这周很忙,今天还加了一天班,但还是抽空实现了五一在安徽泾县山区喝着一壶酒写的 BBR ProbeRTT 的想法,没多少行代码,它真就消除了带宽锯齿,皮了个鞋👞,昨天我还在群里说了今天再说说 BBR 的,回到家就作图作文了。
去年夏天,我花了些精力量化 BBR 动力学,并给出一些相图以及收敛方程的数值解,但数学也只是描述而非解释,就像牛顿定律只能描述万有引力却无法解释引力的由来(任何理论都无法解释)一样。所以这个话题要不断推敲,常看常新,搞不好就有新思路了。
BBR 动力学核心是收敛,归为一句话就是 “带宽越大 Probe 加速比越小”,这句话是收敛的原因,进一步通俗解释,大的想更大更难,是为边际收益递减,小的想更大也难,但边际收益单调递减,却仍高于大的,相对而言其加速比就更大。buffer 动力学解释,即小流 Probe 的结果比大流的更大,大流就表现出净损而让给小流了。
《道德经》里早有论述,“天之道,损有余而补不足”,看来这是天道,容不得解释。而 “人之道则不然,损不足以奉有余”,则与《新约 · 马太福音》相呼应了。
我也常常提到 “矩”,它是一个乘积,与一个值不同的是,它体现了两个维度的胶合,两个维度的矩针对一个维度的值,其结果就是边际收益递减了,因为两个维度的伸缩比例并不常一致,所谓矩的效应,就比如面积相同而周长不等,或周长相同而面积各异,正如力和力臂,矩不变,但费料不同。
套用解释 buffer 动力学,BDP 就是挤出带宽的矩,BBR 靠 1.25 倍增益来体现边际收益递减,直到当它继续再减下去时,对方也要跟着减下去,这时候收敛到公平,方可停止,惊奇的是,这件事确实自然发生。
5 月 2 日晚,我在安徽宣城写了一篇 BBR ProbeRTT 新改,提出一个新思路,近日测试,是那么回事。我大致说的是,BBR 一定需要借宿于 buffer 中收敛到公平,为守其初衷,却又要 ProbeRTT,但原生 ProbeRTT 的假设太苛刻,对全局同步过度依赖,这境况在强弱不等的持续统计波动中未必能保持,何不哺其糟而歠其醨,将自己因 Probe 而建立的 queue 吐出即可。
我模仿 Jaffe’s style,用四则混合运算描述 BBR buffer 动力学,基于表达式推出一个结论,基于该结论给出上述 ProbeRTT 描述,即刻取消 BBR 由于 ProbeRTT 导致的邪恶带宽锯齿(BBR 终于摆脱了 cwnd 锯齿,却为何还要面对 bw 锯齿)。
设总带宽为 1,流 1 带宽为 x,则流 2 带宽则为 1 - x,以 ProbeBW 之 ProbeUP phase 论,流 1 和流 1 的带宽增量表示为:
