图像分类系统
一、简介
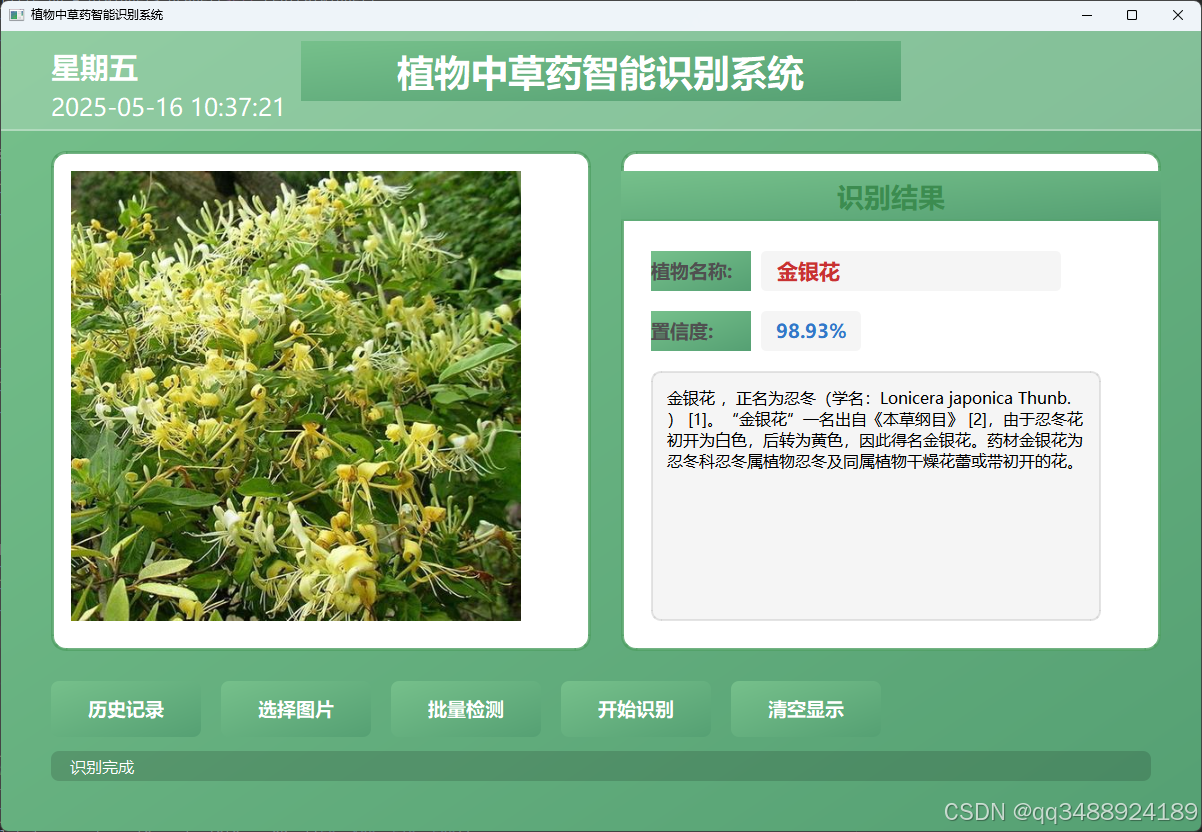
本项目构建了基于swin_transformer的植物中草药分类识别系统。凭借swin_transformer卓越的性能,该系统能够高效、精准地识别检测 '白茅根', '白芍','白头翁','百部', '百合' '半夏','北沙参', '苍术','侧柏叶', '柴胡','赤芍', '佛手'等67种常见植物中草药,满足多样化的使用需求。在接下来的内容中会详细阐述数据集介绍、技术栈、模型训练和精心打造的应用界面设计。利用该应用,用户仅需上传中草药图片,系统便能快速检测输出其类别、预测结果的置信度,同时展示该中草药的详细描述信息。
如果您仅需要完整系统(含数据集)可以通过下方演示视频的评论区获取下载方式。
项目演示视频:(项目完整文件下载请见参考视频的简介处给出:➷➷➷)
课设:基于swin
二、数据集介绍
通过网络上搜集关于不同中草药的相关图片。本系统数据集一共包含67类图片。 部分图像及标注如下图所示:


三、技术栈
PyQt5
- 界面构建:使用 PyQt5 的 QtWidgets 模块创建图形界面,包括主窗口、标签、按钮、表格等组件。通过 QSS(Qt Style Sheets)实现界面美化,如渐变背景、圆角边框、阴影效果等。
- 交互逻辑:处理用户点击事件(如选择图片、批量检测、查看历史记录),通过信号与槽机制连接 UI 组件和功能函数,实现界面与后台逻辑的交互。
- 多窗口管理:实现主窗口与历史记录窗口的切换,并在不同窗口间传递数据(如历史检测结果)。
OpenCV
- 图像读取与处理:使用
