目录
3.3 多参数回归(Multivariate Linear Regression)
(2)梯度下降法(Gradient Descent)【数值解】
3.4.1 最小二乘法(Least Squares Method)
一、写在前面的话
1.1 前言导览
“线性回归是理解所有监督学习算法的钥匙”,在机器学习中,线性回归是相对来说最方便初学者入门的回归算法类型,因此我们从这里开始进行学习。结合上之前讲的KNN分类算法,通过学习两个分别代表着分类与回归的基础算法,我们可以更全面更深入地理解机器学习中的模型训练阶段。接下来文章将从基础性概念开始讲解,而后主要分析有关线性回归的概念和知识。
1.2 分类与回归
模型训练阶段(Model Training Phase)是指通过已有数据让模型学习如何进行预测或分类的过程,“分类(Classification)”与“回归(Regression)”是其中的两种基本任务类型,依据我们想预测的“目标变量(也叫输出变量)”的类型而区分。
- 分类的任务是:预测一个离散的类别标签,输出是有限个类别中的一个
回归任务的目标是:预测一个连续的数值型结果,输出是一个数值结果
回归一词最早来源于统计学,表示“变量间的关系”。在机器学习中,我们学习一个函数 f(x) 近似表示输入 x 与输出 y 之间的关系,使得输出尽可能接近真实值。
回归分析:建立连续型变量之间的数学关系,预测一个或多个自变量如何影响因变量。
1.3 数据的类型
分类的目标变量是标称型数据,回归是对连续型数据做出预测。
1.3.1 标称型数据(Nominal Data)
概念:用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
特点:
- 无序性:标称数据的各个类别之间没有固有的顺序关系。例如,“性别”可以分为“男”和“女”,但“男”和“女”之间不存在大小、高低等顺序关系。
- 非数值性:标称数据不能进行数学运算,因为它们没有数值含义。你不能对“颜色”或“品牌”这样的标称数据进行加减乘除。
- 多样性:标称数据可以有很多不同的类别,具体取决于研究的主题或数据收集的目的。
1.3.2 连续型数据(Continuous Data)
