论文填补了传统统计方法(如 PCFG、Markov)与深度学习方法(如 LSTM、GAN)之间的研究空白,提出基于随机森林的口令猜测框架 RFGuess,覆盖三种核心猜测场景,为口令安全研究提供了全新技术路线。
一、研究背景
口令面临的核心威胁是猜测攻击。目前猜测攻击存在局限:传统方法存在过拟合和数据稀疏的问题;而深度学习需要大规模训练数据,训练时间长,调参复杂等问题。
二、本文研究
可概括为 “1 条技术路线 + 3 个模型 + 1 套优化算法 + 大规模验证”
技术路线:通过口令字符的多维度重新编码,将机器学习应用于口令猜测
三个模型:
①RFGuess:针对 “漫步猜测”(无目标信息,追求破解数量);
② RFGuess-PII:针对 “基于个人信息(PII)的定向猜测”(利用姓名、生日等,快速破解指定用户);
③RFGuess-Reuse:针对 “基于口令重用的定向猜测”(利用用户旧口令,破解新口令)
一套算法:近似最优 PII 匹配算法:改进传统 “左最长匹配” (优先匹配左侧最长 PII 片段)的局限,通过信息熵最小化选择全局最优 PII 表示,提升定向猜测成功率 7%~13%。
大规模验证:基于 13 个真实口令数据集(共 2.41 亿条口令,含中 / 英文、普通用户 / 安全意识较高用户),验证模型在不同场景下的有效性。
三、具体实现
3.1 口令字符的多维度编码(特征工程)
设计6 阶前缀 + 26 维特征向量(4×6+2)
单字符 4 维特征:字符类型,类型内序号,键盘行号,键盘列号。
额外2维长度特征:字符在整个口令中的位置,字符在当前字段的位置
3.2 场景一:漫步猜测模型:RFGuess
核心逻辑:将口令生成视为 “多分类问题”
输入:6 阶前缀的 26 维特征向量;输出:下一个字符的类别;模型:随机森林(由 30 棵 CART 决策树组成,通过 “特征随机选择 + 样本随机抽样” 避免过拟合)
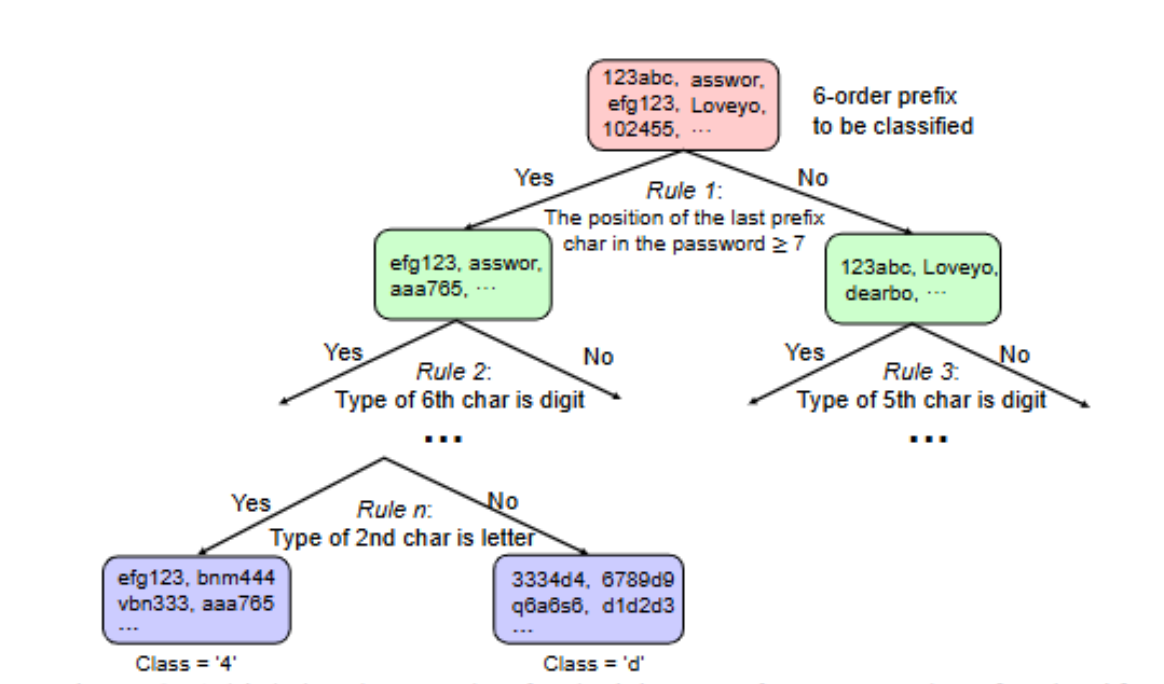
步骤:
1.训练阶段:将训练集中的每个口令拆分为 “6 阶前缀 - 下一个字符” 对(Bs作为开始符);用前缀的 26 维特征向量作为输入,下一个字符的序号作为标签,训练随机森林。
2.生成阶段:从初始前缀(Bs×6)开始,通过随机森林预测下一个字符的概率分布;对未获投票的字符采用 “add-δ 平滑”(δ=0.001),避免概率为 0;按概率降序生成猜测,直至生成终止符 Es 或达到预设猜测数。
优势:
