
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
作为一名深耕AI领域多年的技术探索者,我见证了人工智能从概念到落地的全过程。在这个技术浪潮中,我不断思考如何为初入行的开发者提供一份清晰的导航图。人工智能已经不再是遥不可及的科幻概念,而是渗透到我们日常生活的方方面面。从语音助手到自动驾驶,从医疗诊断到金融风控,AI的应用无处不在。然而,对于许多开发者来说,AI领域庞大而复杂的知识体系常常让人望而生畏。在我多年的技术咨询和项目实践中,最常被问到的问题就是:"我该如何选择适合自己的AI细分方向?"这篇文章,我将基于自己的实战经验,为大家梳理当前AI领域的主要细分方向,分析每个方向的技术栈、应用场景、发展前景以及入门路径。我希望通过这篇文章,能够帮助你在AI的星图上找到属于自己的那颗北极星,开启一段充满可能性的技术旅程。无论你是刚刚踏入编程世界的新手,还是寻求转型的资深开发者,这份AI细分方向全景图都将为你提供清晰的技术路径指引。
人工智能的基础分类
人工智能作为一个庞大的技术领域,可以从多个维度进行分类。在深入细分方向之前,我们需要先了解AI的基本分类框架。
按技术范式分类
# AI技术范式的简单表示
class AIParadigm:
def __init__(self):
self.symbolic_ai = "基于规则和逻辑的符号推理系统" # 早期AI的主流方向
self.statistical_learning = "基于数据和统计模型的学习系统" # 机器学习的基础
self.deep_learning = "基于神经网络的端到端学习系统" # 当前AI的主流技术
self.hybrid_systems = "结合符号推理和深度学习的混合系统" # 未来发展趋势
在这段代码中,我们可以看到AI的四种主要技术范式。其中深度学习目前是最热门的方向,但混合系统正在成为新的研究热点。
按应用领域分类
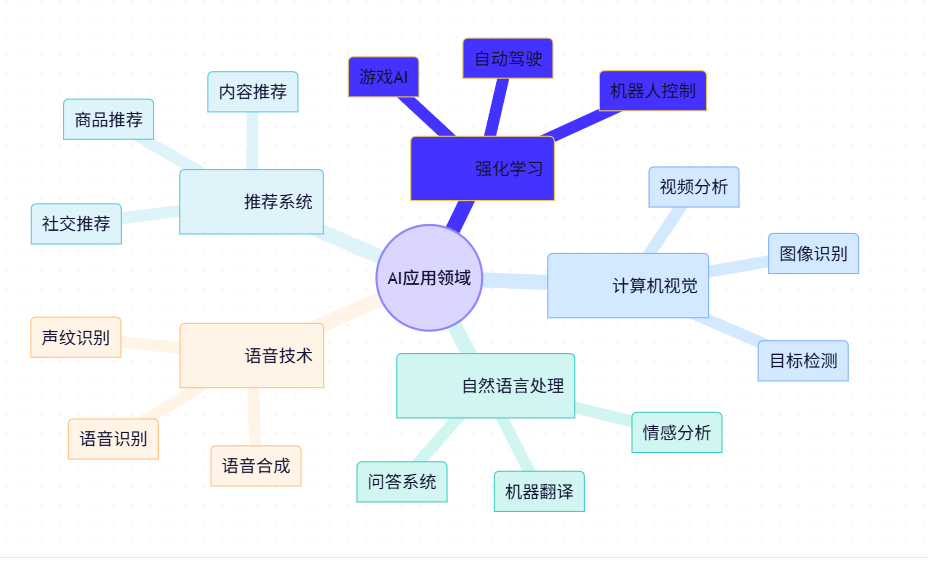
图1:AI应用领域思维导图 - 展示了人工智能的主要应用方向及其子领域
计算机视觉(CV):让机器拥有"眼睛"
计算机视觉是AI领域中最活跃的方向之一,它赋予机器理解和处理视觉信息的能力。
核心技术与应用场景
计算机视觉的应用极其广泛,从安防监控到医疗诊断,从自动驾驶到增强现实,都离不开CV技术的支持。
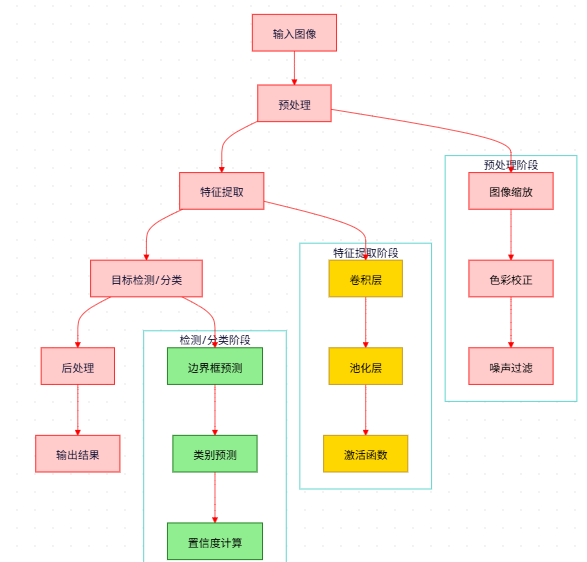
图2:计算机视觉处理流程图 - 展示了从输入图像到输出结果的完整处理过程
CV方向的技术栈
作为CV方向的开发者,你需要掌握以下技术栈:
# CV开发者的核心技术栈
def cv_tech_stack():
# 基础编程语言
languages = ["Python", "C++"]
# 核心框架和库
frameworks = {
"深度学习": ["PyTorch", "TensorFlow", "Keras"],
"图像处理": ["OpenCV", "Pillow", "scikit-image"],
"数据处理": ["NumPy", "Pandas"]
}
# 核心算法知识
algorithms = [
"卷积神经网络(CNN)",
"目标检测算法(YOLO, SSD, Faster R-CNN)",
"图像分割算法(U-Net, Mask R-CNN)",
"生成对抗网络(GAN)",
"Transformer架构(ViT)"
]
return languages, frameworks, algorithms
在CV领域,PyTorch和TensorFlow是两大主流框架,而YOLO系列和Transformer架构则是近年来的热门技术方向。
CV方向的就业前景
“在人工智能时代,计算机视觉工程师就像文艺复兴时期的画家,他们不仅在创造技术,更在重新定义人类与世界交互的方式。” —— 李飞飞,斯坦福大学人工智能实验室主任
计算机视觉工程师的需求持续增长,尤其在以下行业:
图3:CV工程师需求行业分布饼图 - 展示了不同行业对计算机视觉人才的需求比例