概念:表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等。
特点:
- 可测量性:连续型数据通常来源于物理测量,如长度、重量、温度、时间等,这些量是可以精确测量的。
- 无限可分性:连续型数据的取值范围理论上是无限可分的,可以无限精确地细分。例如,你可以测量一个物体的长度为2.5米,也可以更精确地测量为2.53米,甚至2.5376米,等等。
- 数值运算:连续型数据可以进行数学运算,如加、减、乘、除以及求平均值、中位数、标准差等统计量。
二、基础知识铺垫
2.1 回归的概念
回归方程是用于表达输入变量(自变量)与输出变量(因变量)之间的关系的一种数学模型,比方说 y = ax + b ,其中 a , b 是方程的系数,求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做出预测就非常容易了,所以我们的模型训练的目的可以看作是求解这些回归系数的过程。
2.2 矩阵与矩阵运算
矩阵是描述和操作线性空间的基本工具,是线性代数中最重要的结构之一。
2.2.1 矩阵概念
(1)矩阵可用于表达线性方程:
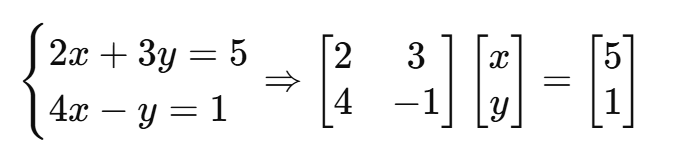
(2)在机器学习中,矩阵的每行表示一个样本,每列表示一个特征。
(3)在图像处理中,图片的每个像素就是矩阵的一个元素。
(4)特殊矩阵有:零矩阵、对角矩阵、单位矩阵、对称矩阵、稀疏矩阵、转置矩阵等。
2.2.2 矩阵基本介绍
(1)矩阵加法
前提条件:两个矩阵维度相同。
方法:对应位置元素相加或相减。
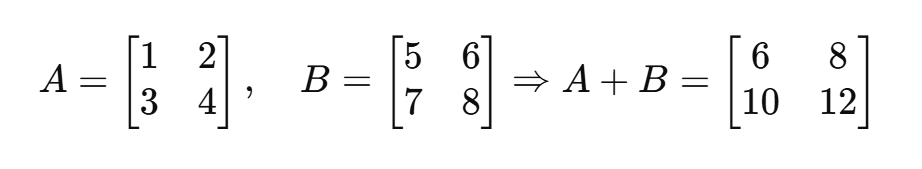
(2)矩阵数乘
即数与矩阵的乘法,每个元素对应乘上一个标量即可:
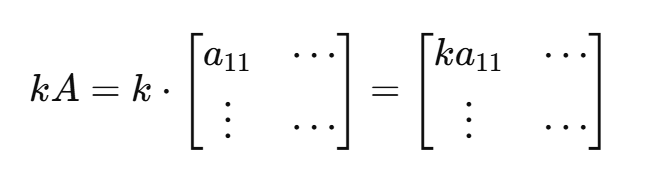
(3)矩阵乘法
条件:矩阵 A 的列数 = 矩阵 B 的行数。
方法:第 i 行点乘第 j 列,得到新矩阵的第 ( i , j ) 元素。
设 A 为 m×n 矩阵,B 为 n×p 矩阵,那么乘积 C = A B 是一个 m×p 矩阵。
例子1:
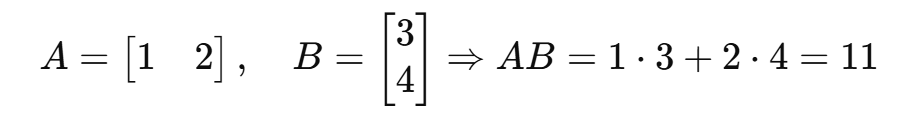