f 1 ( x ) = g ⋅ x g ⋅ x + 1 − x − x x + 1 − x f_1(x)=\dfrac{\mathrm{g}\cdot x}{\mathrm{g}\cdot x+1-x}-\dfrac{x}{x+1-x} f1(x)=g⋅x+1−xg⋅x−x+1−xx
f 2 ( x ) = g ⋅ ( 1 − x ) g ⋅ ( 1 − x ) + x − ( 1 − x ) ( 1 − x ) + x f_2(x)=\dfrac{\mathrm{g}\cdot (1-x)}{\mathrm{g}\cdot (1-x)+x}-\dfrac{(1-x)}{(1-x)+x} f2(x)=g⋅(1−x)+xg⋅(1−x)−(1−x)+x(1−x)
不必化简,直接画图:
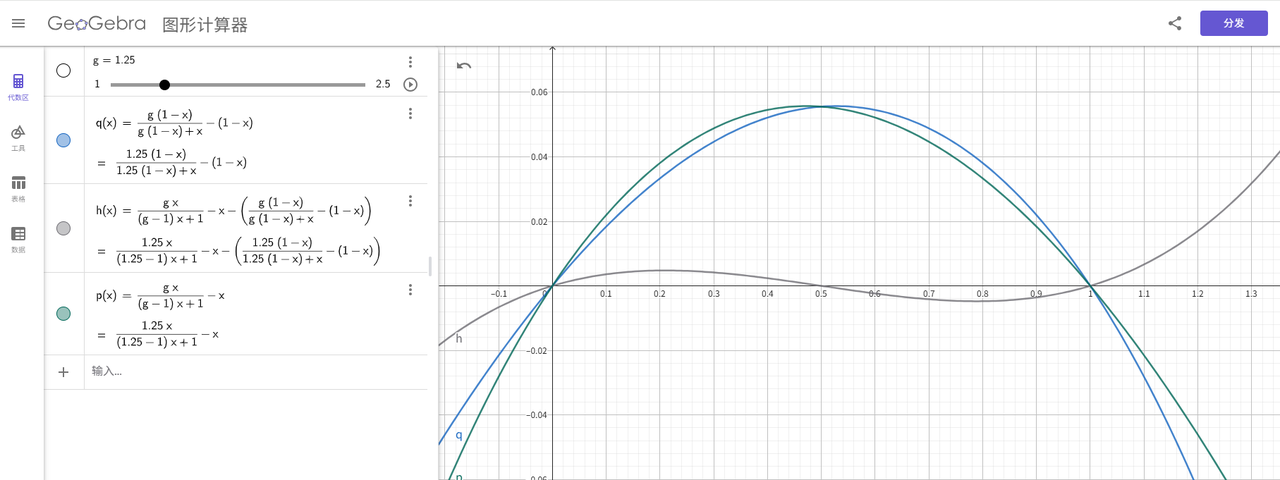
最下面灰线是 f1(x) - f2(x),可清晰看出 x = 0.5 的分水岭,当 x < 0.5,f1(x) 属小流带宽演进,f2(x) 属大流带宽演进,小流挤压大流带宽,反之亦然。
这也不难直观理解,以 AIMD 为例,当 x,y 分别为两流不同的初始 cwnd 时,设 x < y,那么 x + L y + L \dfrac{x+L}{y+L} y+Lx+L 当 L 越大,值越趋向 1 收敛到公平,即只要 additive increase 一直持续,总会收敛,BBR 同样,每次 Probe 都会堆一小丢丢 queue,大流堆的少,小流堆得更多些, x + L b i g g e r y + L s m a l l e r \dfrac{x+L_{bigger}}{y+L_{smaller}} y+Lsmallerx+Lbigger 看起来要比 AIMD 更快趋向 1,但 L 都超级小(如图所示,我还特意缩放了坐标比例),总体上还是 AIMD 应有的收敛速度。
f1(x),f2(x) 显然关于 x = 0.5 对称,它们之做差结果显示了 “损有余而补不足” 的过程,该过程强度逐渐收缓(如图绿蓝线之间的间隙),直至两者再无差异,它们与 x = 0.5 相交的此点即稳定点,它是不动点。
依照上述 5 月 2 日的 ProbeRTT 方法,释放自己堆积的 queue,在上图的意义就是分别求绿线 x 到 0.5 以及蓝线 0.5 到 1 - x 的积分,肉眼观测,面积是相等的,大差不差一个相位。
现在演示一下实际上是不是这样:
import numpy as np
import matplotlib.pyplot as plt
import random
x0 = 0.2
y0 = 0.8
g = 1.25
bx, by = 0, 0
R = 2
C = 1
num_steps = 500
t = np.arange(num_steps)
# 带宽
x = np.zeros(num_steps)
