今天梳理一下TriplaneGaussian的代码逻辑,文章的简介可以先看这一篇博文。
项目地址:Github
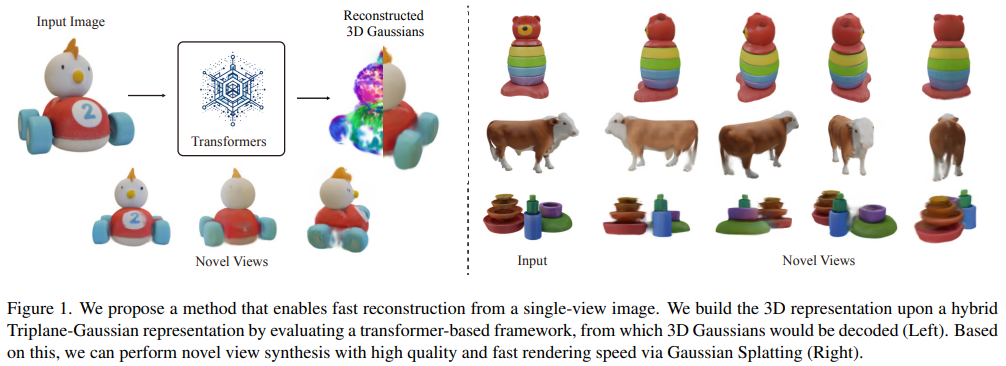
接下来我将挑选重点来梳理,逐行解析会在代码注释里。
triplane.py
既然是Triplane Meets Gaussian,我们就先从models/tokenizers/triplane.py看起。
这段代码实现了一个可学习的Triplane位置编码模块,主要用于将特征映射到三张正交平面的表示形式,便于后续3D体素或点采样操作。
class TriplaneLearnablePositionalEmbedding(BaseModule):
@dataclass
class Config(BaseModule.Config):
plane_size: int = 32 # 每个平面的分辨率
num_channels: int = 1024 # 每个平面的通道数
# 一共会有3个平面(XY、XZ、YZ),因此总token数为3*plane_size^2
cfg: Config
def configure(self) -> None:
super().configure()
# 初始化可学习的triplane embedding
self.embeddings = nn.Parameter(
torch.randn(
(3, self.cfg.num_channels, self.cfg.plane_size, self.cfg.plane_size),
dtype=torch.float32,
)
* 1
/ math.sqrt(self.cfg.num_channels) # 这里是Xavier初始化风格的缩放,避免梯度爆炸
)
def forward(self, batch_size: int, cond_embeddings: Float[Tensor, "B Ct"] = None) -> Float[Tensor, "B Ct Nt"]:
embeddings = repeat(self.embeddings, "Np Ct Hp Wp -> B Np Ct Hp Wp", B=batch_size) # 为每个batch复制一份
if cond_embeddings is not None:
# 如果有cond_embeddings(例如图像特征条件),则加到每个平面上做条件调制
embeddings = embeddings + cond_embeddings
# 最后展平为 (B, Ct, Nt),其中Nt = 3 * H * W,相当于将三平面的空间像素展平成 token
return rearrange(
embeddings,
"B Np Ct Hp Wp -> B Ct (Np Hp Wp)",
)
def detokenize(
self, tokens: Float[Tensor, "B Ct Nt"]
) -> Float[Tensor, "B 3 Ct Hp Wp"]:
# 这里相当于是forward的逆操作
batch_size, Ct, Nt = tokens.shape
assert Nt == self.cfg.plane_size**2 * 3
assert Ct == self.cfg.num_channels
return rearrange(
tokens,
"B Ct (Np Hp Wp) -> B Np Ct Hp Wp",
Np=3,
Hp=self.cfg.plane_size,
Wp=self.cfg.plane_size,
)
renderer.py
我们再来看看models/renderer.py中的操作,这里我们略过一些矩阵变换的工具函数和Camera、GaussianModel的类。
GSLayer
先看GSLayer,它将输入特征映射为高斯的各个属性。这个类的作用主要是将输入特征映射成高斯参数(位置偏移、密度、缩放、旋转、球谐系数等)。
class GSLayer(BaseModule):
@dataclass
class Config(BaseModule.Config):
in_channels: int = 128 # 该层输入的特征通道数
feature_channels: dict = field(default_factory=dict) # 定义每个输出特征的输出维度。
xyz_offset: bool = True # 是否预测位置偏移
restrict_offset: bool = False # 是否限制offset
use_rgb: bool = False # 果为 True,shs 输出直接变为 RGB,而不是球谐系数
clip_scaling: Optional[float] = None # 对预测的 scaling 做截断,防止数值爆炸
init_scaling: float = -5.0
init_density: float = 0.1
cfg: Config
def configure(self, *args, **kwargs) -> None:
self.out_layers = nn.ModuleList()
# 遍历 feature_channels 中的每一个 key(特征类型)
for key, out_ch in self.cfg.feature_channels.items():
if key == "shs" and self.cfg.use_rgb:
# 如果 shs 且 use_rgb=True,输出通道变为 3(直接预测 RGB)
out_ch = 3
# 使用 nn.Linear 将 in_channels 线性映射到目标通道数 out_ch
layer = nn.Linear(self.cfg.in_channels, out_ch)
# initialize
# 对高斯参数权重和偏置全初始化为 0,表示默认输出接近 0
if not (key == "shs" and self.cfg.use_rgb):
nn.init.constant_(layer.weight, 0)
nn.init.constant_(layer.bias, 0)
if key == "scaling":
nn.init.constant_(layer.bias, self.cfg.init_scaling)
elif key == "rotation":
nn.init.constant_(layer.bias, 0)
nn.init.constant_(layer.bias[0], 1.0)
elif key == "opacity":
