一、数据库基础操作
数据库是数据存储的容器,所有表和数据都依赖于数据库存在,以下是数据库的核心操作:
1. 创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] `数据库名`
DEFAULT CHARACTER SET 字符集
[DEFAULT COLLATE 排序规则];
示例:
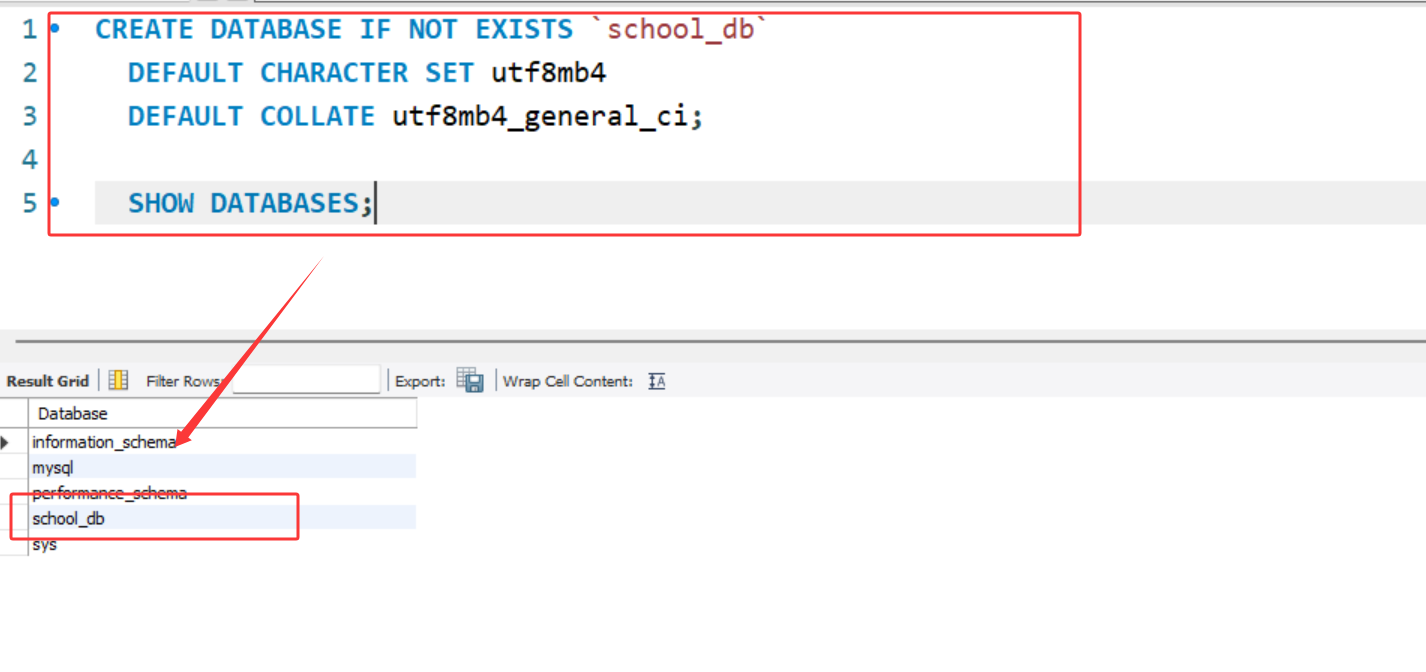
CREATE DATABASE IF NOT EXISTS `school_db`
DEFAULT CHARACTER SET utf8mb4
DEFAULT COLLATE utf8mb4_general_ci;
详细讲解:
IF NOT EXISTS:可选参数,用于避免重复创建数据库导致的报错(若数据库已存在,不执行操作)。DEFAULT CHARACTER SET:指定数据库默认字符集。推荐使用utf8mb4(而非utf8),因为utf8仅支持部分Unicode字符,而utf8mb4可完整支持包括emoji在内的所有Unicode字符,兼容性更好。DEFAULT COLLATE:指定排序规则,utf8mb4_general_ci为不区分大小写的排序(ci即case-insensitive),若需区分大小写可使用utf8mb4_bin。数据库名用反引号
`包裹,避免与MySQL关键字冲突(如user、order等)。
2. 删除数据库
语法:
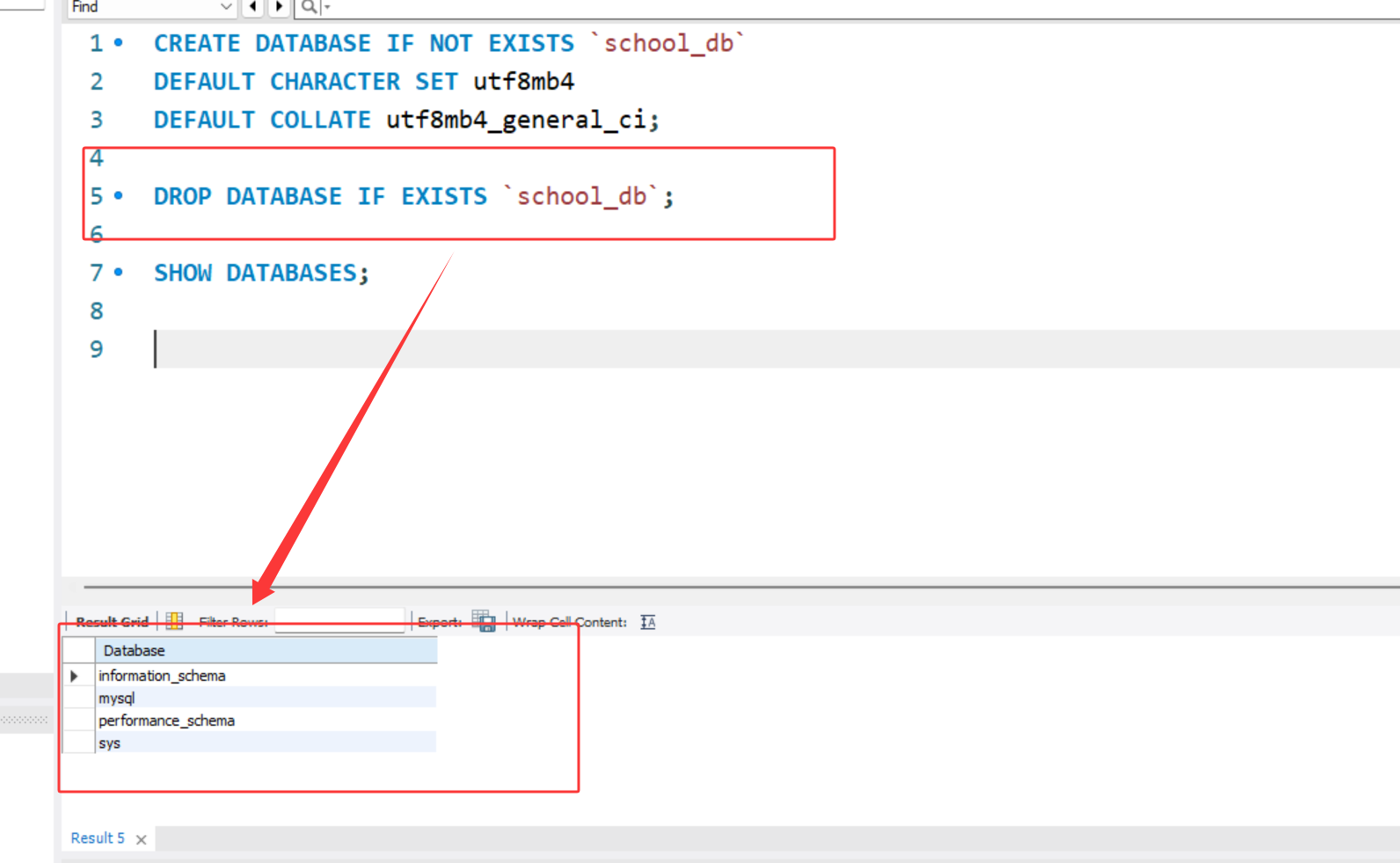
DROP DATABASE [IF EXISTS] `数据库名`;
示例:
DROP DATABASE IF EXISTS `school_db`;
详细讲解:
DROP DATABASE会彻底删除数据库及其中的所有表和数据,操作不可逆,务必谨慎。IF EXISTS:可选参数,若数据库不存在,可避免报错(仅提示警告)。执行前建议备份数据,尤其是生产环境。
3. 选择数据库
语法:
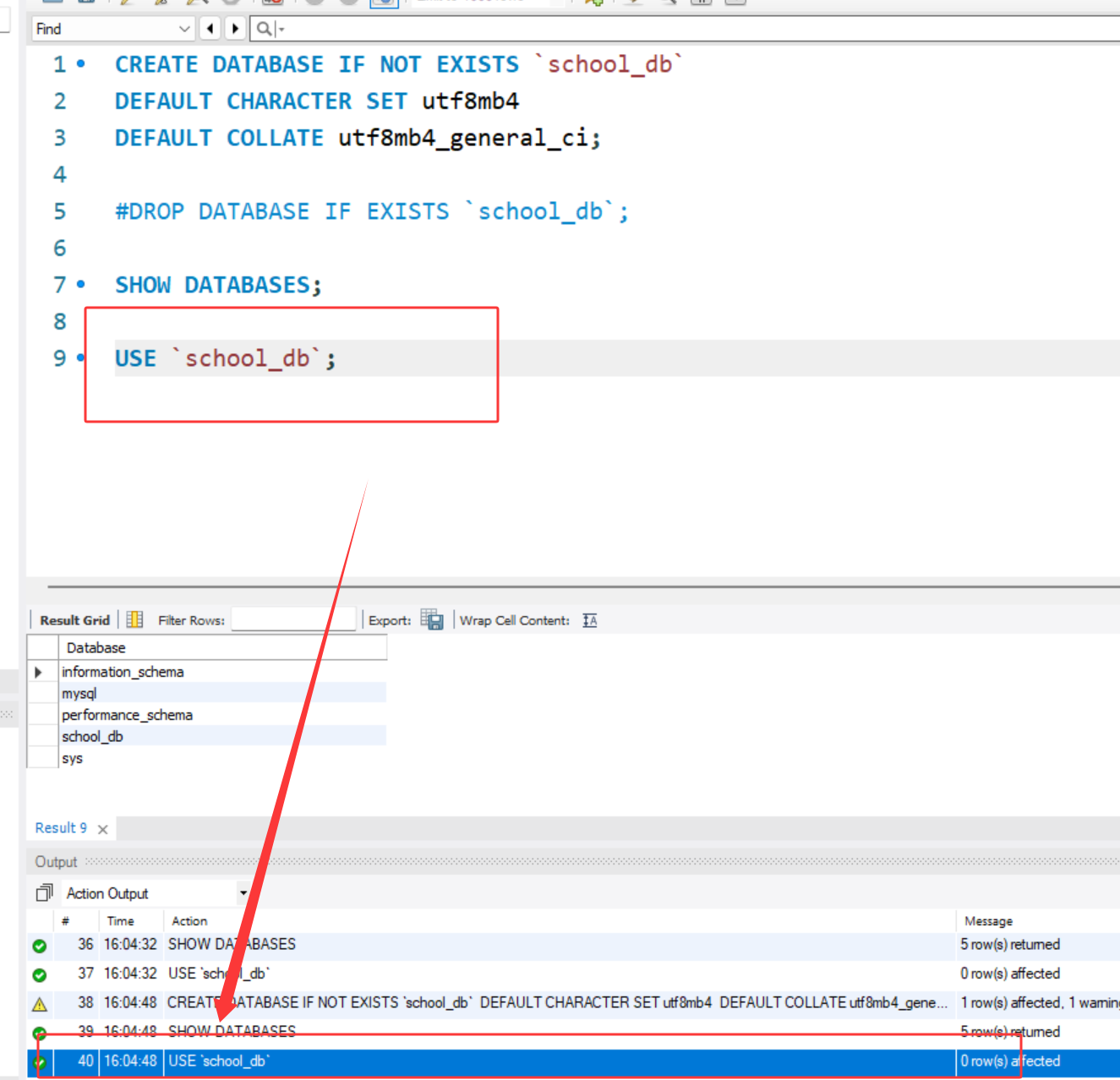
USE `数据库名`;
示例:
USE `school_db`;
详细讲解:
USE语句用于指定当前操作的数据库。MySQL中所有表操作(创建表、查询数据等)都需先指定数据库,否则会提示“未选择数据库”。执行后,后续所有SQL语句默认在该数据库中执行,直至再次使用
USE切换到其他数据库。
二、数据表操作
表是数据库中存储数据的基本单位,由字段(列)和记录(行)组成,以下是表的核心操作:
1. 创建表
语法:
CREATE TABLE [IF NOT EXISTS] `表名` (
`字段1` 数据类型 [约束] [COMMENT '注释'],
`字段2` 数据类型 [约束] [COMMENT '注释'],
...
