cuBLAS 是 NVIDIA 提供的 GPU 加速 BLAS 库;使用时需要#include <cublas_v2.h>
如果使用VS,需要添加cublas.lib的链接;如果用命令编译,-l记得加上cublas
cuBLAS 的核心基础概念
cublasStatus_t
类型:枚举类型
作用:表示 cuBLAS API 的返回状态(错误码)。
常用值:
常量 含义 CUBLAS_STATUS_SUCCESS成功 CUBLAS_STATUS_NOT_INITIALIZEDcuBLAS 库未初始化 CUBLAS_STATUS_ALLOC_FAILEDGPU 设备内存分配失败 CUBLAS_STATUS_INVALID_VALUE传入参数无效 CUBLAS_STATUS_ARCH_MISMATCH硬件不支持请求的功能(如 Tensor Core) CUBLAS_STATUS_EXECUTION_FAILED核函数执行失败
返回值检查(典型模式):
cublasStatus_t status = cublasCreate(&handle);
if (status != CUBLAS_STATUS_SUCCESS) {
printf("cuBLAS initialization failed!\n");
}
cublasHandle_t
类型:指向 cuBLAS 库上下文的句柄(类似于会话)。
作用:
所有 cuBLAS 函数都需要它。
cuBLAS 使用 上下文模型,通过
handle管理状态。
生命周期:
通过
cublasCreate()创建。用完后调用
cublasDestroy()销毁。
cublasOperation_t
类型:枚举类型
作用:指定矩阵是否需要 转置。
值:
常量 含义 CUBLAS_OP_N不转置(Normal) CUBLAS_OP_T转置(Transpose) CUBLAS_OP_C共轭转置(Conjugate)
使用场景:cublasSgemm() 等矩阵乘法接口。
例如:
cublasOperation_t transA = CUBLAS_OP_N;
cublasOperation_t transB = CUBLAS_OP_T; // B 矩阵转置
cublasCreate()
cublasStatus_t cublasCreate(cublasHandle_t *handle);
作用:
初始化 cuBLAS 库。
创建 cuBLAS 句柄。
参数:
handle:指向cublasHandle_t的指针,返回创建的句柄。
返回值:
CUBLAS_STATUS_SUCCESS表示成功。
cublasDestroy()
cublasStatus_t cublasDestroy(cublasHandle_t handle);
作用:
释放
cublasHandle_t占用的资源。
参数:
handle:之前用cublasCreate()创建的句柄。
返回值:
成功返回
CUBLAS_STATUS_SUCCESS。
矩阵乘法(GEMM)
函数原型
cublasStatus_t cublasSgemm(
cublasHandle_t handle,
cublasOperation_t transa,
cublasOperation_t transb,
int m, int n, int k,
const float *alpha,
const float *A, int lda,
const float *B, int ldb,
const float *beta,
float *C, int ldc
);
参数说明
transa,transb:CUBLAS_OP_N: 不转置CUBLAS_OP_T: 转置
矩阵维度:
m × k矩阵 Ak × n矩阵 Bm × n矩阵 C
alpha,beta: 标量,计算公式:
C = alpha * op(A) * op(B) + beta * C
lda, ldb, ldc: leading dimension(行主序时是行数)
最小示例:矩阵乘法 C = A × B
#include <cublas_v2.h>
#include <cuda_runtime.h>
#include <iostream>
#include <vector>
#define M 4
#define N 4
#define K 4
int main() {
// 创建 cuBLAS handle
cublasHandle_t handle;
cublasCreate(&handle);
// Host 矩阵
std::vector<float> h_A(M*K), h_B(K*N), h_C(M*N);
for (int i = 0; i < M*K; i++) h_A[i] = 1.0f;
for (int i = 0; i < K*N; i++) h_B[i] = 2.0f;
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, M*K*sizeof(float));
cudaMalloc(&d_B, K*N*sizeof(float));
cudaMalloc(&d_C, M*N*sizeof(float));
cudaMemcpy(d_A, h_A.data(), M*K*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B.data(), K*N*sizeof(float), cudaMemcpyHostToDevice);
const float alpha = 1.0f;
const float beta = 0.0f;
// 调用 cuBLAS GEMM
cublasSgemm(handle,
CUBLAS_OP_N, CUBLAS_OP_N,
M, N, K,