例子2:
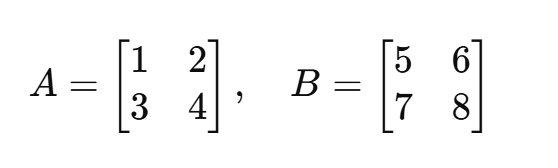
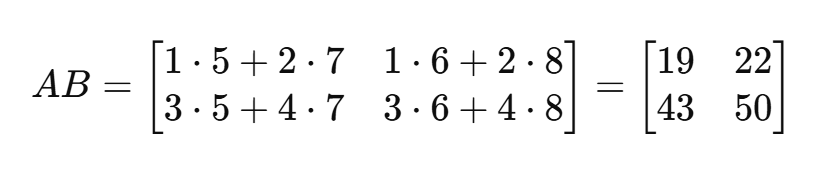
(4)转置(Transpose)
将原矩阵的行 “变成” 列,列 “变成” 行:

(5)单位矩阵
单位矩阵:主对角线元素均为 1,其余元素均为 0
- 单位矩阵是对称矩阵,其转置等于自身
示例:

(6)逆矩阵
定义:

示例:

2.3.3 矩阵运算性质
(1)基本运算性质
| 性质名称 | 表达式 | 说明 |
|---|---|---|
| 加法交换律 | A+B = B+A | 矩阵加法可交换 |
| 加法结合律 | (A+B) + C = A + (B+C) | |
| 乘法结合律 | A(BC) = (AB)C | 注意乘法不交换,但结合 |
| 乘法分配律 | A(B+C) = AB + AC | |
| 标量分配律 | α(A+B) = αA + αB |
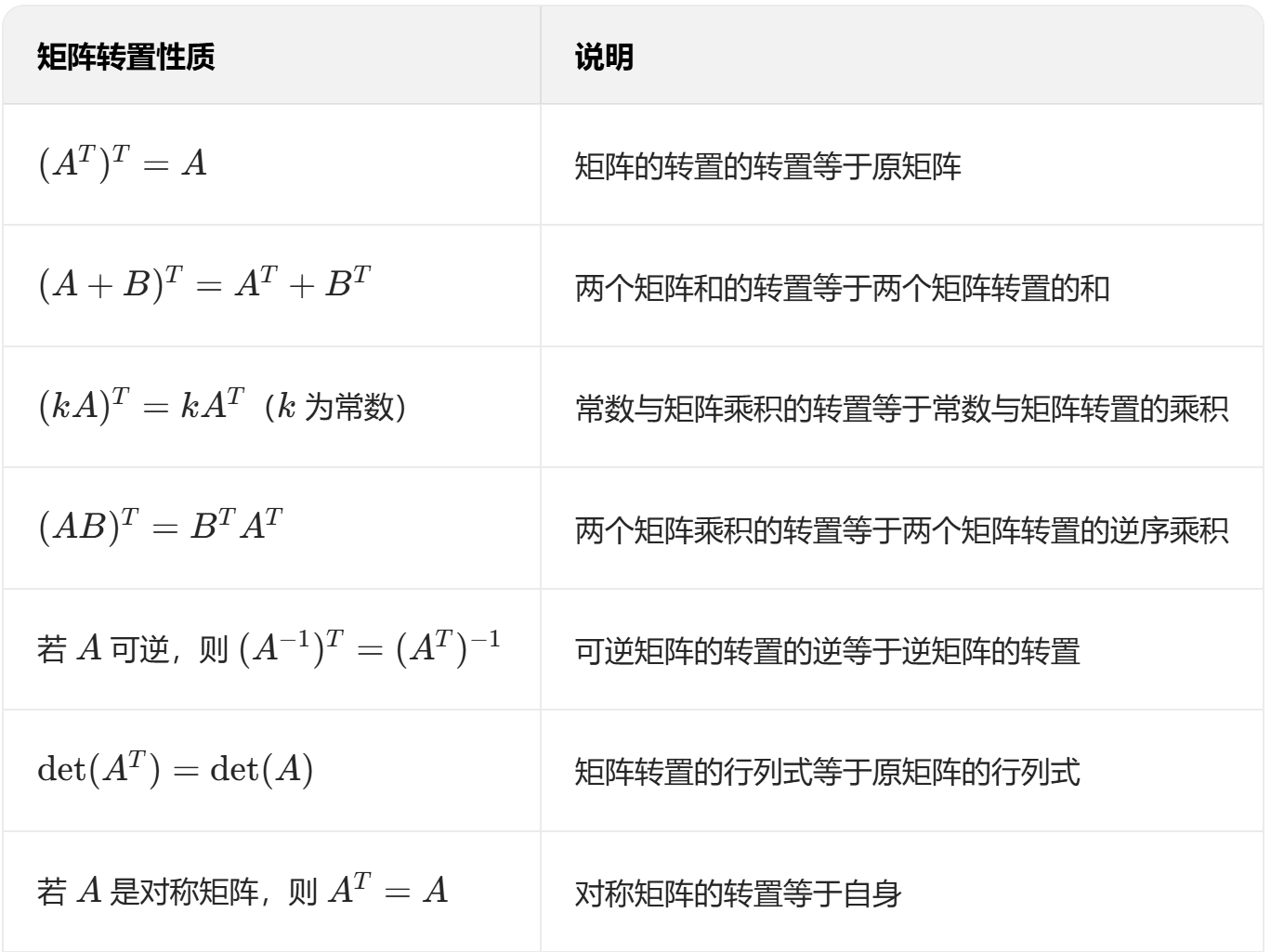
(2)转置性质
(3)逆矩阵性质
仅对可逆方阵成立:

(4)单位矩阵
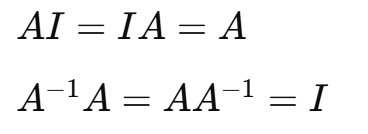
2.3.4 矩阵求导法则
矩阵的偏导公式在机器学习的梯度下降、反向传播中非常常见。
(1)常用求导公式
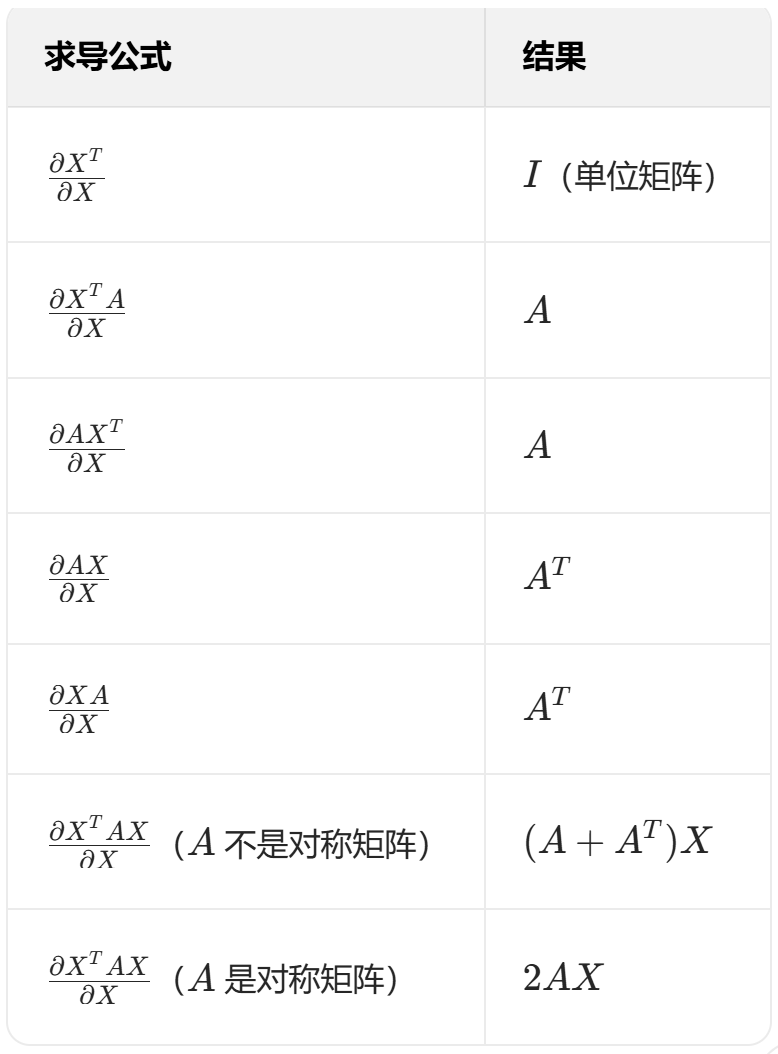
(2)关于链式法则求导

2.3.5 矩阵除法的实现
在线性代数中,没有真正意义上的“矩阵除法”,因为矩阵不像数那样有一般的“除法”操作。但我们可以用其他方式来实现类似“除法”的效果。
假设我们要求解的是:AX = B,令其左右两边都同左乘A的逆矩阵:
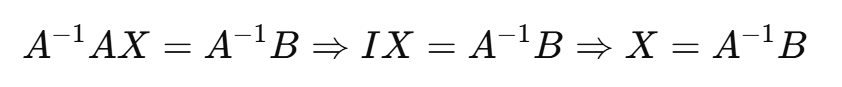
三、线性回归详解
3.1 基本概念
3.1.1 概念介绍
线性回归是一种最基础的监督学习算法,用于回归问题,即预测一个连续数值的输出。其目标是:
找出输入特征 x 和输出目标值 y 之间的一个线性关系。
3.1.2 概念引入
