目录
一、前言
上篇文章中,我们提到了Redis单机模式下的问题,并且引入了Redis的主从复制架构,从主从复制的配置谈起,并且演示了Redis的一主二从的架构,提到了两种实现主从复制的方案,且大致介绍了主从复制的原理和流程。
- 虽然Redis支持主从复制实现数据冗余,但当主节点故障时,需要人工干预进行故障转移,无法自动恢复服务。
- 我们在生产环境中,需要保证Redis服务在节点故障时能够自动恢复,减少人工干预和停机时间。
- 需要持续监控Redis实例的健康状态,及时发现潜在问题。
基于上面情况的考虑,我们是不是可以大胆假设一下,如果有一个东西能自动帮我们监控Redis的实例的状态,并且在主节点宕机的时候立即帮我们重新设置一个新的主节点,这样就大大减少了人工干预所浪费的时间。
这就是本文的主题--Redis哨兵
二、哨兵
1、是什么?
主从模式中,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址。显然,多数业务场景都不能接受这种故障处理方式。Redis从2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题,它是一个分布式系统,用于监控Redis主从实例的健康状态,在主从复制的基础上,哨兵引入了主节点的自动故障转移。
哨兵会巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务,俗称无人值守运维
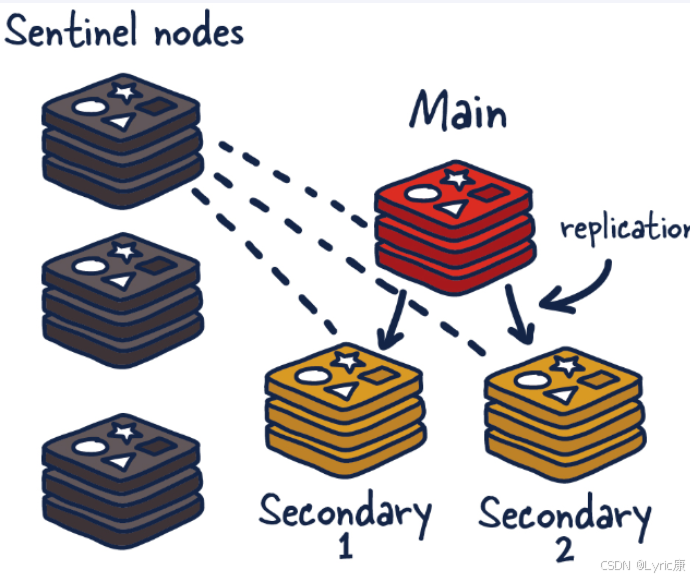
下图展示了一个Redis哨兵架构图,其中红色方块代表主节点,负责处理读写请求。黄色方块代表从节点,通过 replication 从主节点同步数据。灰色方块代表哨兵节点,有三个哨兵,这是官方建议的最小的哨兵数量,为了避免单点故障。 哨兵通过虚线箭头持续监控主节点和从节点的健康状态,如心跳检测
2、哨兵的功能
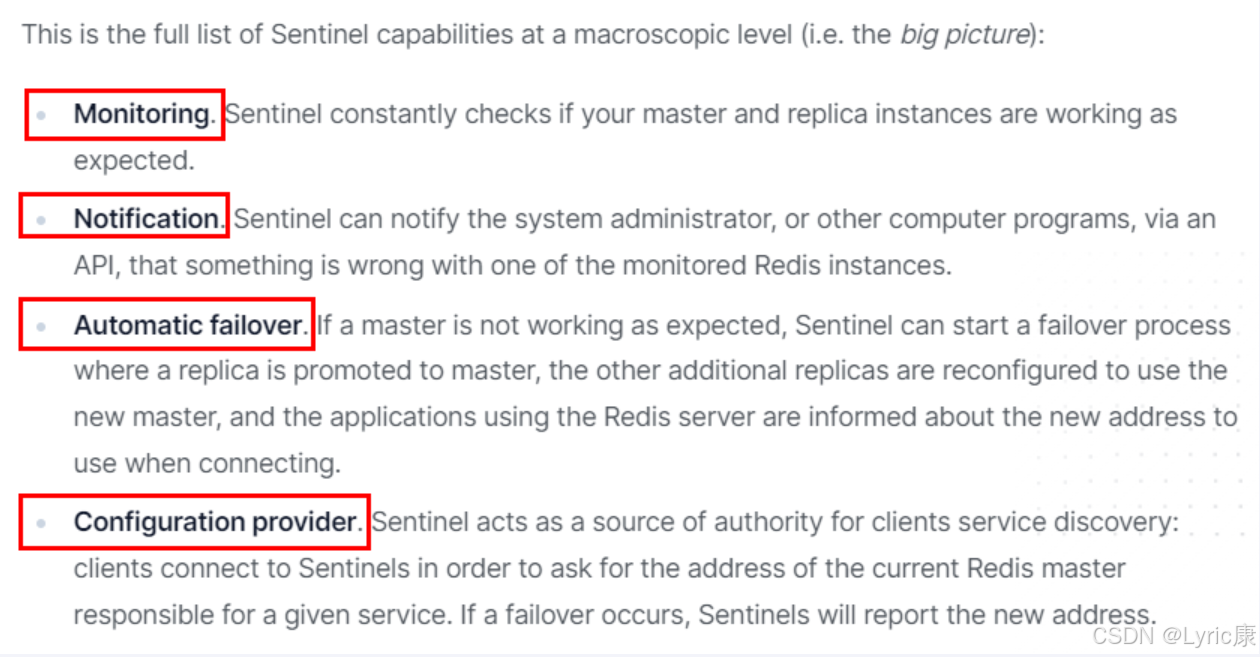
- 主从监控
- 监控主从redis库运行是否正常
- 消息通知
- 哨兵可以将故障转移的结果发送到客户端
- 故障转移
- 如果master异常,则会进行主从切换,将其中一个slave作为新master
- 配置中心
- 客户端通过连接哨兵来获得当前Redis服务的主节点地址
3、案例演示
Redis Sentinel 架构
主从架构还是采用上篇文章中的一主二从架构,另外再增加三个哨兵,自动监控和维护集群,不存放数据,只是监控。
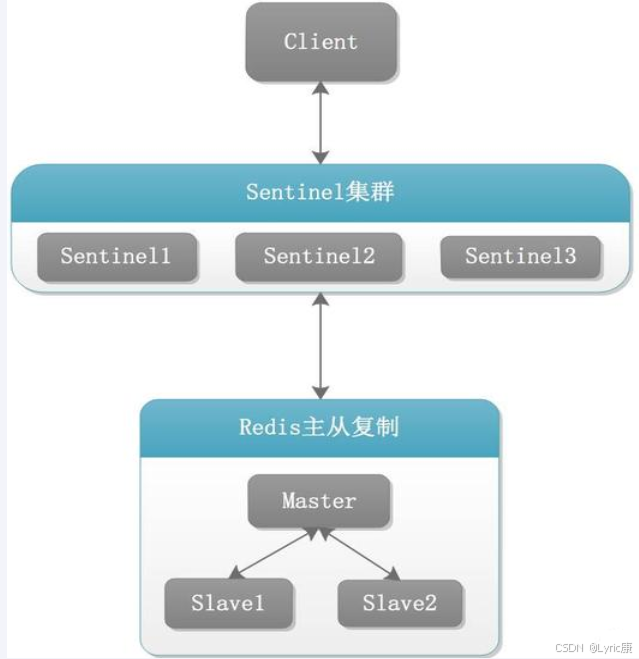
上图展示了 Redis Sentinel 的架构,需要注意的是 由于虚拟机运行内存问题,这次演示是将哨兵放在一台机器上,真正部署项目时要分开。
