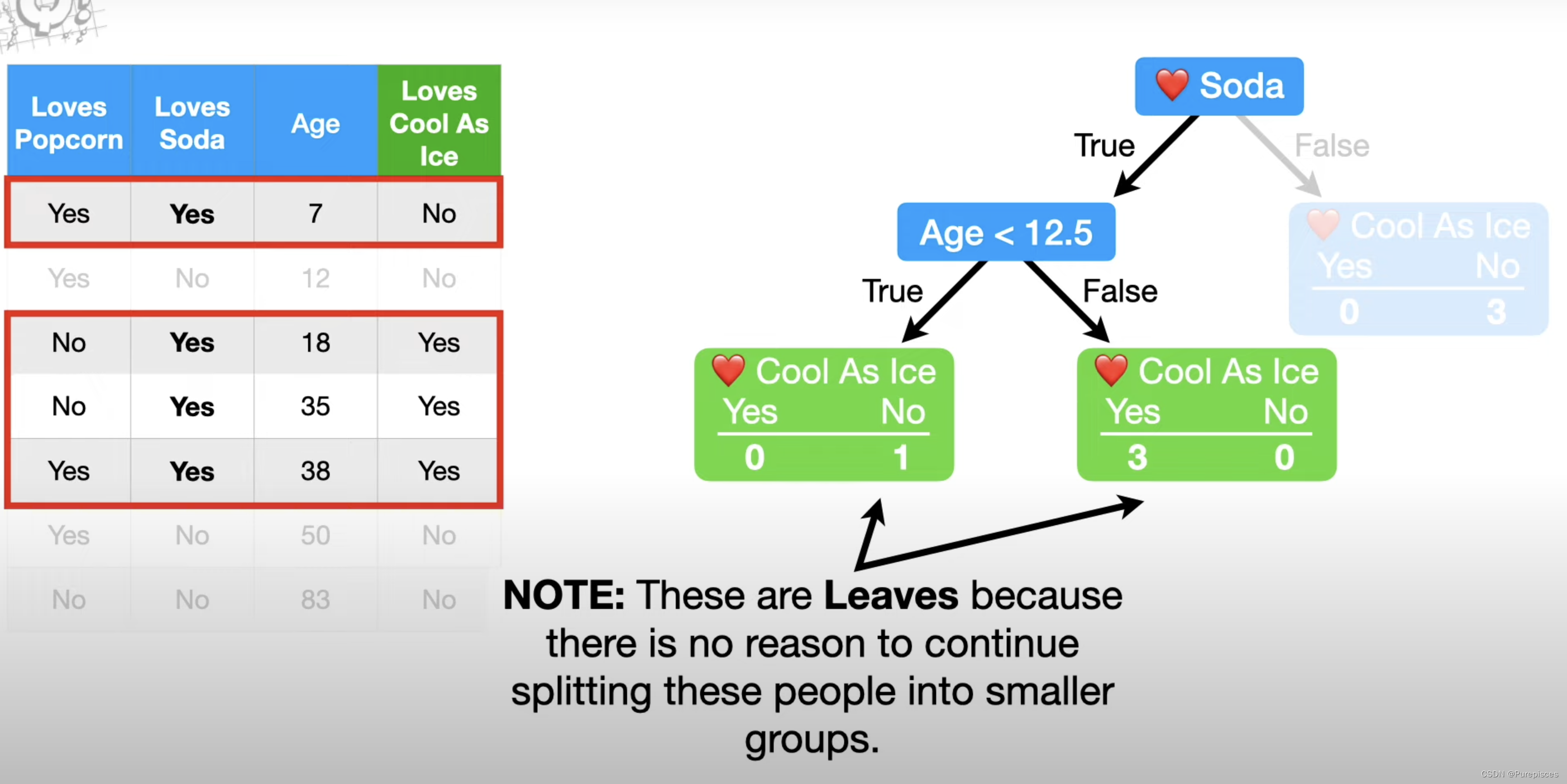
步骤2:找到内部节点
现在让我们关注左边的节点。所有喜欢苏打水的4个人都在这个节点中,3个人喜欢《Cool as Ice》,1个人不喜欢,因此这个节点是不纯的。所以让我们看看是否可以通过基于“喜欢爆米花”或年龄将喜欢苏打水的人分开来减少不纯度。