Hive作为Apache顶级项目,是Hadoop生态系统中最具影响力的SQL查询引擎,它解决了大数据处理与传统SQL技能之间的鸿沟。Hive的核心价值在于将类SQL查询语言HiveQL无缝转换为分布式计算框架MapReduce的任务,使数据分析师能够利用熟悉的SQL语法操作Hadoop中的海量数据,无需掌握复杂的MapReduce编程模型。本文将从Hive的基本概念、架构设计、工作原理到实际应用场景进行全面解析,帮助技术开发人员深入了解这一大数据处理工具。
一、Hive是什么:诞生背景与核心价值
Hive诞生于2007年,由Facebook公司开发,2008年8月开源并成为Apache顶级项目 。它的出现源于大数据处理的困境:Hadoop虽然提供了强大的分布式存储和计算能力,但MapReduce编程模型对数据分析师来说门槛过高。传统数据仓库的OLAP分析需求与Hadoop的静态批处理特性之间存在巨大鸿沟,Hive正是为弥合这一鸿沟而设计的数据仓库工具。
Hive的核心价值体现在三个方面:
首先,它降低了大数据处理的技术门槛。Hive提供了类SQL查询语言HiveQL,使熟悉SQL的数据分析师能够轻松操作Hadoop中的数据,无需掌握Java或MapReduce编程。这一特性使得Hive在数据仓库的统计分析领域获得了广泛应用,特别适合处理海量日志数据和用户行为数据。
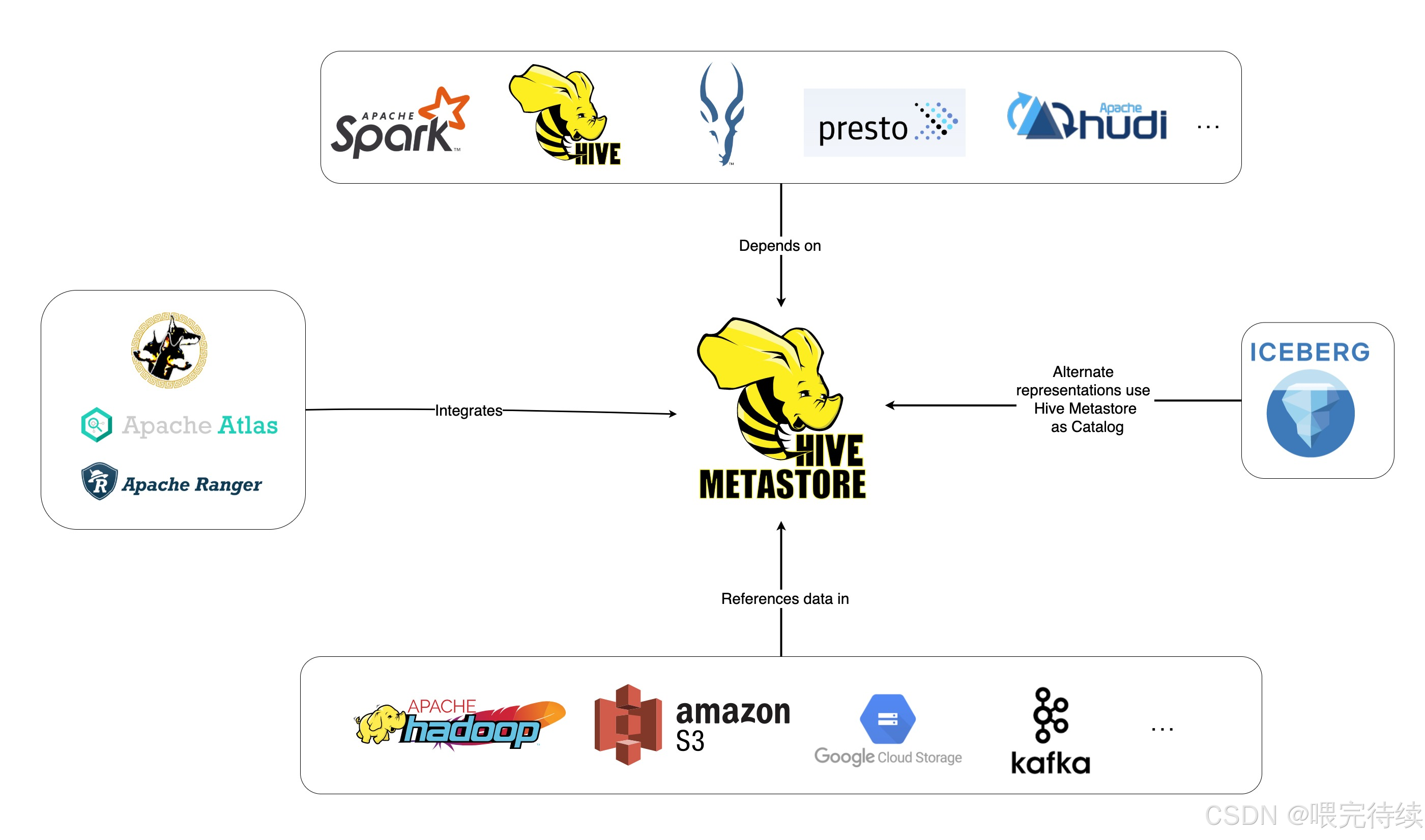
其次,Hive为Hadoop提供了元数据管理能力。它通过Metastore组件将表结构、列属性和分区信息等元数据存储在关系型数据库中,大大简化了数据仓库的管理。这种元数据管理方式不仅提高了查询效率,还使Hive能够与其他Hadoop组件(如Spark、HBase)协同工作,形成完整的数据处理生态。
最后,Hive支持灵活的数据存储格式和ETL流程。它支持TextFile、SequenceFile、RCFile、ORC等多种文件格式,并提供了强大的ETL工具,使数据能够从各种来源导入、转换并加载到Hadoop数据仓库中。这种灵活性使Hive成为处理异构数据源的理想工具。
二、Hive的架构设计:组件与交互流程
Hive的架构设计充分考虑了大数据处理的需求,它主要由以下组件构成:
HiveServer2是Hive的服务端组件,负责接收和处理客户端的查询请求。用户可以通过CLI、JDBC、ODBC或REST API等方式连接到HiveServer2,提交HiveQL查询。HiveServer2通过Thrift协议与客户端通信,支持多用户并发访问。
Metastore是Hive的元数据管理组件,负责存储表结构、列属性、分区信息等元数据。Metastore使用关系型数据库(如MySQL、PostgreSQL)作为后端存储,并通过Thrift接口提供元数据服务,使HiveServer2、Spark等组件能够访问和操作元数据。Metastore可以配置为本地模式或远程模式,后者通过Thrift服务提供跨语言访问能力,如thrift://master:9083 。
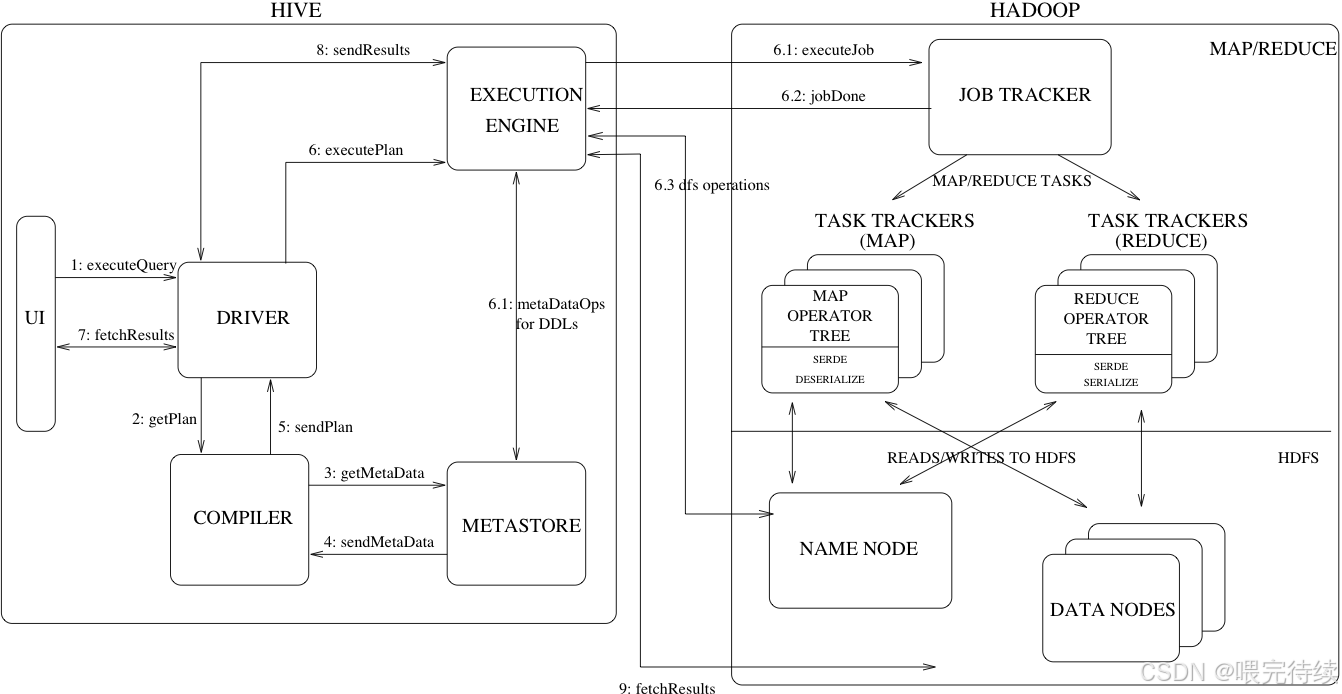
