GraphQL 工程篇:分页、数据优化与 React Hooks 实战
之前的笔记:
完整的代码依旧在:
https://github.com/GoldenaArcher/graphql-by-example
React 集成
这一篇集成了一些 React 的内容,主要包括 custom hook 的部分
之前的实现基于封装实现,在 React 组建内调用,就需要实现 loading、error,不过 apollo-client 本身也提供了基于不同实现的集成:
下面的部分就会使用 apollo-client 对 React 的集成进行重构
添加 provider
首先需要导入 ApolloProvider,目前项目就放在 App.jsx 中实现了,放在最顶层,这样下面所有的组件都可以共享组件的数据、状态和缓存
import { ApolloProvider } from "@apollo/client";
function App() {
return (
<ApolloProvider client={apolloClient}>
<NavBar user={user} onLogout={handleLogout} />
<main className="section"></main>
</ApolloProvider>
);
}
export default App;
useQuery
随后是将之前的 gql 全都导出成一个单独的 query:
export const companyByIdQuery = gql`
query CompanyById($id: ID!) {
company(id: $id) {
id
name
description
jobs {
id
date
title
}
}
}
`;
export async function getCompany(id) {
const query = companyByIdQuery;
const { data } = await apolloClient.query({ query, variables: { id } });
return data.company;
}
这里 getCompany 其实可以删了,不过这里留着作为一个 referred
接下来就是在 React 组建中使用合适的 query:
import { useParams } from "react-router";
import { companyByIdQuery } from "../lib/graphql/queries";
import JobList from "../components/JobList";
import { useQuery } from "@apollo/client";
function CompanyPage() {
const { companyId } = useParams();
const { data, loading, error } = useQuery(companyByIdQuery, {
variables: { id: companyId },
});
// const [state, setState] = useState({
// company: null,
// loading: true,
// hasErrors: false,
// });
// useEffect(() => {
// (async () => {
// try {
// const company = await getCompany(companyId);
// setState({ company, loading: false, hasErrors: false });
// } catch (e) {
// setState({
// company: null,
// loading: false,
// hasErrors: true,
// });
// }
// })();
// }, [companyId]);
// const { company, loading, hasErrors } = state;
if (loading) {
return <div>Loading...</div>;
}
if (error) {
return <div>Something went wrong...</div>;
}
const company = data.company;
return (
<div>
<h1 className="title">{company.name}</h1>
<div className="box">{company.description}</div>
<h2 className="title is-5">Jobs At {company.name}</h2>
<JobList jobs={company.jobs} />
</div>
);
}
export default CompanyPage;
可以看到, useQuery 本身接管了状态管理的部分,因此相比较原本的实现,使用 apollo-client 提供的 hooks 的代码更加的简洁明了
换句话说,如果前端的实现比较简单,不需要在非 React 组件中调用,那么使用 apollo-client 提供的 hooks 即可;如果有额外的业务需求,需要在 React 组件外调用 GQL,那么可以 GQL 保存为对应的方法,再在不同的地方进行调用
不过总体来说,90%以上的业务场景是可以通过直接使用 apollo-client 提供的 hooks 解决的
custom hook
这个的实现比较简单,就是将对应的业务逻辑保存到对应的 custom hooks 里,起到更加方便管理、提升代码复用率的作用:
custom hook