[PRIMARY KEY (`字段名`)] -- 主键约束(可在字段后直接定义)
) ENGINE=存储引擎 DEFAULT CHARSET=字符集 COMMENT '表注释';
示例:
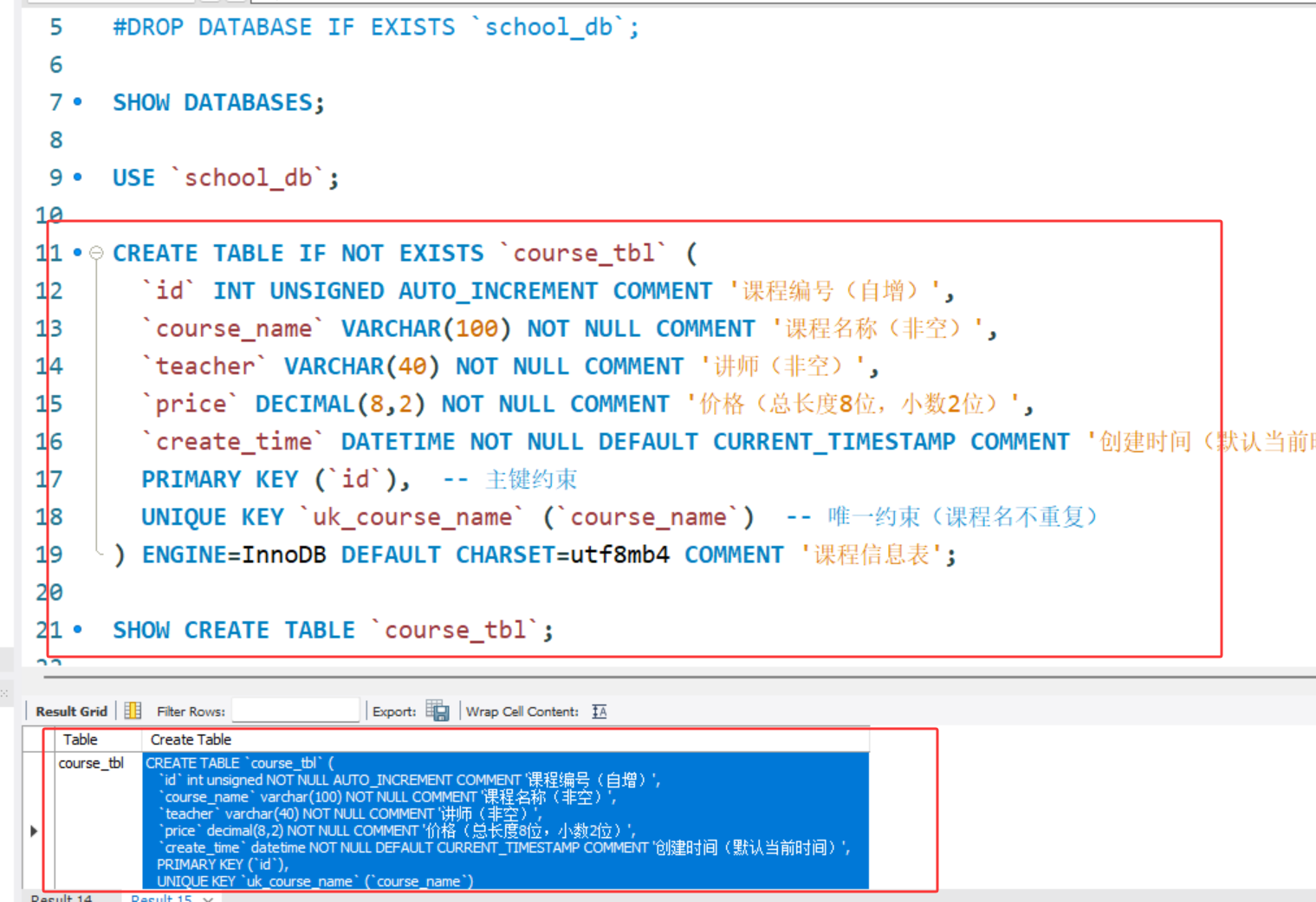
CREATE TABLE IF NOT EXISTS `course_tbl` (
`id` INT UNSIGNED AUTO_INCREMENT COMMENT '课程编号(自增)',
`course_name` VARCHAR(100) NOT NULL COMMENT '课程名称(非空)',
`teacher` VARCHAR(40) NOT NULL COMMENT '讲师(非空)',
`price` DECIMAL(8,2) NOT NULL COMMENT '价格(总长度8位,小数2位)',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间(默认当前时间)',
PRIMARY KEY (`id`), -- 主键约束
UNIQUE KEY `uk_course_name` (`course_name`) -- 唯一约束(课程名不重复)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '课程信息表';
详细讲解:
IF NOT EXISTS:避免表已存在时的创建报错,常用于脚本初始化。字段定义:
数据类型:需根据业务选择合适类型(如
INT存整数、VARCHAR存字符串、DECIMAL存金额等),避免浪费空间(如用TINYINT存年龄而非INT)。- 约束:
NOT NULL:字段不允许为空(强制数据完整性,避免NULL导致的查询歧义)。AUTO_INCREMENT:自增,需配合主键或唯一索引使用,常用于生成唯一ID。PRIMARY KEY:主键,唯一标识记录,一个表只能有一个主键(可组合主键),InnoDB表会自动基于主键创建聚簇索引。UNIQUE:唯一约束,确保字段值不重复(可多个,如course_name唯一)。DEFAULT:默认值(如create_time默认当前时间,用CURRENT_TIMESTAMP获取系统时间)。
- 约束:
存储引擎:
-InnoDB:支持事务、外键、行级锁,适合写操作频繁或需数据完整性的场景(MySQL 5.5+默认引擎)。
-MyISAM:不支持事务和外键,读性能好,适合只读场景(如日志表)。字符集:同数据库,推荐
utf8mb4以支持所有字符。
MySQL 数据类型
- MySQL中定义数据字段的类型对数据库的优化是非常重要的。
- MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型
数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
| 类型 | 大小 ( bytes) |
范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
2. 删除表
语法:
DROP TABLE [IF EXISTS] `表名`;
示例:
DROP TABLE IF EXISTS `course_tbl`;
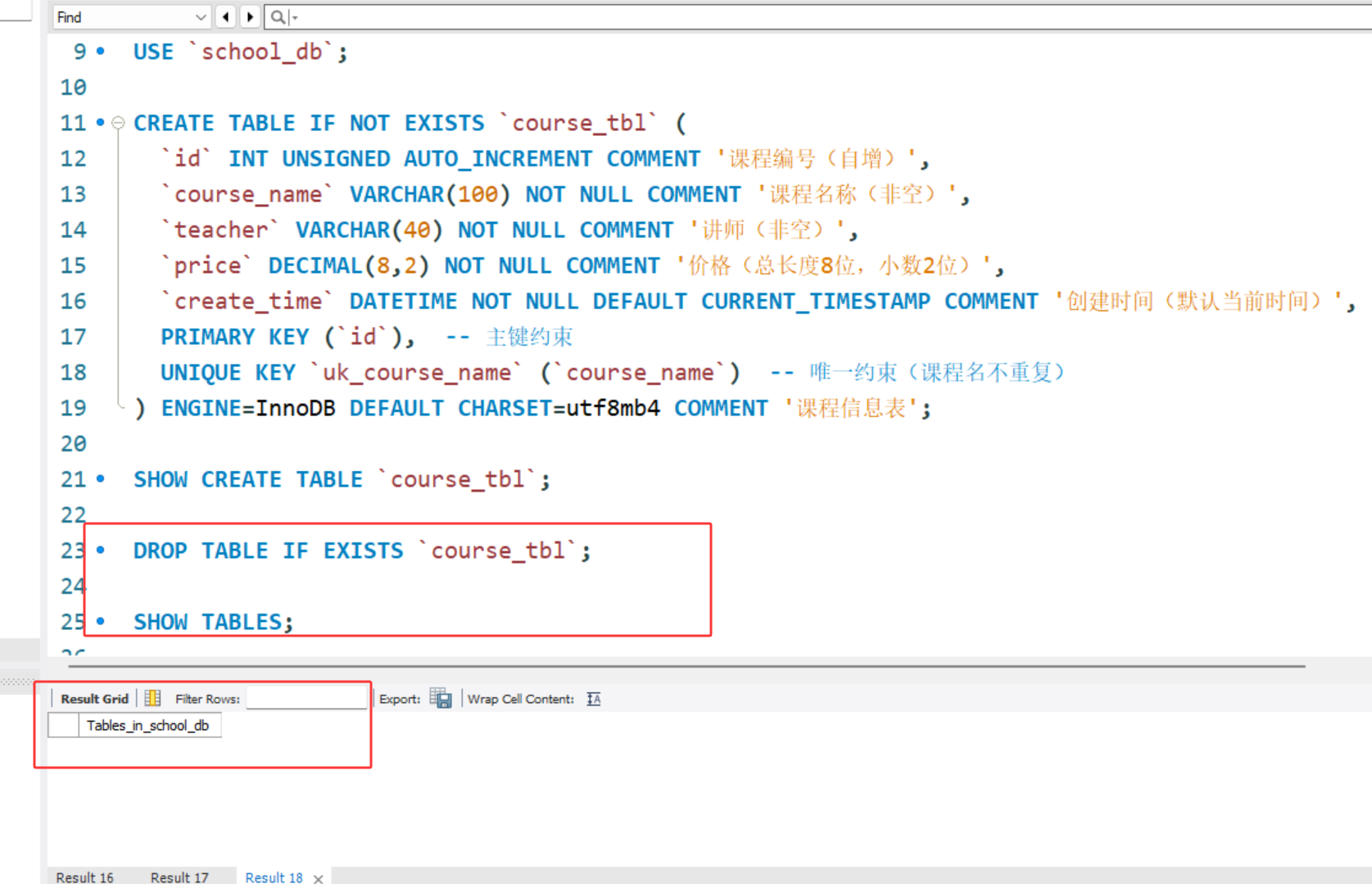
详细讲解:
DROP TABLE会彻底删除表结构及所有数据,不可逆,执行前需确认。IF EXISTS:表不存在时不报错,仅提示警告,适合脚本中清理历史表。
3. 清空表数据
清空表数据有两种常用方式:TRUNCATE TABLE和DELETE FROM,二者区别显著:
| 操作 | TRUNCATE TABLE 表名`` |
DELETE FROM 表名 [WHERE 条件] |
|---|---|---|
| 原理 | 以“页”为单位删除数据(快速清空,保留表结构) | 逐行删除数据(慢,尤其大数据量) |
| 自增主键 | 重置为初始值(如从1开始) | 不重置(继续从上次最大值自增) |
| 事务支持 | 不支持(DDL操作,执行后无法回滚) |
支持(DML操作,可在事务中回滚) |
| 日志 | 不写redo/undo日志(性能高) | 写日志(支持回滚,性能低) |
| 条件删除 | 不支持(只能清空全表) | 支持WHERE条件(删除部分数据) |
| 权限要求 | 需要DROP权限 |
需要DELETE权限 |
示例:
-- 清空全表(快速,自增重置,不可回滚)
TRUNCATE TABLE `course_tbl`;
-- 清空全表(逐行删,自增不重置,可回滚)
DELETE FROM `course_tbl`;
-- 删除部分数据(如删除价格为0的课程)
DELETE FROM `course_tbl` WHERE `price` = 0;
使用场景:
- 若需快速清空全表且无需回滚(如测试环境重置),用
TRUNCATE。 - 若需删除部分数据或在事务中操作(如生产环境清理无效数据),用
DELETE。
三、数据操纵语言(DML)
DML用于操作表中数据,核心是INSERT(增)、UPDATE(改)、DELETE(删)。
1. 插入数据(INSERT)
语法:
-- 指定字段插入(推荐,不依赖表结构顺序)
INSERT INTO `表名` (`字段1`, `字段2`, ...)
VALUES (值1, 值2, ...);
-- 批量插入(高效,减少IO)
INSERT INTO `表名` (`字段1`, `字段2`, ...)
VALUES
(值1-1, 值1-2, ...),
(值2-1, 值2-2, ...),
...;
示例:
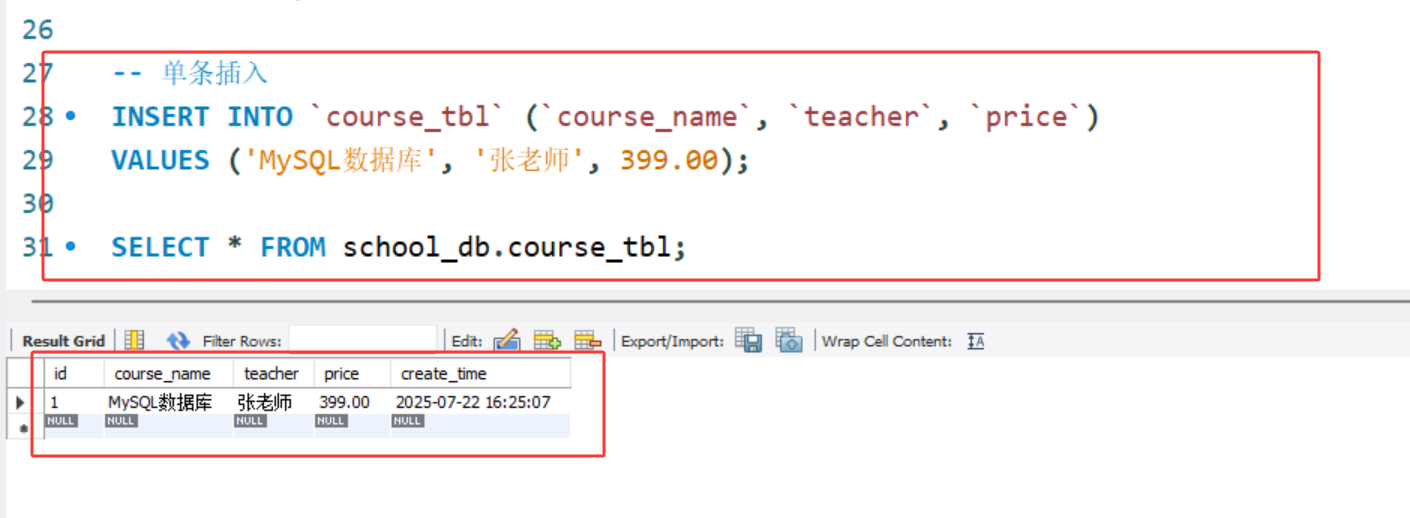
-- 单条插入
INSERT INTO `course_tbl` (`course_name`, `teacher`, `price`)
VALUES ('MySQL数据库', '张老师', 399.00);
-- 批量插入(推荐,比多条单插效率高)
INSERT INTO `course_tbl` (`course_name`, `teacher`, `price`)
VALUES
('Python编程', '李老师', 499.00),
('Java开发', '王老师', 599.00);
详细讲解:
指定字段:避免表新增字段后插入报错(若不指定字段,需按表字段顺序传入所有值,包括自增主键和默认值字段)。
值的类型:需与字段类型匹配(如字符串用单引号包裹、日期格式符合
YYYY-MM-DD HH:MM:SS)。批量插入:减少与数据库的交互次数(一次IO插入多条),适合初始化数据或批量导入,是优化插入性能的常用手段。
单条插入:
批量插入:

2. 更新数据(UPDATE)
语法:
UPDATE `表名`
SET `字段1` = 新值1, `字段2` = 新值2, ...
