目录
一、技术融合的时代背景
在人工智能技术高速发展的当下,AI 大模型凭借其强大的学习能力和泛化能力,已成为推动各领域变革的核心力量。深度学习作为 AI 大模型的技术基石,通过构建多层神经网络实现复杂模式识别;分布式计算解决了大模型训练所需的海量算力问题;自动化技术则大幅提升了模型开发、部署及应用的效率。三者深度融合,正在重塑整个 AI 生态。
| 技术维度 | 关键作用 | 融合价值 |
|---|---|---|
| 深度学习 | 实现特征提取与模式识别 | 提供模型核心能力 |
| 分布式计算 | 突破单机算力瓶颈,支持大规模训练 | 保障模型训练的资源需求 |
| 自动化技术 | 贯穿模型全生命周期,提升开发与部署效率 | 降低人力成本,加速技术落地 |
二、深度学习在 AI 大模型中的核心作用
2.1 预训练与微调机制
AI 大模型普遍采用 “预训练 + 微调” 的范式。以 GPT-3、ChatGPT 为代表的大语言模型,在预训练阶段通过 Transformer 架构,在海量文本数据上学习通用语言知识。
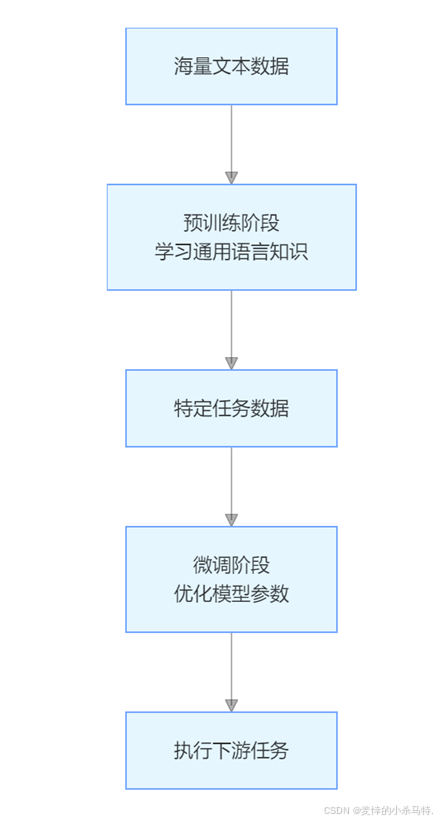
微调阶段针对具体任务,在少量标注数据上优化模型参数。以下是基于 Hugging Face Transformers 库实现文本分类微调的代码示例:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 准备微调数据
texts = ["This is a positive review", "This is a negative review"]
labels = [1, 0]
encoding = tokenizer(texts, truncation=True, padding=True, return_tensors="pt")
input_ids = encoding["input_ids"]
attention_mask = encoding["attention_mask"]
labels = torch.tensor(labels)
# 微调过程
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
2.2 多模态深度学习的突破
传统深度学习局限于单一模态数据处理,而 AI 大模型推动了多模态融合的发展。
| 多模态模型 | 核心能力 | 典型应用场景 |
|---|---|---|
| CLIP | 图像与文本跨模态对齐 | 图文检索、图像生成标题 |
| DALL・E 系列 | 文本生成图像 | 创意设计、广告制作 |
| 多模态对话模型 | 处理文本、图像、语音等多种输入 | 智能客服、虚拟助手 |
多模态模型框架代码:
import torch
import torchvision.models as models
import torch.nn as nn
class ImageTextModel(nn.Module):
def __init__(self):
super(ImageTextModel, self).__init__()
self.image_encoder = models.resnet50(pretrained=True)
self.text_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=512, nhead=8),
num_layers=6
)
self.fusion_layer = nn.Linear(512 + 512, 128)
self.classifier = nn.Linear(128, 10)
def forward(self, images, texts):
image_features = self.image_encoder(images).flatten(1)
text_embeddings = nn.Embedding(len(vocab), 512)(texts)
text_features = self.text_encoder(text_embeddings)
text_features = text_features.mean(dim=1)
fused_features = self.fusion_layer(torch.cat([image_features, text_features], dim=1))