y = np.zeros(num_steps)
# BDP
Bx = np.zeros(num_steps)
By = np.zeros(num_steps)
# RTwait
r = np.zeros(num_steps)
# 自己堆占的 queue
Ax = np.zeros(num_steps)
Ay = np.zeros(num_steps)
# 自己堆栈 queue 的平均
sAx = np.zeros(num_steps)
sAy = np.zeros(num_steps)
x[0] = x0
y[0] = y0
r[0] = 0
Bx[0], By[0] = x0, y0
Ax[0], Ay[0], sAx[0], sAy[0] = 0, 0, 0, 0
nx, ny = random.randint(5, 15), random.randint(5, 15)
for i in range(1, num_steps):
if i > 150:
C = 5
if i > 350:
C = 0.2
dec = 0
x[i] = C * (g * x[i-1]) / (g * x[i-1] + y[i-1])
tx = C * x[i-1] / (x[i-1] + y[i-1])
bx += R * (x[i] - tx)
if i % nx == 0: # x 随意 ProbeRTT,不再依赖同步
dec += bx
bx = 0 # 退掉自己 Probe 造成的 queue,堆多少退多少
nx = random.randint(5, 15)
Ax[i] = bx
sAx[i] = 0.9 * sAx[i-1] + 0.1 * bx
#y[i-1] = C - x[i] # 忘记 max-filter bw
y[i] = C * (g * y[i-1]) / (g * y[i-1] + x[i])
ty = C * y[i-1]/(y[i-1] + x[i])
by += R * (y[i] - ty)
if i % ny == 0: # y 随意 ProbeRTT,不再依赖同步
dec += by
by = 0 # 退掉自己 Probe 造成的 queue,堆多少退多少
ny = random.randint(5, 15)
Ay[i] = by
sAy[i] = 0.9 * sAy[i-1] + 0.1 * by
#x[i] = C - y[i] # 忘记 max-filter bw
r[i] = (((x[i] + y[i]) * R) + bx + by- dec) / C - R
if r[i] < 0:
r[i] = 0
Bx[i] = r[i] * x[i]
By[i] = r[i] * y[i]