[WHERE 条件]; -- 必须加条件,否则更新全表!
示例:
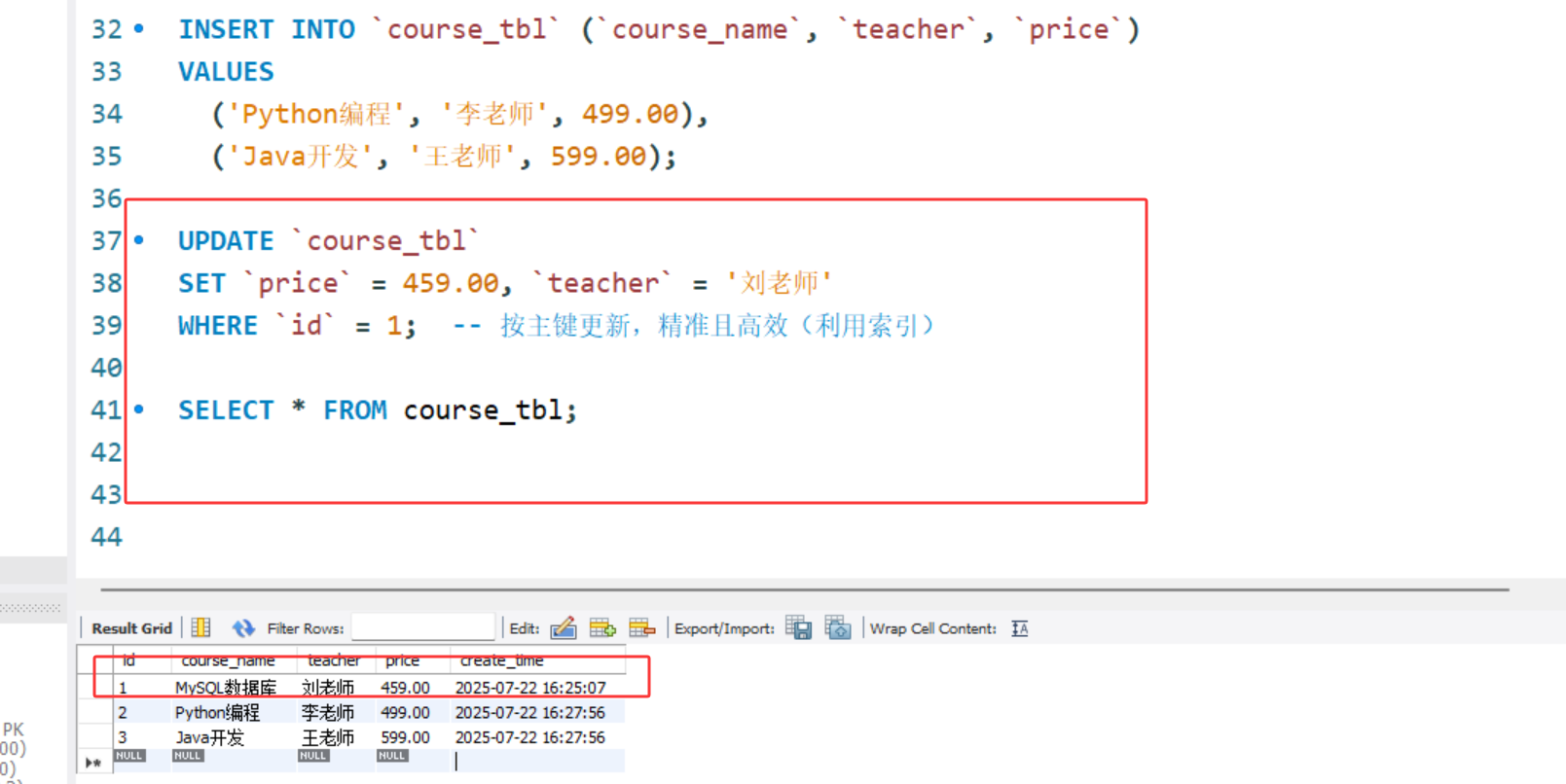
-- 修改单条记录(更新课程价格)
UPDATE `course_tbl`
SET `price` = 459.00, `teacher` = '刘老师'
WHERE `id` = 1; -- 按主键更新,精准且高效(利用索引)
-- 批量更新(如所有课程涨价10%)
UPDATE `course_tbl`
SET `price` = `price` * 1.1
WHERE `create_time` > '2023-01-01'; -- 仅更新2023年后的课程
详细讲解:
WHERE条件:核心! 若省略,将更新表中所有记录(生产环境中可能导致数据灾难),务必检查条件是否正确。- 更新逻辑:支持字段间计算(如
price = price * 1.1)、调用函数(如update_time = NOW())。 - 性能:更新时尽量基于索引字段(如主键
id)过滤,减少扫描行数(否则可能全表扫描,锁表时间长)。
修改单条记录
批量修改
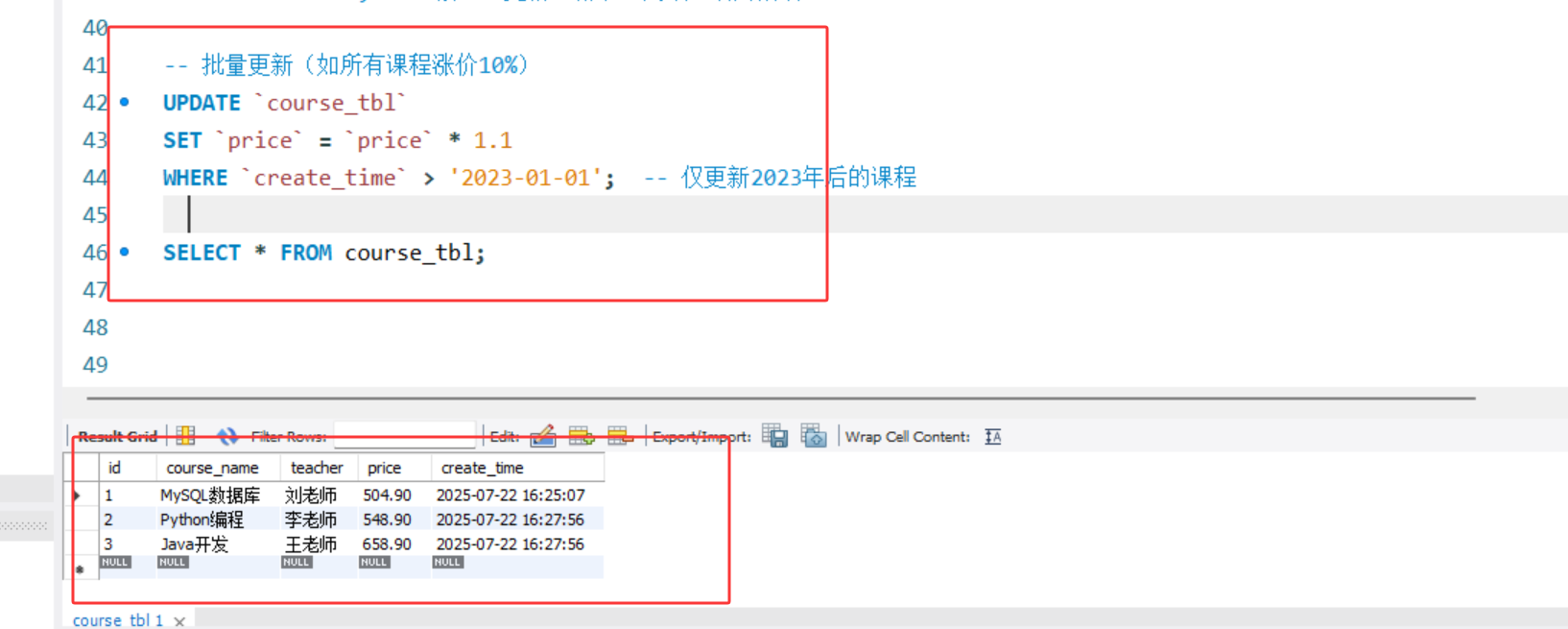
3. 删除数据(DELETE)
语法:
DELETE FROM `表名` [WHERE 条件]; -- 必须加条件,否则删除全表!
示例:
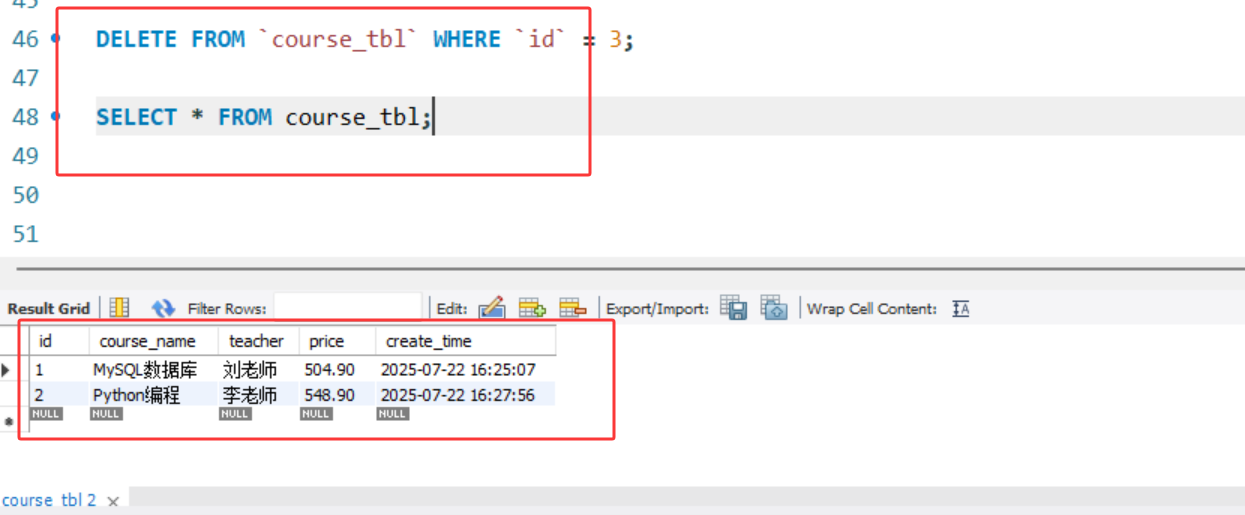
-- 删除单条记录(按主键删除,高效)
DELETE FROM `course_tbl` WHERE `id` = 3;
-- 删除批量记录(如删除已下架的课程)
DELETE FROM `course_tbl` WHERE `status` = 'deleted' AND `create_time` < '2022-01-01';
详细讲解:
WHERE条件:同UPDATE,必须明确,避免误删全表。- 事务与回滚:
DELETE是DML操作,可在事务中执行(如BEGIN; DELETE ...; ROLLBACK;),适合需要确认后再提交的场景(如生产环境删除)。 - 性能:大量数据删除时,
DELETE逐行删效率低(写日志、触发触发器),可分批次删除(如LIMIT 1000每次删1000条),避免长时间锁表。
删除单条记录
四、数据查询语言(DQL):查询
SELECT是SQL中最复杂也最核心的操作,用于从表中获取数据,支持多种过滤、聚合、关联方式。
1. 基础查询
语法:
SELECT [DISTINCT] 字段1 [AS 别名1], 字段2 [AS 别名2], ...