&alpha,
d_A, M,
d_B, K,
&beta,
d_C, M);
cudaMemcpy(h_C.data(), d_C, M*N*sizeof(float), cudaMemcpyDeviceToHost);
// 打印结果
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
std::cout << h_C[i + j*M] << " "; // 注意列主序
}
std::cout << "\n";
}
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cublasDestroy(handle);
}
矩阵转置or矩阵加法
cuBLAS 提供了 cublasSgeam:
cublasSgeam 是 cuBLAS 提供的矩阵加法/转置操作接口,可以完成:
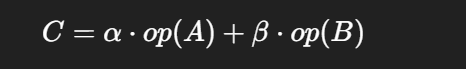
其中 op(X) 表示矩阵 X 是否转置。
cublasStatus_t cublasSgeam(
cublasHandle_t handle, // cuBLAS 句柄
cublasOperation_t transa, // A 是否转置 (CUBLAS_OP_N 或 CUBLAS_OP_T)
cublasOperation_t transb, // B 是否转置
int m, // C 的行数
int n, // C 的列数
const float *alpha, // 缩放系数 α
const float *A, // 矩阵 A
int lda, // A 的 leading dimension (步长)
const float *beta, // 缩放系数 β
const float *B, // 矩阵 B
int ldb, // B 的 leading dimension
float *C, // 结果矩阵 C
int ldc // C 的 leading dimension
);
handle:cuBLAS 上下文。
transa / transb:
CUBLAS_OP_N→ 不转置CUBLAS_OP_T→ 转置
m, n:结果矩阵 C 的维度 (m 行 n 列)。
alpha, beta:系数,通常
alpha = 1.0f,beta = 1.0f。A, lda:矩阵 A 的指针和 leading dimension。
B, ldb:矩阵 B 的指针和 leading dimension。
C, ldc:结果矩阵 C 的指针和 leading dimension。
⚠ leading dimension (lda, ldb, ldc):
cuBLAS 默认使用 列主存储(和 Fortran 一致),所以 lda = A 的行数,即 A 每列元素的间隔。
可以实现 矩阵转置(单独把 beta 设为 0)。
可以实现 矩阵加法。
可以实现 带缩放的线性组合。
示例代码
#include <cuda_runtime.h>
#include <cublas_v2.h>
#include <iostream>
int main() {
int m = 2, n = 3;
float alpha = 1.0f, beta = 1.0f;
// Host 数据
float h_A[6] = {1, 2, 3, 4, 5, 6}; // 2x3
float h_B[6] = {10, 20, 30, 40, 50, 60};
float h_C[6];
// Device 指针
float *d_A, *d_B, *d_C;
cudaMalloc((void**)&d_A, 6 * sizeof(float));
cudaMalloc((void**)&d_B, 6 * sizeof(float));
cudaMalloc((void**)&d_C, 6 * sizeof(float));
cudaMemcpy(d_A, h_A, 6 * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, 6 * sizeof(float), cudaMemcpyHostToDevice);
cublasHandle_t handle;
cublasCreate(&handle);
// C = A^T + B
cublasSgeam(handle,
CUBLAS_OP_T, CUBLAS_OP_N,
m, n, // C 大小 (m x n)
&alpha,
d_A, n, // A^T,所以 lda = n(原矩阵的列数)
&beta,
d_B, m, // B 不转置,ldb = m
d_C, m); // C 不转置,ldc = m
cudaMemcpy(h_C, d_C, 6 * sizeof(float), cudaMemcpyDeviceToHost);
std::cout << "Result C:\n";
for (int i = 0; i < 6; i++) {
std::cout << h_C[i] << " ";
}
cublasDestroy(handle);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}
向量乘矩阵
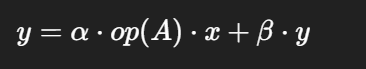
op(A)表示 A 或 Aᵀ(取决于trans参数)x和y是向量alpha、beta是缩放因子
cublasStatus_t cublasSgemv(
cublasHandle_t handle,
cublasOperation_t trans, // 是否转置 A
int m, int n, // 矩阵 A 的维度 (m x n)
const float *alpha, // 缩放因子 alpha