cv2.imdecode读取图像文件,支持中文路径;通过cv2.resize调整图像大小以适应显示区域;利用QtGui.QImage和QtGui.QPixmap将 OpenCV 图像转换为 PyQt 可显示的格式。 - 图像处理优化:通过计算图像宽高比自动缩放,确保图像在界面中完整显示且比例不变。
NumPy
- 数据处理:在图像解码时使用
np.fromfile处理二进制数据,支持非标准格式图像读取;在图像缩放计算中使用 NumPy 数组操作,高效处理图像数据。
CSV
- 数据存储:使用 Python 内置的
csv模块读写历史记录文件,将检测结果(图片路径、识别结果、置信度、时间)保存为 CSV 格式,便于后续查询和分析。
Datetime
- 时间处理:生成当前时间戳用于记录检测时间,通过
strftime格式化时间字符串,确保时间显示符合中文习惯。
四、模型训练
4.1 训练文件(部分)
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model(num_classes=args.num_classes).to(device)4.2 模型评估
运行train.py,训练完成之后会获得评估指标文件夹,如下图所示
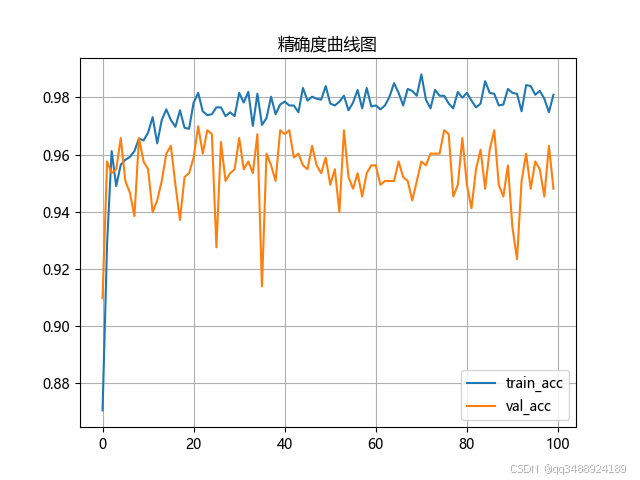
曲线含义及分析
- 蓝色曲线(train_acc):训练集上模型的精确度。起始时精确度较低,随后快速上升,在接近 0.96 后,呈现出在 0.96 - 0.98 之间波动上升的趋势。这表明随着训练的进行,模型在训练集上的表现不断提升,逐渐能够更准确地对训练数据进行预测。不过波动也说明训练过程中模型的表现并非稳定提升,存在一些训练的不稳定性 。
- 橙色曲线(val_acc):验证集上模型的精确度。起始值相对较高,在训练过程中呈现出较大的波动,整体波动范围大致在 0.92 - 0.96 之间。虽然有波动,但也能看出有一定的上升趋势。验证集精确度波动大,是因为验证集数据量相对较小,模型对验证集数据的泛化能力存在一定问题。