假设理想情况下,在森林中随机选择了一些树木,其高度 Y 与生长时间 X 存在正相关关系,统计成(X,Y)的格式,将其坐标点标在坐标图上:
数据:[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]
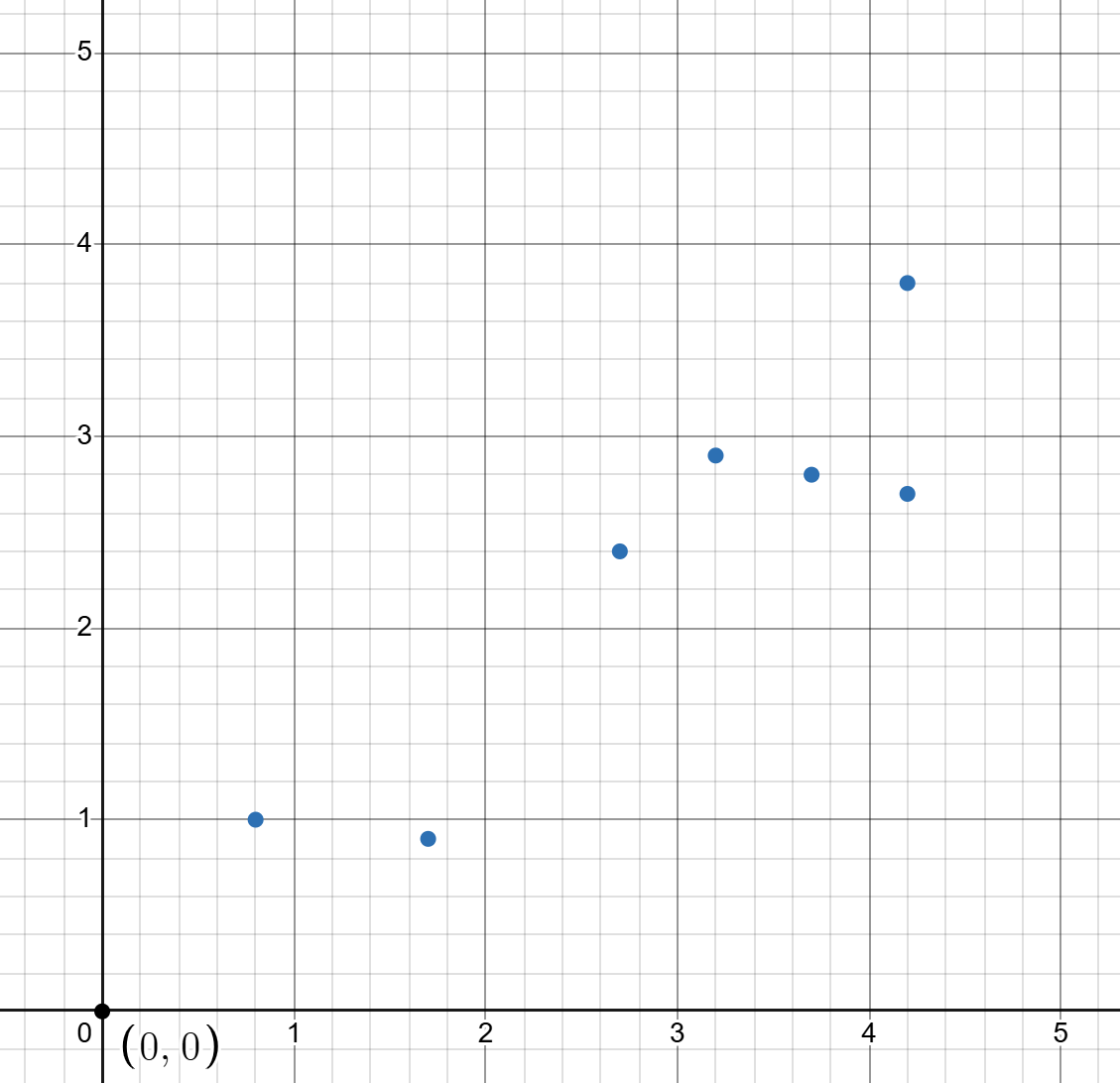
我们的目的就是通过这些散点来拟合一条直线,使该直线能尽可能准确的描述 X 与 Y 的关系,这样的话我们就可以通过树木的生长年龄大概判断其生长高度了。
于是我们假定线性模型:Y = wX +b 用来描述是最合适的,此处暂且使 b = 0,那么通过不同的 w(权重系数) 我们可以得到不同的直线,如下方的图,我们可以感觉出:红色实线最接近实际数据点。
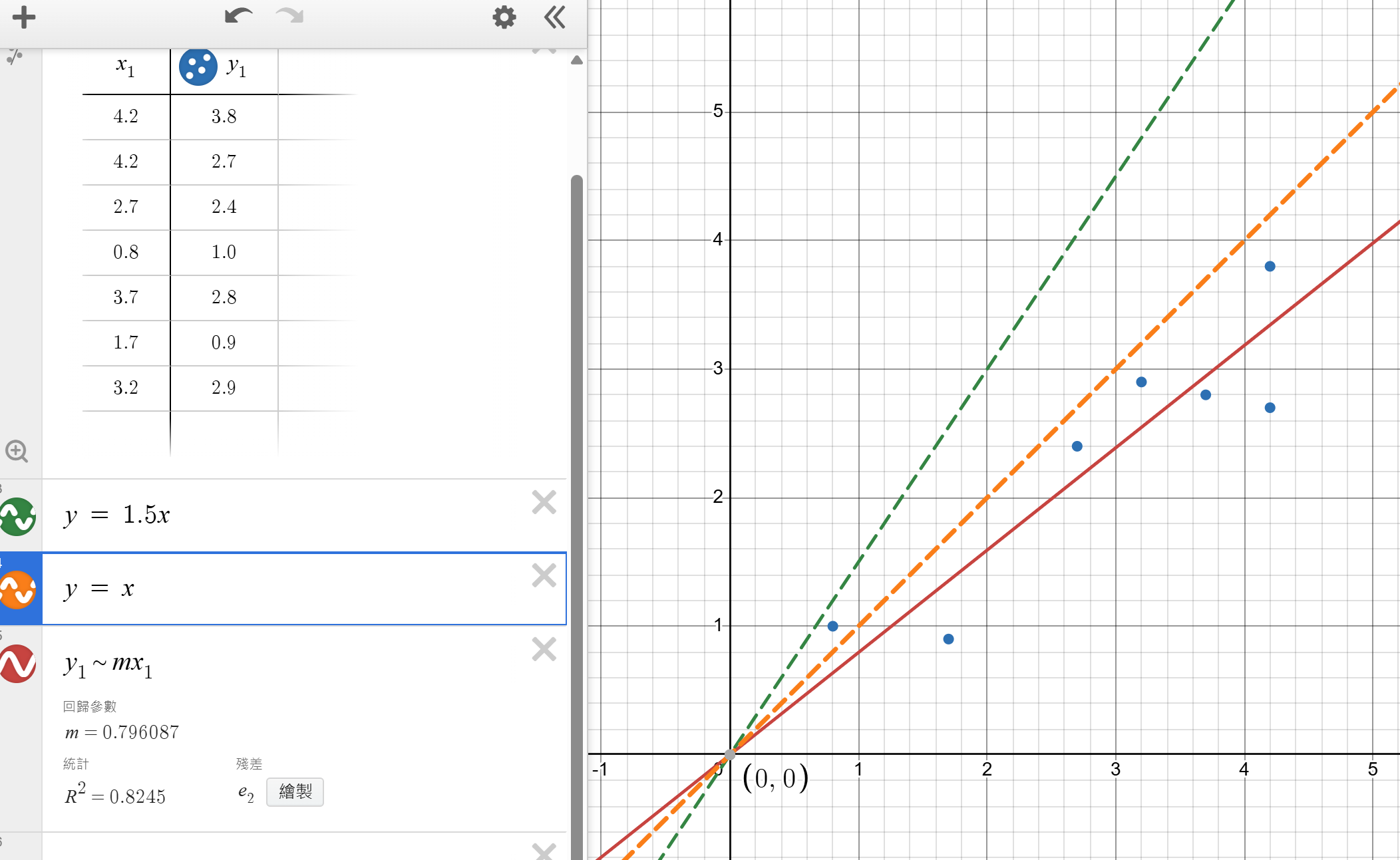
其实我们的模型训练的最终目的,就是要确定模型参数(如上面的 w ),找出最合适的值也就是完成了对模型的初步训练。
3.2 损失函数
3.2.1 承接上文
那么,我们如何能够得出上图中红色的直线呢,这就要引入一个概念:损失函数。通过计算最小损失能够让我们确定下来我们所需要的模型参数。
在机器学习中,损失函数(Loss Function)是一个非常核心的概念,它用来衡量模型预测值和真实值之间的差距。我们希望通过不断优化损失函数,让模型输出的预测结果越来越接近真实数据。
这里我们令直线的方程为 Y = wX + b,对于同水平值 X 代入所得出的结果我们记为 Y^
如下图,其含义为 Y 代表 X 对应的真实值即真实的生长高度,而我们通过线性模型预测得出的 Y^ 代表着模型的预测值,其差距就是 (Y^ - Y)。如果能使得这个差值越小,就说明我们的预测直线离实际的数据点越接近,我们的预测模型就越准确。
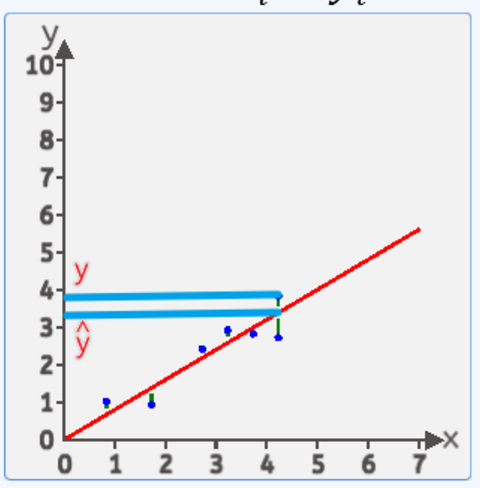
由于数据点可能分布在直线上下两侧,那么差值可能为负数,因此我们不妨给其加上平方:(Y^ - Y)^2,令其为水平值为X时,对应的差距平方值 e (X)。将其全部的对应值加起来,就是我们的损失函数。
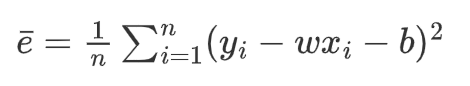
至此,我们就可以去求取 e(X) 的最小值来达到我们的最初目的:找到最合适的拟合直线。
