2.1 计算机系统概述
- 定义:计算机系统是用于数据管理的计算机硬件、软件及网络组成的系统,能按人的要求接收和存储信息,自动处理数据并输出结果。通常指由硬件和软件子系统组成的系统,简称计算机;连接多个计算机实现数据交换的网络设备则称为计算机网络。
- 组成:
- 硬件:由机械、电子元器件等物理实体构成,如处理器、存储器、输入输出设备等。
- 软件:按特定顺序组织的数据和指令,可分为系统软件(支持应用软件运行,提供开发平台)和应用软件(用户为专门应用目的开发)。
- 特点:硬件有形,软件无形,两者界限逐渐模糊,部分功能可根据设计由硬件或软件实现。
- 分类:分类维度多,结合构成特征、应用领域和用途有常见分类,但因技术交叉融合,分类无严格界限,主要依据主体功能。
2.2 计算机硬件
- 2.2.1 组成:基于冯·诺依曼计算机结构,划分为处理器、存储器、总线、接口和外部设备。
- 2.2.2 处理器:
- 作为运算和控制核心,在位宽、能力构成、内核等方面不断发展。
- 指令集分复杂指令集(CISC,如Intel、AMD的x86CPU)和精简指令集(RISC,如ARM和Power),RISC是发展趋势。
- 典型系统结构中各部件协同工作,且有专用处理器如GPU(适用于深度学习等)、DSP(用于实时数字信号处理)等。国产处理器如华睿、翔腾微等在不同行业应用。
- 2.2.3 存储器:
- 利用多种介质存储数据,按硬件结构有SRAM、DRAM等。
- 采用分层体系结构,按与处理器物理距离分片上缓存、片外缓存、主存(内存)、外存,各层次在结构、容量、特性等方面不同。外存掉电后数据可保留,但不同介质保存年限不同。
- 2.2.4 总线:
- 是计算机部件间遵循特定协议实现数据交换的形式。
- 按位置分内总线(片上/内总线)、系统总线(狭义为CPU与主存等连接的总线,广义含局部总线)、外部总线(通信总线)。
- 总线间通过桥连接实现协议转换,性能指标有带宽、QoS等,常见类型有并行总线(如PCI)和串行总线(如USB),专业领域还有特定总线。
- 2.2.5 接口:是同一计算机不同功能层间的通信规则,常见的有显示类、音频类、网络类等接口,一种总线可能有多种接口,也有随需求设计的非标准接口。
- 2.2.6 外部设备:
- 是非必要设备,但计算机必有部分,种类丰富,涵盖常见输入输出设备、外存,以及移动穿戴、工业控制等领域的专用设备。
- 均通过接口与计算机主体连接,通过指令和数据实现功能,且会随需求不断涌现新设备。
这段文本详细介绍了计算机软件的相关知识,尤其是系统软件中的操作系统,具体内容如下:
2.3 计算机软件
概念演变:早期软件与程序概念近乎一致,后来软件概念延伸为计算机系统中的程序及其文档,是计算任务的处理对象(数据或信息)和处理规则(动作和步骤)的描述,文档则是便于理解程序的阐述性资料。
2.3.1 计算机软件概述
- 软件系统定义:是在计算机硬件系统上运行的程序、相关文档资料和数据的集合,用于扩充计算机系统功能、提高效率。
- 分类:
- 系统软件:为整个计算机系统配置,不依赖特定应用领域的通用软件,负责控制和管理软硬件资源,为用户及其他应用软件提供服务,是硬件协调工作和应用软件运行的基础。可分为操作系统、程序设计语言翻译系统、数据库管理系统和网络软件等。