配置说明
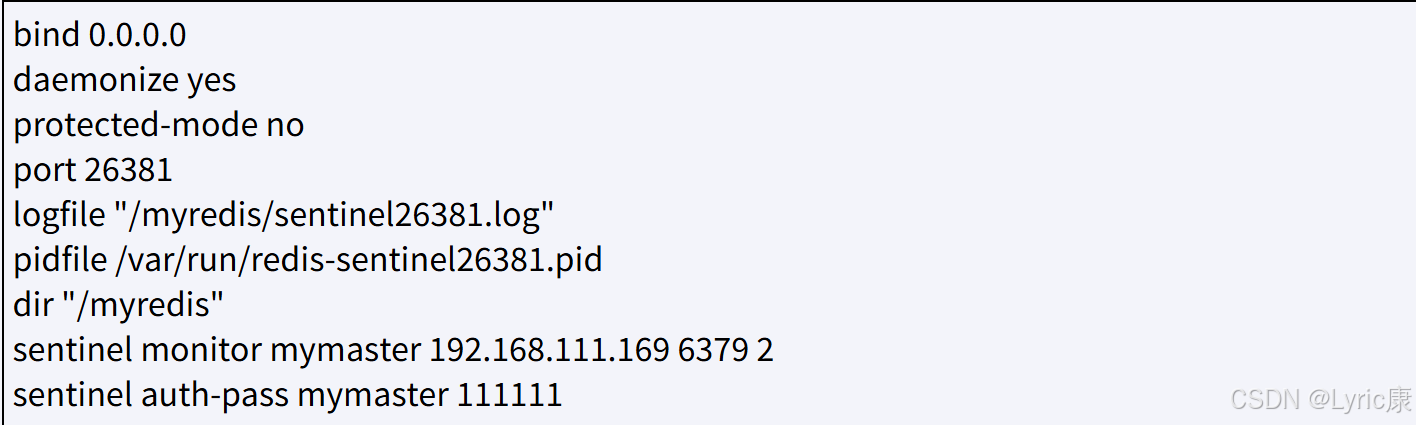
1、在 /myredis 目录新建或者拷贝 sentinel.conf
2、redis解压目录下默认的sentinel.conf文件如下
3、sentinel.conf 文件配置
- bind 服务监听地址,用于客户端连接
- daemonize 是否以后台daemon方式运行
- protected-mode 安全保护模式
- port 端口
- logfile 日志文件路径
- pidfile pid日志路径
- dir 工作目录
重点参数项说明
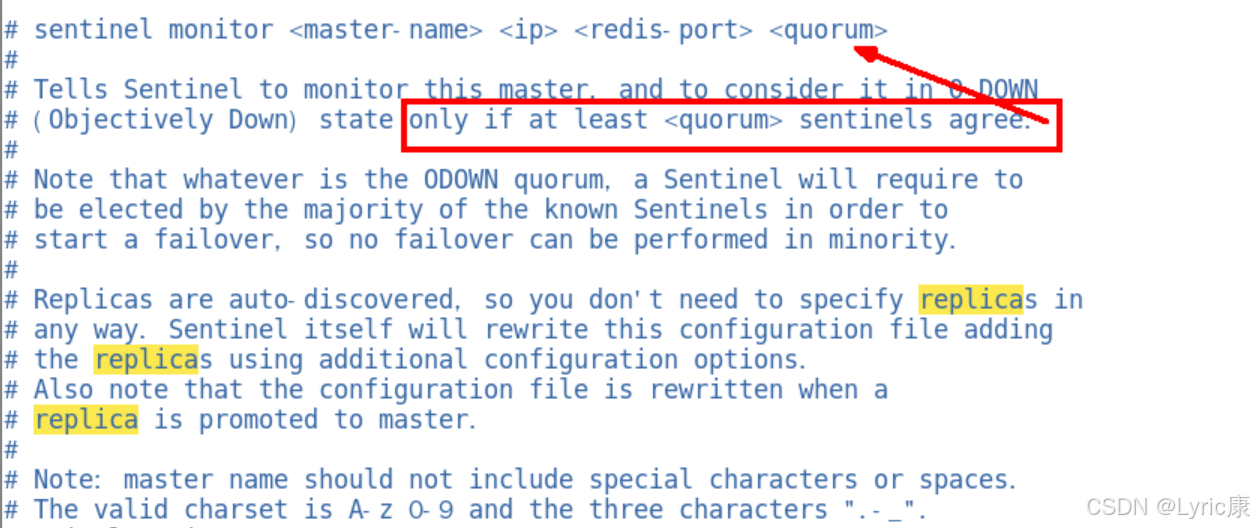
sentinel monitor <master-name> <ip> <redis-port> <quorum>
- 设置要监控的master服务器。
- quorum 表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数。
我们知道,网络是不可靠的,有时候一个 sentinel 会因为网络堵塞而误以为一个 master redis 已经死掉了,在 sentinel 集群环境下需要多个 sentinel 互相沟通来确认某个 master 是否真的死了,quorum 这个参数是进行客观下线的一个依据,意思是至少有 quorum 个 sentinel 认为这个 master有故障,才会对这个 master 进行下线以及故障转移。因为有的时候,某个 sentinel 节点可能因为自身网络原因,导致无法连接 master,而此时 master 并没有出现故障,所以,这就需要多个sentinel 都一致认为该 master 有问题,才可以进行下一步操作,这就保证了公平性和高可用。
sentinel auth-pass <master-name> <password> //如果master设置了密码,连接master服务的密码 sentinel down-after-milliseconds <master-name> <milliseconds> //指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线 sentinel parallel-syncs <master-name> <nums>: //表示允许并行同步的slave个数,当Master挂了后,哨兵会选出新的Master, //此时,剩余的slave会向新的master发起同步数据 sentinel failover-timeout <master-name> <milliseconds>: //故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败 sentinel notification-script <master-name> <script-path> : //配置当某一事件发生时所需要执行的脚本 sentinel client-reconfig-script <master-name> <script-path>: //客户端重新配置主节点参数脚本