把x_1, x_2, x_3 ... 带入进去 然后得出:
y_1 = w*x_1 + b
y_2 = w*x_2 + b
y_3 = w*x_3 + b
……
这里先假定 b = 0 ,最简化我们的计算过程:

这就是一个简单的抛物线求极值的问题了,求得 w=0.795 时损失函数取得最小值。
于是拟合直线也就确定了下来,我们成功得到了一个简单的直线预测模型 Y = 0.795 * X
3.2.2 损失函数
上面所使用到的 e (X) 我们称为均方差损失(Mean Squared Error,MSE)
我们主要介绍一下损失函数的大概分类,以及常用的几个损失函数。
(1)分类
| 损失函数 | 类型 | 特点/适用场景 |
|---|---|---|
| MSE | 回归 | 惩罚大误差严重,平滑 |
| MAE | 回归 | 鲁棒,对异常值不敏感 |
| Huber | 回归 | 综合 MSE 和 MAE |
| Log-Cosh | 回归 | 平滑、对异常值较稳健 |
| Cross Entropy | 分类 | 标准分类损失,适合 softmax 输出 |
| KL 散度 | 分类 | 比较两个概率分布 |
| Focal Loss | 分类 | 类别不平衡问题 |
| Hinge Loss | 分类 | SVM 专用损失函数 |
| Contrastive Loss | 度量学习 | 判断样本是否相似 |
| Triplet Loss | 度量学习 | 学习嵌入空间中样本之间的相对距离 |
| CTC Loss | 序列任务 | 可变长输入输出的对齐 |
(2)常用
- 均方误差(MSE,Mean Squared Error):平滑、可导,适合梯度下降
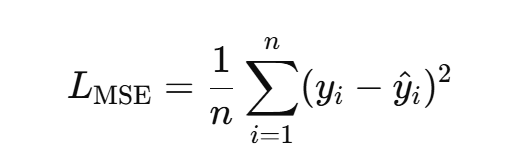
- 平均绝对误差(MAE,Mean Absolute Error):比 MSE 更鲁棒(不太受离群值影响)
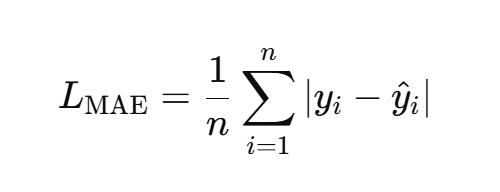
- 交叉熵损失(Cross Entropy Loss):C 是类别数,适用几乎所有的分类任务
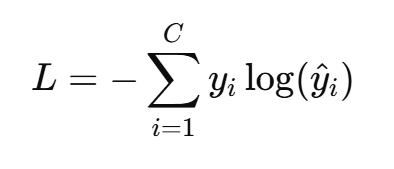
