系列文章目录
前言
在之前项目维护中遇到过一个问题,环境: 基于GTID搭建的主从mysql数据库,版本5.7.32,服务器配置8C 16G 500G数据盘<SSD盘>
现象: 在最近这两天,prometheus监控告警频发mysql从库,主从同步延时过高,配置的延时阈值是300秒,通过监控和在从数据库服务器上执行show slave status\G命令后,发现主从延时高达4784150秒,这严重的超过了阈值,而且执行的是delete删表语句,且该表数据只有50w~100w左右,这么大的延迟而且数据量不大的情况下执行delete都这么长时间,那么相当于从服务器早已夯死,只有一个主库运行。给项目带来了极大的风险,容易造成单点故障,在解决了此问题后,补充一篇文章进行分享。
提示:以下是本篇文章正文内容,下面案例可供参考
结合顶部之前写的初步排查方案,本篇文章进行细节补充和解决方案补充
零、数据库性能指标
| 指标 | 英文含义 | 说明 |
|---|---|---|
| QPS | Query Per Second | 数据库每秒执行的SQL数,包含insert、select、update、delete等。 |
| TPS | Transaction Per Second | 数据库每秒执行的事务数,每个事务中包含18条SQL语句。 |
| 磁盘IOPS | Input/Output Per Second | 即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一 |
一、mysql高延迟排查思路
1、数据库服务磁盘IO性能测试
2、数据库服务器网络测试
3、检查数据库err日志及messages日志.通过相关错误日志调整数据库配置参数
4、数据库性能测试,检查QPS、TPS
5、检查数据库进程、以及事务,根据查找出来的表查看表结构,检查是否存在索引、主键ID
如果以上5步曲都没有问题,那么启动终极大招换服务器,重新搭建主从
1、sysbench工具安装
1.1、yum方式在线安装
yum -y install sysbench
1.2、离线安装
#在可以出公网的机器上使用以下命令进行下载,将下载好的rpm包保存到本地后再上传到对应的数据库服务器上
yum -y install sysbench --downloadonly --downloaddir=/tmp/
1.3、sysbench简介
sysbench 支持以下几种测试模式:
1、CPU 运算性能
2、磁盘 IO 性能
3、调度程序性能
4、内存分配及传输速度
5、POSIX 线程性能–互斥基准测试
6、数据库性能(OLTP 基准测试) #本次使用OLTP基准测试
sysbench其余相关测试方法详解可见下方地址:
https://blog.csdn.net/oschina_41731918/article/details/128000593
2、主从延时过高问题排查流程
2.1、登录从库查看从库状态、事务及相关进程
mysql> show slave status\G;
....
Seconds Behind Master: 4784150 #主从同步延时时间(秒)
....
mysgl> select * from information_schema.innodb_trx\G; #查看是否存在大事务
trx_id: 444902200
trx_state: RUNNING #事务执行状态
trx_started: 2024-09-10 08:26:26 #事务开始执行时间
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 137910
trx_mysql_thread_id: 15
trx_query: DELETE FROM wggl_sjgdxq #事务执行的具体sql
trx_operation_state: NULL
trx_tables_in_use: 1
trx_tables_locked: 1
trx_lock_structs: 1111
