一、集成学习概念
集成学习是一种通过结合多个基学习器(弱学习器)的预测结果来提升模型整体性能的机器学习方法。其核心思想是“集思广益”,通过多样性(Diversity)和集体决策降低方差(Variance)或偏差(Bias),从而提高泛化能力。
核心思想:
弱学习器:指性能略优于随机猜测的简单模型(如决策树桩、线性模型);
强学习器:通过组合多个弱学习器构建的高性能模型;
核心目标:减少过拟合(降低方差)或欠拟合(降低偏差)。
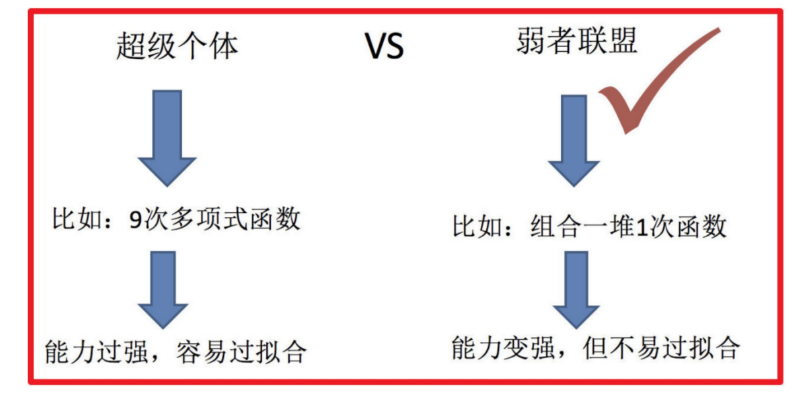
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。
二、集成学习分类
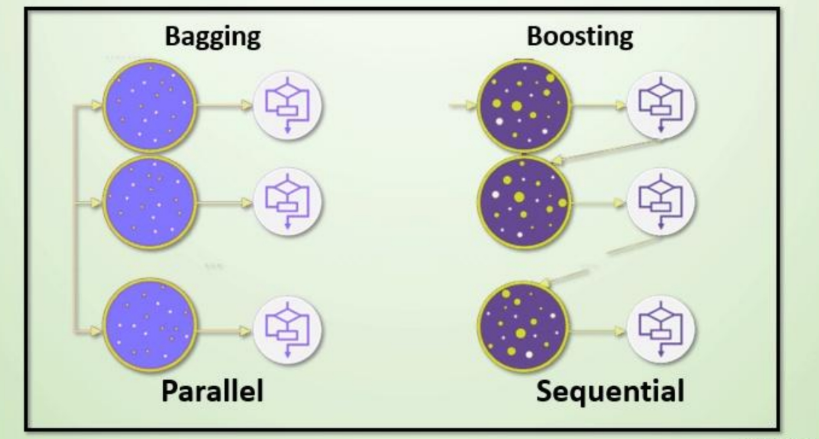
集成学习算法一般分为:bagging和boosting
(一)Bagging集成
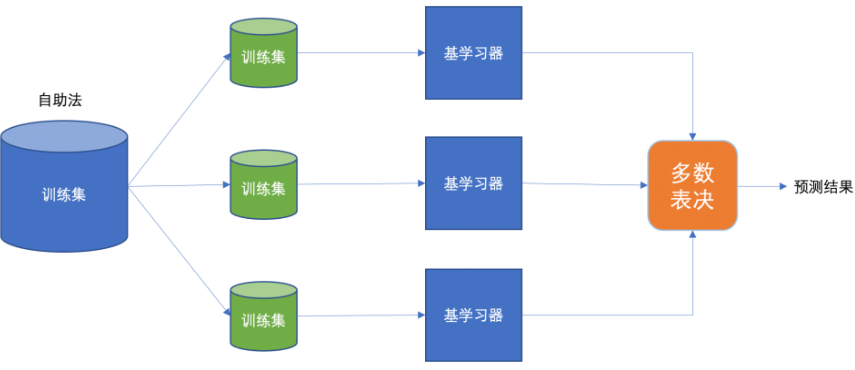
Bagging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
(二)Boosting集成
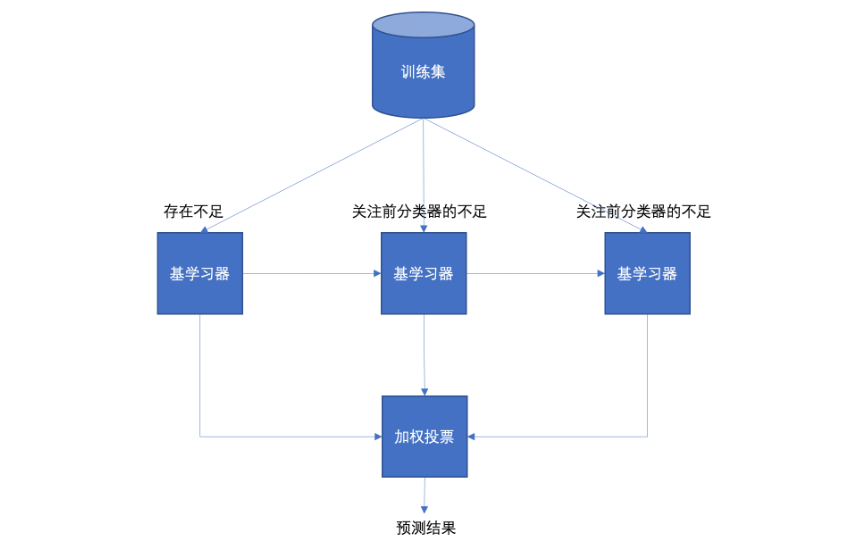
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
Boosting是一组可将弱学习器升为强学习器算法,这类算法的工作机制类似:
1.先从初始训练集训练出一个基学习器;
2.在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本(增加权重)在后续得到最大的关注;
3.然后基于调整后的样本分布来训练下一个基学习器;
4.如此重复进行,直至基学习器数目达到实现指定的值T为止。
5.再将这T个基学习器进行加权结合得到集成学习器。
简而言之:每新加入一个弱学习器,整体能力就会得到提升

(三)两种集成方法对比

三、随机森林
随机森林是基于 Bagging 思想实现的一种集成学习算法,通过构建多棵决策树并结合它们的预测结果来提高模型的准确性和鲁棒性。它由Leo Breiman在2001年提出,广泛应用于分类和回归任务。
(一)构造过程
- 训练:
(1)有放回的产生训练样本;
(2)随机挑选 n 个特征(n 小于总特征数量)。 - 预测:
(1)分类任务:投票(多数表决);