我们将从问喜欢苏打水的4个人是否也喜欢爆米花开始。此拆分的总基尼不纯度为0.25。
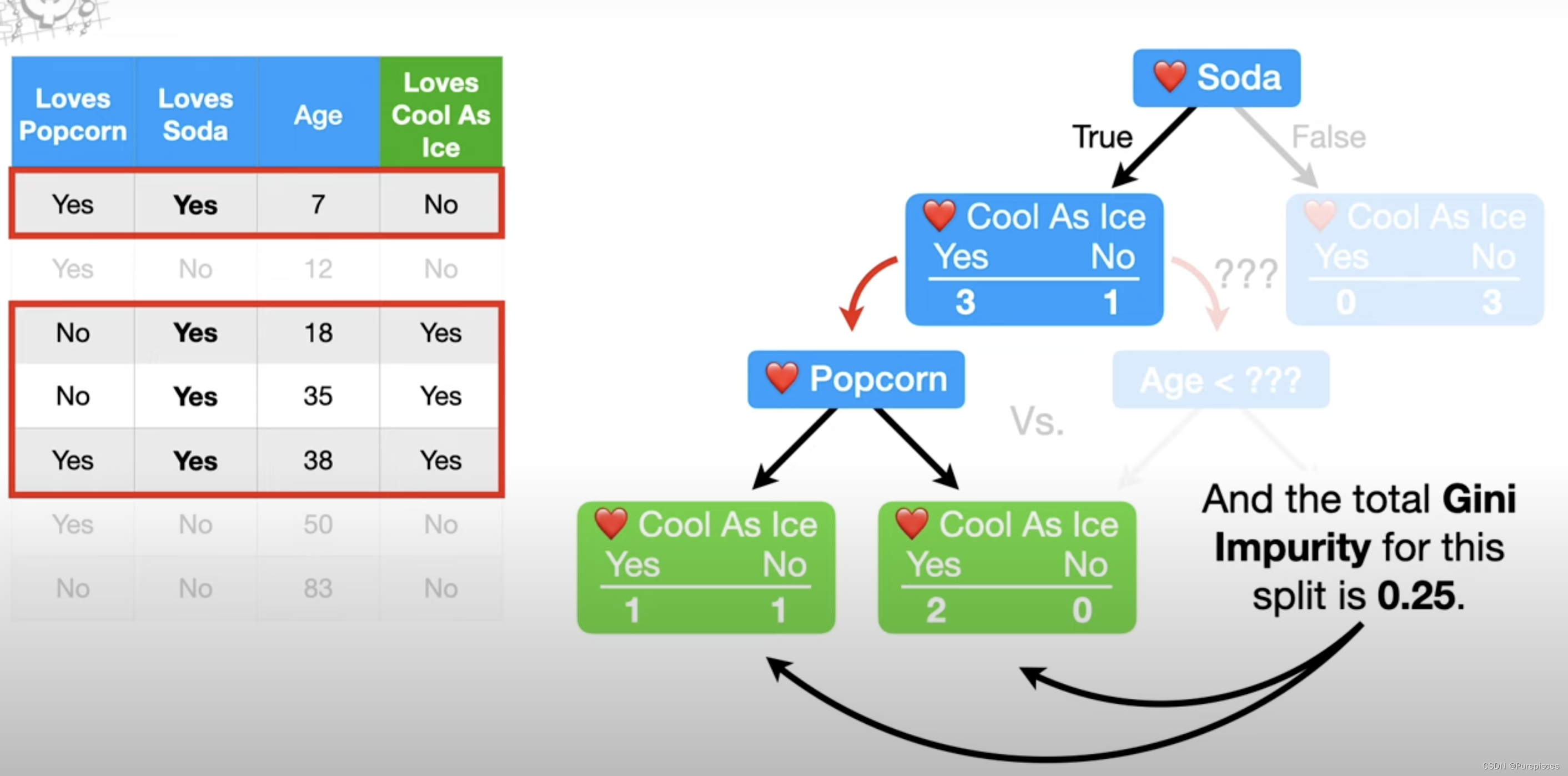
现在像之前一样测试不同的年龄阈值,这次只考虑喜欢苏打水的人的年龄,年龄<12.5给我们最低的不纯度0,因为这两个叶子都没有不纯度。
