HiggsAudio-V2: 融合语言与声音的下一代音频大模型
在音频生成领域,Boson AI 的 HiggsAudio-V2 正在重新定义可能性。这款模型并非一个孤立的系统,而是一个精巧的“增强型”大型语言模型(LLM),它巧妙地将先进的音频处理能力嫁接到一个强大的文本语言模型之上,从而实现了在多说话人、高保真、富有情感的语音合成上的卓越表现。
核心架构:基于 Llama-3.2-3B 的增强之路
HiggsAudio-V2 的核心是一个著名的开源大语言模型——Llama-3.2-3B。Llama-3.2-3B 本身是一个拥有 32.1 亿参数的自动回归语言模型,经过海量多语言文本数据的预训练和指令微调,在文本理解和生成方面表现出色。
Boson AI 的创新之处在于,他们没有从零开始训练一个庞大的音频模型,而是选择了一条更高效、更聪明的路径:将 Llama-3.2-3B 作为“大脑”,并为其添加一个专门处理音频的“耳朵”和“声带”。
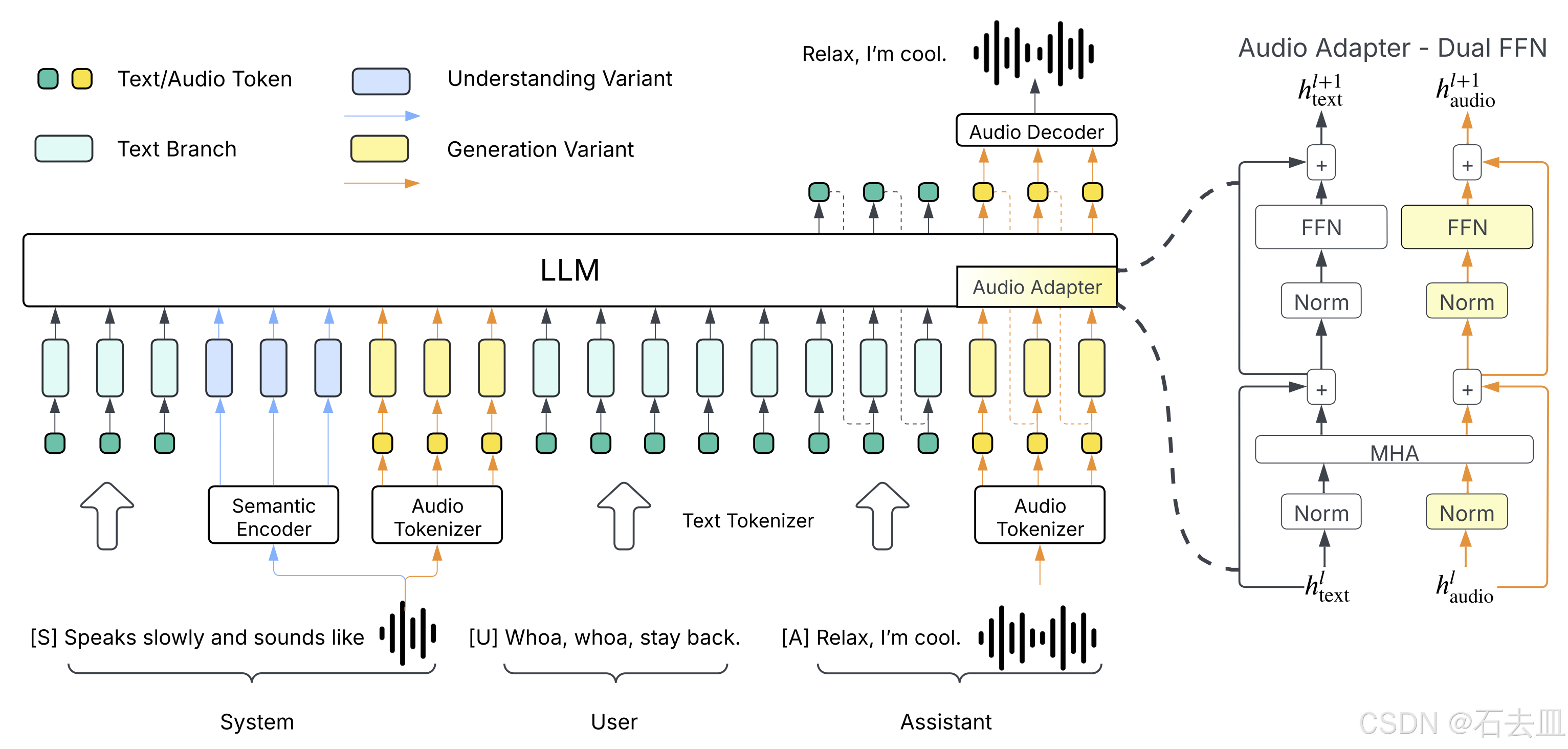
关键创新:DualFFN 音频适配器
为了赋予 Llama 模型处理音频的能力,HiggsAudio-V2 引入了名为 DualFFN 的架构,作为其核心的音频适配器 (audio adapter)。
- 作用:DualFFN 充当了一个“音频领域的专家”。它被嵌入到 Llama 模型的每一层中,专门负责处理和增强与音频相关的 token 信息。
- 优势:这种设计的关键优势在于极低的计算开销。通过仅对 Llama 模型的结构进行局部增强,HiggsAudio-V2 在引入强大音频能力的同时,保留了原始 LLM 91% 的训练速度。这意味着开发者可以在不牺牲太多效率的情况下,获得一个功能全面的多模态模型。
音频处理的基石:Higgs Audio Tokenizer
HiggsAudio-V2 能够“听”和“说”,其背后离不开一个关键的底层技术——Higgs Audio Tokenizer。该分词器使用残差向量量化 (RVQ) 技术,将连续的音频信号分解为多个码本(codebooks)中的离散 token。
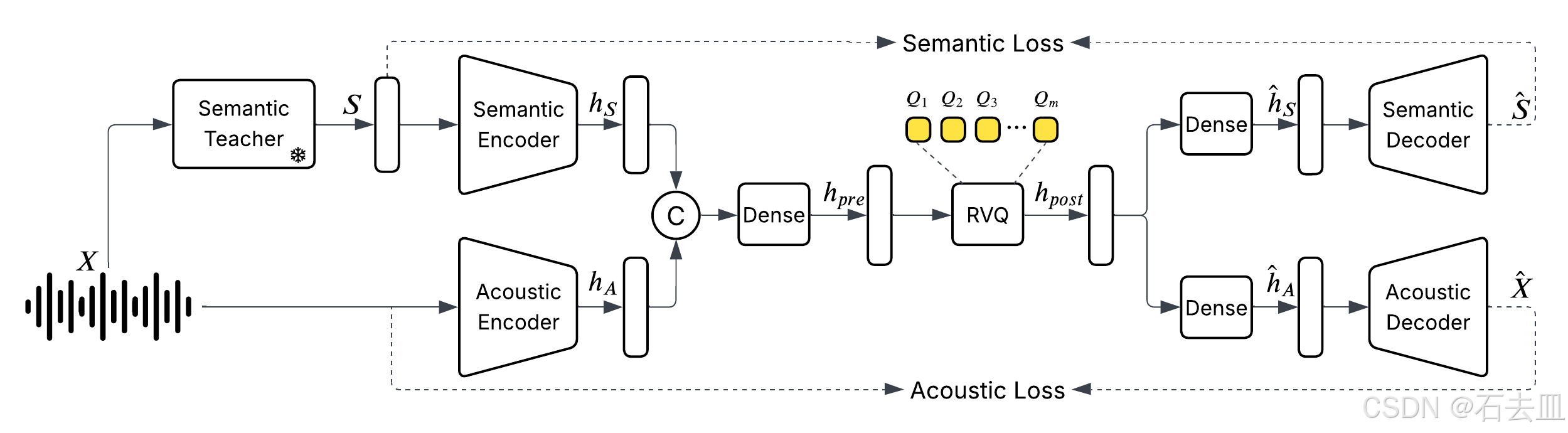
为了处理 RVQ 产生的多个 token 流,HiggsAudio-V2 采用了先进的 “delay pattern” 技术。这一模式允许模型在生成音频时,能够同时为所有码本生成 token,从而支持高质量的流式音频生成 (streaming)。用户无需等待整个音频生成完毕,声音就可以实时、流畅地输出,极大地提升了交互体验。