Driver是Hive的核心执行组件,包含Compiler、Optimizer和Executor三个模块。Compiler负责将HiveQL解析为逻辑执行计划,Optimizer对执行计划进行优化(包括逻辑优化和物理优化),Executor将优化后的计划转换为分布式任务(如MapReduce或Spark作业)并提交到YARN集群执行 。
ZooKeeper集群用于协调HiveServer2实例,记录各实例的IP地址列表,客户端通过ZooKeeper获取可用的HiveServer2实例并进行连接。这种设计提高了Hive服务的可用性和扩展性。
HDFS/HBase集群是Hive的数据存储层,Hive表数据可以存储在HDFS或HBase中。Hive通过HCatalog(基于Metastore)提供表和存储管理层,使用户能够通过不同的数据处理工具(如MapReduce)轻松读写HDFS上的数据。
YARN集群是Hive的任务执行层,负责资源管理和任务调度。Hive通过YARN的ResourceManager分配计算资源,NodeManager执行具体任务,形成完整的分布式计算环境。
Hive的架构设计遵循"计算与存储分离"的原则,将元数据管理、查询处理和数据存储分布在不同的组件中,既保证了系统的可扩展性,又简化了各个组件的实现复杂度。这种架构使得Hive能够适应从几十GB到PB级的数据处理需求,同时保持较低的维护成本。
三、Hive解决的问题:大数据处理的痛点
Hive主要解决以下大数据处理中的痛点:
大数据处理的技术门槛问题。传统Hadoop应用需要编写Java/MapReduce程序,这对熟悉SQL的数据分析师来说难度较大。Hive通过提供类SQL查询语言HiveQL,使数据分析人员能够利用熟悉的SQL语法操作Hadoop中的数据,大大降低了技术门槛。例如,一个简单的数据统计任务,使用HiveQL可能只需要几行代码,而用MapReduce则需要数百行代码。
数据仓库的元数据管理问题。Hadoop生态系统缺乏统一的元数据管理机制,导致数据难以被发现和理解。Hive通过Metastore组件提供结构化的元数据管理,使数据能够被有效组织、管理和查询。这种元数据管理方式不仅提高了数据的可发现性,还增强了数据的安全性和权限控制能力。
ETL流程的复杂性问题。大数据处理通常需要复杂的ETL流程,将数据从各种源系统导入、转换并加载到数据仓库中。Hive提供了一系列ETL工具和函数,简化了数据转换和加载过程。例如,Hive支持通过LOAD DATA命令直接从本地或HDFS导入数据,通过INSERT OVERWRITE命令进行数据转换和加载,大大简化了ETL流程。
大规模数据的查询效率问题。Hadoop的MapReduce编程模型虽然能够处理大规模数据,但启动和调度开销较大,导致查询响应时间较长。Hive通过优化HQL到MapReduce的转换过程,提高了查询效率 。例如,Hive的优化器能够合并多个MapReduce阶段,减少任务启动开销,提高整体查询性能。
数据与查询的分离问题。在传统数据库中,数据存储和查询处理通常紧密耦合,而在Hadoop生态系统中,数据存储(HDFS)和查询处理(MapReduce)是分离的。Hive通过提供统一的数据抽象和查询接口,解决了这一分离问题,使数据能够被一致地查询和分析。