自然语言处理(NLP):让机器理解人类语言
自然语言处理是AI领域中另一个极其重要的方向,它专注于让计算机理解、处理和生成人类语言。
NLP的技术演进
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#8A2BE2', 'primaryTextColor': '#fff' }}}%%
timeline
title NLP技术演进时间线
2013 : Word2Vec词向量
2014 : Seq2Seq序列模型
2015 : 注意力机制
2017 : Transformer架构
2018 : BERT预训练模型
2019 : GPT-2大规模语言模型
2020 : GPT-3超大规模模型
2022 : ChatGPT对话模型
2023 : GPT-4多模态模型
2024 : 多智能体协作系统
图4:NLP技术演进时间线 - 展示了自然语言处理领域的关键技术里程碑
NLP的核心任务与技术
NLP领域包含多种核心任务,每种任务都有其特定的技术方法:
# NLP核心任务及其技术实现
nlp_tasks = {
"文本分类": {
"应用": ["情感分析", "垃圾邮件过滤", "新闻分类"],
"技术": ["BERT", "RoBERTa", "XLNet"]
},
"序列标注": {
"应用": ["命名实体识别", "词性标注", "关键词提取"],
"技术": ["BiLSTM-CRF", "BERT-CRF", "SpanBERT"]
},
"文本生成": {
"应用": ["机器翻译", "文本摘要", "对话系统"],
"技术": ["Seq2Seq", "Transformer", "GPT系列"]
},
"问答系统": {
"应用": ["客服机器人", "搜索引擎", "知识问答"],
"技术": ["BERT", "T5", "RAG"]
}
}
# 示例:实现一个简单的情感分析模型
def simple_sentiment_analysis(text):
# 这里只是示意代码,实际应用需要更复杂的模型
import re
from collections import Counter
# 简单的情感词典
positive_words = {"good", "great", "excellent", "amazing", "wonderful", "happy"}
negative_words = {"bad", "terrible", "awful", "sad", "disappointed", "angry"}
# 分词并计数
words = re.findall(r'\w+', text.lower())
word_counts = Counter(words)
# 计算情感得分
positive_score = sum(word_counts[word] for word in positive_words if word in word_counts)
negative_score = sum(word_counts[word] for word in negative_words if word in word_counts)
# 返回情感倾向
if positive_score > negative_score:
return "Positive", positive_score - negative_score
elif negative_score > positive_score:
return "Negative", negative_score - positive_score
else:
return "Neutral", 0
这段代码展示了一个极简的情感分析实现,实际应用中我们会使用更复杂的深度学习模型。
大语言模型(LLM)的崛起
图5:大语言模型工作流程时序图 - 展示了从用户输入到模型输出的完整交互过程
推荐系统:个性化信息筛选的智能引擎
推荐系统是AI的重要应用方向,它通过分析用户行为和内容特征,为用户提供个性化的推荐。
推荐系统的核心算法
