我们身处数据洪流时代,智能手机、社交网络、传感器每天产生海量信息。如何把这些原始记录转化为可理解、可行动的知识,正是数据挖掘(Data Mining)的核心使命。它通常被定义为“从大型数据集中发现有趣模式、模型及其他类型知识的过程”。
有人笑称“数据挖掘”一词并不准确,更贴切的说法应是“从数据中挖掘知识”(knowledge mining from data),因而学术界也常用KDD(Knowledge Discovery from Data)等术语。
作为一门年轻而充满活力的交叉学科,数据挖掘已在商业、科研、公共安全等领域展现出巨大潜力。
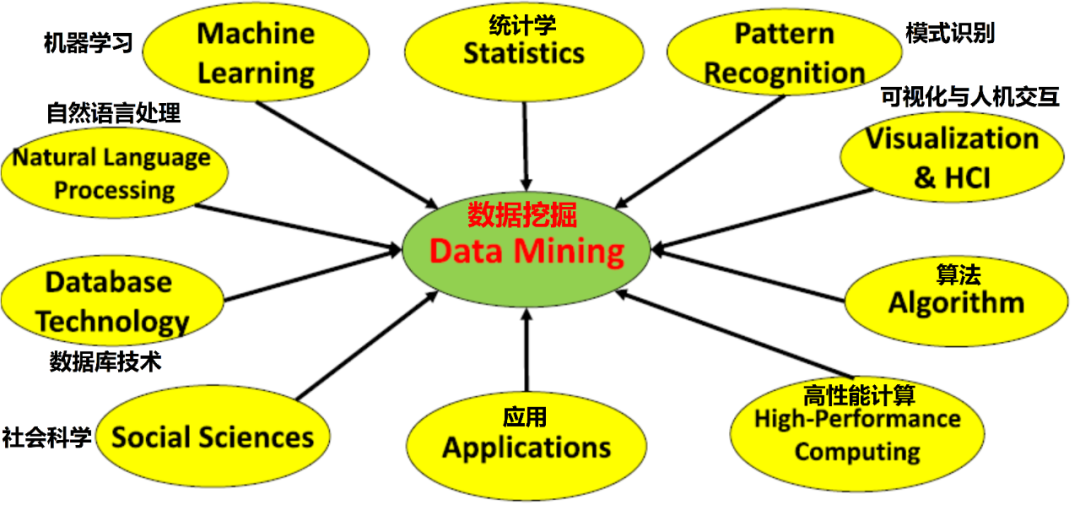
△ 数据挖掘:多学科的交汇
01 What:挖掘什么?
1. 数据形态的多样性
现实世界数据可分为结构化、半结构化与非结构化三类。
结构化数据如关系数据库、数据仓库,拥有固定模式;
半结构化数据包括交易序列、时间序列、图或网络,结构灵活;