四、Hive的关键特性:从批处理到实时分析
Hive具有以下关键特性:
类SQL查询语言HiveQL。Hive定义了一种类似于SQL的查询语言HiveQL,支持大部分标准SQL语法,如DDL、DML、DQL等。HiveQL的语法与传统SQL高度兼容,但功能上有所限制,如不支持更新、索引和事务,只支持"Write Once Read Many"的数据操作模式 。这种设计使Hive能够专注于大数据的查询和分析,而非事务处理。
多计算引擎支持。Hive可以配置为使用不同的计算引擎,包括MapReduce、Tez和Spark等。通过简单的配置参数(如hive.exec.engine),用户可以在不同引擎之间切换,适应不同的计算需求 。例如,对于延迟敏感的查询,可以使用Spark或Tez引擎;对于资源受限的场景,可以使用MapReduce引擎。
元数据管理与共享。Hive的Metastore组件提供元数据服务,管理表结构、列属性和分区信息等。Metastore支持多客户端访问,如HiveServer2、Spark和WebHCat等,使元数据能够被不同组件共享和使用。这种元数据共享机制不仅提高了数据管理效率,还促进了Hadoop生态系统的整合。
数据存储格式多样性。Hive支持多种数据存储格式,包括TextFile、SequenceFile、RCFile和ORC等。ORC(Optimized Row Columnar)格式是Hive推荐的列式存储格式,具有高压缩率和查询效率 。例如,ORC文件支持row group index和bloom filter index等索引机制,可以显著减少查询的输入数据量,提高查询性能。
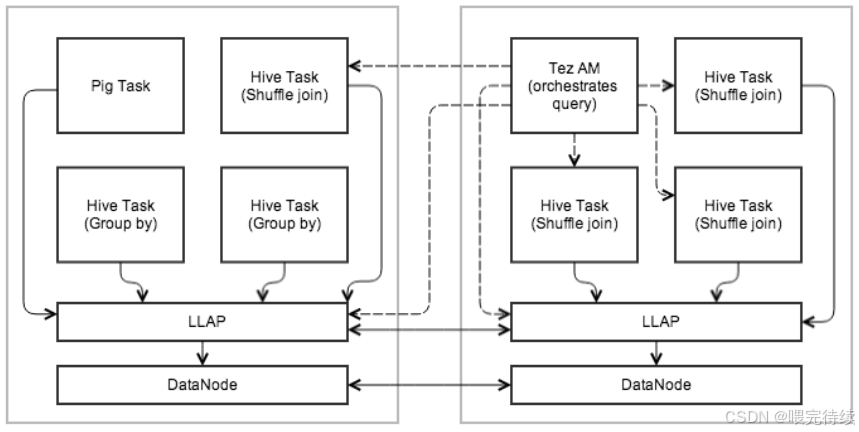
LLAP(低延迟分析处理)。Hive LLAP是Hive的实时查询特性,通过持久化查询服务器和内存缓存,将查询延迟降低至秒级 。LLAP结合了持久查询服务器和优化的内存缓存,使Hive能够立即启动查询,避免不必要的磁盘开销。在物流数据仓库中,LLAP被用于实现实时数据查询,满足决策支持需求。
分区与分桶。Hive支持表的分区和分桶,用于组织和管理大规模数据。分区将数据按特定字段划分为多个目录,分桶将数据按哈希值划分为多个文件,都减少了查询时的数据扫描量,提高了查询效率 。在电商大数据平台中,商品表可以根据商品分类或地区进行分区或分桶,提高查询效率。
用户定义函数(UDF)。Hive允许用户自定义函数,扩展HiveQL的功能。UDF可以是Java、Python或C#编写的函数,用于处理时间、字符串和其他复杂的数据操作。在车联网数据仓库中,可以使用自定义UDF解析JSON格式的半结构化数据,将其转换为结构化数据进行存储和查询。这些关键特性使Hive成为处理大规模结构化数据的首选工具,特别适合数据仓库的统计分析和ETL流程。
五、Hive与同类产品对比:各有所长
Hive与Spark SQL、Impala和Presto等同类产品在大数据处理领域各有所长,以下是它们的核心对比:
| 特性 | Hive | Spark SQL | Impala | Presto |
