文章目录
1 介绍
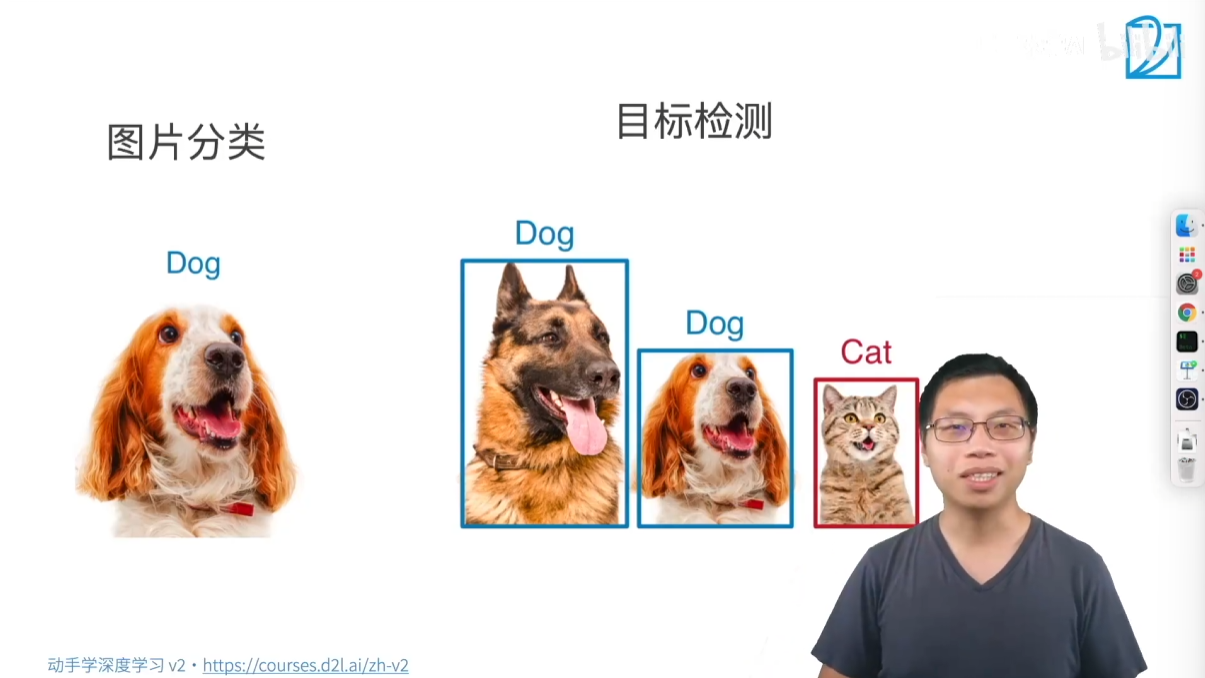
目标检测,也称为物体检测,是计算机视觉领域一个非常重要的应用。它的核心任务是在一张图片中识别出所有感兴趣的物体,并确定它们的位置。
这个任务比简单的图片分类要复杂得多,因为它需要处理以下两个问题:
- 识别多个物体:一张图片可能包含多个不同的物体(比如多只猫、多只狗、甚至猫和狗同时出现)。目标检测需要识别出所有这些物体。
- 定位物体位置:仅仅识别出物体还不够,它还需要用一个边界框(Bounding Box) 把每个物体圈出来,从而确定它们在图片中的具体位置。
| 特征 | 图片分类(Image Classification) | 目标检测(Object Detection) |
|---|---|---|
| 任务 | 判断一张图片的主体内容属于哪个类别。 | 识别图片中所有感兴趣的物体,并确定它们的类别和位置。 |
| 关注点 | 整体图像,通常假设图片中只有一个主体物体。 | 多个物体,即使它们属于同一类别。 |
| 输出 | 一个类别标签(例如:“狗”)。 | 多个物体的类别标签 和 它们对应的位置信息(边界框)。 |
| 举例 | 一张图片中有只狗,分类任务是判断这张图片是“狗”。 | 一张图片中有两只狗和一只猫,目标检测任务是识别出“狗1”、“狗2”、“猫1”,并用边界框标出它们各自的位置。 |
1.1 实际应用
目标检测在现实世界中有非常广泛的应用,以下是几个典型例子:
- 自动驾驶:这是目标检测一个非常重要的应用。自动驾驶汽车需要实时识别周围的车辆、行人、交通信号灯和路标等,以确保安全行驶。
- 智能零售/无人售货:系统可以自动识别顾客从货架上拿走了哪些商品,从而实现无人收银。
- 安防监控:识别可疑人员、遗留物品或车辆,并进行跟踪。
- 工业质检:识别产品上的缺陷或瑕疵。
1.2 边界框