trx_lock_memory_bytes: 123088
trx_rows_locked: 136799
trx_rows_modified: 136799
trx_concurrency_tickets: 0
trx_isolation_level: READ CoMMITTED
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive hash_timeout: 0
trx is_read only: 0
trx autocommit_ non_locking: 0
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> select * from information_schema.processlist where info is not null; #查看不为空的进程
mysql> select count(*) from wggl_sjgdxq; #数据量大约为50万条
从上述排查看到,主从同步延时是因为这个大事务导致的,但是从这个事务开始执行的时间到问题排查时间,也远远达不到4784150秒,这个时间对不上,因此可能还存在其他问题,因此继续走排查流程
2.2、查看服务器磁盘、cpu等信息
[root@mysql2 ~]# iostat -xmt 3
[root@mysql2 ~]# top

关键监控指标解析:
%util: 被I/O操作消耗的CPU百分比。理想情况下应小于80%,超过90%表明磁盘接近饱和,无法处理更多I/O请求。例如当运行高负载fio测试时,若%util持续接近100%,则表明磁盘是性能瓶颈。
await: 平均每次设备I/O操作的等待时间(毫秒)。对于SSD正常范围为0.1-1ms;对于HDD正常范围为10-30ms。如果await显著高于svctm(平均服务时间),则表明I/O队列过长,磁盘响应变慢。
r/s和w/s: 每秒完成的读/写操作数直接反映IOPS性能。r/s和w/s的总和即为TPS(每秒事务数)。
rrqm/s和wrqm/s: 每秒合并的读/写请求数。高值表明内核优化了相邻I/O请求,合并为更大的请求,这在顺序读写中常见
从服务器资源使用情况看,8C只用满了1C(因为mysql属于单线程,所以此情况也正常),cpu使用也正常,但是iostat 显示磁盘的读写为0,怀疑是磁盘问题,要不就是当前没有任何读写操作,排除了服务器cpu的问题,接着往下排查数据盘性能问题
2.3、使用fio命令压测数据盘性能
2.3.1、安装fio工具
#二进制安装
[root@mysql2 ~]# tar -zxvf fio-3.17.tar.gz
[root@mysql2 ~]# yum install gcc
[root@mysql2 ~]# yum install libaio-devel
[root@mysql2 ~]# cd fio-3.17
[root@mysql2 ~]# ./configure
[root@mysql2 ~]# make && make install
#yum在线安装
[root@mysql2 ~]# yum -y install fio
2.3.2、执行磁盘随机读写压测命令
[root@mysql2 ~]# time fio -filename=/export/test_randreadwrite.out -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=10G -numjobs=10 -runtime=60 -group_reporting -name iops_randwrite
#这个 fio 命令将执行一个性能测试,随机读写模式下的测试文件大小为 10 GB,块大小为 16 KB,测试持续 60 秒,使用直接 I/O,且每个线程会处理单个 I/O 请求。测试会以 70% 的读取和 30% 的写入比例来模拟真实的应用负载,并汇总所有线程的性能数据。