FROM `表名` [AS 表别名];
示例:
-- 查询所有字段(不推荐,依赖表结构,性能差)
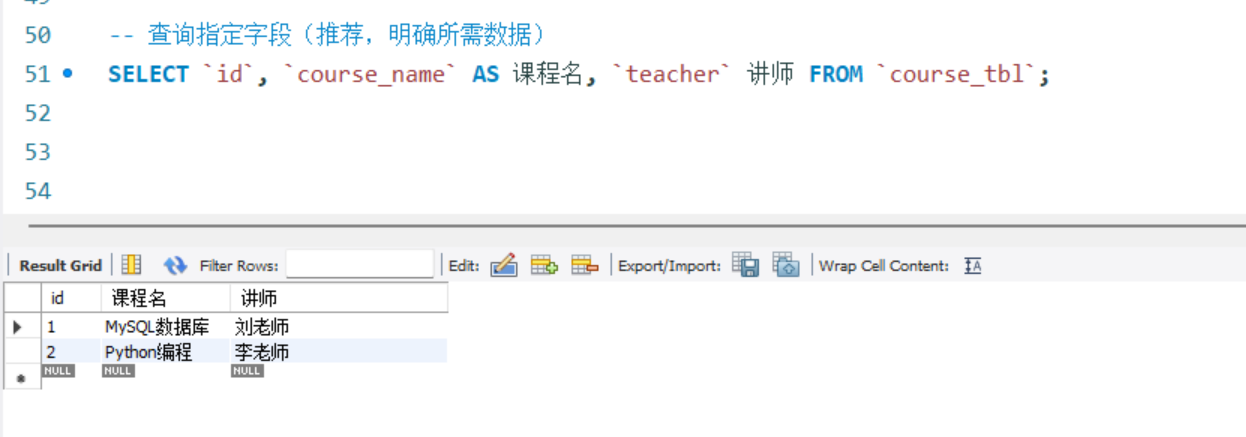
SELECT * FROM `course_tbl`;
-- 查询指定字段(推荐,明确所需数据)
SELECT `id`, `course_name` AS 课程名, `teacher` 讲师 FROM `course_tbl`;
-- 去重查询(如查询所有讲师,不重复)
SELECT DISTINCT `teacher` FROM `course_tbl`;
详细讲解:
SELECT *:不推荐,原因:① 若表新增字段,会多余返回不需要的数据(浪费带宽);② 不明确所需字段,代码可读性差;③ 无法利用“覆盖索引”优化查询性能。别名(
AS):简化字段名或表名(AS可省略),尤其多表查询时(如course_tbl AS c)。DISTINCT:对查询结果去重(作用于所有字段,而非单个,如SELECT DISTINCT a, b会对a+b的组合去重)。
2. 条件查询(WHERE)
通过WHERE指定过滤条件,支持多种运算符,精准筛选数据。
常用运算符:
| 类型 | 运算符/关键字 | 说明 |
|---|---|---|
| 比较运算 | =、!=/<>、>、<等 |
基本比较(如price > 500) |
| 逻辑运算 | AND、OR、NOT |
组合条件(如price > 500 AND teacher = '张老师') |
| 范围查询 | IN、NOT IN |
匹配列表中的值(如id IN (1,2,3)) |
| 范围查询 | BETWEEN ... AND ... |
匹配区间(含边界,如price BETWEEN 300 AND 600) |
| 模糊查询 | LIKE |
通配符匹配(%任意字符,_单个字符) |
| 空值判断 | IS NULL、IS NOT NULL |
判断NULL(不能用=或!=,NULL不与任何值相等) |
示例:
-- 比较+逻辑运算(查询张老师的价格>500的课程)
SELECT `course_name`, `price`
FROM `course_tbl`
WHERE `teacher` = '张老师' AND `price` > 500;
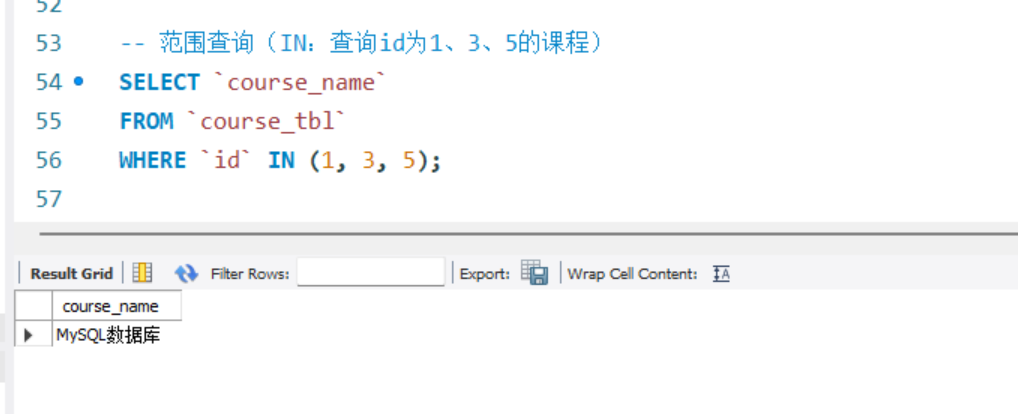
-- 范围查询(IN:查询id为1、3、5的课程)
SELECT `course_name`
FROM `course_tbl`
WHERE `id` IN (1, 3, 5);
-- 范围查询(BETWEEN:查询价格300-600的课程)
SELECT `course_name`, `price`
FROM `course_tbl`
WHERE `price` BETWEEN 300 AND 600; -- 等效于 price >= 300 AND price <= 600
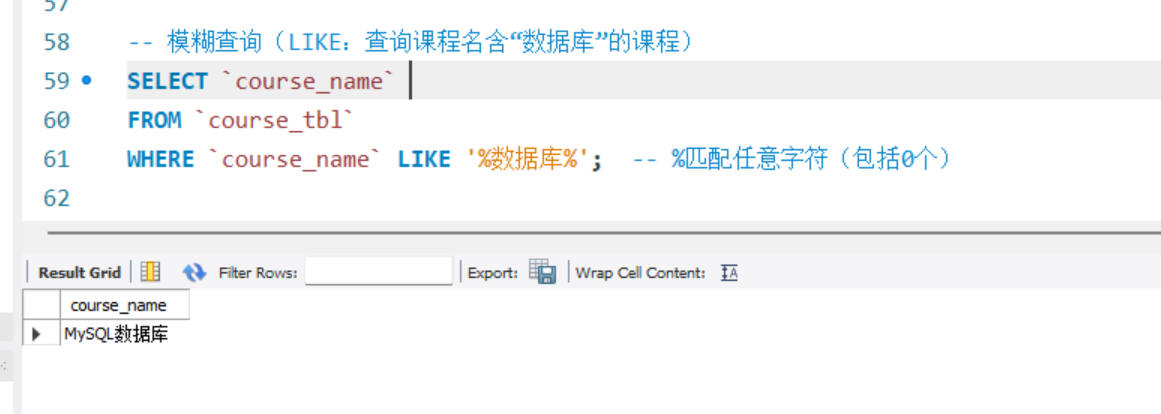
-- 模糊查询(LIKE:查询课程名含“数据库”的课程)
SELECT `course_name`
FROM `course_tbl`
WHERE `course_name` LIKE '%数据库%'; -- %匹配任意字符(包括0个)
-- 模糊查询(_:查询课程名第二个字是“据”的课程,如“数据库”“数据结构”)
SELECT `course_name`
FROM `course_tbl`
WHERE `course_name` LIKE '_据%'; -- _匹配单个字符
-- 空值判断(查询未设置讲师的课程,假设teacher可为空)
SELECT `course_name`
FROM `course_tbl`
WHERE `teacher` IS NULL; -- 注意:不能用 teacher = NULL
注意:
LIKE '%xxx'(前缀模糊)会导致索引失效(全表扫描),若需优化,可考虑全文索引(FULLTEXT)。NULL处理:NULL表示“未知”,而非“空字符串”(''),二者不同(如teacher IS NULL与teacher = ''是两个条件)。
范围查询:
模糊查询:
3. 排序查询(ORDER BY)
语法:
SELECT 字段...
FROM `表名`
[WHERE 条件]
ORDER BY 字段1 [ASC|DESC], 字段2 [ASC|DESC], ...;
示例:
-- 按价格升序(默认ASC,从低到高)
SELECT `course_name`, `price`
FROM `course_tbl`
ORDER BY `price`;
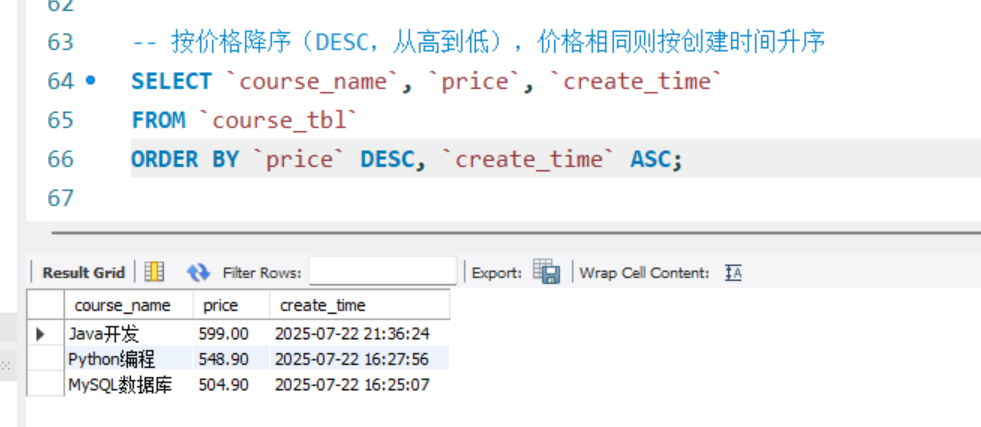
-- 按价格降序(DESC,从高到低),价格相同则按创建时间升序
SELECT `course_name`, `price`, `create_time`
FROM `course_tbl`
ORDER BY `price` DESC, `create_time` ASC;
详细讲解:
ASC:升序(默认,可省略);DESC:降序。- 多字段排序:先按第一个字段排序,若值相同,再按第二个字段排序(如电商中“按销量降序,再按价格升序”)。
- 性能:
ORDER BY会触发排序操作(内存或磁盘),若基于索引字段排序(如id是主键,有序),可避免额外排序(利用索引有序性)。
排序查询:
4. 分页查询(LIMIT)
用于限制返回结果数量(如分页展示列表数据)。
语法:
SELECT 字段...
FROM `表名`
[WHERE 条件]
[ORDER BY 字段]
LIMIT [偏移量,] 条数; -- 偏移量:从第几条开始(0-based,默认0)
示例:
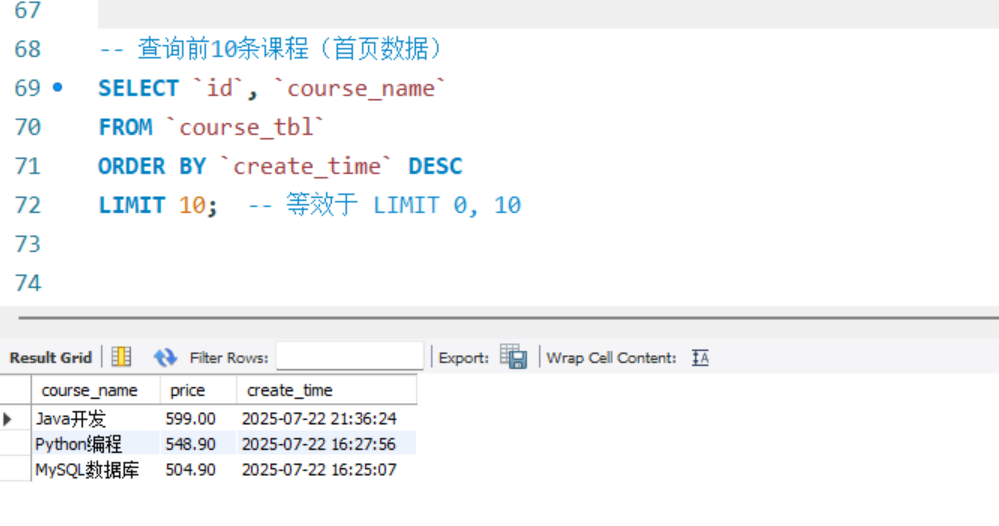
-- 查询前10条课程(首页数据)
SELECT `id`, `course_name`
FROM `course_tbl`
ORDER BY `create_time` DESC
LIMIT 10; -- 等效于 LIMIT 0, 10
-- 查询第2页数据(每页10条,即第11-20条)
SELECT `id`, `course_name`
FROM `course_tbl`
ORDER BY `create_time` DESC
LIMIT 10, 10; -- 偏移量10(跳过前10条),取10条
详细讲解:
- 偏移量计算:第
n页(从1开始)的数据,偏移量 =(n-1) * 每页条数。 - 性能:当偏移量很大时(如
LIMIT 100000, 10),会扫描前100010条数据再取最后10条,效率低。优化方案:用“索引定位”(如WHERE id > 100000 LIMIT 10,需id有序)。
分页查询:
5. 聚合查询(聚合函数 + GROUP BY)
聚合函数用于对数据进行统计(如求和、平均值),常与GROUP BY结合实现分组统计。
常用聚合函数:
| 函数 | 说明 |
|---|---|
COUNT(*) |
统计行数(包括NULL) |
COUNT(字段) |
统计字段非NULL的行数 |
SUM(字段) |
求和(仅数值型) |
AVG(字段) |
求平均值(仅数值型) |
MAX(字段) |
求最大值 |
MIN(字段) |
求最小值 |
GROUP BY语法:
SELECT 分组字段, 聚合函数(字段) [AS 别名]...
FROM `表名`
[WHERE 条件]
GROUP BY 分组字段1, 分组字段2...