非结构化数据则涵盖文本、音频、图像与视频。
不同应用还会带来特殊形态:生物序列、空间-时间数据、流式监控数据等。
2. 可挖掘的知识类型
多维汇总:借助数据立方体与OLAP技术,可快速汇总销售、气候等多维数据,实现“干区vs湿区”等概念描述。
频繁模式与关联:在沃尔玛购物篮中发现“尿布→啤酒”这一经典规则,引出支持度、置信度与相关性度量,并可用于分类、聚类等下游任务。
分类与回归:基于训练集构建模型,预测未来实例的离散标签或连续值。决策树、支持向量机、神经网络等方法已广泛用于信用卡欺诈检测、疾病诊断、天文天体分类等场景。
聚类分析:无监督地将对象分组,使组内相似、组间相异,从而发现房屋分布、市场细分等新模式。
深度学习:卷积网络、循环网络、图神经网络、Transformer 等前沿架构,正重塑计算机视觉、自然语言处理与社交网络分析。
异常检测:识别与主流行为不符的数据点,在欺诈、稀有事件监测中大显身手。
此外,序列、趋势与演化分析、图挖掘、信息网络与Web挖掘等,进一步扩展了数据挖掘的疆域。
02 How:怎样挖掘?
数据挖掘并非孤立步骤,而是知识发现过程中的关键环节。该流程包括:数据准备、清洗、集成、变换、选择,随后才进入真正的挖掘阶段;得到模式后,还要经过评估与知识表示,最终交付给用户。只有走完这一闭环,原始“矿石”才真正成为可用“金属”。
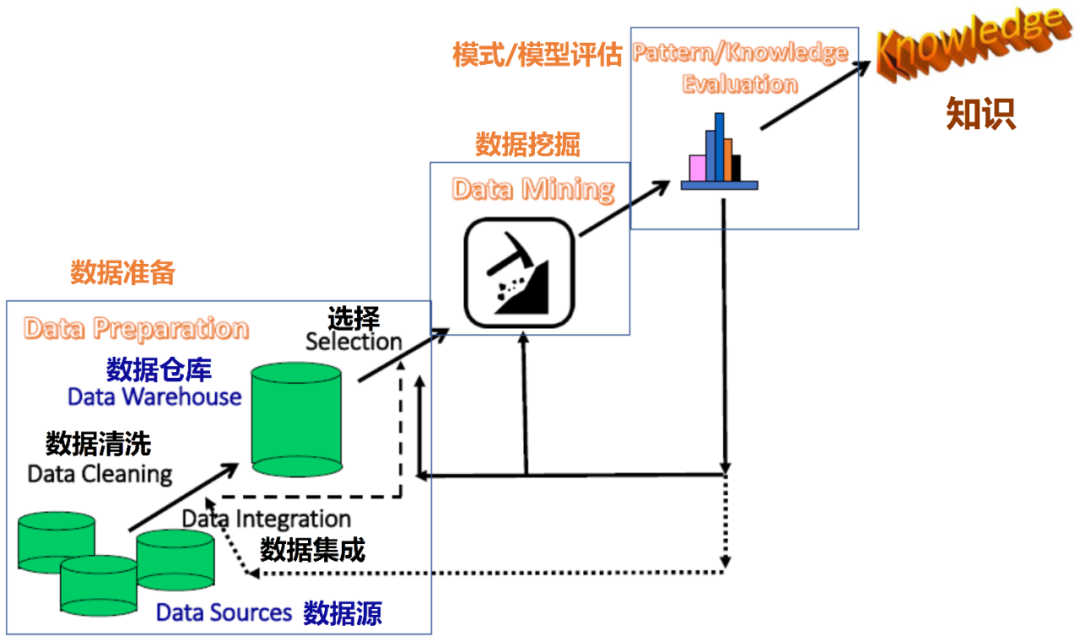
△ 数据挖掘:知识发现过程中的必要一步
最近刚刚完成更新重装上市的《数据挖掘:概念与技术(原书第4版)》就是系统性地详解数据挖掘技术的著作,内容覆盖了从基础理论到应用案例的完整知识体系。如果你想要学习和研究数据挖掘技术,这本数据挖掘领域的经典著作一定是你的必读书目。
目录
Data Mining Concepts and Techniques, Fourth Edition
译者序
推荐序
第2版序
前言
致谢
作者简介
第1章 绪论 1
1.1 什么是数据挖掘 1
1.2 数据挖掘:知识发现中不可或缺的
一步 2
1.3 数据挖掘的数据类型多样性 3
1.4 挖掘各种各样的知识 4
1.4.1 多维数据汇总 4
1.4.2 挖掘频繁模式、关联和相关性 5
1.4.3 用于预测分析的分类和回归 5
1.4.4 聚类分析 7
1.4.5 深度学习 7
1.4.6 离群点分析 7
1.4.7 数据挖掘的所有结果都有趣吗 8
1.5 数据挖掘:多学科的交汇 9
1.5.1 统计学与数据挖掘 9
1.5.2 机器学习与数据挖掘 10
1.5.3 数据库技术与数据挖掘 11
1.5.4 数据挖掘与数据科学 11
1.5.5 数据挖掘与其他学科 12
1.6 数据挖掘与应用 12
1.7 数据挖掘与社会 14
1.8 总结 14
1.9 练习 15
1.10 文献注释 15
第2章 数据、度量与数据预处理 17
2.1 数据类型 18
2.1.1 标称属性 18
2.1.2 二元属性 18
2.1.3 序数属性 19
2.1.4 数值属性 19
2.1.5 离散属性与连续属性 20
2.2 数据的基本统计描述 20
2.2.1 中心趋势度量 21
2.2.2 数据离散趋势度量 22
2.2.3 协方差和相关系数 25
2.2.4 数据基本统计描述的图形
显示 27
2.3 数据的相似性与相异性度量 30
2.3.1 数据矩阵与相异性矩阵 31
2.3.2 标称属性的邻近性度量 32
2.3.3 二元属性的邻近性度量 32
2.3.4 数值属性的相异性:闵可夫斯基距离 34
2.3.5 序数属性的邻近性度量 35
2.3.6 混合类属性的相异性 36
