系统使用中经常有数据库单表达到千万级的级别,查询特别慢,经常需要几秒到十几秒,影响用户体验。
接下来讲解下对mysql单表达到千万级别时,对单表进行分区来优化数据库查询。
假设有个记录从1990年开始全A股市场的日线行情的数据库表(共1500多万条记录):
CREATE TABLE `stock_daily_non_partitioned` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`symbol` varchar(10) NOT NULL COMMENT '股票代码',
`trade_date` date NOT NULL COMMENT '交易日期',
`open` decimal(10,2) NOT NULL COMMENT '开盘价',
`high` decimal(10,2) NOT NULL COMMENT '最高价',
`low` decimal(10,2) NOT NULL COMMENT '最低价',
`close` decimal(10,2) NOT NULL COMMENT '收盘价',
`volume` bigint(20) NOT NULL COMMENT '成交量(手)',
`turnover` decimal(16,2) NOT NULL COMMENT '成交额(元)',
`amplitude` decimal(16,2) NOT NULL COMMENT '振幅(%)',
`change_percent` decimal(10,2) NOT NULL COMMENT '涨跌幅(%)',
`change_amount` decimal(10,2) NOT NULL COMMENT '涨跌额(元)',
`turnover_rate` decimal(5,2) NOT NULL COMMENT '换手率(%)',
PRIMARY KEY (`symbol`,`trade_date`,`id`),
UNIQUE KEY `idx_symbol_date` (`symbol`,`trade_date`),
UNIQUE KEY `idx_id` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15558685 DEFAULT CHARSET=utf8mb4 COMMENT='A股每日行情数据'
这里我们把trade_date作为分区键,而分区键必须是主键的一部分,所以这里没有设置id作为单独主键。
(一)数据准备
1.克隆表结构
CREATE TABLE stock_daily_partitioned LIKE stock_daily;
CREATE TABLE stock_daily_non_partitioned LIKE stock_daily;
2.导入数据
INSERT INTO stock_daily_partitioned SELECT * FROM stock_daily;
INSERT INTO stock_daily_non_partitioned SELECT * FROM stock_daily;
3.修改分区键为主键的一部分
如果分区键不是主键的一部分,则需要修改。
-- 1. 删除原主键和自增属性(如果有)
ALTER TABLE stock_daily_partitioned
DROP PRIMARY KEY; -- 移除主键列的
-- 2. 创建包含分区键的新主键
ALTER TABLE stock_daily_partitioned
ADD PRIMARY KEY (symbol, trade_date, id); -- 分区键必须在主键中
4.分区方案设计
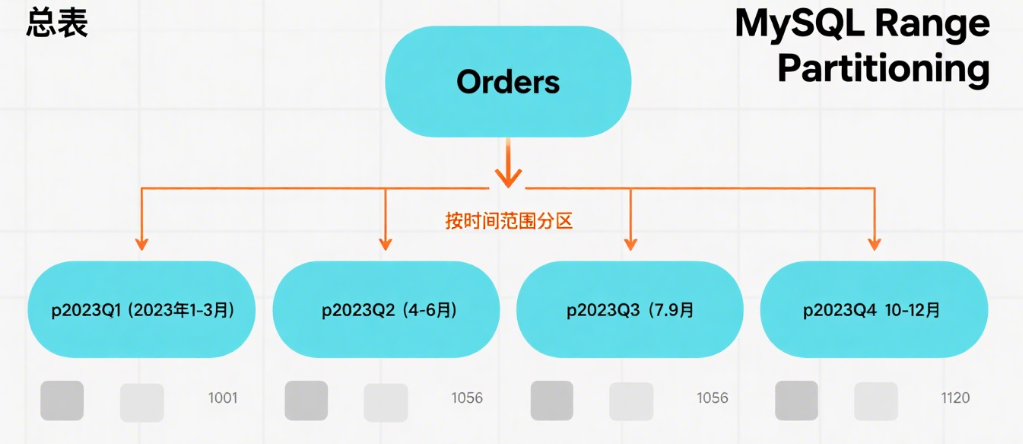
据查询模式(如按日期范围过滤),推荐按trade_date进行范围分区:
ALTER TABLE stock_daily
PARTITION BY RANGE COLUMNS(trade_date) (
PARTITION p2018 VALUES LESS THAN ('2019-01-01'),
PARTITION p2019 VALUES LESS THAN ('2020-01-01'),
PARTITION p2020 VALUES LESS THAN ('2021-01-01'),
PARTITION p2021 VALUES LESS THAN ('2022-01-01'),
PARTITION p2022 VALUES LESS THAN ('2023-01-01'),
PARTITION p2023 VALUES LESS THAN ('2024-01-01'),
PARTITION p_future VALUES LESS THAN (MAXVALUE)
);
一般是按数据查询的热门程度进行分区,不一定是严格按照每年进行分区。
5.查看分区状态
接着可以执行下列命令,查看数据库表是否分区成功
# 查看create_options是否有partitioned标识
SHOW TABLE STATUS LIKE 'stock_daily_partitioned';
# 查看建表语句是否有PARTITION标识
SHOW CREATE TABLE stock_daily_non_partitioned;
(二)性能测试
1.按日期范围查询
-- 非分区表
SELECT COUNT(*) FROM stock_daily
WHERE trade_date BETWEEN '2020-01-01' AND '2020-12-31';
-- 分区表(应只扫描p2020分区)
SELECT COUNT(*) FROM stock_daily_partitioned
WHERE trade_date BETWEEN '2020-01-01' AND '2020-12-31';
在我的电脑上显示,非分区表耗时4s281ms,而分区表耗时346ms。
性能提高约十几倍。
2.按股票代码+日期查询
-- 非分区表
SELECT * FROM stock_daily_non_partitioned
WHERE symbol = '600000' AND trade_date = '2023-05-20';
-- 分区表
SELECT * FROM stock_daily_partitioned
WHERE symbol = '600000' AND trade_date = '2023-05-20';
两者均耗时40多ms,没有性能提升。
3.跨分区范围查询
-- 非分区表
SELECT AVG(close) FROM stock_daily_non_partitioned
