一.初识排序
排序是将一组数据元素按照特定的顺序(如升序或降序)进行重新排列的操作。排序算法则是实现这种数据重新排列的具体方法。
c/c++中,这些元素可以是各种数据类型,比如整数、浮点数、字符串,甚至是自定义的结构体或类对象。排序的目的通常是为了提高数据检索、分析和处理的效率。例如,在一个已排序的数组中进行二分查找,时间复杂度可以从无序数组的 O(n) 降低到 O(log n)。
不同的排序算法在时间复杂度、空间复杂度和稳定性等方面各有特点:
①时间复杂度:衡量算法执行所需时间随数据规模增长的变化情况,如 O(n^2)、O(n \log n) 等。
②空间复杂度:表示算法在执行过程中临时占用存储空间的大小,例如 O(1) 表示原地排序,不需要额外的大量空间。
③稳定性:若排序前后相同元素的相对顺序保持不变,该排序算法就是稳定的。比如在对包含相同分数的学生成绩进行排序时,稳定排序能保证原有的学生顺序关系不变。
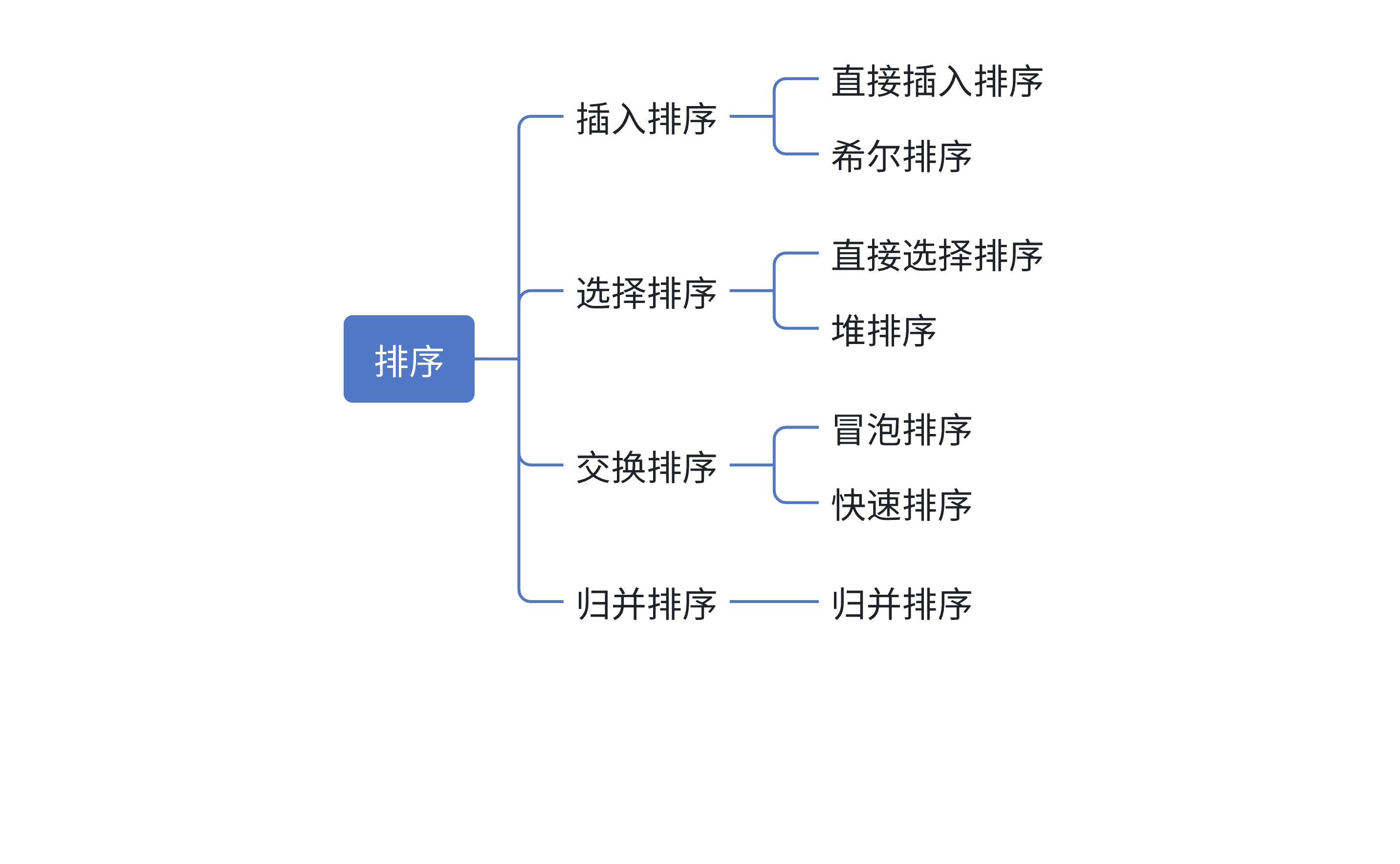
常见的排序算法包括冒泡排序、插入排序、选择排序、快速排序、归并排序、堆排序等,每种算法都基于不同的策略来实现数据的排序。
二.常见排序算法的模拟实现
1.插入排序