nn.init.constant_(layer.bias, inverse_sigmoid(self.cfg.init_density))
# 将所有的线性层收集到 self.out_layers,这样在 forward 时可以批量计算
self.out_layers.append(layer)
def forward(self, x, pts):
ret = {}
for k, layer in zip(self.cfg.feature_channels.keys(), self.out_layers):
v = layer(x)
if k == "rotation":
v = torch.nn.functional.normalize(v)
elif k == "scaling":
v = trunc_exp(v)
if self.cfg.clip_scaling is not None:
v = torch.clamp(v, min=0, max=self.cfg.clip_scaling)
elif k == "opacity":
v = torch.sigmoid(v)
elif k == "shs":
if self.cfg.use_rgb:
v = torch.sigmoid(v)
v = torch.reshape(v, (v.shape[0], -1, 3))
elif k == "xyz":
if self.cfg.restrict_offset:
max_step = 1.2 / 32
v = (torch.sigmoid(v) - 0.5) * max_step
v = v + pts if self.cfg.xyz_offset else pts
ret[k] = v
return GaussianModel(**ret)
这里的思路和MVSGaussian、MVSPlat等方法基本上一脉相承,就是靠网络学参数即可。
GS3DRenderer
这个里面还有一个GS3DRenderer类,它是一个基于3D Gaussian Splatting的渲染器,同时支持基于Triplane的特征查询(query_triplane方法)。
class GS3DRenderer(BaseModule):
@dataclass
class Config(BaseModule.Config):
mlp_network_config: Optional[dict] = None # 控制是否使用 MLP 对特征进行进一步处理的配置
gs_out: dict = field(default_factory=dict) # 传递给 GSLayer 的配置字典(输出通道数等)
sh_degree: int = 3 # 球谐函数的阶数
scaling_modifier: float = 1.0 # 控制高斯点的缩放比例
random_background: bool = False # 是否使用随机背景
radius: float = 1.0 # 3D场景坐标的半径范围,用于triplane查询的归一化
feature_reduction: str = "concat" # 特征融合方式,mean或者concat
projection_feature_dim: int = 773 # 投影特征维度
background_color: Tuple[float, float, float] = field(
default_factory=lambda: (1.0, 1.0, 1.0)
) # 默认背景颜色
cfg: Config # 将配置类型与实例绑定
def configure(self, *args, **kwargs) -> None:
# 根据 feature_reduction 确定输入特征维度
if self.cfg.feature_reduction == "mean":
mlp_in = 80
elif self.cfg.feature_reduction == "concat":
mlp_in = 80 * 3
else:
raise NotImplementedError
# 加上 projection_feature_dim 作为额外特征输入
mlp_in = mlp_in + self.cfg.projection_feature_dim
if self.cfg.mlp_network_config is not None:
# 如果提供了 mlp_network_config,会实例化 MLP 将特征映射到 gs_out 需要的通道数
self.mlp_net = MLP(mlp_in, self.cfg.gs_out.in_channels, **self.cfg.mlp_network_config)
else:
# 否则,直接把输入维度作为 gs_out 的输入通道
self.cfg.gs_out.in_channels = mlp_in
self.gs_net = GSLayer(self.cfg.gs_out) # 最终的高斯渲染层
def forward_gs(self, x, p):
# 先经过 MLP(如果有),再交给 GSLayer 进行高斯相关计算
if self.cfg.mlp_network_config is not None:
x = self.mlp_net(x)
return self.gs_net(x, p)
# 顾名思义,这个方法负责单视角的高斯渲染
def forward_single_view(self,
gs: GaussianModel,
viewpoint_camera: Camera,
background_color: Optional[Float[Tensor, "3"]],
ret_mask: bool = True,
):
# Create zero tensor. We will use it to make pytorch return gradients of the 2D (screen-space) means
screenspace_points = torch.zeros_like(gs.xyz, dtype=gs.xyz.dtype, requires_grad=True, device=self.device) + 0
try:
screenspace_points.retain_grad()
except:
pass
# 背景与光栅化配置
bg_color = background_color
# Set up rasterization configuration
# 相机的水平和垂直视场角的 tan 值,用于光栅化
tanfovx = math.tan(viewpoint_camera.FoVx * 0.5)
