1、什么是 Milvus ?
向量数据库是专门用来存储和查询向量的数据库,其存储的向量来自对文本、语音、图像、视频等的向量化。同传统数据库相比,向量数据库不仅能够完成基本的CRUD(添加、读取查询、更新、删除)等操作,还能够对向量数据进行更快速的相似性搜索。
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
Milvus 基于FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求。通常,建议用户使用 Kubernetes 部署 Milvus,以获得最佳可用性和弹性。
2、Milvus 的架构和节点组成
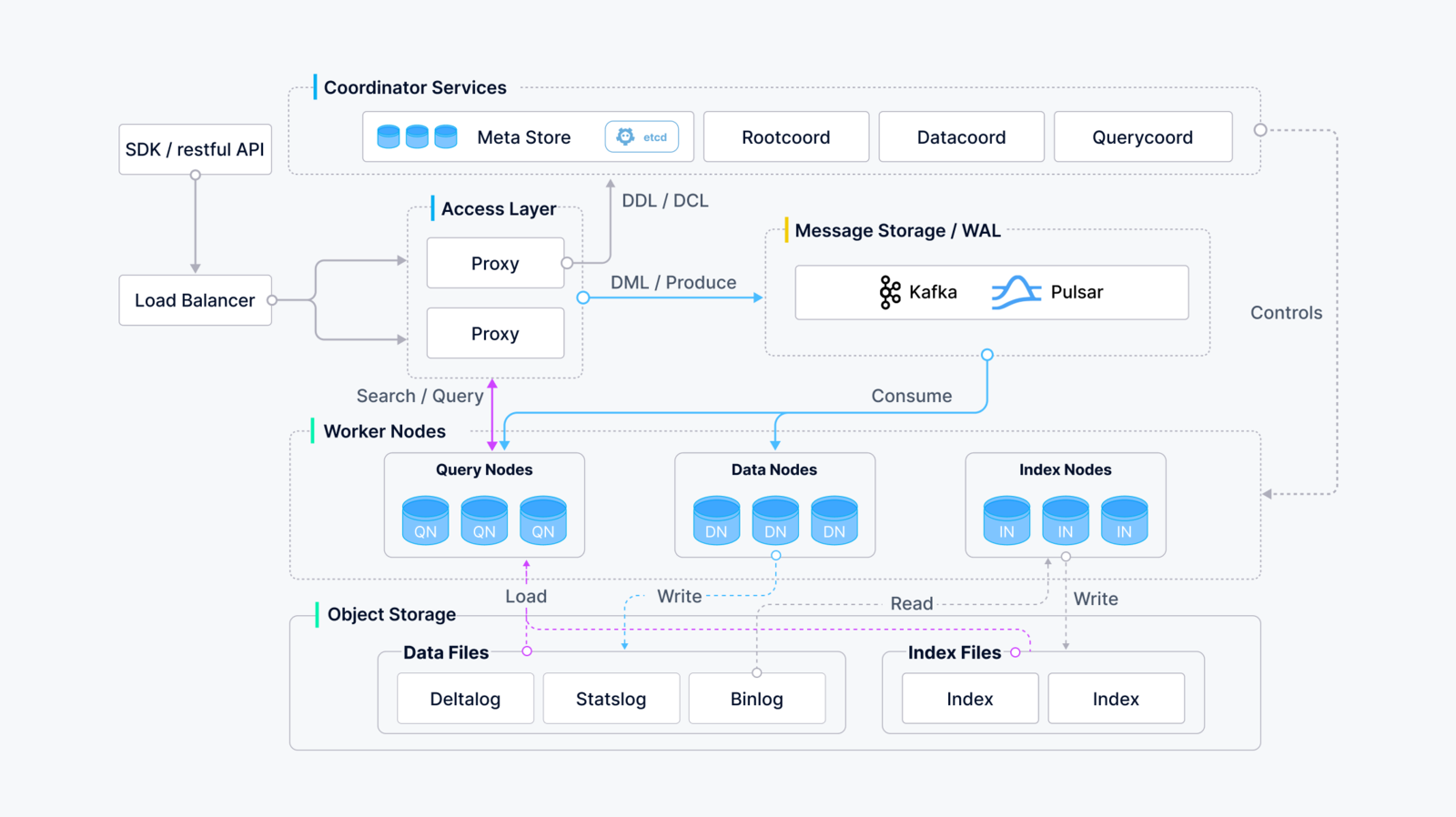
Milvus 的计算节点采用共享存储架构,具有存算分离和水平扩展的特点。遵循数据面和控制面解耦的原则,Milvus 由接入层、协调器服务层、工作节点和存储层四层组成。在扩展或灾难恢复方面,这些层是相互独立的。
1、接入层(Access Layer):系统的门面,由一组无状态 proxy 组成。对外提供用户连接的 endpoint,负责验证客户端请求并合并返回结果。
Proxy 本身是无状态的,一般通过负载均衡组件(Nginx、Kubernetes Ingress、NodePort、LVS)对外提供统一的访问地址并提供服务。
由于 Milvus 采用大规模并行处理(MPP)架构,proxy 会先对执行节点返回的中间结果进行全局聚合和后处理后,再返回至客户端。
![]()
2、协调服务层(Coordinator Service):系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
协调服务共有四种角色:
root coord :负责处理数据定义语言(DDL)和数据控制语言(DCL)请求。比如,创建或删除 collection、partition、index 等,同时负责维护中心授时服务 TSO 和时间窗口的推进。
query coord :负责管理 query node 的拓扑结构和负载均衡以及从 growing segment 移交切换到 sealed segment。Query node 中的 segment 只存在两种状态:growing 和 sealed,分别对应增量数据和历史数据。
data coord :负责管理 data node 的拓扑结构,维护数据的元信息以及触发 flush、compact 等后台数据操作。
index coord :负责管理 index node 的拓扑结构,构建索引和维护索引元信息。
补充:
1、segment 是什么?
