点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Compress Any Segment Anything Model (SAM)
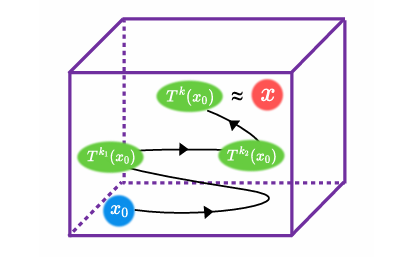
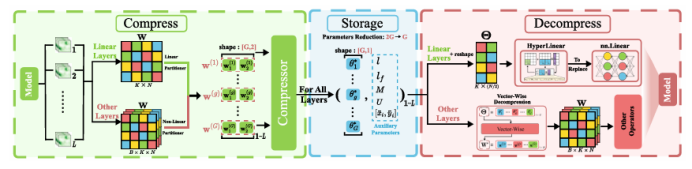
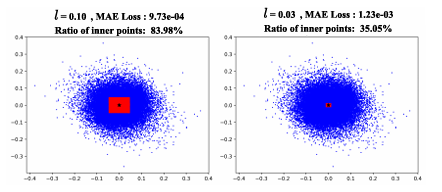
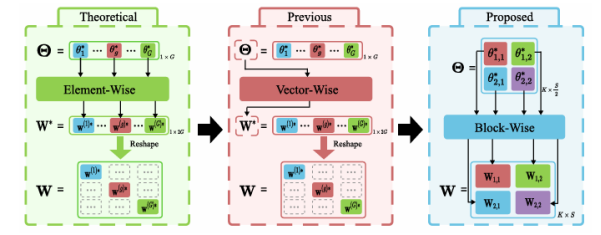
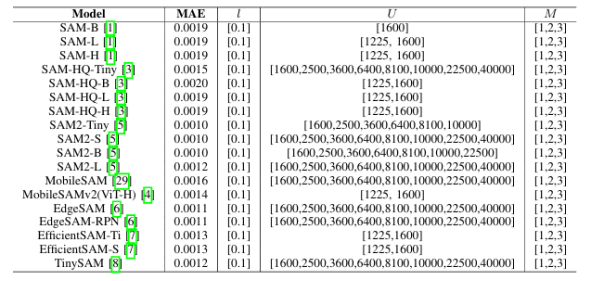
受SAM在零样本分割任务上卓越表现的驱动,其各类变体已被广泛应用于医疗、智能制造等场景。然而,SAM系列模型体量巨大,严重限制了在资源受限环境中的部署效率。本文提出了一种名为Birkhoff的新型无数据压缩算法,旨在对SAM及其变体进行高效压缩。与传统剪枝、量化、蒸馏等方法不同,Birkhoff具备跨模型通用、部署迅捷、忠实原模型、体积紧凑四大优势。其核心创新是引入“超压缩”机制:通过寻找稠密轨迹,将高维参数向量映射为低维标量。此外,本文设计了专用线性算子HyperLinear,将解压缩与矩阵乘法融合,显著提升压缩模型的推理速度。在COCO、LVIS、SA-1B三大数据集上对18个SAM变体的实验表明,Birkhoff在压缩时间、压缩率、压缩后性能及推理速度上均表现优异。例如,在SAM2-B上实现5.17倍压缩率,性能下降不足1%,且无需任何微调数据,压缩全程在60秒内完成。
文章链接:
https://arxiv.org/pdf/2507.08765
02
Compactor: Calibrated Query-Agnostic KV Cache Compression with Approximate Leverage Scores
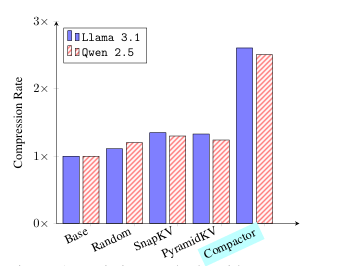
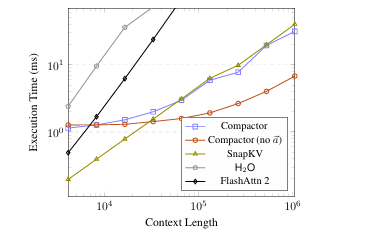
