25年5月来自清华大学、上海姚期智研究院和星动纪元(RoboEra)公司的论文“Learning Generalizable Robot Policy with Human Demonstration Video as a Prompt”。
最近的机器人学习方法通常依赖于从通过遥操作收集的大量机器人数据集中进行模仿学习。当面对新任务时,此类方法通常需要收集一组新的遥操作数据并微调策略。此外,遥操作数据收集流程也很繁琐且昂贵。相反,人类只需观察他人操作即可高效地学习新任务。本文介绍一种两阶段框架,如图所示。
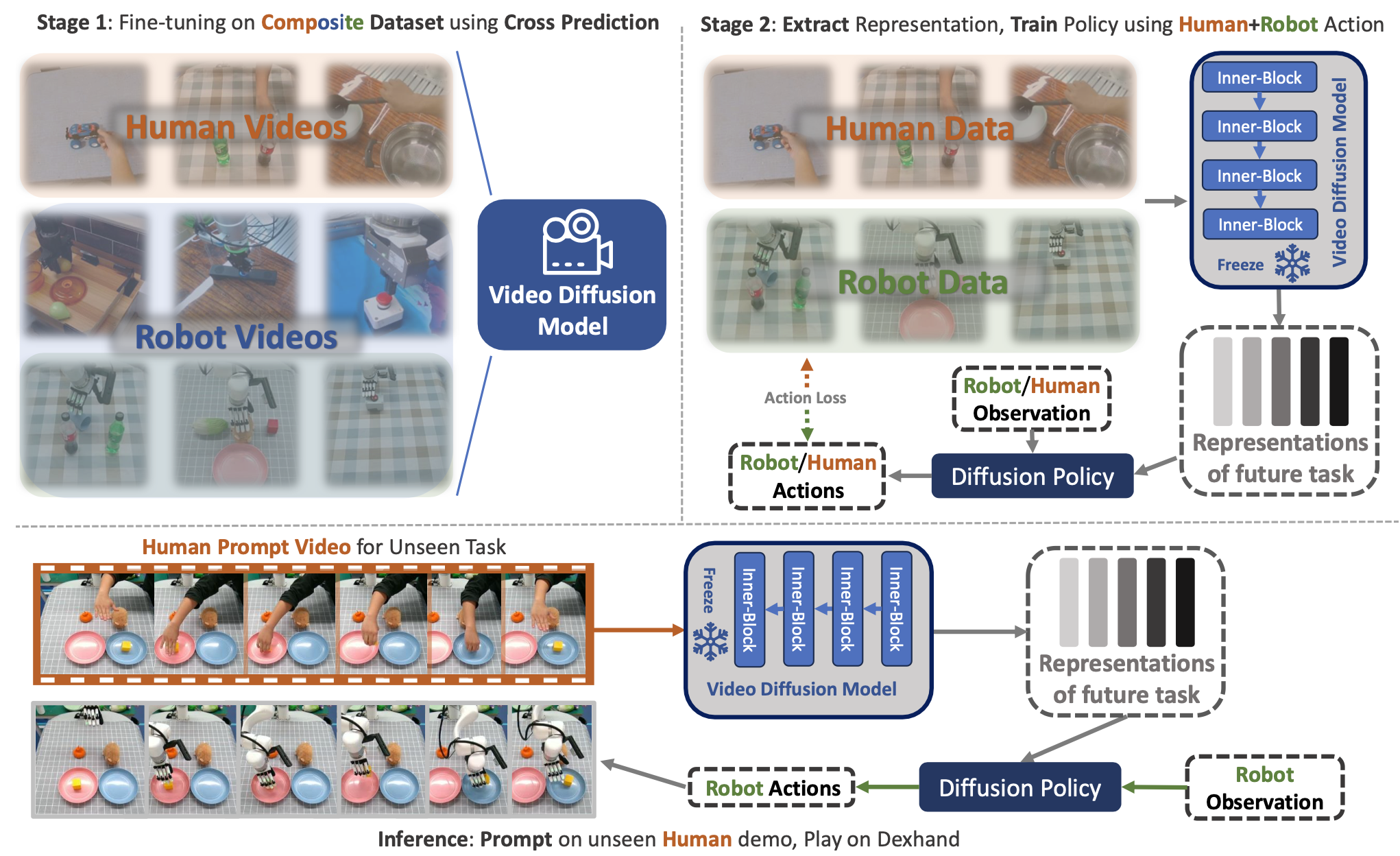
该框架利用人类演示来学习可泛化的机器人策略。这种策略可以直接以人类演示视频为提示,执行新任务,而无需任何新的遥操作数据和模型微调。在第一阶段,训练视频生成模型,该模型使用交叉预测来捕获人类和机器人演示视频数据的联合表示。在第二阶段,使用原型对比损失(prototypical contrastive loss) 将学习的表示与人机共享的动作空间融合。在现实世界灵巧操作任务上的实证评估,证明了该方法的有效性和泛化能力。
传统的机器人学习方法通常基于通过遥操作收集的大型数据集来训练基于语言的策略[1, 2]。虽然这种范式对于已知任务有效,但在处理新任务时面临两个根本限制。首先,语言指令虽然对人类来说直观易懂,但仅提供分类信息,缺乏对物理操作至关重要的丰富空间和时间细节。其次,适应新任务通常需要收集额外的机器人演示,由于遥操作系统的复杂性,这一过程既耗时又昂贵。
相比之下,人类只需观察他人执行任务即可高效地掌握新技能。这一观察结果表明,视觉演示可能为机器人教学提供一种更自然、信息更丰富的媒介。视频不仅可以捕捉要执行的任务,还可以捕捉如何执行任务,包括目标关系、运动轨迹和时间安排等关键方面。此外,与机器人数据相比,无论是在实验室环境中捕获还是从现有的在线资源中获取,人类演示视频的获取都更具可扩展性。
目前的方法才刚刚开始探索这个方向。虽然像 EgoMimic[3] 这样的研究已经融入人类演示,但它专注于单任务场景。该领域仍然缺乏一个能够充分利用人类视频潜力进行机器人学习的通用框架。
从人类视频中学习
