有问题欢迎评论,因为别人已经做过,所以写的不是很详细(感觉没必要了)
ml-agents版本:Release 22
UnityHub:最新的3.9.1
Unity编译器版本:2023.2.13f1
Python:3.10.2(可以从Anaconda中来,GitHub上有明确的版本范围要求)
安装细节
安装教程参考官方文档:
ml-agents/docs/Installation.md at release_22 · Unity-Technologies/ml-agents · GitHub
1.UnityHub 安装直接安装就行(只是一个集成平台,不重要)

2.Unity编译器下载:我下载的是2023.2.13f1 (需要一段时间,这个时候进行下面的准备)
 3.conda虚拟环境创建
3.conda虚拟环境创建
conda create -n mlagents python=3.10.12 && conda activate mlagents
拿到ml-agents源码release22版本:
git clone --branch release_22 https://github.com/Unity-Technologies/ml-agents.git
保证在mlagents虚拟环境中,安装pytorch
pip3 install torch~=2.2.1 --index-url https://download.pytorch.org/whl/cu121

安装完后,还需要安装mlagents包,主要是运行ml-agents-envs文件夹下的setup文件,再安装ml-agents文件夹下的setup文件,注意有先后顺序
进入到xxxx\ml-agents-release_22下,同时在虚拟环境中
cd ml-agents-envs
pip install -e . (注意有个.)
cd ..cd ml-agents
pip install -e .
安装以后打开文件项目

按理说 ML Agents 和 ML Agents Extension 会被自动安装的,没有就点+号 从硬盘装,就是com.unity.ml-agents和com.unity.ml-agents.extensions下的json文件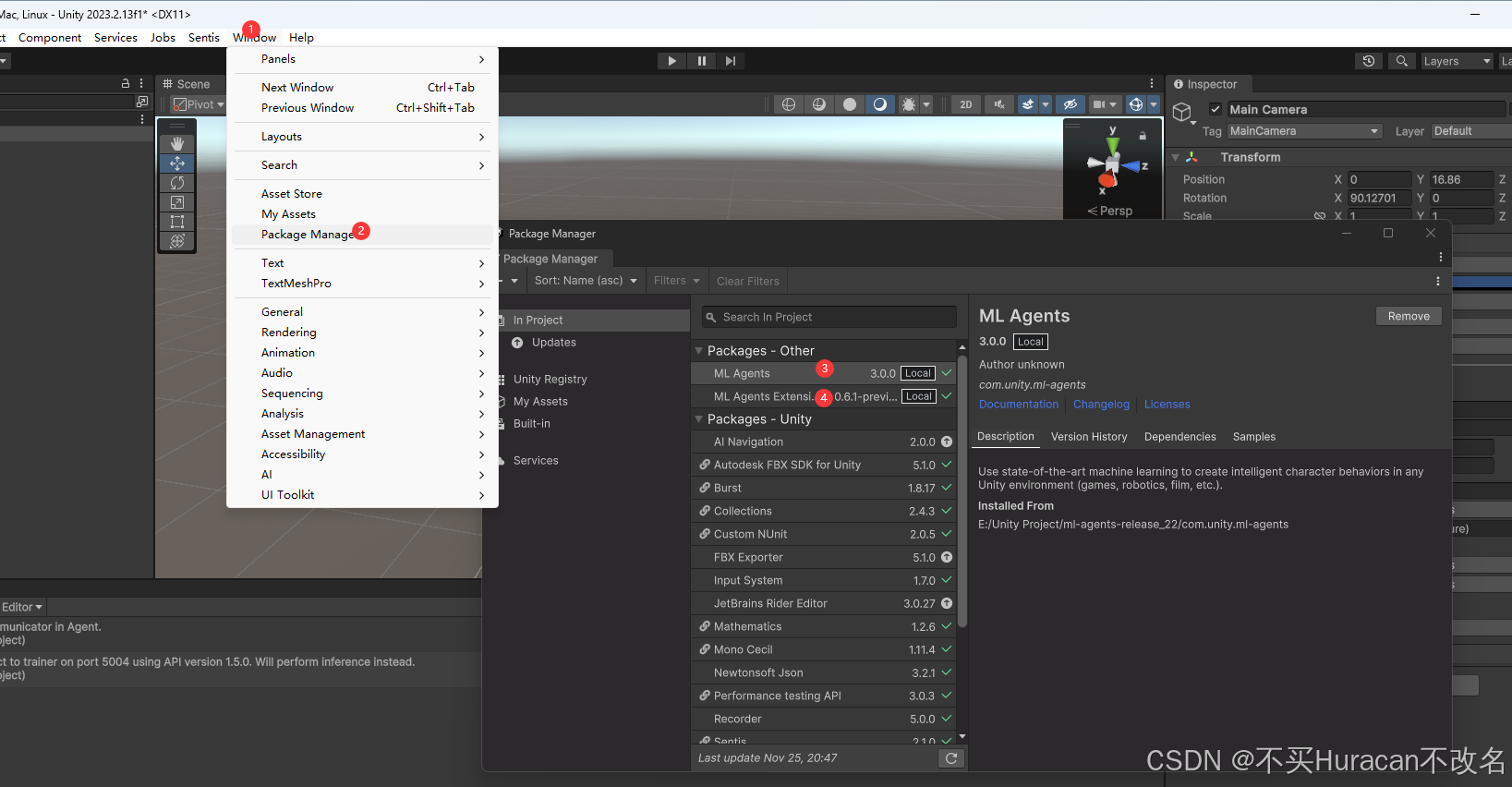