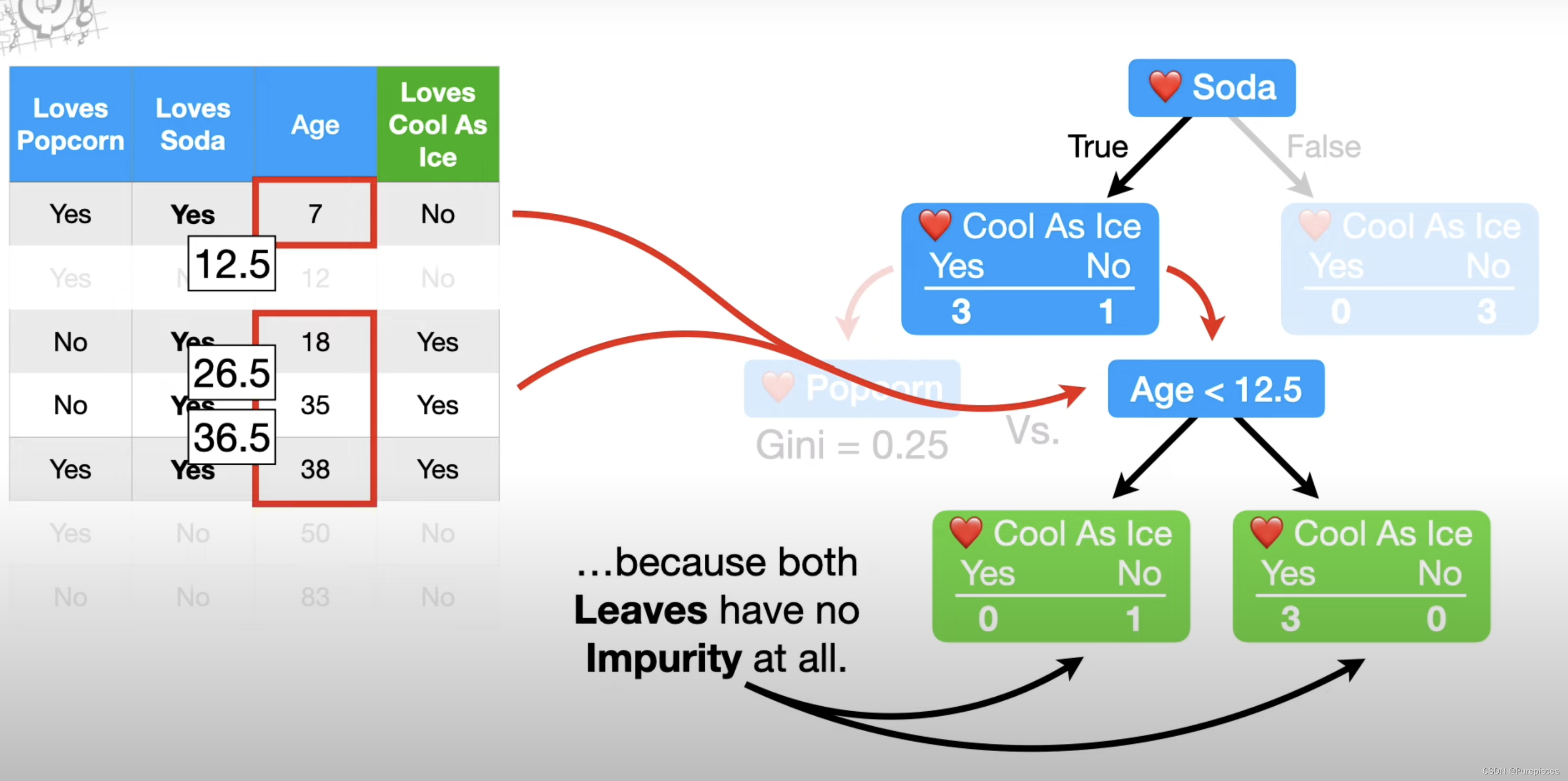
因为0小于0.25,所以我们使用年龄<12.5将此节点拆分为叶子。
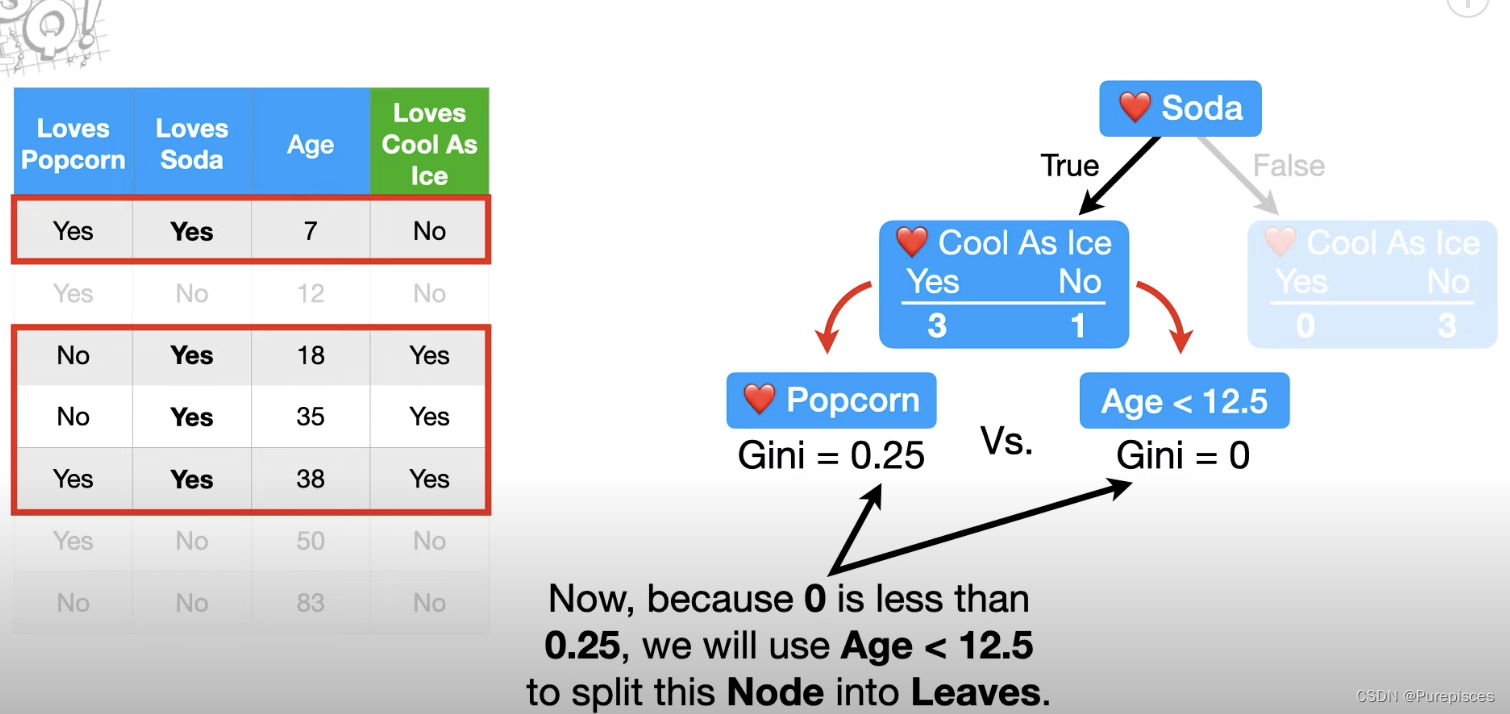
箭头指向叶子,不需要进一步拆分。
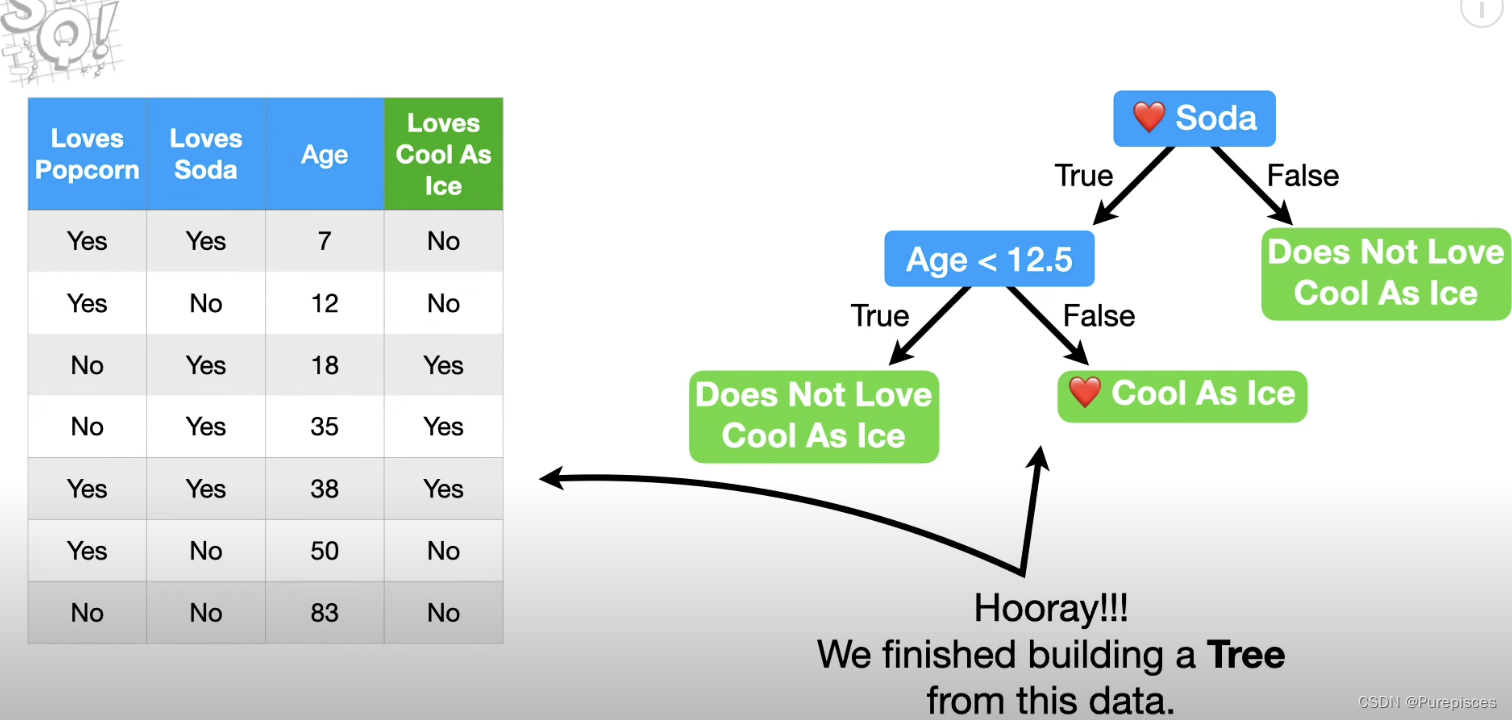