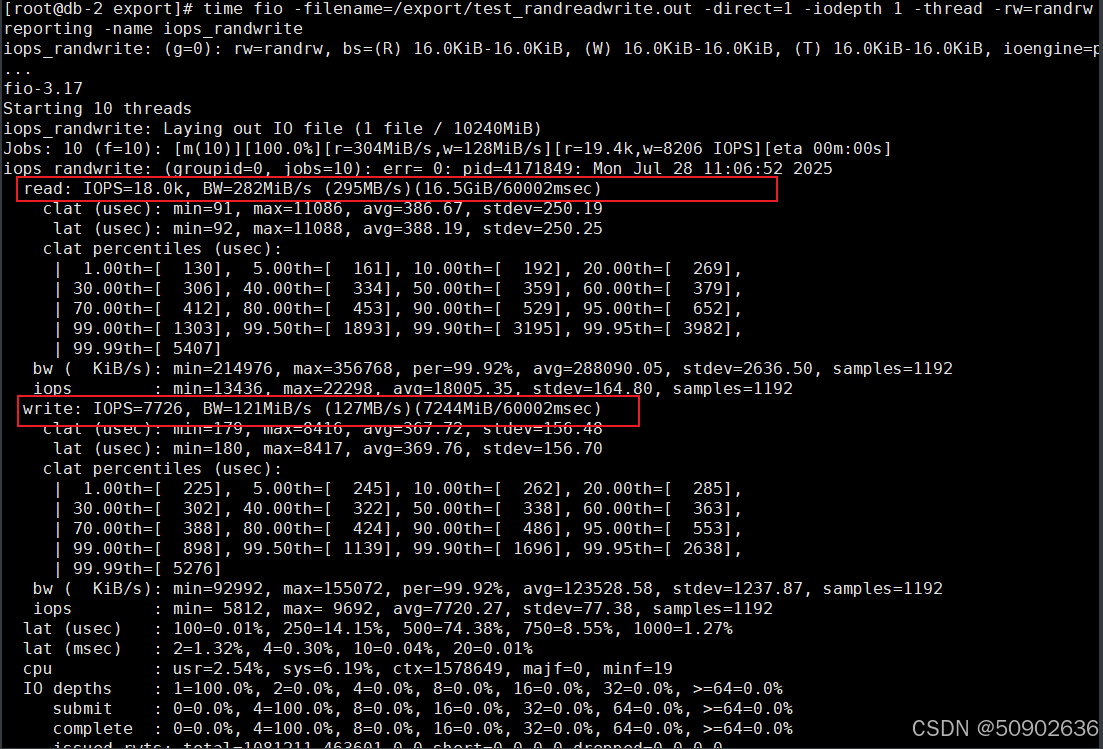
总结:
fio 结果表明:
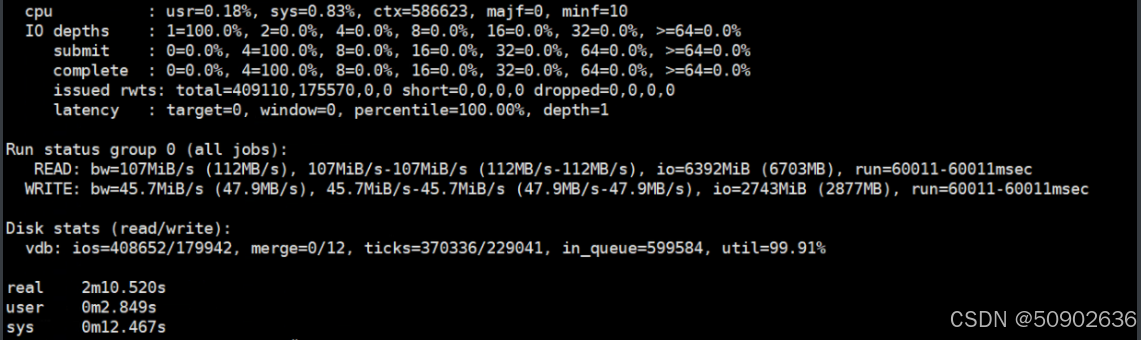
读取吞吐量速度: 107 MiB/s (112 MB/s),总共读取了 6392 MiB (6703 MB)。
写入吞吐量速度: 45.7 MiB/s (47.9 MB/s),总共写入了 2743 MiB (2877 MB)。
磁盘利用率: 99.91%,表明磁盘几乎处于满负荷运行状态。
读取 IOPS: 从 vdb 的统计信息中可以计算读取 IOPS。总读取 I/O 操作次数为 408,652 次,运行时间为 60 秒,因此读取 IOPS 为 408562/60=6810(IOPS)
写入 IOPS: 总写入 I/O 操作次数为 179,942 次,运行时间同样为 60 秒,因此写入 IOPS 为 179942/60=2,665 IOPS
延迟: 通常不是直接从 fio 输出中获取的,但可以通过 fio 的 latency 输出或其他工具(如 iostat)来获得。由于你的测试结果中没有直接显示延迟,我们可以从吞吐量和 IOPS 间接推测:
如果吞吐量较高且 IOPS 较低,通常意味着延迟较高,因为每个 I/O 操作花费的时间较长。
如果 IOPS 高且吞吐量也高,则延迟通常较低,因为磁盘能迅速处理每个 I/O 操作。
从分析来看读取吞吐量较高,但写入吞吐量相对较低。这个不平衡可能表明写入操作的延迟较高。但是从主从同步延时的sql语句查看,执行的也是insert或update操作,而是delete操作,因此,写入操作的延迟较高对数据库的延时高问题并没有直接的关系,因此,也可以排除磁盘性能问题。接着往下排查。
命令参数解释:
-filename=/export/test_randreadwrite.out: 指定测试文件的路径和名称。在这个例子中,测试文件将被创建或使用在 /export/test_randreadwrite.out。
-direct=1: 使用直接 I/O 模式。这意味着 I/O 操作不会经过操作系统的缓存,从而提供更准确的性能测试。
-iodepth 1: 设置 I/O 队列深度为 1。这表示每个线程同时只能处理一个 I/O 请求。
-thread: 启用线程模式,这样每个 numjobs 参数指定的作业将以线程的形式执行,而不是独立的进程。
-rw=randrw: 设置读写模式为随机读写。即在测试中会进行随机读取和随机写入操作。
-rwmixread=70: 设置读写混合比例。70 表示 70% 的操作是随机读取,30% 是随机写入。
-ioengine=psync: 使用 psync I/O 引擎,它通过系统调用 pwrite 和 pread 来进行同步 I/O 操作。
-bs=16k: 设置块大小为 16 KB。这是每次读写操作的数据块大小。
-size=10G: 设置测试文件的大小为 10 GB。
-numjobs=10: 设置同时运行的作业数为 10。每个作业都是一个独立的线程,能够并发执行 I/O 操作。
-runtime=60: 设置测试的运行时间为 60 秒。在这段时间内,fio 将持续执行测试。
-group_reporting: 汇总并报告所有作业的性能结果,而不是分别报告每个作业的结果。
-name iops_randwrite: 设置测试的名称为 iops_randwrite,这有助于在生成的报告中识别该测试。
2.3.3、iostst
当开启fio测试时,开启另一个终端,执行iostat -xmt 3命令,配合fio查看磁盘性能
1、iostat 用于报告CPU(中央处理器)统计信息和整个系统、适配器、tty设备、磁盘和CD-ROM的输入/输出统计信息;通过观察设备处于活动状态的时间(相对于其平均传输速率)来整理实时报告输出,主要用于监视nfs网络文件系统和本地文件系统
参数详解:
-c: 仅显示CPU统计信息.与-d选项互斥.
-d: 仅显示磁盘统计信息.与-c选项互斥.
-k: 以K为单位显示每秒的磁盘请求数,默认单位块.