[HAVING 聚合条件]; -- 筛选分组结果(替代WHERE,因WHERE不能用聚合函数)
示例:
假设有score_tbl(成绩表):id、student_id(学生ID)、course_id(课程ID)、score(分数)。
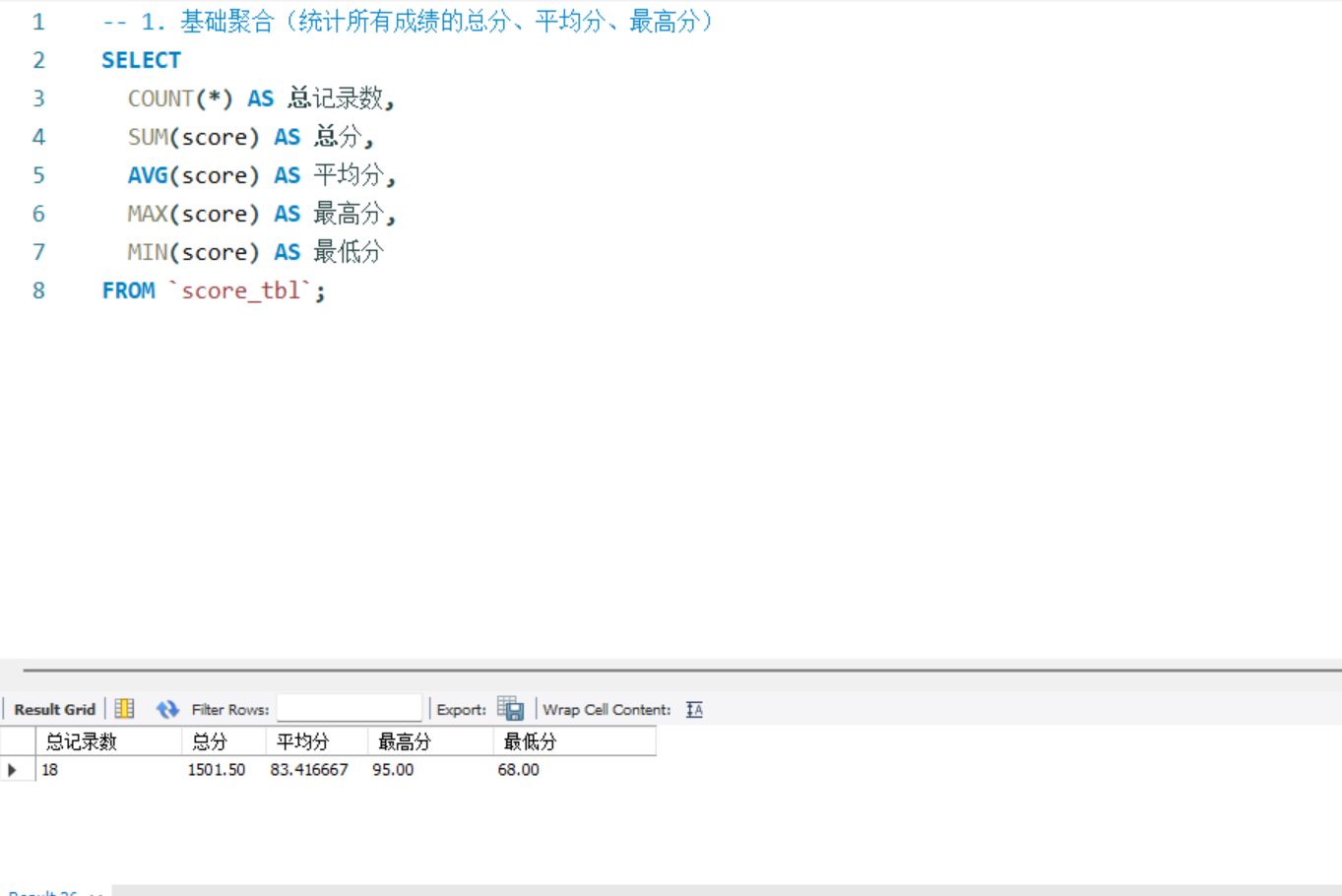
-- 1. 基础聚合(统计所有成绩的总分、平均分、最高分)
SELECT
COUNT(*) AS 总记录数,
SUM(score) AS 总分,
AVG(score) AS 平均分,
MAX(score) AS 最高分,
MIN(score) AS 最低分
FROM `score_tbl`;
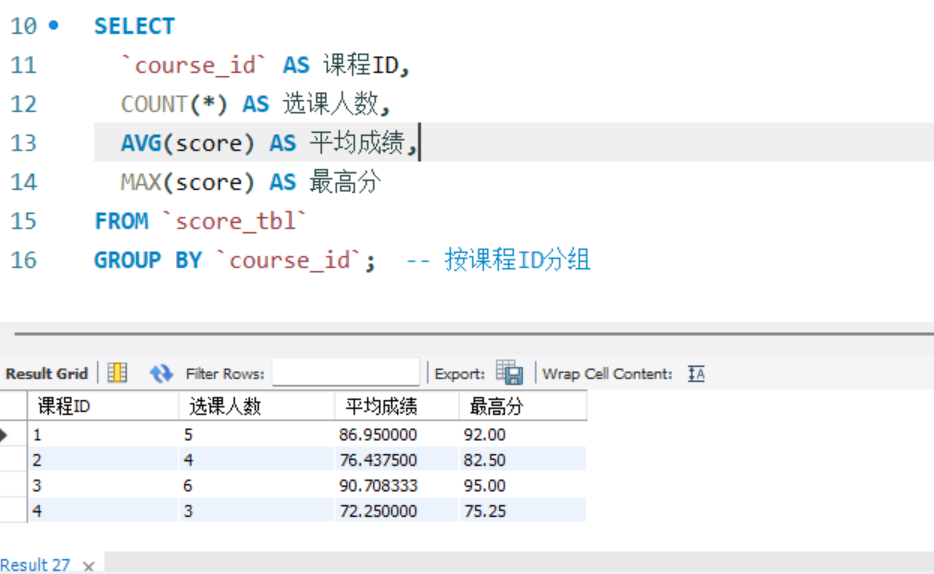
-- 2. 分组聚合(按课程ID分组,统计每门课的成绩情况)
SELECT
`course_id` AS 课程ID,
COUNT(*) AS 选课人数,
AVG(score) AS 平均成绩,
MAX(score) AS 最高分
FROM `score_tbl`
GROUP BY `course_id`; -- 按课程ID分组
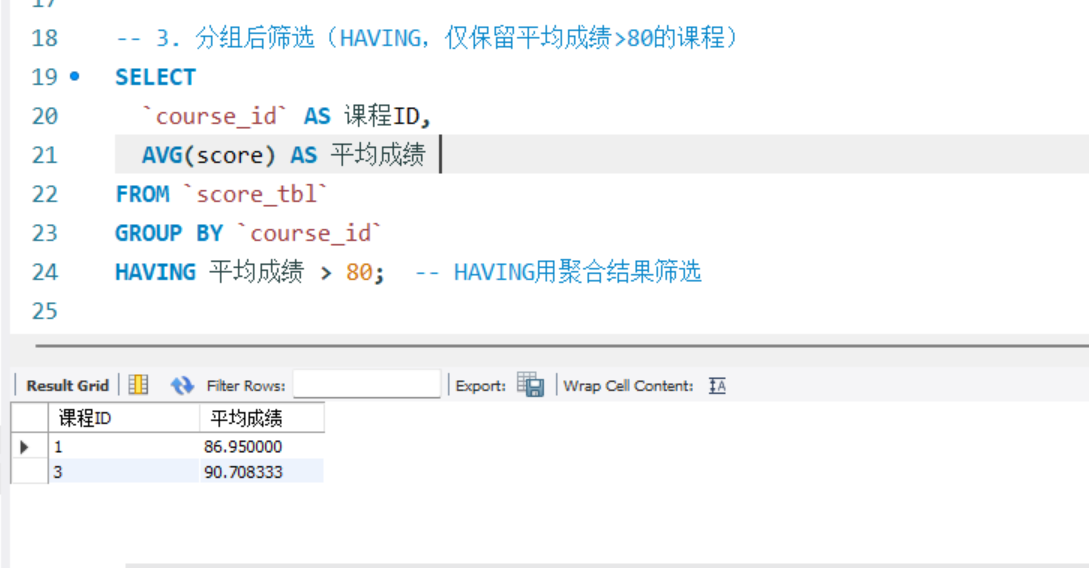
-- 3. 分组后筛选(HAVING,仅保留平均成绩>80的课程)
SELECT
`course_id` AS 课程ID,
AVG(score) AS 平均成绩
FROM `score_tbl`
GROUP BY `course_id`
HAVING 平均成绩 > 80; -- HAVING用聚合结果筛选
WHERE与HAVING的区别:
WHERE:在分组前筛选行(作用于原始数据),不能使用聚合函数(如WHERE AVG(score) > 80错误)。HAVING:在分组后筛选分组结果(作用于聚合后的分组),可使用聚合函数(如HAVING AVG(score) > 80)。
创建一个score_tbl,并且插入一些数据用于测试
-- 创建成绩表
CREATE TABLE IF NOT EXISTS `score_tbl` (
`id` INT PRIMARY KEY AUTO_INCREMENT COMMENT '成绩记录ID',
`student_id` INT NOT NULL COMMENT '学生ID',
`course_id` INT NOT NULL COMMENT '课程ID',
`score` DECIMAL(5,2) NOT NULL COMMENT '分数(满分100)'
COMMENT '学生成绩表'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入测试数据
INSERT INTO `score_tbl` (`student_id`, `course_id`, `score`) VALUES
-- 课程1的成绩(5名学生)
(1, 1, 85.50),
(2, 1, 92.00),
(3, 1, 78.75),
(4, 1, 90.00),
(5, 1, 88.50),
-- 课程2的成绩(4名学生)
(1, 2, 76.00),
(2, 2, 82.50),
(3, 2, 68.00),
(6, 2, 79.25),
-- 课程3的成绩(6名学生)
(1, 3, 95.00),
(4, 3, 89.50),
(5, 3, 91.75),
(6, 3, 87.00),
(7, 3, 93.00),
(8, 3, 88.00),
-- 课程4的成绩(3名学生)
(2, 4, 72.50),
(5, 4, 69.00),
(7, 4, 75.25);
统计所有成绩的总分、平均分、最高分:
分组后统计成绩的总分、平均分、最高分:
分组并筛选后统计平均成绩:
6. 联表查询(多表关联)
当数据分布在多个表中时(如用户表和订单表),需通过联表查询关联数据(核心是“外键”关联,即表间的字段对应关系)。
常见联表类型:
| 连接类型 | 语法 | 说明 |
|---|---|---|
内连接(INNER JOIN) |
A INNER JOIN B ON A.字段 = B.字段 |
只返回两表中匹配的记录(交集) |
左连接(LEFT JOIN) |