Higgs Audio Tokenizer通过一个**非扩散的编码器/解码器(non-diffusion encoder/decoder)**架构将连续的音频信号转换为离散的“token”。这个过程可以分解为以下几个关键步骤:
1. 音频分帧 (Frame Splitting)
首先,原始的音频信号(采样率为 f s f_s fs,文中为 24 kHz)被送入编码器。编码器以一个固定的帧移 (hop size M M M) 将连续的音频流分割成一系列重叠或不重叠的短时帧。这决定了处理的帧率 f r = f s / M f_r = f_s / M fr=fs/M。Higgs Audio Tokenizer 的关键优势之一就是其极低的帧率(25 fps),这意味着它每秒只生成 25 个 token,大大降低了后续模型处理的序列长度。
2. 特征提取与编码 (Encoding)
编码器(Encoder)是一个神经网络,它接收分割后的音频帧作为输入。它的任务是将这些时域或频域的音频信号编码成一个或多个更高维度的、包含音频语义和声学信息的连续特征向量(continuous latent representations)。这个过程类似于将原始音频“压缩”或“抽象”成一种中间表示。
3. 离散化/量化 (Discretization/Quantization)
这是生成“token”的核心步骤。上一步得到的连续特征向量需要被转换成离散的数字(即 token)。Higgs Audio Tokenizer 使用了文中提到的量化器,如残差向量量化 (RVQ) 或 有限标量量化 (FSQ)。
- 量化器的作用:量化器内部包含一个或多个“码本 (codebook)”,码本可以看作是一个巨大的查找表,里面存储了许多预定义的向量模式。
- 匹配过程:对于编码器输出的每一个连续特征向量,量化器会在码本中寻找一个或多个最相似的向量。
- 生成Token:找到最相似的向量后,量化器不再输出这个向量本身,而是输出它在码本中的索引号(index)。这个索引号就是一个“token”。例如,如果一个码本有 1024 个向量,那么每个 token 就可以用 10 个比特(bit)来表示(因为 2 10 = 1024 2^{10} = 1024 210=1024)。