实现强化学习

目标:球尽可能的去撞(方块)
参考教程:ML-Agents(二)创建一个学习环(w境 - 煦阳 - 博客园
准备环境
新建一个文件夹存放场景文件

新建一个sence,然后双击他,默认有下面两个物品出现在屏幕中

然后创建 一个Plane(命名为Floor),一个方块Cube(Target),一个球Sphere(RollerAgent)
修改位置参数(尽量放在中间)


同理创建一个球Sphere(RollerAgent)
单击Inspector面板下的Add Component,添加一个Rigidbody

单击Add Component->New Script,新建一个脚本RollerAgent
其中Roller Agent代码:
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
using UnityEngine;
public class RollerAgent : Agent
{
[SerializeField]
private Transform Target; // 方块目标
public float speed = 10; // 小球移动速度
private Rigidbody rBody; // 小球刚体
private void Start()
{
// 获取刚体组件
rBody = GetComponent<Rigidbody>();
}
/// <summary>
/// Agent重置:每次训练开始时调用
/// </summary>
public override void OnEpisodeBegin()
{
// 如果小球掉落平台,重置其位置和速度
if (this.transform.position.y < 0)
{
rBody.velocity = Vector3.zero;
rBody.angularVelocity = Vector3.zero;
transform.position = new Vector3(0, 0.5f, 0);
}
// 随机移动目标方块的位置
Target.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
/// <summary>
/// 收集智能体的观察值
/// </summary>
/// <param name="sensor"></param>
public override void CollectObservations(VectorSensor sensor)
{
// 添加目标的位置 (3 个值:x, y, z)
sensor.AddObservation(Target.position);
// 添加小球的位置 (3 个值:x, y, z)
sensor.AddObservation(transform.position);
// 添加小球的速度 (2 个值:x, z,因为 y 方向不需要)
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
}
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 获取动作数组:连续动作
var continuousActions = actionBuffers.ContinuousActions;
// 动作控制小球的移动
Vector3 controlSignal = Vector3.zero;
controlSignal.x = continuousActions[0]; // x 轴方向的力
controlSignal.z = continuousActions[1]; // z 轴方向的力
rBody.AddForce(controlSignal * speed);
// 计算小球与目标的距离
float distanceToTarget = Vector3.Distance(transform.position, Target.position);
// 不同情况给奖励
if (distanceToTarget < 1.42f)
{
// 到达目标
SetReward(1.0f);
EndEpisode();
}
if (transform.position.y < 0)
{
// 小球掉落
EndEpisode();
}
}
/// <summary>
/// 手动测试用的动作生成逻辑(启用 Heuristic Only 时调用)
/// </summary>
/// <param name="actionsOut"></param>
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActions = actionsOut.ContinuousActions;
continuousActions[0] = Input.GetAxis("Horizontal"); // 左右
continuousActions[1] = Input.GetAxis("Vertical"); // 前后
// 调试信息
Debug.Log($"Heuristic Actions: {continuousActions[0]}, {continuousActions[1]}");
}
}
同理单击Add Component,添加Behavior Parameters,如下设置

继续添加Decision Requester组件 (不然小球是无法动起来的)

如果到现在都是编译正常的,上面脚本中 下面的代码决定了小球的属性中,应该有一个Targe选项,需要把Target这个物体拖到这个空上,也就是下面的图(没有这个属性代表编译有问题)
[SerializeField]
private Transform Target; // 方块目标

开始训练
准备一个训练参数文件rollerball_config.yaml,放到哪里都行但是要记住,我在config文件夹下
behaviors:
RollerBallBrain:
trainer_type: ppo
hyperparameters:
batch_size: 64
buffer_size: 2048
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000
要进入虚拟环境并且进入文件夹下,运行run-id代表了result文件夹下结果的文件夹名字
mlagents-learn config/rollerball_config.yaml --run-id=RollerBall-1 --train

根据提示 回到Unity点击Play,然后可以看到小球在疯狂的乱撞

然后等待Mean Reward接近于1 就可以Ctrl c 停止了
输出信息提示有一个onnx文件被保存了,把他导入Unity后导入到小球的属性中,修改如下两处

点击运行就可以看到最开始展示的效果了。