(2)回归任务:平均预测值。
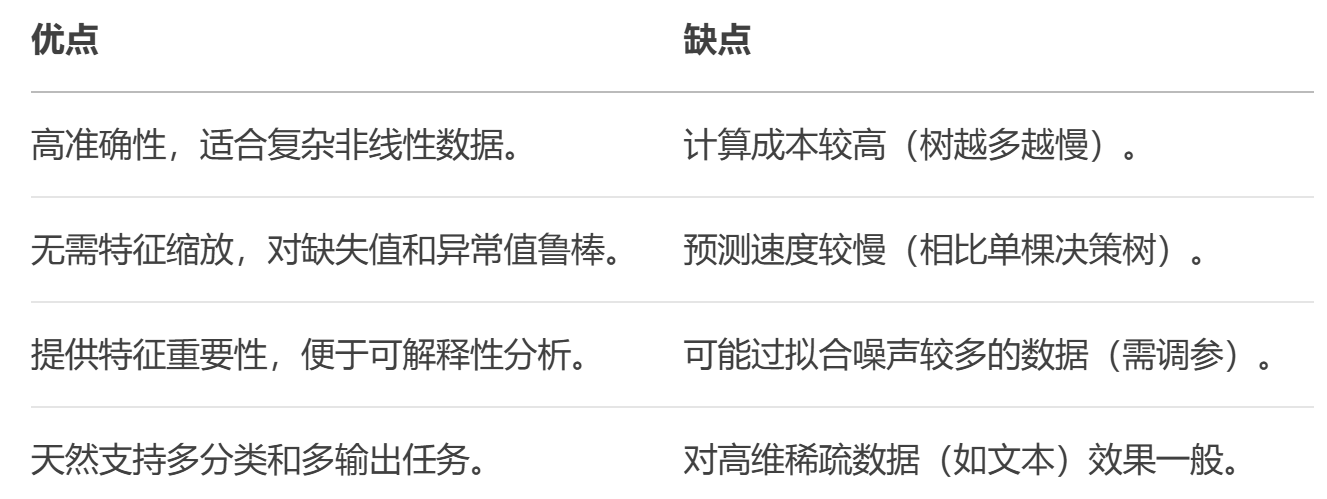
优点与缺点:
(二)代码实现—泰坦尼克号例子
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块从互联网中收集泰坦尼克号数据集
titanic=pd.read_csv("data/泰坦尼克号.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
X = pd.get_dummies(X)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)
#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
dtc.score(X_test,y_test)
#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(max_depth=6,random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
rfc.score(X_test,y_test)
#6.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))
# 随机森林做预测
# 1 实例化随机森林
rf = RandomForestClassifier()
# 2 定义超参数的选择列表
param={"n_estimators":[80,100,200], "max_depth": [2,4,6,8,10,12],"random_state":[9]}
# 超参数调优
# 3 使用GridSearchCV进行网格搜索
from sklearn.model_selection import GridSearchCV
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("随机森林预测的准确率为:", gc.score(X_test, y_test))
四、Adaboost
Adaptive Boosting(自适应提升)是基于 Boosting思想实现的一种集成学习算法核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。
