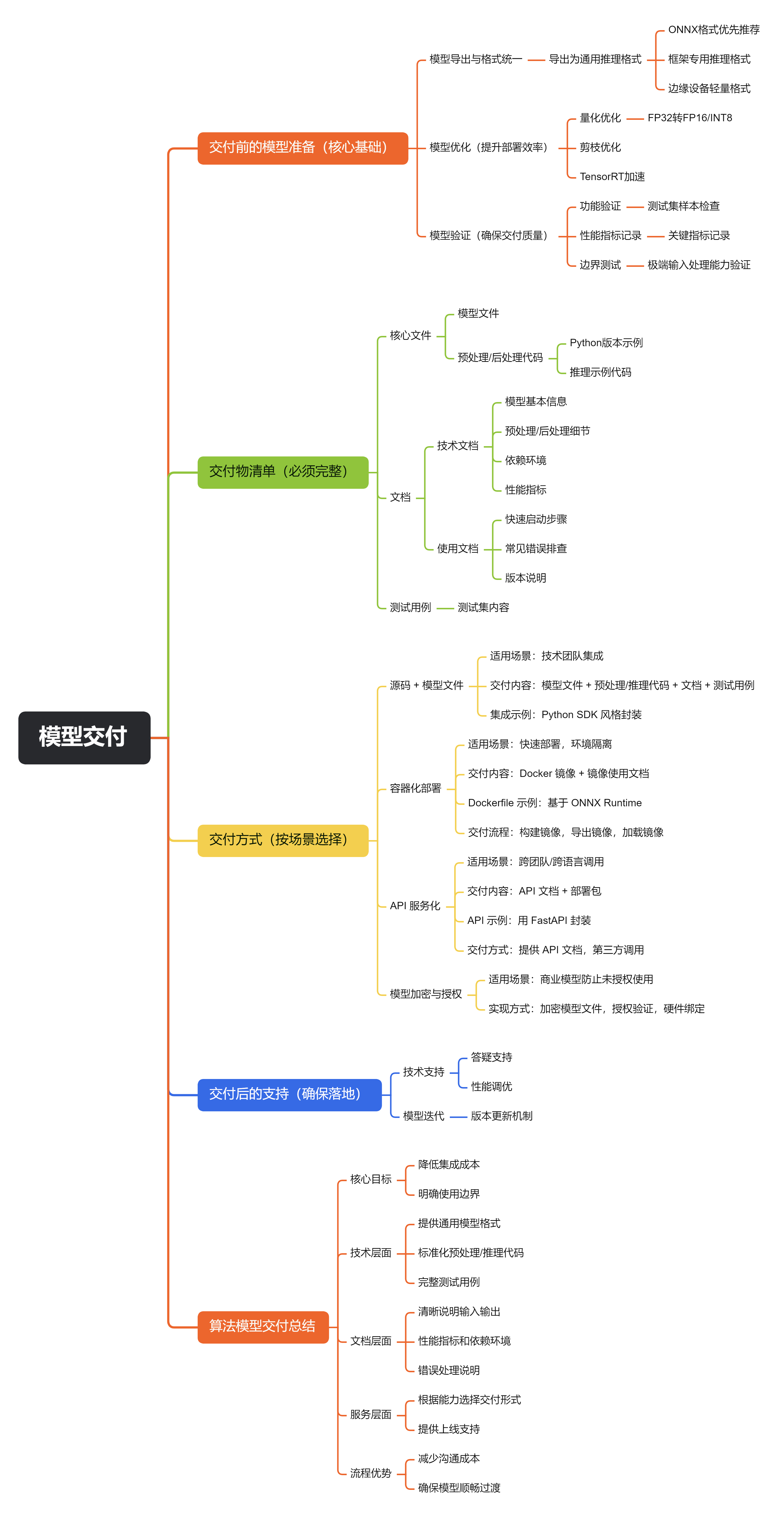
作为算法工程师,模型训练完成后的交付不仅是提供一个模型文件,更需要确保第三方(可能是工程团队、客户或其他业务方)能正确集成、高效部署、稳定运行,并明确模型的使用边界。以下是系统化的交付流程和具体方案,覆盖技术细节、文档规范和常见场景:
一、交付前的模型准备(核心基础)
在交付前,需对模型进行标准化处理,确保兼容性和可用性:
1. 模型导出与格式统一
训练好的模型(如 PyTorch 的.pth、TensorFlow 的.ckpt)需导出为通用推理格式,避免依赖训练框架,降低部署门槛:
- ONNX:跨框架通用格式(支持 PyTorch/TensorFlow/TensorRT 等),优先推荐。
# PyTorch模型导出为ONNX示例 import torch model = torch.load("train_model.pth") # 加载训练好的模型 model.eval() dummy_input = torch.randn(1, 3, 224, 224) # 符合模型输入shape的占位数据 torch.onnx.export( model, dummy_input, "model.onnx", input_names=["input"], output_names=["output"], dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}} # 支持动态batch ) - 框架专用推理格式:如 TensorFlow 的
.pb/SavedModel、PyTorch 的TorchScript(.pt),适合确定框架的场景。 - 边缘设备格式:若部署在边缘端(如手机、嵌入式设备),需转为轻量格式:TensorFlow Lite(
.tflite)、PyTorch Mobile(.ptl)、ONNX Runtime Mobile。
2. 模型优化(提升部署效率)
对导出的模型进行优化,降低推理 latency 和资源占用(尤其重要 for 生产环境):
- 量化:将 32 位浮点数(FP32)转为 16 位(FP16)或 8 位(INT8),精度损失可控(通常 < 1%),但推理速度提升 2-4 倍,显存占用减半。
# ONNX量化示例(用onnxruntime) from onnxruntime.quantization import quantize_dynamic, QuantType quantize_dynamic( "model.onnx", "model_quantized.onnx", weight_type=QuantType.INT8 ) - 剪枝:移除冗余参数(如不重要的卷积核),减小模型体积(适合边缘设备)。
- TensorRT 加速:对 GPU 部署,用 TensorRT 将 ONNX 转为优化的引擎文件(
.engine),利用 GPU 硬件特性(如 Tensor Core)进一步提速。
3. 模型验证(确保交付质量)
交付前必须验证模型功能和性能,提供可复现的测试报告:
- 功能验证:用测试集样本检查模型输出是否与训练时一致(避免导出 / 优化过程中出错)。
- 性能指标:记录关键指标(准确率 / 召回率、推理延迟(P50/P99)、显存占用、CPU/GPU 使用率),附测试环境(硬件型号、框架版本)。
- 边界测试:验证极端输入(如空数据、超大规模输入)的处理能力,避免部署时崩溃。
二、交付物清单(必须完整)
除模型文件外,需提供配套资源,确保第三方能 “开箱即用”:
1. 核心文件
- 模型文件:导出的推理格式(如
model.onnx、model_quantized.onnx)+ 训练时的配置文件(config.yaml,含超参数、预处理方式等)。 - 预处理 / 后处理代码:模型输入的标准化(如归一化、Resize)、输出的解析(如解码分类概率、NMS 处理目标检测框),需提供 Python/Java/C++ 版本(根据第三方技术栈)。