tanfovy = math.tan(viewpoint_camera.FoVy * 0.5)
# 设置光栅化参数,包括图像大小、相机矩阵、球谐阶数、背景颜色等
raster_settings = GaussianRasterizationSettings(
image_height=int(viewpoint_camera.height),
image_width=int(viewpoint_camera.width),
tanfovx=tanfovx,
tanfovy=tanfovy,
bg=bg_color,
scale_modifier=self.cfg.scaling_modifier,
viewmatrix=viewpoint_camera.world_view_transform,
projmatrix=viewpoint_camera.full_proj_transform.float(),
sh_degree=self.cfg.sh_degree,
campos=viewpoint_camera.camera_center,
prefiltered=False,
debug=False
)
rasterizer = GaussianRasterizer(raster_settings=raster_settings)
# 高斯参数
means3D = gs.xyz
means2D = screenspace_points
opacity = gs.opacity
# If precomputed 3d covariance is provided, use it. If not, then it will be computed from
# scaling / rotation by the rasterizer.
scales = None
rotations = None
cov3D_precomp = None
scales = gs.scaling
rotations = gs.rotation
# If precomputed colors are provided, use them. Otherwise, if it is desired to precompute colors
# from SHs in Python, do it. If not, then SH -> RGB conversion will be done by rasterizer.
shs = None
colors_precomp = None
if self.gs_net.cfg.use_rgb:
colors_precomp = gs.shs.squeeze(1)
else:
shs = gs.shs
# Rasterize visible Gaussians to image, obtain their radii (on screen).
# 渲染
with torch.autocast(device_type=self.device.type, dtype=torch.float32):
rendered_image, radii = rasterizer(
means3D = means3D,
means2D = means2D,
shs = shs,
colors_precomp = colors_precomp,
opacities = opacity,
scales = scales,
rotations = rotations,
cov3D_precomp = cov3D_precomp)
# 输出
ret = {
"comp_rgb": rendered_image.permute(1, 2, 0),
"comp_rgb_bg": bg_color
}
# 可选 Mask 渲染
if ret_mask:
mask_bg_color = torch.zeros(3, dtype=torch.float32, device=self.device)
raster_settings = GaussianRasterizationSettings(
image_height=int(viewpoint_camera.height),
image_width=int(viewpoint_camera.width),
tanfovx=tanfovx,
tanfovy=tanfovy,
bg=mask_bg_color,
scale_modifier=self.cfg.scaling_modifier,
viewmatrix=viewpoint_camera.world_view_transform,
projmatrix=viewpoint_camera.full_proj_transform.float(),
sh_degree=0,
campos=viewpoint_camera.camera_center,
prefiltered=False,
debug=False
)
rasterizer = GaussianRasterizer(raster_settings=raster_settings)
with torch.autocast(device_type=self.device.type, dtype=torch.float32):
rendered_mask, radii = rasterizer(
means3D = means3D,
means2D = means2D,
# shs = ,
colors_precomp = torch.ones_like(means3D),
opacities = opacity,
scales = scales,
rotations = rotations,
cov3D_precomp = cov3D_precomp)
ret["comp_mask"] = rendered_mask.permute(1, 2, 0)
return ret
def query_triplane(
self,
positions: Float[Tensor, "*B N 3"], # 3D 采样点 (B, N, 3)
triplanes: Float[Tensor, "*B 3 Cp Hp Wp"], # 三平面特征 (B, 3, C, H, W)
) -> Dict[str, Tensor]:
batched = positions.ndim == 3
# 统一 batch 维度
if not batched:
# no batch dimension
triplanes = triplanes[None, ...]
positions = positions[None, ...]