segment是Milvus中存储插入数据的自动创建的数据文件。一个collection可以包含多个segments,每个segment可以包含许多实体。在向量相似度搜索期间,Milvus会检查每个segment来编译搜索结果。
Milvus中有三种状态的segments:
Growing Segment (增长段)
Sealed Segment (封闭段)
这是一个已关闭的segment,不能再分配给proxy进行数据插入2
在以下情况下,growing segment会被sealed:
使用空间达到总空间的75%
用户手动调用Flush()
growing segments长时间未sealedFlushed Segment (已刷新段)
这是已经写入磁盘的segment- 只有当sealed segment中分配的空间过期后,该segment才能被刷新这种设计使得任何插入到Milvus的数据都可以立即被搜索。
2、flush是什么操作?
flush操作的主要功能是将数据持久化到存储中
工作原理:
当数据插入成功时,Milvus首先将数据加载到消息队列中1
然后数据节点将消息队列中的数据以增量日志的形式写入持久化存储- 调用flush()会强制数据节点立即将消息队列中的所有数据写入持久化存储注意事项:
不建议在每次数据插入后都调用flush()2
因为这会产生许多小型sealed segments,可能逐渐降低搜索性能- 建议等待Milvus自动seal所有segments后再进行搜索。
3、工作节点(Worker Node):系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。

4、存储服务层 (Storage): 系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
存储服务是系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
元数据存储:负责存储元信息的快照,比如:集合 schema 信息、节点状态信息、消息消费的 checkpoint 等。元信息存储需要极高的可用性、强一致和事务支持,因此,etcd 是这个场景下的不二选择。除此之外,etcd 还承担了服务注册和健康检查的职责。
对象存储:负责存储日志的快照文件、标量/向量索引文件以及查询的中间处理结果。Milvus 采用 MinIO 作为对象存储,另外也支持部署于 AWS S3 和 Azure Blob 这两大最广泛使用的低成本存储。但是,由于对象存储访问延迟较高,且需要按照查询计费,因此 Milvus 未来计划支持基于内存或 SSD 的缓存池,通过冷热分离的方式提升性能以降低成本。
消息存储:消息存储是一套支持回放的发布订阅系统,用于持久化流式写入的数据,以及可靠的异步执行查询、事件通知和结果返回。执行节点宕机恢复时,通过回放消息存储保证增量数据的完整性。
目前,分布式版Milvus依赖 Pulsar 作为消息存储,单机版Milvus依赖 RocksDB 作为消息存储。消息存储也可以替换为 Kafka、Pravega 等流式存储。
3、Milvus 的主要节点
Milvus 支持两种部署模式,单机模式(standalone)和分布式模式(cluster)。两种模式具备完全相同的能力,用户可以根据数据规模、访问量等因素选择适合自己的模式。Standalone 模式部署的 Milvus 暂时不支持在线升级为 cluster 模式。
单机版 Milvus 主要包括三个节点
Milvus 负责提供系统的核心功能。
Etcd 是元数据引擎,用于管理 Milvus 内部组件的元数据访问和存储,例如:proxy、index node 等。
MinIO 是存储引擎,负责维护 Milvus 的数据持久化。
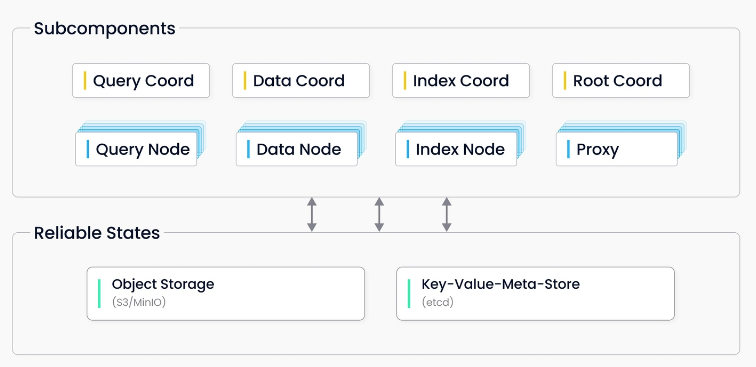
分布式版 Milvus 由八个微服务组件和三个第三方依赖组成,每个微服务组件可使用 Kubernetes 独立部署
微服务组件
Root coord
Proxy
Query coord
Query node
Index coord
Index node
Data coord
Data node
第三方依赖
etcd 负责存储集群中各组件的元数据信息。
MinIO 负责处理集群中大型文件的数据持久化,如索引文件和全二进制日志文件。
Pulsar 负责管理近期更改操作的日志,输出流式日志及提供日志订阅服务。
Kafka
适用于对数据实时性要求不那么高的场景
Kafka 接收各个客户端产生的数据来模拟生成的流式数据,当 Kafka 队列中有数据到达时,读取 Kafka 中的数据,当数据积累到一定量(比如数据为 10 万)的时候,批量插入 Milvus 中,这样能够减少插入次数,提高整体检索性能。
适用于数据实时性要求较高的场景
Kafka 接收各个客户端产生的数据来模拟生成的流式数据。当 Kafka 消息队列中有数据时,数据接收端持续从 Kafka 队列中读取数据并立即插入 Milvus 中。 Milvus 中插入向量的数据量是可大可小的,用户可一次插入十条向量,也可一次插入数十万条向量。
Zookeeper


4、安装部署
docker-compose 单机版 Milvus 部署
1、安装 docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io
systemctl start docker
systemctl enable docker
docker version
vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://dockerproxy.com",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://ccr.ccs.tencentyun.com" ]
}
systemctl daemon2、安装 docker-compose
curl -L "https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 添加执行权限
chmod +x /usr/local/bin/docker-compose
echo 'export PATH=$PATH:/usr/local/bin' >> ~/.bashrc
source ~/.bashrc
# 验证安装是否成功
docker-compose --version3、安装 Milvus
# 新建一个名为milvus的目录用于存放数据 目录名称可以自定义
mkdir milvus