- 应用软件:为某类应用需求或解决特定问题而设计的软件,如图形图像处理软件、财务软件等。按使用面可分为专用应用软件和通用应用软件,在企事业单位的各类管理工作中发挥重要作用。
2.3.2 操作系统
- 定位:是计算机系统的资源管理者,是配置在硬件上的第一层软件,向下管理裸机及文件,向上为其他系统软件和应用软件提供支持及用户接口。
- 1. 组成:
- 由操作系统内核和诸多附加配套软件组成。
- 内核是最基本部分,提供进程管理、存储管理等功能,驻留内存,以CPU最高优先级运行,可执行特权指令,直接访问外设和主存,对硬件抽象后为应用软件提供统一接口(系统调用接口或API)。
- 附加配套软件包括图形用户界面程序、常用应用程序、实用程序及支持应用软件开发运行的软件构件等。
- 2. 作用:
- 管理程序运行和分配软硬件资源,避免冲突,保证程序有序运行,涵盖处理器、存储、文件、I/O设备等管理。
- 提供友善人机界面(如GUI),方便用户与计算机通信。
- 为应用程序开发和运行提供高效平台,屏蔽物理设备细节,提供支持。此外,还有辅导操作、处理错误、监控性能、保护安全等作用。
- 3. 特征:
- 并发性:多道程序环境下,宏观上多个程序同时运行,单CPU环境下微观上交替执行,多CPU可实现并行。
- 共享性:资源可被多个并发进程(线程)共同使用,有同时共享和互斥共享两种方式。
- 虚拟性:通过管理技术将物理实体转换为逻辑上的对应物,为用户提供便捷高效的操作环境。
- 不确定性:多道程序环境中,进程执行“走走停停”,其执行时间、推进速度等不可预知,可能导致程序执行结果不唯一。
- 4. 分类:
- 批处理操作系统:分单道和多道,单道一次装入一个作业执行,多道允许多个作业装入内存,提高资源利用率。
- 分时操作系统:将CPU时间划分为时间片,轮流为终端用户服务,具有多路性、独立性等特点。
- 实时操作系统:能快速处理外来信息并及时响应,分实时控制系统和实时信息处理系统,对可靠性要求高。
- 网络操作系统:用于实现联网计算机的资源共享,提供多种服务,具有硬件独立性、多用户支持等特征。
- 分布式操作系统:为分布式计算机系统配置,能动态分配资源、协调任务,是更高级的网络操作系统,具有透明性等特性。
- 微型计算机操作系统:如Windows、Mac OS、Linux等。
- 嵌入式操作系统:运行在嵌入式智能设备中,具有微型化、可定制、实时性等特点,常见的有VxWorks、μC/OS-III等。
2.3.3 数据库
在信息处理领域,由于数据量庞大,如何有效组织、存储数据对实现高效率的信息处理至关重要。数据库技术是目前最有效的数据管理技术。
数据库(DataBase,DB)是指长期存储在计算机内、有组织的、统一管理的相关数据的集合。它不仅描述事物的数据本身,而且还包括相关事物之间的联系。数据库可以直观地理解为“存放数据的仓库”,只不过这个仓库建立在计算机的存储设备上,且数据按特定格式存放,具有冗余度小、数据独立性高、易扩展性强的特点,可支持多个用户共享使用。
早期数据库主要分为3类,分别是层次式数据库、网络式数据库和关系型数据库。目前主流的数据库类型为关系型数据库和非关系型数据库;若按存储体系分类,还可细分为关系型数据库、键值(Key-Value)数据库、列存储数据库、文档数据库和搜索引擎数据库等,各类数据库的核心特性如下:
| 数据库类型 | 核心特性与应用场景 |
|---|---|
| 1. 关系型数据库 | 最传统的数据库类型,将复杂数据结构归结为“二元关系”(即二维表),数据操作基于一张或多张关联表格。通过分类、合并、连接、选取等运算实现管理,适用于数据结构固定、事务一致性要求高的场景(如金融、电商订单系统)。 |
| 2. 键值数据库 | 非关系型数据库的一种,以“键值对”(Key-Value Pair)形式存储数据,其中“键”作为唯一标识符。结构简单、读写效率高,适用于缓存、会话存储、配置管理等轻量数据场景(如Redis)。 |
| 3. 列存储数据库 | 与传统关系型数据库的“行式存储”相对,按“列”存储表中数据。擅长批量读取指定列数据、压缩率高,适用于数据分析、数据仓库等场景(如HBase)。 |
| 4. 文档数据库 | 存储XML、JSON、BSON等格式的“文档”,文档具备自描述性(Self-Describing),呈现分层树状结构,可包含映射表、集合和纯量值。文档间可相似但无需完全一致,可视为“值可查询的键值数据库”,适用于内容管理、电商商品描述等场景(如MongoDB)。 |
| 5. 搜索引擎数据库 | 专为搜索引擎场景设计,支持对海量爬取数据的高效存储与检索,通过特定索引结构优化查询性能,适用于全文检索、日志分析等场景(如Elasticsearch)。 |
下面简要介绍信息处理中常用的关系数据库和分布式数据库:
1. 关系数据库
数据模型是数据特征的抽象,是数据库系统的核心与基础,包含数据结构、数据操作、完整性约束条件三要素。在关系数据库中,“关系”可理解为“二维表”,一个关系模型即通过若干二维表表示实体(如“学生”“课程”)及其联系(如“选课”),并以二维表形式存储数据。
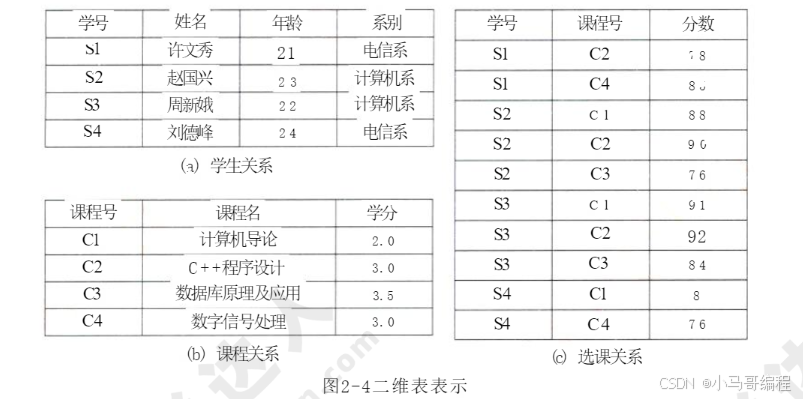
例如,某高校学生选课管理系统中,数据可通过以下三张二维表表示(带下画线的属性为“主码”,主码能唯一确定某个实体,如“学号”唯一确定一名学生):
- 学生(学号,姓名,年龄,系别)
- 课程(课程号,课程名,学分)
- 选课(学号,课程号,分数)
1) 关系数据库设计的特点及方法
数据库设计是指针对给定的应用环境,构造最优数据库及应用系统,以实现数据的有效存储和用户需求满足。其核心包括结构特性设计(数据模型设计)和行为特性设计(应用程序设计)两方面,且多数设计阶段可与软件工程阶段对应。
数据库设计的特点
- 以数据模型为核心展开,从数据结构设计起步;
- 静态结构设计(数据存储结构)与动态行为设计(数据操作逻辑)分离;
- 设计过程具有试探性、反复性和多步性(需多次迭代优化)。
常用数据库设计方法
数据库设计方法可分为直观设计法、规范设计法、计算机辅助设计法和自动化设计法4类,实际应用中常用的有:
- 基于第三范式(3NF)的设计方法(消除数据冗余和异常);
- 基于实体联系(E-R)模型的设计方法(通过E-R图描述实体、属性与联系);
- 基于视图概念的设计方法(从用户视角出发设计数据视图);