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(8, 6))
ax1.plot(t, r, label='rtt(t)', color='green')
ax1.plot(t, x, label='bw_x(t)', linestyle=':', color='blue')
ax1.plot(t, y, label='bw_y(t)', linestyle=':', color='red')
ax2.plot(t, Bx, label='bdp_x(t)', linestyle=':')
ax2.plot(t, By, label='bdp_y(t)', linestyle=':')
ax3.plot(t, Ax, label='buf_x(t)', linestyle=':')
ax3.plot(t, Ay, label='buf_y(t)', linestyle=':')
ax3.plot(t, sAx, label='avg_buf_x(t)', linestyle='-')
ax3.plot(t, sAy, label='avg_buf_y(t)', linestyle='-')
ax1.set_xlabel('t')
ax1.set_ylabel('v')
ax2.set_xlabel('t')
ax2.set_ylabel('BDP')
ax2.set_xlabel('t')
ax2.set_ylabel('total buffer')
ax1.legend()
ax1.grid(True)
ax2.legend()
ax2.grid(True)
ax3.legend()
ax3.grid(True)
plt.show()
给出几个结局:
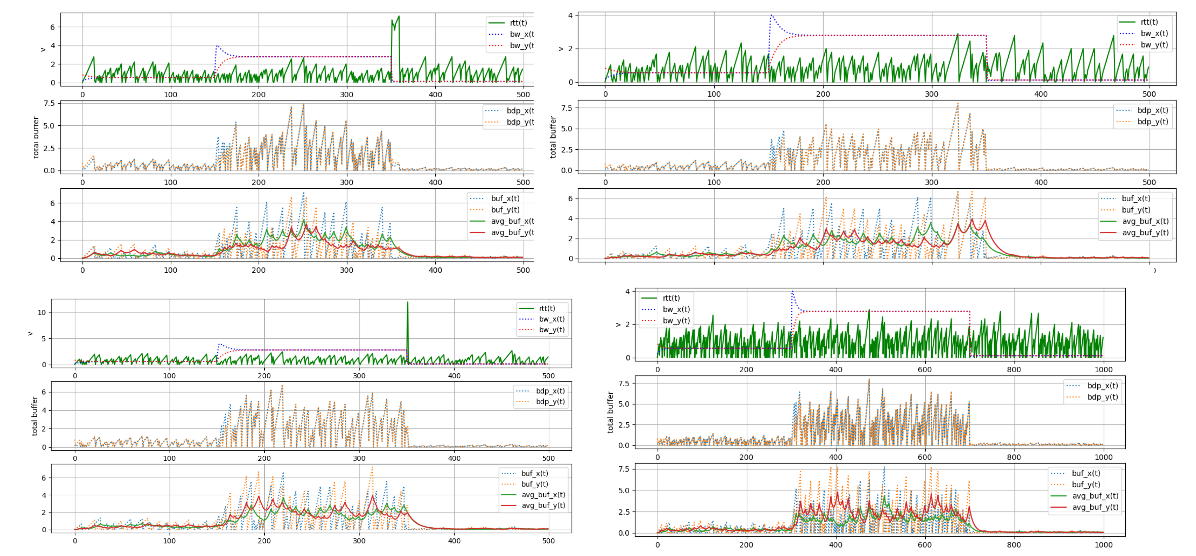
观测到的现象是:
- total buffer 写错了,应该去掉,因为已经有了图例;
- RTT 总体在一个很小范围内波动,视 ProbeRTT 平均期望窗口而定,窗口越大,RTT 振幅越大;
- bw,BDP,自己堆积 queue 总体都属于统计公平状态;
- BDP 随总带宽 C 而涨跌,但整体非常公平;
这才像个真实的样子,没有任何假设和约束,但却收敛到了公平。
但这里有个 BBR 细节,“为什么要在一个 max-filter bw 窗口内至少进入 Probe phase 一次”,比如 10-round 的 max-filter bw 窗口,要设计 8-round 的 ProbeBW cycle。如果将上述 python 代码的两行 “忘记 max-filter bw” 注释放开,结局如下:
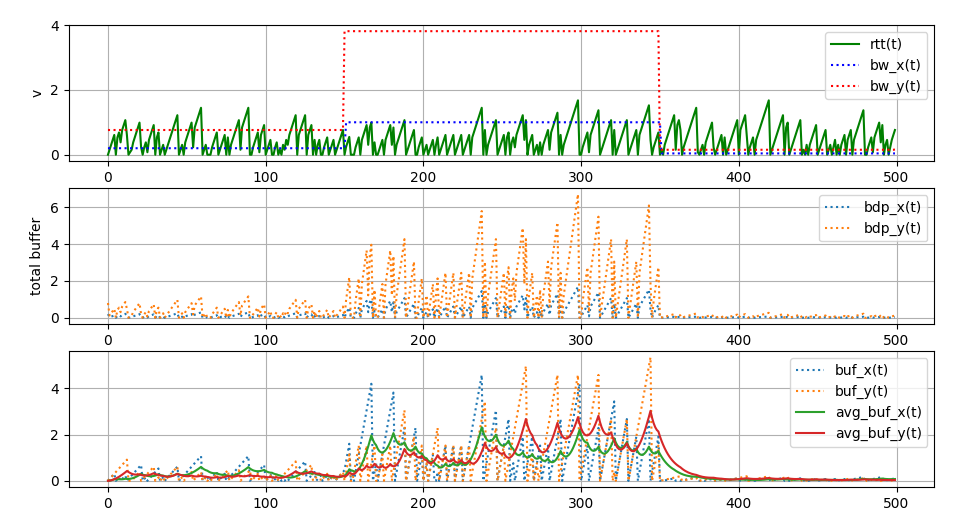