-m: 以M为单位显示每秒的磁盘请求数
-p: device | ALL,与-x选项互斥,用于显示块设备及系统分区的统计信息.也可以在-p后指定一个设备名,如:# iostat -p hda 或显示所有设备# iostat -p ALL
-t: 在输出数据时,打印搜集数据的时间.
-V: 打印版本号和帮助信息.
-x: 输出扩展信息
常用命令:
iostat -xmt 1: 每秒输出一次cpu&device信息
iostat -c 1 2: 每秒输出一次cpu信息,总共输出2次
iostat -d 2: 间隔2秒输出一次device信息
iostat -xm 1 /dev/sdb: 每秒输出1次sdb的device信息和cpu信息
iostat -p /dev/sdb -d 1 2: 每秒输出一次sdb的分区的设备信息,总共输出2次
关键监控指标解析:
%util: 被I/O操作消耗的CPU百分比。理想情况下应小于80%,超过90%表明磁盘接近饱和,无法处理更多I/O请求。例如当运行高负载fio测试时,若%util持续接近100%,则表明磁盘是性能瓶颈。
await: 平均每次设备I/O操作的等待时间(毫秒)。对于SSD正常范围为0.1-1ms;对于HDD正常范围为10-30ms。如果await显著高于svctm(平均服务时间),则表明I/O队列过长,磁盘响应变慢。
r/s和w/s: 每秒完成的读/写操作数直接反映IOPS性能。r/s和w/s的总和即为TPS(每秒事务数)。
rrqm/s和wrqm/s: 每秒合并的读/写请求数。高值表明内核优化了相邻I/O请求,合并为更大的请求,这在顺序读写中常见
注意事项:
%util代表磁盘使用率,对于hdd类型的磁盘,使用率达到100%代表已经达到磁盘瓶颈,但对于ssd并不代表已经达到瓶颈,因为util是按照(svctm*(r/s+w/s))/1000,对于ssd因为有并发,所以达到100%只能说明单通道达到了100%
2.4、查看从库相关参数
mysql> show variables like '%para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK | #行级别多线程
| slave_parallel_workers | 4 | #线程数量
+------------------------+---------------+
2 rows in set (0.00 sec)
mysql> show variables like '%thread%';
+-----------------------------------------+---------------------------+
| Variable_name | Value |
+-----------------------------------------+---------------------------+
| innodb_purge_threads | 4 |
| innodb_read_io_threads | 4 |
| innodb_thread_concurrency | 0 |
| innodb_thread_sleep_delay | 10000 |
| innodb_write_io_threads | 4 |
| max_delayed_threads | 20 |
| max_insert_delayed_threads | 20 |
| myisam_repair_threads | 1 |
| performance_schema_max_thread_classes | 50 |
| performance_schema_max_thread_instances | -1 |
| pseudo_thread_id | 103475012 |
| thread_cache_size | 512 |
| thread_handling | one-thread-per-connection |
| thread_stack | 196608 |
+-----------------------------------------+---------------------------+
14 rows in set (0.00 sec)
经过DBA同事结合服务器配置进行参数分析,发现参数也没有问题,那么这个主从同步延时高在哪里呢?接着排查
2.5、使用sysbench工具对mysql从服务器压测
2.5.1、在从数据库,创建测试库
mysql> create database dbtest;
Query OK, 1 row affected (0.00 sec)
mysql> grant all on dbtest.* to dbtest@'%' identified by 'dbtest';
