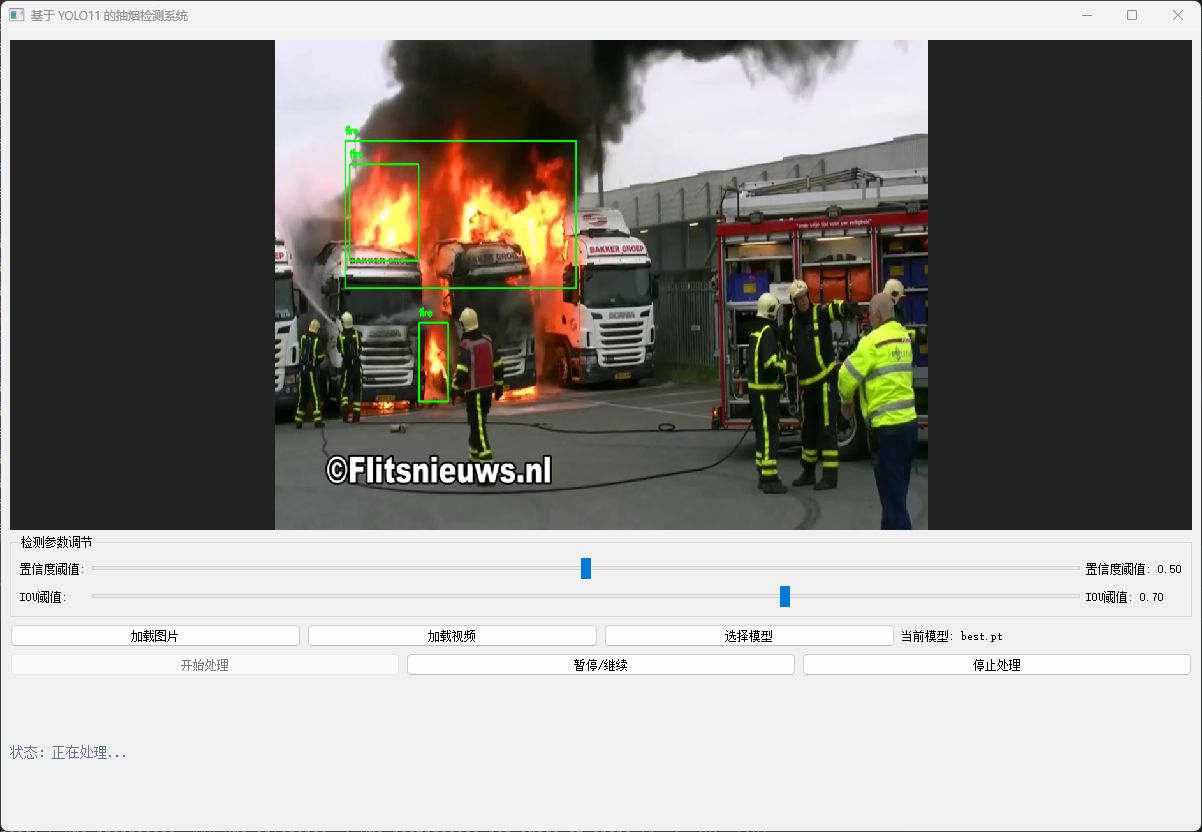
一、项目背景与需求
视频介绍
【图像算法 - 09】基于深度学习的烟雾检测:从算法原理到工程实现,完整实战指南
今天我们使用深度学习来训练一个烟雾明火检测系统。这次我们使用了大概一万五千张图片的数据集训练了这次的基于深度学习的烟雾明火检测模型,然后在推理的基础上使用PyQt设计了可视化的操作界面。

二、为什么选择深度学习?