**边界框(Bounding Box)**是目标检测中用来表示物体位置的核心概念。它是一个方框,通常用来粗略地圈出图片中的一个物体。
一个边界框可以用四个数字来定义,主要有两种常用的表示方法:
左上角和右下角坐标:
( x t o p _ l e f t , y t o p _ l e f t , x b o t t o m _ r i g h t , y b o t t o m _ r i g h t ) (x_{top\_left},y_{top\_left},x_{bottom\_right},y_{bottom\_right}) (xtop_left,ytop_left,xbottom_right,ybottom_right)- 优点:直观,可以直接确定框的对角线。
左上角坐标、宽度和高度:
( x t o p _ l e f t , y t o p _ l e f t , w , h ) (x_{top\_left},y_{top\_left},w,h) (xtop_left,ytop_left,w,h)- 优点:在某些计算中更方便,例如缩放或大小调整。

1.3 数据集
目标检测任务的数据集与图片分类有显著不同,因为其标注成本更高。
- 工作量大:每张图片可能包含多个物体,每个物体都需要单独标注。如果一张图片平均有 5 个物体,标注工作量至少是图片分类的 5 倍。
- 需要画框:标注者需要用鼠标拖动来画出每个物体的边界框,这比简单地选择一个类别标签要耗时得多。
由于标注成本高昂,目标检测的数据集通常比图片分类的数据集小。
一张图片可能对应多个物体和类别,数据不能像图片分类那样简单地按类别存放在子文件夹中。通常,标注信息会存放在一个单独的文件中,比如一个文本文件或 CSV 文件。
- 格式举例:每一行代表图片中的一个物体,包含以下信息:
- 文件名
- 物体类别
- 边界框的四个坐标值