Query OK, 0 rows affected, 1 warning (0.00 sec)
2.5.2、准备测试数据
#执行模式为complex,使用了10个表,每个表有10万条数据,客户端的并发线程数为10,执行时间为120秒,每10秒生成一次报告。
[root@mysql2 ~]# sysbench --db-driver=mysql --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=dbtest --mysql-password=dbtest --mysql-db=dbtest --mysql-storage-engine=innodb --tables=10 --table-size=500000 /usr/share/sysbench/oltp_common.lua --forced-shutdown=1 --threads=16 --time=600 --report-interval=1 prepare

#参数解释
--db-driver=mysql: 使用 MySQL 数据库驱动。
--mysql-host=127.0.0.1: 数据库服务器地址,127.0.0.1 表示本地服务器。
--mysql-port=3306: 数据库服务器端口,3306 是 MySQL 的默认端口。
--mysql-user=dbtest: 数据库用户。
--mysql-password=dbtest: 数据库密码。
--mysql-db=dbtest: 要连接的数据库名。
--mysql-storage-engine=innodb: 使用 InnoDB 存储引擎。
--tables=10: 创建 10 个表。
--table-size=500000: 每个表包含 500,000 行数据。
/usr/share/sysbench/oltp_common.lua: 指定测试脚本文件,执行准备操作。
--forced-shutdown=1: 强制关闭所有进程和线程,确保测试环境干净。
--threads=16: 使用 16 个线程进行数据准备。
--time=600: 数据准备时间为 600 秒(10 分钟)。
--report-interval=1: 每 1 秒报告一次进度。
2.5.3、执行测试命令
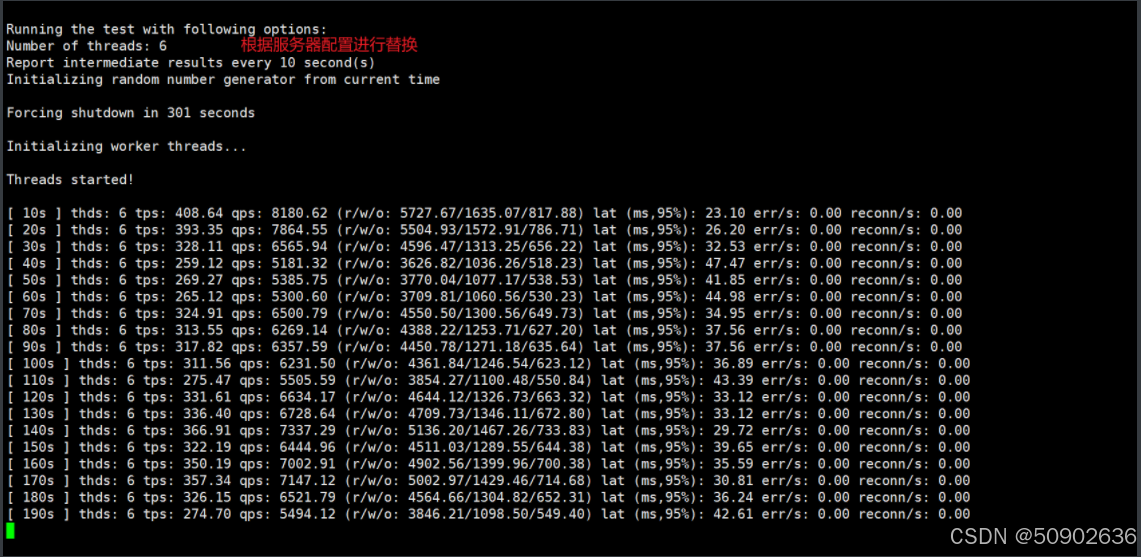
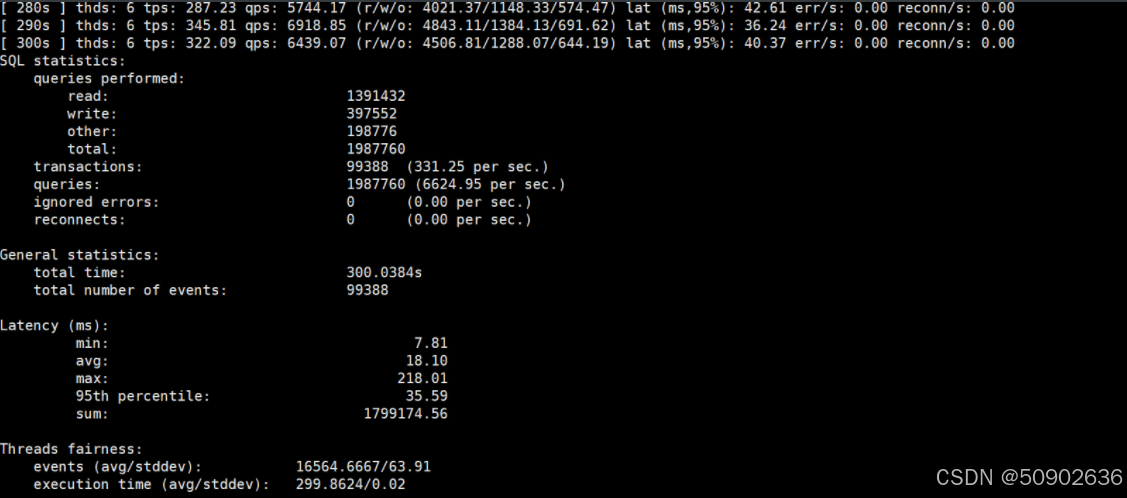
#场景:10张表,每张表个1000万行,16线程,花费300秒进行读写测试, 结果导出到文件中,便于后续分析。
[root@mysql2 ~]# sysbench --db-driver=mysql --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=dbtest --mysql-password=dbtest --mysql-db=dbtest --mysql-storage-engine=innodb --tables=10 --table-size=500000 oltp_read_write --forced-shutdown=1 --threads=16 --time=300 --report-interval=10 run
#参数解释:
--db-driver=mysql: 使用 MySQL 数据库驱动。
--mysql-host=127.0.0.1: 数据库服务器地址,127.0.0.1 表示本地服务器。
--mysql-port=3306: 数据库服务器端口,3306 是 MySQL 的默认端口。
--mysql-user=dbtest: 数据库用户。
--mysql-password=dbtest: 数据库密码。
--mysql-db=dbtest: 要连接的数据库名。
--mysql-storage-engine=innodb: 使用 InnoDB 存储引擎。
--tables=10: 测试使用 10 个表。
--table-size=500000: 每个表包含 500,000 行数据。
oltp_read_write: 指定测试类型为 oltp_read_write,表示执行 OLTP(在线事务处理)读写混合负载测试。这是一个测试脚本,通常包含对数据库的读写操作。
--forced-shutdown=1: 强制关闭所有进程和线程,确保测试环境干净。
--threads=16: 使用 16 个线程来执行测试。
--time=300: 测试持续时间为 300 秒(5 分钟)。
--report-interval=10: 每 10 秒报告一次测试进度。
从测试后的结果看,数据库性能也不存在问题,那主从同步延时高这个问题就很诡异了,测试了磁盘性能、测试了数据库性能,都没有发现问题,而且查看数据库服务器的messages信息,也没有异常~~到这里就给我整不会了.