五、界面展示
5.1 界面设计
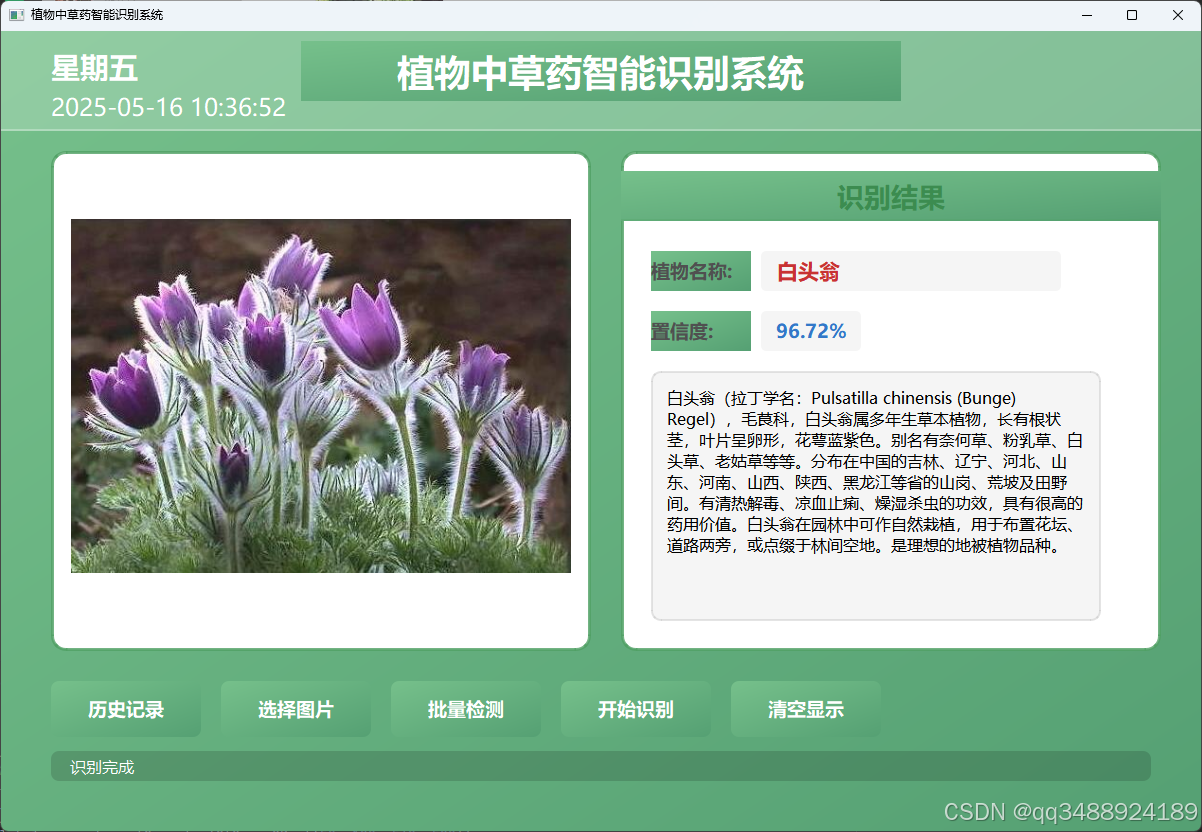
1. 操作功能区
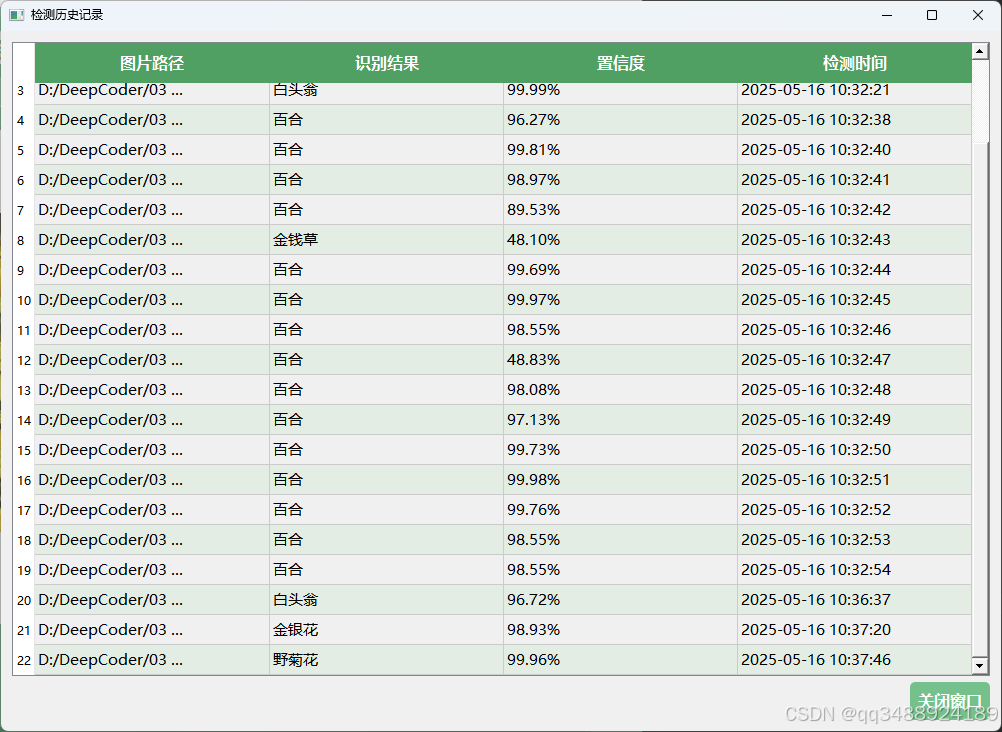
- 历史记录:点击该按钮,系统会展示过往对植物中草药的识别记录,包括每次识别的相关信息,方便用户回溯查看之前检测过的植物详情,总结识别历史情况。
- 选择图片:用户点击后可从本地设备中选取单张植物图片,系统针对这张图片进行植物中草药识别分析,适用于有单独拍摄的植物样本需鉴定的场景。
- 批量检测:用于处理多个植物图片。用户选定包含多张植物图片的文件夹,系统会依次对文件夹内所有图片进行植物中草药识别,大幅提升批量处理的效率,适用于大量样本集中检测的情况。
- 开始识别:在选择好待检测的图片(单张或批量)后,点击此按钮触发识别程序,系统调用内部算法和模型对图片中的植物进行分析判断,给出识别结果。
- 清空显示:将当前界面上显示的植物图片、识别结果等信息清除,使界面恢复到初始状态,方便进行下一次的识别操作。
2. 检测结果显示区
- 总目标数:在本次识别操作中,若只识别出一种植物(如界面中的白头翁),则显示为 1;若图片中有多株不同或相同的可识别植物,就显示实际数量。
- 用时:记录系统从开始对选定图片进行识别操作到得出完整结果所耗费的时间,反映系统处理识别任务的速度快慢,可用于评估系统性能。
- 目标选择:当识别出多个植物目标时,此区域提供下拉选项,用户可通过选择不同选项查看对应目标的详细识别信息;若仅识别出一个目标,可能默认显示该目标信息或此功能呈现非激活状态。