|---|---|---|---|---|
| 查询延迟 | 分钟级 | 秒级 | 毫秒级 | 秒级 |
| 数据存储 | HDFS/HBase | 内存/HDFS | HDFS | 多数据源 |
| 计算引擎 | MapReduce/Tez/Spark | Spark | Impala MPP | 自有引擎 |
| 元数据管理 | Metastore | 共享Metastore | 共享Metastore | 自有目录 |
| 适用场景 | 大规模批处理/ETL | 批处理/流处理 | 实时交互式查询 | 跨数据源查询 |
| 资源占用 | 较低 | 较高 | 较高 | 中等 |
| ACID支持 | 有限 | 有限 | 基本支持 | 有限 |
Hive与Spark SQL的对比:两者都基于Hadoop生态系统,支持HiveQL/SQL查询,但实现方式不同 。Hive通过HiveServer2接收查询,转换为MapReduce/Tez/Spark任务执行;Spark SQL则直接基于Spark引擎处理查询。Hive on Spark架构可以复用Hive的元数据和HQL语法,但Spark SQL在内存计算和复杂查询优化上更具优势 。
Hive与Impala的对比:Impala是Cloudera开发的MPP(大规模并行处理)SQL查询引擎,专为Hadoop设计 。Impala直接操作HDFS文件,无需元数据转换,支持ACID事务,查询速度比Hive快10到50倍 。
Hive与Presto的对比:Presto是Facebook开发的分布式SQL查询引擎,支持跨多数据源的查询。Presto能够从Hive、MySQL、Cassandra等多种数据源查询数据,并在单个查询中合并结果。在企业数据湖场景中,Presto可以同时查询Hive表和关系型数据库中的数据,提供统一的分析视图。然而,Hive在Hadoop生态内的整合更为紧密,对HDFS数据的处理更为高效。
Hive与HBase的对比:HBase是Hadoop生态系统中的分布式NoSQL数据库,提供实时读写能力。HBase适合需要低延迟读写的场景,而Hive适合需要复杂查询和分析的场景。在社交媒体平台中,HBase用于实时存储用户状态和动态,Hive用于分析用户行为和社交网络。两者可以结合使用,形成完整的数据处理解决方案。
六、Hive的工作原理:从HQL到MapReduce
Hive的工作原理可以概括为将HiveQL查询转换为分布式计算任务(如MapReduce)并在Hadoop集群上执行的过程。这一转换过程由HiveServer2驱动,通过Driver组件(包含Compiler、Optimizer和Executor)完成 ,具体流程如下:
首先,用户通过CLI、JDBC或REST API提交HiveQL查询。HiveServer2接收查询请求后,通过Metastore获取表结构、列属性和分区信息等元数据,确保查询的语法和语义正确性。
其次,Compiler将HiveQL解析为逻辑执行计划。Hive的编译器使用类似传统数据库的查询优化技术,将HiveQL转换为逻辑操作符树 ,如SELECT、WHERE、JOIN等。这一步骤类似于传统数据库的查询解析和优化过程,但针对的是Hadoop生态系统。