哨兵配置文件
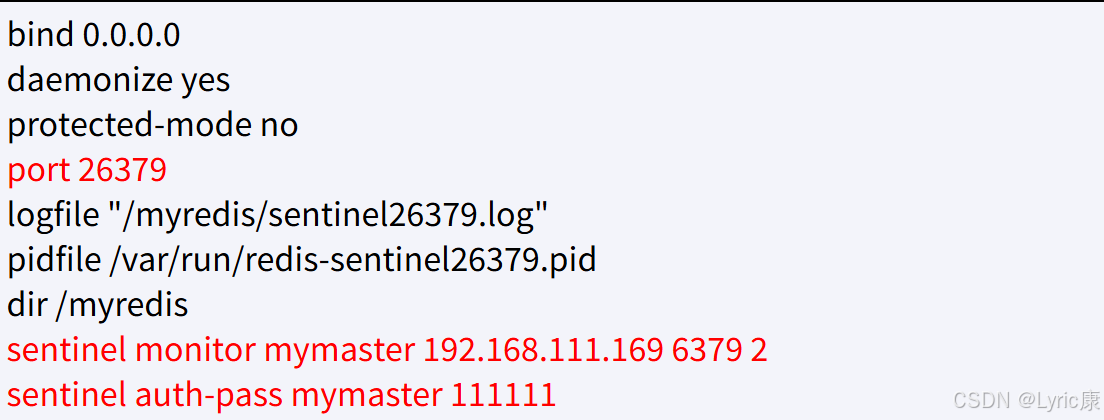
三台哨兵配置如下
由于机器硬件关系,三个哨兵都同时配置在192.168.111.169同一台机器上:
- sentinel26379.conf
- sentinel26380.conf
- sentinel26381.conf
这些文件中都是我们自己要填写的,内容如下
- sentinel26379.conf
sentinel26380.conf
- sentienl26381.conf
主从配置文件
接下来一主二从架构如下
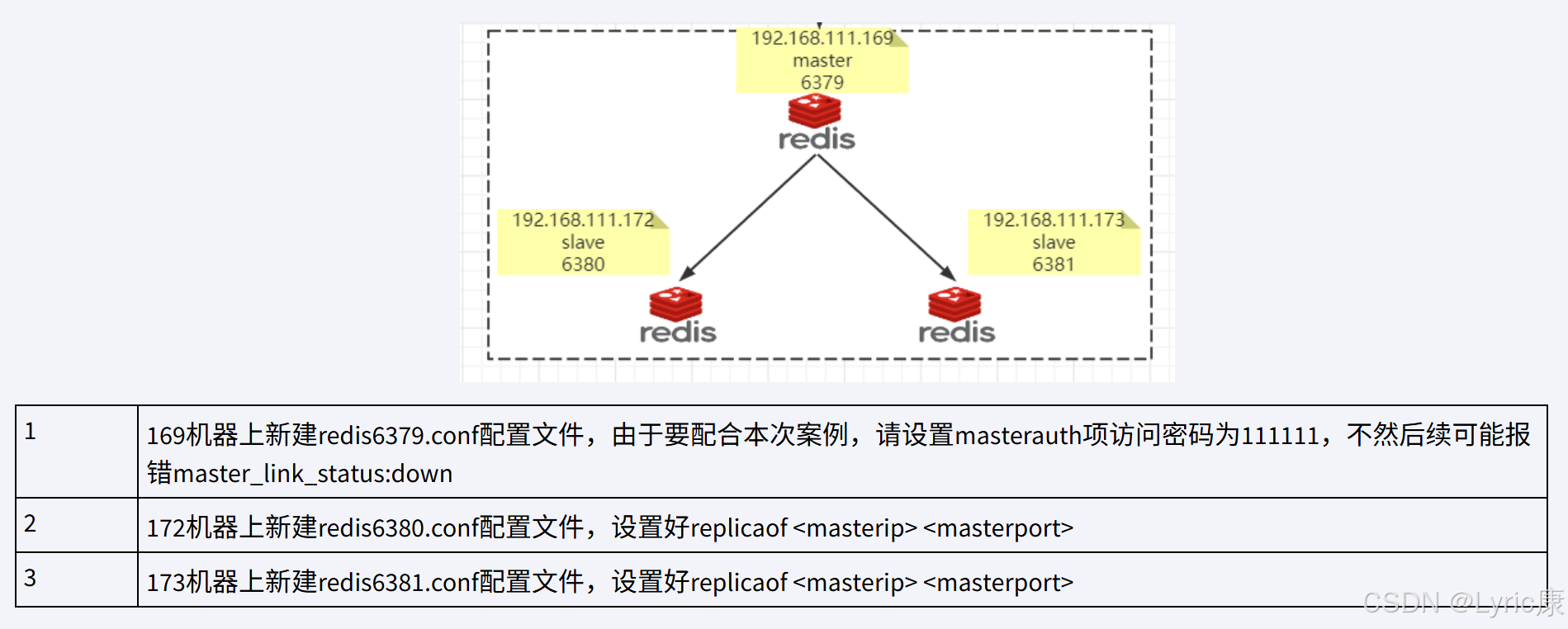
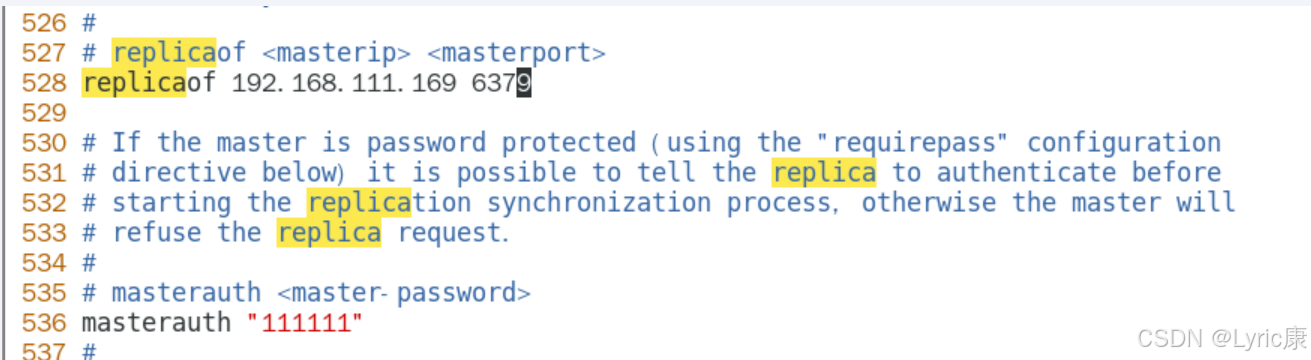
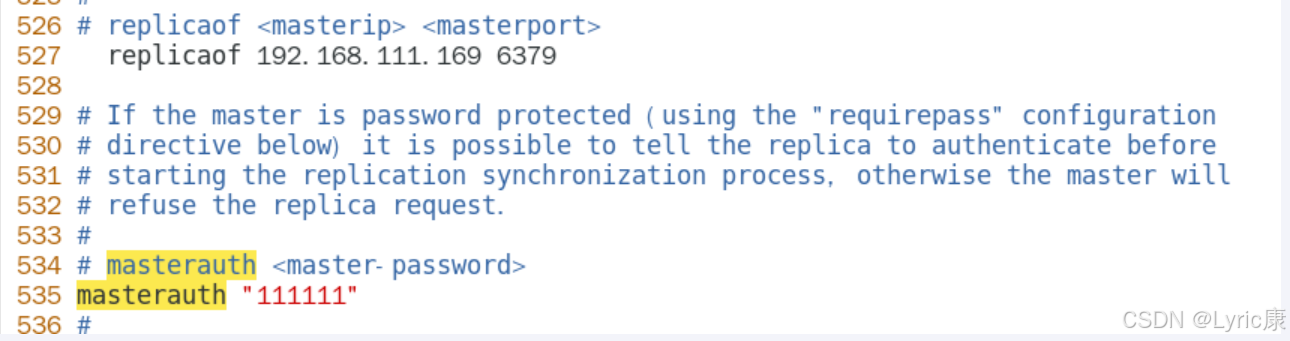
需要注意的是,我们测试主机宕机的情况,所有6379后续可能会变成从机,需要设置访问新主机的密码, 设置masterauth项访问密码为111111,
不然后续可能报错master_link_status:down
主机 redis6379.conf

从机 redis6380.conf
从机 redis6381.conf
启动一主二从
6379.conf
redis-server /myredis/redis6379.conf
redis-cli -a 123456
6380.conf
redis-server /myredis/redis6380.conf
redis-cli -a 123456 -p 6380
6381.conf
redis-server /myredis/redis6381.conf
redis-cli -a 123456 -p 6381
启动哨兵
redis-sentinel sentinel26379.conf --sentinel
redis-sentinel sentinel26380.conf --sentinel
redis-sentinel sentinel26381.conf --sentinel
完成一次主从复制,可以看到没什么问题
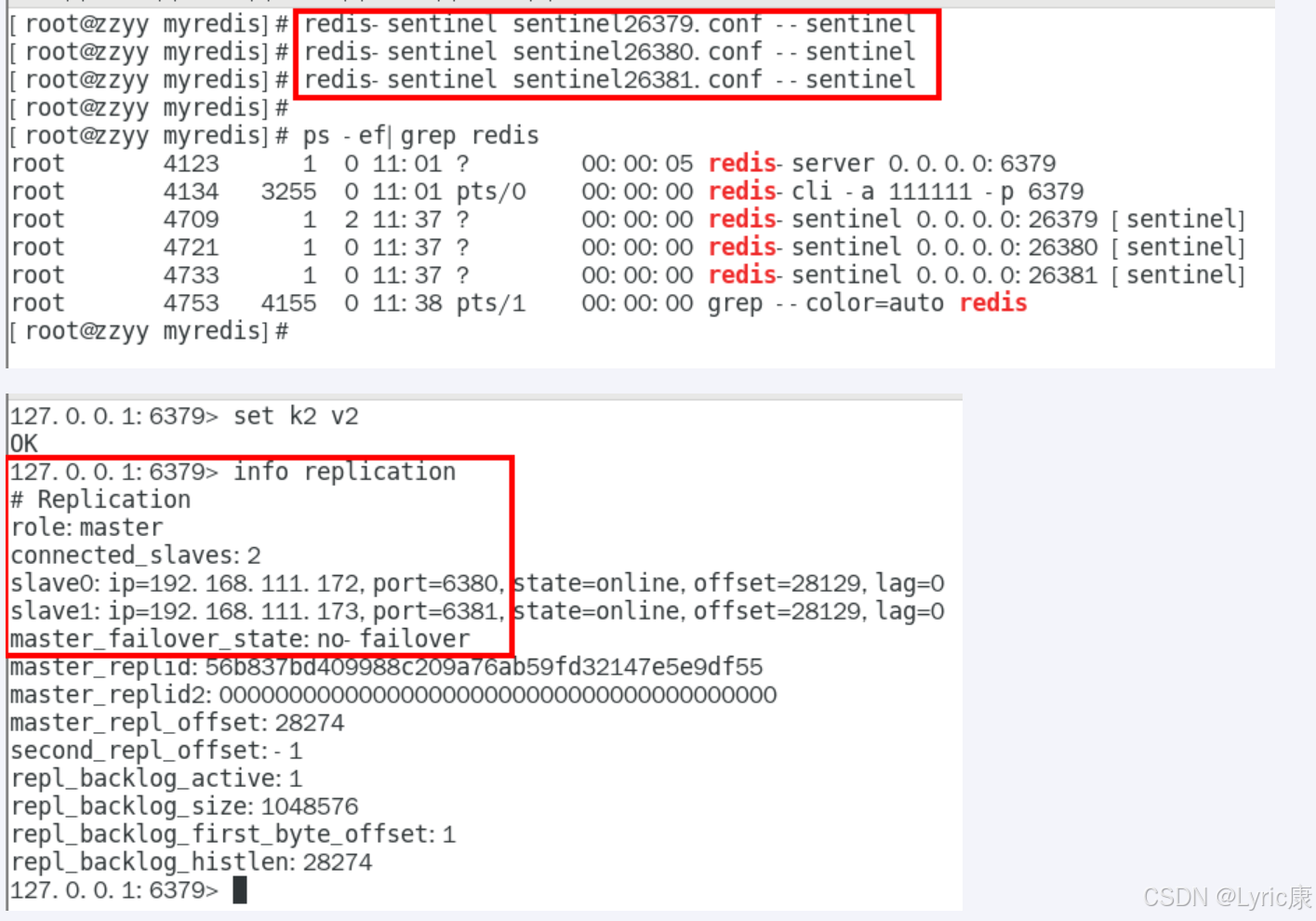
主节点宕机后各节点状态
下面手动关闭6379主机,模仿主机意外宕机
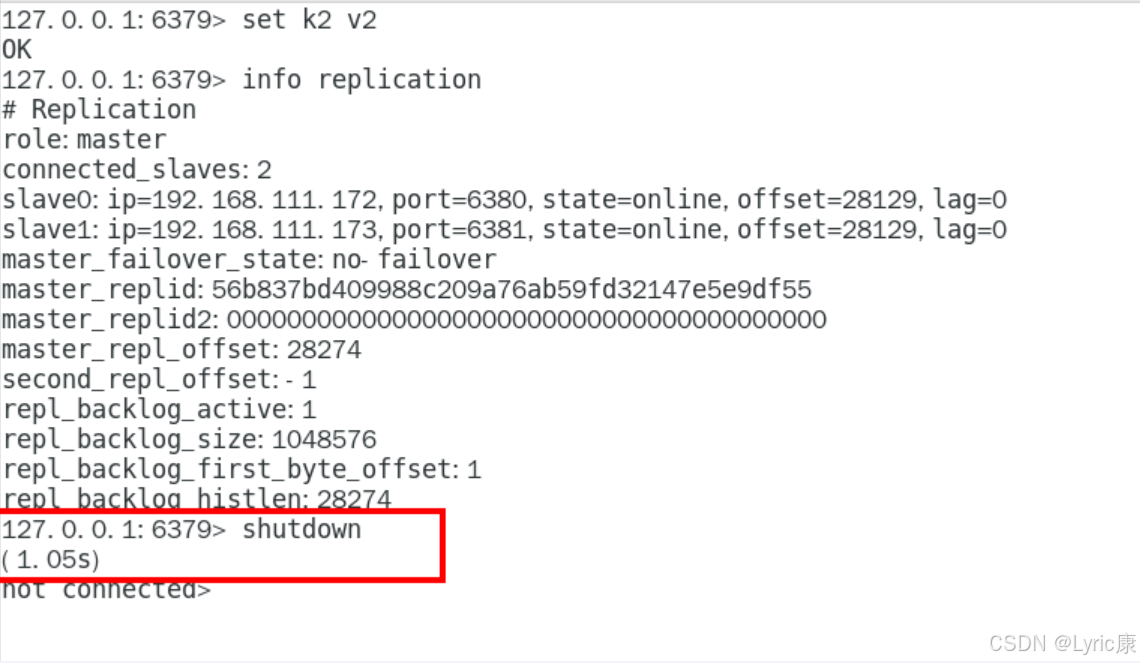