- 类型:明确显示识别出的植物种类,如本界面中的 “白头翁”,让用户快速知晓植物名称。
- 置信度:以百分比形式呈现(如本界面的 96.72% ),表示系统对识别结果准确性的把握程度,数值越高说明系统对判断为该植物的信心越足。
- 目标位置(xmin、ymin、xmax、ymax ):由于本界面未明确展示相关坐标数值,若存在多株植物被识别情况,这些坐标可确定每株白头翁在图片中的具体位置范围,通过坐标值可在图片上精准定位目标植物所在区域。
3. 检测结果与位置信息表格
- 序号:对每次识别结果进行顺序编号,方便用户在查看多条记录时能够快速区分和定位特定的识别任务及结果。
- 文件路径:记录用于识别的植物图片在本地存储的具体路径,便于用户后续查找原始图片资料,也有助于确认识别数据来源。
- 目标编号:针对同一张图片中识别出的多个植物目标进行编号区分,若一张图片中有多株白头翁,可通过目标编号分别查看每一株的详细识别情况。
- 类别:填写识别出的植物所属类别,如 “白头翁”,与检测结果显示区的类型信息对应。
- 置信度:同检测结果显示区的置信度,再次明确系统对识别结果的可靠程度判断,以数值形式提供结果可信度参考。
- 坐标位置:记录目标植物在图片中的坐标信息,以精确确定其在画面中的位置,对于分析植物在图片中的分布、多目标识别时区分位置关系等有重要作用。
4. 信息简介区
- 来源信息:白头翁属于毛茛科,白头翁属多年生草本植物 。多生长于中国的吉林、辽宁、河北、山东、河南、山西、陕西、黑龙江等省的山岗、荒坡及田野间 ,对生长环境有一定要求,偏好开阔且有一定光照的野外环境。
- 药用价值:白头翁具有清热解毒、凉血止痢、燥湿杀虫等功效 。在中医药应用中,常用于治疗热毒血痢、温疟发热等病症,是一种具有较高药用价值的中药材,在中医临床和中药制剂中均有应用。
5.2 功能展示