Map
HashMap
Hashable
LinkedHashMap
TreeMap
Properties
HashMap的原理
- 数组存储的是桶的引用。
- 链表存储的是键值对(key-value pair)。
JDK1.7版本之前,HashMap的底层数据结构是数组+链表,HashMap通过哈希算法会将元素的key映射待数组的的槽位(Bucket)。如果多个键映射到同一个槽位,就会以链表的形式存储在同一个槽位上。但是链表的查询的复杂度O(n),所有冲突比较严重,当链表的长度很长时,效率就很低了;

所以在JDK1.8之后,一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。

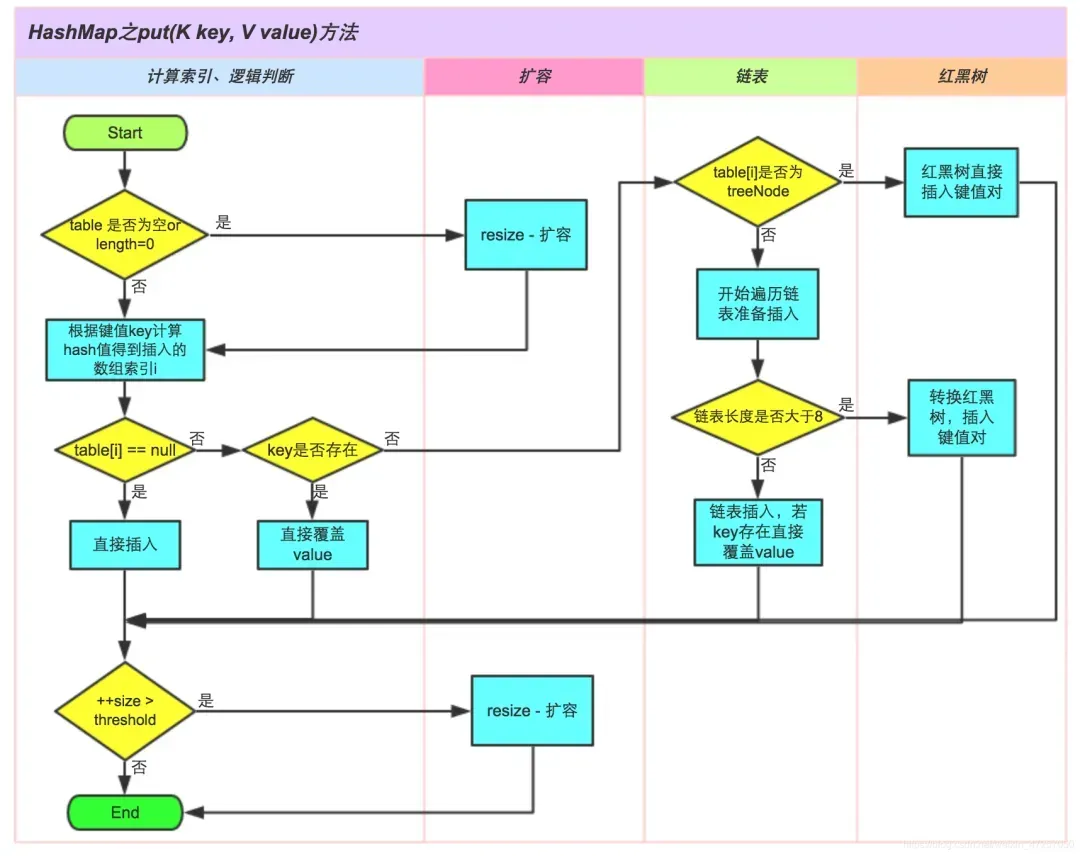
HashMap的put原理
第一步:根据要添加的键(key)的哈希码计算出在数组的位置(索引)。
第二步:检查该位置是否为空(没有键值对的存在)
2.1如果在该位置为空,直接在该位置创建一个新的Entry对象来存储键值对。将要添加的键值对作为该Entry的键
和值,并保存在数组的对应位置。
2.2如果在位置已经存在,就会检查该位置的第一个键值对的哈希码和要添加的键的哈希值对比判断是否相同
第三步:
3.1如果第一个键值对的哈希码和要添加的键的哈希值相同,就会直接将新的值替换旧的值(更新操作)
3.2如果第一个键值对的哈希码和要添加的键的哈希值不一样,就需要遍历链表或者红黑树来查找是否有相同的键;
第四步:
4.1如果找到了相同的键,使用新的值替换旧的值(更新操作)
4.2如果没有找到,就将新的键值对添加到链表/红黑树上
第五步:添加完后,检查链表长度是否达到阈值(默认为8)
5.1如果链表长度超过阈值,而且HashMap的数组长度>=64,链表就会转换红黑树(提高查询效率)
第六步:检查负载因子是否超过阈值(默认0.75)
6.1如果键值对的数量/数组的长度 > 阈值,就需要扩容。
第七步:扩容操作
7.1创建一个两倍大小的数组
7.2讲旧数组的键值对重新计算哈希值并分配到新数组中的位置
7.3更新HashMap的数组引用和阈值参数
第八步:退出
HashMap的key可以为空吗(可以的但是要唯一)
可以为空
HashMap的循环链表问题