弱分类器的性能比随机猜测强就行,即可构造出一个非常准确的强分类器。其特点是:训练时,样本具有权重,并且在训练过程中动态调整。被分错的样本会加大权重,算法更加关注错误样本。
(一)核心公式
AdaBoost模型公式:
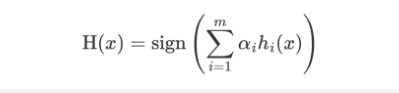
- α 为模型的权重
- m 为弱学习器数量
- hi(x) 表示弱学习器
- H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。
AdaBoost权重更新公式:
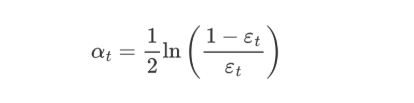
εt 表示第 t 个弱学习器的错误率
AdaBoost 样本权重更新公式:
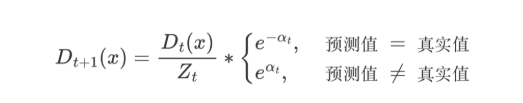
- Zt 为归一化值(所有样本权重的总和)
- Dt(x) 为样本权重
- αt 为模型权重。
(二)主要过程演示
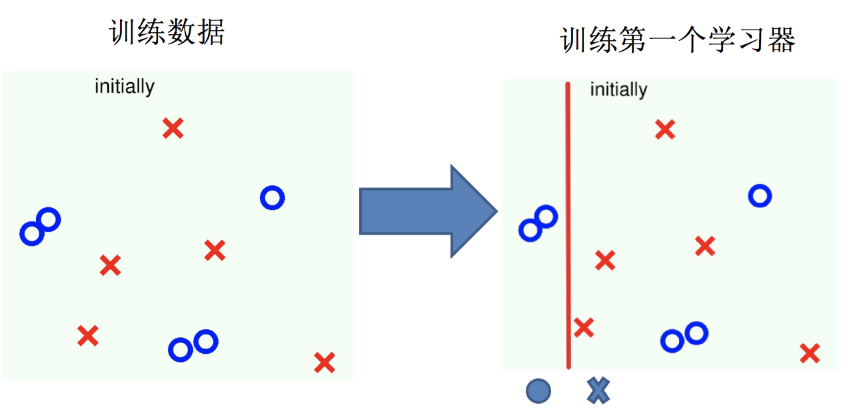
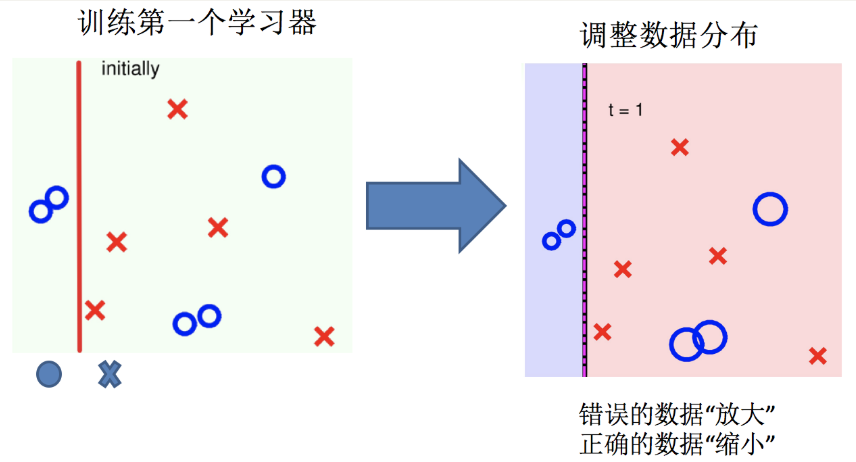
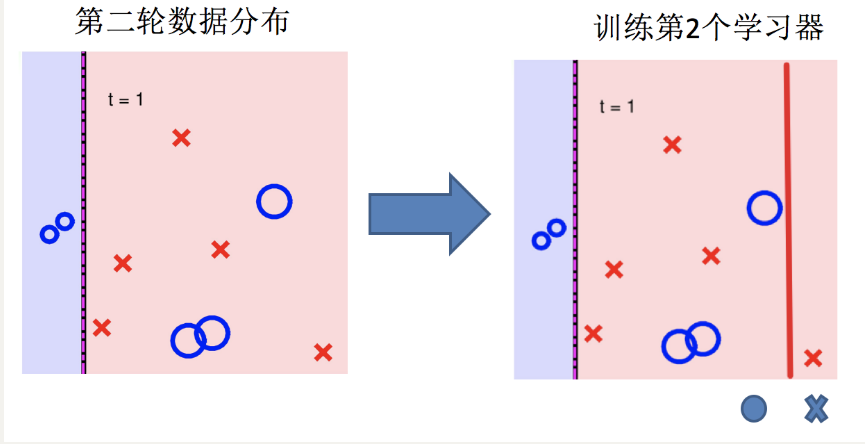
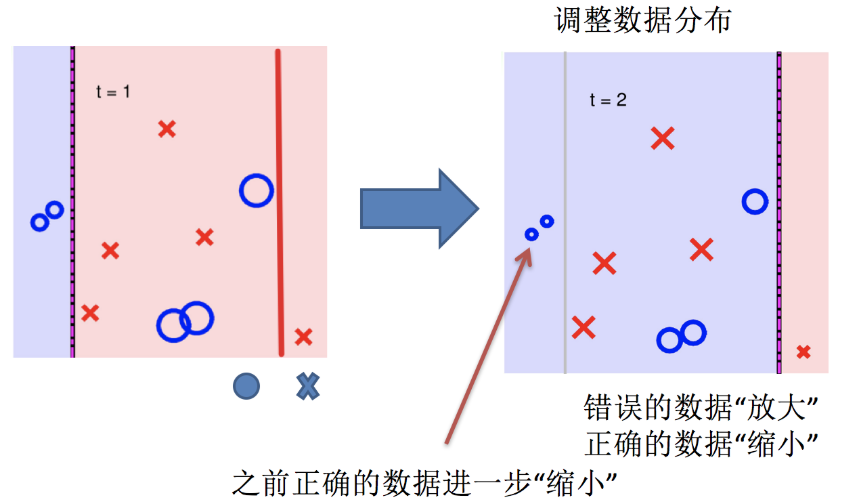
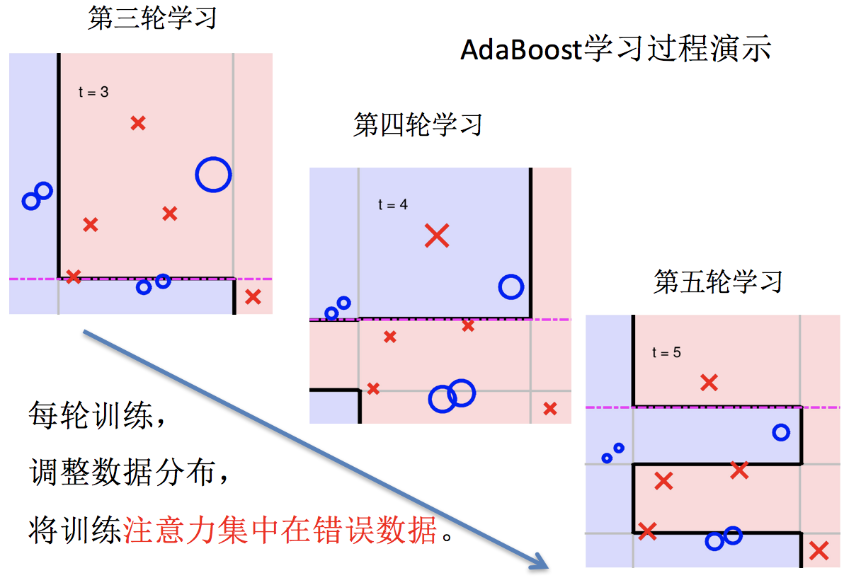
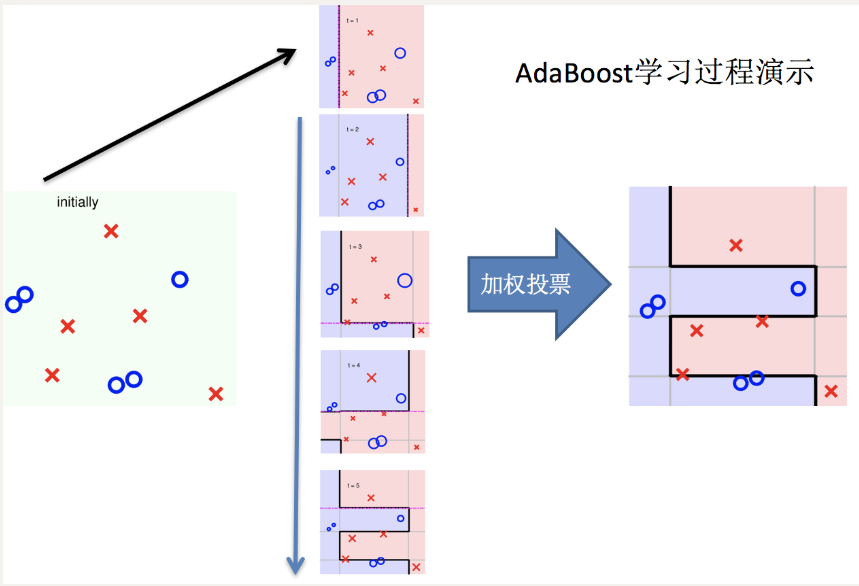
AdaBoost算法的两个核心步骤:
权值调整: AdaBoost算法提高那些被前一轮基分类器错误分类样本的权值,而降低那些被正确分类样本的权值。从而使得那些没有得到正确分类的样本,由于权值的加大而受到后一轮基分类器的更大关注。
基分类器组合: AdaBoost采用加权多数表决的方法。
分类误差率较小的弱分类器的权值大,在表决中起较大作用。
分类误差率较大的弱分类器的权值小,在表决中起较小作用。
(三)Adaboost构建过程(例)
下面为训练数数据,假设弱分类器由 x 产生,其阈值 v 使该分类器在训练数据集上的分类误差率最低,试用 Adaboost 算法学习一个强分类器。

1. 构建第一个弱学习器
初始化工作:初始化 10 个样本的权重,每个样本的权重为:0.1
构建第一个基(弱)学习器:
(1)寻找最优分裂点