import { useQuery } from "@apollo/client"; import { companyByIdQuery } from "../lib/graphql/queries"; export const useFetchCompany = (companyId) => { const { data, loading, error } = useQuery(companyByIdQuery, { variables: { id: companyId }, }); return { company: data?.company, loading, error }; };组件内调用
import { useParams } from "react-router"; import JobList from "../components/JobList"; import { useFetchCompany } from "../hooks/useCompany"; function CompanyPage() { const { companyId } = useParams(); const { company, loading, error } = useFetchCompany(companyId); if (loading) { return <div>Loading...</div>; } if (error) { return <div>Something went wrong...</div>; } return ( <div> <h1 className="title">{company.name}</h1> <div className="box">{company.description}</div> <h2 className="title is-5">Jobs At {company.name}</h2> <JobList jobs={company.jobs} /> </div> ); } export default CompanyPage;
同样的,有需要讲 GQL 保存为单独的方法在不同地方调用的需求,也是可以通过封装 custom hook 减少 React 组件内的重复代码
useMutate
和 useQuery 对立,不过这里是 mutation,即 CUD 操作的实现
custom hook
export const useCreateJob = () => { const [mutate, options] = useMutation(createJobMutation); const createJob = async ({ title, description }) => { const { data: { createJob: job }, } = await mutate({ variables: { input: { title, description, }, }, update: (cache, { data: { createJob: job } }) => { cache.writeQuery({ query: jobByIdQuery, data: { job, }, }); }, }); return job; }; return [createJob, options]; };调用
import { useState } from "react"; import { useNavigate } from "react-router-dom"; import { useCreateJob } from "../hooks/useJob"; function CreateJobPage() { // omitting other state management // loading can be used to block re-submit with disable attributes const [createJob, { loading }] = useCreateJob(); const handleSubmit = async (event) => { event.preventDefault(); const job = await createJob({ title, description }); navigate(`/jobs/${job.id}`); }; // omitting return } export default CreateJobPage;
这种封装的方法,根据不同情况可以修改不同的返回值
Data Loader
Data Loader,这里提到的,是一个 npm 上的包:**dataloader,在这里主要可以提升和优化,解决一下 n+1 问题**
n+1 问题
n+1 问题是一个比较经典的数据库 query 问题了,以当前这个项目为例,它可能会出现这样的情况:
具体的流程为:
出现调用
getJobs()方法的情况每一个 job 都会有对应的 company
根据现在的实现,获取 company 的方法为:
company: (job) => { return getCompany(job.companyId); },数据库会通过
select * from db where id={job.companyId}的方法去返回所有的公司如果有 N 个 job,就会调用 N 次该查询,去寻找对应的公司
再算上原本调用 Jobs 的 query,就形成了 n+1 次调用
解决方案 & 使用方式
通过 **dataloader,调用方式就变成了这样:**
具体的流程为:
出现调用
getJobs()方法的情况获取所有 jobs 的
companyId通过
select * from db where id in (a,b,c,d)的方式去调用这样可以有效地把 n 次调用减少为 1 次 → 假设没有 pagination,这样可以减少后端和数据库之间沟通的压力
具体使用方式为:
- 新增一个 loader