2.3.7 余弦相似性 37
2.3.8 度量相似的分布:Kullback-Leibler散度 38
2.3.9 捕获相似性度量中的隐藏
语义 39
2.4 数据质量、数据清洗和数据集成 39
2.4.1 数据质量度量 39
2.4.2 数据清洗 40
2.4.3 数据集成 44
2.5 数据转换 45
2.5.1 规范化 45
2.5.2 离散化 47
2.5.3 数据压缩 48
2.5.4 抽样 50
2.6 维归约 50
2.6.1 主成分分析 50
2.6.2 属性子集选择 51
2.6.3 非线性维归约方法 52
2.7 总结 55
2.8 练习 56
2.9 文献注释 59
第3章 数据仓库和在线分析处理 61
3.1 数据仓库 61
3.1.1 数据仓库:基本概念 61
3.1.2 数据仓库的架构:企业数据
仓库和数据集市 63
3.1.3 数据湖 66
3.2 数据仓库建模:模式和度量标准 69
3.2.1 数据立方体:一个多维数据
模型 69
3.2.2 多维数据模型的模式:星型、
雪花和事实星座 72
3.2.3 概念层次结构 74
3.2.4 度量:分类和计算 75
3.3 OLAP操作 76
3.3.1 典型的OLAP操作 76
3.3.2 索引OLAP数据:位图索引和
连接索引 78
3.3.3 存储实现:基于列的数据库 81
3.4 数据立方体计算 82
3.4.1 数据立方体计算的相关术语 82
3.4.2 数据立方体物化思路 83
3.4.3 OLAP服务器架构:ROLAP、MOLAP、HOLAP 85
3.4.4 数据立方体计算的一般策略 86
3.5 数据立方体计算方法 87
3.5.1 用于完全立方体计算的多路
数组聚合 87
3.5.2 BUC:从顶点方体向下计算
冰山立方体 91
3.5.3 为快速高维OLAP预计算壳
片段 93
3.5.4 使用立方体高效处理OLAP
查询 95
3.6 总结 96
3.7 练习 97
3.8 文献注释 102
第4章 模式挖掘:基本概念和
方法 105
4.1 基本概念 105
4.1.1 购物篮分析:启发示例 105
4.1.2 频繁项集、闭项集和关联
规则 106
4.2 频繁项集挖掘方法 108
4.2.1 Apriori算法:通过受限候选
生成来查找频繁项集 108
4.2.2 从频繁项集生成关联规则 111
4.2.3 提高Apriori的效率 112
4.2.4 挖掘频繁项集的模式增长
方法 113
4.2.5 使用垂直数据格式挖掘频繁
项集 116
4.2.6 挖掘闭模式和最大模式 117
4.3 哪些模式有趣?—模式评估
方法 117
4.3.1 强规则不一定有趣 118
4.3.2 从关联分析到相关分析 118
4.3.3 模式评估方法的比较 119
4.4 总结 122
4.5 练习 123
4.6 文献注释 125
第5章 模式挖掘:高级方法 127
5.1 挖掘多类型的模式 127
5.1.1 挖掘多层关联 127
5.1.2 挖掘多维关联 130
5.1.3 挖掘定量关联规则 131
5.1.4 挖掘高维数据 132
5.1.5 挖掘稀有模式和负模式 134
5.2 挖掘压缩模式或近似模式 135
5.2.1 利用模式聚类挖掘压缩模式 136
5.2.2 提取冗余感知的top-k模式 137
5.3 基于约束的模式挖掘 139
5.3.1 具有模式修剪约束的模式空间
修剪 140
5.3.2 具有数据修剪约束的数据
空间修剪 142
5.3.3 具有简洁性约束的挖掘空间
修剪 143
5.4 序列模式挖掘 144
5.4.1 序列模式挖掘:概念与原语 144