COCO (Common Objects in Context) 是目标检测领域一个非常重要和广泛使用的大型数据集,它的地位类似于图片分类中的 ImageNet。
- 特点:
- 包含 80 个日常生活中常见的物体类别(如人、车辆、交通灯、飞机、日常用品等),类别数远少于 ImageNet 的 1000 类。
- 包含约 33 万张图片,标注了超过 150 万个物体。
- 用途:
- 由于其规模和多样性,COCO 数据集被广泛用于学术研究和模型性能评估。

2 锚框
由于直接预测边界框(Bounding Box) 的四个坐标值难度较大,基于锚框的算法提供了一种更有效的方法。
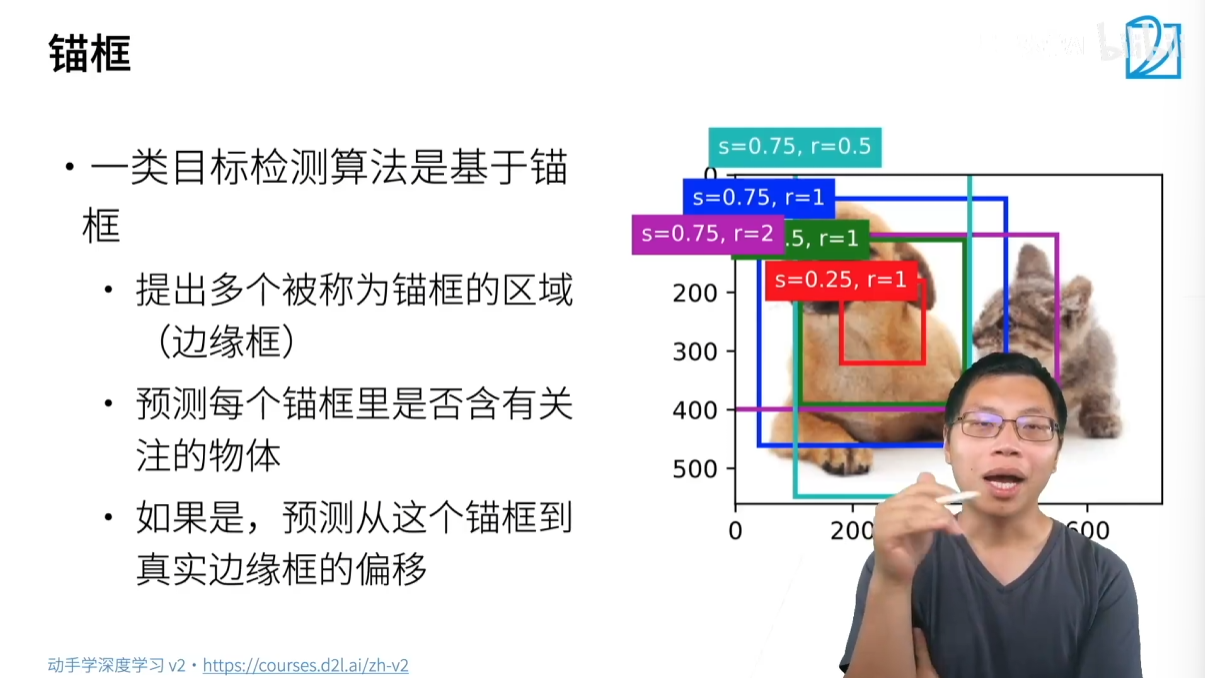
2.1 什么是锚框
锚框,也叫 Anchor Box,是目标检测算法预先生成的一系列候选框。算法会先在图片中生成大量的锚框,然后对每个锚框进行两项预测:
- 分类:判断这个锚框内是否包含感兴趣的物体(例如:狗、猫),或者只包含背景。
- 回归:如果锚框内有物体,则预测这个锚框需要进行多大的平移和缩放才能与真实的边界框(Ground Truth Bounding Box) 完全重合。
通过这种方法,算法不再是直接从零开始预测边界框的坐标,而是基于预设的锚框进行微调,这大大简化了预测任务。
基于锚框的算法需要进行两次预测:
- 第一次预测(分类):预测每个锚框是否包含某个物体,以及属于哪一类。
- 第二次预测(回归):预测每个锚框到真实边界框的偏移量。
这与目标检测需要预测类别和位置的任务相吻合。
2.2 交并比
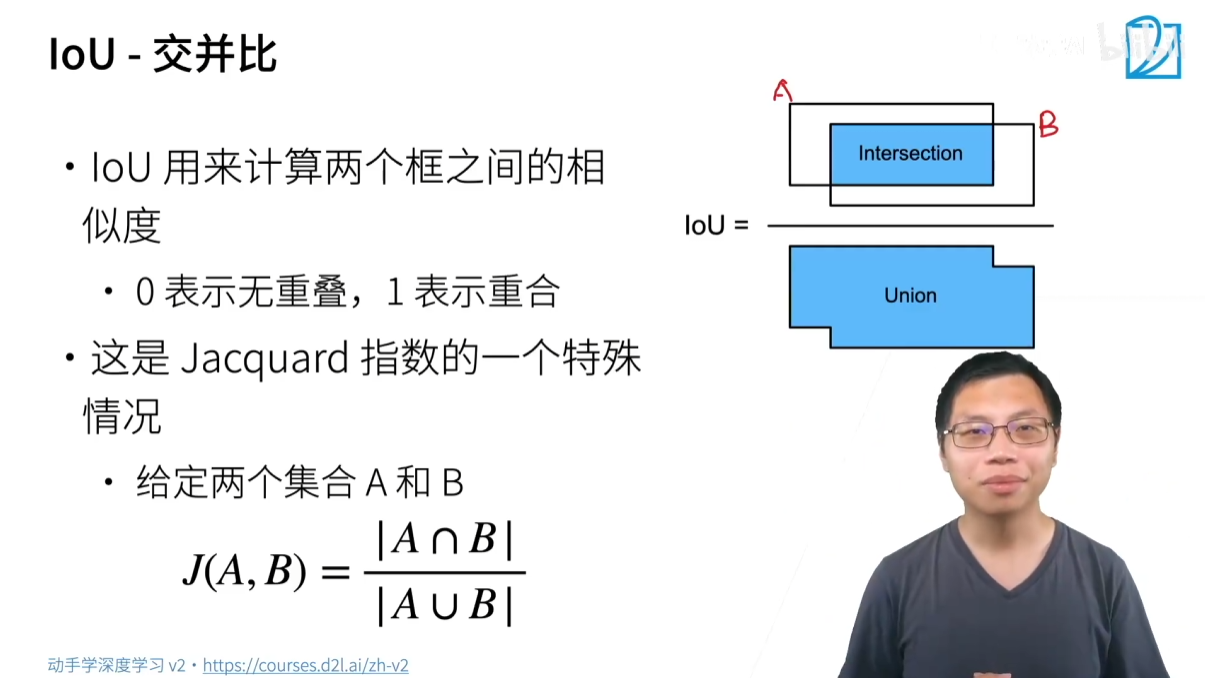
为了评估锚框与真实边界框的相似度,我们使用一个称为 IOU(Intersection over Union) 的指标。
IOU(交并比)是衡量两个框重叠程度的指标,其值在 0 到 1 之间:
- IOU = 0:两个框完全没有重叠。
- IOU = 1:两个框完全重合。
- IOU 的值越接近 1,表示两个框的相似度越高。
IOU 的计算方法非常直观:
I O U ( A , B ) = 面积 ( A ∪ B ) 面积 ( A ∩ B ) IOU(A,B)=面积(A∪B)面积(A∩B) IOU(A,B)=面积(A∪B)面积(A∩B)
其中:
- A 和 B 代表两个框。
- A∩B 是两个框的交集面积(重叠部分)。
- A∪B 是两个框的并集面积(两个框的总面积减去重叠面积)。
IOU 本质上是雅可比指数(Jaccard Index) 在边界框上的应用。如果我们将每个框看作一个像素集合,IOU 就是两个集合的交集大小除以它们的并集大小。
2.3 分配标签
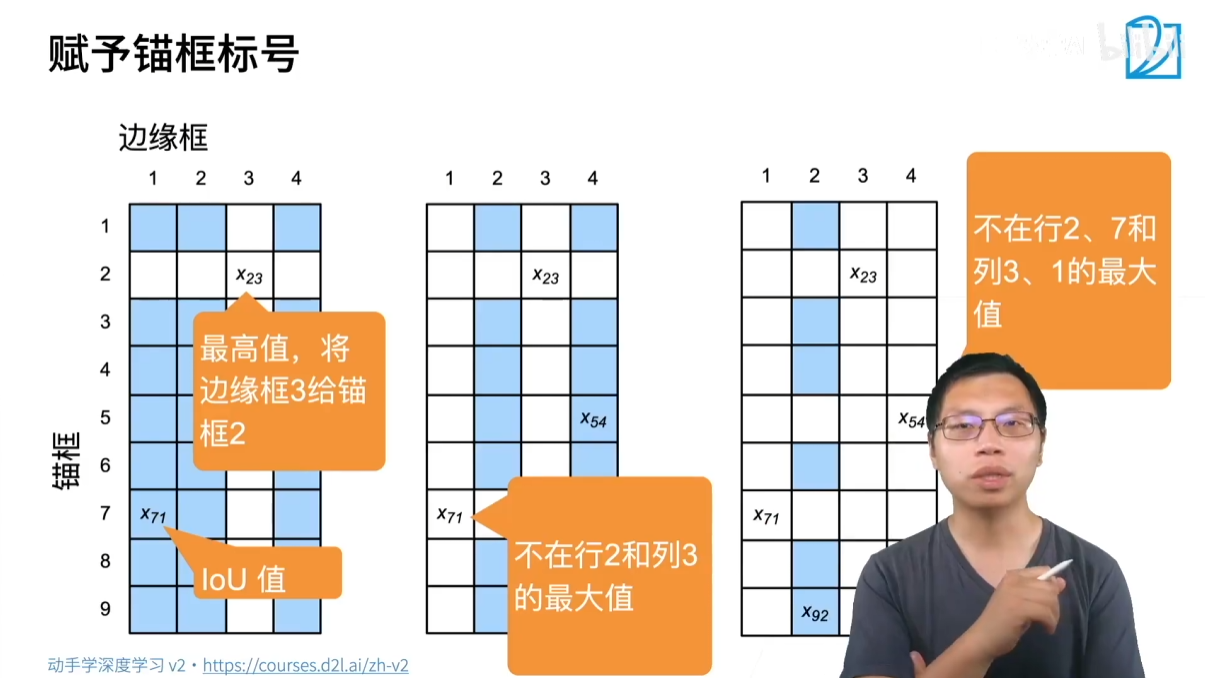
在训练模型时,我们需要为每个锚框分配一个“标签”,告诉模型这个锚框应该预测什么。
一个简单的分配策略是:
- 为每个真实边界框(Ground Truth Bounding Box),找到与之 IOU 值最大的那个锚框。将这个锚框标记为正样本,并将其与该真实边界框关联起来。
- 在剩下的锚框中,找到那些与任意一个真实边界框的 IOU 值大于某个阈值(比如 0.5)的锚框。这些锚框也标记为正样本。
- 所有不属于上述两类的锚框都被标记为负样本(即只包含背景)。

注意点:
- 一张图片可能会生成成千上万个锚框,但真实边界框通常只有十几个。因此,绝大多数锚框都是负类样本。
- 为锚框分配标签是一个动态过程,每次读入一张图片时都需要重新计算,因为锚框的位置是预设的,而真实边界框的位置是根据图片内容而变化的。
2.4 非极大值抑制
由于算法会为每个锚框生成一个预测结果,最终的输出会包含大量重叠且相似的预测框。NMS(Non-Maximum Suppression)的作用是去除冗余的预测框,得到一个干净、最终的预测结果。