步骤3:分配输出值
叶子的输出是最多票的类别。例如,如果叶子中的大多数人喜欢《Cool as Ice》,那就是输出值。
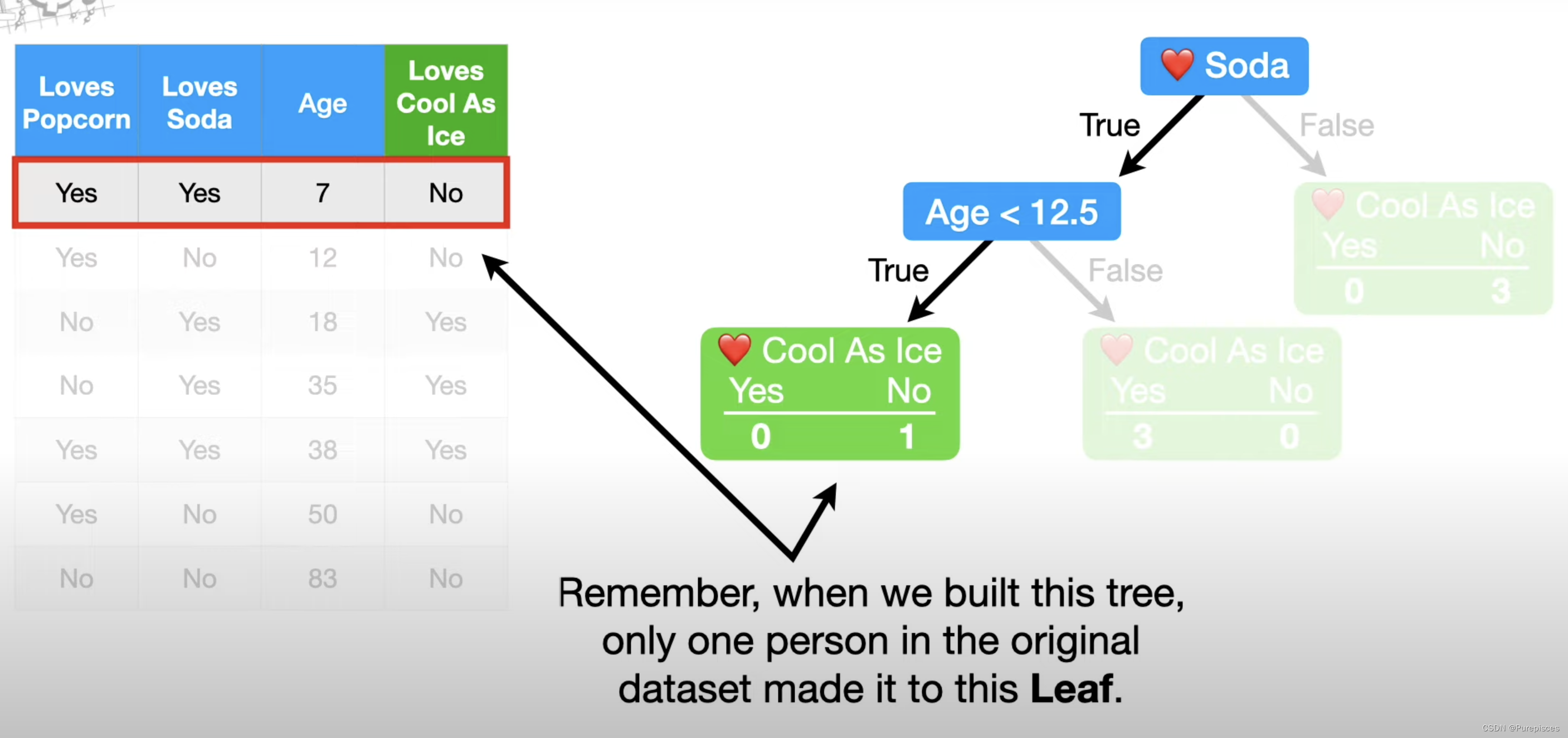
处理过拟合
最后,记住我们构建这棵树时,原始数据集中只有一个人进入了这个叶子。因为这么少的人进入了这个叶子,所以很难有信心它会在未来的数据中做出出色的预测。