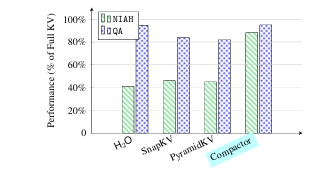
现代大语言模型(LLM)已能支持极长上下文,但在实际部署中,KV 缓存随序列长度线性增长的内存开销成为主要瓶颈。本文提出 Compactor——一种无需查询信息、完全无参数的 KV 缓存压缩策略。该方法利用近似统计杠杆分数衡量 token 重要性,并结合非因果注意力分数,共同决定保留哪些 token。实验表明,Compactor 在 27 项合成与真实长文本任务(RULER、Longbench)上,仅用 50% 的 KV 缓存即可达到与完整缓存相当的性能,且计算开销极低。此外,本研究引入“上下文校准压缩”机制,可在推理阶段为任意文本动态估计最大可压缩比例,在 Longbench 上平均减少 63% 的 KV 内存,同时保持与全缓存一致的性能。作者在 Qwen2.5 与 Llama3.1 系列模型上验证了方法的通用性与有效性。
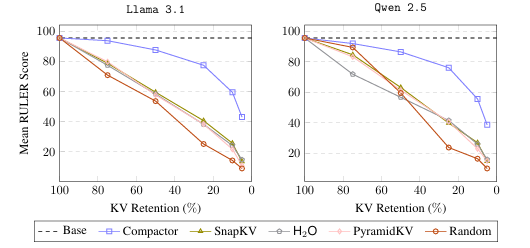
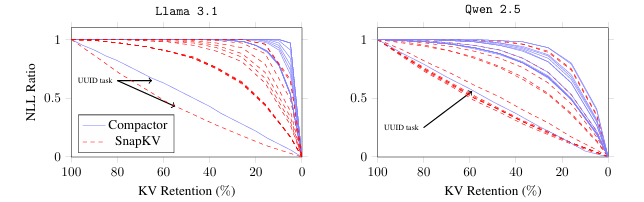
文章链接:
https://arxiv.org/pdf/2507.08143
03
Integrating External Tools with Large Language Models (LLM) to Improve Accuracy
大语言模型(LLM)在缺乏相关上下文时容易产生幻觉或给出低质量回答。为缓解这一问题,本文提出Athena框架,通过调用外部API及计算工具(如计算器、日历、Wolfram Alpha、ArXiv、搜索引擎等)为模型提供实时、精确的信息与计算能力。Athena采用Schema化工具注册机制,使模型可自动识别何时调用何种工具,并解析参数、整合结果。在MMLU数学与科学推理数据集上的评估显示,Athena在数学任务上达到83%准确率,在科学任务上达到88%,显著优于GPT-4o、LLaMA-Large、Mistral-Large、Phi-Large及GPT-3.5等基线(最佳基线分别为67%与79%)。实验表明,工具整合带来的增益可弥补模型规模扩张的不足,为构建围绕LLM的复杂计算生态系统提供了可行路径。