5.4.2 可扩展的序列模式挖掘方法 146
5.4.3 基于约束的序列模式挖掘 153
5.5 挖掘子图模式 154
5.5.1 挖掘频繁子图的方法 154
5.5.2 挖掘变体和受约束子结构
模式 159
5.6 模式挖掘:应用程序示例 162
5.6.1 海量文本数据中的短语挖掘 162
5.6.2 挖掘软件程序中的复制和粘贴
错误 167
5.7 总结 169
5.8 练习 170
5.9 文献注释 171
第6章 分类:基本概念和方法 174
6.1 基本概念 174
6.1.1 什么是分类 174
6.1.2 分类的一般方法 175
6.2 决策树归纳 177
6.2.1 决策树算法 177
6.2.2 属性选择度量 181
6.2.3 剪枝 187
6.3 贝叶斯分类方法 189
6.3.1 贝叶斯定理 189
6.3.2 朴素贝叶斯分类 190
6.4 惰性学习器 193
6.4.1 k-最近邻分类器 194
6.4.2 基于案例的推理 195
6.5 线性分类器 196
6.5.1 线性回归 197
6.5.2 感知机:将线性回归转化为
分类 198
6.5.3 logistic回归 199
6.6 模型评估与选择 202
6.6.1 评估分类器性能的度量 203
6.6.2 保持方法和随机二次抽样 206
6.6.3 交叉验证 207
6.6.4 自助法 207
6.6.5 使用统计显著性检验选择
模型 208
6.6.6 基于成本效益和ROC曲线
比较分类器 209
6.7 提高分类准确率的技术 211
6.7.1 集成分类方法简介 211
6.7.2 装袋 212
6.7.3 提升 213
6.7.4 随机森林 216
6.7.5 提高类不平衡数据的分类
准确率 217
6.8 总结 218
6.9 练习 219
6.10 文献注释 221
第7章 分类:高级方法 224
7.1 特征选择与特征工程 224
7.1.1 过滤法 225
7.1.2 包装法 227
7.1.3 嵌入法 227
7.2 贝叶斯信念网络 230
7.2.1 概念和原理 230
7.2.2 训练贝叶斯信念网络 231
7.3 支持向量机 233
7.3.1 线性支持向量机 233
7.3.2 非线性支持向量机 237
7.4 基于规则和基于模式的分类 239
7.4.1 使用IF-THEN规则进行分类 239
7.4.2 从决策树中提取规则 241
7.4.3 使用序列覆盖算法进行规则
归纳 242
7.4.4 关联分类 245
7.4.5 基于判别频繁模式的分类 247
7.5 弱监督分类 250
7.5.1 半监督分类 251
7.5.2 主动学习 252
7.5.3 迁移学习 253
7.5.4 远程监督 255
7.5.5 零样本学习 256
7.6 对丰富数据类型进行分类 258
7.6.1 流数据分类 258
7.6.2 序列分类 260
7.6.3 图数据分类 261
7.7 其他相关技术 264
7.7.1 多类分类 264
7.7.2 距离度量学习 266
7.7.3 分类的可解释性 268
7.7.4 遗传算法 269
7.7.5 强化学习 270
7.8 总结 271
7.9 练习 272
7.10 文献注释 275
第8章 聚类分析:基本概念和
方法 278
8.1 聚类分析 278
8.1.1 什么是聚类分析 278
8.1.2 聚类分析的要求 280
8.1.3 基本聚类方法概述 281
8.2 划分方法 283
8.2.1 k-均值:一种基于形心的
技术 283
8.2.2 k-均值方法的变体 285
8.3 层次方法 289
