必须执行以下操作序列以通过 Windows 图形堆栈传递命令缓冲区:
- 当 Direct3D 运行时调用以下任一 UMD 函数以执行指定操作时,用户模式显示驱动程序(UMD)将启动命令缓冲区提交。(用于显示图形的 Present 函数)。(用于提交硬件命令的 Flush 函数。)用于锁定资源(在当前命令批处理中使用的 Lock 函数)。
- 只要命令缓冲区已满,UMD 也会启动命令缓冲区提交。
- UMD 调用 Direct3D 运行时的 pfnRenderCb 函数,将命令缓冲区提交到运行时。
- DirectX 图形内核子系统 (Dxgkrnl) 调用内核模式显示微型端口驱动程序 (KMD) DxgkDdiRender 或 DxgkDdiRenderKm 函数来验证命令缓冲区,以硬件格式编写 DMA 缓冲区,并生成描述所用图面的分配列表。 请注意,DMA 缓冲区尚未修补(即分配的物理地址)。 注意如果运行时通过调用 UMD 的 Present 函数启动命令缓冲区提交,图形子系统将调用 KMD 的 DxgkDdiPresent 函数,而不是 DxgkDdiRender 或 DxgkDdiRenderKm。
- 视频内存管理器调用 KMD 的 DxgkDdiBuildPagingBuffer 函数,以创建特殊用途的 DMA 缓冲区(称为分页缓冲区),该缓冲区将 DMA 缓冲区随附的分配移入和移出 GPU 可访问的内存。 有关详细信息,请参阅 分页视频内存资源。
- GPU 计划程序调用 KMD 的 DxgkDdiPatch 函数,将物理地址分配给 DMA 缓冲区中的资源。 但是,计划程序不需要调用 DxgkDdiPatch 将物理地址分配给分页缓冲区,因为分页缓冲区的物理地址是在 DxgkDdiBuildPagingBuffer 调用期间传入和分配的。
- GPU 计划程序调用 KMD 的 DxgkDdiSubmitCommand 函数,请求驱动程序将分页缓冲区排队到 GPU 执行单元。
- GPU 计划程序调用 KMD 的 DxgkDdiSubmitCommand 函数,请求驱动程序将 DMA 缓冲区排队到 GPU 执行单元。 提交到 GPU 的每个 DMA 缓冲区都包含围栏标识符。 GPU 处理完 DMA 缓冲区后,GPU 将生成中断。
- KMD 在其 DxgkDdiInterruptRoutine 函数中收到中断的通知。 KMD 应从 GPU 中读取刚刚完成的 DMA 缓冲区的栅栏标识符。
- KMD 应调用 DxgkCbNotifyInterrupt 函数,以通知 GPU 计划程序 DMA 缓冲区已完成。
- KMD 应调用 DxgkCbQueueDpc 函数来排队延迟过程调用(DPC)。
- KMD 的 DPC 被通知来负责大部分 DMA 缓冲区的处理。
1. 命令提交全流程概览
sequenceDiagram
participant App as 应用程序
participant UMD as 用户模式驱动
participant Runtime as Direct3D运行时
participant Dxgkrnl as 图形内核
participant VidMm as 视频内存管理器
participant KMD as 内核模式驱动
participant GPU as GPU硬件
App->>UMD: 1. Present/Flush/Lock调用
UMD->>Runtime: 2. pfnRenderCb提交命令
Runtime->>Dxgkrnl: 3. 进入内核模式
Dxgkrnl->>KMD: 4. DxgkDdiRender验证命令
KMD->>VidMm: 5. 请求资源驻留
VidMm->>KMD: 6. DxgkDdiBuildPagingBuffer
KMD->>GPU: 7. 提交分页缓冲区
Dxgkrnl->>KMD: 8. DxgkDdiPatch物理地址
Dxgkrnl->>KMD: 9. DxgkDdiSubmitCommand
GPU->>KMD: 10. 中断通知完成
KMD->>Dxgkrnl: 11. DxgkCbNotifyInterrupt2. 关键阶段深度解析
(1) 用户模式触发点(UMD)
触发命令提交的四种情况:
// 情况1:Present触发
HRESULT UmdPresent() {
if (HasPendingCommands()) {
pfnRenderCb(&cmdBuffer); // 隐式Flush
}
return pfnPresentCb();
}
// 情况2:显式Flush
void UmdFlush() {
pfnRenderCb(&cmdBuffer);
}
// 情况3:Lock同步
void* UmdLockResource() {
if (IsCmdBufferReferencing(resource)) {
pfnRenderCb(&cmdBuffer); // 确保命令已提交
}
return pfnLockCb(resource);
}
// 情况4:命令缓冲区满
void UmdEmitCommand() {
if (cmdBuffer.remaining() < CMD_SIZE) {
pfnRenderCb(&cmdBuffer);
cmdBuffer.reset();
}
// 添加新命令...