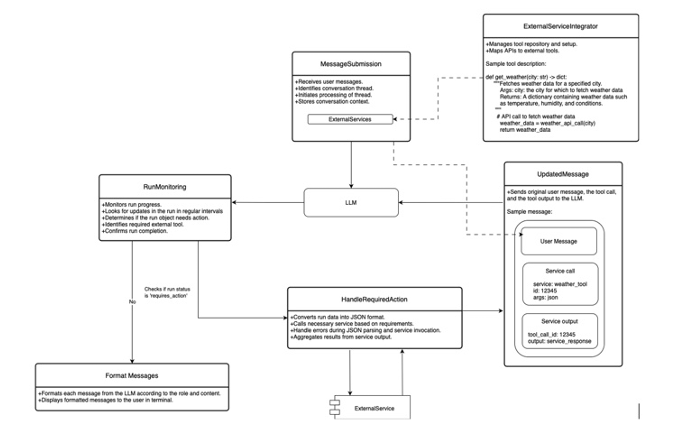

文章链接:
https://arxiv.org/pdf/2507.08034
04
Unveiling Effective In-Context Configurations for Image Captioning: An External & Internal Analysis
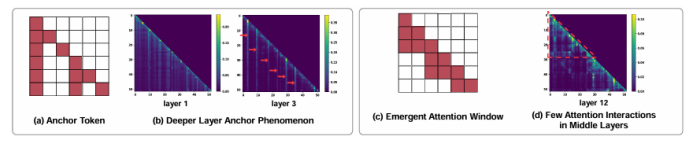
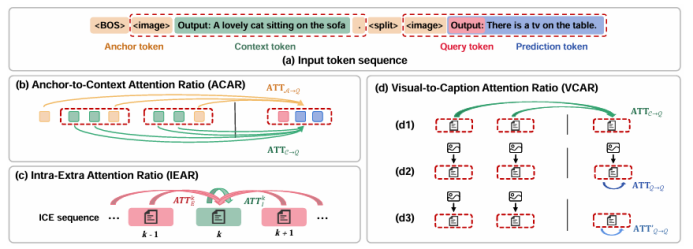
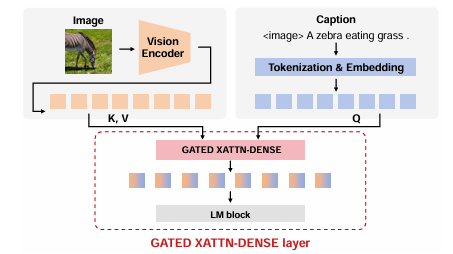
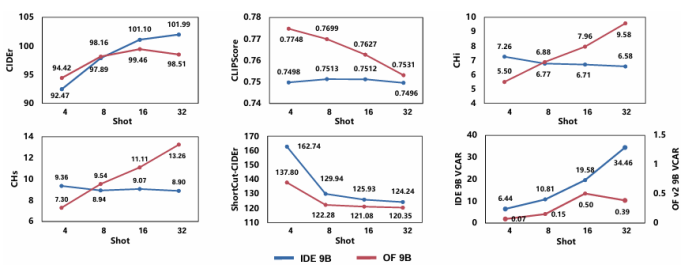
随着大模型的发展,上下文学习(ICL)已被成功从自然语言处理推广到视觉-语言多模态任务。然而,如何为多模态ICL设计合适的示例配置仍缺乏系统研究,且模型内部机制亦未得到充分解释。本文以图像描述任务为切入点,从“外部配置”与“内部机理”两个维度开展全面探究。外部方面,作者系统探索了示例数量、图像检索策略及文本描述质量三个因素,利用多种评价指标总结其影响规律;内部方面,作者深入分析大视觉-语言模型的注意力分布,提出锚定标记、涌现注意力窗口和描述捷径三种典型模式,并设计对应注意力指标进行量化。实验表明,随着示例数量增加,语言连贯性提高,但视觉-文本对齐可能下降;低质量描述会在多示例场景下放大噪声,而相似图像检索易诱发“描述抄袭”捷径行为。此外,作者发现即使架构相同,预训练数据差异也会导致模型行为显著不同,并据此提出基于锚定标记的轻量化推理加速方法,可在几乎不损失性能的前提下降低50% KV缓存。
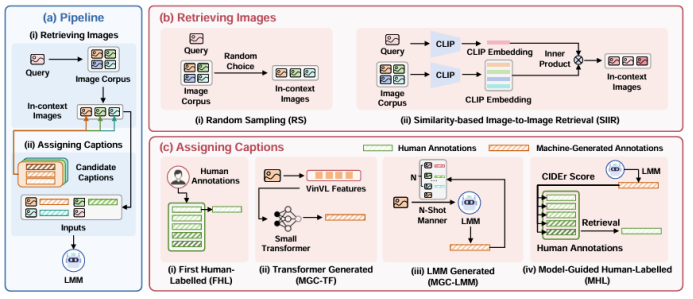
文章链接:
https://arxiv.org/pdf/2507.08021