【大厂面试必问的HashMap扩容死循环问题源码分析问题,20分钟讲清楚!】 大厂面试必问的HashMap扩容死循环问题源码分析问题,20分钟讲清楚!_哔哩哔哩_bilibili
在 JDK1.7 的 HashMap 中,底层使用数组 + 链表实现。当 HashMap 的容量达到一定阈值时会触发 resize() 扩容操作。
在多线程并发下,多个线程可能同时触发 resize()。因为 1.7 中的 resize() 方法没有加锁,导致链表在重新插入时可能出现链表重排顺序错乱,从而形成循环链表。
举个例子,如果两个线程同时对同一个桶进行 rehash 操作,并且都修改了 next 指针的指向,就可能出现 a→b→c→a 的闭环。
后果是当我们遍历这条链表时(比如 get()),会进入死循环,程序 CPU 占用率飙高甚至 OOM。
在 JDK1.8 之后,这个问题被规避了:
- JDK1.8 在底层结构上将链表在长度超过一定阈值后转为红黑树;
- 并且在并发环境下推荐使用
ConcurrentHashMap替代 HashMap。
HashMap的扩容机制
HashMap的负载因子是0.75,如果HashMap中的元素个数超过了总容量的75%,就会触发扩容。
1.将哈希表的长度扩容2倍
2.将旧哈希表的元素的数据放到新的哈希表中
在 JDK1.8 中,rehash 做了优化:
- 不再重新计算 hash,而是根据
(原索引 & oldCap)判断元素是 留在原位置 还是 移动到新位置 = 原位置 + oldCap - 因为容量是 2 的幂,这个操作非常高效(只涉及位运算)
标准回答:
HashMap 的扩容机制是在元素个数超过容量×负载因子时触发,默认阈值是 16×0.75=12。当触发扩容时,HashMap 会创建一个新的数组,其大小是原来的 2 倍,并将原数组中的元素重新映射到新数组中,这个过程叫 rehash。
在 JDK1.8 中,rehash 不会重新计算 hash 值,而是根据原 hash 与旧容量做位运算来决定是否移动位置。为了提高性能和避免 hash 冲突,JDK1.8 还在链表长度大于 8 且容量大于 64 时将链表转为红黑树。
与 JDK1.7 相比,JDK1.8 采用尾插法进行扩容,避免了多线程下链表反转成环的问题,提高了线程安全性。在实际开发中,如果涉及并发操作,建议使用 ConcurrentHashMap 代替 HashMap。