然后,Optimizer对逻辑执行计划进行优化。Hive的优化器分为逻辑优化器和物理优化器,分别对HiveQL生成的执行计划和MapReduce任务进行优化。逻辑优化器可以合并多个MapReduce阶段,减少任务启动开销;物理优化器可以根据数据分布和计算需求,选择最优的MapReduce任务配置。
最后,Executor将优化后的执行计划转换为分布式任务(如MapReduce或Spark作业)并提交到YARN集群执行 。Executor根据配置的计算引擎(MapReduce、Tez或Spark),将逻辑执行计划转换为相应的分布式任务 ,如MapReduce的Job和Task,Spark的RDD操作等。这些任务在YARN集群上并行执行,最终将结果返回给用户。整个过程的关键在于HiveQL到分布式计算任务的转换,这使得Hive能够将SQL查询无缝集成到Hadoop生态系统中。Hive的转换机制依赖于Hadoop的分布式存储和计算能力,同时通过元数据管理和查询优化提高效率。
七、Hive的使用方法:从安装到查询
Hive的使用方法主要包括安装配置、元数据管理、表操作和查询执行等步骤。以下是Hive的基本使用流程:
安装与配置。Hive需要先安装和配置Hadoop和元数据库(如MySQL) 。安装Hive后,需要配置hive-site.xml文件,设置元数据库连接信息、计算引擎类型和其他关键参数 。例如,配置MySQL作为元数据库:
<configuration>
<!-- Metastore 配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 执行引擎配置 -->
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
</configuration>表创建与数据加载。Hive支持创建内部表和外部表。内部表的数据存储在Hive数据仓库中(默认路径为/hive/warehouse/),而外部表的数据可以存储在HDFS的任意位置。创建表后,可以通过LOAD DATA命令从本地或HDFS导入数据,或通过INSERT OVERWRITE命令从其他表导入数据 。例如,创建一个日志表并加载数据:
CREATE EXTERNAL TABLE log4jLogs (
t1 string,
t2 string,
t3 string,
t4 string,
t5 string,
t6 string,
t7 string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
STORED AS TEXTFILE
LOCATION '/example/data/';
LOAD DATA LOCAL INPATH '/path/to/logfile.txt'
INTO TABLE log4jLogs;数据查询与分析。Hive支持标准的SQL语法进行数据查询和分析。用户可以通过HiveQL执行SELECT、WHERE、JOIN、GROUP BY等操作,进行数据统计、汇总和分析。例如,查询日志表中的错误信息:
SELECT t4 AS error_type, COUNT(*) AS count