3.3 多参数回归(Multivariate Linear Regression)
在实际情况下,往往影响结果 y 的因素不止1个,这时x就从一个变成了n个,x_1, x_2, x_3 ... x_n, 上面的思路是对的,但是求解的公式就不再适用了,这时候就要分析多参数的回归情况了(也叫多元线性回归)。
3.3.1 概念
定义:当我们有多个输入变量(特征)时,用来拟合一个连续输出变量 y 的模型。
回归方程形式: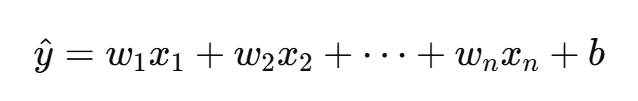
我们可以进一步用矩阵来表示:
W = [ w1, w2, ... , wn, b ],X = [ x1, x2, ... , xn ],则可简化为 Y^ = WT × X
3.3.2 解决方法
对于多参数的回归我们可以使用如下的方法:
(1)正规方程(Normal Equation)【闭式解】
一种不用迭代的方法,直接用线性代数解出最优解(一般不推荐这个方法):
- 优点:计算表达式简单、直接,数学上很严谨
- 缺点:当特征很多时计算量较大,对内存要求高
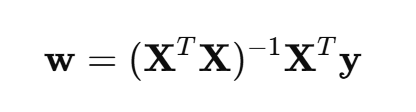
(2)梯度下降法(Gradient Descent)【数值解】
不断迭代优化权重 w ,使损失函数最小,常用的损失函数是 均方误差(MSE):
- 优点:适合高维数据、容易扩展
- 缺点:需要选择合适的学习率、可能陷入局部最优
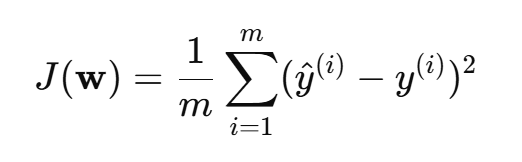
权重更新规则: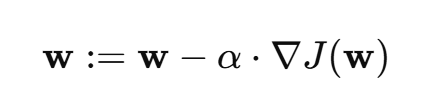
α:学习率,标量
∇ J :损失函数对 w 的梯度
(3)正则化回归(防止过拟合)
1、Ridge 回归(L2 正则):
- 平滑权重,防止过拟合
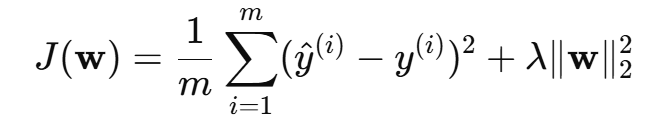
2、Lasso 回归(L1 正则):
- 可以做特征选择(将一些 w 变为 0)
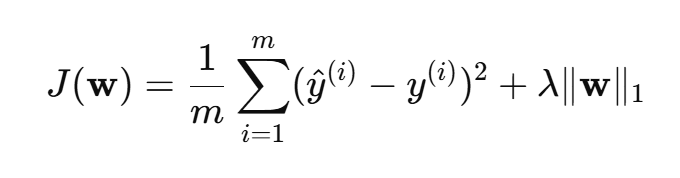
3.4 关于正规方程闭式解