a. 对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
b. 当以 0.5 为分裂点时,有 5 个样本分类错误
c. 当以 1.5 为分裂点时,有 4 个样本分类错误
d. 当以 2.5 为分裂点时,有 3 个样本分类错误
e. 当以 3.5 为分裂点时,有 4 个样本分类错误
f. 当以 4.5 为分裂点时,有 5 个样本分类错误
g. 当以 5.5 为分裂点时,有 4 个样本分类错误
h. 当以 6.5 为分裂点时,有 5 个样本分类错误
i. 当以 7.5 为分裂点时,有 4 个样本分类错误
j. 当以 8.5 为分裂点时,有 3 个样本分类错误
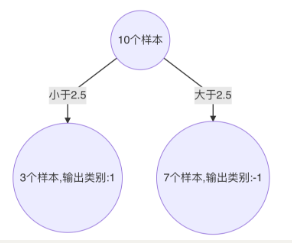
k. 最终,选择以 2.5 作为分裂点,计算得出基学习器错误率为:3/10=0.3(2) 计算模型权重:
1/2 * np.log((1-0.3)/0.3)=0.4236(3)更新样本权重:
a. 分类正确样本为:1、2、3、4、5、6、10 共 7 个,其计算公式为:e-αt,则正确样本权重变化系数为:e-0.4236 = 0.6547
b. 分类错误样本为:7、8、9 共 3 个,其计算公式为:eαt,则错误样本权重变化系数为:e0.4236 = 1.5275
c. 样本 1、2、3、4、5、6、10 权重值为:0.06547
d. 样本 7、8、9 的样本权重值为:0.15275
e. 归一化 Zt 值为:0.06547 * 7 + 0.15275 * 3 = 0.9165
f. 样本 1、2、3、4、5、6、10 最终权重值为:0.07143
g. 样本 7、8、9 的样本权重值为:0.1667
h. 此时得到:

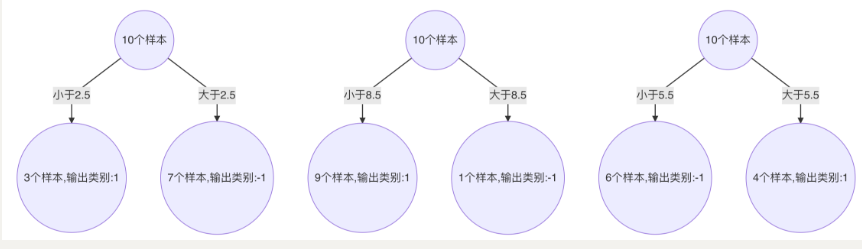
2.构建第二个弱学习器
寻找最优分裂点:
(1)对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
(2) 当以 0.5 为分裂点时,有 5 个样本分类错误,错误率为:0.07143 * 5 = 0.35715
(3)当以 1.5 为分裂点时,有 4 个样本分类错误,错误率为:0.07143 * 1 + 0.16667 * 3 = 0.57144
(4)当以 2.5 为分裂点时,有 3 个样本分类错误,错误率为:0.16667 * 3 = 0.57144
。。。 。。。