FROM log4jLogs
WHERE t1 = 'ERROR'
GROUP BY t4
ORDER BY count DESC;数据转换与ETL。Hive提供了丰富的ETL工具和函数,用于数据转换和加载。用户可以通过HiveQL执行数据清洗、转换和加载操作 ,将数据从原始格式转换为适合分析的格式。例如,在车联网数据仓库中,可以使用HiveQL解析JSON格式的半结构化数据,将其转换为结构化数据并存储到Hive表中 。
INSERT OVERWRITE TABLE structured_data
SELECT
get_json_object(json_data, '$.user_id') AS user_id,
get_json_object(json_data, '$.event_type') AS event_type,
get_json_object(json_data, '$.timestamp') AS timestamp
FROM raw_data;性能优化。Hive提供了多种性能优化手段,如分区、分桶、压缩和统计信息收集等 。用户可以通过合理设计表结构、使用高效的存储格式(如ORC)和收集统计信息,显著提高查询性能 。例如,在电商大数据平台中,商品表可以根据商品分类或地区进行分区或分桶,提高查询效率 。
CREATE TABLE product_data (
product_id STRING,
category STRING,
price DOUBLE,
region STRING
)
PARTITIONED BY (category STRING)
BUCKETS 128
STORED AS ORC;多引擎切换。Hive可以配置为使用不同的计算引擎,如MapReduce、Tez或Spark等。用户可以通过设置hive.exec.engine参数切换计算引擎 ,适应不同的计算需求。例如,在高校数字化校园大数据平台中,Hive可以切换到Spark引擎处理实时数据查询,提高响应速度 。
SET hive.exec.engine=spark;八、Hive的适用场景:日志分析到数据仓库
Hive适用于多种大数据处理场景,主要包括:
日志分析。Hive是处理网络日志和用户行为日志的理想工具。Hive的批处理特性适合处理海量日志数据,提取有价值的信息。分析网站访问模式、用户行为特征和系统性能指标等。在Hadoop的早期应用中,Hive主要用于Facebook等互联网公司的日志分析和用户行为分析 。
ETL流程。Hive提供了强大的ETL工具和函数,适合数据清洗、转换和加载流程。Hive的ETL能力使其成为构建数据仓库的理想工具。
数据仓库。Hive是Hadoop生态系统中的数据仓库工具,适合存储和管理结构化数据。Hive的元数据管理和分区分桶特性使其成为构建企业数据仓库的理想选择。
数据湖。Hive可以与HBase、HDFS等存储系统结合使用,形成数据湖架构。Hive的灵活性使其能够处理多种数据格式和来源,适应复杂的数据分析需求。
跨数据源查询。虽然Hive主要面向HDFS数据,但也可以与Spark、HBase等系统集成,实现跨数据源查询。Hive的多引擎支持使其能够适应不同的数据存储和计算需求 。