const float *A, int lda, // 矩阵 A
const float *x, int incx, // 向量 x
const float *beta, // 缩放因子 beta
float *y, int incy // 向量 y
);
trans:CUBLAS_OP_N→ A 不转置,维度 m×nCUBLAS_OP_T→ A 转置,维度 n×m
lda:leading dimension,通常等于m(A 的行数)incx、incy:向量步长,通常 = 1
示例代码:
#include <cublas_v2.h>
#include <cuda_runtime.h>
#include <iostream>
int main() {
cublasHandle_t handle;
cublasCreate(&handle);
const int m = 3, n = 3;
float h_A[m*n] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; // 3x3 矩阵
float h_x[n] = { 1, 1, 1 }; // 向量
float h_y[m] = { 0, 0, 0 };
float *d_A, *d_x, *d_y;
cudaMalloc(&d_A, m*n*sizeof(float));
cudaMalloc(&d_x, n*sizeof(float));
cudaMalloc(&d_y, m*sizeof(float));
cudaMemcpy(d_A, h_A, m*n*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_x, h_x, n*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, m*sizeof(float), cudaMemcpyHostToDevice);
float alpha = 1.0f;
float beta = 0.0f;
// y = alpha * A * x + beta * y
cublasSgemv(handle, CUBLAS_OP_N, m, n,
&alpha, d_A, m, d_x, 1, &beta, d_y, 1);
cudaMemcpy(h_y, d_y, m*sizeof(float), cudaMemcpyDeviceToHost);
std::cout << "Result y: ";
for (int i = 0; i < m; i++) std::cout << h_y[i] << " ";
std::cout << std::endl;
cudaFree(d_A); cudaFree(d_x); cudaFree(d_y);
cublasDestroy(handle);
return 0;
}
矩阵 × 向量(gemv)其实可以用 矩阵 × 矩阵(gemm)来替代,但有几点需要注意:
性能原因:
gemv是 BLAS Level 2 操作,专门针对 矩阵-向量做了优化,尤其在小规模问题上,它的内存访问模式和寄存器利用更高效。内存开销:
用gemm处理 m×n 矩阵 × n×1 向量,cuBLAS 内部仍按矩阵矩阵方式调度,会引入不必要的开销。语义清晰:
gemvAPI 直接说明这是矩阵-向量操作,避免错误。
总结:
gemm是通用 API,可以替代gemv。但如果只是单次
矩阵 × 向量,gemv更高效。深度学习场景,通常是批处理(
GEMMdominate),所以主流框架用gemm。
多流并发
cublasHandle_t 绑定 CUDA 流:
默认情况下,cuBLAS 的操作运行在 默认流(stream 0) 上,这意味着 cuBLAS 操作会和其他默认流的操作 顺序执行,无法并发。
绑定流后(通过
cublasSetStream(handle, stream)):cuBLAS 的运算将提交到指定的 CUDA 流
可以和其他流中的 kernel 并发执行,实现任务流水线和异步调度
对多 GPU 或 pipeline 加速非常重要(比如计算和数据拷贝重叠)
cuBLAS系列函数的本质:
cuBLAS API(如
cublasSgemm)是主机端函数,它的作用是:通过
handle向 CUDA 驱动提交任务把矩阵乘法封装成 GPU 内核,并异步调度到 GPU 上运行
计算实际发生在 GPU 上,不是 CPU
调用
cublasSgemm后,不会阻塞主机(异步执行),除非你显式调用cudaDeviceSynchronize或访问 GPU 结果
核心区别:
cublasSgemm不做计算本身,它只是 发起任务CUDA 流 +
handle控制 任务在哪个流上执行默认流会串行执行,多个流能并发
举个并发例子:
cublasHandle_t handle;
cublasCreate(&handle);
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
// 第一批数据在 stream1
cublasSetStream(handle, stream1);
cublasSgemm(handle, ... /* batch1 */);
// 第二批数据在 stream2
cublasSetStream(handle, stream2);
cublasSgemm(handle, ... /* batch2 */);
// 两个 GEMM 并行执行
cudaStreamSynchronize(stream1);
cudaStreamSynchronize(stream2);
如果学习过我的Boost.Asio文章的话,cublasHandle_t非常像Boost.Asio里的io_context