点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!“快的模型 + 深度思考模型 + 实时路由”,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到:
Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
分片策略
分片概念详解
分片(Sharding)是分布式数据库系统中用于确定数据在多台存储设备上分布的核心技术。Shard这个词来源于"碎片"的概念,我们可以将整个数据库形象地比作一块完整的玻璃,当这块"玻璃"被打碎成多个部分时,每一部分就称为一个数据库碎片(Database Sharding)。将一个完整的数据库分割成多个碎片的过程就称为分片,这是一种典型的横向扩展(Scale-out)解决方案。
核心概念区分
● 分片:
- 这是一个逻辑上的概念,指的是数据划分的策略和方法
- 描述了如何将数据分散到不同节点的算法和规则
- 示例:按照用户ID的哈希值分配,或按照地域划分
● 分库分表:
- 这是物理上的实现结果,是分片策略的具体体现
- 表示数据最终被实际存储在不同的数据库或表中
- 示例:将用户表user拆分为user_0、user_1等分表
数据库扩展方案对比
横向扩展(Scale-out):
- 特点:通过增加机器数量来扩展系统
- 实现方式:将单一数据库拆分为多个数据库实例
- 优势:理论上可以无限扩展
- 适用场景:数据量大、读写请求高的互联网应用
- 示例:电商平台的订单数据按用户ID分片到不同数据库
纵向扩展(Scale-up):
- 特点:通过提升单机性能来增强系统能力
- 实现方式:升级CPU、增加内存、使用更快的存储设备
- 优势:实现简单,不需要改造应用架构
- 局限:受限于单机硬件性能上限
- 示例:金融核心系统使用高端服务器处理交易
分片技术的应用价值
在分布式存储系统中,当数据量达到TB甚至PB级别时,单节点数据库会遇到严重的IO瓶颈。分片技术通过以下方式解决这些问题:
性能提升:
- 将读写负载分散到多个节点
- 每个节点只需处理部分数据,响应时间显著降低
- 示例:10亿用户数据分散到10个节点,每个节点只需处理1亿
存储扩容:
- 突破单机存储容量限制
- 可以随着数据增长不断添加新节点
- 实际案例:某社交平台使用分片存储用户发布的数十PB图片
高可用性:
- 单个节点故障不会影响整个系统
- 可以通过副本机制保证数据可靠性
- 实现方式:每个分片配置多个副本节点
运维灵活性:
- 可以针对不同分片采用不同的硬件配置
- 热点数据可以分配到更高性能的节点
- 示例:将VIP用户的数据存储在SSD节点上
分片策略
数据分片是根据分片键和分片策略将数据水平拆分,拆分多个数据片后分散到多个数据存储节点中。分片键是用于划分和定位表的字段,一般使用ID或者时间字段。而分片策略是指分片的规则,常用规则有以下几种。
基于范围分片
基于范围分片(Range-based Sharding)是一种常见的数据分片策略,它根据特定字段的数值范围将数据划分到不同的存储节点上。常见的分片键包括:
- 用户ID:例如将用户ID在0-100万的分配到节点1,100-200万分配到节点2
- 订单时间:按月份划分,如2023年1月订单在节点1,2月订单在节点2
- 产品价格:0-100元商品在节点1,100-500元在节点2等
优点详解:
扩容友好性:
- 新增数据天然落在新范围的节点上
- 集群扩容时,只需为新范围添加节点,旧数据无需重新分配
- 示例:当增加2023年7月订单节点时,之前月份的订单数据保持原状
查询效率:
- 范围查询性能优异(如查询2023年Q1的订单)
- 支持高效的分片键顺序扫描
缺点详解:
热点问题:
- 近期订单集中在最新时间范围节点,造成访问不均衡
- 示例:电商大促期间,最新订单节点可能承受90%的读写压力
数据分布不均:
- 某些范围可能包含过多数据(如低价商品数量庞大)
- 节点负载差异可达10倍以上,导致资源浪费
维护复杂度:
- 需要持续监控和调整范围边界
- 冷数据处理困难(如5年前的订单几乎无访问但仍需存储)
适用场景:
- 有明显时间特征的数据(如日志、订单)
- 数值分布均匀的键(如均匀分布的用户ID)
- 需要频繁进行范围查询的业务
不适用场景:
- 键值分布严重不均的系统
- 随机访问为主的业务模型
- 对负载均衡要求极高的场景
哈希取模分片
哈希取模是一种基础且常用的数据分片方法,主要应用于分布式存储系统、数据库分片等场景。
实现原理
整型Key处理
对于整型主键Key,可以直接对设备数量N取模运算:
设备编号 = Key % N其他类型Key处理
对于字符串等非整型Key,需要先通过哈希函数(如MD5、SHA1等)计算出哈希值,再取模:
设备编号 = Hash(Key) % N其中设备编号范围是0到N-1,N表示当前集群中的设备总数。
特点分析
优点:
- 实现简单,逻辑清晰,开发成本低
- 数据分布均匀性较好,通过哈希函数的离散特性,可以保证数据相对均匀地分布在各个节点上
