scale up 作为一种系统扩展优化的方法,旨在提高系统组件的执行效率,比如替换更高性能的硬件或算法。是否可以此为依据优化 TCP 呢,例如通过多条路径聚合带宽实现吞吐优化(对,还是那个 MPTCP),答案是否定的。
因为 TCP 是 scale out 协议,绝大多数情况下,你无法在不触碰另一个瓶颈的前提下,通过更多资源换得等价的性能。
没有任何 scale up 是线性的,都会受边际效用和沟通成本影响而趋平,但为便于理解,我将 scale up 系统的单流性能 y 随资源 x 变化写作 y = a · x,而在 scale out 系统则为 y’ = b,其中 a,b 为常量。举个例子,网卡作为 x 升级后突破了原始瓶颈,y 变大,b 产生新值,此时增加多块同样的网卡,无论怎么做也不会将更多的网卡利用起来让单个 y’ 从新 b 继续提升,那么产生该单流的协议就是一个 scale out 协议。
要理解传输性能优化,首先得区分带宽和吞吐,忽略丢包,重传,延时抖动等因素,它们到底在衡量什么。
如下图形象,带宽是一个静态空间中的概念,衡量管道截面积,如果多根管道组成传输路径(即多路径传输),就是它们截面积之和,而吞吐是一个动态时间序中的概念,衡量单位时间首尾流入管道的数据量和流出管道的数据量之差。
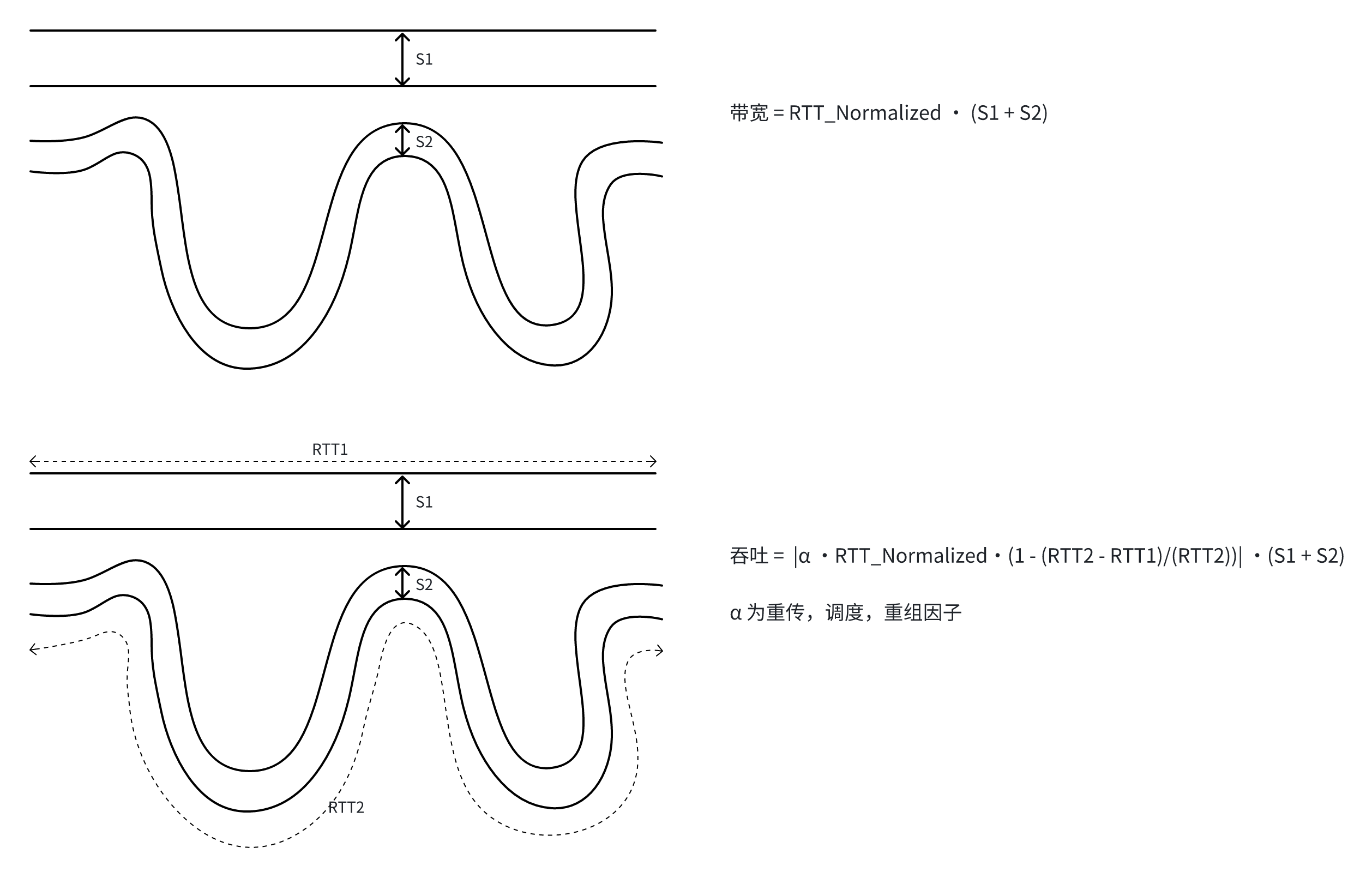
简单解释一下吞吐的描述。虽然管道可以提供 RTT_Normalized · (S1 + S2) 的带宽,但如果某时刻从左边注入这么多数据,RTT_Normalized 过后,仅流出 RTT_Normalized · |RTT2 - RTT1|/RTT2 · (S1 + S2) 数据,若要流出更多的数据,则必须在更大 RTT2 路径上更早注入数据,如果没有足够的数据提前注入,就要在右侧等待重组,该力度由 α 调节,表现为多路径调度和重组算法,由这些算法决定(前面写过,但不是本文重点),对于可靠传输,左边不等右边等,怎么优化都没用。
上述式子表明,路径 RTT 越异构,越聚合越差,类似健康人拖着一个瘸子走。
从要解决的问题而不是概念入手,带宽优化是一个 scale out 扩展问题,只要你多聚合一个管道,里面跑数据,截面积肯定能增加,而吞吐优化则是 scale up 扩展问题,需要依赖并联合重传,调度,乱序重排序等算法单元。这个理解可让你一下子就能区分诸多传输协议的聚合处理,哪些是好的,哪些是坏的。
