摘要:具备可验证奖励的大规模强化学习(RLVR)已证明其在利用大型语言模型(LLMs)潜力以完成单轮推理任务方面的有效性。在现实推理场景中,大型语言模型常可借助外部工具辅助完成任务求解。然而,当前的强化学习算法未能充分平衡模型固有的长程推理能力与多轮工具交互熟练度。为填补这一空白,我们提出了智能体强化策略优化(Agentic Reinforced Policy Optimization,ARPO)算法,这是一种专为训练基于多轮大型语言模型的智能体而设计的新型智能体强化学习算法。初步实验表明,在与外部工具交互后,大型语言模型往往会表现出高度不确定的行为,其特征是生成令牌的熵分布增加。基于这一观察,ARPO引入了基于熵的自适应推演机制,动态平衡全局轨迹采样与步级采样,从而在工具使用后不确定度高的步骤促进探索。通过集成优势归因估计,ARPO使大型语言模型能够在逐步工具使用交互中内化优势差异。我们在计算推理、知识推理和深度搜索领域的13个具有挑战性的基准测试中进行的实验表明,ARPO优于轨迹级强化学习算法。值得注意的是,ARPO仅使用现有方法所需工具使用预算的一半,即可实现性能提升,为基于大型语言模型的智能体与实时动态环境的对齐提供了一种可扩展的解决方案。我们的代码和数据集已在https://github.com/dongguanting/ARPO 发布。Huggingface链接:Paper page,论文链接:2507.19849
研究背景和目的
研究背景
近年来,大规模强化学习与可验证奖励(RLVR)在利用大型语言模型(LLMs)进行单轮推理任务中展现出了巨大的潜力。然而,在实际的推理场景中,LLMs往往需要借助外部工具来完成复杂的任务。这些任务不仅要求模型具备长程的推理能力,还需要在多轮交互中有效利用工具。然而,当前的强化学习算法在平衡模型内在的长程推理能力和多轮工具交互熟练度方面存在不足。具体来说,现有的轨迹级强化学习算法(如GRPO、DAPO等)往往强调完整轨迹的采样,而忽视了在多轮交互中每一步工具使用的精细行为学习。
研究目的
本研究旨在填补现有强化学习算法在训练基于多轮LLMs的智能体方面的空白。通过提出一种新的智能体强化学习算法——智能体强化策略优化(Agentic Reinforced Policy Optimization, ARPO),本研究旨在实现以下目标:
- 提高多轮工具交互的效率:ARPO算法通过引入基于熵的自适应推演机制,动态平衡全局轨迹采样与步级采样,从而在工具使用后不确定度高的步骤促进探索。
- 增强LLMs的推理能力:通过集成优势归因估计,ARPO使LLMs能够在逐步工具使用交互中内化优势差异,从而提升其推理能力。
- 提供可扩展的解决方案:ARPO算法在保持高性能的同时,显著减少了工具使用的预算,为基于LLMs的智能体与实时动态环境的对齐提供了一种可扩展的解决方案。
研究方法
算法设计
ARPO算法的核心在于其独特的自适应推演机制和优势归因估计方法。具体来说:
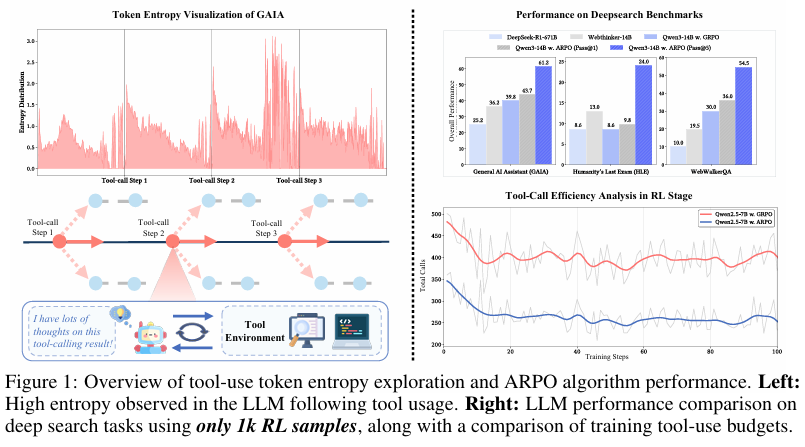
- 自适应推演机制:ARPO算法通过监测LLMs在与外部工具交互后生成令牌的熵分布变化,来识别不确定度高的步骤。在不确定度高的步骤,ARPO会增加步级采样的比例,从而在这些步骤中促进探索。
- 优势归因估计:ARPO算法引入了共享优势和个体优势的概念。共享优势用于分配给在同一推理路径上的所有令牌,而个体优势则分配给分支路径上的不同令牌。这种方法鼓励模型在逐步工具使用交互中内化优势差异。