这个结果写出递推式就能看明白,完全不必分析不动点和相图。
最后,给出完全由 buffer 动力学驱动而不是照着 “算法” 临摹的实际效果。还是先给出仿真代码:
for i in range(1, num_steps):
if i > 150:
C = 5
if i > 350:
C = 0.2
dec = 0
# 根据 buffer 占比求带宽
x[i] = C * (g * x[i-1] * R) / (g * x[i-1] * R + y[i-1] * (r[i-1] + R))
# 如果不 probe 的带宽
tx = C * x[i-1] * (r[i-1] + R) / (x[i-1] * (r[i-1] + R) + y[i-1] * (r[i-1] + R))
bx += R * (x[i] - tx)
# 随机而生的 ProbeRTT,不依赖同步
if i % nx == 0:
dec += bx
bx = 0
nx = random.randint(5, 15)
# 即时 buffer
Ax[i] = bx
# 即时 buffer 移动指数平均
sAx[i] = 0.9 * sAx[i-1] + 0.1 * bx
# 同 x,略
y[i] = C * (g * y[i-1] * R) / (g * y[i-1] * R + x[i] * (r[i-1] + R))
ty = C * y[i-1] * (r[i-1] + R)/(y[i-1] * (r[i-1] + R) + x[i] * (r[i-1] + R))
by += R * (y[i] - ty)
if i % ny == 0:
dec += by
by = 0
ny = random.randint(5, 15)
Ay[i] = by
sAy[i] = 0.9 * sAy[i-1] + 0.1 * by
# RTwait = total_bdp / C - RTprop
r[i] = (((x[i] + y[i]) * R) + bx + by- dec) / C - R
if r[i] < 0:
r[i] = 0
Bx[i] = r[i] * x[i]
By[i] = r[i] * y[i]
以下几个例子的实际采样结局:
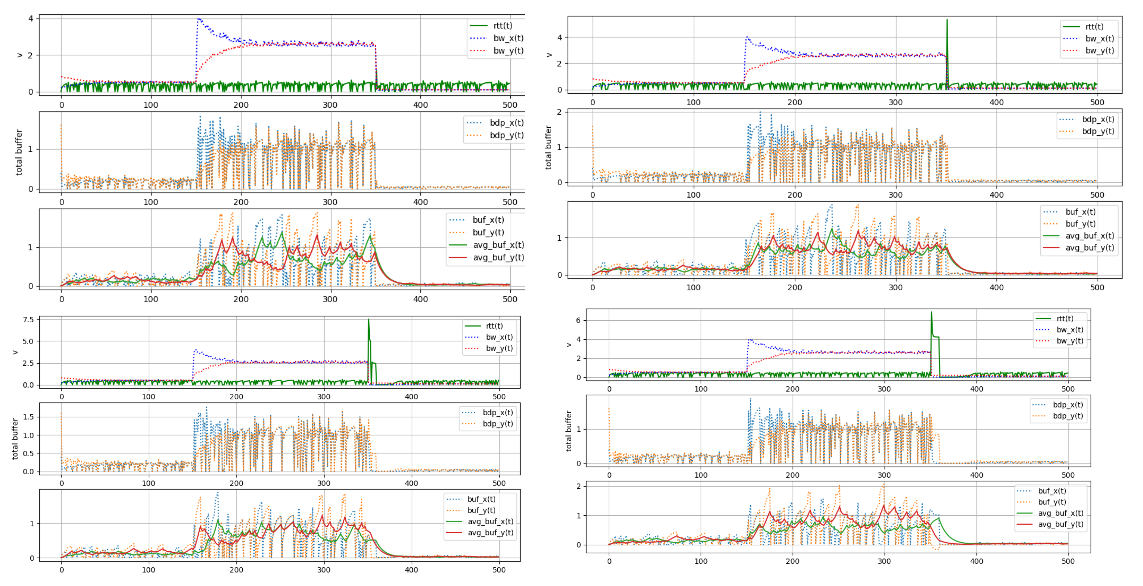
真正的统计律主导,不以精确而以统计应对时局,可以看出 queue 以一个非常有限的振幅波动,没有完全消除,但也不过度增加,且 ProbeRTT 也不再需同步,任意时刻执行均可(在一个最大窗口比如 5~10s 的约束内),它完全通过 buffer 动力学驱动。整体而言,这达到了一个松散的统计公平。
浙江温州皮鞋湿,下雨进水不会胖。