在烟火检测领域,传统算法与深度学习的技术路径存在本质差异,这些差异直接影响检测效果、适用场景和落地难度。以下从核心逻辑、技术细节、优劣势等维度展开对比,解释两者的不同:
1. 核心逻辑:“人工设计” vs “自动学习”
传统算法:依赖 ”人工设计特征 + 规则判断“
核心逻辑是:通过人类对烟火的先验知识(如颜色、形状、动态特性),手动设计特征提取规则,再用简单分类器判断是否为烟火。
例如:- 颜色特征:用 HSV 阈值筛选红色 / 橙色区域(火焰典型色)、灰色 / 白色区域(烟雾典型色);
- 动态特征:通过帧差法检测区域的闪烁(火焰)或缓慢扩散(烟雾);
- 形状特征:用边缘检测判断是否存在不规则、动态变化的轮廓(火焰)或模糊扩散的区域(烟雾)。
深度学习:依赖 “数据驱动 + 自动特征学习”
核心逻辑是:无需人工设计特征,通过神经网络从大量标注数据中自动学习烟火的本质特征(包括人类难以描述的细微特征),端到端完成 “输入图像 / 视频→输出是否为烟火” 的判断。
例如:- 用 CNN(如 ResNet、YOLO)自动提取烟火的空间特征(纹理、梯度、高阶组合特征);
- 用 RNN/LSTM 或 3D-CNN 学习烟火的时间动态特征(如火焰的跳跃、烟雾的流动趋势);
- 模型通过反向传播不断优化,最终形成对烟火的 “抽象认知”。
2. 技术细节:从特征到泛化能力的全面差异
| 对比维度 | 传统算法 | 深度学习 |