文件中提到,比特率 (BPS) 的计算公式为 BPS = 帧率 (fr) × N_q × log₂(N_cb),其中 N_q 是量化器的层数(如RVQ的级联层数),N_cb 是码本大小。Higgs Audio Tokenizer 通过低帧率 (25 fps) 和优化的量化结构,实现了仅 2 kbps 的低比特率。
4. 解码与重建 (Decoding)
当需要将 token 还原成可听的音频时,解码器(Decoder)会执行相反的过程:
- 接收离散的 token 序列。
- 根据 token 的索引号,从码本中检索出对应的连续特征向量。
- 解码器神经网络将这些特征向量解码回时域的音频波形。
- 将所有帧的音频波形拼接起来,得到最终的重建音频。
简单来说,Higgs Audio Tokenizer 的编码过程就是:
原始音频 → [编码器] → 连续特征向量 → [量化器] → 离散的Token (索引号)
这个过程将高维度、连续的音频数据压缩成了一个低维度、离散的 token 序列。这些 token 既保留了原始音频的关键语义信息(如说了什么话、是谁说的),也保留了足够的声学细节(如音色、韵律),同时以极高的效率(25 fps, 2 kbps)运行,为大型语言模型处理音频铺平了道路。
DualFFN 的有效性验证
为了证明 DualFFN 的价值,Boson AI 进行了一项消融研究(Ablation Study)。他们基于更小的 LLaMA-3.1-1B 模型,训练了两个版本:一个包含 DualFFN,另一个不包含。在 SeedTTS-Eval 数据集上的评估结果清晰地展示了 DualFFN 的优势:
- 更低的词错误率 (WER):在英语(EN)和中文(ZH)测试中,配备 DualFFN 的模型生成的语音内容更准确,词错误率显著低于未配备的模型。
- 更高的说话人相似度 (SIM):配备 DualFFN 的模型在模仿目标说话人音色和风格方面表现更佳,说话人相似度更高。
这些结果有力地证明,DualFFN 作为一个轻量级的音频专家,能够有效提升模型在语义准确性和音色保真度两方面的性能。
总结
HiggsAudio-V2 代表了一种构建多模态 AI 的先进范式:以强大的通用语言模型为基础,通过精心设计的适配器(如 DualFFN)注入特定领域的专家能力。结合其高效的 Higgs Audio Tokenizer 和流式生成技术,HiggsAudio-V2 不仅在技术上实现了突破,更为开发者提供了一个高效、高质量、可实时交互的音频生成解决方案,预示着下一代语音助手、虚拟角色和音频内容创作工具的未来方向。