(5) 当以 8.5 为分裂点时,有 3 个样本分类错误,错误率为:0.07143 * 3 = 0.21429
(6) 最终,选择以 8.5 作为分裂点,计算得出基学习器错误率为:0.21429
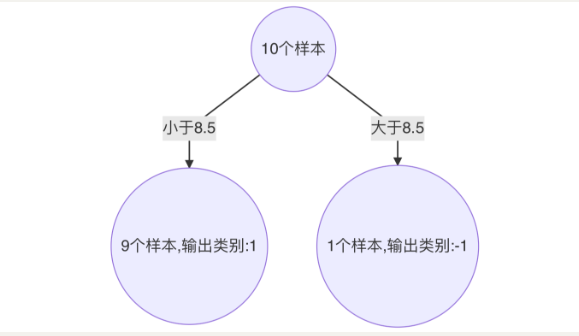
计算模型权重:
1/2 * np.log((1-0.21429)/0.21429)=0.64963分类正确的样本:1、2、3、7、8、9、10,其权重调整系数为:0.5222
分类错误的样本:4、5、6,其权重调整系数为:1.9148
分类正确样本权重值:
(1)样本 0、1、2、、9 为:0.0373
(2)样本 6、7、8 为:0.087分类错误样本权重值:0.1368
归一化 Zt 值为:
0.0373 * 4 + 0.087 * 3 + 0.1368 * 3 = 0.8206最终权重:
(1)样本 0、1、2、9 为 :0.0455
(2) 样本 6、7、8 为:0.1060
(3)样本 3、4、5 为:0.1667最后得到:
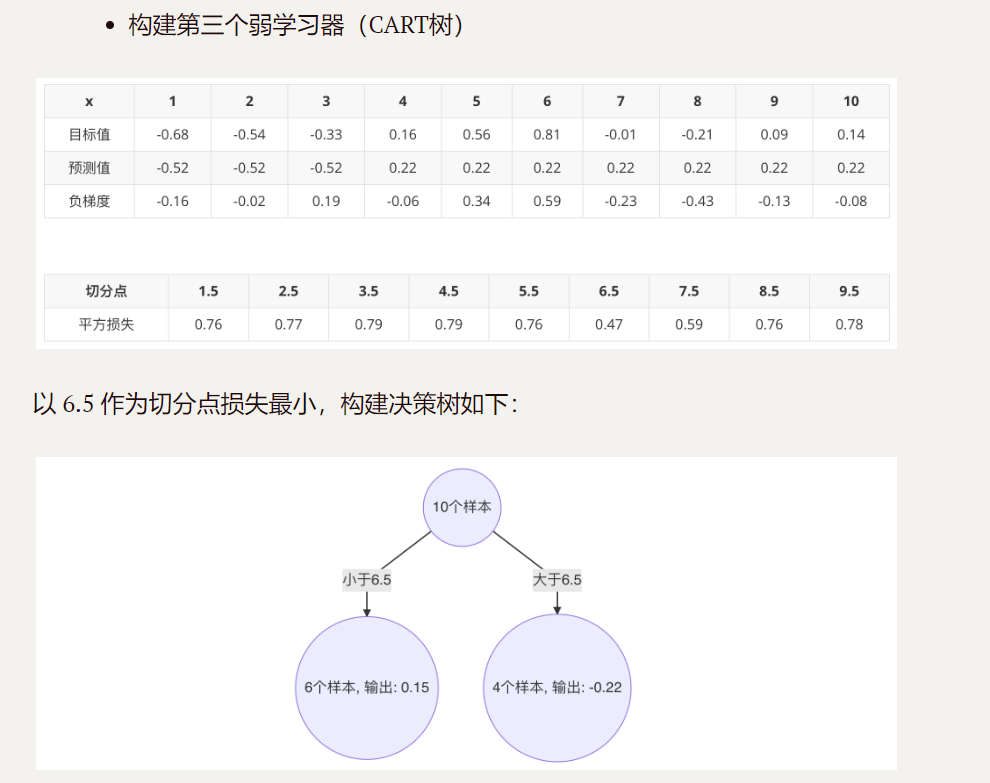
3.照着如上步骤,构建好的第三个弱学习器
如下:
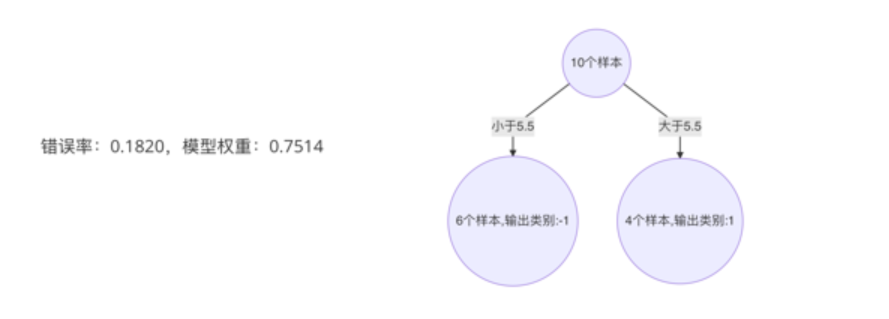
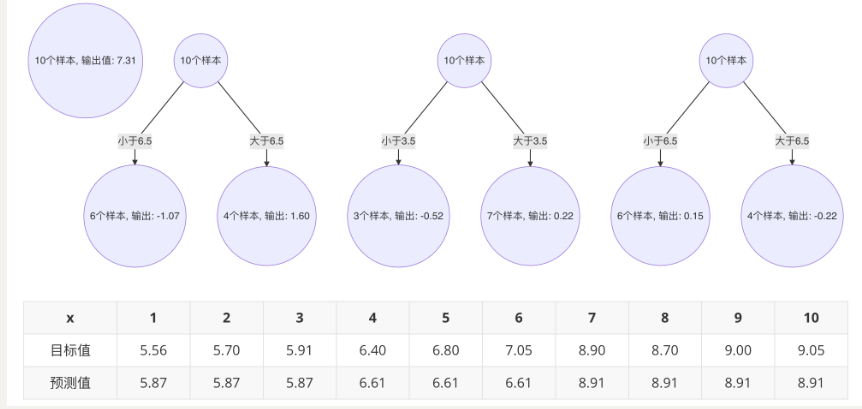
最后,由三个弱学习器组成的强学习器
如下:
(四)代码实现—葡萄酒例子
葡萄酒分为白葡萄酒和红葡萄酒两类。
该分析涉及白葡萄酒,并基于数据集中显示的13个变量/特征:
固定酸度,挥发性酸度,柠檬酸,残留糖,氯化物,游离二氧化硫,总二氧化硫,密度,pH值,硫酸盐,酒精,质量等。为了评估葡萄酒的质量,我们提出的方法就是根据酒的物理化学性质与质量的关系,找出高品质的葡萄酒具体与什么性质密切相关,这些性质又是如何影响葡萄酒的质量。
# 获取数据
import pandas as pd
df_wine = pd.read_csv('data/wine.data')
# 修改列名
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
# 去掉一类(1,2,3)
df_wine = df_wine[df_wine['Class label'] != 1]
# 获取特征值和目标值
X = df_wine[['Alcohol', 'Hue']].values