export const companyLoader = new DataLoader(async (ids) => { const companies = await getCompanyTable().select().whereIn("id", ids); return ids.map((id) => companies.find((company) => company.id === id)); }); - 在 resolver 中调用这个 loader
Job: { date: (parent) => { return toIsoDate(parent.createdAt); }, company: (job) => { return companyLoader.load(job.companyId); }, },
缓存问题
默认情况下 **dataloader 是会 cache 数据的,也就是说,如果使用 singleton,在永远都有 1 个实例的情况下,就只能获取实例初始化时获取的资料。如果这是一个只读数据库,那么不会有很大的问题,不过在大多数的业务场景下,还是需要考虑 CRUD 四个操作的**
目前的解决方式是在 context 中,在每次调用时,都创建一个新的 instance
loader 更新
const companyLoader = new DataLoader(async (ids) => { const companies = await getCompanyTable().select().whereIn("id", ids); return ids.map((id) => companies.find((company) => company.id === id)); }); export const createCompanyLoader = () => companyLoader;server 中更新 context
const getContext = async ({ req }) => { const companyLoader = createCompanyLoader(); const context = { companyLoader, }; if (!req.auth) { return context; } const user = await getUser(req.auth.sub); context.user = user; return context; };调用
Job: { date: (parent) => { return toIsoDate(parent.createdAt); }, company: (job, _args, { companyLoader }) => { return companyLoader.load(job.companyId); }, },
这样总体就能够解决数据缓存从而 stale 的问题
分页 pagination
分页根据具体的实现大体分成两种:
- offset pagination
这种情况假设数据的变更不是非常的频繁,单纯的将数据按页分。比如说如果有 100 个数据,分成 10 页,那么数据的现实就是 1-10,11-20,等
使用 offset 会遇到的问题就是,如果数据的变更比较频繁,依旧以上面的案例来说,在用户查询 1-10 条数据后,向数据库的头部新增 10 条新的数据,用户再查询第二页时,出现的还是 1-10 条数据 - cursor pagination
cursor 的实现比较复杂,它的分页不是取决于数据库的 index,而是用一个更加动态的 hash id,这样可以解决 offset 的问题,不过在实现的时候也更加的负责。一些实现会用数据库 id——用的是 uuid 这种——去进行 cursor pagination,不过具体我也没有做过这方面的后端实现,不是特别的了解
cursor pagination 用的比较多的地方就是流媒体/短视频/社媒这种平台,数据推送/新增更加的无序,更加依赖算法实现,所以用 cursor pagination 能够很好的减少重复数据推送的问题——也就是当数据操作比较频繁时,offset pagination 中比较常见的问题
之前写 YT 复刻的时候,因为用的就是 YT 的 API,所以复刻的也是实际的功能: **Redux Toolkit + React + TS + Tailwind CSS 复刻 YouTube 学习心得,**yt 用的就是 cursor pagination
下面的案例基于 offset 实现
分页 - server
同样,后端代码需要修改 3 个地方
- schema
增加定义,否则无法 query 到数据type Query { job(id: ID!): Job jobs(limit: Int, offset: Int): [Job] company(id: ID!): Company } - resolvers
接和传参Query: { jobs: async (_root, { limit , offset}) => getJobs(limit, offset), }, - db
具体的数据库实现export async function getJobs(limit, offset) { const query = getJobTable().select().orderBy("createdAt", "desc"); if (limit) { query.limit(limit); } if (offset) { query.offset(offset); } return await query; }
分页 - client
client 也是修改三个部分,query,hook 和 component
queries
export const jobsQuery = gql` query Jobs($limit: Int, $offset: Int) { jobs(limit: $limit, offset: $offset) { ...JobDetail } } ${jobDetailFragment} `;同上,可以从 GQL 拿到数据
hook