机器人操控领域的最新进展越来越多地利用人类视频数据来增强灵巧操控和基于抓取器的操作。在灵巧操控方面,[4、5、6] 等研究侧重于多指系统的细粒度控制,而 [7] 则融合 affordance 提示。对于抓取器操控,[8、9、10、11] 等端到端视频调节策略将视觉提示转化为可操作的策略。[12]、[13、14]、[15]、[16]、[3] 和 [17] 等方法使用配对的人机演示数据,通过将人类动作与机器人轨迹关联起来,解决了域差距问题。最近,[18]、[19]、[20] 和 [21] 等生成视频技术利用视频合成和文本提示来生成视觉运动策略。这些研究突显使用人类视频演示、配对数据和生成方法来创建更具适应性、更鲁棒机器人操作策略的日益增长趋势。
视频作为机器人学习的提示
最近的研究[22, 23]越来越多地使用人类演示视频来指导机器人学习。例如,[14]通过使用无监督领域自适应和关键点提取将人类视频转换为以机器人为中心的演示来解决人机具身不匹配的问题。[24]通过对预训练视频嵌入进行调整,将机器人策略实现零样本泛化。类似地,[8]通过交叉注意机制将人类视频映射到机器人动作,而[25]通过对比学习、模仿和有限自适应来提高样本效率和泛化能力。[11]专注于跨具身技能的发现,以获得可迁移的表征。
用于机器人策略学习的扩散模型
扩散模型在生成式计算机视觉领域 [26, 27] 取得了巨大成功,并因此被应用于机器人策略学习。一些先驱性研究 [28, 29, 30] 展示了其生成去噪机器人动作和捕捉多模态行为分布的能力。诸如 [31] 等扩展性研究展示基于 Transformer 的扩散策略在 Open X-Embodiment 数据集上预训练后,在不同机器人平台上的泛化能力。MDT [32] 和 RDT-1B [33] 等模型使用基于 Transformer 的扩散模型,取代传统的 U-Net。RDT-1B 进一步统一不同机器人的动作表征,并整合了多机器人数据以实现双手操作。
基于扩散的策略可以在高维空间中建模多模态动作分布 [28, 34, 35]。 [36] 通过无监督聚类和内在奖励增强这些模型,以维持多种行为模式;[37] 则添加熵正则化器以增强鲁棒性。