A LEFT JOIN B ON A.字段 = B.字段 |
返回左表所有记录 + 右表匹配记录(右表无匹配则为NULL) |
右连接(RIGHT JOIN) |
A RIGHT JOIN B ON A.字段 = B.字段 |
返回右表所有记录 + 左表匹配记录(左表无匹配则为NULL) |
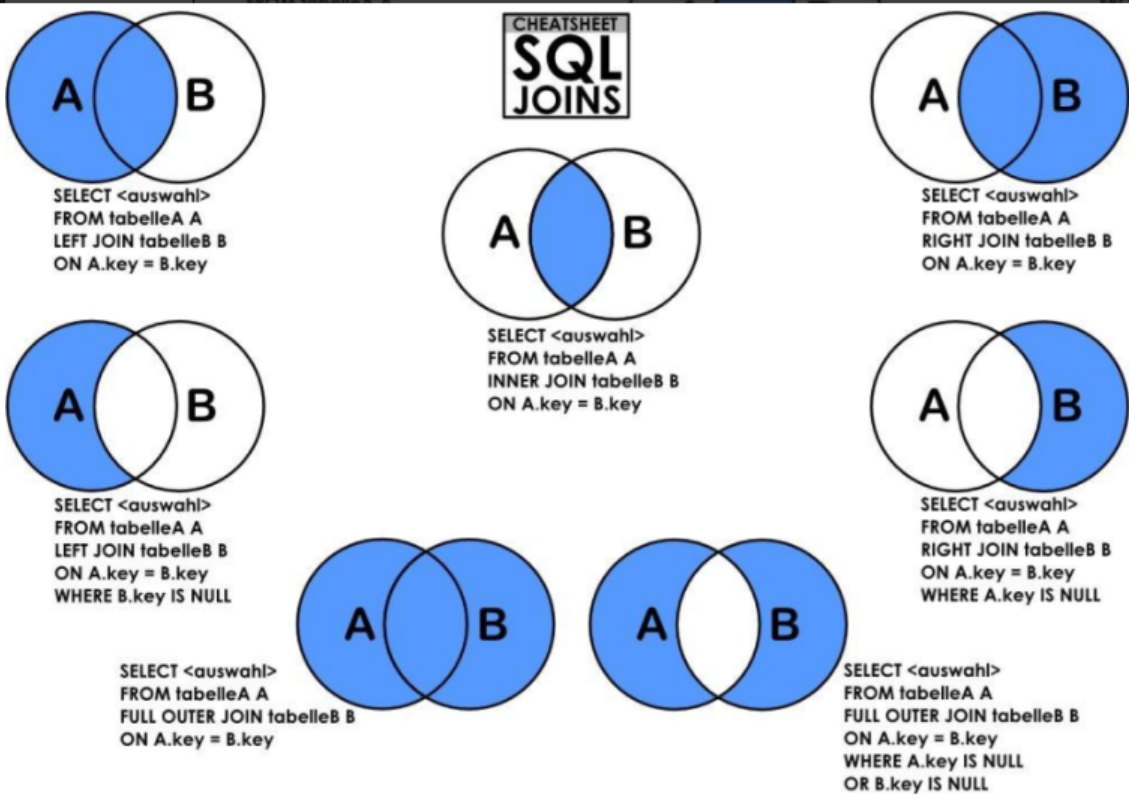
示例:
假设有:
course_tbl(课程表):id(课程ID)、course_name、teacher_id(讲师ID,外键)。teacher_tbl(讲师表):id(讲师ID)、teacher_name、major(专业)。
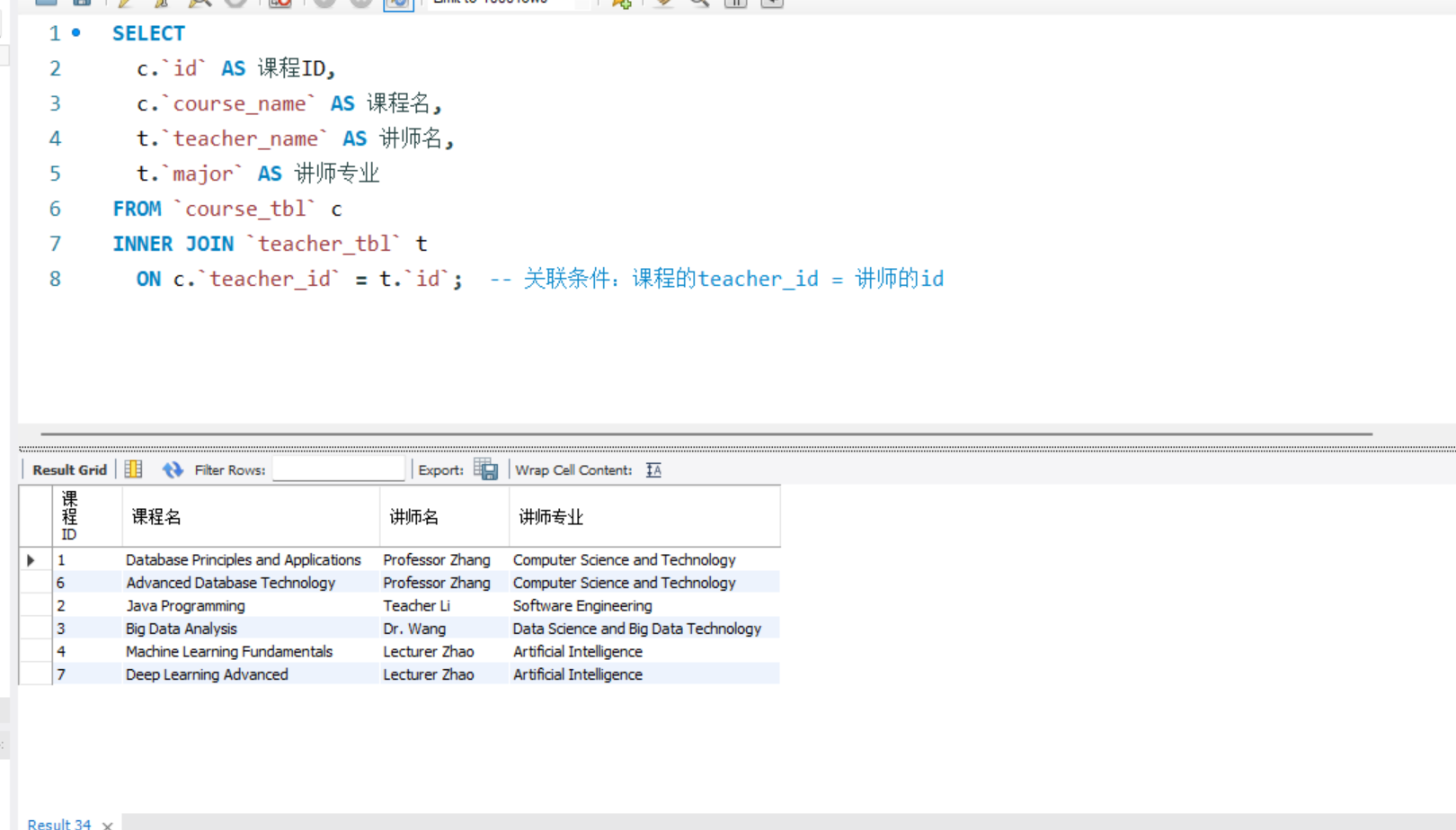
-- 1. 内连接(查询有对应讲师的课程及讲师信息)
SELECT
c.`id` AS 课程ID,
c.`course_name` AS 课程名,
t.`teacher_name` AS 讲师名,
t.`major` AS 讲师专业
FROM `course_tbl` c
INNER JOIN `teacher_tbl` t
ON c.`teacher_id` = t.`id`; -- 关联条件:课程的teacher_id = 讲师的id
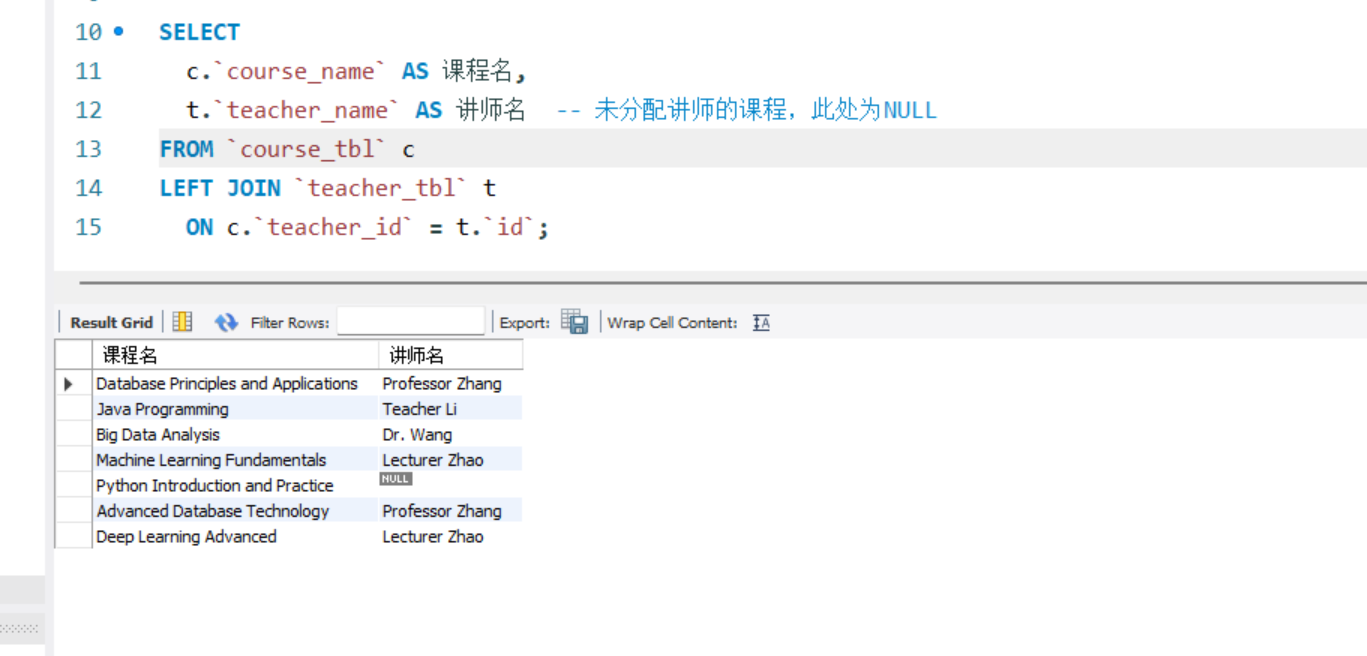
--2. 左连接(查询所有课程,包括未分配讲师的课程)
SELECT
c.`course_name` AS 课程名,
t.`teacher_name` AS 讲师名 -- 未分配讲师的课程,此处为NULL
FROM `course_tbl` c
LEFT JOIN `teacher_tbl` t
ON c.`teacher_id` = t.`id`;
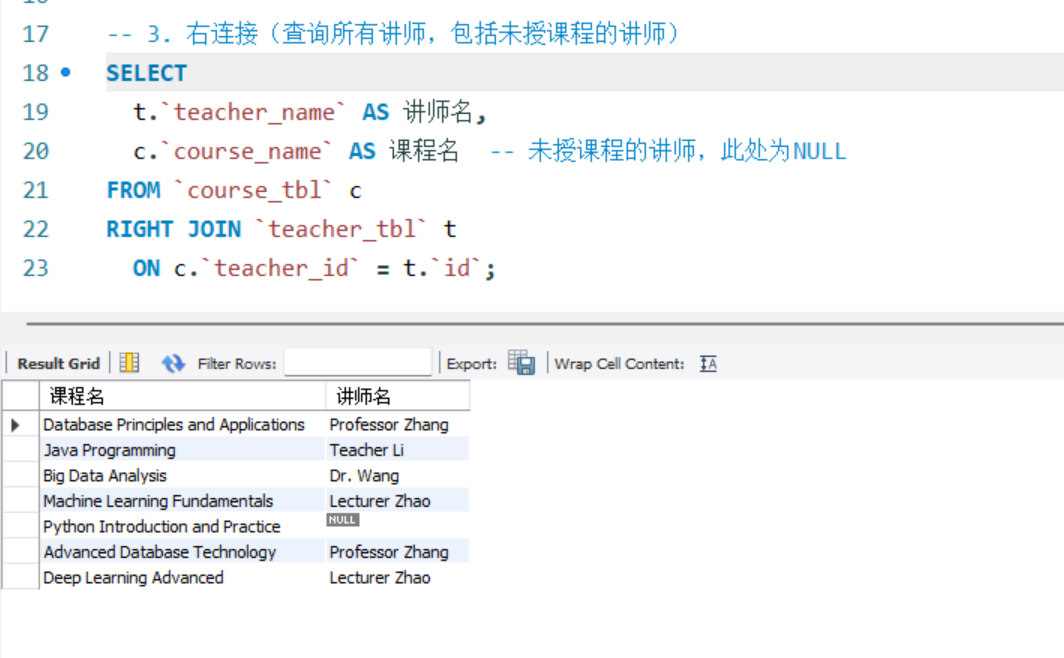
-- 3. 右连接(查询所有讲师,包括未授课程的讲师)
SELECT
t.`teacher_name` AS 讲师名,
c.`course_name` AS 课程名 -- 未授课程的讲师,此处为NULL
FROM `course_tbl` c
RIGHT JOIN `teacher_tbl` t
ON c.`teacher_id` = t.`id`;
注意:
- 联表查询需明确
ON关联条件,否则会产生“笛卡尔积”(两表行数相乘,数据爆炸)。 - 多表联表时,建议用表别名简化(如
c代表course_tbl),避免字段名冲突(如两表都有id,需用c.id区分)。
创建一个teacher_tbl和cource_tbl用于测试
CREATE table if not exists `teacher_tbl` (
`id` int primary key auto_increment,
`teacher_name` varchar(50) not null,
`major` varchar(100) not null
) engine=innodb default charset=utf8mb4;
create table if not exists `course_tbl` (
`id` int primary key auto_increment,
`course_name` varchar(100) not null,
`teacher_id` int,
constraint `fk_course_teacher` foreign key (`teacher_id`)
references `teacher_tbl` (`id`)
on delete set null
on update cascade
) engine=innodb default charset=utf8mb4;
insert into `teacher_tbl` (`teacher_name`, `major`) values
('Professor Zhang', 'Computer Science and Technology'),
('Teacher Li', 'Software Engineering'),
('Dr. Wang', 'Data Science and Big Data Technology'),