return self.classifier(fused_features)
三、分布式计算:大模型训练的基础设施
3.1 分布式训练核心原理
大模型训练需要处理海量数据和庞大的参数,单机计算无法满足需求,分布式训练通过将计算任务分配到多个节点并行处理,显著提升效率。其核心包括数据并行、模型并行和流水并行三种策略:
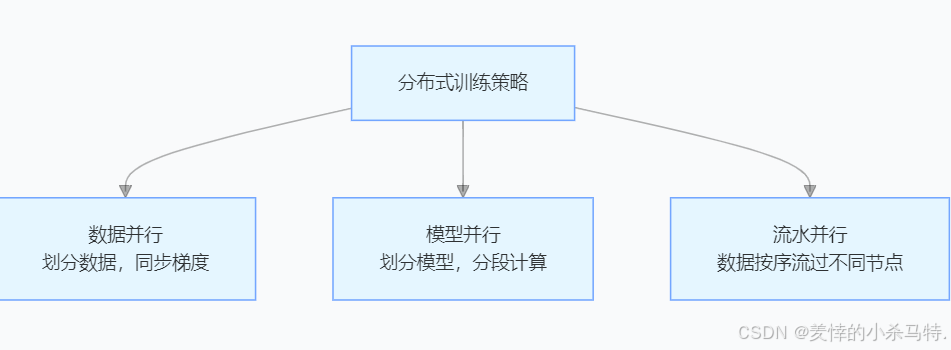
3.2 数据并行实战(PyTorch DDP)
PyTorch 的 DistributedDataParallel(DDP)是实现数据并行的常用工具。以下是使用 DDP 训练 ResNet-18 模型进行图像分类的完整代码:
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import resnet18
from torch.nn.parallel import DistributedDataParallel as DDP
# 初始化分布式环境
dist.init_process_group(backend='nccl')
local_rank = dist.get_rank()
torch.cuda.set_device(local_rank)
# 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32,
sampler=train_sampler)
# 定义模型、损失函数和优化器
model = resnet18(num_classes=10).to(local_rank)
ddp_model = DDP(model, device_ids=[local_rank])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001, momentum=0.9)
# 训练过程
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(local_rank), data[1].to(local_rank)
optimizer.zero_grad()
outputs = ddp_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Rank {local_rank}, Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')
# 关闭分布式环境
dist.destroy_process_group()
3.3 模型并行与混合并行
对于参数规模超大的模型,模型并行可解决单卡内存不足的问题。混合并行结合数据并行和模型并行,在微软的 DeepSpeed 框架中得到广泛应用。
| 分布式策略 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|
| 数据并行 | 模型规模适中,数据量庞大 | 实现简单,扩展性强 | 通信开销随节点增加 |
| 模型并行 | 模型超大,单卡内存不足 | 降低单卡内存压力 | 协调复杂,效率易受影响 |
| 混合并行 | 超大规模模型 | 综合两者优势 | 部署难度高 |
四、自动化技术:提升大模型全生命周期效率
4.1 自动化代码生成
AI 大模型具备代码生成能力,GitHub Copilot、AWS CodeWhisperer 等工具可根据自然语言描述生成代码。
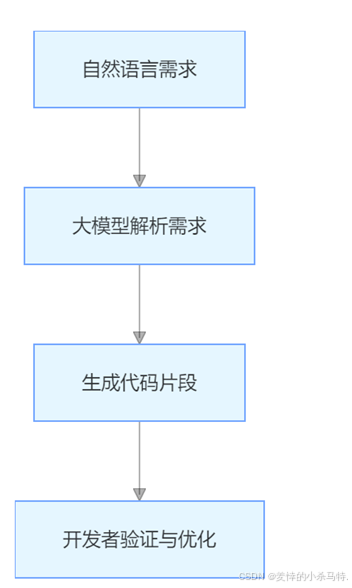
例如,输入 “写一个 Python 函数,计算列表中所有偶数的和”,Copilot 可生成以下代码:
def sum_even_numbers(lst):
return sum(x for x in lst if x % 2 == 0)
4.2 自动化模型开发流程
自动化技术贯穿模型开发的全流程,包括数据预处理、超参数调优、模型评估等。例如,使用 Optuna 库进行超参数自动化调优:
import optuna
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义模型