本文提出一个两阶段的人类提示学习框架,该框架将机器人数据集与人类演示数据相结合,以应对任务学习中的挑战。其目标是使智体能够从人类演示视频中学习并提取有意义的特征和表征,从而执行特定任务。在第一阶段,用一个视频生成模型,该模型接收人类执行任务的提示视频和机械手的图像。该模型生成机器人执行任务的视频,并通过交叉预测策略嵌入具身迁移信息。在第二阶段,用扩散策略对表征进行微调,并融合人类和机器人数据。统一的动作空间弥合两种模态之间的差距,而基于聚类的损失函数则增强技能分离和多技能模仿性能。在实际任务上的实验证明该框架在提升人机交互和灵活操控方面的有效性。
通过交叉预测增强视频生成 (VGCP)
视频生成模型的最新进展利用了大量包含物理世界动态先验知识的在线视频数据集。然而,这些模型缺乏与机器人操作相关的数据。为了解决这个问题,用一个专注于机器人和物体操作的自定义数据集对现有模型进行了微调。目标是使智体能够根据人类提示视频执行任务,尤其是复杂的灵巧手操作。因此,视频生成模型经过训练,包含有关人类操作、物体运动、场景环境和 affordance 的细节。该数据集主要由人类操作视频组成,并辅以机器人夹持器和自行采集的灵巧手视频。虽然夹持器视频与灵巧手操作有所不同,但它们提供了关于物体运动和场景理解的宝贵信息,从而增强了模型的性能。
交叉预测:为了进一步利用这些数据并提高学习表征的质量,本文提出一种称为交叉预测的方法。如图所示,视频生成模型接收一个视频提示,其中显示源具身执行的任务以及目标具身的初始场景,然后生成目标具身执行任务的视频,从而有效地迁移具身。例如,给定一段人类抓握杯子的提示视频,该模型会生成一只灵巧的手执行相同动作的视频。
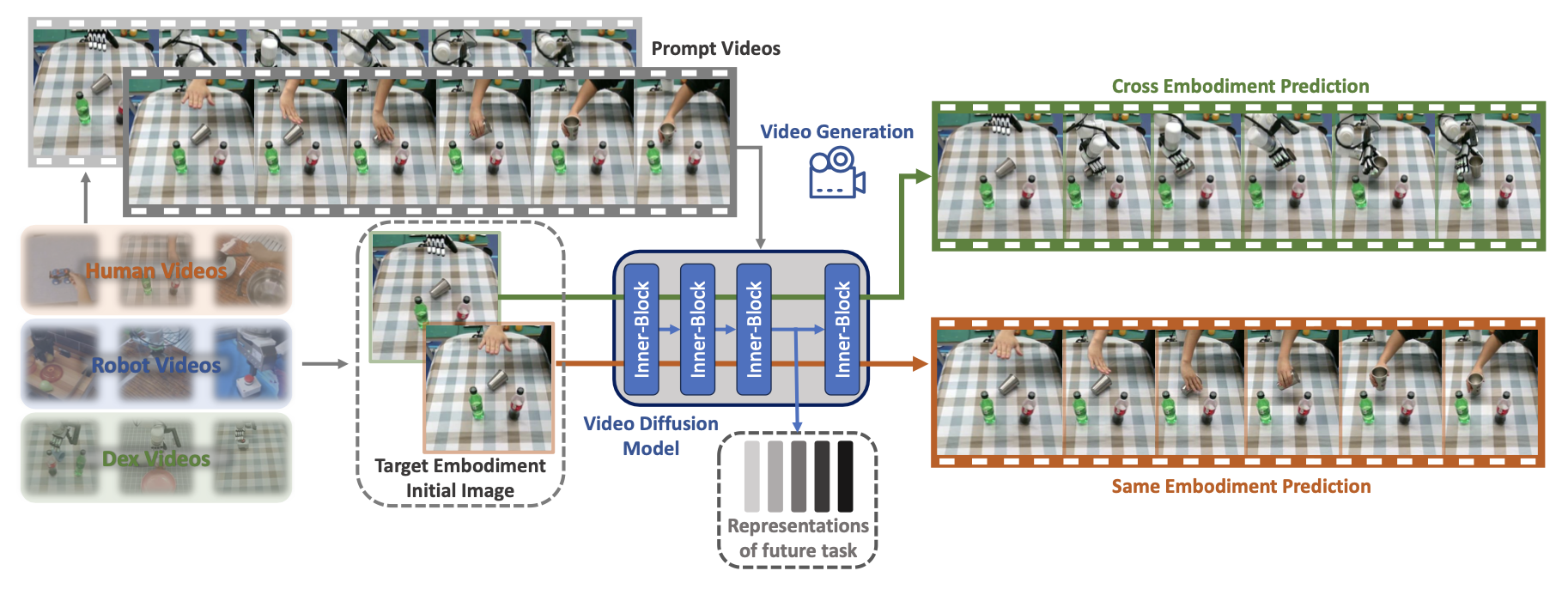
在训练期间,选择概率为 P 的交叉预测(使用不同的源具身和目标具身)或概率为 1-P 的正常预测(使用相同的具身)。这种方法将具身迁移信息嵌入到视频生成模型中,进一步提高了学习表征的可迁移性。交叉预测方法以概率 P 随机选择不同的源(s)和目标(t)具身,以概率 1-P 随机选择相同的具身。当两个具身相同时,该过程镜像典型的视频生成模型,即从初始帧生成后续帧。工作目标是让模型学习人机之间的模态迁移,同时保留有关其操作的现有知识。这种方法能够使模型捕捉到包含源具身所使用的技能、被操控的目标以及一些环境背景的视频提示表征。经过微调的模型将在第二阶段的训练中被冻结。