|---|---|---|
| 特征提取方式 | 手工设计(颜色、形状、运动、纹理等规则) | 自动学习(神经网络从数据中挖掘深层特征) |
| 数据依赖 | 对数据量要求低(依赖先验规则,无需大量样本) | 强依赖大规模标注数据(数据量不足易过拟合) |
| 鲁棒性 | 弱(受场景干扰大): - 光照变化(如夕阳误判为火焰)、遮挡(部分遮挡即失效)、复杂背景(如红色广告牌误判)会严重影响效果; - 对烟火形态变化(如小火苗、浓 / 淡烟雾)适应性差。 | 强(复杂场景适应性好): - 能学习到抗干扰特征(如区分火焰与夕阳的细微纹理差异); - 对遮挡、形态变化的容忍度高(通过大量多样本训练实现)。 |
| 计算成本 | 低(轻量级算法,可在 CPU / 嵌入式设备运行) | 高(需 GPU 加速,模型参数量大,计算耗时) |
| 泛化能力 | 差(规则固定,换场景需重新设计特征) | 强(通过迁移学习可快速适配新场景) |
| 典型方法 | 颜色阈值分割、帧差法、SVM 分类器、AdaBoost 等 | CNN(ResNet)、目标检测模型(YOLO、Faster R-CNN)、3D-CNN(处理视频)等 |
3. 适用场景:各有侧重,按需选择
传统算法:适合简单场景、资源受限的场景
例如:固定摄像头监控空旷区域(如仓库、森林),烟火形态单一、背景简单(无复杂干扰物),且设备算力有限(如嵌入式摄像头、低端 CPU)。优势是部署成本低、实时性强(毫秒级响应),但需人工针对场景调参。