这表明我们可能对数据进行了过拟合。
在实践中,有两种主要方法来解决这个问题:
- 剪枝:这项技术涉及通过删除提供很少或没有预测能力的节点来修剪树。例如,如果我们有一个基于某个特征进行分裂的节点,但它并没有显著减少不纯度,我们可以删除这个节点并合并它的分支。这个简化有助于提高模型对新数据的泛化能力。想象一个基于某人是否喜欢很小众的电影分裂的节点,大多数人都没看过这部电影。如果这个分裂对预测结果没有帮助,我们可以剪掉这个节点以防止过拟合。
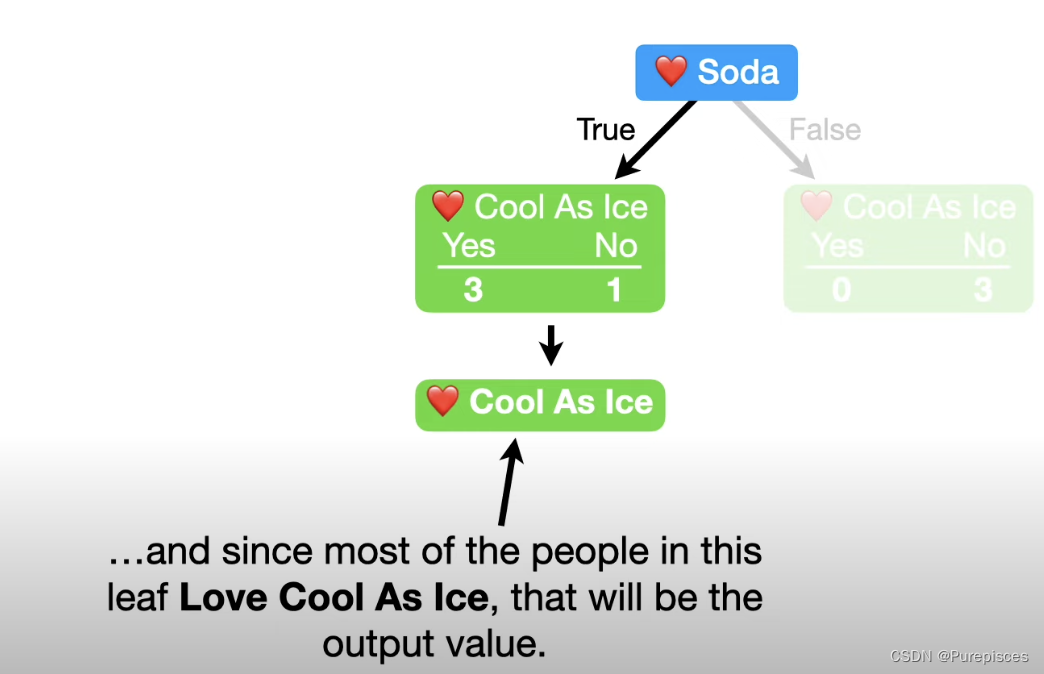
- 设置增长限制:我们可以限制树的增长,例如,要求每个叶子至少有3个人。这导致了一个不纯的叶子,但它更好地反映了我们预测的准确性。例如,如果叶子中的75%的人喜欢《Cool as Ice》,我们仍然需要一个输出值来进行分类。由于这个叶子中的大多数人喜欢《Cool as Ice》,那将是输出值。
此外,在构建树时,我们事先不知道每个叶子的最佳人数。因此,我们使用一种称为交叉验证的方法测试不同的值,并选择最适合的方法。