实验设计
为了验证ARPO算法的有效性,研究者在计算推理、知识推理和深度搜索领域的13个具有挑战性的基准测试中进行了实验。实验采用了以下设置:
- 模型选择:使用了Qwen2.5和Qwen3系列模型,包括8B和14B参数版本。
- 训练数据:使用了Tool-Star数据集和WebSailor数据集中的样本进行训练。
- 评估指标:采用F1分数作为主要评估指标,对于需要生成答案的任务,使用LLM-as-Judge方法进行评估。
- 基线方法:选择了直接推理、轨迹级强化学习算法(如GRPO、DAPO、REINFORCE++)和基于工作流程的搜索代理作为基线方法。
研究结果
性能提升
实验结果表明,ARPO算法在多个基准测试中均优于基线方法。具体来说:
- 计算推理和知识推理任务:在AIME24、AIME25、MATH500、GSM8K和MATH等基准测试中,ARPO算法相比基线方法平均提高了4%的准确率。
- 深度搜索任务:在GAIA、Humanity’s Last Exam(HLE)和xbench等深度搜索任务中,ARPO算法显著优于基线方法。特别是在HLE和GAIA基准测试中,ARPO算法使用14B参数的Qwen3模型分别达到了43.2%和61.2%的准确率。
工具使用效率
ARPO算法在保持高性能的同时,显著减少了工具使用的预算。具体来说:
- 工具使用次数减少:ARPO算法仅需现有方法所需工具使用预算的一半,即可实现相同的性能提升。
- 采样效率提高:通过自适应推演机制,ARPO算法在不确定度高的步骤中增加了步级采样的比例,从而提高了采样的多样性。
研究局限
尽管ARPO算法在多个基准测试中展现出了优越的性能,但本研究仍存在以下局限:
- 数据集依赖:实验结果高度依赖于所选用的数据集。不同数据集之间的差异可能会影响ARPO算法的性能表现。
- 模型规模限制:尽管使用了8B和14B参数的Qwen3模型进行实验,但更大规模的模型可能会带来不同的结果。未来研究需要进一步探索ARPO算法在不同规模模型上的表现。
- 实时交互挑战:虽然ARPO算法在离线实验中表现优异,但在实时动态环境中与用户进行交互时,仍可能面临新的挑战。例如,实时响应速度和用户反馈的处理等问题需要进一步研究。
未来研究方向
针对本研究的局限性和当前领域的挑战,未来研究可以从以下几个方面展开:
- 跨数据集验证:在更多样化的数据集上验证ARPO算法的有效性,以确保其泛化能力。通过引入不同领域和难度的数据集,可以更全面地评估ARPO算法的性能。
- 大规模模型实验:探索ARPO算法在更大规模模型上的表现。随着模型规模的增大,ARPO算法的自适应推演机制和优势归因估计方法可能会带来更大的性能提升。
- 实时交互优化:研究ARPO算法在实时动态环境中的表现,并优化其实时响应速度和用户反馈处理能力。通过引入在线学习机制和用户反馈循环,可以进一步提升ARPO算法的实用性和用户体验。
- 多模态推理:将ARPO算法扩展到多模态推理任务中,如结合视觉、音频等多种模态信息进行推理。这需要研究如何有效地融合不同模态的信息,并在多模态交互中应用自适应推演机制和优势归因估计方法。
- 可解释性研究:深入研究ARPO算法的决策过程和推理路径,提高其可解释性。通过可视化工具和解释性技术,可以帮助用户更好地理解ARPO算法的工作原理和推理依据。