('Lecturer Zhao', 'Artificial Intelligence'),
('Teacher Chen', 'Network Engineering');
insert into `course_tbl` (`course_name`, `teacher_id`) values
('Database Principles and Applications', 1),
('Java Programming', 2),
('Big Data Analysis', 3),
('Machine Learning Fundamentals', 4),
('Python Introduction and Practice', null),
('Advanced Database Technology', 1),
('Deep Learning Advanced', 4);
内连接(查询有对应讲师的课程及讲师信息):
左连接(查询所有课程,包括未分配讲师的课程):
右连接(查询所有讲师,包括未授课程的讲师):
7. 子查询(嵌套查询)
子查询是嵌套在其他查询中的查询,用于复杂逻辑(如“查询成绩高于平均分的学生”)。
分类:
- 单行子查询:返回单行单列(用
=、>等比较)。 - 多行子查询:返回多行(用
IN、ANY、ALL等)。 - 子查询作为数据源:子查询结果作为临时表(
FROM后)。
示例:
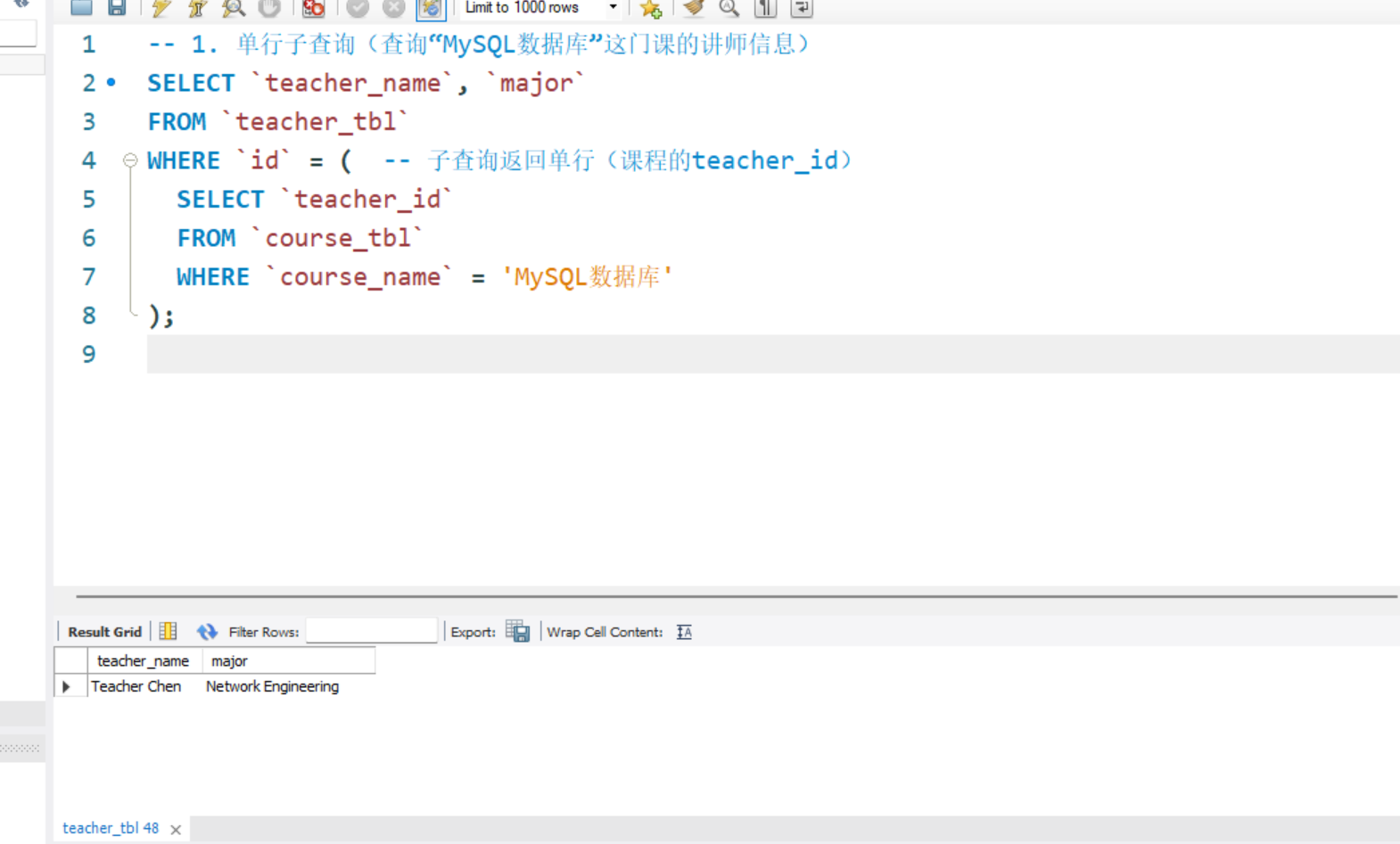
-- 1. 单行子查询(查询“MySQL数据库”这门课的讲师信息)
SELECT `teacher_name`, `major`
FROM `teacher_tbl`
WHERE `id` = ( -- 子查询返回单行(课程的teacher_id)
SELECT `teacher_id`
FROM `course_tbl`
WHERE `course_name` = 'MySQL数据库'
);
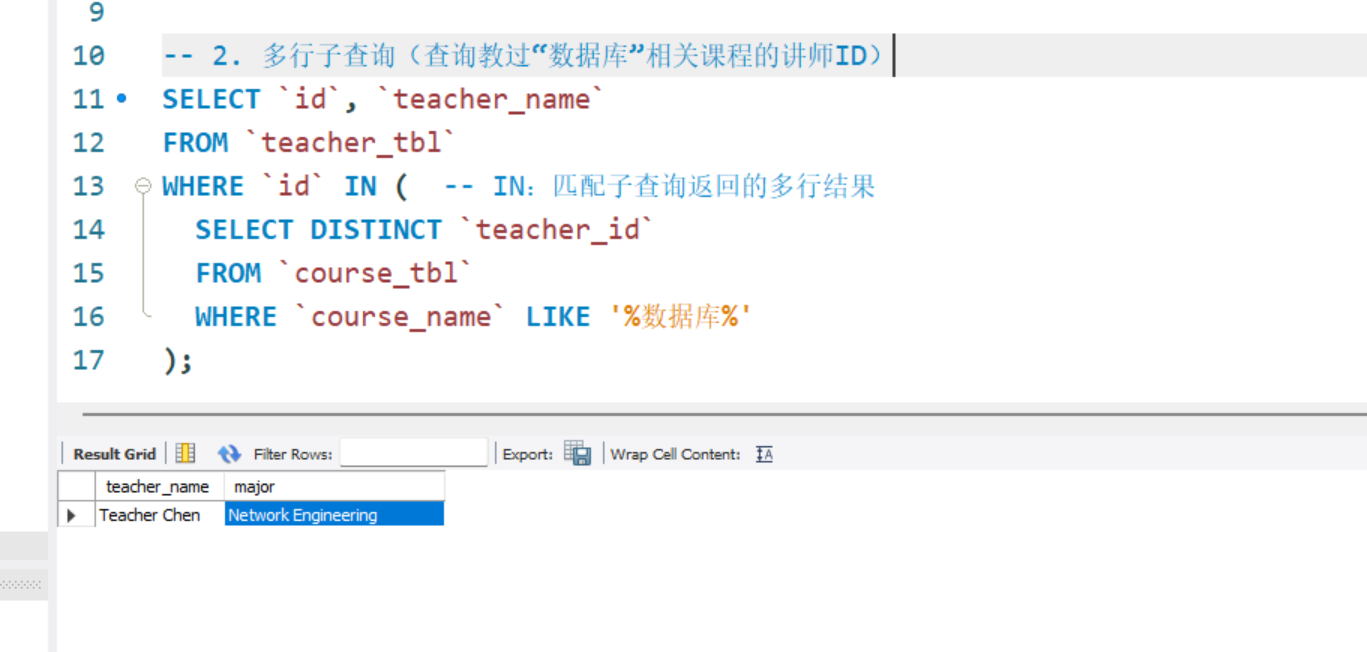
-- 2. 多行子查询(查询教过“数据库”相关课程的讲师ID)
SELECT `id`, `teacher_name`
FROM `teacher_tbl`
WHERE `id` IN ( -- IN:匹配子查询返回的多行结果
SELECT DISTINCT `teacher_id`
FROM `course_tbl`
WHERE `course_name` LIKE '%数据库%'
);
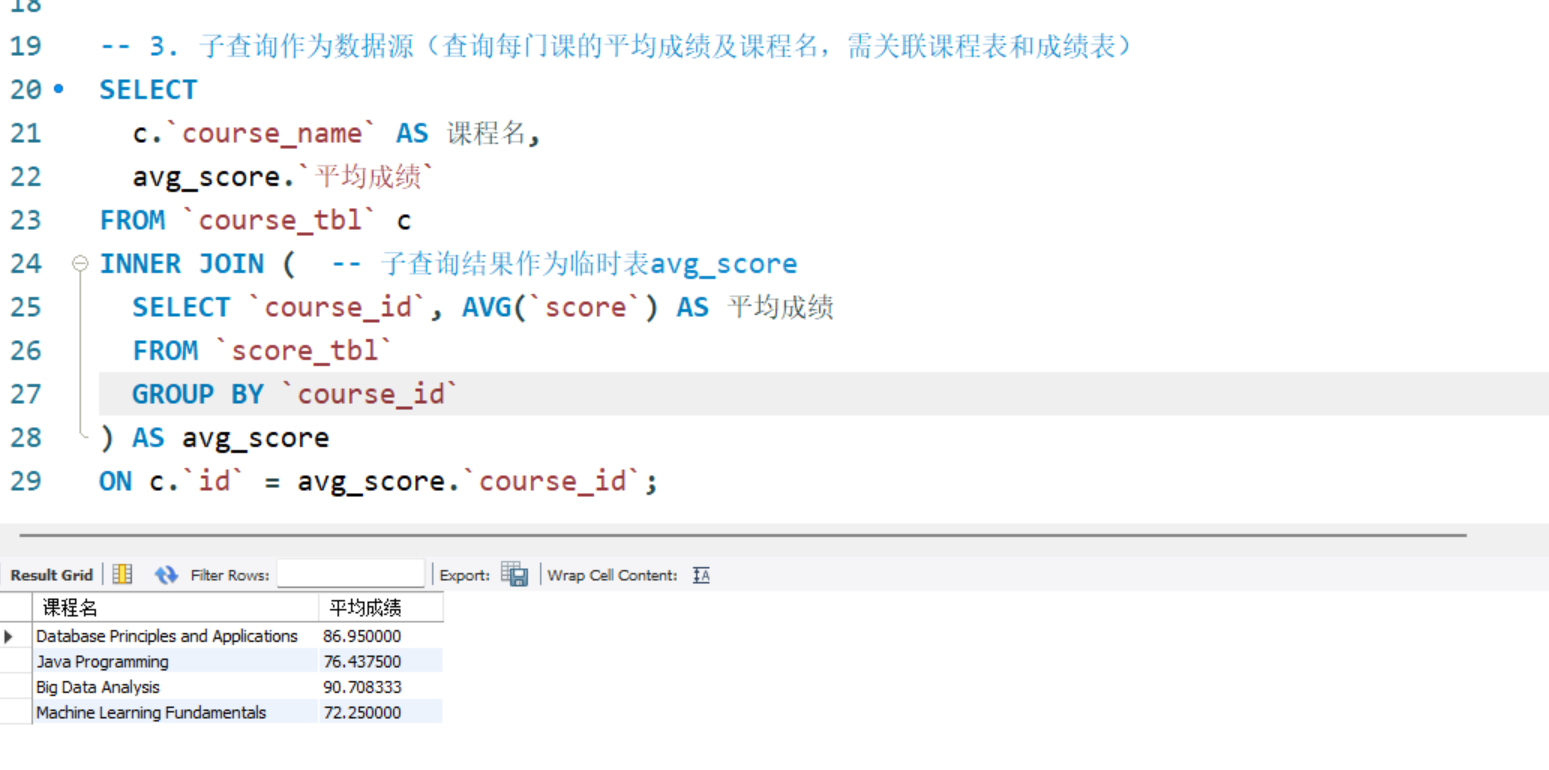
-- 3. 子查询作为数据源(查询每门课的平均成绩及课程名,需关联课程表和成绩表)
SELECT
c.`course_name` AS 课程名,
avg_score.`平均成绩`
FROM `course_tbl` c
INNER JOIN ( -- 子查询结果作为临时表avg_score
SELECT `course_id`, AVG(`score`) AS 平均成绩
FROM `score_tbl`
GROUP BY `course_id`
) AS avg_score
ON c.`id` = avg_score.`course_id`;
详细讲解:
- 子查询可简化复杂逻辑,但多层嵌套可能影响性能(需多次执行),简单场景可用联表查询替代。
EXISTS:子查询是否返回结果(存在则为TRUE),常用于“判断是否存在”(如SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE B.id = A.id)),效率有时高于IN(尤其子查询结果大时)。
单行子查询(查询“MySQL数据库”这门课的讲师信息):
多行子查询(查询教过“数据库”相关课程的讲师ID):
子查询作为数据源(查询每门课的平均成绩及课程名,需关联课程表和成绩表):
五、高级功能
1. 视图(VIEW)
定义:视图是虚拟表,其数据来自底层表(基表)的查询结果,本身不存储数据,仅保存查询逻辑。
语法:
CREATE [OR REPLACE] VIEW `视图名` AS
SELECT 字段...
FROM 表名...