# 坐标归一化将3D点映射到[-1, 1],方便grid_sample采样
positions = scale_tensor(positions, (-self.cfg.radius, self.cfg.radius), (-1, 1))
# 生成2D采样索引,也就是3个平面的2D投影坐标:XY, XZ, YZ
indices2D: Float[Tensor, "B 3 N 2"] = torch.stack(
(positions[..., [0, 1]], positions[..., [0, 2]], positions[..., [1, 2]]),
dim=-3,
)
# 对三平面进行双线性采样
out: Float[Tensor, "B3 Cp 1 N"] = F.grid_sample(
rearrange(triplanes, "B Np Cp Hp Wp -> (B Np) Cp Hp Wp", Np=3),
rearrange(indices2D, "B Np N Nd -> (B Np) () N Nd", Np=3),
align_corners=False,
mode="bilinear",
)
# 特征融合
if self.cfg.feature_reduction == "concat":
out = rearrange(out, "(B Np) Cp () N -> B N (Np Cp)", Np=3)
elif self.cfg.feature_reduction == "mean":
out = reduce(out, "(B Np) Cp () N -> B N Cp", Np=3, reduction="mean")
else:
raise NotImplementedError
if not batched:
out = out.squeeze(0)
return out
# 批量渲染,对一批相机逐个调用forward_single_view,再把结果堆叠
def forward_single_batch(
self,
gs_hidden_features: Float[Tensor, "Np Cp"],
query_points: Float[Tensor, "Np 3"],
c2ws: Float[Tensor, "Nv 4 4"],
intrinsics: Float[Tensor, "Nv 4 4"],
height: int,
width: int,
background_color: Optional[Float[Tensor, "3"]],
):
gs: GaussianModel = self.forward_gs(gs_hidden_features, query_points)
out_list = []
# 遍历所有相机视角
for c2w, intrinsic in zip(c2ws, intrinsics):
out_list.append(self.forward_single_view(
gs,
Camera.from_c2w(c2w, intrinsic, height, width),
background_color
))
out = defaultdict(list)
for out_ in out_list:
for k, v in out_.items():
out[k].append(v)
out = {k: torch.stack(v, dim=0) for k, v in out.items()}
out["3dgs"] = gs
return out
def forward(self,
gs_hidden_features: Float[Tensor, "B Np Cp"], # 批量高斯点的隐藏特征
query_points: Float[Tensor, "B Np 3"], # 高斯点位置
c2w: Float[Tensor, "B Nv 4 4"],
intrinsic: Float[Tensor, "B Nv 4 4"],
height,
width,
additional_features: Optional[Float[Tensor, "B C H W"]] = None, # 额外的特征
background_color: Optional[Float[Tensor, "B 3"]] = None,
**kwargs):
batch_size = gs_hidden_features.shape[0]
out_list = []
# 调用 query_triplane 在三平面上采样特征
gs_hidden_features = self.query_triplane(query_points, gs_hidden_features)
if additional_features is not None:
gs_hidden_features = torch.cat([gs_hidden_features, additional_features], dim=-1)
# 渲染循环
for b in range(batch_size):
out_list.append(self.forward_single_batch(
gs_hidden_features[b],
query_points[b],
c2w[b],
intrinsic[b],
height, width,
background_color[b] if background_color is not None else None))
out = defaultdict(list)
for out_ in out_list:
for k, v in out_.items():
out[k].append(v)
for k, v in out.items():
if isinstance(v[0], torch.Tensor):
out[k] = torch.stack(v, dim=0)
else:
out[k] = v
return out
到这里可以清楚,作者是让网络学到一种能从输入特征中自动生成三平面表示的机制,而不是直接手工定义三平面特征。
query_triplane不是直接用固定的voxel/grid特征,而是基于点特征动态生成三平面表示,然后再从这些三平面中对 query_points做投影采样。这个feature field本质上是一个“能在任意3D点处查询特征的函数”。
其实现方式是:
- 给每个高斯点分配一个latent feature。
- query_triplane根据这些latent feature生成三平面特征。
- 三平面特征被采样后用于渲染。
这样,三平面表示是隐式学到的,而不是显示存储的。这意味着,每个点的三平面特征是由网络预测出来的,可以自适应点分布。