# 推荐系统的三大类算法
recommendation_algorithms = {
"协同过滤": {
"基于用户": "找到相似用户,推荐他们喜欢的物品",
"基于物品": "找到相似物品,推荐给喜欢类似物品的用户",
"优点": "不需要物品特征,能发现用户潜在兴趣",
"缺点": "冷启动问题,数据稀疏问题"
},
"基于内容": {
"原理": "基于物品特征和用户偏好进行匹配",
"优点": "能解释推荐理由,不受冷启动问题影响",
"缺点": "难以发现用户潜在兴趣,需要丰富的特征工程"
},
"深度学习": {
"模型": ["Wide & Deep", "DeepFM", "NCF", "DSSM"],
"优点": "自动特征提取,处理复杂关系",
"缺点": "需要大量数据,模型解释性差"
}
}
# 简单的基于用户的协同过滤实现示例
def user_based_cf(user_id, user_item_matrix, k=5, n=10):
"""
user_id: 目标用户ID
user_item_matrix: 用户-物品交互矩阵
k: 相似用户数量
n: 推荐物品数量
"""
import numpy as np
from scipy.spatial.distance import cosine
# 计算用户相似度
similarities = []
for other_id in range(len(user_item_matrix)):
if other_id != user_id:
sim = 1 - cosine(user_item_matrix[user_id], user_item_matrix[other_id])
similarities.append((other_id, sim))
# 找到最相似的k个用户
similar_users = sorted(similarities, key=lambda x: x[1], reverse=True)[:k]
# 找出这些用户喜欢但目标用户未接触的物品
recommendations = {}
for similar_user_id, similarity in similar_users:
for item_id in range(len(user_item_matrix[0])):
if user_item_matrix[user_id][item_id] == 0 and user_item_matrix[similar_user_id][item_id] > 0:
if item_id not in recommendations:
recommendations[item_id] = 0
recommendations[item_id] += similarity * user_item_matrix[similar_user_id][item_id]
# 返回评分最高的n个物品
return sorted(recommendations.items(), key=lambda x: x[1], reverse=True)[:n]
这段代码展示了一个基于用户的协同过滤算法的简单实现,实际系统中会使用更复杂的矩阵分解或深度学习方法。
推荐系统的评估指标

图6:推荐算法性能对比XY图表 - 展示了不同推荐算法在各评估指标上的表现
强化学习:让AI学会决策与控制
强化学习是AI领域中一个独特的分支,它通过"试错"的方式让AI代理学习如何在环境中做出最优决策。
强化学习的核心组件
# 强化学习的核心组件
rl_components = {
"代理(Agent)": "学习做决策的实体",
"环境(Environment)": "代理交互的外部系统",
"状态(State)": "环境的当前情况",
"动作(Action)": "代理可以执行的操作",
"奖励(Reward)": "环境对代理动作的反馈信号",
"策略(Policy)": "代理的行为策略,决定在给定状态下采取什么动作"
}