8.3.1 层次聚类的基本概念 290
8.3.2 凝聚式层次聚类 291
8.3.3 分裂式层次聚类 294
8.3.4 BIRCH:使用聚类特征树的
可伸缩层次聚类 295
8.3.5 概率层次聚类 297
8.4 基于密度和基于网格的方法 299
8.4.1 DBSCAN:基于高密度相连
区域的密度聚类 300
8.4.2 DENCLUE:基于密度分布
函数的聚类 303
8.4.3 基于网格的方法 304
8.5 聚类评估 306
8.5.1 评估聚类趋势 307
8.5.2 确定簇数量 308
8.5.3 衡量聚类质量:外在方法 309
8.5.4 内在方法 312
8.6 总结 313
8.7 练习 314
8.8 文献注释 315
第9章 聚类分析:高级方法 318
9.1 基于概率模型的聚类 318
9.1.1 模糊簇 319
9.1.2 基于概率模型的簇 321
9.1.3 期望最大化算法 323
9.2 聚类高维数据 325
9.2.1 聚类高维数据的问题和挑战 325
9.2.2 轴平行子空间方法 328
9.2.3 任意定向子空间方法 329
9.3 双聚类 330
9.3.1 为什么以及在哪里使用
双聚类 330
9.3.2 双簇的类型 332
9.3.3 双聚类方法 333
9.3.4 使用MaPle枚举所有双簇 334
9.4 聚类的维归约方法 334
9.4.1 用于聚类的线性维归约方法 335
9.4.2 非负矩阵分解 337
9.4.3 谱聚类 339
9.5 聚类图和网络数据 341
9.5.1 应用场景和挑战 341
9.5.2 相似性度量 342
9.5.3 图聚类方法 346
9.6 半监督聚类 349
9.6.1 标记部分数据的半监督聚类 350
9.6.2 基于成对约束的半监督聚类 350
9.6.3 半监督聚类的其他背景知识
类型 352
9.7 总结 353
9.8 练习 354
9.9 文献注释 355
第10章 深度学习 357
10.1 基本概念 357
10.1.1 什么是深度学习 357
10.1.2 反向传播算法 360
10.1.3 训练深度学习模型的重要
挑战 367
10.1.4 深度学习架构概述 368
10.2 改进深度学习模型的训练 369
10.2.1 响应性激活函数 369
10.2.2 自适应学习率 371
10.2.3 dropout 373
10.2.4 预训练 375
10.2.5 交叉熵 377
10.2.6 自编码器:无监督深度
学习 378
10.2.7 其他技术 381
10.3 卷积神经网络 383
10.3.1 引入卷积操作 383
10.3.2 多维卷积 385
10.3.3 卷积层 388
10.4 循环神经网络 390
10.4.1 基本RNN模型和应用 390
10.4.2 门控循环神经网络 396
10.4.3 解决长期依赖性的其他
技术 398
10.5 图神经网络 401
10.5.1 基本概念 401
10.5.2 图卷积网络 402
10.5.3 其他类型的图神经网络 406
10.6 总结 407
10.7 练习 409
10.8 文献注释 411
第11章 离群点检测 416
11.1 基本概念 416
11.1.1 什么是离群点 416
11.1.2 离群点的类型 417
11.1.3 离群点检测的挑战 419
11.1.4 离群点检测方法概述 420
11.2 统计方法 422
11.2.1 参数方法 422
11.2.2 非参数方法 425
11.3 基于邻近性的方法 426
11.3.1 基于距离的离群点检测 426