# 进入到新建的目录
cd milvus
# 下载并编辑docker-compose.yml
# CPU单机版
wget https://github.com/milvus-io/milvus/releases/download/v2.3.5/milvus-standalone-docker-compose.yml -O docker-compose.yml
# GPU单机版
wget https://github.com/milvus-io/milvus/releases/download/v2.3.5/milvus-standalone-docker-compose-gpu.yml -O docker-compose.yml
# 下载完后修改其内容
修改minio镜像名
image: docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Z
修改milvus镜像名
image: 10.0.31.201/k8s/milvus:v2.4.13-hotfix
在倒数第三行上面添加以下内容
attu:
container_name: attu
image: zilliz/attu:v2.4
restart: always
environment:
MILVUS URL: standalone:19530
ports:
- "8000:3000"
depends_on:
- "standalone"4、拉取镜像
docekr pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Z
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Z docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Z
docker pull quay.io/coreos/etcd:v3.5.5
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/milvusdb/milvus:v2.4.8
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/milvusdb/milvus:v2.4.8 milvusdb/milvus:v2.4.8
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/zilliz/attu:v2.4
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/zilliz/attu:v2.4 zilliz/attu:v2.45、docker-compose 部署
docker compose up -d
docker ps 


k8s 中 集群版 Milvus 部署
1、环境准备
服务器 4 台
系统:Anolis OS 8.9
软件环境:Docker、kubernetes 集群
数据盘:
1、minio 对象存储使用:每台服务器的数据盘数量和大小相同,每台至少分配一块独立的数据盘,每块数据盘大小相同(/milvus/minio1)。
2、etcd、kafka、zookeeper 和 docker 使用(/data1)
2、 系统环境初始化
每台服务器上安装 Docker;
在所有服务器的基础上安装 kubernetes 集群;
3、集群信息
IP |
角色 |
hostname |
minio 数据盘 |
其他数据盘 |
control-plane |
master-1 |
/milvus/minio1 |
/data1 |
|
worker |
node-1 |
/milvus/minio1 |
/data1 |
|
worker |
node-2 |
/milvus/minio1 |
/data1 |
|
worker |
node-3 |
/milvus/minio1 |
/data1 |
涉及的镜像拉取
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/milvusdb/milvus:v2.3.21
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/minio/minio:RELEASE.2024-06-13T22-53-53Z
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka:3.3
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/etcd:3.5.14
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/zookeeper:3.8.3
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/milvusdb/milvus-config-tool:v0.1.2 4、安装 etcd
在三台 node 节点执行以下操作
mkdir -p /data1/milvus/etcd/data
chown -R 1001:1001 /data1/milvus/etcd/node-1 执行
docker run -d \
--name etcd \
--network host \
--restart always \
-v /data1/milvus/etcd/data:/bitnami/etcd/data \
-v /etc/localtime:/etc/localtime \
-e ETCD_NAME=milvus-01 \
-e ALLOW_NONE_AUTHENTICATION=yes \
-e ETCD_INITIAL_ADVERTISE_PEER_URLS=http://10.0.41.84:3380 \
-e ETCD_LISTEN_PEER_URLS=http://0.0.0.0:3380 \
-e ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:3379 \
-e ETCD_ADVERTISE_CLIENT_URLS=http://10.0.41.84:3379 \
-e ETCD_INITIAL_CLUSTER_TOKEN=milvus-etcd-cluster \
-e ETCD_INITIAL_CLUSTER=milvus-01=http://10