在低速场景,TCP 各项指标都不孬,它的边际收益随资源的增值曲线上凸远没到值得警惕的地步,很难看出 TCP 更善于填充带宽还是优化吞吐,但 TCP 是典型 scale out 协议,特别当它被喂到 10Gbps+ 后,单流吞吐就显得力不从心,边际收益曲线几乎水平甚至向下减损,只能靠注入多流横向填充带宽。
早在 2010 年代初,随着带宽持续提高和低延时需求激增,依靠统计均值回归的 TCP 带宽利用率问题就开始突出,TCP 不得不靠填充更多 buffer 的代价来填充更多带宽,BBR 正是在 2016 年底放出缓解这一问题,然而更严峻的挑战在数据中心,在数据中心网络 scale up 扩展中,高性能网络中的 TCP 传输过程,总有某些资源利用率不足,只能 scale out 去填充,紧接着就会遭遇另一些资源过载,于是继续 scale up,再 scale out,针对 TCP scale out 的资源密度内卷问题,各类适应 scale up 扩展的协议纷纷亮相,SRD,Homa,Falcon,TTPoE,对于应对资源密度问题,这些都是正确的。
从文初的定义看,只要可以通过将数据乱序 spray 到更多网卡,就可以压缩单卡串行时间,从而提高 y’。
但有两条几乎同时但完全走错的路,DPDK 用户态 TCP 协议栈和 MPTCP。这两条错误本质上都是在用 scale up 思想扩展 scale out 协议,相当于给鱼带游泳圈。
TCP 的串行本质注定了它的处理逻辑中总在同步,总在等待。TCP 无法享用可并行分发的 scale up 设施,这是它作为 scale out 协议的根源,作为相对一面,数据中心的很多其它协议往往对并行资源的利用率更高,同时将串行流抽象解耦到另一些可 scale up 的设施中来保证,依靠重排序解决,从而跳出了资源密度的内卷。我并非说 Homa 是最好的替代,但它的宣讲中对 TCP 的总结最为全面:It’s Time to Replace TCP in the Datacenter。
网络传输时间尺度即使在数据中心都比主机时间尺度大至少一个数量级(10us vs. 800ns),在用户态协议栈中,CPU 将大量时间浪费在 TCP 主机时间同步对齐网络时间,为了比内核 TCP 更快,这个能耗代价着实大。主机侧对 TCP 单流效率无法通过更多的资源 scale up,传输侧的 MPTCP 又进一步加深了时间尺度的鸿沟。