[WHERE 条件] [GROUP BY ...] [JOIN ...];
示例:
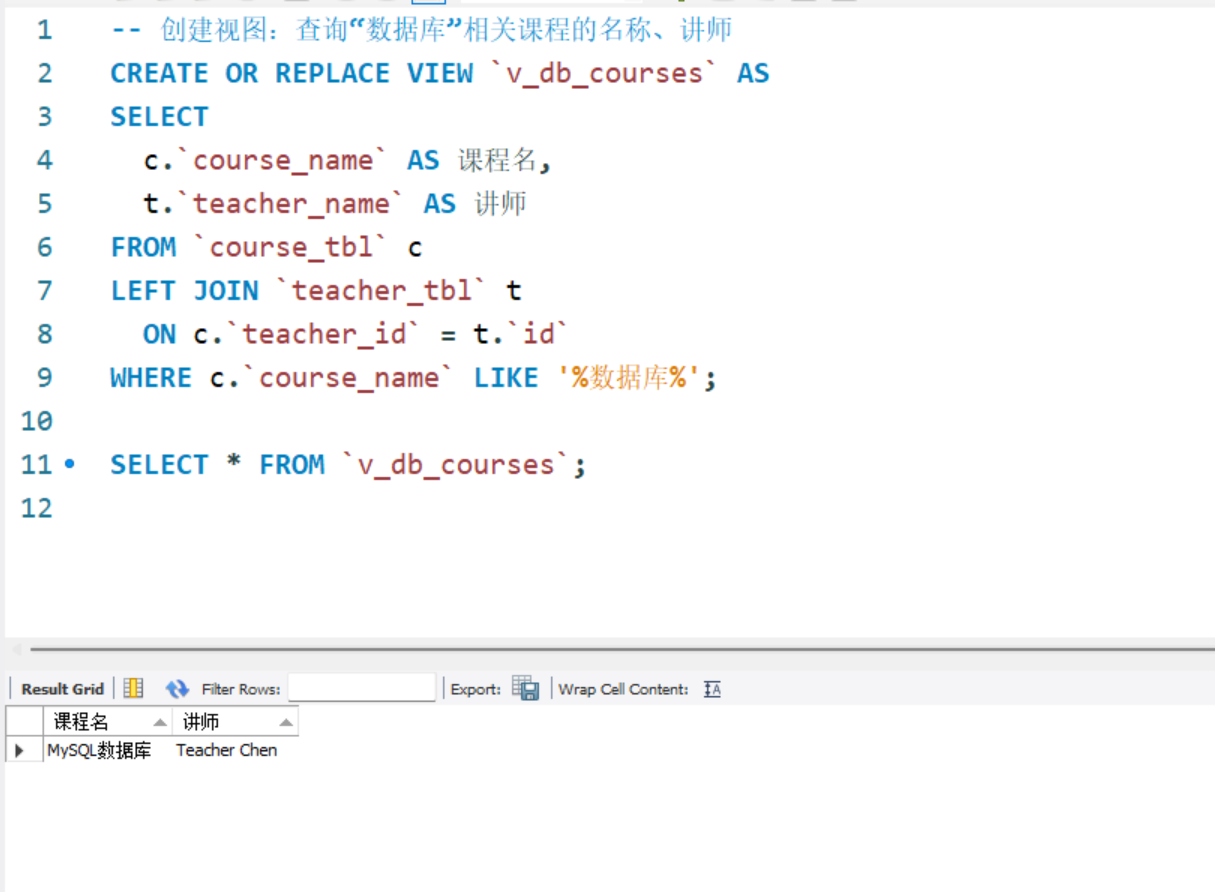
-- 创建视图:查询“数据库”相关课程的名称、讲师
CREATE OR REPLACE VIEW `v_db_courses` AS
SELECT
c.`course_name` AS 课程名,
t.`teacher_name` AS 讲师
FROM `course_tbl` c
LEFT JOIN `teacher_tbl` t
ON c.`teacher_id` = t.`id`
WHERE c.`course_name` LIKE '%数据库%';
-- 使用视图(像表一样查询)
SELECT * FROM `v_db_courses`
作用:
- 复用查询逻辑:将常用复杂查询定义为视图,避免重复书写(如报表查询)。
- 简化权限管理:限制用户只能访问视图(而非基表),隐藏敏感字段(如基表有
password,视图可剔除)。 - 数据独立:若基表结构变更(如字段名修改),可通过修改视图适配,不影响依赖视图的应用(如
SELECT * FROM 视图无需改代码)。
注意:
- 视图可更新(
INSERT/UPDATE/DELETE),但需满足一定条件(如无GROUP BY、DISTINCT等),建议仅用视图查询,避免更新(逻辑复杂易出错)。
创建视图并使用:
2. 触发器(TRIGGER)
定义:触发器是与表关联的“自动执行”的存储过程,当表发生INSERT/UPDATE/DELETE操作时自动触发(无需手动调用)。
四要素:
- 监视对象:哪个表(
ON 表名)。 - 监视事件:
INSERT/UPDATE/DELETE(触发条件)。 - 触发时间:
BEFORE(操作前)/AFTER(操作后)。 - 触发操作:触发时执行的SQL(
INSERT/UPDATE/DELETE)。
NEW与OLD:
INSERT触发:NEW.字段表示新增的记录值。DELETE触发:OLD.字段表示被删除的记录值。UPDATE触发:OLD.字段表示旧值,NEW.字段表示新值。
示例:
需求:当新增订单时,自动减少对应商品的库存。
-- 1. 准备表
CREATE TABLE `goods` ( -- 商品表
`id` INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL,
`stock` INT NOT NULL DEFAULT 0 COMMENT '库存'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `orders` ( -- 订单表
`id` INT PRIMARY KEY AUTO_INCREMENT,
`goods_id` INT NOT NULL COMMENT '商品ID',
`num` INT NOT NULL COMMENT '购买数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 2. 创建触发器(新增订单后,减少商品库存)
DELIMITER // -- 临时修改分隔符(避免触发器内;结束定义)
CREATE TRIGGER `trig_order_after_insert`
AFTER INSERT ON `orders` -- 监视orders表的INSERT事件,在操作后触发
FOR EACH ROW -- 每行触发一次(行级触发器)
BEGIN
-- 用NEW.goods_id获取新增订单的商品ID,NEW.num获取购买数量
UPDATE `goods`
SET `stock` = `stock` - NEW.`num`
WHERE `id` = NEW.`goods_id`;
END //
DELIMITER ; -- 恢复分隔符
-- 3. 测试:新增订单,查看库存是否减少
INSERT INTO `goods` (`name`, `stock`) VALUES ('MySQL教程', 100); -- 初始库存100
INSERT INTO `orders` (`goods_id`, `num`) VALUES (1, 5); -- 购买5本
SELECT `stock` FROM `goods` WHERE `id` = 1; -- 结果为95(100-5)
事务性:触发器的操作与触发它的DML操作在同一事务中(如INSERT orders后触发UPDATE goods,若UPDATE失败,INSERT会回滚),保证数据一致性。
3. 存储过程(PROCEDURE)
定义:存储过程是预编译的SQL集合(含逻辑控制),存储在数据库中,可通过名称调用,用于封装复杂业务逻辑(如批量处理、计算)。
特点:
- 可编程性:支持变量、条件判断(
IF)、循环(WHILE/LOOP)等。 - 复用性:一次创建,多次调用(避免重复编写SQL)。
- 减少网络传输:客户端只需调用存储过程名,无需传输大量SQL(尤其复杂逻辑)。
参数类型:
IN:输入参数(调用时传入,存储过程内可使用,修改不影响外部)。OUT:输出参数(存储过程内修改,可返回给外部)。INOUT:输入输出参数(调用时传入,存储过程内修改后返回)。
示例:
-- 1. 创建无参数存储过程(查询所有商品)
DELIMITER //
CREATE PROCEDURE `proc_get_all_goods`()
BEGIN
SELECT `id`, `name`, `stock` FROM `goods`;
END //
DELIMITER ;
-- 调用
CALL `proc_get_all_goods`();
-- 2. 创建带IN和OUT参数的存储过程(查询指定商品的库存,返回库存数量)
DELIMITER //
CREATE PROCEDURE `proc_get_goods_stock`(
IN goods_id_in INT, -- 输入参数:商品ID
OUT stock_out INT -- 输出参数:返回库存
)
BEGIN
SELECT `stock` INTO stock_out -- 将查询结果赋值给输出参数
FROM `goods`
WHERE `id` = goods_id_in;
END //
DELIMITER ;
-- 调用(用用户变量@stock接收结果)
CALL `proc_get_goods_stock`(1, @stock);
SELECT @stock; -- 查看返回的库存
-- 3. 带循环的存储过程(批量插入商品)
DELIMITER //
CREATE PROCEDURE `proc_batch_insert_goods`(
IN count_in INT -- 插入数量
)
BEGIN
DECLARE i INT DEFAULT 1; -- 循环变量
WHILE i <= count_in DO -- 循环count_in次
INSERT INTO `goods` (`name`, `stock`)
VALUES (CONCAT('商品', i), 100); -- 商品名:商品1、商品2...
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
-- 调用(插入5个商品)
CALL `proc_batch_insert_goods`(5);
注意:存储过程调试困难(无断点),且移植性差(不同数据库语法不同),简单逻辑建议在应用层实现,复杂批量操作(如数据迁移)可考虑使用。
六、权限管理
数据库权限用于控制用户对数据库/表的操作范围(如仅允许查询,不允许删除),保障数据安全。
1. 创建用户
语法:
CREATE USER '用户名'@'主机' IDENTIFIED BY '密码';
示例:
-- 创建仅允许本地登录的用户(localhost)
CREATE USER 'dev_user'@'localhost' IDENTIFIED BY 'Dev@123456';
-- 创建允许任意主机登录的用户(%表示所有远程主机,生产环境慎用)
CREATE USER 'admin_user'@'%' IDENTIFIED BY 'Admin@123456';
详细讲解:
主机:限制用户登录的来源(localhost:仅本地;192.168.1.%:仅192.168.1网段;%:所有主机)。- 密码:需符合安全策略(如长度、复杂度,可通过
validate_password插件设置)。
2. 授权(GRANT)
语法:
GRANT 权限列表 ON 数据库.表 TO '用户名'@'主机' [WITH GRANT OPTION];
示例:
-- 1. 授予dev_user对school_db库所有表的查询、插入权限(本地登录)
GRANT SELECT, INSERT ON `school_db`.* TO 'dev_user'@'localhost';
-- 2. 授予admin_user所有数据库所有表的所有权限(%登录,生产环境谨慎)
GRANT ALL PRIVILEGES ON *.* TO 'admin_user'@'%';
-- 3. 授予视图权限(允许查询视图v_db_courses)
GRANT SELECT, SHOW VIEW ON `school_db`.`v_db_courses` TO 'dev_user'@'localhost';
详细讲解:
- 权限列表:
- 常用权限:
SELECT(查询)、INSERT(插入)、UPDATE(更新)、DELETE(删除)、CREATE(创建)、DROP(删除)等。 ALL PRIVILEGES:所有权限(除GRANT OPTION外)。
- 常用权限:
ON 数据库.表:*.*:所有数据库所有表。school_db.*:school_db库所有表。school_db.course_tbl:仅school_db库的course_tbl表。
WITH GRANT OPTION:允许用户将自己的权限授予其他用户(如管理员可授权给其他用户)。
3. 刷新权限
权限修改后需刷新,使其生效:
FLUSH PRIVILEGES;
七、游标(Cursor)
游标是数据库中用于逐行处理查询结果集的工具,适用于需要对多行数据执行独立操作的场景,常用于存储过程、函数等数据库程序中。
1. 声明变量(接收游标数据)
语法:
DECLARE 变量名 数据类型 [CHARACTER SET 字符集];
示例:
-- 声明变量存储游标取出的数据(与查询字段类型匹配)
DECLARE p_id INT;
DECLARE p_name VARCHAR(50) CHARACTER SET utf8; -- 中文需指定字符集
DECLARE p_score DECIMAL(5,2);
2. 声明游标结束标志
语法:
DECLARE 标志变量 INT DEFAULT 0; -- 0:未结束,1:已结束
示例:
DECLARE done INT DEFAULT 0; -- 标记游标是否遍历完成
3. 声明游标
语法:
DECLARE 游标名 CURSOR FOR SELECT语句;
示例:
-- 定义游标,关联查询结果集
DECLARE score_cursor CURSOR FOR
SELECT id, student_name, score FROM score_tbl WHERE course_id = 1;
4. 声明游标结束处理程序
语法:
DECLARE CONTINUE HANDLER FOR NOT FOUND SET 标志变量 = 1;
示例:
-- 当游标无数据可取时,将done设为1(终止循环)
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;
5. 打开游标
语法:
OPEN 游标名;
示例:
OPEN score_cursor; -- 初始化游标,指向结果集第一行
6. 循环获取并处理数据
语法:
WHILE 标志变量 != 1 DO
FETCH 游标名 INTO 变量1, 变量2, ...; -- 取当前行数据
IF 标志变量 != 1 THEN
-- 行级操作(如计算、更新等)
END IF;
END WHILE;
示例:
-- 循环处理游标数据
WHILE done != 1 DO
FETCH score_cursor INTO p_id, p_name, p_score; -- 取出一行数据
IF done != 1 THEN
-- 示例:统计及格人数(score >= 60)
IF p_score >= 60 THEN
SET pass_count = pass_count + 1;
END IF;
END IF;
END WHILE;
7. 关闭游标
语法:
CLOSE 游标名;
示例:
CLOSE score_cursor; -- 关闭游标,释放资源
8. 释放游标(可选)
语法:
DEALLOCATE 游标名;
示例:
DEALLOCATE score_cursor; -- 彻底释放游标(MySQL中通常可省略)
注意事项
- 声明顺序:必须严格遵循“变量 → 游标 → 处理程序”的顺序,否则会报错。
- 性能:游标为行级操作,处理大量数据时效率较低,优先使用批量SQL(如
UPDATE)。 - 作用范围:仅能在存储过程、函数、触发器等数据库程序中使用,不可直接在SQL脚本中单独执行。
八、正则表达式(Regular Expression)
正则表达式用于模糊匹配字符串,通过特定模式匹配符合规则的文本,MySQL中通过 REGEXP 关键字实现正则匹配。
1. 基本语法
语法:
SELECT 字段 FROM 表名 WHERE 字段 REGEXP '正则模式';
示例:
-- 查询姓名以“谢”开头的讲师
SELECT * FROM teacher WHERE tname REGEXP '^谢';
2. 常用正则模式及说明
| 模式符号 | 说明 | 示例模式 | 匹配示例 |
|---|---|---|---|
^ |
匹配字符串开始位置 | ^b |
“book”、“big”(以b开头) |
$ |
匹配字符串结束位置 | e$ |
“apple”、“love”(以e结尾) |
. |
匹配任意单个字符(除换行符) | b.t |
“bit”、“bat”(b和t之间有一个字符) |
* |
匹配前面字符0次或多次 | f*n |
“fn”、“fan”、“faan”(n前有任意个f) |
+ |
匹配前面字符1次或多次 | ba+ |
“ba”、“bay”、“battle”(b后至少1个a) |
[字符集] |
匹配字符集中的任意一个字符 | [xz] |
“dizzy”、“zebra”(含x或z) |
[^字符集] |
匹配不在字符集中的任意字符 | [^abc] |
“desk”、“fox”(不含a、b、c) |
字符串{n} |
匹配前面字符串至少n次 | b{2} |
“bbb”、“bbbb”(至少2个b) |
字符串{n,m} |
匹配前面字符串至少n次,至多m次 | b{2,4} |
“bb”、“bbb”、“bbbb”(2-4个b) |
| |
匹配多个模式中的一个(逻辑“或”) | cat|dog |
“cat”、“dog”(匹配cat或dog) |
3. 与其他查询结合示例
示例1:结合子查询筛选
-- 查询课程名称含“数学”或“物理”的学生(用正则匹配课程名)
SELECT * FROM student
WHERE class_id IN (
SELECT cid FROM course
WHERE course_name REGEXP '数学\|物理' -- 匹配“数学”或“物理”
);
示例2:匹配复杂模式
-- 查询手机号以138开头且第4位为0-5的用户(假设手机号字段为phone)
SELECT * FROM user
WHERE phone REGEXP '^138[0-5]'; -- ^138匹配开头,[0-5]匹配第4位
4. 注意事项
- MySQL的
REGEXP匹配默认不区分大小写,若需区分,可使用REGEXP BINARY。 - 正则匹配可能导致索引失效,大数据量查询时需谨慎使用。
- 复杂模式建议结合子查询或视图,提高可读性。