NMS 的基本思想是保留那些置信度最高的预测框,并抑制(移除)那些与它高度重叠的低置信度预测框。
NMS 算法步骤:
- 筛选:从所有预测框中,筛选出那些置信度(即预测物体类别概率)大于某个阈值的非背景类预测框。
- 排序:将这些预测框按置信度从高到低排序。
- 迭代:
- 选取置信度最高的预测框作为最终预测。
- 移除(抑制)所有与该预测框 IOU 值大于某个阈值(例如 0.5)的其他预测框。
- 从剩余的预测框中,重复上述步骤,直到没有更多的预测框。
这个过程将确保最终输出的预测框是不重叠且置信度最高的。

3 经典目标检测网络
3.1 R-CNN
R-CNN (Region-based Convolutional Neural Network) 是目标检测领域一个里程碑式的工作,它首次将深度学习引入目标检测。
3.1.1 R-CNN (原始版本)
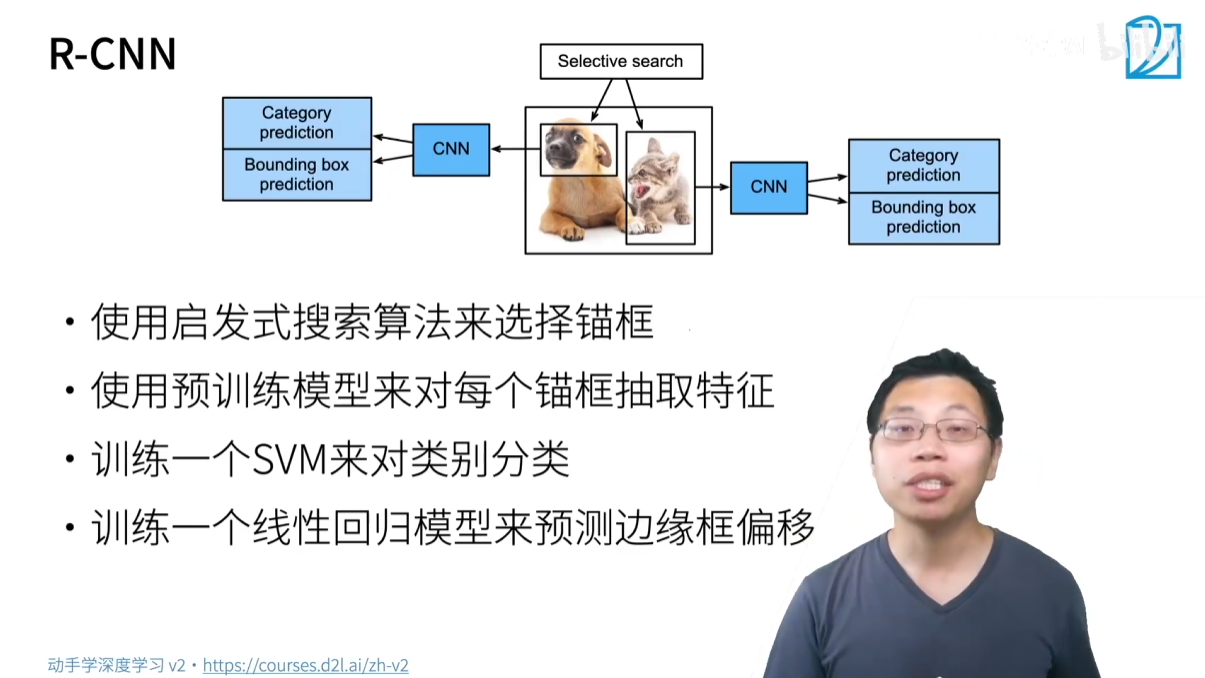
- 核心思想:这是一个“两阶段(two-stage)”算法,先生成候选区域,再对每个区域进行分类和回归。
- 流程:
- 区域建议(Region Proposal):使用一种传统的启发式算法(如 Selective Search)在图像中生成数千个锚框(候选区域)。
- 特征提取:将每个锚框中的内容裁剪并缩放成固定大小,然后输入到一个预训练的 CNN 模型(如 VGG, AlexNet)中提取特征。
- 分类和回归:
- 使用 SVM 分类器对提取的特征进行分类(判断是哪一类物体或背景)。
- 使用一个线性回归模型预测边界框的偏移量,对锚框进行微调。
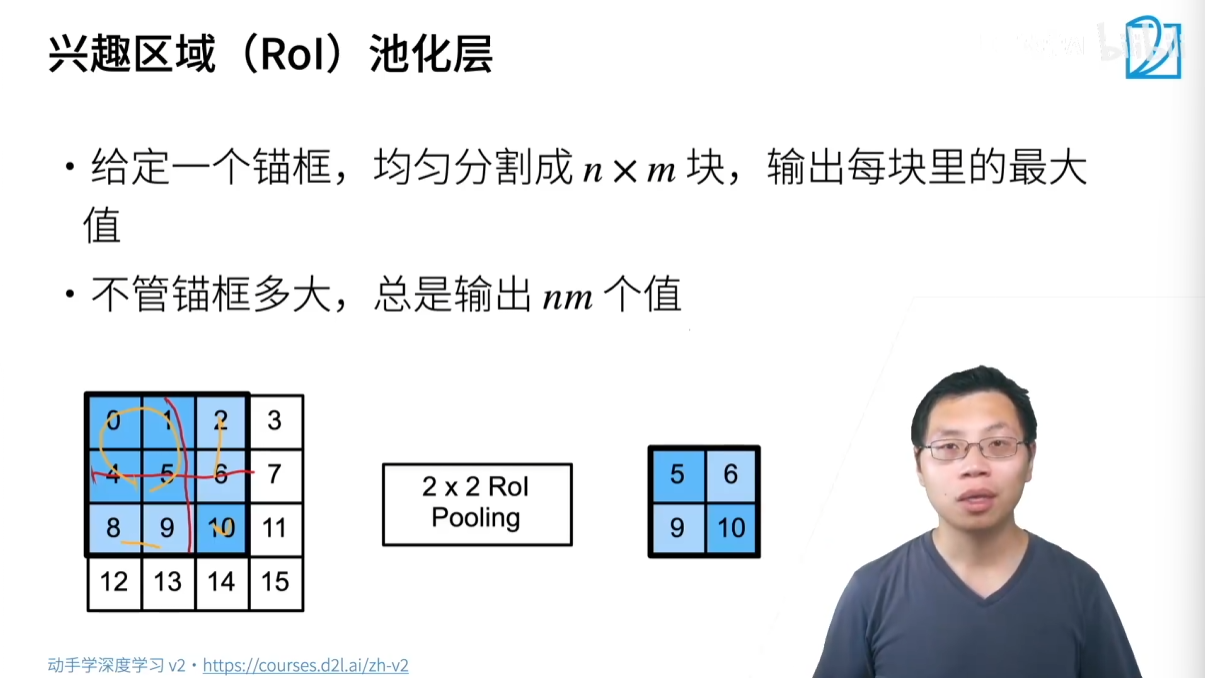
- 关键技术:ROI Pooling
- 为了处理不同大小的锚框,R-CNN 引入了 ROI (Region of Interest) Pooling。