插入排序是把数据分为已排序和未排序两部分。起初,已排序部分只有第一个元素。接着,算法从第二个元素开始,依次将未排序元素取出,在已排序部分从后往前找合适位置插入。每次插入后,已排序部分依然有序,直至所有元素都插入到已排序部分,完成整个序列的排序。插入排序适用于小规模数据或部分有序的数据,平均和最坏时间复杂度为 O(n^2),最好情况接近 O(n),空间复杂度 O(1),且是稳定排序算法 。
①直接插入排序
当插入第 i(i>=1) 个元素时,前⾯的array[0],array[1],…,array[i-1] 已经排好序,此时
⽤ array[i] 的排序码与 array[i-1],array[i-2],… 的排序码顺序进⾏⽐较,找到插⼊位置即将 array[i] 插入,原来的位置上的元素顺序后移。
如下图所示
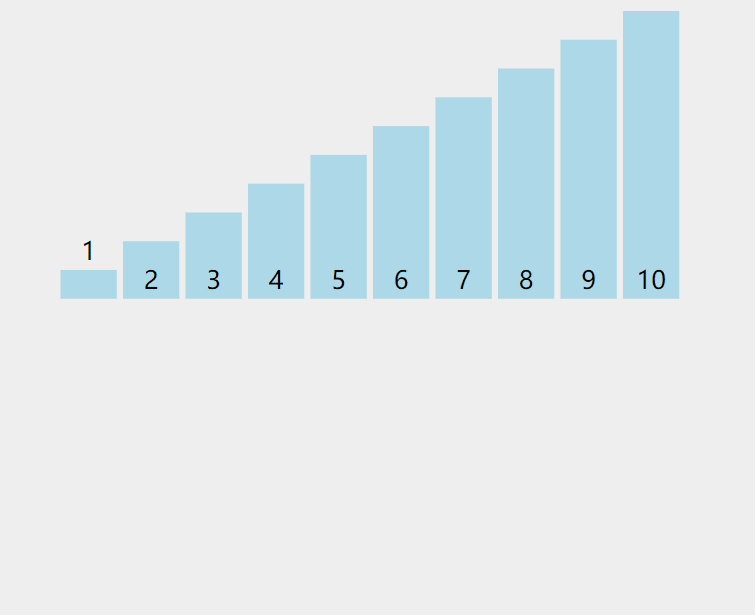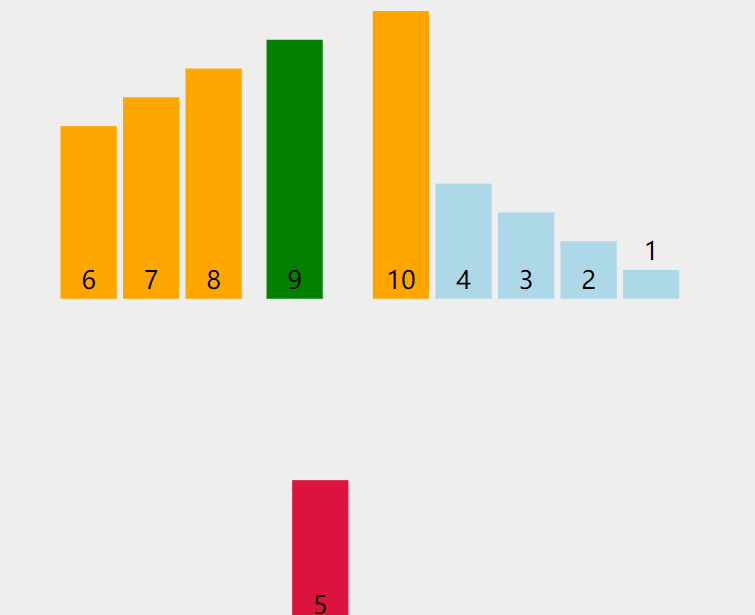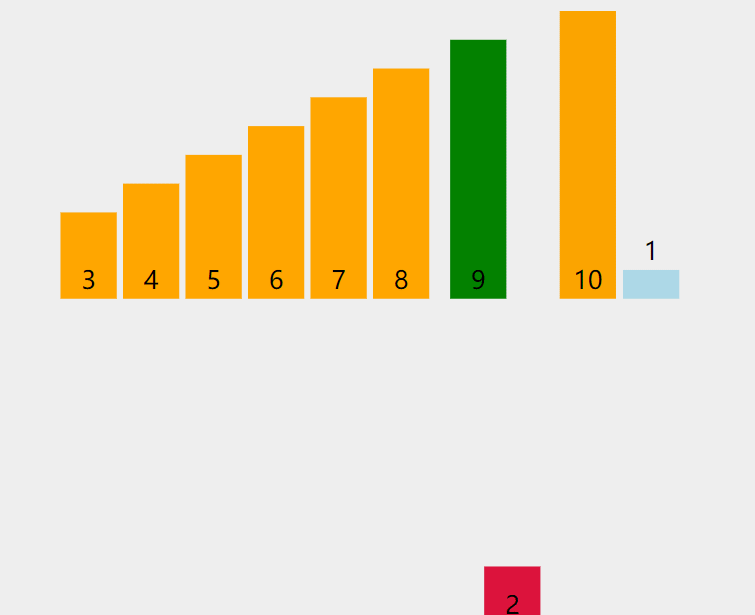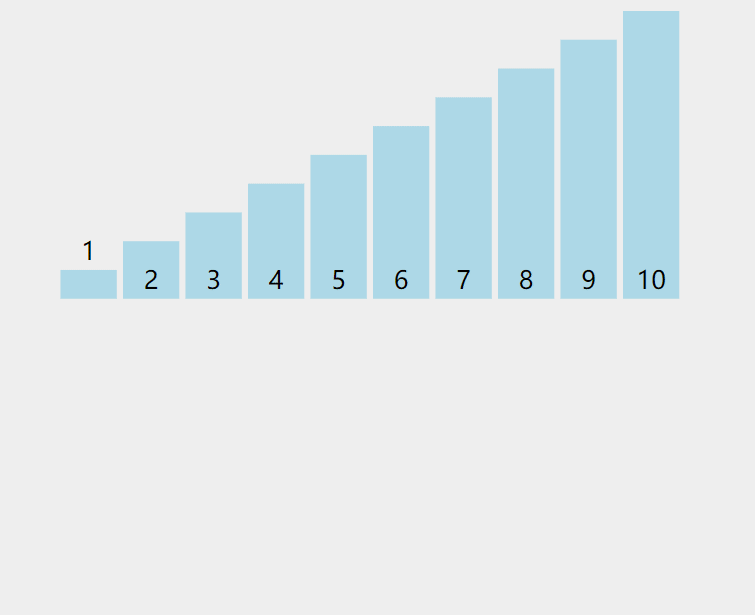
参考代码
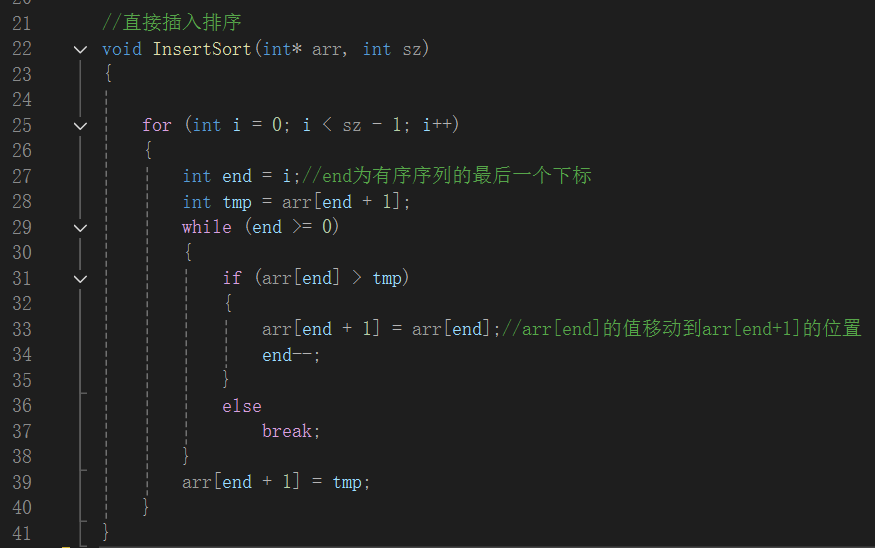
这段实现直接插入排序的代码。直接插入排序是一种简单直观的排序算法,它将一个数据插入到已经排好序的数组中的适当位置。这段代码中,外层循环逐步扩大有序序列范围,内层循环通过比较和移动元素,把当前无序部分的第一个元素插入到有序序列的合适位置,最终实现整个数组的有序排列。