3.4.1 最小二乘法(Least Squares Method)
(1)概念
最小二乘法是一种用于拟合线性模型的方法,它的目标是让模型预测值与实际值之间的误差的平方和最小。它是线性回归的核心思想之一,用于确定最佳回归直线(或超平面)对应的参数。
(2)引入
给定数据集: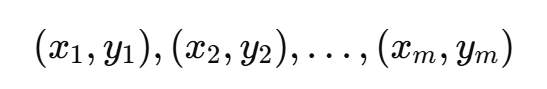
要找到一条直线: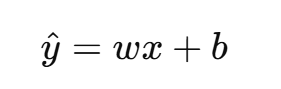
使得所有预测值 y^ 与实际值 y 的误差尽可能小。
我们使用均方差损失来确定模型系数,那么,最小二乘法目标就是求解:
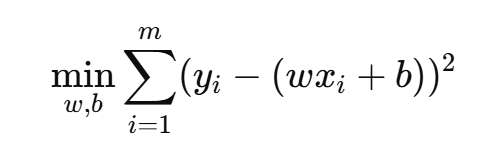
最小二乘损失函数(MSE):
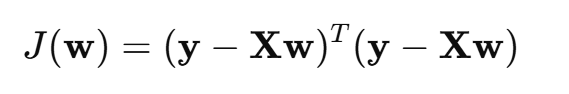
(3)公式
对于多参数线性回归,其最优解为:
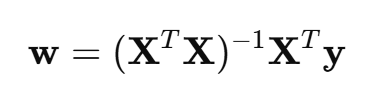
这是一个闭式解,可以直接解出,不需要迭代。
3.4.2 公式推导
这一部分需要用到之前的基础知识,不是很理解的读者也可以跳过这一部分,不影响后续内容。
已知损失函数:
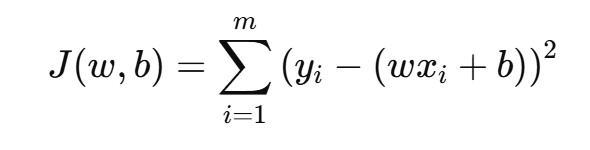
参考上一节,我们需要得到 :Y^ = WT × X
让W = [ w1, w2, ... , wn, b ],为了将偏置 b 包含在矩阵运算中,我们通常在输入特征矩阵 X 中添加一列全为 1 的截距项(intercept term)。新的输入特征矩阵 X 变为 m ×(n+1) 的矩阵:
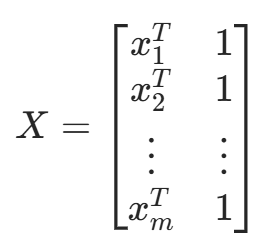
这样,参数向量 W 中的偏置 b 可以与权重 w 一起通过矩阵乘法进行计算。
那么便有:


即推导出:
3.4.3 最小二乘法代码示例
# 最小二乘法
from sklearn.linear_model import LinearRegression
import numpy as np
data = np.array([[]])
x = data[:,:-1]
y = data[:,-1]