深度学习:适合复杂场景、高精度需求的场景
例如:城市街道(背景复杂,有车辆、行人干扰)、室内场所(光照多变、可能有遮挡),需要区分 “烟火” 与 “类似物”(如红色灯笼、蒸汽)。优势是检测精度高、泛化能力强,但需 GPU 支持,部署成本较高(需服务器或边缘计算设备)。
二、数据集
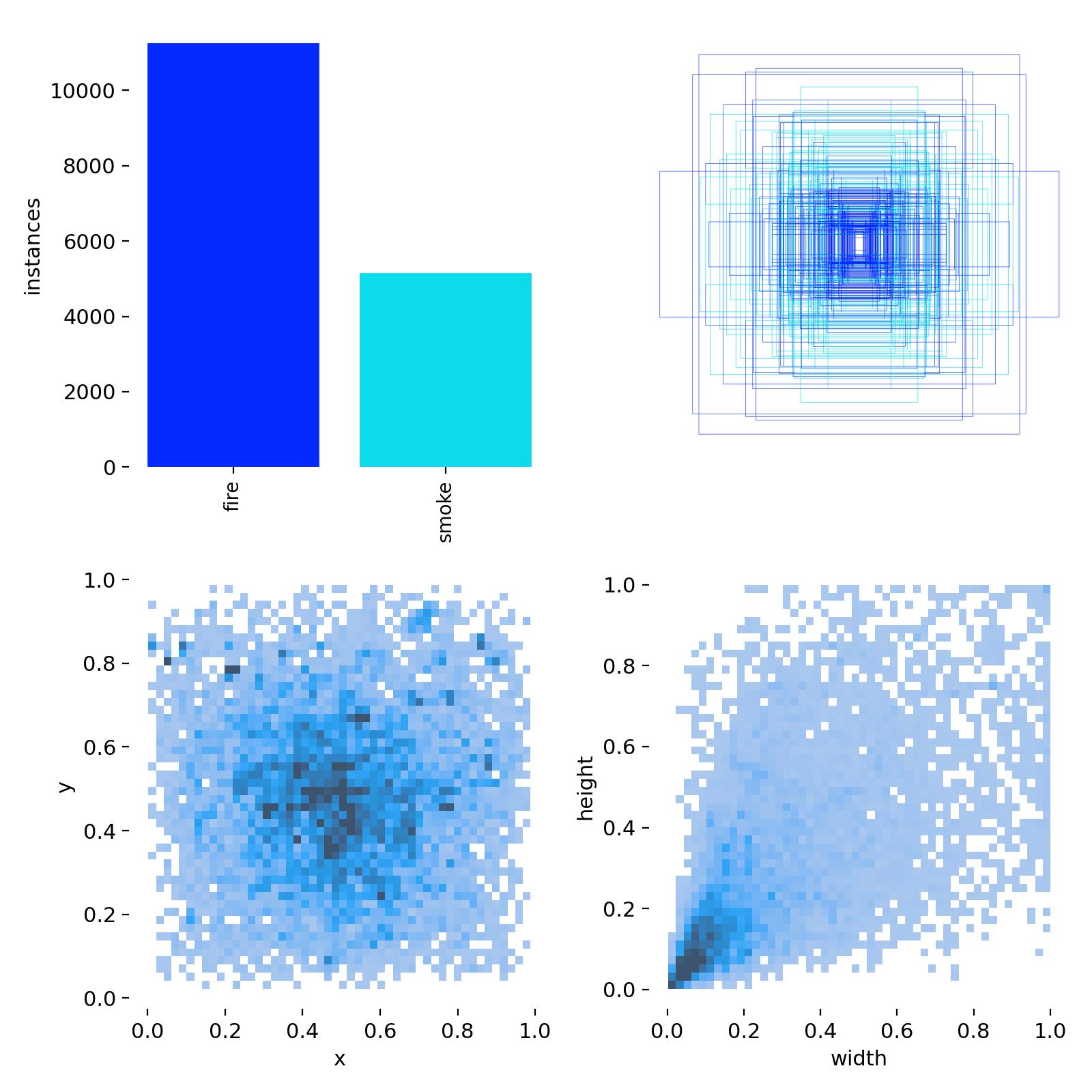
此次训练使用的烟雾明火数据集,有两类,即smoke、fire。然后下面是数据集的统计分析图。一共有10000余火焰目标、近6000的烟雾目标,标签的中心坐标分布比较均匀,居中较多,同时都不靠近边缘;目标,即抽烟目标的长宽同样比较集中,属于小目标的范围(小于图像长宽的0.2倍)。
三、网络选择
这里我们选择的是yolo11s的网络结构,其参数如下表所示:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
四、模型训练
本次训练使用的预训练模型是YOLO11s.pt(COCO数据集训练所得),epochs设置为100,batch设置为16,imgsz设置为640,其他均采用默认参数,训练时间大概4小时。
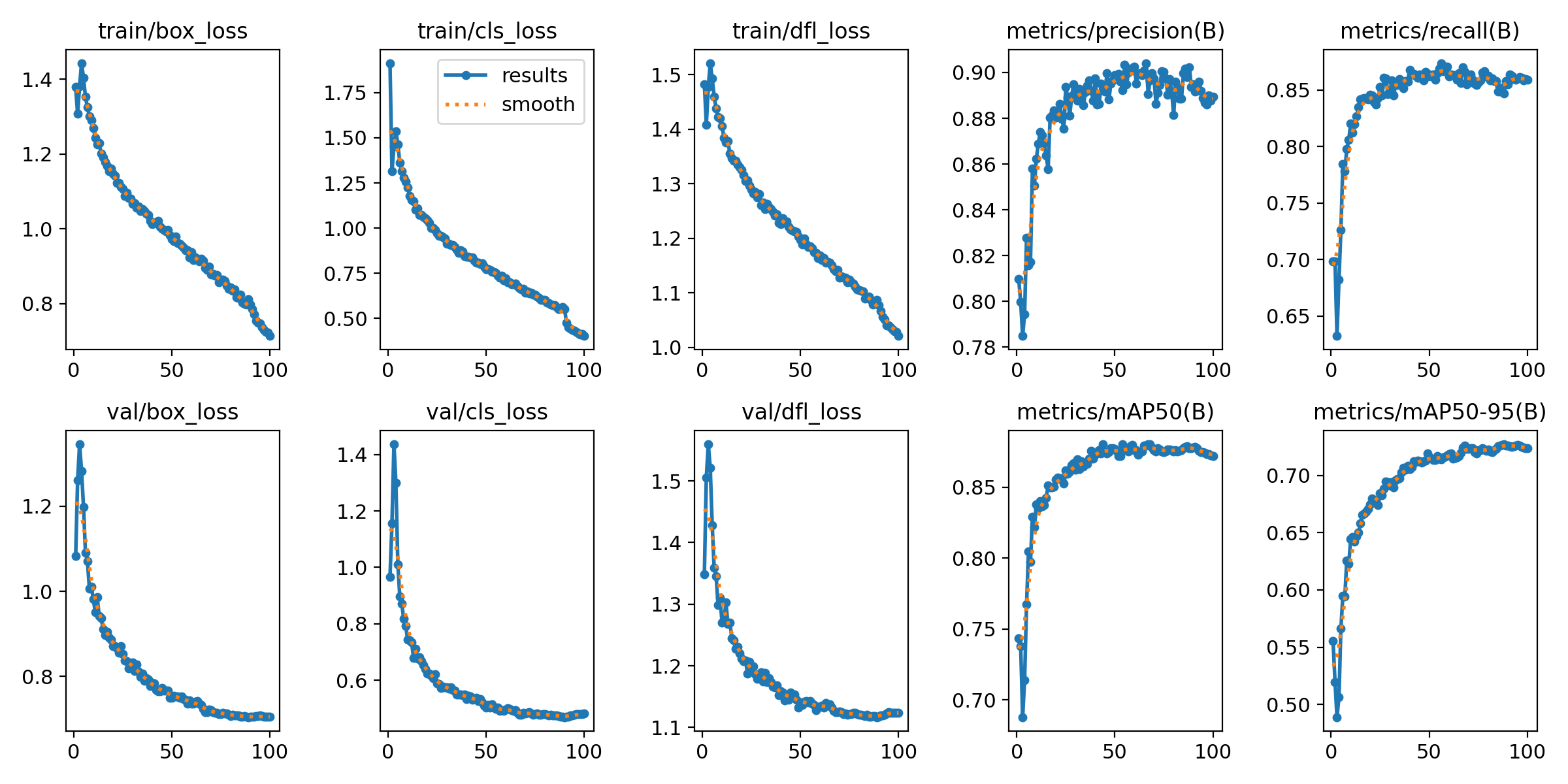
五、可视化模型推理