y = df_wine['Class label'].values
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# 类别转化 (2,3)=>(0,1),将类别2,3分别转化为0,1
le = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
# 机器学习(决策树和AdaBoost)
tree = DecisionTreeClassifier(criterion='entropy',max_depth=1,random_state=0)
ada= AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=0)
from sklearn.metrics import accuracy_score
# 决策树和AdaBoost分类器性能评估
# 决策树性能评估
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# Decision tree train/test accuracies 0.845/0.854
# AdaBoost性能评估
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# Adaboost train/test accuracies 1/0.875
总结:AdaBosst预测准确了所有的训练集指标,与单层决策树相比,它在测试集上表现稍微好一些。单决策树对于训练数据过拟合的程度更加严重一些。总之,我们可以发现Adaboost分类器能够些许提高分类器性能,并且与bagging分类器的准确率接近。
五、GBDT(梯度提升树)
梯度提升树(Gradient Boosting Decision Tre)是提升树(Boosting Decision Tree)的一种改进算法,是一种基于梯度下降和决策树的集成学习算法,通过逐步优化损失函数来提升模型性能。
它在Kaggle等数据科学竞赛中表现优异,是XGBoost、LightGBM等现代算法的基础。
假设:
- 我们前一轮迭代得到的强学习器是:fi-1(x)
- 损失函数是:L(y,fi−1(x))
- 本轮迭代的目标是找到一个弱学习器:hi(x)
- 让本轮的损失最小化: L(y, fi(x))=L(y, fi−1(x)) + hi(x))