测试结果 如下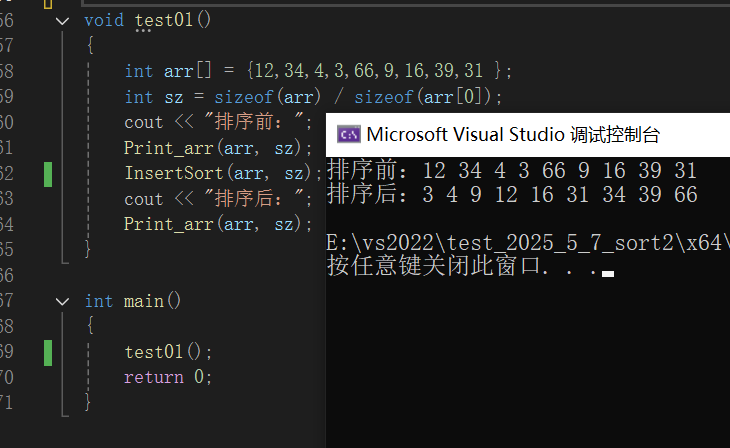
②希尔排序
希尔排序(Shell Sort)是插入排序的改进版,也叫缩小增量排序。
基本思想
先把待排序记录序列分割成若干子序列分别进行直接插入排序,使序列“基本有序”后,再对全体记录进行一次直接插入排序。这里“基本有序”指数据元素相对位置大致正确,离最终位置不远。
算法步骤
1. 选增量序列:确定 h_1, h_2, \cdots, h_t 这样的增量序列,满足 h_1 > h_2 > \cdots > h_t = 1 。常见的如希尔提出的 h_i = \frac{n}{2^k} (n 是待排序序列长度,k 从大到小取值 )。
2. 分组排序:依据增量 h_i 将序列分成 h_i 个子序列(元素下标间隔为 h_i ),分别对这些子序列做直接插入排序。
3. 重复操作:不断减小增量并重复分组排序步骤,当增量为 1 时,进行最后一次直接插入排序,此时序列有序。
性能特点
①时间复杂度:和增量序列选择相关,最坏情况 O(n^2) ,一般比直接插入排序的 O(n^2) 优,平均约 O(n^{1.3}) 。
②空间复杂度:是就地排序,仅需少量额外变量用于元素比较交换,空间复杂度 O(1) 。
③ 稳定性:不稳定,不同子序列排序时相同元素相对位置可能改变。
参考代码
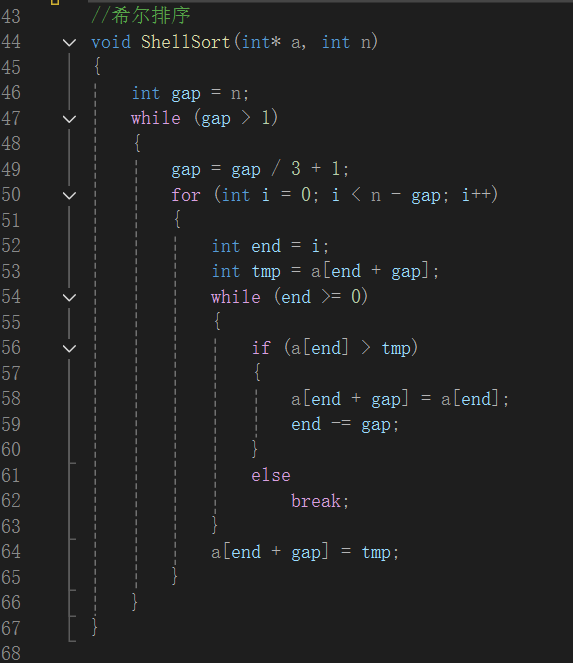