WHERE trade_date BETWEEN '2009-01-01' AND '2023-12-31';
-- 分区表(需扫描p2019~p2023分区)
SELECT AVG(close) FROM stock_daily_partitioned
WHERE trade_date BETWEEN '2009-01-01' AND '2023-12-31';
非分区表耗时7s301ms,分区表耗时7s187ms。
若分区范围太广,则没有性能提升。若分区范围小,则视情况有大概有数倍的性能提升。
4.测试写入性能
-- 测试:插入一条2024年的新数据
-- 非分区表
INSERT INTO stock_daily_non_partitioned (symbol, trade_date, open, high, low, close, volume, turnover, amplitude, change_percent, change_amount, turnover_rate)
VALUES ('600000', '2026-08-13', 10.50, 10.80, 10.40, 10.60, 1000000, 10600000.00, 3.81, 0.95, 0.10, 2.50);
-- 分区表(应写入p2024分区)
INSERT INTO stock_daily_partitioned (symbol, trade_date, open, high, low, close, volume, turnover, amplitude, change_percent, change_amount, turnover_rate)
VALUES ('600000', '2026-08-13', 10.50, 10.80, 10.40, 10.60, 1000000, 10600000.00, 3.81, 0.95, 0.10, 2.50);
经测试,两者的插入耗时约十几ms左右,无性能差别。
5.平均执行时间
使用SQL_CALC_FOUND_ROWS或BENCHMARK函数,或通过客户端工具(如 Navicat、MySQL Workbench)记录执行耗时,多次执行取平均值(建议 10 次以上)。
示例:用BENCHMARK测试重复执行效率
-- 测试查询执行100次的耗时(非分区表)
SELECT BENCHMARK(100,
(SELECT COUNT(*) FROM stock_daily_non_partitioned WHERE trade_date BETWEEN '2020-01-01' AND '2020-12-31')
);
-- 分区表
SELECT BENCHMARK(100,
(SELECT COUNT(*) FROM stock_daily_partitioned WHERE trade_date BETWEEN '2020-01-01' AND '2020-12-31')
);
在我的电脑上显示,命中分区表的情况下,非分区表耗时4s331ms,而分区表耗时365ms。
性能提高约十几倍。
6.执行计划分析
通过EXPLAIN查看查询是否使用分区修剪(分区表特有优化),确认是否只扫描必要分区。
-- 分区表执行计划(关注"partitions"列,显示涉及的分区)
EXPLAIN PARTITIONS
SELECT COUNT(*) FROM stock_daily_partitioned
WHERE trade_date BETWEEN '2020-01-01' AND '2020-12-31';
若partitions列只显示p2020,说明分区修剪生效(高效);若显示所有分区,说明分区策略不合理或查询条件未命中分区键。
7.资源消耗
通过SHOW PROFILE查看 CPU、IO 等资源占用(需开启 profiling):
-- 开启 profiling
SET profiling = 1;
-- 执行测试查询
SELECT COUNT(*) FROM stock_daily WHERE trade_date BETWEEN '2020-01-01' AND '2020-12-31';
-- 查看结果
SHOW PROFILE CPU, BLOCK IO FOR QUERY 1; -- 1是查询ID

一般来说,分区总数不超过 50~100个,避免元数据开销。
8.总结
通过上述测试,有以下结论:
分区表优势场景:
- 按分区键(trade_date)的范围查询:分区表效率通常提升 50% 以上(因只扫描单个分区);
- 批量删除 / 归档历史数据:分区表可直接DROP PARTITION(毫秒级),而非分区表需DELETE(全表扫描,耗时久)。
性能差异不大的场景:
- 单条记录查询:因联合索引idx_symbol_date已优化,两者效率接近;
- 跨大量分区的查询:分区表需扫描多个分区,与非分区表全表扫描差异可能不大。
注意事项:
- 分区键选择错误会导致性能下降(如按id分区但查询用trade_date,分区表会扫描所有分区);
- 分区数量不宜过多(建议不超过 100 个),否则元数据管理成本上升。
(三)维护技巧
1.分区维护操作
-- 1. 新增分区(每年1月执行)
ALTER TABLE stock_daily_partitioned
REORGANIZE PARTITION p_future INTO (
PARTITION p2024 VALUES LESS THAN ('2025-01-01'),
PARTITION p_future VALUES LESS THAN (MAXVALUE)
);
-- 2. 合并旧分区(每3年执行)
ALTER TABLE stock_daily_partitioned
REORGANIZE PARTITION p2019, p2020 INTO (
PARTITION p2019_2020 VALUES LESS THAN ('2021-01-01')
);
-- 3. 删除归档数据(秒级完成)
ALTER TABLE stock_daily_partitioned
DROP PARTITION p_archive;
-- 4. 重建分区(优化性能)
ALTER TABLE stock_daily_partitioned
REBUILD PARTITION p2023;
2.查看分区大小
-- 查看分区大小
SELECT
PARTITION_NAME,
TABLE_ROWS,
DATA_LENGTH/1024/1024 AS size_mb,
INDEX_LENGTH/1024/1024 AS index_mb
FROM information_schema.PARTITIONS
WHERE TABLE_NAME = 'stock_daily_partitioned';