九、Hive的发展趋势:批处理到实时分析
Hive作为Hadoop生态系统中的重要组件,其发展趋势主要体现在以下几个方面:
实时查询能力增强。Hive LLAP是Hive向实时查询领域的重要扩展,通过持久化查询服务器和内存缓存,将查询延迟降低至秒级 。LLAP结合了持久查询服务器和优化的内存缓存,使Hive能够立即启动查询,避免不必要的磁盘开销。
多引擎支持扩展。Hive不断扩展对不同计算引擎的支持,如Spark、Tez和LLAP等。通过统一的HiveQL接口和灵活的引擎切换机制,Hive能够适应不同的计算需求 。
与Spark生态的融合。Hive on Spark架构是Hive与Spark生态融合的重要成果,通过共享元数据和计算引擎,提高整体性能和功能 。Hive on Spark不仅提高了查询性能,还增强了Hive的功能,如支持更多SQL特性。
云平台支持增强。随着云计算的发展,Hive不断增强对云平台的支持,如AWS EMR、Azure HDInsight等。云平台提供的弹性资源和预配置环境使Hive能够更灵活地适应不同的计算需求。
ACID事务支持改进。Hive不断改进对ACID事务的支持,从0.14版本开始支持有限的事务操作 。通过与HBase等存储系统的集成,Hive能够提供更好的事务支持 ,适应更广泛的业务场景。在金融大数据分析中,Hive可以与HBase结合使用,提供既支持分析又支持事务的数据处理方案。
十、Hive的总结与建议:技术发展与应用前景
Hive作为Hadoop生态系统中的数据仓库工具,通过提供类SQL查询语言HiveQL,降低了大数据处理的技术门槛,使数据分析师能够利用熟悉的SQL语法操作Hadoop中的数据。Hive的核心价值在于将SQL查询无缝集成到Hadoop生态系统中,提供了一种平衡易用性和性能的数据处理方案随着大数据技术的发展,Hive也在不断演进,从最初的MapReduce引擎到现在的多引擎支持(包括Spark、Tez和LLAP),Hive的查询性能和功能都在不断提升 。虽然Hive在实时查询方面不如Impala等MPP引擎,但在大规模批处理和ETL流程方面仍然具有优势。
对于技术开发人员,建议在以下场景中考虑使用Hive:
- 大规模结构化数据的批处理和分析,如日志分析、用户行为分析等 。
- 数据仓库的构建和管理,特别是需要长期保存和分析的场景 。
- ETL流程的实施,将数据从各种源系统导入、转换并加载到数据仓库中 。
- 与Hadoop生态系统的其他组件(如Spark、HBase)协同工作,形成完整的数据分析解决方案。
同时,也应认识到Hive的局限性,如高延迟、不支持事务处理等。对于需要低延迟查询的场景,可以考虑使用Impala等实时查询引擎;对于需要复杂数据处理的场景,可以考虑使用Spark SQL 。通过合理选择和组合不同的大数据处理工具,可以构建更高效、更灵活的数据分析平台。
Hive的未来发展将更加注重与AI/ML的融合、实时查询能力的提升和多数据源支持的增强 ,使其能够适应更广泛的数据分析需求。对于技术开发人员来说,深入了解Hive的工作原理和最佳实践,将有助于更好地利用这一工具解决实际业务问题,提升数据处理和分析效率。