CourcurrentHashMap的原理
CourcurrentHashMap是一种线程安全的高效Map集合
JDK1.7版本之前底层采用的分段的数组+链表实现
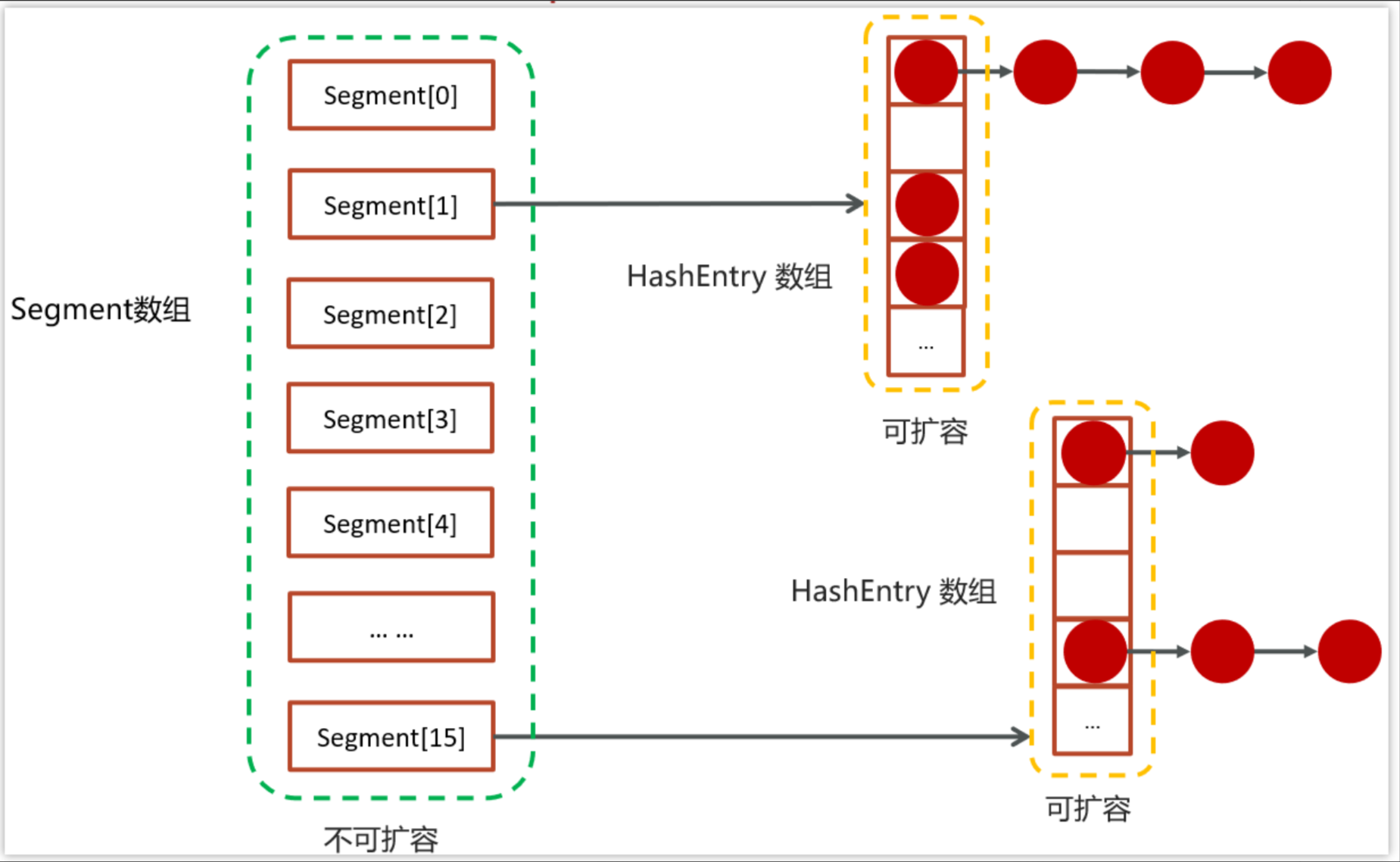
而数组又分为:大数组 Segment 和小数组 HashEntry,Segment 是一种可重入锁(ReentrantLock)在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素。
JDK1.8采用的数据结构跟HashMap的结构也相同,数组+链表/红黑二叉树
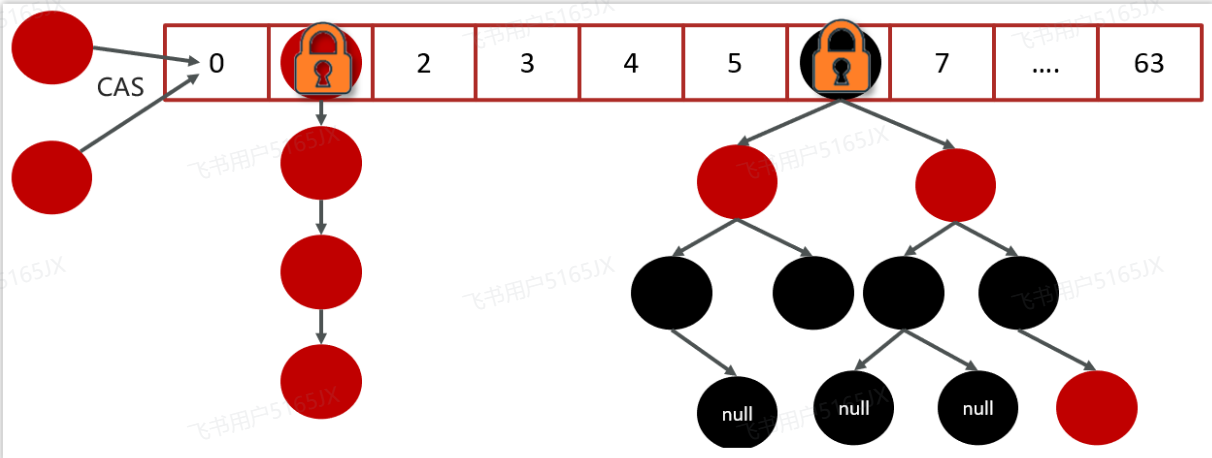
JDK 1.8 ConcurrentHashMap 主要通过 volatile + CAS 或者 synchronized 来
实现的线程安全的。添加元素时首先会判断容器是否为空:
- 如果为空则使用 volatile 加 CAS 来初始化
- 如果容器不为空,则根据存储的元素计算该位置是否为空。
- 如果根据存储的元素计算结果为空,则利用CAS 设置该节点;
- 如果根据存储的元素计算结果不为空,则使用 synchronized,然后,遍历桶中的数据,并替换或新增
- 节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
如果把上面的执行用一句话归纳的话,就相当于是ConcurrentHashMap通过对头结点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。而且JDK1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn)的时间复杂度。、
CourcurrentHashMap的原理
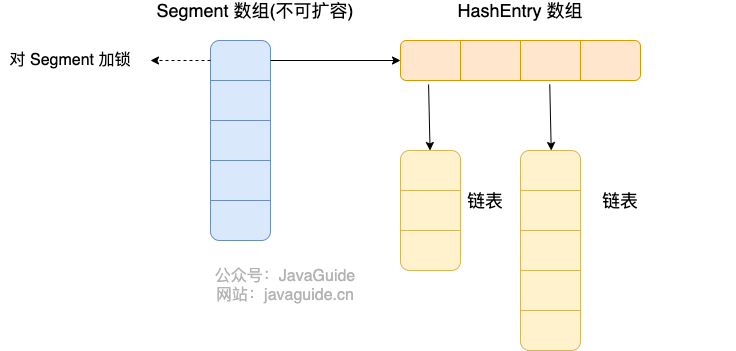
在java1.7之前,ConcurrentHashMap的底层是数组+链表,数组分为Segment和HashEntry。
Segment继承ReentranLock,是一个可重入锁。
HashEntry是用来存储键值对的。