通过人类视频-动作对增强进行技能学习
利用灵巧手数据训练操控策略已成为机器人操控的关键方法。然而,通过遥操作收集此类数据既耗时又昂贵。为了解决这个问题,利用人手演示来增强操控能力,从而减少对机器手数据的依赖。人手数据的可用性几乎是无限的,视频可以轻松从互联网上获取或自行采集,从而最大限度地减少所需的时间和基础设施。将人手演示与遥操的机器手数据合并成一种兼容的格式,然后使用模仿学习 (IL) 进行联合训练。这构成了第二阶段算法的核心方法。如图所示:
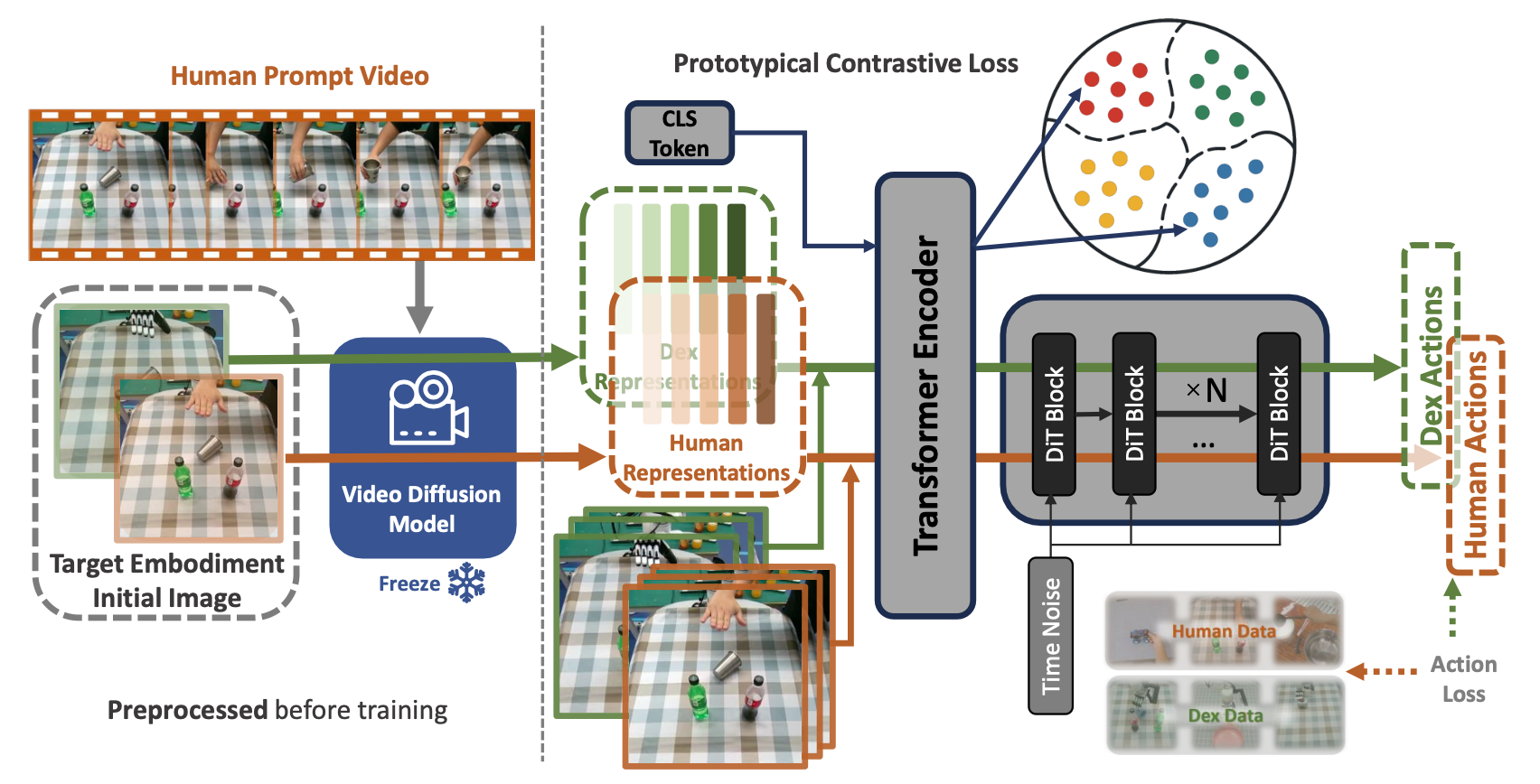
人体数据预处理:人体数据处理的目标是建立人体演示数据和机器人运动数据之间的对应关系。鉴于本文只有人类演示的第三人称视角 RGB 视频,而机器人数据包含第三人称视角 RGB 视频和关节状态信息。机器人的末端执行器状态包含两个部分:6D 手腕姿势(手腕位置和手腕方向)和手指关节。采用手部跟踪方法 WiLoR[40] 在视频帧中定位手部并重建 3D 手部网格,该模型每帧输出 21 个关键点。其能够从这 21 个关键点获得手腕 6D 位置。
对于手腕位置,可以使用相机内参计算人手在相机坐标系中的 3D 位置。为了使其与机器人的基础坐标系对齐,将所有坐标系转换为相机坐标系。为了在人机系统之间建立关节级的对应关系,需要进行手部运动重定向,将人类演示者手部的运动学配置映射到目标机器人机械手上。借鉴 Anyteleop[41] 的经验,将重定向问题转化为一个优化问题。如图所示:跨预测的视频生成例子

表征条件扩散策略:该框架采用一种扩散策略,对条件动作分布 p(a_t|s_t,z) 进行建模,其中:s_t = f_resnet34(o_t) 是由预训练的 ResNet-34 提取的视觉观察特征,z 是第一阶段输出的表征,a_t 是时间 t 的动作向量。扩散过程在动作空间中运行生成 a^i_t,而其逆过程则通过基于 Transformer 的去噪网络 ε_θ 学习预测和消除噪声。
对于灵巧手控制任务,将动作空间分解为三个不同的部分:手指关节角度 afinger_t、手腕方向 arot_t 和手腕位置 apos_t。这种分解能够通过去噪网络中独立的预测头对每种动作模式进行专门处理。
原型扩散对比策略 (PDCP)