# 简单的Q-learning算法实现
def q_learning(env, episodes=1000, alpha=0.1, gamma=0.9, epsilon=0.1):
"""
env: 环境对象,需要提供reset()和step()方法
episodes: 训练轮数
alpha: 学习率
gamma: 折扣因子
epsilon: 探索率
"""
import numpy as np
import random
# 初始化Q表
q_table = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(episodes):
state = env.reset()
done = False
while not done:
# ε-贪婪策略选择动作
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 探索:随机选择动作
else:
action = np.argmax(q_table[state]) # 利用:选择最优动作
# 执行动作,观察新状态和奖励
next_state, reward, done, _ = env.step(action)
# 更新Q值
best_next_action = np.argmax(q_table[next_state])
q_table[state, action] = (1 - alpha) * q_table[state, action] + \
alpha * (reward + gamma * q_table[next_state, best_next_action])
state = next_state
return q_table
这段代码实现了经典的Q-learning算法,它是强化学习中最基础的算法之一。
强化学习的应用场景
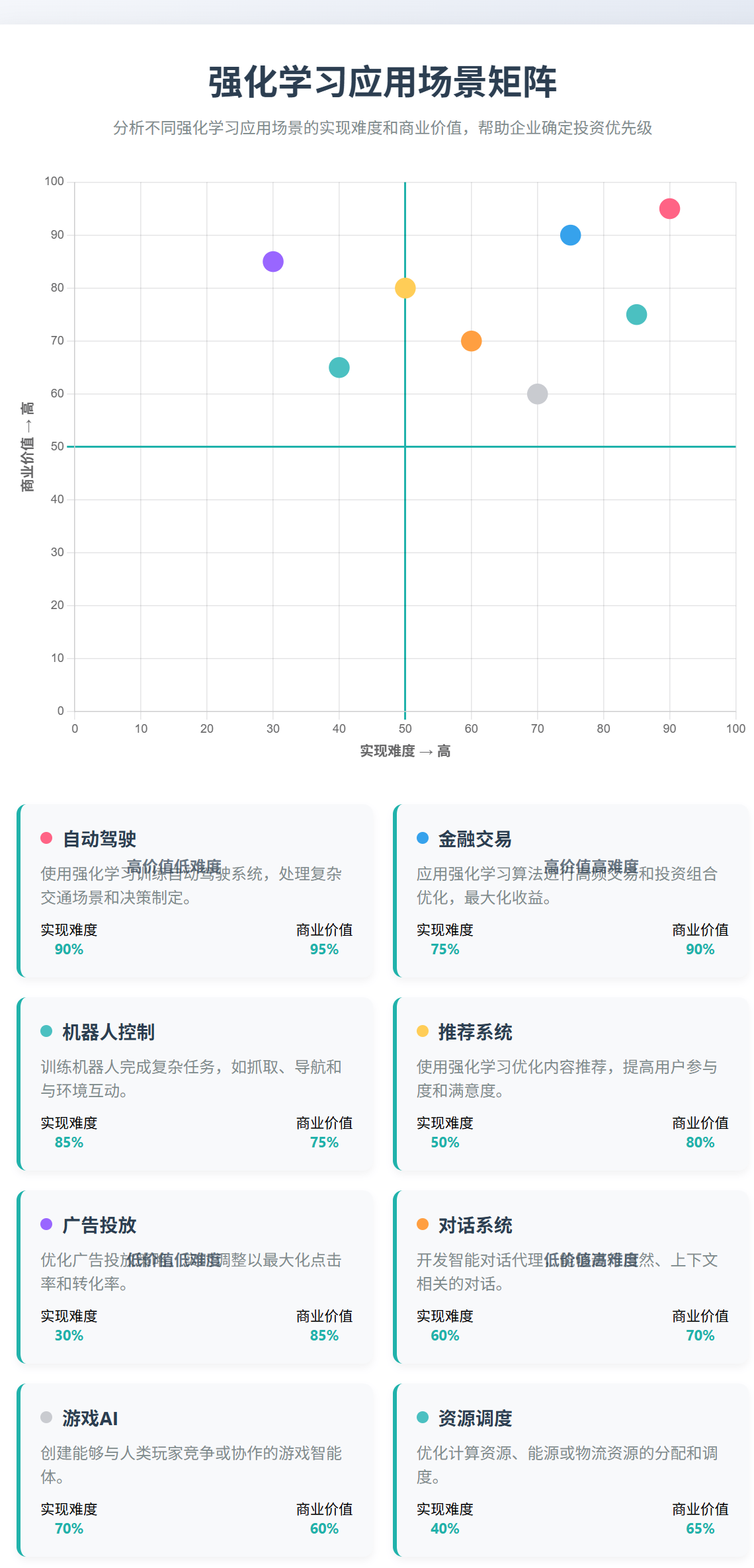
图7:强化学习应用场景象限图 - 展示了不同应用场景在实现难度和商业价值维度上的分布
AI细分方向的技术栈与入门路径对比
不同的AI细分方向需要不同的技术栈和学习路径。下面是各个方向的对比:
| 细分方向 | 核心技术栈 | 入门难度 | 就业前景 | 推荐入门路径 |
|---|---|---|---|---|
| 计算机视觉 | Python, PyTorch/TensorFlow, OpenCV | ★★★☆☆ | ★★★★☆ | 1. 掌握Python和图像处理基础 2. 学习CNN原理与实践 3. 掌握目标检测算法 4. 实践项目:人脸识别系统 |
| 自然语言处理 | Python, PyTorch/TensorFlow, Transformers | ★★★★☆ | ★★★★★ | 1. 掌握Python和文本处理基础 2. 学习词向量和RNN/LSTM 3. 掌握Transformer架构 4. 实践项目:情感分析系统 |
| 推荐系统 | Python, PyTorch/TensorFlow, Pandas | ★★★☆☆ | ★★★★☆ | 1. 掌握Python和数据分析基础 2. 学习协同过滤算法 3. 掌握深度推荐模型 4. 实践项目:电影推荐系统 |
| 强化学习 | Python, PyTorch/TensorFlow, Gym | ★★★★★ | ★★★☆☆ | 1. 掌握Python和深度学习基础 2. 学习MDP和Q-learning 3. 掌握DQN和策略梯度 4. 实践项目:游戏AI代理 |
| 多模态学习 | Python, PyTorch/TensorFlow, CLIP | ★★★★★ | ★★★★★ | 1. 掌握CV和NLP基础 2. 学习跨模态表示学习 3. 掌握多模态融合技术 4. 实践项目:图像描述生成 |
AI领域的发展趋势


图8:AI技术架构演进图 - 展示了从云端到设备端的AI技术部署架构
如何选择适合自己的AI方向
在选择AI细分方向时,需要考虑以下几个因素:
“选择AI方向不仅是选择一项技术,更是选择一种思维方式和解决问题的视角。找到与你个人兴趣和认知风格匹配的方向,才能在这个领域走得更远。” —— 吴恩达,AI领域教育家
