01. Model 组件的基本组成
Model 是 LangChain 的核心组件,但是 LangChain 本身不提供自己的 LLM,而是提供了一个标准接口,用于封装不同类型的 LLM 进行交互,其中 LangChain 为两种类型的模型提供接口和集成:
- LLM:使用纯文本作为输入和输出的大语言模型。
- Chat Model:使用聊天消息列表作为输入并返回聊天消息的聊天模型。
在 LangChain 中,无论是 LLM 亦或者 Chat Model 都可以接受 PromptValue/字符串/消息列表 作为参数,内部会根据模型的类型自动转换成字符串亦或者消息列表,屏蔽了不同模型的差异。
对于 Model 组件,LangChain 有一个模型总基类,并对基类进行了划分

调用大模型最常用的方法为:
- invoke:传递对应的文本提示/消息提示,大语言模型生成对应的内容。
- batch:invoke 的批量版本,可以一次性生成多个内容。
- stream:invoke 的流式输出版本,大语言模型每生成一个字符就返回一个字符。
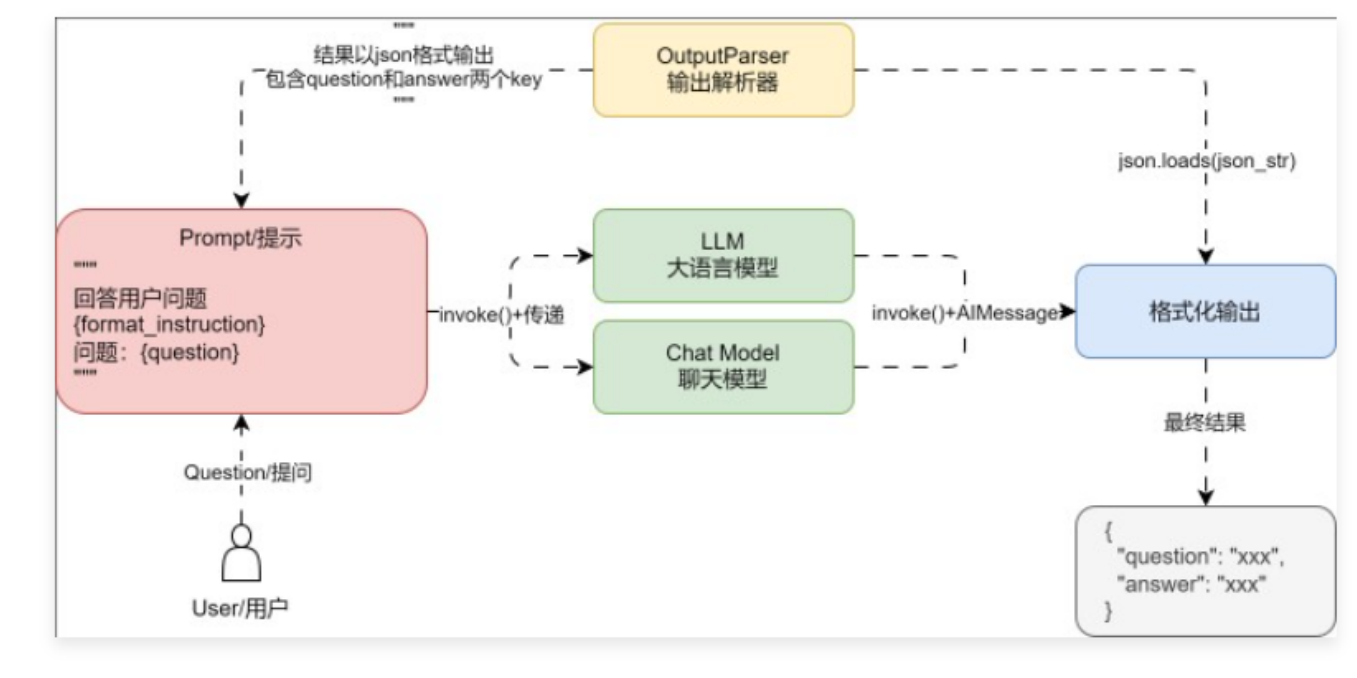
基础聊天应用的运行流程更改成如下
 02. Message 组件
02. Message 组件
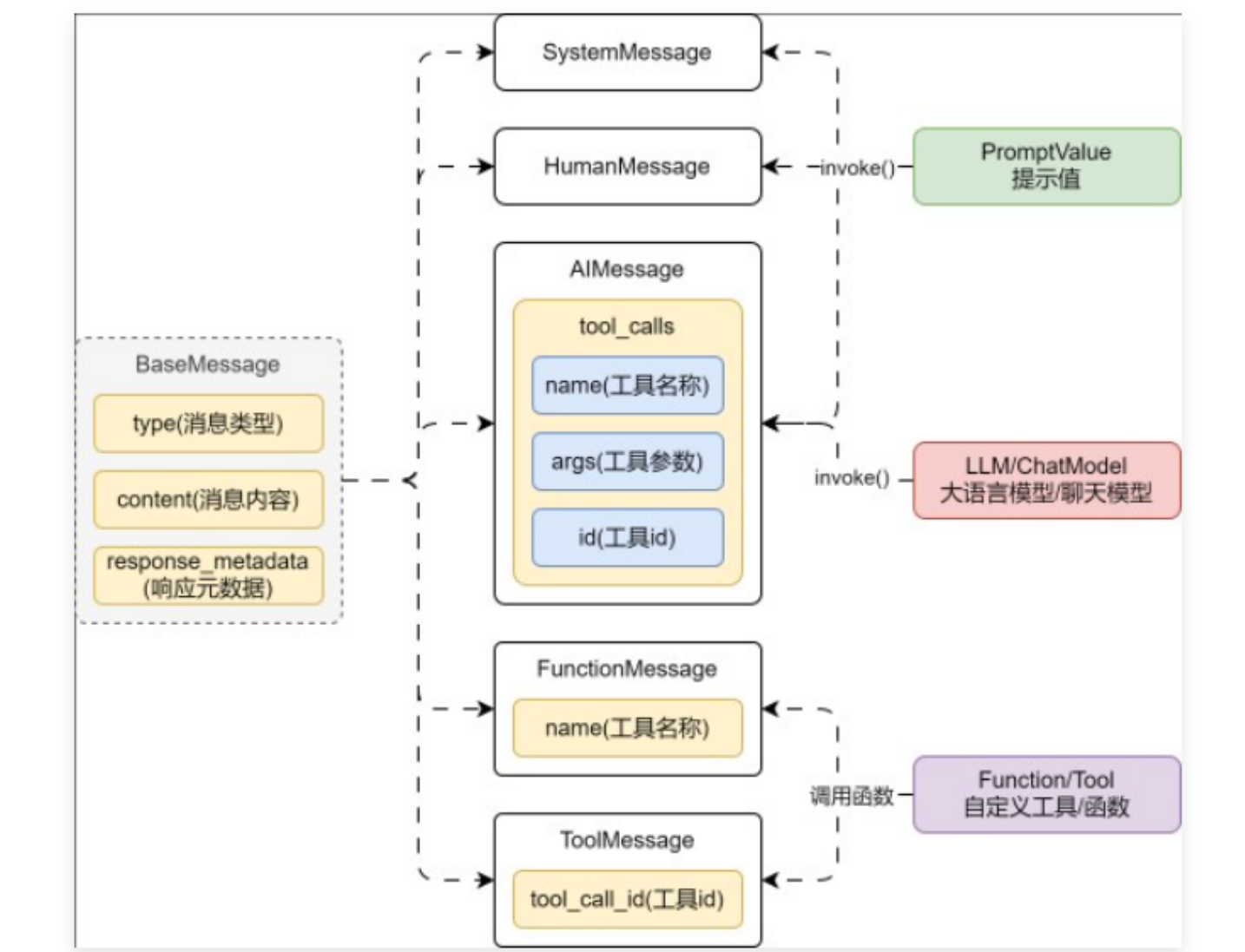
在 LangChain 中,Message 是消息组件,并且所有消息都具有type(类型)、content(内容)、response_metadata(响应元数据),LangChain 封装的 Message 涵盖了 5 种类型的消息:SystemMessage、HumanMessage、AIMessage、FunctionMessage、ToolMessage,基类及子类如下
03. Model 组件示例
3.1 LLM与ChatModel使用技巧
代码
from datetime import datetime
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1.编排Prompt
prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的聊天机器人,请回答用户的问题,现在的时间是{now}"),
("human", "{query}"),
]).partial(now=datetime.now())
# 2.创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.生成内容
prompt_value = prompt.invoke({"query": "现在是几点,请讲一个关于程序员的冷笑话"})
ai_message = llm.invoke(prompt_value)
# 4.提取内容
print("type:", ai_message.type)
print("content:", ai_message.content)