- ROI Pooling 的作用是将任意大小的区域池化(pooling)成固定大小的输出(例如 7x7),这使得所有锚框的特征可以被送入到后续的全连接层。
- 方法:将 ROI 区域均匀地划分为 NxN 网格,然后在每个网格中执行最大池化,得到一个固定大小的特征图。
- 缺点:计算成本高。因为要对每个候选框都单独进行一次 CNN 特征提取,一张图片可能需要重复处理上千次。
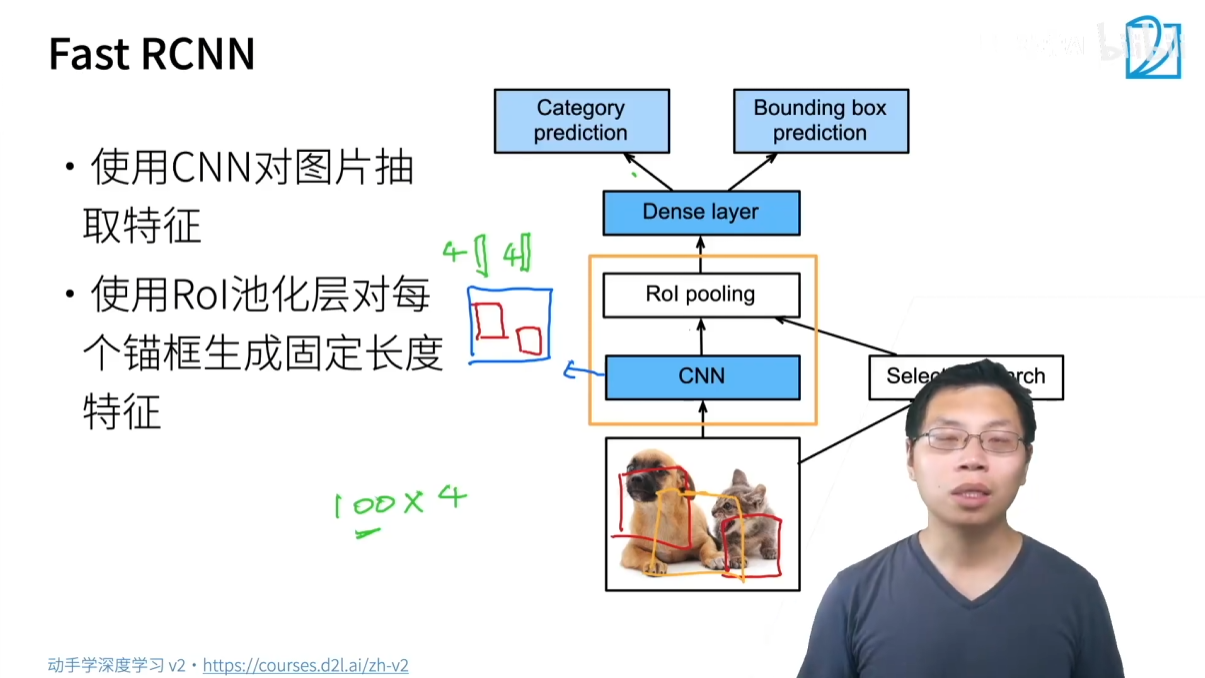
3.1.2 Fast R-CNN
- 核心思想:为了解决 R-CNN 的速度问题,Fast R-CNN 提出了只对整张图片进行一次 CNN 特征提取。
- 改进流程:
- 对整张图片进行 CNN 特征提取,得到一个完整的特征图(Feature Map)。
- 仍然使用 Selective Search 生成锚框。
- 将这些锚框映射到第一步生成的特征图上。
- 使用 ROI Pooling 从特征图上提取每个锚框的特征向量。
- 将特征向量送入全连接层,进行分类(使用 Softmax)和边界框回归。
- 优点:大幅提升速度,因为 CNN 特征提取只进行了一次。
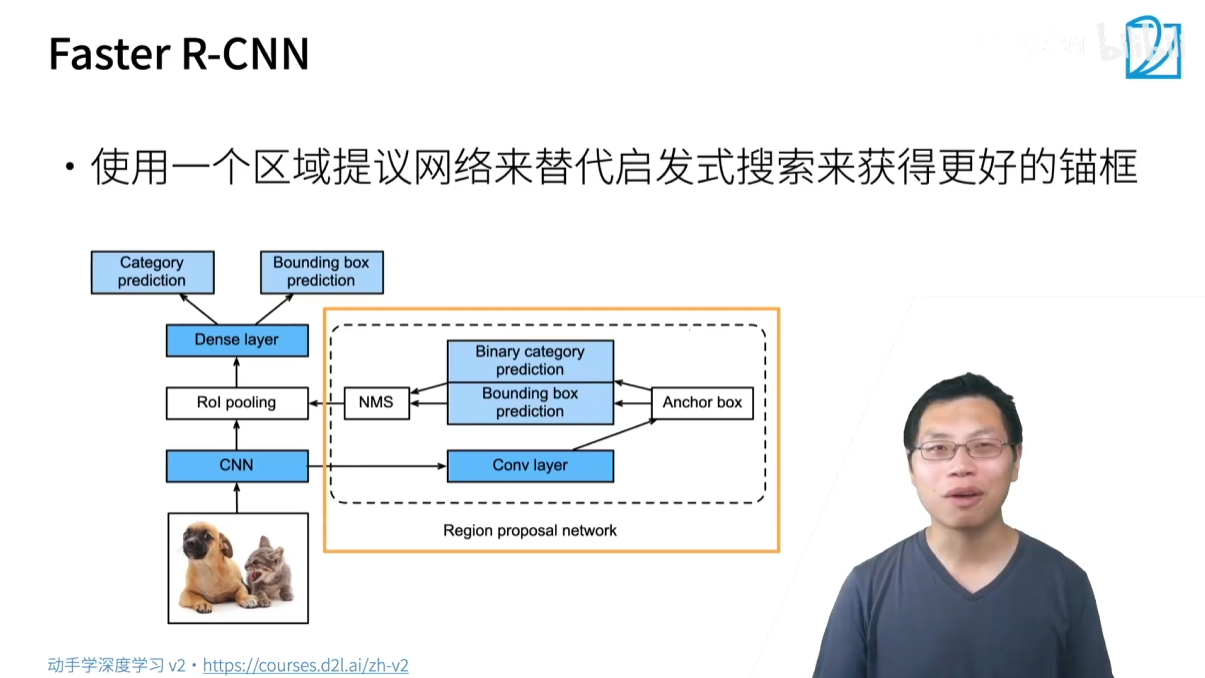
3.1.3 Faster R-CNN
- 核心思想:进一步加速,用神经网络取代传统的 Selective Search。
- 改进流程:
- 引入一个名为 RPN (Region Proposal Network) 的小型神经网络来自动生成高质量的锚框。
- RPN 本身是一个简化的目标检测器,它接收 CNN 的特征图作为输入,并预测哪些区域可能包含物体,同时预测这些区域的边界框偏移量。
- NMS 被用来去除 RPN 生成的冗余锚框。
- 这些由 RPN 生成的锚框作为 Fast R-CNN 的输入,进行后续的分类和回归。