Siamese 原型对比学习 (SPCL)[38, 39] 首先通过 K-均值将特征嵌入分组到原型(prototype)中,然后应用Siamese-式的度量损失,将每个原型(prototype)中的嵌入聚集在一起,同时将不同原型中的嵌入分开;同时,应用原型交叉熵损失,将原型分配视为软标签,以增强每个样本与其聚类的亲和力。通过利用学习的聚类结构而非单个实例,SPCL 可以减少假负样本并产生更稳定的正样本集,从而增强自监督学习中的语义辨别能力。
为了使 SPCL 适用于扩散策略训练,在扩散Transformer (DiT) 编码器的输入中添加一个可学习的聚类 token,并将该 token 的编码器输出(记为 h)用作原型-觉察潜向量。在训练过程中,联合优化三个损失函数:
(1) NT-Xent 对比损失函数 L_contra,将具有相同技能的任务视为正样本,将具有不同技能的任务视为负样本(类似于视觉领域的数据增强正样本);
(2) 原型交叉熵损失函数 L_proto,鼓励每个学习的潜向量 h 与其 K-Means 原型标签上的交叉熵分布对齐,从而促进原型内聚更紧密、原型间分离更清晰。
(3) 原型级别的Siamese-式度量损失函数 L_metric,进一步增强度量空间中相同原型样本之间的接近性,同时排斥不同原型样本,从而减少语义混淆。
共同地,这些目标指导网络学习任务判别性、技能-觉察和模态不可知性的表示,从而改善人类和机器人演示之间的跨模态一致性,并最终增强扩散策略的鲁棒性和泛化性。
本文策略完全依赖于来自固定摄像机的第三人称 RGB 图像,并在多任务基准测试上评估方法。与三个基准进行比较:(1)表征+机器人:表示仅使用机器人数据,不使用人类数据。(2)语言+机器人+人类:表示用 CLIP 编码的任务标签(例如“倒水”)替换技能表征作为策略输入。(3)表征+机器人+人类:表示同时使用机器人数据和人类数据。
位置、场景、背景泛化
为了评估策略的泛化能力,在三个关键维度上进行全面的测试。位置泛化:表示在工作空间内随机重新定位目标对象。场景泛化:表示在工作空间内随机更改或替换不可操作的目标。背景泛化:表示在不同背景(桌布等)下进行测试。
为了评估任务执行性能,引入两个指标:成功率 (SR) 和任务得分。二进制 SR 指标(1 表示完全成功,0 表示否则)和子任务指标。