一个ConcurrentHashMap里面包含一个Segment数组,默认大小为16,Segment数组一旦初始化就不要能改变。ConcurrentHashMap结构类似与HashMap,是一种数组+链表,一个Segment包含一个HashEntry,HashEntry里面是一个链表结构的元素,每一个Segment守护这一个HashEntry数组。修改HashEntry数组的元素必须要先获得对应的锁
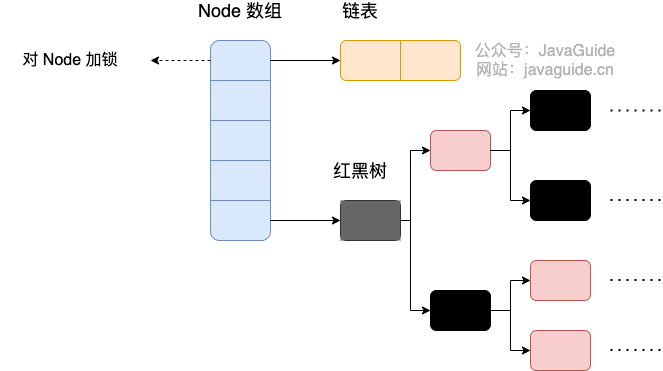
1.8之后,ConcurrentHashMap取消了Segment分段锁,采用了Node+CAS+Synchronized保证并发安全。
实现的线程安全的。添加元素时首先会判断容器是否为空:
- 如果为空则使用 volatile 加 CAS 来初始化
- 如果容器不为空,则根据存储的元素计算该位置是否为空。
- 如果根据存储的元素计算结果为空,则利用CAS 设置该节点;
- 如果根据存储的元素计算结果不为空,则使用 synchronized,然后,遍历桶中的数据,并替换或新增
- 节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
如果把上面的执行用一句话归纳的话,就相当于是ConcurrentHashMap通过对头结点加锁来保证线程安全
的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。
而且JDK1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很
大的提升,从之前的 O(n) 优化到了 O(logn)的时间复杂度。
ConcurrentHashMap用了Synchronized为什么还要CAS呢?
synchronized的锁粒度比较大对性能损耗大,cas使用的无锁机制性能较好。在某些操作中使用synchronized还是使用cas,主要是根据锁竞争的程度来判断。
比如:在putVal中,如果计算出来的hash槽没有存放元素,那么就可以直接使用CAS来进行设置值,这是
因为在设置元素的时候,因为hash值经过了各种扰动后,造成hash碰撞的几率较低,那么我们可以预测使
用较少的自旋来完成具体的hash落槽操作。
当发生了hash碰撞的时候说明容量不够用了或者已经有大量线程访问了,因此这时候使用synchronized来
处理hash碰撞比CAS效率要高,因为发生了hash碰撞大概率来说是线程竞争比较强烈。