}(2) 内核验证与DMA生成(KMD)
DxgkDdiRender 的典型实现:
NTSTATUS DxgkDdiRender(
HANDLE hContext,
DXGKARG_RENDER* pRenderArgs)
{
// 1. 命令验证
if (!ValidateCommandBuffer(pRenderArgs->pCommand)) {
return STATUS_GRAPHICS_INVALID_COMMAND_BUFFER;
}
// 2. 转换为DMA格式
DMA_BUFFER* pDmaBuffer = pRenderArgs->pDmaBuffer;
ConvertToDmaFormat(pRenderArgs->pCommand, pDmaBuffer);
// 3. 生成资源列表
pRenderArgs->AllocationList = BuildAllocationList(pDmaBuffer);
pRenderArgs->AllocationListSize = GetListSize();
return STATUS_SUCCESS;
}(3) 分页与地址修补
分页缓冲区构建与地址修补的协作:
// VidMm 触发分页
void VidMmEnsureResidency(DMA_BUFFER* pDmaBuffer) {
foreach (Allocation* alloc in pDmaBuffer->Allocations) {
if (!alloc->IsResident) {
DXGKARG_BUILDPAGINGBUFFER args = {0};
args.Operation = DXGK_OPERATION_TRANSFER;
args.Source.SysMem = alloc->SysMemBacking;
args.Destination.DevMem = alloc->DevMemAddr;
KMD->DxgkDdiBuildPagingBuffer(&args);
}
}
}
// KMD 实现地址修补
NTSTATUS DxgkDdiPatch(
const DXGKARG_PATCH* pPatchArgs)
{
foreach (DXGK_PATCHLOCATION loc in pPatchArgs->PatchLocationList) {
PHYSICAL_ADDRESS pa = VidMmGetPhysAddr(loc.Allocation);
WriteGpuAddress(pPatchArgs->pDmaBuffer + loc.Offset, pa);
}
}(4) GPU 提交与完成处理
中断处理流程示例:
// 中断服务例程 (ISR)
BOOLEAN DxgkDdiInterruptRoutine(UINT MessageNumber) {
UINT64 fenceId = ReadGpuFenceRegister();
DxgkCbNotifyInterrupt(fenceId); // 通知图形内核
DxgkCbQueueDpc(); // 触发DPC
return TRUE;
}
// DPC处理
void DpcRoutine() {
UINT64 completedFence = GetCompletedFence();
VidMmReleaseResources(completedFence); // 释放相关资源
SignalUserModeEvents(); // 通知UMD完成
}3. 关键数据结构
(1) DMA缓冲区头部格式(示例)
struct DmaBufferHeader {
UINT64 fenceId; // 围栏标识符
UINT32 commandSize; // 命令数据大小
UINT32 patchLocCount; // 修补位置数量
// 硬件特定字段...
};(2) 修补位置描述符
struct DXGK_PATCHLOCATION {
UINT Offset; // DMA缓冲区内的偏移
HANDLE hAllocation; // 资源句柄
UINT PatchType; // 地址类型(如32/64位)
};4. 性能关键设计
(1) 批处理优化
- 命令聚合:UMD应累积多个DrawCall后一次性提交
- 资源预声明:通过AllocationList提前告知VidMm所需资源
(2) 零拷贝分页
现代GPU架构支持
// UMA架构下的优化路径
if (IsUmaDevice()) {
args.Operation = DXGK_OPERATION_FILL; // 直接引用系统内存
args.FillPattern = 0; // 表示无数据传输
}(3) 异步提交管道
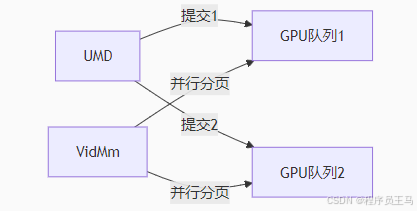
5. 错误处理规范
| 错误类型 | 处理方式 |
|---|---|
| 命令验证失败 | 返回STATUS_GRAPHICS_INVALID_COMMAND |
| 分页缓冲区溢出 | 触发VIDEO_TDR_FAILURE (蓝屏) |
| GPU超时无响应 | 调用DxgkCbResetEngine 重置GPU引擎 |
| 资源泄露 | VidMm在DPC阶段强制释放 |
6. 开发者检查清单
6.1UMD必须:
- 在Present/Flush/Lock时正确刷新命令
- 确保命令不超过pfnRenderCb返回的缓冲区大小
6.2KMD必须:
- 严格验证所有GPU命令
- 实现完整的修补/分页逻辑
- 正确处理GPU中断和DPC
6.3共同要求:
- 维护围栏标识符的严格顺序
- 处理资源生命周期跨CPU/GPU域
该流程体现了WDDM如何平衡安全隔离(用户/内核模式分离)、资源虚拟化和硬件加速,是现代Windows图形栈的核心支柱。