# 预处理示例(分类模型) import cv2 import numpy as np def preprocess(image_path): # 读取并 resize 为模型输入尺寸 img = cv2.imread(image_path) img = cv2.resize(img, (224, 224)) # BGR转RGB(若模型训练时用RGB) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 归一化(与训练时一致) img = img / 255.0 img = (img - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225]) # 转为batch格式((1, 3, 224, 224)) img = np.transpose(img, (2, 0, 1))[None, ...].astype(np.float32) return img - 推理示例代码:不同场景的调用示例(如 Python 单条推理、批量推理、多线程推理)。
2. 文档(最关键的交付物之一)
必须包含技术文档和使用文档,避免第三方反复沟通:
- 技术文档:
- 模型基本信息(任务类型:分类 / 检测 / 分割;输入 shape:
(batch, 3, 224, 224);输出格式:(batch, 1000)对应类别概率)。 - 预处理 / 后处理细节(如归一化均值方差、坐标格式:相对坐标 / 绝对坐标)。
- 依赖环境(推理框架:ONNX Runtime 1.14.0;CUDA 版本:11.7;CPU/GPU 最低配置)。
- 性能指标(测试集准确率:92.5%;GPU 推理延迟:8ms / 张;CPU 延迟:50ms / 张)。
- 模型基本信息(任务类型:分类 / 检测 / 分割;输入 shape:
- 使用文档:
- 快速启动步骤(如 “安装依赖→加载模型→调用预处理→推理→解析输出”)。
- 常见错误排查(如 “输入维度错误”“ONNX Runtime 版本不兼容” 的解决方法)。
- 版本说明(模型版本:v1.0;训练数据截止时间:2024-08;更新日志)。
3. 测试用例
提供最小可复现的测试集(10-20 个样本,含输入、预期输出),方便第三方验证集成是否正确:
test_cases/
├── images/ # 测试图片
├── inputs.npy # 预处理后的输入数据(numpy格式)
├── expected_outputs.npy # 模型预期输出
└── test.py # 自动测试脚本(运行后输出通过率)
三、交付方式(按场景选择)
根据第三方的技术能力和部署场景,选择合适的交付形式:
1. 源码 + 模型文件(适合技术团队集成)
- 适用场景:第三方是工程团队,需将模型集成到自有系统(如后端服务、APP)。
- 交付内容:模型文件 + 预处理 / 推理代码(Python/C++) + 文档 + 测试用例。
- 集成示例:提供 Python SDK 风格的封装,方便调用:
# model_sdk.py import onnxruntime as ort import numpy as np class ModelInference: def __init__(self, model_path): self.session = ort.InferenceSession(model_path) self.input_name = self.session.get_inputs()[0].name self.output_name = self.session.get_outputs()[0].name def predict(self, preprocessed_data): """preprocessed_data: 预处理后的numpy数组""" outputs = self.session.run([self.output_name], {self.input_name: preprocessed_data}) return outputs[0] # 第三方使用方式 model = ModelInference("model.onnx") data = preprocess("test.jpg") # 用提供的预处理函数 result = model.predict(data)
2. 容器化部署(适合快速上线,环境隔离)
- 适用场景:第三方需要快速部署,或模型依赖复杂(如特定 CUDA 版本、系统库)。
- 交付内容:Docker 镜像(含模型、推理代码、依赖环境) + 镜像使用文档。
- Dockerfile 示例(基于 ONNX Runtime):