- 优点:速度再次提升,且完全端到端(end-to-end),不再依赖外部算法。Faster R-CNN 在精度上表现优异,但速度仍然相对较慢。
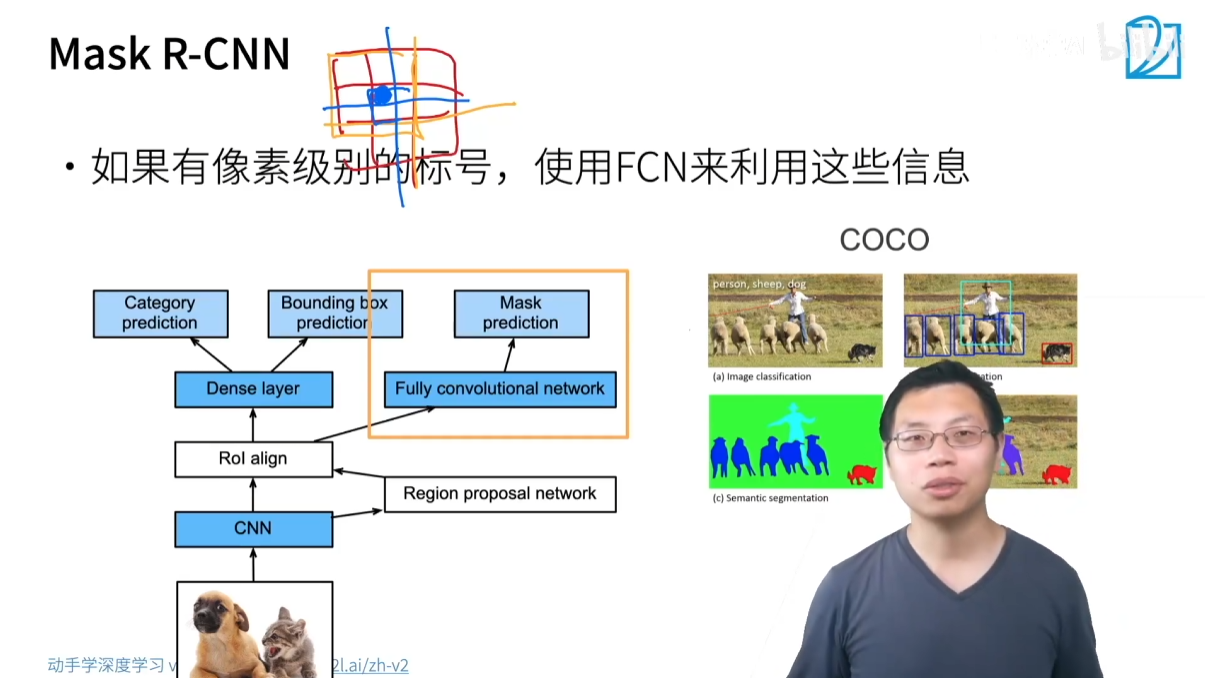
3.1.4 Mask R-CNN
- 核心思想:在 Faster R-CNN 的基础上,增加了一个实例分割(Instance Segmentation)分支,可以预测每个物体的像素级掩码(mask)。
- 关键技术:ROI Align
- 为了实现像素级别的预测,Mask R-CNN 提出了 ROI Align 来替代 ROI Pooling。
- ROI Pooling 在划分区域和取整时会产生舍入误差,导致特征图和原图的像素对齐不精确,这对边界框回归影响不大,但会严重影响像素级分割的精度。
- ROI Align 采用双线性插值(bilinear interpolation)来精确地从特征图中获取像素值,避免了舍入误差,从而提高了像素级预测的准确性。
- 应用:常用于需要高精度和像素级信息的场景,如自动驾驶。
3.2 单阶段检测器:SSD 和 YOLO
与 R-CNN 系列的“两阶段”不同,单阶段(Single-stage) 检测器直接从 CNN 的输出中预测边界框和类别,无需单独的区域建议网络。
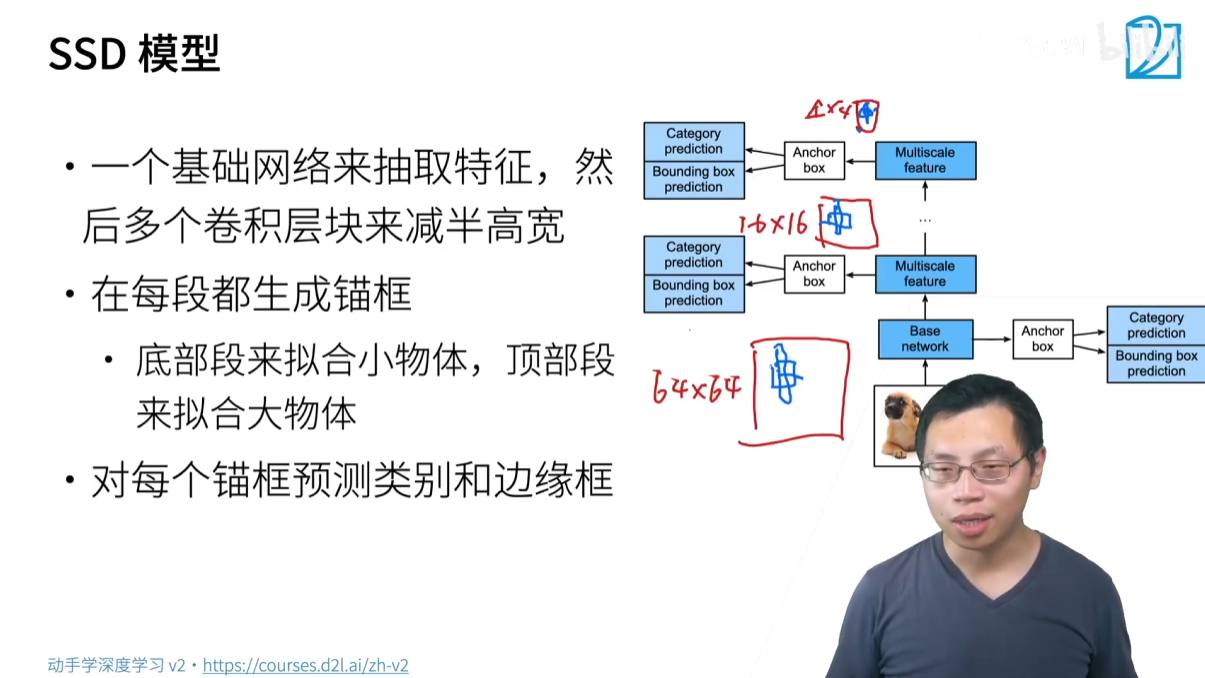
3.2.1 SSD (Single Shot Detection)
- 核心思想:通过一个神经网络直接完成所有预测,并且利用多尺度特征图来提升效果。
- 流程:
- 使用 CNN 提取特征,在不同层级的特征图上进行预测。
- 在每个特征图的每个像素上生成多个不同尺寸和长宽比的锚框。
- 对每个锚框同时预测其类别和边界框偏移量。
- 优点:速度非常快,因为它只进行一次前向传播。