2.5.4、清理测试数据
[root@mysql2 ~]# sysbench --db-driver=mysql --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=dbtest --mysql-password=dbtest --mysql-db=dbtest --mysql-storage-engine=innodb --tables=10 --table-size=500000 oltp_read_write --threads=16 cleanup
#参数解释:
--db-driver=mysql: 使用 MySQL 数据库驱动。
--mysql-host=127.0.0.1: 数据库服务器地址,127.0.0.1 表示本地服务器。
--mysql-port=3306: 数据库服务器端口,3306 是 MySQL 的默认端口。
--mysql-user=dbtest: 数据库用户。
--mysql-password=dbtest: 数据库密码。
--mysql-db=dbtest: 要连接的数据库名。
--mysql-storage-engine=innodb: 使用 InnoDB 存储引擎。
--tables=10: 指定有 10 个表。
--table-size=500000: 每个表包含 500,000 行数据。
oltp_read_write: 指定测试类型为 oltp_read_write,这通常是一个测试脚本,包含对数据库的读写操作。
--threads=16: 使用 16 个线程来执行测试。
cleanup: 执行清理操作,这通常会删除在测试准备阶段创建的表和数据,恢复数据库到清理前的状态。
总结来说,cleanup 命令用于删除之前由 sysbench 创建的测试表和数据,以便清理测试环境或准备进行新的测试。
2.6、重新做主从关系
最后仅剩重新做主从方法看是否能解决此问题,重新做主从在此处不再过多描述。
经过重新做主从后,分别执行show slave status\G; select * from information_schema.innodb_trx\G; 命令,发现从库还是存在刚开始的大事务,而且主从延时Seconds Behind Master时间也在不断增长,trx_rows_modified数据变化速度也逐渐降低。到此,心态崩了~~~~
2.7、模拟测试
在测试环境MySQL上构造了500w的假数据,然后执行删除操作,发现1-2分钟左右sql执行完成,如下图所示,没有任务异常.两者对比就很明显了。现在大概率怀疑到生产环境从数据库服务器存在问题,后续等封网结束后,找个时间重启从数据库服务器,然后再观察看是否还会存在该问题

二、解决方案一
通过上述的fio和sysbench工具测试磁盘IO、数据库TPS是否达标

如果通过fio测试数据库服务器磁盘IO低于上述标准,那么建议选择使用SSD硬盘
三、解决方案二
因表结构无主键ID导致的主从延迟时间日益增大,执行此解决方案
如果进行了fio和sysbench操作后,发现都没有问题,那么则直接进行此步骤
3.1、查看指定库下的所有表的表结构,确认是否存在主键id
#针对指定库下的所有表
mysql> SELECT
-> TABLE_NAME AS `表名`,
-> IF(COUNT(COLUMN_KEY) > 0, '有主键', '无主键') AS `主键状态`,
-> GROUP_CONCAT(COLUMN_NAME ORDER BY ORDINAL_POSITION) AS `主键列`
-> FROM
-> INFORMATION_SCHEMA.COLUMNS
-> WHERE
-> TABLE_SCHEMA = 'yz_work'
-> AND COLUMN_KEY = 'PRI'
-> GROUP BY
-> TABLE_NAME
-> UNION
-> SELECT
-> TABLE_NAME AS `表名`,
-> '无主键' AS `主键状态`,
-> NULL AS `主键列`
-> FROM
-> INFORMATION_SCHEMA.TABLES
-> WHERE
-> TABLE_SCHEMA = 'yz_work'
-> AND TABLE_NAME NOT IN (
-> SELECT DISTINCT TABLE_NAME
-> FROM INFORMATION_SCHEMA.COLUMNS
-> WHERE TABLE_SCHEMA = 'yz_work'
-> AND COLUMN_KEY = 'PRI'
-> )
-> ORDER BY
-> `表名`;
+---------------------------------------------+--------------+--------------------+
| 表名 | 主键状态 | 主键列 |
+---------------------------------------------+--------------+--------------------+
| tesl_xb | 无主键 | id |
| tghl_xq | 无主键 | id |
| yz_urce | 有主键 | id |
+---------------------------------------------+--------------+--------------------+
#单表确认表结构语句,检查是否有PRIMARY KEY字样
mysql> show create table 表名\G;
3.2、在主库执行增加无意义的自增主键sql
#如果表中有id这个字段,则把alter语句中的id字段随便替换为一个字段名称就行