11.3.2 基于密度的离群点检测 427
11.4 基于重构的方法 430
11.4.1 基于矩阵分解的数值型数据
离群点检测 430
11.4.2 基于模式压缩方法的分类数据
离群点检测 434
11.5 基于聚类和分类的方法 437
11.5.1 基于聚类的方法 437
11.5.2 基于分类的方法 438
11.6 挖掘情境和集体离群点 440
11.6.1 将情境离群点检测转化为传统
离群点检测 440
11.6.2 建模关于情境的正常行为 441
11.6.3 挖掘集体离群点 441
11.7 高维数据中的离群点检测 442
11.7.1 扩展传统的离群点检测 443
11.7.2 在子空间中查找离群点 444
11.7.3 离群点检测集成 445
11.7.4 通过深度学习驯服高维度 446
11.7.5 建模高维离群点 447
11.8 总结 448
11.9 练习 449
11.10 文献注释 450
第12章 数据挖掘趋势和研究
前沿 452
12.1 挖掘丰富的数据类型 452
12.1.1 挖掘文本数据 452
12.1.2 时空数据 456
12.1.3 图和网络 457
12.2 数据挖掘应用 461
12.2.1 情感和观点的数据挖掘 461
12.2.2 真值发现与错误信息识别 463
12.2.3 信息和疾病传播 465
12.2.4 生产力与团队科学 468
12.3 数据挖掘的方法论和系统 470
12.3.1 对用于知识挖掘的非结构化
数据进行结构化处理:一种
数据驱动的方法 470
12.3.2 数据增强 472
12.3.3 从相关性到因果关系 474
12.3.4 将网络作为情境 476
12.3.5 自动化机器学习:方法和
系统 478
12.4 数据挖掘、人类和社会 479
12.4.1 保护隐私的数据挖掘 479
12.4.2 人类与算法的交互 482
12.4.3 超越最大化准确率的挖掘:公平性、可解释性和鲁棒性 484
12.4.4 数据挖掘造福社会 487
附录A 数学背景 489
参考文献 509△ 《数据挖掘:概念与技术(原书第4版)》完整目录
上下滑动查看

03 Why:为什么挖掘?
数据挖掘是从海量数据中提取价值的艺术与科学。作为多学科交汇的前沿阵地,数据挖掘已深刻改变商业、科研乃至社会生活。
在网页分析、推荐系统、精准营销、生物与医学数据分析、软件缺陷检测、社会网络反恐等领域,数据挖掘已成为幕后功臣。Google、Microsoft、LinkedIn、Meta 等公司已将数据挖掘嵌入日常功能,而SAS、Oracle、SQL Server 等工具则提供专业化平台。
然而,技术带来福祉的同时也可能泄露商业机密或个人隐私。研究界正积极开展安全数据挖掘与隐私保护发布的研究,力图在挖掘价值与保护权益之间取得平衡。面向未来,我们既要充分释放其潜能,又需建立伦理与安全的护栏,让数据真正造福人类。
延伸阅读
▼

推荐理由:本书是数据挖掘领域的经典作品,首次出版至今已20余年,成为数据挖掘学习者的必读教材。作为领域的奠基之作,本书创建了数据挖掘的技术分类学框架、从基础理论到应用案例的完整知识体系。第4版内容进行了大量改进和重组。核心技术内容得到了扩展和显著增强。新增 “深度学习”等前沿内容。全书保持简洁、与时俱进。既适合作为计算机科学、数据科学、人工智能等相关专业学生的课程教材,也适合作为相关领域研究人员及从业者的专业参考书。
04 直达链接
当当:https://product.dangdang.com/29922538.html
京东:https://item.jd.com/15109762.html