实现希尔排序的代码。希尔排序是对直接插入排序的改进,通过设置不同的增量将数组分组排序。代码中, gap 代表增量,先进行较大增量的分组排序,逐步缩小增量。内层循环中,类似直接插入排序的方式,将待插入元素与有序组内元素比较并移动,直至找到合适位置插入,最终实现数组整体有序。
测试结果如下
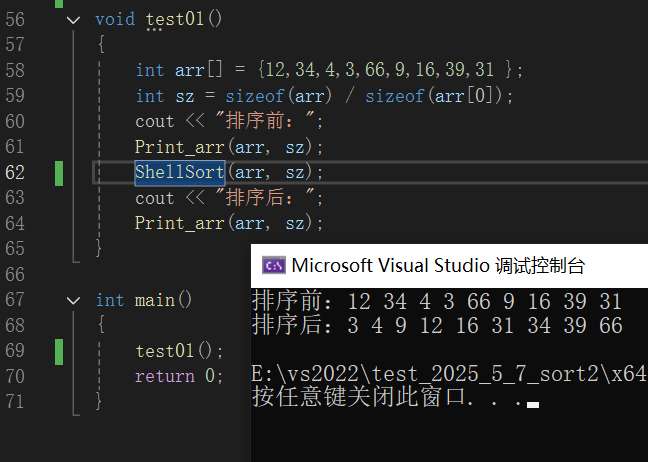
2.选择排序
选择排序是简单直观的排序算法。它每次从待排序数据中选出最小(或最大)元素,存放到排序序列起始位置,然后继续从未排序元素中找最值,依次放入已排序序列末尾,直到所有元素排序完毕。其时间复杂度一般为 O(n^2) ,空间复杂度 O(1) ,是不稳定排序算法。
①直接选择排序
1.在元素集合 array[i]--array[n-1] 中选择关键码最⼤(⼩)的数据元素
2. 若它不是这组元素中的最后⼀个(第⼀个)元素,则将它与这组元素中的最后⼀个(第⼀个)元素 交换
3. 在剩余的 array[i]--array[n-2](array[i+1]--array[n-1]) 集合中,重复上述步 骤,直到集合剩余1个元素为止。
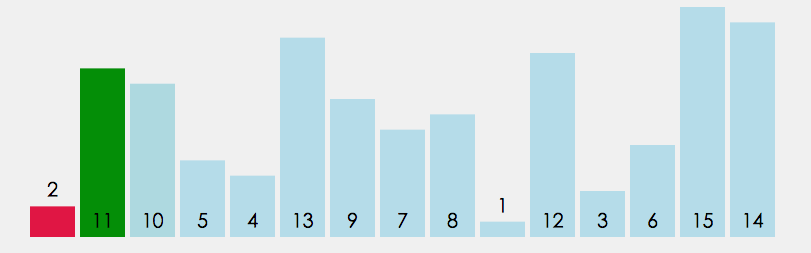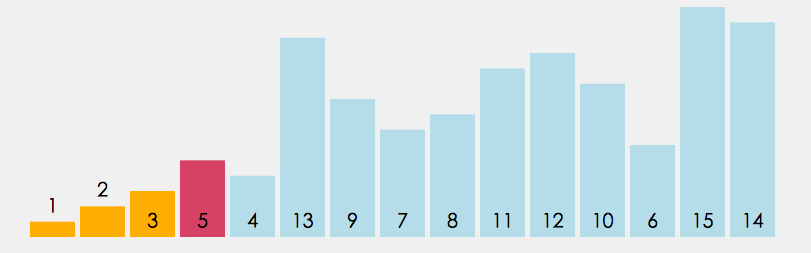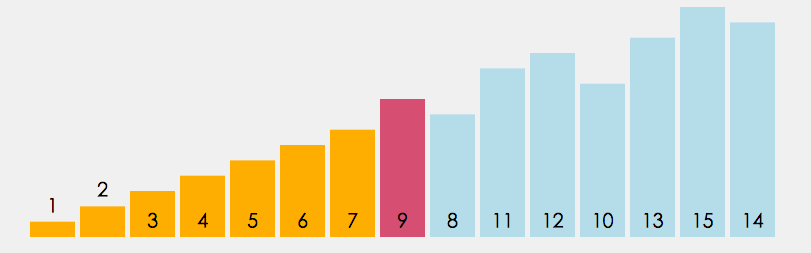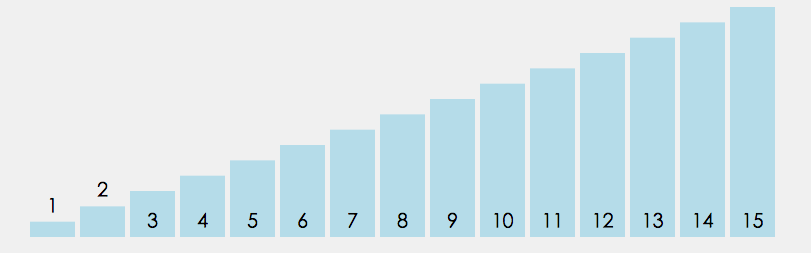