当采用平方损失函数时:
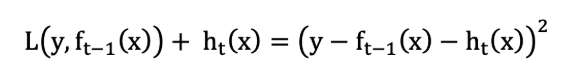
则:
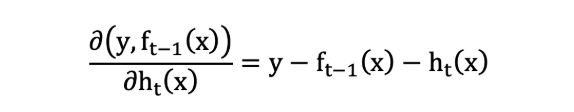
损失函数为平方损失, 则每个样本要拟合的负梯度为:
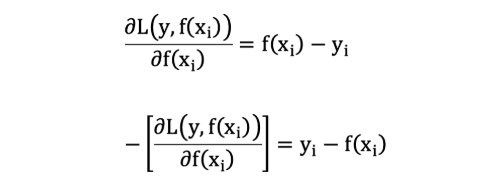
此时, 我们发现 GBDT 拟合的负梯度就是残差,或者说对于回归问题,拟合的目标值就是残差。
如果我们的 GBDT 进行的是分类问题,则损失函数变为 logloss(对数损失),此时拟合的目标值就是该损失函数的负梯度值(对数损失的负梯度 y−p 始终在 [−1,1] 之间)。
(一)GBDT算法流程
1 初始化弱学习器(目标值的均值作为预测值);
2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度;
3 直到达到指定的学习器个数;
4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出。
(二)GBDT构建流程(例)

1.初始化弱学习器(CART树)
我们通过计算当模型预测值为何值时,会使得第一个基学习器的平方误差最小,即:求损失函数对 f(xi) 的导数,并令导数为0。(下文平方误差之所以乘以1/2,是为了方便计算导数【1/2*2可抵消】。)

2.构建第一个cart树
由于我们拟合的是样本的负梯度,即:
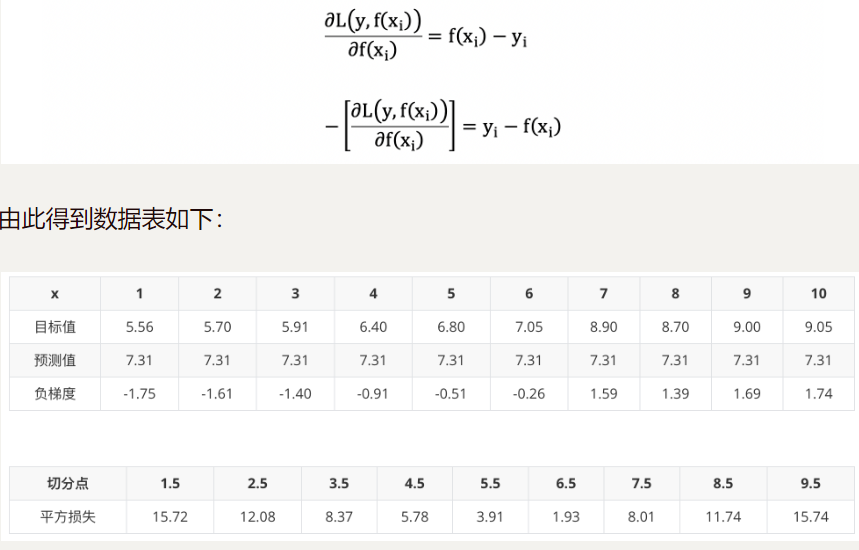
上表中平方损失计算过程说明(以切分点1.5为例):
切分点1.5 将数据集分成两份 [5.56],[5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9. 9.05]
第一份的平均值为5.56 第二份数据的平均值为(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9 = 7.5011
由于是回归树,每份数据的平均值即为预测值,则可以计算误差,第一份数据的误差为0,第二份数据的平方误差为 :
( 5.70 − 7.5011 ) 2 + ( 5.91 − 7.5011 ) 2 + . . . + ( 9.05 − 7.5011 ) 2 = 15.72308 (5.70-7.5011)^2+(5.91-7.5011)^2+...+(9.05-7.5011)^2 = 15.72308 (5.70−7.5011)2+(5.91−7.5011)2+...+(9.05−7.5011)2=15.72308