mysql> ALTER TABLE user ADD COLUMN id INT AUTO_INCREMENT FIRST, ADD PRIMARY KEY (id);
3.3、从库kill 掉当前执行的进程id
首先通过以下语句确定执行的事务sql,以下方为例,一个删除每秒只删除30条,非常的不对劲
#可以通过此语句查看10秒钟 变化了多少行数,然后算出每秒执行的行数
mysql> select * from information_schema.innodb_trx\G; select sleep(10); select * from information_schema.innodb_trx\G;
#查看trx_started字段的开始时间,超过30分钟算大事务
mysql> select * from information_schema.innodb_trx;

通过上述语句确认好对应的大事务语句后,执行下方语句
mysql> show processlist;
+-----+-------------+-----------+------+---------+--------+---------------------------------------+--------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+-----+-------------+-----------+------+---------+--------+---------------------------------------+--------------------------+
| 200 | system user | | NULL | Connect | 82 | Waiting for master to send event | NULL |
| 201 | system user | | NULL | Connect | 0 | Waiting for Slave Worker queue | NULL |
| 202 | system user | | NULL | Connect | 117784 | Executing event | DELETE FROM xxb |
| 203 | system user | | NULL | Connect | 117784 | Waiting for an event from Coordinator | NULL | |
| 214 | root | localhost | NULL | Query | 0 | starting | show processlist |
+-----+-------------+-----------+------+---------+--------+---------------------------------------+--------------------------+
mysql> kill 202;
3.4、在从库再次进行以下操作
#查看执行的gtid
mysql> show slave status\G; #选择最大的这个gtid,当前是5524,那么跳过时则是5525
Executed_Gtid_Set: 4edc6608-394c-11eb-a4d2-fa163efd1323:1-250955524,
5b42d742-394c-11eb-991e-fa163e6fbaa6:1-2,
be893310-692d-11f0-b68b-fa163e6fbaa6:1-659752
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
#关闭从库slave 关闭前一定要先kill掉大事务对应的进程id,否则执行stop slave会卡死
mysql> stop slave;
#跳过事务,在session里设置gtid_next,即跳过当前GTID.
mysql> SET @@SESSION.GTID_NEXT= '4edc6608-394c-11eb-a4d2-fa163efd1323:250955525';
#设置空事物,gtid的生命周期开始了,必须通过显性的提交一个事务来结束
mysql> begin;
mysql> commit;
#恢复事物号
mysql> SET SESSION GTID_NEXT = AUTOMATIC;
#关闭二进制日志记录
mysql> set session sql_log_bin=0;
#关闭从库只读权限
mysql> set global super_read_only=0;
#执行查出来的sql语句
mysql> DELETE FROM wggl_gdhfxxb;
#开启二进制日志记录
mysql> set session sql_log_bin=1;
#开启slave线程;
mysql> start slave;
#开启从库只读权限
mysql> set global super_read_only=1;
#检查processlist、主从延迟时间
mysql> show processlist;
mysql> show slave status\G;
#以上操作执行完成后,会发现主从延迟会急速的降低,最终恢复为0,至此,因为表结构无主键,导致执行delete 语句时产生大事务,以及主从延迟日益增加,最后数据磁盘因为累积的relay中继日志文件过多而爆满,再次期间相当于主从架构的数据库处于`裸奔`状态,即只有一个主库在起作用,从库再此期间就是一个`花瓶`。
3.5、问题分析
1、查看从库mysql配置my.cnf,如下所示