print("response_metadata:", ai_message.response_metadata)
输出:
type: ai
content: 现在是18:12。好的,这是一个关于程序员的冷笑话:
为什么程序员总是觉得寂寞?
因为他们总是在和bug独处!
response_metadata: {'token_usage': {'completion_tokens': 53, 'prompt_tokens': 71, 'total_tokens': 124}, 'model_name': 'gpt-3.5-turbo-16k', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}
3.2 Model批处理
代码
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1.构建提示模板
prompt = ChatPromptTemplate.from_template("请讲一个关于{subject}的冷笑话")
# 2.构建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.批处理获取响应
ai_messages = llm.batch([
prompt.invoke({"subject": "程序员"}),
prompt.invoke({"subject": "Python"}),
])
for ai_message in ai_messages:
print(ai_message.content)
输出:
当程序员去海滩度假时,他们把沙子编成了二进制。为了放松,他们打算写一个程序,把整个海洋分割成像素并给每个像素着色。
为什么Python喜欢处理字符串?
因为它不喜欢弄得太复杂,总是喜欢把问题拆成小块来处理!
3.3 Model流式输出
代码
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1.编排Prompt
prompt = ChatPromptTemplate.from_template("你能简单介绍下{subject}么?")
# 2.构建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.流式输出
response = llm.stream(prompt.invoke({"subject": "LLM和LLMOps"}))
for chunk in response:
print(chunk.content, flush=True, end="")
输出:
LLM 和 LLMOps 都是开发者社区中的术语。LLM 是指"Language Model",而 LLMOps 则是指与操作相关的语言模型。简单来说,LLM 是一种语言模型,通常用于生成文本、理解语言等任务。而 LLMOps 则是指对语言模型进行操作和管理的实践,包括部署、监控、优化等工作。LLMOps 的目标是确保语言模型在生产环境中的稳定性、性能和安全性。