model = LinearRegression(fit_intercept=False)
# XW = Y
model.fit(x,y) # 训练模型
print("模型系数:",model.coef_) # 模型系数,W矩阵
print("模型截距:",model.intercept_) # b也即w0
score = model.score(x,y)
print("准确率:",score)3.5 代码示例
from sklearn.linear_model import LinearRegression
import numpy as np
data=np.array([[ 0, 14, 8, 0, 5,-2, 9,-3, 399],
[ -4, 10, 6, 4,-14,-2,-14, 8,-144],
[ -1, -6, 5,-12, 3,-3, 2,-2, 30],
[ 5, -2, 3, 10, 5,11, 4,-8, 126],
[-15,-15,-8,-15, 7,-4,-12, 2,-395],
[ 11,-10,-2, 4, 3,-9, -6, 7, -87],
[-14, 0, 4, -3, 5,10, 13, 7, 422],
[ -3, -7,-2, -8, 0,-6, -5,-9,-309]])
x=data[:,:-1]
y=data[:,-1]
print(x)
print(y)
# 创建模型
model=LinearRegression(fit_intercept=False)
model.fit(x,y) # 训练
print(model.coef_)
print(model.intercept_)
# 进行预测
y_pred=model.predict([[0,14,8,0,5,-2,9,-3],
[-4,10,6,4,-14,-2,-14,8],
[-1,-6,5,-12,3,-3,2,-2],
[5,-2,3,10,5,11,4,-8],
[-15,-15,-8,-15,7,-4,-12,2],
[11,-10,-2,4,3,-9,-6,7],
[-14,0,4,-3,5,10,13,7],
[-3,-7,-2,-8,0,-6,-5,-9]])
print(y_pred) # 预测值END