参考代码
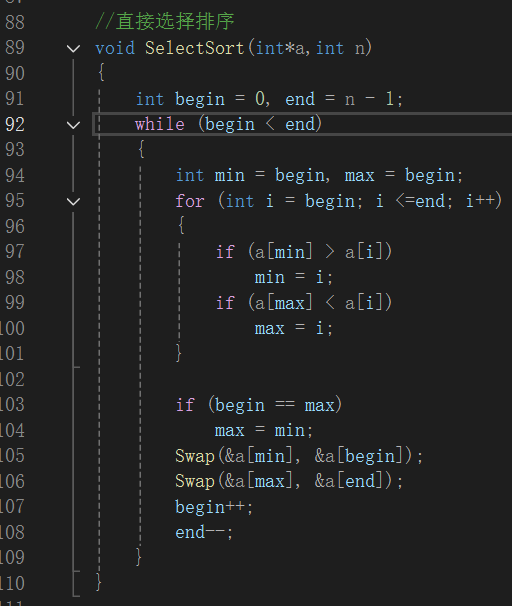
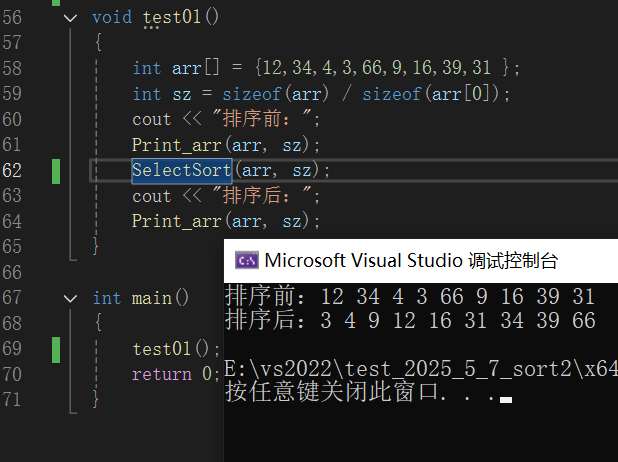
直接选择排序代码。通过 while 循环,每次在 begin 到 end 这个范围内找最小和最大的数,分别标记下标。如果起始位置恰好是最大数,就调整下。然后把最小数和起始位置交换,最大数和末尾位置交换,逐步缩小范围,实现数组的排序。
测试结果如下
3. 交换排序
交换排序基本思想:
所谓交换,就是根据序列中两个记录键值的⽐较结果来对换这两个记录在序列中的位置
交换排序的特点是:将键值较⼤的记录向序列的尾部移动,键值较⼩的记录向序列的前部移动
①冒泡排序
冒泡排序是经典排序算法。它重复走访待排序元素,两两比较,若顺序不对则交换,每轮将最大(或最小)元素“冒泡”到末尾。其原理简单,时间复杂度平均和最坏为 O(n^2) ,最好 O(n) (数据已有序时) ,空间复杂度 O(1) ,是稳定排序算法。
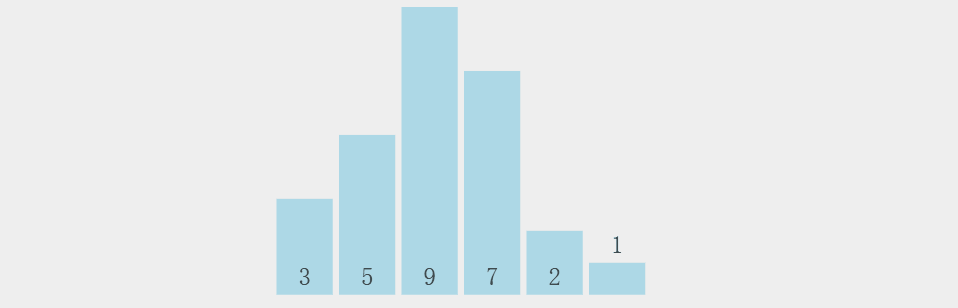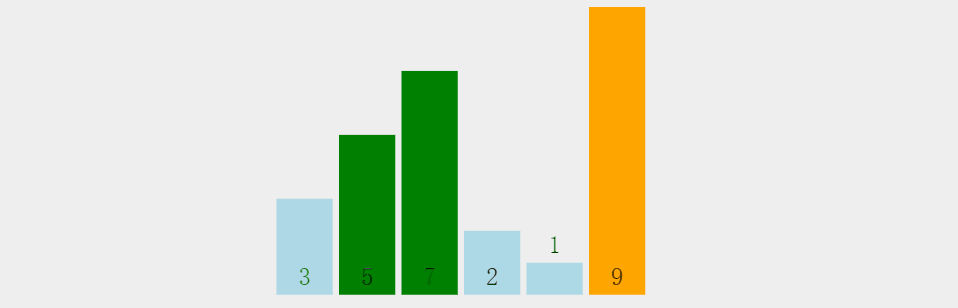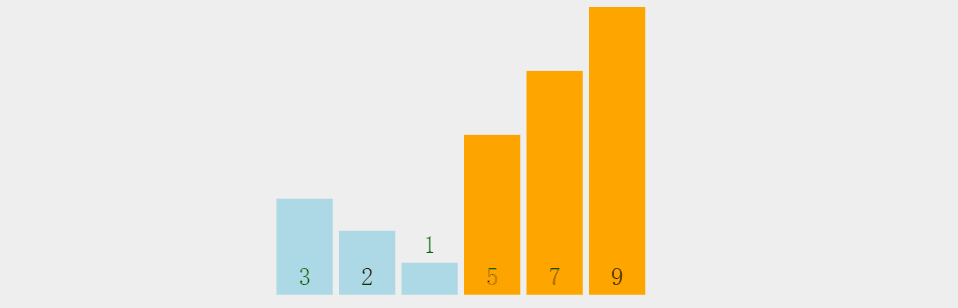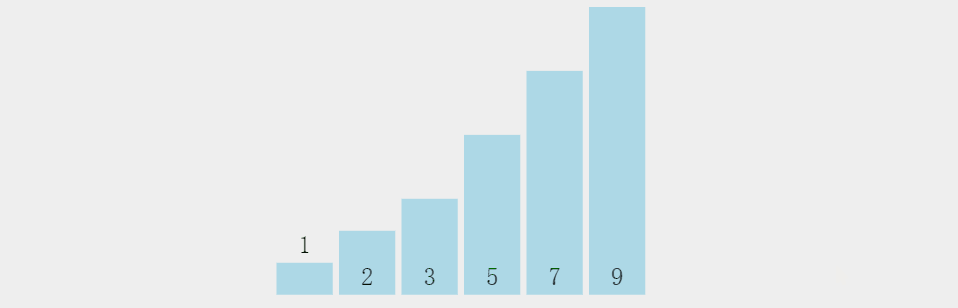
参考代码