以 6.5 作为切分点损失最小,构建决策树如下:
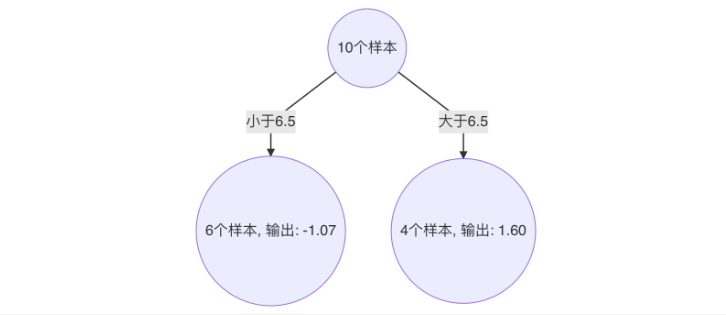
3.构建第二个cart树
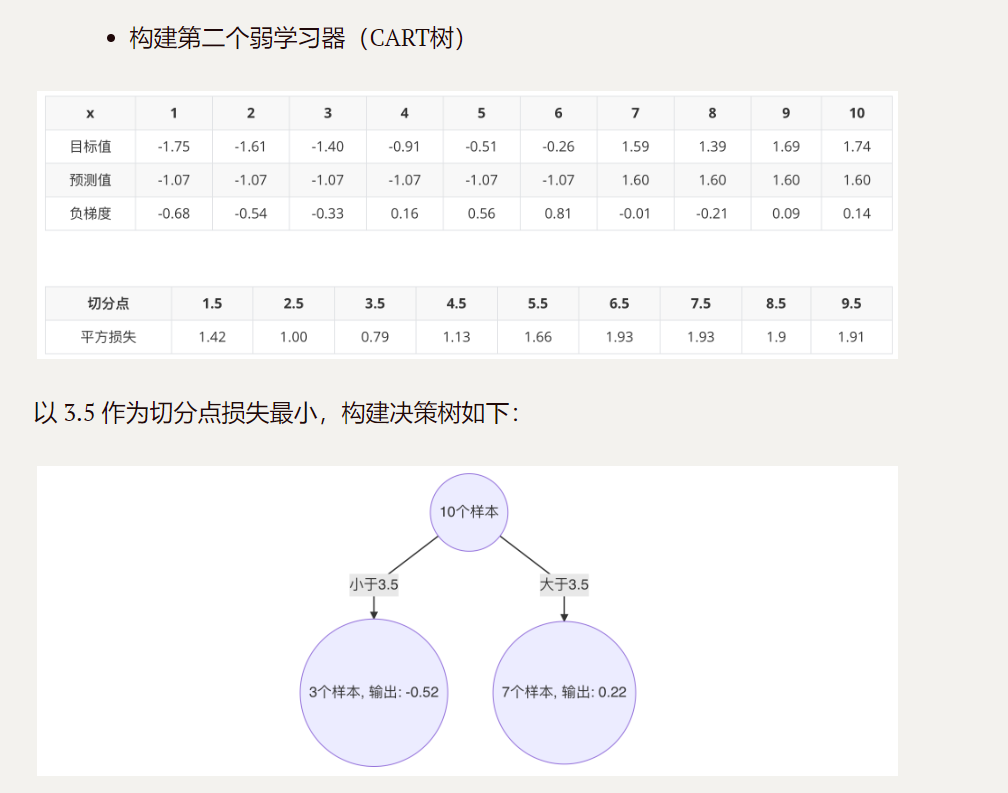
4.构建第三个cart树
5.最终的强学习器:
(三)代码实现—泰坦尼克号例子
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块泰坦尼克号数据集
titanic=pd.read_csv("../data/泰坦尼克号数据集.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)
#将数据转化为特征向量
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='records'))
X_test=vec.transform(X_test.to_dict(orient='records'))
#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
print("score",dtc.score(X_test,y_test))
#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
print("score:forest",rfc.score(X_test,y_test))
#6.GBDT进行模型的训练和预测分析
from sklearn.ensemble import GradientBoostingClassifier
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_pred=gbc.predict(X_test)
print("score:GradientBoosting",gbc.score(X_test,y_test))
#7.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))
print("gbc_report:",classification_report(gbc_y_pred,y_test))
今天的分享到此结束。