- 不易出现热点问题,每个节点承载的请求负载相对均衡
- 查询效率高,通过简单的计算即可准确定位数据位置
缺点:
- 扩容困难,当需要增加节点时(如从N台扩容到N+1台),会导致绝大部分数据的模值发生变化
- 数据迁移量大,扩容时约(N/(N+1))的数据需要重新分配和迁移
- 无法实现平滑扩容,扩容操作会对系统性能产生较大影响
- 缺乏灵活性,不能根据节点性能差异进行加权分配
应用场景示例
分布式缓存系统
Memcached等分布式缓存常采用此方法,将不同的缓存键均匀分布到多台缓存服务器。数据库分库分表
在水平分库分表场景中,可以用用户ID作为分片键,通过取模决定数据存储位置。负载均衡
一些简单的负载均衡算法也会采用类似方法将请求分发到不同的后端服务器。
优化方案
针对扩容问题的改进方法:
- 一致性哈希算法
通过引入虚拟节点,减少扩容时的数据迁移量 - 预分片技术
提前预留部分分片,延缓扩容需求 - 双写过渡
在扩容期间采用新旧集群同时写入的方式平滑迁移
数学特性分析
假设原集群有N个节点,扩容到N+1个节点时:
- 数据迁移比例 = 1 - (N/(N+1)) ≈ 1/N(当N较大时)
- 例如从10台扩容到11台,约90.9%的数据需要迁移
- 从100台扩容到101台,约99%的数据需要迁移
这种特性使得哈希取模分片在大规模集群中的扩容成本非常高。
一致性哈希分片
一致性Hash是将数据库按照特征值映射到一个首尾相接的Hash环上,同时也将节点(按照IP地址或者机器名Hash)映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点,Hash环的示意图如下所示:
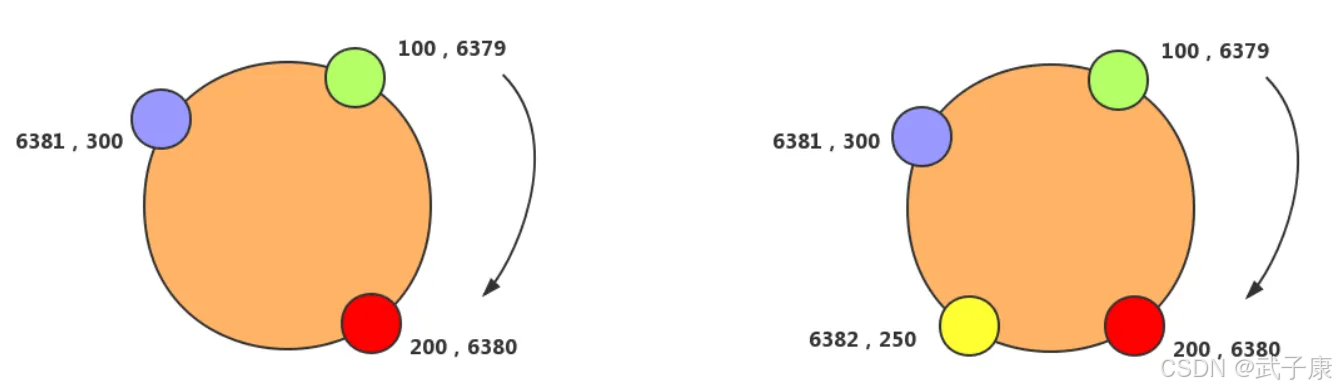
一致性Hash在增加或者删除节点的时候,受到影响的数据是比较有限的,只会影响到Hash环相邻的节点,不会发生大规模的数据迁移。
1. 传统哈希取模分片的局限性
采用传统的Hash取模方式进行数据分片时(如:hash(key) % N,其中N是节点数量),存在一个明显的弊端:当集群需要扩容或缩容(即N值发生变化)时,会导致大量的数据需要重新映射和迁移。例如:
- 初始有4个节点,某条数据的hash(key)%4=2,存储在节点2
- 扩容到5个节点后,hash(key)%5=3,需要迁移到节点3
- 这种改变会导致约75%的数据需要重新分布,迁移成本极高
2. 一致性哈希算法原理
一致性哈希算法通过以下方式解决上述问题:
- 哈希环构建:将整个哈希值空间组织成一个虚拟的环(0~2^32-1)
- 节点映射:对每个节点计算哈希(如hash(IP:port)),将其映射到环上
- 数据定位:对数据key计算哈希,在环上顺时针找到第一个节点即为存储位置
3. 关键优势
- 最小化数据迁移:当增加节点NodeX时,仅影响NodeX与前一节点之间的数据
- 虚拟节点技术:通过为每个物理节点分配多个虚拟节点(如200-300个),解决数据倾斜问题
- 动态平衡:节点上下线时,数据迁移量平均仅为K/N(K是数据总量,N是节点数)
4. 典型应用场景
- Redis集群:采用16384个槽位(slot)的变种一致性哈希
- Memcached:客户端分片常用一致性哈希
- 分布式存储系统:如Ceph的CRUSH算法基于一致性哈希优化
- 负载均衡:Nginx的upstream一致性哈希负载策略
5. Java实现示例
public class ConsistentHash {
private TreeMap<Long, String> virtualNodes = new TreeMap<>();
private int replicaCount; // 虚拟节点数
public void addNode(String node) {
for (int i = 0; i < replicaCount; i++) {
long hash = hash(node + "#" + i);
virtualNodes.put(hash, node);
}
}
public String getNode(String key) {
long hash = hash(key);
SortedMap<Long, String> tail = virtualNodes.tailMap(hash);
if (tail.isEmpty()) {
return virtualNodes.firstEntry().getValue();
}
return tail.get(tail.firstKey());
}
// 使用MurmurHash等优质哈希函数
private long hash(String key) { ... }
}
6. 注意事项
- 热点问题:对频繁访问的key需要通过副本机制解决
- 监控需求:需要实时监控各节点负载情况
- 哈希函数选择:推荐使用MurmurHash、CityHash等均匀性好的算法
- 数据迁移:实际系统中需要配合Pipeline等批量迁移技术