export const useFetchJobs = (limit, offset) => { const { data, loading, error } = useQuery(jobsQuery, { variables: { limit, offset }, }); return { jobs: data?.jobs, loading, error, }; };同理,接和传参
component
import { useState } from "react"; import JobList from "../components/JobList"; import { useFetchJobs } from "../hooks/useJob"; const JOBS_PER_PAGE = 5; function HomePage() { const [currPage, setCurrPage] = useState(1); const { jobs, error, loading } = useFetchJobs( JOBS_PER_PAGE, (currPage - 1) * JOBS_PER_PAGE ); return ( <div> <h1 className="title">Job Board</h1> <div> <button onClick={() => setCurrPage((prev) => (prev === 1 ? 1 : prev - 1))} > Prev </button> <span>{currPage}</span> <button onClick={() => setCurrPage((prev) => prev + 1)}>Next</button> </div> <JobList jobs={jobs} /> </div> ); } export default HomePage;具体的渲染实现
最终效果如下:

这时候还有一个问题,那就是查到数据库没有的数据——也就是本来数据库里只有 50 条数据,但是 query 到了 60,70,甚至更多的情况。GQL 现在是不会报错了 ,不过依旧会给用户一种错误感觉,就是数据和服务不完整的感觉
总数计算 - server
这里同样修改 3 个地方:
schema
type Query { job(id: ID!): Job jobs(limit: Int, offset: Int): PaginatedList company(id: ID!): Company } type PaginatedList { totalCount: Int! items: [Job] }db
export const countJobs = async () => { const { count } = await getJobTable().first().count("* as count"); return count; };新增的一个功能,主要查询总数
resolvers
export const resolvers = { Query: { jobs: async (_root, { limit, offset }) => { const [items, totalCount] = await Promise.all([ getJobs(limit, offset), countJobs(), ]); return { items, totalCount }; }, }, };这里就是调用 db 新增加的功能,然后返回
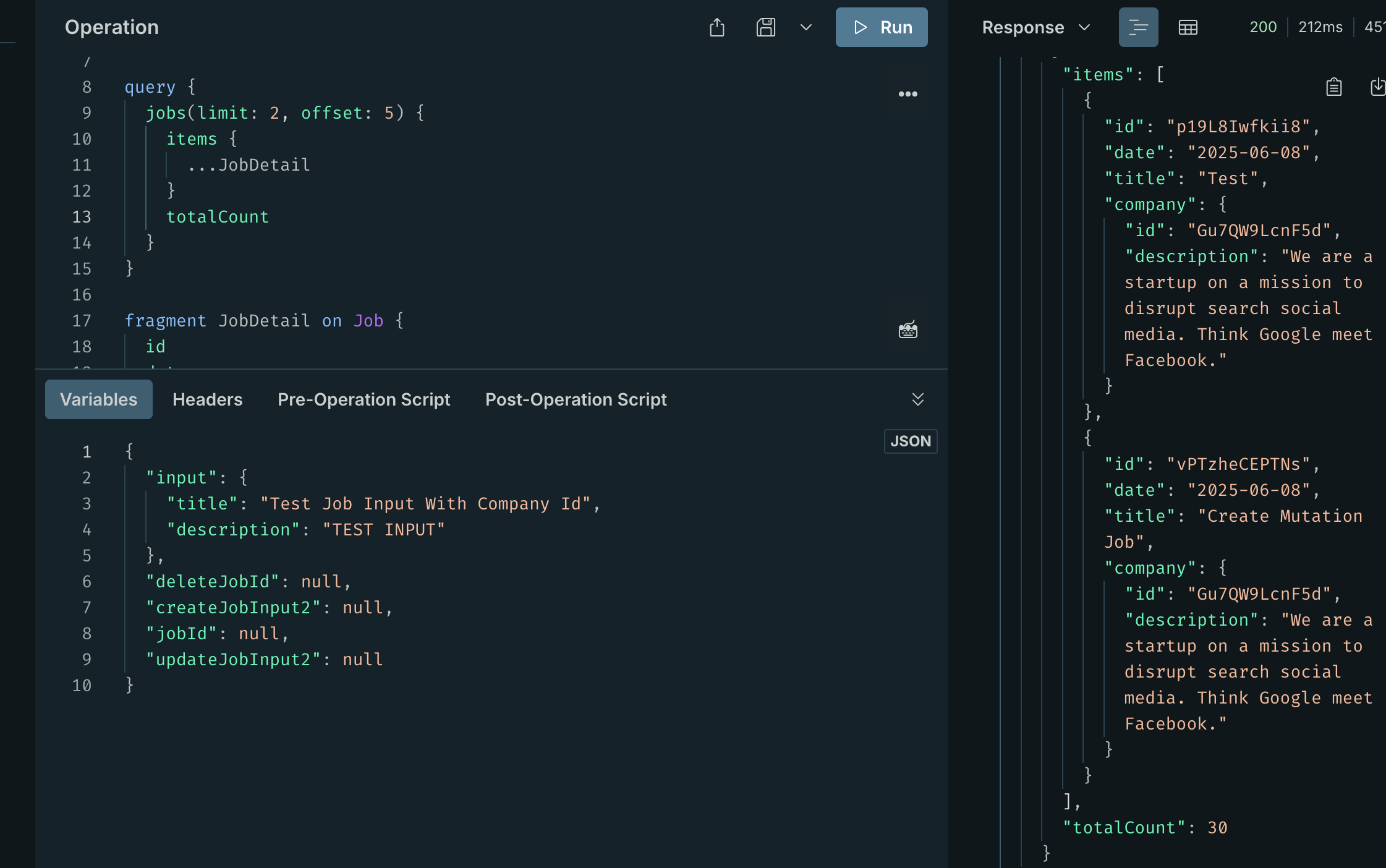
至此,后端的数据已经准备好,可以让前端调用了
总数计算 - client
这里更新两个地方,queries 拿数据——数据结构没有变,所以 hooks 不变,component 渲染
queries
export const jobsQuery = gql` query Jobs($limit: Int, $offset: Int) { jobs(limit: $limit, offset: $offset) { items { ...JobDetail } totalCount } } ${jobDetailFragment} `;component
import { useState } from "react"; import JobList from "../components/JobList"; import PaginationBar from "../components/PaginationBar"; import { useFetchJobs } from "../hooks/useJob"; const JOBS_PER_PAGE = 5; function HomePage() { const [currPage, setCurrPage] = useState(1); const { jobs, error, loading } = useFetchJobs( JOBS_PER_PAGE, (currPage - 1) * JOBS_PER_PAGE ); const totalPages = Math.ceil((jobs?.totalCount || 0) / JOBS_PER_PAGE); return ( <div> <h1 className="title">Job Board</h1> <PaginationBar currentPage={currPage} totalPages={totalPages} onPageChange={setCurrPage} /> <JobList jobs={jobs?.items} /> </div> ); } export default HomePage;

pagination 按钮的实现省略了,不过就是按照 totalPages 进行的计算,大体逻辑就是
- 高亮当前页面
- 当
currPage === 1,disable 第一页 - 当
currPage === totalPages,disable 最后一页