# 基础镜像(含ONNX Runtime和Python) FROM mcr.microsoft.com/onnxruntime/python:1.14.0-cuda11.6-cudnn8-runtime WORKDIR /app # 复制模型和代码 COPY model.onnx . COPY model_sdk.py . COPY preprocess.py . # 安装额外依赖 RUN pip install opencv-python numpy # 启动命令(如提供API服务) CMD ["python", "api_server.py"] # api_server.py用FastAPI封装推理接口 - 交付流程:
- 构建镜像:
docker build -t model-inference:v1 . - 导出镜像:
docker save -o model_image.tar model-inference:v1 - 第三方加载镜像:
docker load -i model_image.tar,运行容器即可提供服务。
- 构建镜像:
3. API 服务化(适合跨团队 / 跨语言调用)
- 适用场景:第三方无需集成模型,只需通过网络调用(如前端、移动端、其他系统)。
- 交付内容:API 文档(含接口地址、请求 / 响应格式) + 部署包(如 Docker 镜像)。
- API 示例(用 FastAPI 封装):
# api_server.py from fastapi import FastAPI, UploadFile, File import numpy as np from model_sdk import ModelInference from preprocess import preprocess app = FastAPI() model = ModelInference("model.onnx") @app.post("/predict") async def predict(file: UploadFile = File(...)): # 读取图片并预处理 img = preprocess(await file.read()) # 推理 result = model.predict(img) # 后处理(如返回Top1类别) top1 = np.argmax(result[0]) return {"top1_class": int(top1), "confidence": float(result[0][top1])} - 交付方式:提供 API 文档(如 Swagger 自动生成的
/docs页面),第三方通过curl或 HTTP 客户端调用:curl -X POST "http://your-ip:8000/predict" -F "file=@test.jpg"
4. 模型加密与授权(商业场景)
- 适用场景:商业模型需防止未授权使用(如按调用次数收费、限制有效期)。
- 实现方式:
- 加密模型文件:用工具(如 TensorFlow 的
tf.keras.models.save_model带密码,或第三方加密库)加密模型,推理时需解密密钥。 - 授权验证:在推理代码中加入授权检查(如调用后端授权服务验证 license,有效期内方可运行)。
- 硬件绑定:限制模型仅能在指定设备(通过 CPU/GPU 序列号)运行。
- 加密模型文件:用工具(如 TensorFlow 的
四、交付后的支持(确保落地)
模型交付不是终点,需配合第三方完成集成和上线:
- 答疑支持:提供 1-2 周的技术支持,解答集成中的问题(如 “推理结果与测试集不一致”“部署后延迟过高”)。
- 性能调优:若第三方反馈推理速度不达标,协助优化(如调整 batch size、更换推理引擎、模型再量化)。
- 版本迭代:约定模型更新机制(如新增类别、提升精度时,如何平滑替换旧模型)。
总结
算法模型的交付核心是 “降低集成成本,明确使用边界”:
- 技术层面:提供通用格式的模型、标准化的预处理 / 推理代码、完整的测试用例;
- 文档层面:清晰说明输入输出、性能指标、依赖环境和错误处理;
- 服务层面:根据第三方能力选择交付形式(源码 / 容器 / API),并提供必要的上线支持。
通过系统化的交付流程,可大幅减少沟通成本,确保模型从 “训练完成” 到 “生产可用” 的顺畅过渡。
如果这个知识点对你有用,那就别客气——点赞、关注、收藏。你的每一次反馈都是给我打的小鸡血,一起冲鸭,变强不掉线!🐒🐒