查看 6379 的主从信息
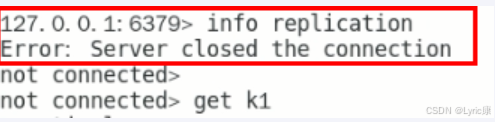
观察从机6380
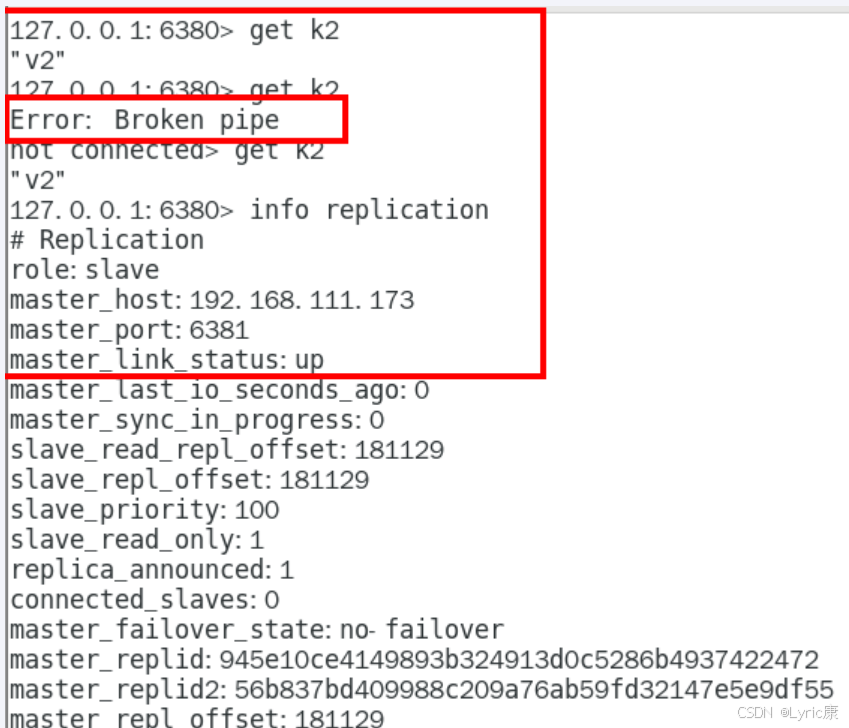
“Broken pipe”错误通常表示客户端与服务器之间的连接被意外中断。错误发生后,客户端显示not connected,表明与Redis服务器的连接已经断开。
| 类别 | 内容 |
|---|---|
| 认识 broken pipe | pipe 是管道的意思,管道里面是数据流,通常是从文件或网络套接字读取的数据。当该管道从另一端突然关闭时,会发生数据突然中断,即是 broken,对于 socket 来说,可能是网络被拔出或另一端的进程崩溃 |
| 解决问题 | 其实当该异常产生的时候,对于服务端来说,并没有多少影响。因为可能是某个客户端突然中止了进程导致了该错误 |
| 总结 Broken Pipe | 这个异常是客户端读取超时关闭了连接,这时候服务器端再向客户端已经断开的连接写数据时就发生了 broken pipe 异常! |
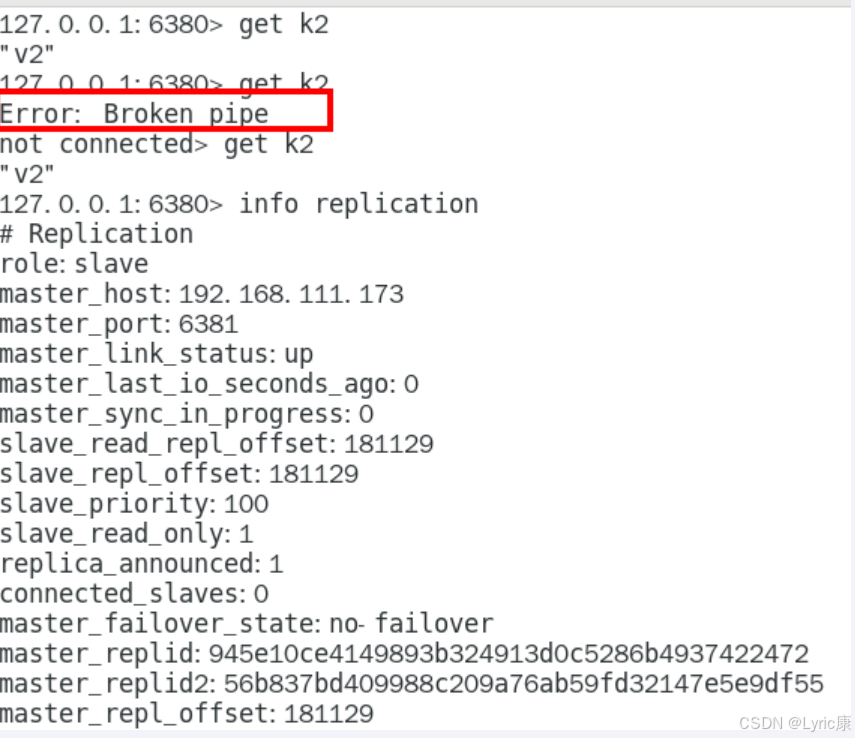
观察从机 6381
接下来查看三台哨兵的日志文件
- sentinel26379
- sentinel26380
- sentinel26381
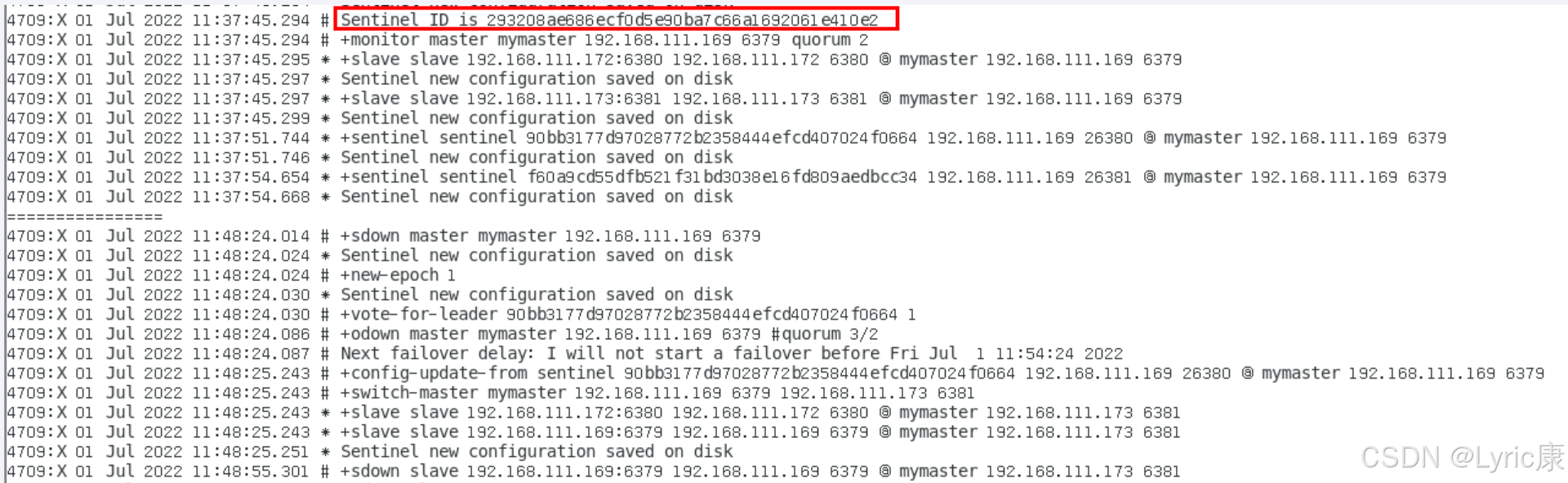
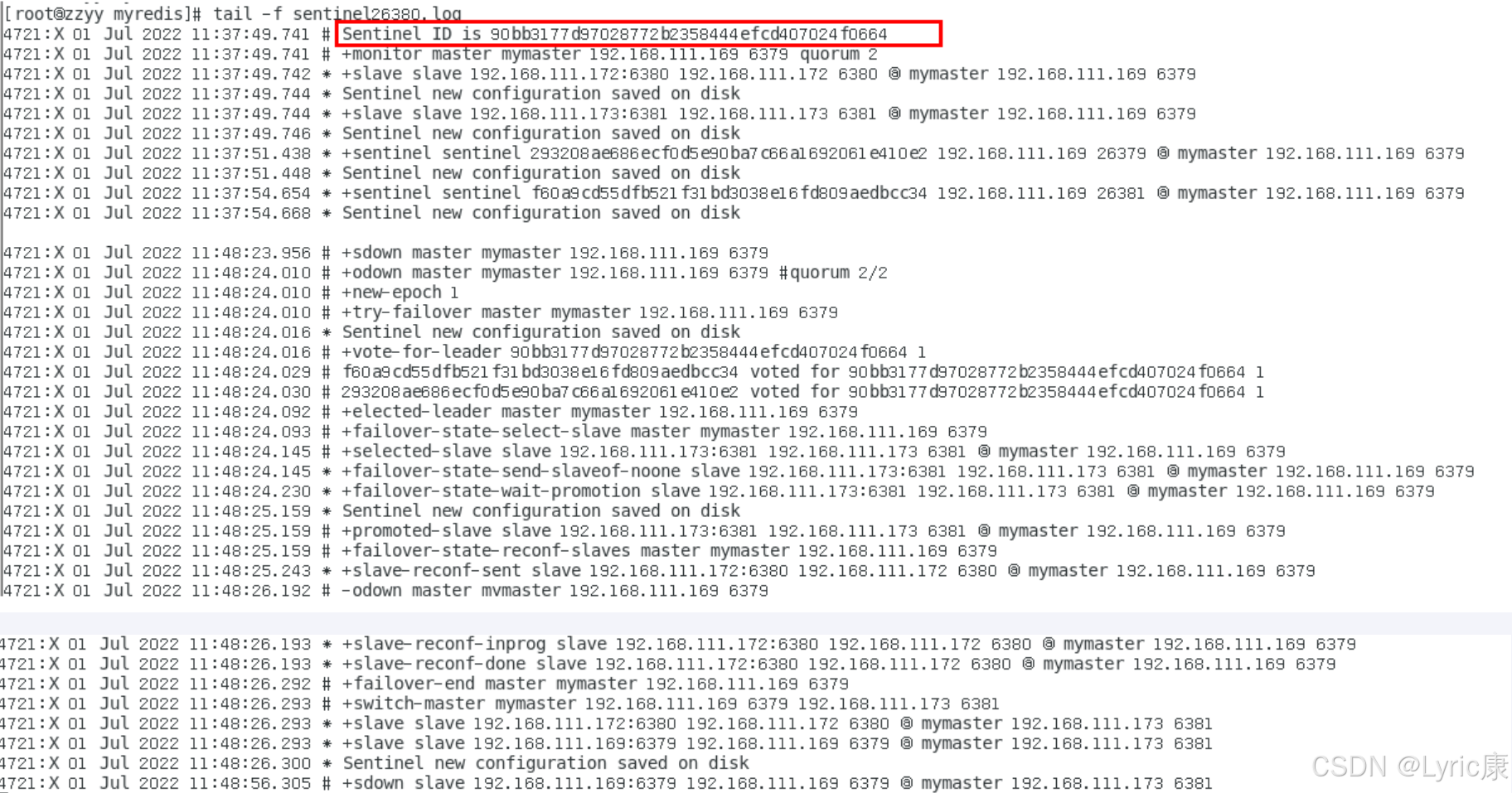
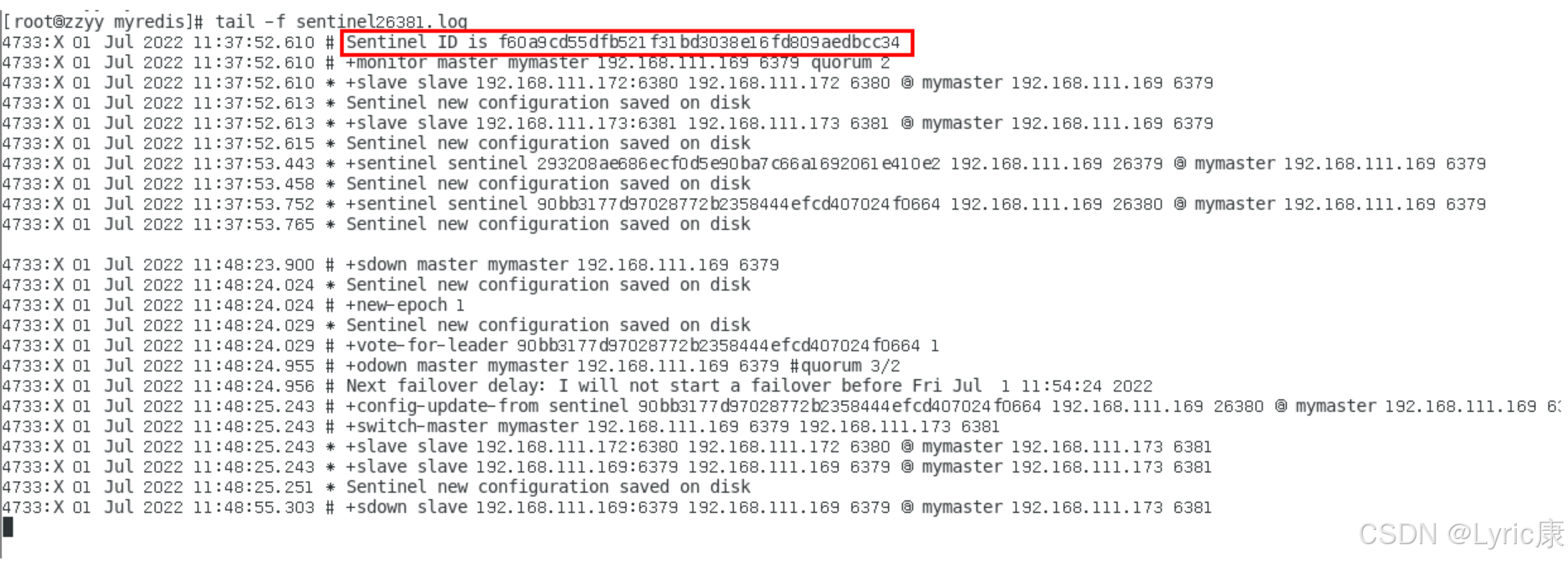
以sentinel26379的日志为例,解释图
1. Sentinel ID
- Sentinel ID is 293208ae686ecf0d5e90ba7c66a1692061e410e2:
- 这是当前Sentinel实例的唯一标识符,用于区分不同的Sentinel节点。
2. 监控主节点
- +monitor master mymaster 192.168.111.169 6379 quorum 2:
- Sentinel开始监控名为mymaster 的主节点,其IP地址为192.168.111.169,端口为
6379。- quorum 2表示至少需要2个Sentinel节点同意才能进行故障转移。
3. 发现从节点
- +slave slave 192.168.111.172:6380 192.168.111.172 6380 @ mymaster 192.168.111.169 6379:
- Sentinel发现了从节点192.168.111.172 6380,该节点属于主节点mymaster。
4. 新配置保存到磁盘