个人兴趣与技能匹配度评估
# 个人兴趣与AI方向匹配度评估函数
def evaluate_ai_direction_fit(interests, skills):
"""
interests: 兴趣列表,如["图像处理", "算法设计", "数据分析"]
skills: 技能字典,如{"Python": 5, "数学": 4, "统计学": 3},1-5表示熟练度
"""
direction_matches = {
"计算机视觉": {
"兴趣匹配": ["图像处理", "视频分析", "模式识别"],
"技能要求": {"Python": 4, "数学": 4, "深度学习": 3, "图像处理": 3}
},
"自然语言处理": {
"兴趣匹配": ["语言学", "文本分析", "语义理解"],
"技能要求": {"Python": 4, "数学": 3, "深度学习": 4, "语言学": 2}
},
"推荐系统": {
"兴趣匹配": ["数据分析", "用户行为", "个性化"],
"技能要求": {"Python": 4, "数学": 3, "机器学习": 4, "数据分析": 4}
},
"强化学习": {
"兴趣匹配": ["决策优化", "游戏AI", "控制系统"],
"技能要求": {"Python": 4, "数学": 5, "深度学习": 3, "算法设计": 4}
}
}
results = {}
for direction, requirements in direction_matches.items():
# 计算兴趣匹配度
interest_match = len(set(interests) & set(requirements["兴趣匹配"])) / len(requirements["兴趣匹配"])
# 计算技能匹配度
skill_scores = []
for skill, required_level in requirements["技能要求"].items():
user_level = skills.get(skill, 0)
skill_scores.append(min(user_level / required_level, 1.0))
skill_match = sum(skill_scores) / len(skill_scores) if skill_scores else 0
# 综合评分
results[direction] = (interest_match * 0.6) + (skill_match * 0.4)
return sorted(results.items(), key=lambda x: x[1], reverse=True)
这个函数可以帮助你根据个人兴趣和技能评估最适合的AI方向。
结语
作为一名在AI领域深耕多年的技术实践者,我深刻体会到选择合适的细分方向对于个人发展的重要性。回顾我的技术成长历程,从最初对计算机视觉的好奇,到后来在自然语言处理领域的专注研究,每一步选择都深刻影响了我的职业轨迹。人工智能不仅仅是一项技术,更是一种解决问题的思维方式。在这个技术日新月异的时代,我们需要不断学习和适应。无论你选择哪个AI细分方向,持续学习的能力都是最宝贵的资产。我希望通过这篇文章,能够为你提供一个清晰的AI领域全景图,帮助你找到适合自己的技术方向。每个人的学习路径都是独特的,没有放之四海而皆准的"最佳路径",关键是找到与自己兴趣、能力和职业目标相匹配的方向。在我看来,AI领域最迷人的地方在于它的无限可能性,每一个细分方向都有广阔的探索空间。无论你是刚刚踏入这个领域的新手,还是寻求转型的资深开发者,希望这篇文章能够成为你AI旅程中的一盏明灯,指引你在这片星辰大海中找到属于自己的那颗闪亮的星星。让我们一起在这个充满无限可能的AI宇宙中,继续探索,不断创新,共同见证人工智能改变世界的伟大历程!
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
关键词标签
#人工智能 #机器学习 #深度学习 #计算机视觉 #自然语言处理