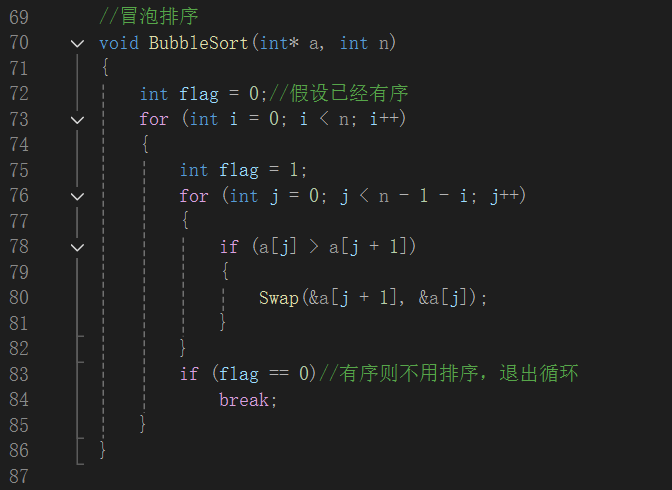 实现冒泡排序。冒泡排序通过多次比较相邻元素并交换来实现排序。此代码中外层循环控制轮数,内层循环负责每轮比较相邻元素并交换逆序对。 flag 用于标记该轮是否有交换,若无交换说明数组已有序,可提前结束排序,提高效率。
实现冒泡排序。冒泡排序通过多次比较相邻元素并交换来实现排序。此代码中外层循环控制轮数,内层循环负责每轮比较相邻元素并交换逆序对。 flag 用于标记该轮是否有交换,若无交换说明数组已有序,可提前结束排序,提高效率。
测试结果如下
②快速排序
快速排序是Hoare于1962年提出的⼀种⼆叉树结构的交换排序⽅法,其基本思想为:任取待排序元素 序列中的某元素作为基准值,按照该排序码将待排序集合分割成两⼦序列,左⼦序列中所有元素均⼩ 于基准值,右⼦序列中所有元素均⼤于基准值,然后最左右⼦序列重复该过程,直到所有元素都排列 在相应位置上为⽌。
其平均时间复杂度为 O(nlogn) ,相比一些简单排序算法效率更高,在处理大规模数据时优势明显。但在最坏情况下(如数组基本有序且每次选最小或最大元素作基准) ,时间复杂度会退化到 O(n^2) ,空间复杂度平均为 O(logn) ,属于不稳定排序算法。
参考代码
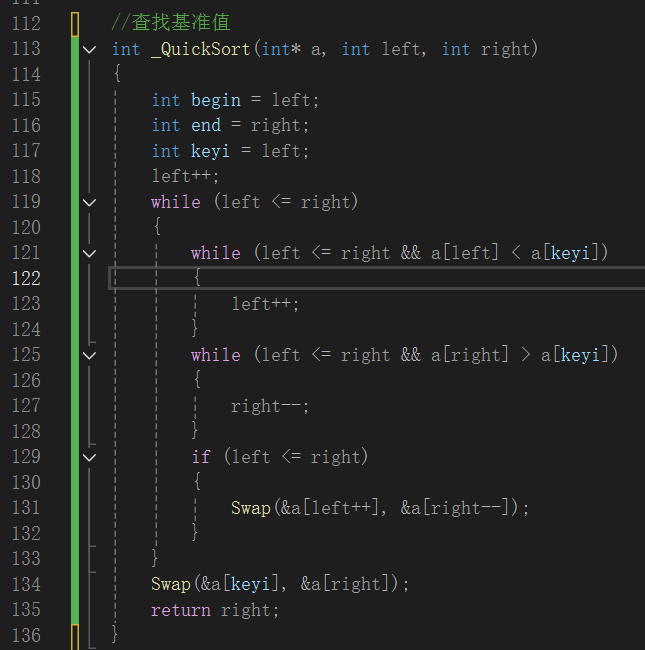