MPTCP 池化了带宽,但却没有改变 TCP 的流式抽象,正如用户态 TCP 协议栈内存不等 CPU 等一样,MPTCP 是带宽不等内存等,串行过程是个漏桶模型,由最慢的一环决定,谁快谁等。比如说 MPTCP socket 接口,先忽略路径拥塞和滑动窗口,假设它们都不受限,在一个单线程中 spray 一条串行流一个窗口的数据,根据 Little 定律,系统总容量没有任何改变。多 Subflow 间的任何抖动,都会把时延单调叠加到内存中的重排序等待,RTT 越异构越发散,而我上周的文章证明,MPTCP 多路径间的抖动发散而不收敛,在统计意义上,相比标准 TCP,MPTCP 的低时延体验趋向劣化:
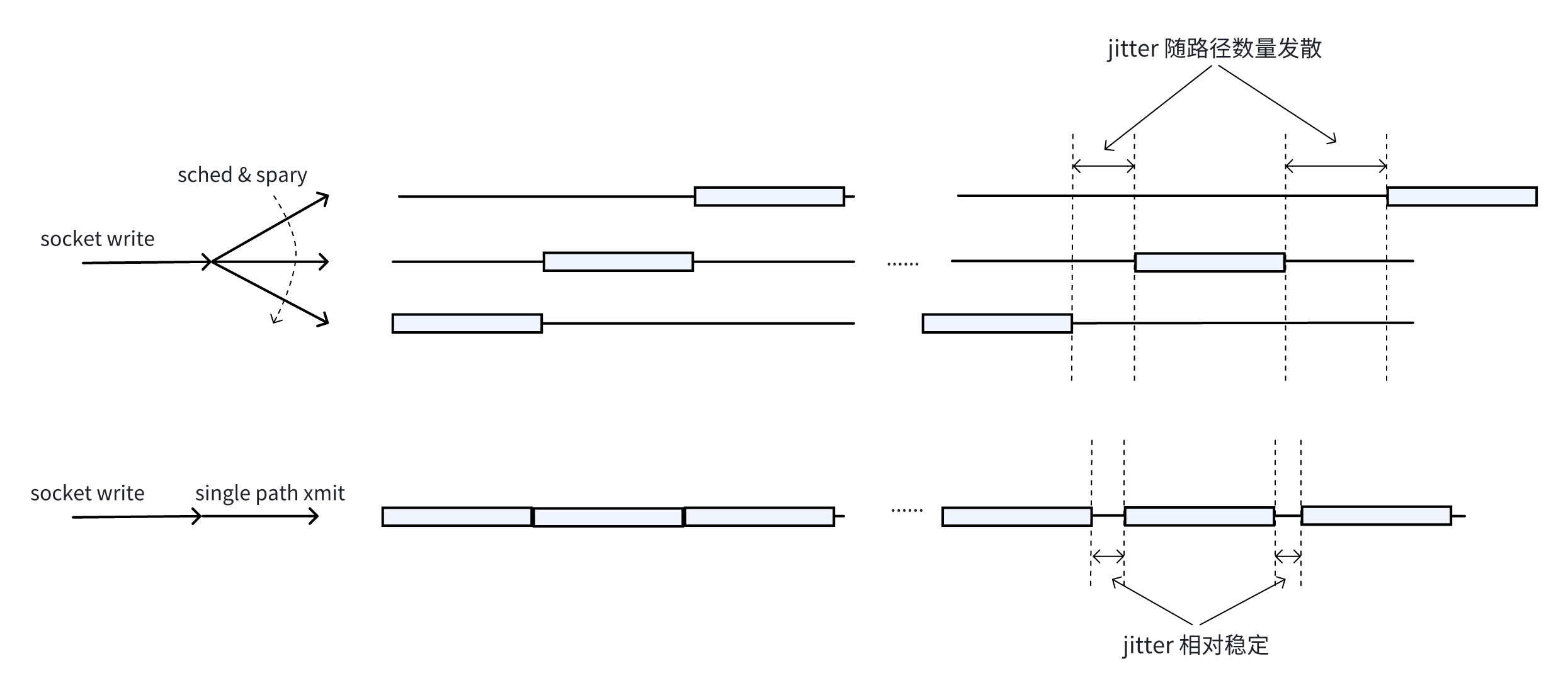
若考虑路径拥塞和滑动窗口,是单路径拥塞控制更简单还是并行化调度一条串行流叠加多路径耦合拥塞控制更简单,搞定了拥塞控制,你又如何保证拥有足够的,多个窗口的数据供 MPTCP 调度。
多路径显然在 MPTCP 这里用错了,因为 MPTCP 本意想叠加吞吐,这是个 scale up 扩展,TCP 无能为力。
作为串行流的 MPTCP,时间序约束着序列号,而序列号又让时延单调发散,解除二者的关联才是多路径传输的正确姿势,那些数据中心多路径传输协议,几乎都可在多路径随意乱序分发消息,而乱序意味着不可靠,因为没有任何端到端机制能区分乱序和丢包,丢包对重传的依赖也解除了,若要支持可靠传输,协议必须单独处理,比如通过 NACK,Request 而不是类似 TCP 带内积累确认。
多路径传输将带宽资源池化,这是典型的 scale up 思想,类似为主机升级更多核的 CPU,但更多核的 CPU 也无法优化一个单线程程序,除非将它重写成可并发执行的多线程代码,但有些逻辑本就发生在时间序本身,无法 scale up,比如处理一个 TCP 流。若作者理解了这个,就不会出现用户态 TCP 协议栈和 MPTCP 这些东西。
另一方面,也就理解了 TCP 协议处理的两面,要么强大的 CPU(和网卡) 造成网络拥塞,要么强大的网络造成 CPU 过载,却无法刚刚好,也无法优化某个单独的方面。因为 TCP 协议处理时间序本身,而时间序无法横向跨越资源,就会遭遇资源密度问题,在资源不足的 stage 过载,在资源充足的 stage 造成低利用率,这就是 TCP 无法适应高性能网络的根源。
再说到单流 TCP 处理本身,涉及到另一个系统如何组织调度任务的问题,是 run-to-complete 还是 pipeline,在此视角,我会继续分析 MPTCP,导出与其它视角相同的结论,即 MPTCP 不行。
处理一个串行流,直观理解肯定是 run-to-complete 最快,但事情没这么简单。 浅引我几年前的两篇文章:加密一条保序流,大吞吐的不二法门。
但还是转贴文中两个图,左边是 scale up 扩展,右边是 scale out 扩展:
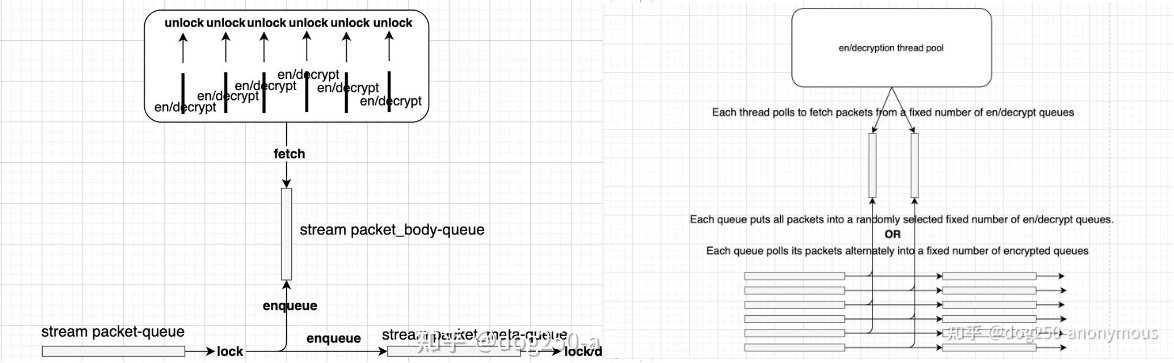
一个并行加密逻辑切断了 run-to-complete 过程,插入了 lock-wait-unlock 的重排序逻辑。
这里的原则是,当串行操作的时间尺度大于重排序时间尺度时,并行化它就值得。加密一条串行流,设加密过程耗时为常量 T1,流长为 n,加密核大于 n,串行加密时间复杂度为 O(n),而如图所示并行加密重排序时间取决于最久的加密时间,时间复杂度为 O(1),何乐而不为。
现在以此原则再审视 MPTCP,设多路径时延为相同常量 T2,流长为 n,路径数量为 m,串行单路径传输时间复杂度为 O(n),对于 MPTCP 而言,传输阶段时间复杂度为 O(n/m),合并阶段为 O(n log m),总体上 O(n/m + n log m) ≈ O(n log m) > O(n)。
这意味着,要么抛弃 MPTCP,要么只分 2 条 Subflow,m 越大越差。相比较而言,标准 TCP 则是准排序的,面对偶尔的,罕见的乱序,也只是执行一个 O(log n) 的插入操作,即 O(log n) < O(n log m)[m = 2] < O(n log n)。
必须要注意的是上述时间复杂度推导存在的偏见,时间复杂度只表示时间随规模增长的趋势曲线形状,它绝不表示程序执行的绝对时间,在加密一条串行流的推导中,我视加密一个单位数据时间为常量 T1,在传输一个串行流时对应的时间常量是 T2,T1 我取了最长时间作为 O(1) 中 1 的常量根据,T2 我却忽略了。
试想在一个 RTT 为 T2 = 500ms 的路径传输,窗口大小为 w,一窗数据传输时间 500ms,m 路并行传输 m 个窗口的时间上界为 (500 + log (n/w))ms,小于串行传输所需的 (n/w) · 500ms,几乎可以肯定,节省下来的时间 ((n/w) · 500 - 500 + log (n/w))ms 小于主机排序时间 β · (n/w) · log m,其中 β 为主机时间尺度。因此,当路径 RTT 足够大时,MPTCP 分担多个窗口的数据传输依然有收益,这里的问题在于是否有足够的 “多个窗口的数据”,还是回到了老问题,大部分情况下你只有一个窗口的数据,难点在于如何在多路径 spray 一个窗口的数据仍有收益,这还是调度策略的问题,这才是难点,分析过了,不再赘述。