- 缺点:精度相对较低,尤其对小物体检测效果不佳。
3.2.2 YOLO (You Only Look Once)
- 核心思想:将目标检测问题看作一个回归问题,只看一遍图片就完成所有预测。
- 与 SSD 的区别:
- 划分网格:YOLO 将图片均匀地划分为 SxS 的网格,每个网格负责预测位于其中心点的物体。
- 锚框生成:每个网格只会生成固定数量的锚框(例如 B 个),而不是像 SSD 那样对每个像素都生成锚框。这大大减少了锚框总数和计算量。
- 演进:YOLO 系列(YOLOv2, YOLOv3, YOLOv4, etc.)持续优化,在保持速度优势的同时,不断提升精度。
- 应用:YOLO 系列以其极快的速度和不断提高的精度,在工业界应用广泛,特别是在需要实时检测的场景。

3.3 非锚框(Anchor-free)算法
- 核心思想:这类算法完全放弃使用锚框,直接预测物体的中心点或边界框的坐标。
- 方法:通常将目标检测任务转换为像素级别的预测,例如,对每个像素预测它是否是某个物体的中心点,以及该物体边界框的大小和偏移量。
- 优势:由于不需要处理大量的锚框,这类算法的流程更简单,计算更高效,并且有望在未来超越基于锚框的算法。
- 代表:CenterNet, FCOS 等。
| 算法家族 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|
| R-CNN 系列 | 精度高,尤其是 Faster R-CNN 和 Mask R-CNN。 | 速度相对较慢,计算成本高。 | 竞赛、需要极高精度的场景,如医学影像。 |
| SSD / YOLO 系列 | 速度快,适合实时检测。 | 早期版本精度不如 R-CNN 系列。 | 工业界、实时监控、无人机等。 |
| 非锚框算法 | 流程更简单,有望超越传统方法。 | 相对较新,还在发展中。 | 学术研究,未来发展方向。 |