实现快速排序中查找基准值位置的代码。它选取数组起始元素为基准值,通过左右两个指针( left 和 right )在数组中移动并比较元素,将小于基准值的元素放左边,大于的放右边,最终把基准值放到合适位置,并返回该位置下标,为后续快速排序做准备。
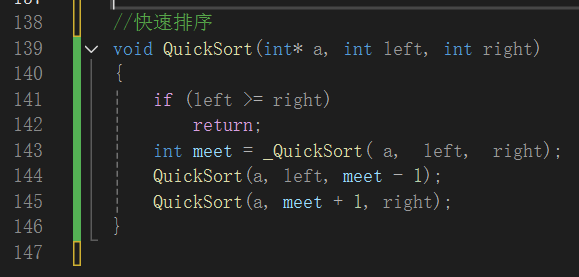
一段实现快速排序的代码。快速排序采用分治思想,此代码中先判断左右边界,若左边界大于等于右边界,说明子数组无需排序,直接返回。然后调用 _QuickSort 函数获取基准值的最终位置 meet ,再分别对基准值左右两侧子数组递归调用 QuickSort 函数,逐步完成整个数组的排序。
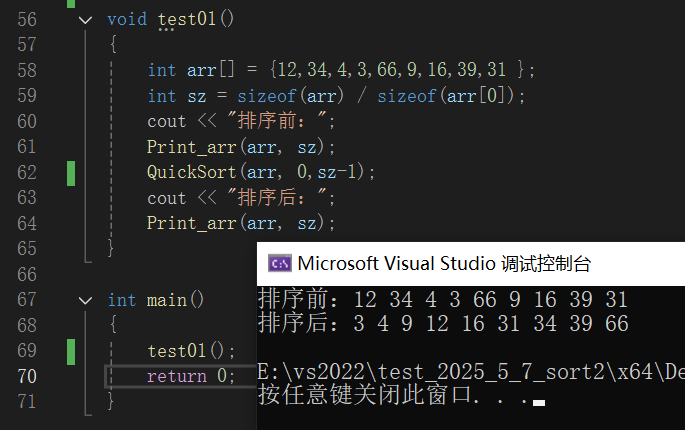
测试结果如下
三.比较几种排序的性能
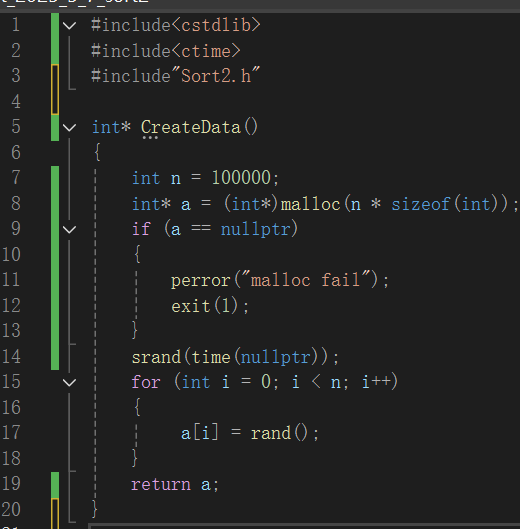
以上代码,功能是创建包含100000个随机整数的数组。代码通过 malloc 函数分配内存,若分配失败则输出错误信息并终止程序。接着利用 srand 结合当前时间设置随机数种子,再通过循环用 rand 函数为数组元素赋值,最后返回指向该数组的指针,为后续排序等操作准备数据。
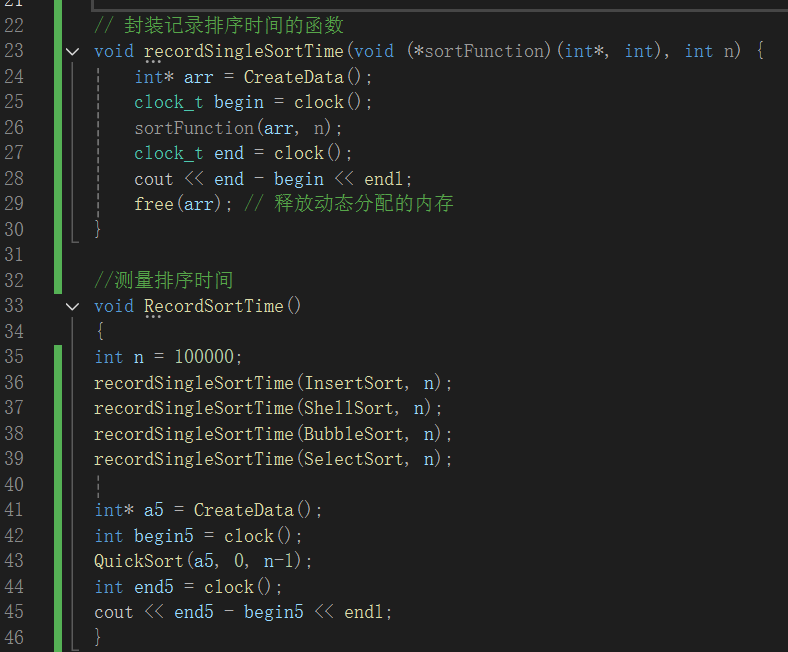
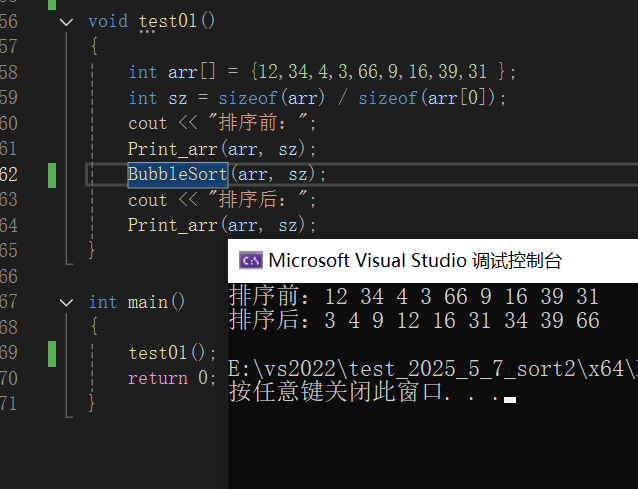