05
Introspection of Thought Helps AI Agents
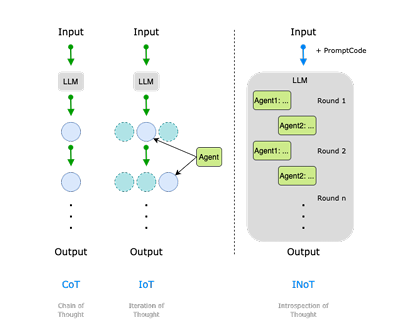
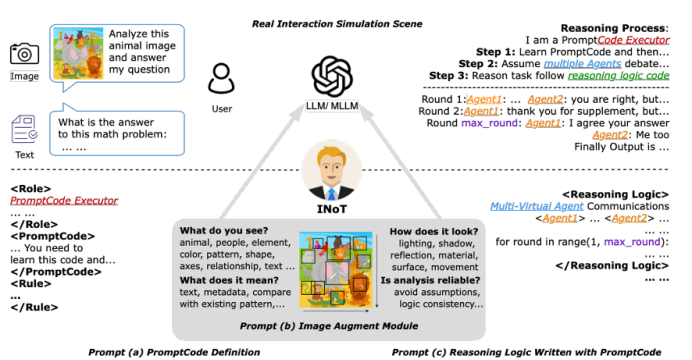
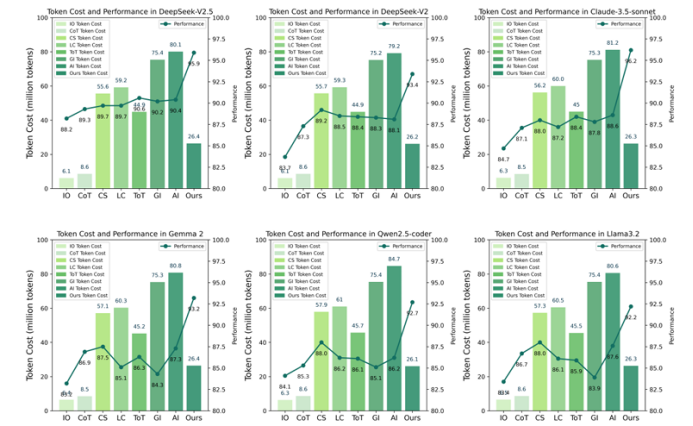
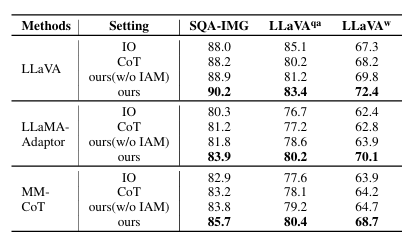
大语言模型(LLM)与多模态大模型(MLLM)已成为 AI Agent 的核心推理引擎,但仅依靠提示工程或外部迭代框架仍受限于模型自身的语言理解局限,且多轮交互带来高昂 token 成本。为此,本文提出 Introspection of Thought(INoT)框架,通过在提示中嵌入“PromptCode”——一种融合 Python 与自然语言的可读代码,使模型在单次调用内部即可完成多轮辩论、自我否定与反思。INoT 将传统外部多 Agent 的迭代过程压缩进 LLM 内部,显著减少 token 开销。在数学、代码、问答 6 个基准及 3 个图像问答数据集上的实验表明,INoT 平均提升 7.95% 性能,token 成本较最佳基线降低 58.3%,并展现了良好的跨模型通用性与多模态适应性。
文章链接:
https://arxiv.org/pdf/2507.08664
06
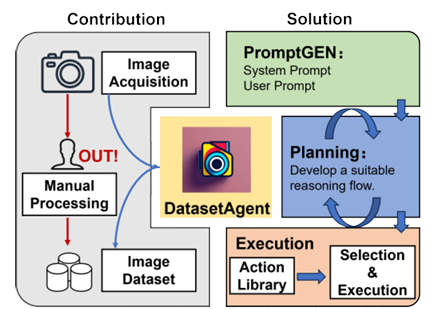
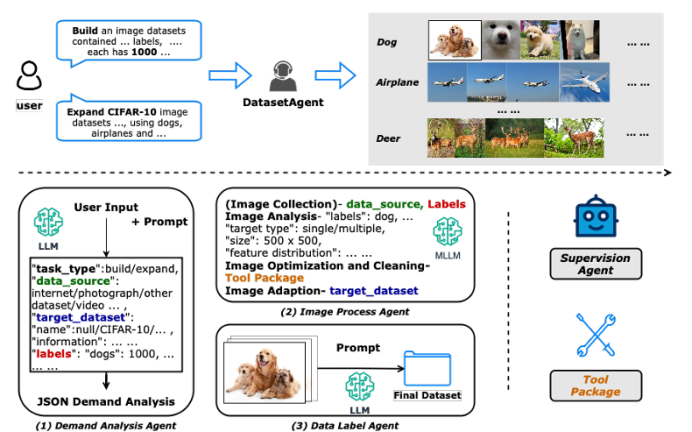
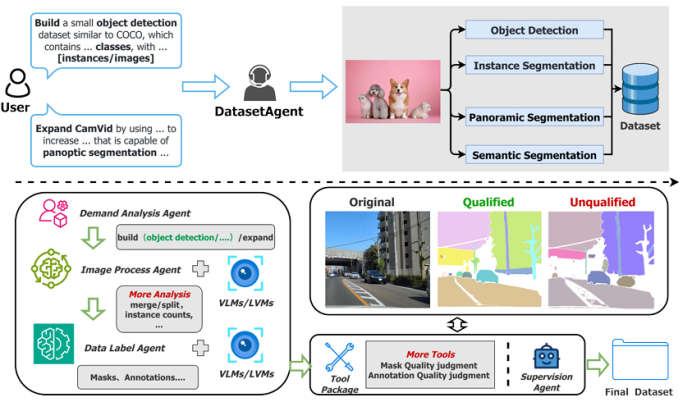
DatasetAgent: A Novel Multi-Agent System for Auto-Constructing Datasets from Real-World Images
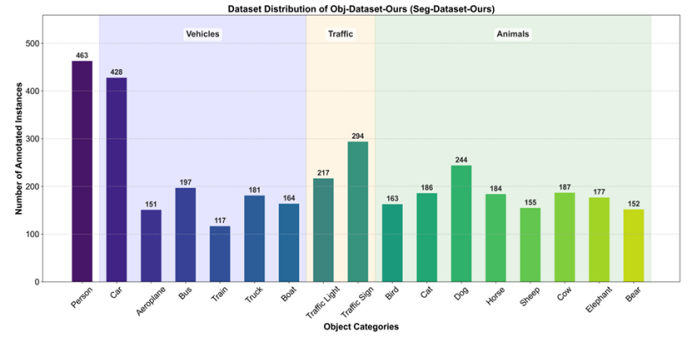