- Sentinel new configuration saved on disk:
- Sentinel将新的配置信息保存到了磁盘上,确保配置的持久化。
5. 主节点下线
- +sdown master mymaster 192.168.111.169 6379:
- Sentinel检测到主节点 mymaster 主观下线(Subjectively Down, SDOWN),即某个Sentinel认为主节点不可用。
6. 故障转移准备
- #new-epoch 1:
- Sentinel进入新的纪元(Epoch),这是为了确保在故障转移过程中的一致性。
- vote-for-leader 90bb3177d97028772b2358444efcd407024f0664 1:
- Sentinel参与选举新的领导者,以协调故障转移过程。
7. 主节点客观下线
- #odown master mymaster 192.168.111.169 6379 #quorum 3/2:
- 至少有3个Sentinel节点(超过quorum 2)确认主节点客观下线(Objectively Down, ODOWN),即大多数Sentinel都认为主节点不可用。
8. 故障转移延迟
- Next failover delay: I will not start a failover before Fri Jul 1 11:54:24 2022:
- Sentinel决定在指定时间之前不启动故障转移,可能是为了避免频繁的故障转移操作。
9. 配置更新和主节点切换
- config-update-from sentinel 90bb3177d97028772b2358444efcd407024f0664 192.168.111.169 26380 @ mymaster 192.168.111.169 6379:
- 从其他Sentinel节点接收配置更新。
- switch-master mymaster 192.168.111.169 6379 192.168.111.173 6381:
- 将主节点切换为192.168.111.173 6381,完成故障转移。
10. 从节点状态更新
- +slave slave 192.168.111.172:6380 192.168.111.172 6380 @ mymaster 192.168.111.173 6381:
- 更新从节点的状态,使其连接到新的主节点。
再次查看 6381 节点的主从信息,可以看到如上面哨兵的日志文件所述,本次是将6381选为新的主机。再次重启6379(之前的主节点)之后,发现此时它已经成为了6381的从节点
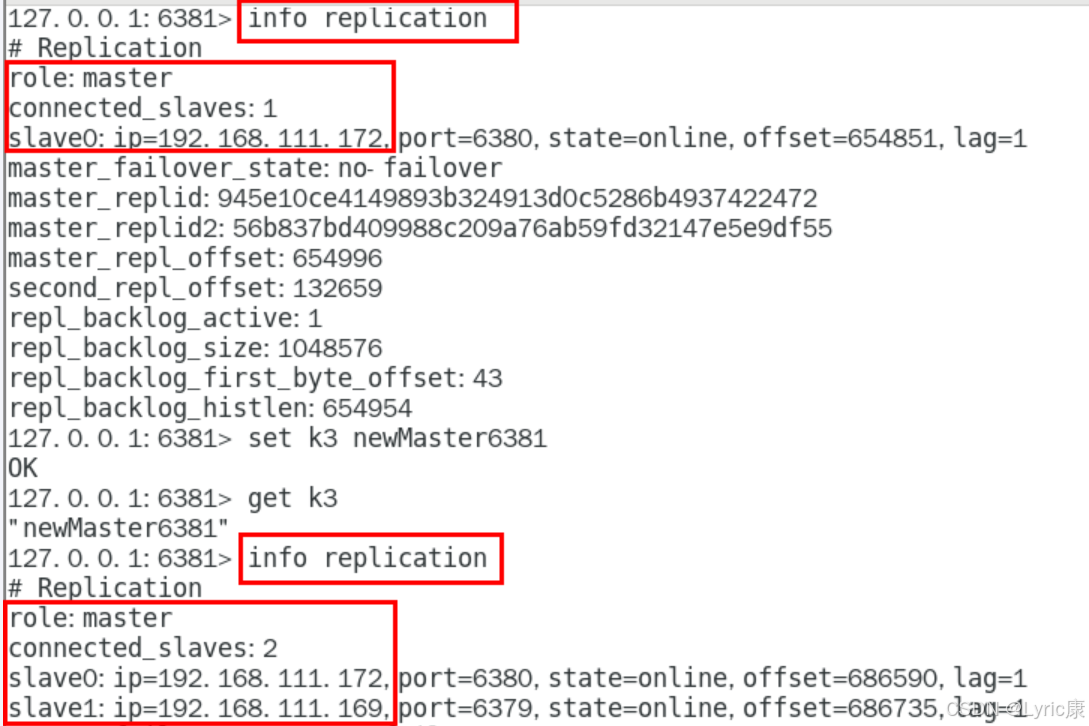
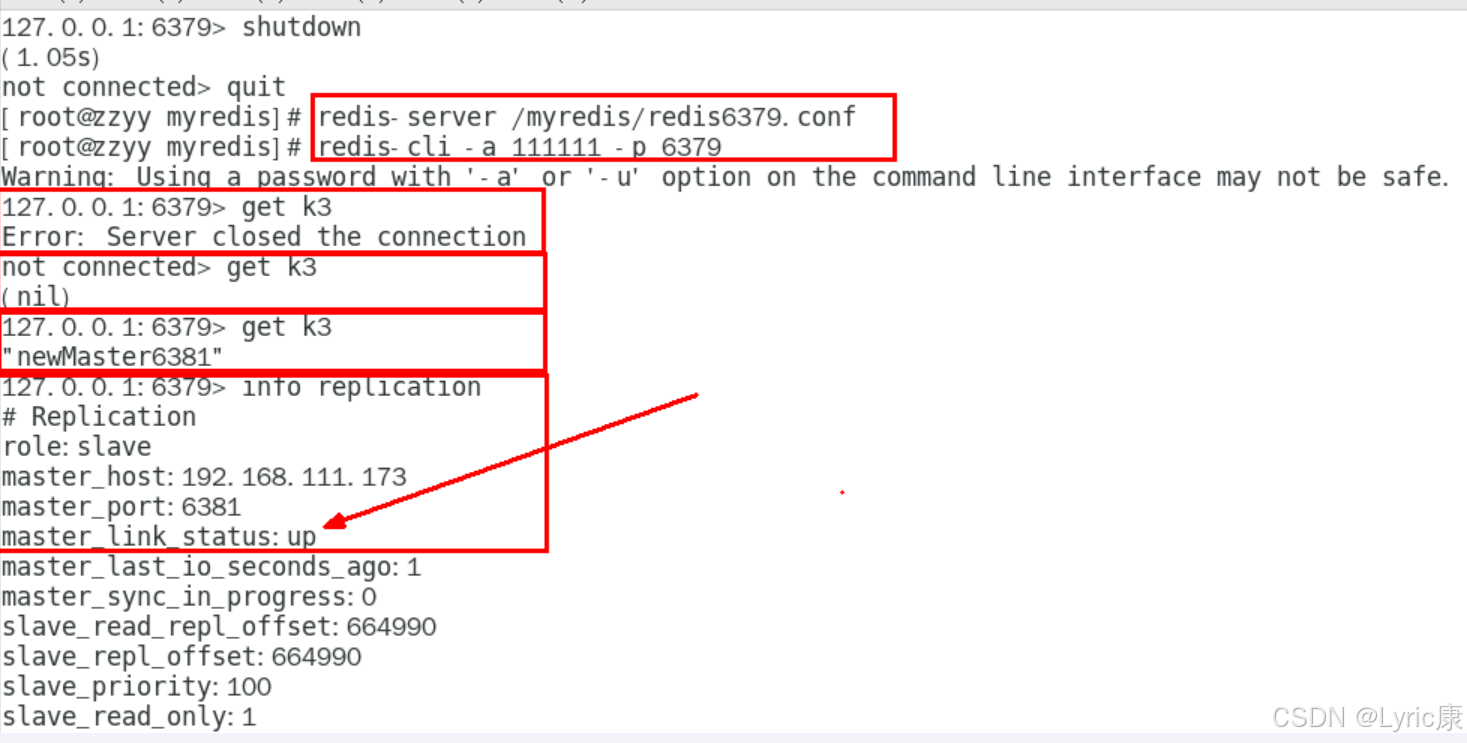