- 解决 Markov 模型的数据稀疏问题:决策树会将 “相似特征的前缀” 归为同一叶节点,即使前缀未在训练集中出现,也能通过相似样本预测;
- 自动特征筛选:随机森林通过 “Gini impurity” 选择重要特征(如字符序号、键盘列号更重要),剔除冗余特征(如键盘行号),提升训练效率。
3.3 场景2:基于PII的定向猜测模型 RFGuess-PII
本文提出通过 “信息熵最小化” 选择全局最优 PII
步骤:
1. PII 标签数字化:将 PII 类型(姓名、生日、用户名等)用数字标签表示
2.枚举所有可能表示:对每个口令,列出所有可能的 PII 标签组合
3.按频次排序与迭代选择:按表示的频次降序排序,用 R₁表示所有可匹配的口令,剩余表示的频次减 1;重复上述步骤,直至所有表示频次≤1,未匹配口令用 “最短结构” 表示;
4.理论验证:该算法能最小化口令集的信息熵
RFGuess-PII模型
特征适配:PII 标签用(PII 类型、PII 序号、0、0)编码
训练:用含 PII 标签的口令集训练随机森林;
生成:将生成的含 PII 标签的猜测,替换为目标用户的真实 PII
3.4 场景 3:基于口令重用的定向猜测模型 RFGuess-Reuse
核心逻辑:用户重用口令时,通常会进行 “结构级”和 “字段级”修改
结构级变换:统计训练集中口令对的结构转换概率(如 “尾部插入 D₃” 的概率);
字段级变换:用随机森林预测字段内的原子修改(插入、删除、替换)概率。
eg:旧口令 “password!!”(结构 L₈S₂)生成新口令 “p@sswor123”(结构 L₇D₃)
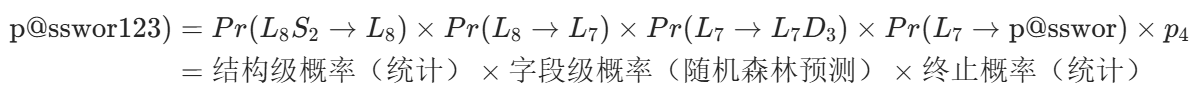
四、实验验证
4.1数据集
基础数据集:13 个真实数据集(8 个英文、5 个中文),共 2.41 亿条口令
PII 数据集:6 个含个人信息的数据集
口令重用数据集:8 个跨平台口令对数据集
4.2 对比方法
漫步猜测:PCFG、3/4 阶 Markov、FLA(LSTM)、Min-auto(理想攻击,取各方法最优结果)
定向 PII 猜测:TarGuess-I(PCFG-based)、Targeted-Markov(Markov-based)、FLA-PII(改进 FLA)
口令重用猜测:TarGuess-II(PCFG-based)、Pass2Path(Seq2Seq-based)
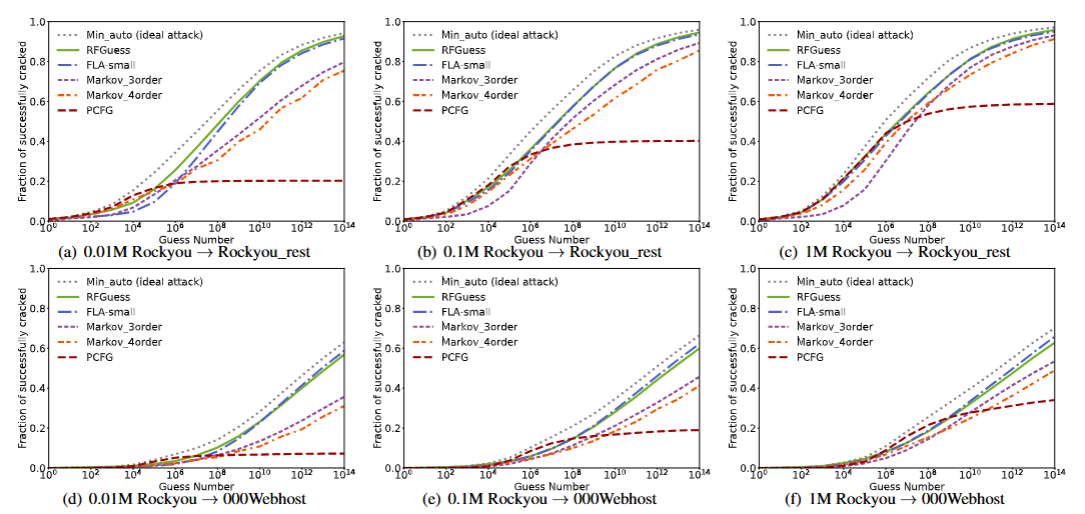
通过实验证明RFGuess 框架在三种核心场景下均表现优异。