那些支持乱序传输的可靠协议为什么没有这个时间复杂度的问题?理论上它们重排序的成本并不会比 MPTCP 更少,答案在于上面段落里一句话,它们将 “串行流抽象解耦到另一些可 scale up 的设施中来保证”,它们可能没有滑动窗口,它们可能直接传递包含位置和空洞信息的接收 buffer 状态位图,而这些均可以通过 scale up 优化甚至并行化,它们不像 TCP,从 socket 到 socket,始终就是那一条串行流,MPTCP 重排序步骤真的就是在做一道单线程归并排序面试题。
这可如何解释各级别会议论文,公众号展示的各大卷厂的 MPTCP 卷果,如何解释各类吊打内核 TCP,吞吐提升 好几十% 的诳语:
- 他们的仿真环境是他们的仿真环境;
- 测试环境 RTT 异构性弱,真实环境更不可控;
- m 不大,O 常量主导,软硬件加速机制与内核 TCP 相比占优;
- 相比内核 TCP 代价高昂,无论 CPU 成本还是卷客们的工资成本;
有以下真实环境进行测试比对多流标准 TCP 对带宽,吞吐的 scale out 和 MPTCP 对带宽,吞吐的 scale up。
客户端为普通 PC,服务器为云主机,有 3 条路径连通,其中 1 条 5G,20Mbps,30ms,一条有线宽带,50Mbps,20ms,1 条 4G,约 5Mbps,35ms:
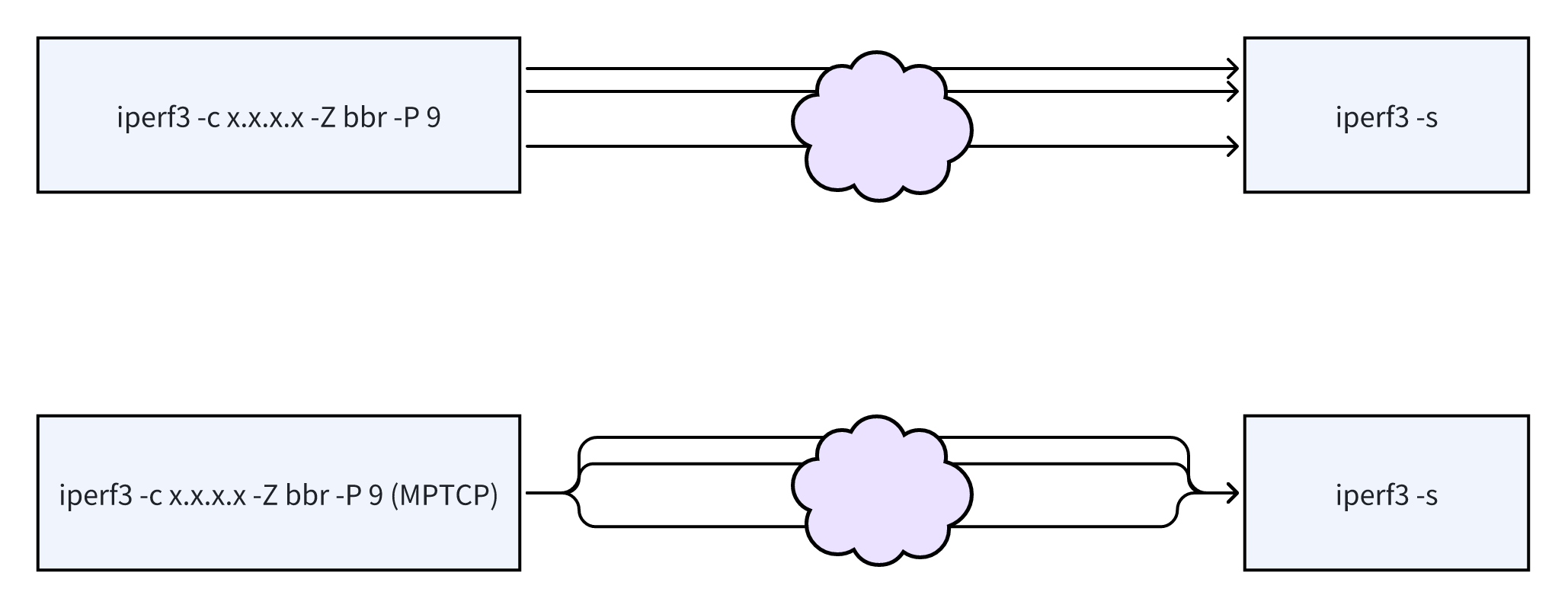
只说多流标准 TCP 如何做。
先吐个陈年老槽。详见 Linux策略路由和iptables OUTPUT链的一个细节,简单说一下。
要想在 5G,4G,宽带路径之间负载均衡 TCP 流,需要配置策略路由(ip-rule),同时需要为分配到该路径上的 TCP 数据包选择对应该路径网卡的 IPv4 地址,可是 Linux 内核不支持为一个路由项多次修改源 IP:
- 即使将 dummy 网卡地址清掉,并设置 default 指向 dummy,系统依然会为数据包选择一个不适配的 saddr;
- 必须配置 nat MASQUERADE 重新指定 saddr;
其根源在于,iptables OUTPUT 在路由之后,而路由子系统并不知道 iptables mangle rule 会在路由之后 mark 数据包,所以它必须为数据包指定好 saddr,问题在于,当 Linux 内核发现数据包的 daddr,fwmark 等信息发生改变后,其 nf_reroute 逻辑不支持 saddr 的重新选择,这一点至今(v6.15)依然未改变。
给出配置:
# iptables 配置
*nat
-A POSTROUTING -j MASQUERADE
*mangle
-A OUTPUT -j CONNMARK --restore-mark