对于6380来说,它依然是从节点,但是它的上级主节点已经从6379换成了6381.
主从切换后配置文件的自动调整
!***!最后还需要注意的是在Redis Sentinel架构中,当发生Master-Slave切换时,相关的配置文件会自动进行相应的调整,以适应新的集群状态。这种动态调整机制保证了Redis集群的高可用性和一致性。
- 当Master-Slave切换完成后,以下三个配置文件的内容会发生改变:
- 新上任的从节点的配置文件
- 原主节点的配置文件
- Sentinel的配置文件
具体来说,对于新上任的主节点(6381)的配置文件
- 在成为主节点之前, redis6381.conf 文件中会包含一行 replicaof 192.168.111.169 6379的配置,用于指定其主节点为6379。
- 当该节点被选举为新的主节点后,Redis Sentinel 会自动删除或注释掉这一行配置,因为新主节点不再需要作为副本(replica)从其他节点同步数据。
对于之前的的主节点(6379)的配置文件
- 原来的主节点在切换后变为从节点,其配置文件中会新增一行 replicaof 192.168.111.169 6381 配置,指定新的主节点地址和端口。
对于哨兵配置文件 sentinel.conf
- Sentinel的监控目标会随之调整,以反映新的主从关系。原本监控旧主节点的配置会被更新为监控新主节点。
- 需要注意的是首次配置 Sentinel 时,会使用类似 sentinel monitor mymaster 192.168.111.169 6379 2 的命令。这行配置告诉 Sentinel:“请开始监控一个名为mymaster的主节点,它当前的地址是 192.168.111.169 6379”。
故障转移后的变化:
- 当发生故障转移后,Sentinel 集群会达成共识,将一个从节点 192.168.111.169 6381提升为新的主节点。
- sentinel.conf 文件本身可能不会重写最初的 sentinel monitor 那一行(即它可能还是
...192.168.111.169 6379...),但这行配置的“意义”已经通过 Sentinel 的内部状态和后续的持久化信息被覆盖了。 - 关键变化在于 Sentinel 会将新的主节点信息持久化到配置文件中。在 sentinel.conf 文件里会看到类似这样的新行被自动添加:
master mymaster 192.168.111.173 6381 //这行 master 记录明确指出了当前 mymaster //这个逻辑名称所对应的实际主节点是 192.168.111.173:6381。
因此,Sentinel 的“监控目标”确实是动态调整的,但它不是简单地修改最初的sentinel monitor 那一行。
