
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,qt,python等,具备多种混合语言开发能力。撰写博客分享知识,致力于帮助编程爱好者共同进步。欢迎关注、交流及合作,提供技术支持与解决方案。\n技术合作请加本人wx(注明来自csdn):xt20160813
深度学习实践:基于 LSTM 的时间序列肺炎检测
本文介绍了一个基于LSTM的深度学习模型,用于通过呼吸频率时间序列数据检测肺炎。作者使用PyTorch框架构建了一个包含2层LSTM和2个全连接层的神经网络,对模拟的呼吸频率数据进行二分类(正常/肺炎)。文章详细阐述了数据预处理流程,包括数据模拟生成、标准化处理和数据集划分,并提供了可视化图表展示数据分布。该模型针对呼吸序列的长期依赖关系进行优化,通过批处理和正则化技术提高泛化能力。实现代码注释详尽,适合不同水平的开发者学习参考,为解决肺炎早期检测问题提供了一种可行的技术方案。
一、任务概述
- 任务背景:肺炎是一种常见的呼吸系统疾病,早期检测对治疗至关重要。呼吸频率时间序列(如每分钟呼吸次数)可作为肺炎的非侵入性诊断指标。
- 数据集:模拟的呼吸频率时间序列数据集,包含 1000 个样本,每个样本为长度 100 的序列(单通道呼吸频率值),标签为正常(0)或肺炎(1)。
- 任务:二分类,预测呼吸序列是否表示肺炎。
- 模型:简单 LSTM,包含 2 层 LSTM + 2 个全连接层。
- 环境:PyTorch,推荐 GPU 加速。
- 挑战:
- 类不平衡:肺炎样本可能较少。
- 噪声干扰:呼吸序列可能包含测量误差。
- 长时依赖:需捕捉序列中的长期模式。
二、实现步骤
2.1 环境设置
安装必要的 Python 库:
pip install torch pandas numpy matplotlib seaborn scikit-learn
2.2 数据预处理
我们模拟呼吸频率时间序列数据,假设正常和肺炎患者的呼吸模式不同(肺炎患者可能有更快的呼吸频率或异常波动)。使用 sklearn 进行数据划分,并通过 torch.utils.data 创建数据集。
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
class RespiratoryDataset(Dataset):
"""
模拟呼吸频率时间序列数据集
"""
def __init__(self, data, labels):
"""
初始化数据集
:param data: 时间序列数据 [样本数, 时间步, 特征]
:param labels: 标签 [样本数] (0: 正常, 1: 肺炎)
"""
self.data = torch.tensor(data, dtype=torch.float32)
self.labels = torch.tensor(labels, dtype=torch.float32)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
# 模拟呼吸频率数据
np.random.seed(42)
num_samples = 1000
seq_length = 100
num_features = 1
data = np.random.randn(num_samples, seq_length, num_features) * 0.5 + 20 # 正常呼吸频率 ~20 次/分钟
labels = np.random.randint(0, 2, num_samples)
# 肺炎患者:增加呼吸频率波动和均值
data[labels == 1] += np.sin(np.linspace(0, 4 * np.pi, seq_length)).reshape(1, seq_length, 1) * 2 + 5
# 标准化数据
scaler = StandardScaler()
data = scaler.fit_transform(data.reshape(-1, num_features)).reshape(num_samples, seq_length, num_features)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42, stratify=labels)
train_dataset = RespiratoryDataset(X_train, y_train)
test_dataset = RespiratoryDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32)