传统图像数据集的构建高度依赖人工收集与标注,耗时低效;而纯合成数据又难以覆盖真实世界的多样性。针对这一矛盾,本文提出 DatasetAgent——一个由四个专业化智能体(需求分析、图像处理、数据标注、监督协调)协同工作的多模态系统。该系统仅需用户提供高层需求或现有数据集,即可自动完成图像检索、质量优化、清洗与多任务标注(分类、检测、分割),全程使用真实世界图像,避免合成数据的缺陷。在扩展 CIFAR-10、STL-10、PASCAL VOC 与 CamVid 以及从零构建新数据集的实验中,DatasetAgent 输出的数据集在类别平衡、视觉质量、标注可靠性等六项指标上均达到或超越人工基准,且下游模型在分类、检测、分割任务上平均准确率提升 0.4–3.9 个百分点。
文章链接:
https://arxiv.org/pdf/2507.08648
07
From Language to Logic: A Bi-Level Framework for Structured Reasoning
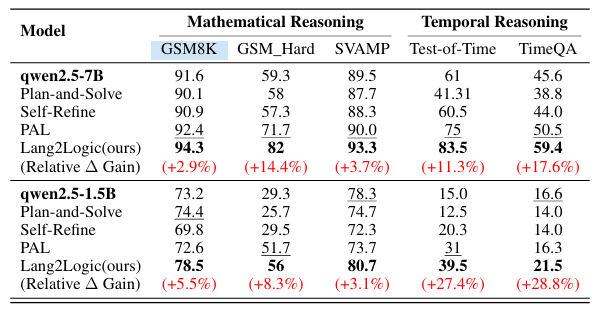
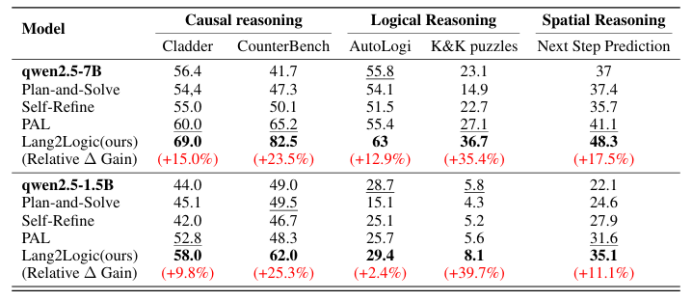
当前大语言模型在结构化推理任务中仍依赖非结构化的链式思考,易出现冗长、不可解释且易错的问题。本文提出 Lang2Logic——一种双层推理框架,将自然语言问题先抽象为包含变量、约束与目标的结构化模型,再生成可执行的 Python 逻辑程序并运行以得到最终答案。该框架采用“优化引导形式化”与“逻辑生成”两级 LLM 协作,并通过双层强化学习算法联合优化,实现跨领域(因果、逻辑、数学、时空推理等)的模块化、可解释推理。在 9 个挑战性基准上的实验表明,Lang2Logic 相比最佳基线平均提升 10% 以上,在复杂任务中最高提升 40%,同时显著降低推理链长度与幻觉风险。

文章链接:
https://arxiv.org/pdf/2507.08501
本期文章由陈研整理
近期活动分享
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!