-A OUTPUT -m mark ! --mark 0x0 -j ACCEPT
-A OUTPUT -p tcp --dport 5201 -m statistic --mode random --probability 0.5 -j MARK --set-xmark 100
-A OUTPUT -m mark ! --mark 0 -j CONNMARK --save-mark
-A OUTPUT -m mark ! --mark 0 -j ACCEPT
-A OUTPUT -p tcp --dport 5201 -m statistic --mode random --probability 0.25 -j MARK --set-xmark 200
-A OUTPUT -m mark ! --mark 0 -j CONNMARK --save-mark
-A OUTPUT -m mark ! --mark 0 -j ACCEPT
-A OUTPUT -p tcp --dport 5201 -m statistic --mode random --probability 0.25 -j MARK --set-xmark 300
-A OUTPUT -m mark ! --mark 0 -j CONNMARK --save-mark
-A OUTPUT -m mark ! --mark 0 -j ACCEPT
-A OUTPUT -p tcp --dport 5201 -j MARK --set-xmark 100
-A OUTPUT -j CONNMARK --save-mark
-A OUTPUT -j ACCEPT
# ip-rule 配置
32763: from all fwmark 300 lookup lb42
32764: from all fwmark 200 lookup lb41
32765: from all fwmark 100 lookup lb50
# policy-routing 配置(每张表分别指向默认网关,略)
总吞吐稳稳当当 70Mbps+,至于哪个线程被扔进低带宽,高延时路径,纯属运气不好,但在统计意义上,好坏运气机会均等。同样聚合 3 条路径的带宽,MPTCP 可聚合吞吐吗?
结论是,多流标准 TCP 填满了带宽,聚合了总吞吐,但未对单独的流承诺吞吐,MPTCP 既没有填满带宽,更奢谈承诺吞吐,实话实说,总吞吐只有 25~40Mbps,很容易理解这个结果,路径太异构了。
浙江温州皮鞋湿,下雨进水不会胖。