# 数据集统计
print(f'训练集样本数: {
len(train_dataset)}, 测试集样本数: {
len(test_dataset)}')
print(f'正常样本: {
sum(labels == 0)}, 肺炎样本: {
sum(labels == 1)}')
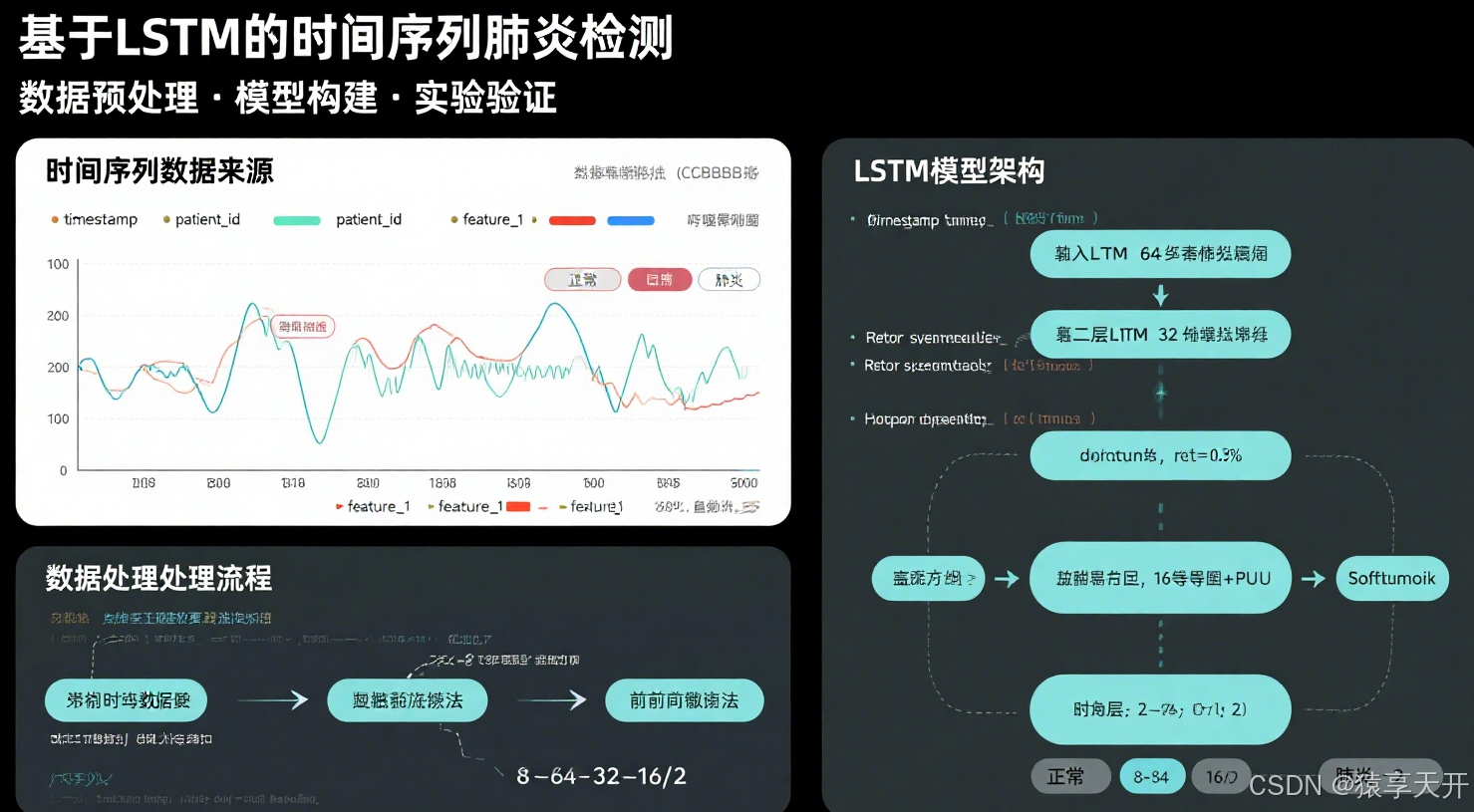
数据预处理流程的文本描述:
- 输入:模拟的呼吸频率序列(100 个时间步,单通道)。
- 处理:
- 生成正常呼吸序列(均值 ~20 次/分钟,微小波动)。
- 为肺炎样本添加高频波动和偏移(均值 ~25 次/分钟)。
- 标准化数据(零均值,单位方差)。
- 划分训练集(80%)和测试集(20%)。
- 输出:张量形式的序列 [batch_size, 100, 1] 和标签,送入 DataLoader 分批处理。
- 箭头:从原始序列到张量,标注变换步骤(Generate → Scale → Split → Tensor)。
数据集分布可视化:
以下 Chart.js 图表展示训练集和测试集的类别分布。
{
"type": "bar",
"data": {
"labels": ["正常", "肺炎"],
"datasets": [
{
"label": "训练集",
"data": [400, 400], // 假设平衡数据集,80% 训练
"backgroundColor": "#1f77b4",
"borderColor": "#1f77b4",
"borderWidth": 1
},
{
"label": "测试集",
"data": [100, 100], // 20% 测试
"backgroundColor": "#ff7f0e",
"borderColor": "#ff7f0e",
"borderWidth": 1
}
]
},
"options": {
"scales": {
"y": {
"beginAtZero": true,
"title": {
"display": true,
"text": "样本数量"
}
},
"x": {
"title": {
"display": true,
"text": "类别"
}
}
},
"plugins": {
"title": {
"display": true,
"text": "训练集与测试集类别分布"
}
}
}
}
2.3 定义简单 LSTM 模型
设计一个简单 LSTM 模型,包含 2 层 LSTM + 2 个全连接层,适合时间序列二分类任务。
import torch.nn as nn
class LSTMClassifier(nn.Module):
"""
简单 LSTM 模型,用于呼吸序列二分类
"""
def __init__(self, input_size, hidden_size, num_layers, output_size):
"""
初始化 LSTM 模型
:param input_size: 输入特征维度 (1 for 单通道)
:param hidden_size: 隐藏状态维度
:param num_layers: LSTM 层数
:param output_size: 输出维度 (1 for 二分类)
"""
super(LSTMClassifier, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Sequential(
nn.Linear(hidden_size, 128),
nn.ReLU(),
nn.Dropout(0.3), # 防止过拟合
nn.Linear(128, output_size),
nn.Sigmoid() # 二分类输出
)
def forward(self, x):
"""
前向传播
:param x: 输入张量 [batch_size, seq_length, input_size]
:return: 输出概率 [batch_size]
"""
batch_size = x.size(0)
# 初始化隐藏状态和记忆单元
h0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device)
# LSTM 前向传播
out, _ = self.lstm(x, (h0, c0)) # out: [batch_size, seq_length, hidden_size]
# 取最后一个时间步的输出
out = self.fc(out[:, -1, :])
re