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3)
self.fc = nn.Linear(16 * 30 * 30, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = x.view(-1, 16 * 30 * 30)
x = self.fc(x)
return x
# 数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=32)
# 目标函数
def objective(trial):
model = SimpleNet()
optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'SGD'])
lr = trial.suggest_loguniform('lr', 1e-5, 1e-1)
optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0], data[1]
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(trainloader)
# 调优过程
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=10)
print('Best trial:')
best_trial = study.best_trial
print(' Value:', best_trial.value)
print(' Params:')
for key, value in best_trial.params.items():
print(' {}: {}'.format(key, value))
4.3 自动化部署与监控
在模型部署阶段,Kubernetes 结合自动化脚本可实现模型的弹性伸缩和高可用部署。Prometheus 和 Grafana 用于自动化监控模型的性能指标。
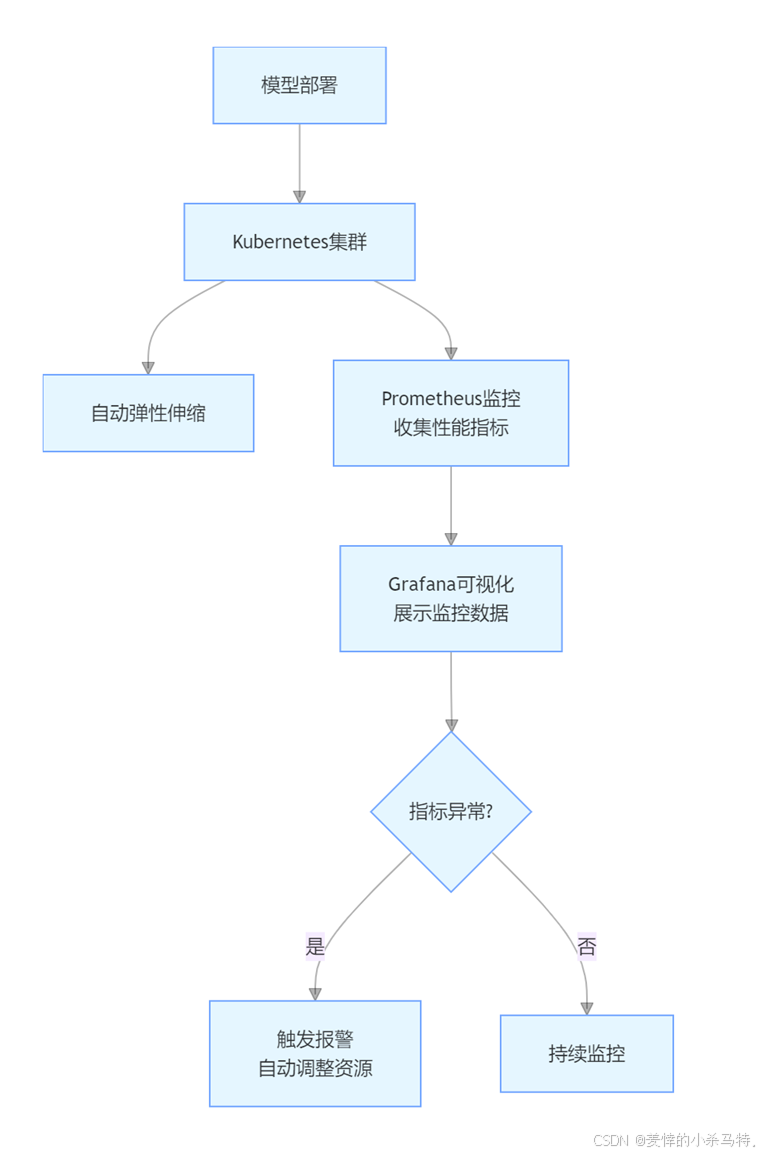
五、行业应用案例
5.1 医疗领域:疾病诊断与药物研发
| 案例名称 | 技术方案 | 应用效果 |
|---|---|---|
| IBM Watson for Oncology | 分布式整合医疗数据,深度学习模型分析 | 提供个性化癌症治疗方案建议 |
| DeepMind 的 AlphaFold | 分布式训练预测蛋白质结构 | 加速药物研发进程 |
5.2 金融领域:风险防控与智能投顾
| 案例名称 | 技术方案 | 应用效果 |
|---|---|---|
| 蚂蚁集团 OceanBase 数据库 | 分布式计算 + AI 大模型分析交易数据 | 实时风险预警,处理海量交易 |
| 高盛 Marquee 平台 | 自动化 + 深度学习模型提供投资建议 | 智能投资决策,风险管理 |
5.3 工业领域:智能制造与质量检测
| 案例名称 | 技术方案 | 应用效果 |
|---|---|---|
| 西门子 MindSphere 平台 | 部署 AI 大模型实现设备预测性维护 | 减少设备停机时间 |
| 富士康 AI 质检系统 | 多模态深度学习模型检测产品缺陷 | 检测准确率超 99% |
六、技术融合面临的挑战
| 挑战类型 | 具体问题 | 现有解决方案 |
|---|---|---|
| 数据安全 | 分布式数据易泄露,联邦学习存在模型逆向攻击风险 | 同态加密、差分隐私 |
| 模型可解释性 | 大模型参数复杂,决策过程难以解释 | LIME、SHAP 等解释性工具 |
| 资源调度 | 分布式训练资源需求高,调度不当影响效率,能耗问题突出 | 动态资源分配、绿色 AI 技术 |
七、未来发展趋势
通用人工智能(AGI)探索:AI 大模型向更通用化方向发展,尝试解决复杂的多领域任务。
边缘计算与大模型结合:在边缘设备上部署轻量化大模型,实现实时智能决策,降低对云端的依赖。
绿色 AI 技术:研究更高效的算法和硬件架构,降低大模型训练和运行的能耗。
八、收尾
AI 大模型驱动下的深度学习、分布式与自动化融合,正深刻改变着各行业的发展模式。尽管面临诸多挑战,但随着技术的不断创新和突破,三者的深度融合将推动人工智能迈向更高阶段,为人类社会创造更大价值。