[root@db-1 ~]# grep "binlog" /export/servers/data/my3306/my.cnf
binlog_cache_size = 512K
binlog_rows_query_log_events = on
binlog_checksum = CRC32
#binlog_group_commit_sync_delay = 50
#binlog_group_commit_sync_no_delay_count =100
binlog_format = row
binlog_row_image = full
max_binlog_size = 500M
log-bin = /export/servers/data/my3306/binlog/mysql-bin
relay_log = /export/servers/data/my3306/binlog/mysqld-relay-bin
sync_binlog = 1
#注意:
发现binlog默认使用了row模式,binlog会记录所有的数据变更,这意味着一个 update 或者 delete 语句如果修改了非常多的数据,那么每一行数据的变化都会记录到 binlog 中,最终会产生非常多的 binlog 日志。
从服务器上有一个I/O线程,它会连接到主服务器并请求二进制日志的内容。主服务器收到请求后,会创建一个dump线程来发送二进制日志内容给从服务器。
从服务器将接收到的二进制日志内容写入到中继日志(relay log)。然后,从服务器上的SQL线程会读取中继日志,并在从服务器上重放这些日志记录,以此来更新从服务器上的数据。
从库在处理这些中继日志时,每一行数据的操作都会去尝试定位具体的数据,然后再判断是不是需要执行操作来完成数据变更。如果在某张大表上 update 或者 delete 一些数据,而这张表没有索引,那么定位数据的时候就会变成全表扫描,且 update 或者 delete 的每一行数据都会触发一次全表扫描,从库会产生非常大的延迟,以及从库重放这些中继日志也会非常慢,随着主从延迟的增加,从库钟的中继日志文件越来越多,导致从库磁爆满,主从架构演变为单节点,容易导致单点故障产生。
通过修改参数可能会加速追同步的速度,但是最好的办法还是加上不影响业务的无意义自增主键或者唯一索引,索引搜索数据的效率还是远高于 HASH 算法的。
四、解决方案三
如果不是因为表结构无主键ID导致的主从延迟问题,尝试执行此解决方案
#从库执行以下语句
mysql> set global innodb_flush_log_at_trx_commit = 2; #默认为1
含义:
设置 InnoDB 事务日志的刷新策略为模式 2。
详细解释:
这个参数控制 InnoDB 如何将事务日志(redo log)写入磁盘:
0:日志每秒写入并刷新一次磁盘(性能最好,但可能丢失最多 1 秒的事务)
1:每次事务提交时都写入并刷新磁盘(最安全,但性能最低)
2:每次事务提交时写入日志,但每秒刷新一次磁盘(折中方案)
设置为 2 的效果:
提高了事务提交的性能(减少了磁盘 I/O)
在操作系统崩溃时可能丢失最多 1 秒的事务
在 MySQL 崩溃时不会丢失数据(因为日志已写入文件系统缓存)
mysql> set global sync_binlog = 100; #默认为1
含义:
设置二进制日志(binlog)的同步频率为每 100 次事务提交同步一次。
详细解释:
这个参数控制 MySQL 如何将二进制日志写入磁盘:
0:由文件系统决定何时同步
1:每次事务提交时都同步(最安全,性能最低)
N: 每 N 次事务提交后同步一次
设置为 100 的效果:
显著提高了写入性能
在服务器崩溃时可能丢失最多 99 个事务
降低了磁盘 I/O 压力
#如果查看mysql 错误日志发现以下日志,则在执行下方这个sql
2025-07-27T21:31:42.055251+08:00 178 [Note] Multi-threaded slave statistics for channel '': seconds elapsed = 120; events assigned = 1477633; worker queues filled over overrun level = 42820; waited due a Worker queue full = 35952; waited due the total size = 0; waited at clock conflicts = 191056433300 waited (count) when Workers occupied = 83569 waited when Workers occupied = 0
mysql> set global slave_parallel_workers = 8; #默认为4
含义:
设置从库并行复制工作线程数为 8。
详细解释:
这个参数用于配置 MySQL 复制(主从同步)的并行度:
默认值为 0(单线程复制)
设置大于 0 的值启用并行复制
设置为 8 的效果:
从库可以同时应用 8 个事务,大幅提高复制速度
减少主从延迟(replication lag)
特别适合高并发写入的主库环境
#执行完成后,观察主从延迟时间是否逐渐降低并恢复为0
总结
我遇到的属于从库服务器磁盘IO过低且部分表结构中既没有索引也没有主键ID,同时binlog配置的是row模式,导致执行delete删表操作时,会记录到binlog中,通过mysql主从复制,从库的IO和SQL线程会把复制过来的binlog写到中继日志,然后在从库中重新重放这些日志记录。最终导致主从延迟越来越高,从库服务器数据盘爆满,主库裸奔的现象。因此,在线上环境运行时,一定要规范表结构,类似无主键、无索引的表禁止上线!!!