它是通过维护一个动态的、持久化的主节点记录来实现的。Sentinel 在运行时会优先使用这个最新的 master mymaster
...记录来确定当前的主节点是谁。即使最初的 sentinel monitor 行没有改变,Sentinel 的实际监控行为已经完全指向了新的主节点。
4、哨兵运行流程和选举原理
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master用于自动接替原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。
一般建议sentinel采用奇数台,哨兵集群的可靠性依赖于 “多数投票机制”,而奇数个哨兵节点是确保这一机制有效的关键。
SDOWN主观下线
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在[sentinel down-after-milliseconds]给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了
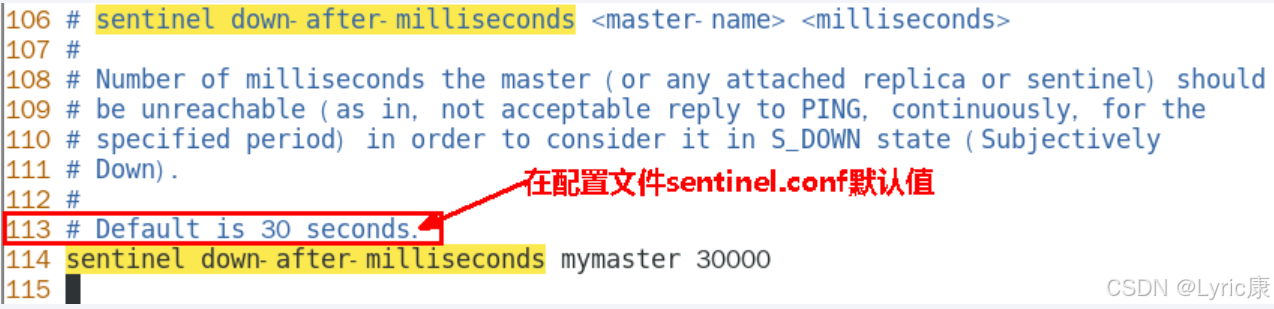
- sentinel down-after-milliseconds <masterName> <timeout>
- 表示master被当前sentinel实例认定为失效的间隔时间,这个配置其实就是进行主观下线的一个依据
- master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态。
ODOWN客观下线
- ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个master客观上已经宕机
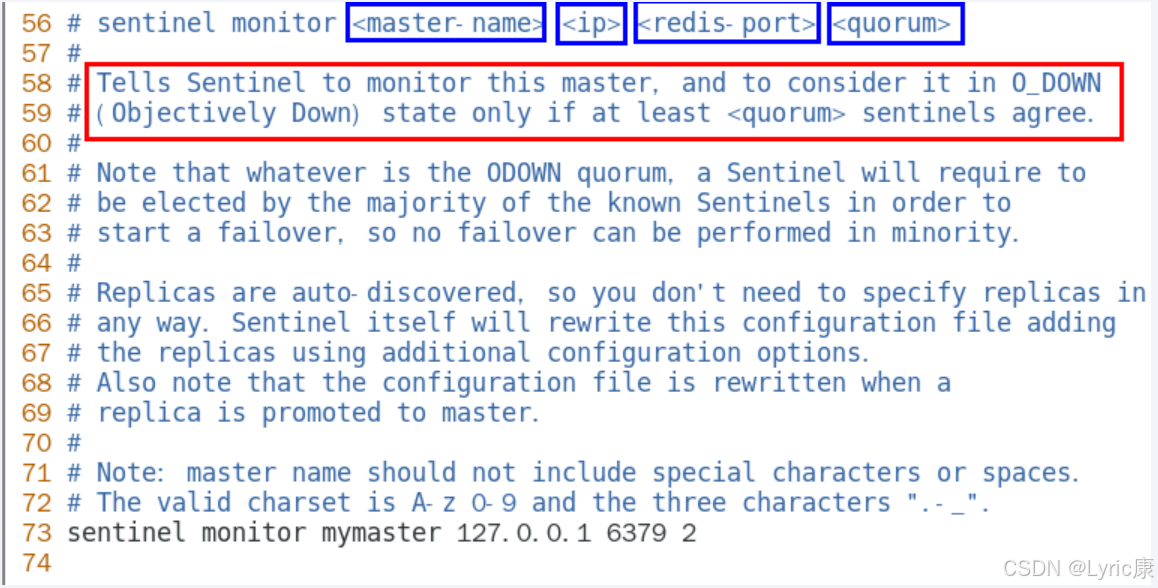
在前面的哨兵配置文件中见到过<quorum>这个参数,
这个参数是进行客观下线的一个依据,法定人数/法定票数
意思是至少有quorum个sentinel认为这个master有故障才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因导致无法连接master,而此时master并没有出现故障,所以这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
选出新的主节点
当主节点被判断客观下线以后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点并由该领导者节点进行failover(故障迁移)
哨兵领导者选举流程