这段C++ 代码用于记录不同排序算法的运行时间。 recordSingleSortTime 函数实现了对单个排序算法计时的功能,它先调用 CreateData 函数创建包含100000个随机整数的数组,接着用 clock 函数记录排序开始和结束的时间点,计算差值得到排序耗时并输出,最后释放数组内存。
RecordSortTime 函数则负责批量测量多种排序算法的时间,依次调用 recordSingleSortTime 来记录直接插入排序( InsertSort )、希尔排序( ShellSort )、冒泡排序( BubbleSort )、直接选择排序( SelectSort )的耗时。此外,还单独对快速排序( QuickSort )进行计时操作,先创建数据数组,记录排序前后时间,输出快速排序的运行时长,从而方便对比不同排序算法的效率。
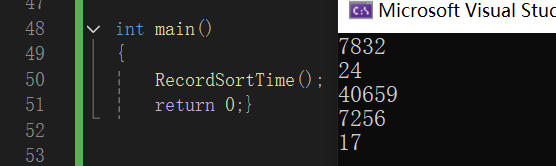 main 函数部分,调用 RecordSortTime 函数来测量多种排序算法的运行时间。右侧控制台输出的数值,单位为ms,应分别对应直接插入排序、希尔排序、冒泡排序、直接选择排序和快速排序的耗时。通过这些耗时数据,能直观对比不同排序算法在处理数据时的效率高低。
main 函数部分,调用 RecordSortTime 函数来测量多种排序算法的运行时间。右侧控制台输出的数值,单位为ms,应分别对应直接插入排序、希尔排序、冒泡排序、直接选择排序和快速排序的耗时。通过这些耗时数据,能直观对比不同排序算法在处理数据时的效率高低。