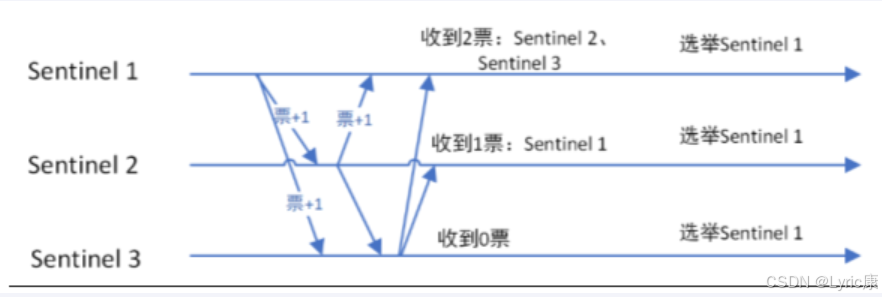
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者
新主节点选举
由领导者节点开始推动故障转移并选出一个新master
故障转移步骤
1、选举新主节点
- 优先级最高:指从节点配置 replica-priority(Redis 5.0前叫 slave-priority,值越小优先级越高,默认100),优先级最高的从节点优先被选中(如配置为50的从节点 > 配置为100的节点)。
- 复制偏移量最大:若优先级相同,选择与原主节点数据同步最完整的从节点(通过 INFO replication 中的 master_repl_offset 判断,偏移量越大数据越新)。
- 最小 Run ID:若偏移量也相同,通过 Redis 实例的唯一运行ID(runid,类似身份证号)字典序最小的节点当选(避免平局的兜底规则)。

2、从节点角色切换
- slaveof no one:哨兵领导者向选中的从节点发送此命令,使其停止复制原主节点,升级为独立主节点
- 其他从节点“臣服”:哨兵领导者向剩余从节点发送 slaveof <新主节点IP> <端口> 命令,让它们重新指向新主节点,开始同步数据
3、原主节点回归后的角色处理
- 原主节点因故障下线,恢复后哨兵会自动向其发送 slaveof <新主节点IP> <端口> 命令,使其降级为从节点,从新主节点同步数据(“旧主退位称臣”)。
- 避免数据冲突:若原主节点恢复后仍以主节点身份运行,会导致“双主并存”(数据写入不一致),此设计确保集群只有一个主节点。
****以上的failover都是sentinel自己独立完成,完全无需人工干预
5、使用建议
- 哨兵节点的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该是奇数个
- 各个哨兵节点的配置应该一致
- 如果哨兵节点部署在Docker等容器里,要注意端口的正确映射
- 哨兵集群+主从复制,并不能保证数据零丢失
6、哨兵架构的缺陷
- 单主节点写入压力:哨兵模式本质仍是“一主多从”架构,所有写入操作集中在单个主节点,无法横向扩展写入性能(主节点CPU、内存、网络带宽易成为瓶颈)。
- 存储容量限制:单主节点的存储容量受限于单台服务器的硬件配置(如最大内存),无法通过增加从节点扩展数据容量。
- 服务中断窗口:从主节点故障到新主节点选举完成(约几秒到十几秒),期间写入操作不可用(读操作可由从节点分担,但写操作完全中断)。
- 数据丢失风险:若主节点故障前未落盘的数据未同步到从节点,故障转移后这部分数据会丢失(即使开启AOF持久化,仍可能因主从同步延迟导致数据不一致)。
针对上述问题,下一篇就该引入Redis的集群的概念了!
感谢阅读!