- 面向对象的关系数据库设计方法(融合面向对象思想与关系模型);
- 计算机辅助数据库设计方法(借助工具如PowerDesigner自动化设计);
- 敏捷数据库设计方法(快速迭代、适应需求变化)。
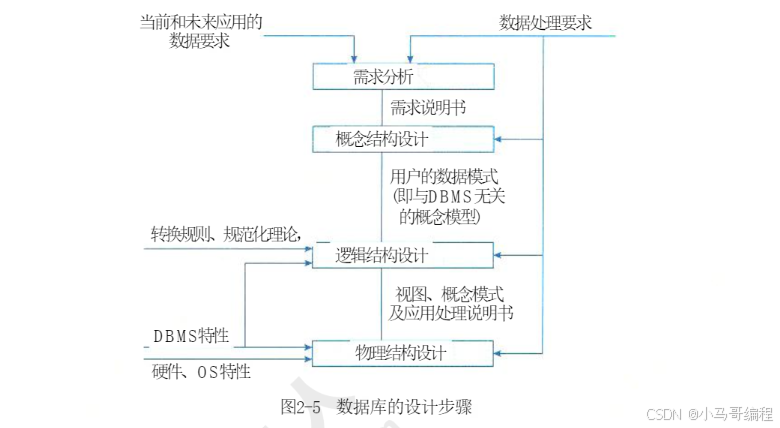
2) 关系数据库设计的基本步骤
数据库设计需经历需求分析、概念结构设计、逻辑结构设计、物理结构设计、应用程序设计、运行维护6个阶段,各阶段核心任务如下:
| 设计阶段 | 核心任务 |
|---|---|
| 需求分析 | 对现实处理对象(如企业、部门)进行详细调查,明确用户的数据需求(需存储的数据)和业务处理需求(数据操作逻辑),是后续设计的基础。 |
| 概念结构设计 | 在需求分析基础上,对用户信息分类、聚集、概括,建立概念模型(如E-R模型),核心是“数据建模”。常用E-R方法,分三步:设计局部E-R模型→设计全局E-R模型→全局E-R模型优化。 |
| 逻辑结构设计 | 将概念模型(如E-R图)转换为指定的数据模型(层次、网状或关系模型),确定数据完整性约束(如主码唯一、外码关联)和用户视图(用户可访问的数据范围)。 |
| 物理结构设计 | 对已确定的逻辑结构,利用数据库管理系统(DBMS)提供的技术,设计物理存储结构(如数据文件格式、索引结构)、数据存取路径、数据存放位置,目标是实现高效存储与查询。 |
| 应用程序设计 | 属于DBMS的二次开发,需选择设计方法(结构化设计/面向对象设计)、制定开发计划、确定系统架构(如C/S/B/S)、设计安全性策略(硬件/操作系统/数据库/网络/应用的安全防护)。 |
| 运行维护 | 保障数据库长期稳定运行,包括:数据转储与恢复(应对故障)、安全性与完整性控制(防止数据泄露或异常)、性能监督与优化(如索引调整)、数据库重组与重构(适应需求变化)。 |
2. 分布式数据库
分布式数据库系统(Distributed DataBase System,DDBS)是为满足“地理上分散、管理上需一定集中”的需求而提出的数据管理系统。若一个数据库系统满足分布性(数据分散存储在多个场地)、逻辑相关性(分散数据在逻辑上构成统一整体)、场地透明性(用户无需关注数据存储位置)、场地自治性(各场地可独立管理本地数据),则称为“完全分布式数据库系统”。
分布式数据库系统的核心特点
- 数据集中控制(全局统一管理,避免数据混乱);
- 数据独立性(逻辑独立性:用户无需关注数据逻辑结构;物理独立性:无需关注数据存储位置);
- 数据冗余可控(可保留必要冗余以提升查询效率,同时避免冗余过多导致一致性问题);
- 场地自治性(各场地可独立处理本地事务,降低依赖);
- 存取有效性(就近访问数据,减少网络传输开销)。
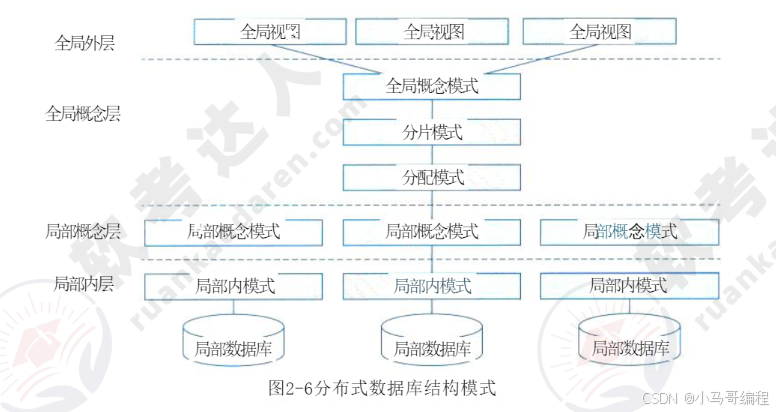
1) 分布式数据库体系结构
我国在分布式数据库研究与标准制定中,提出了4层抽象结构模式(得到国内外广泛认可),适用于同构型(各场地DBMS相同)和异构型(各场地DBMS不同)分布式数据库系统。4层结构及层间映射如下:
- 全局外层:面向用户,提供全局数据视图(用户可访问的全局数据);
- 全局概念层:描述全局数据的逻辑结构(如全局关系模式),是分布式数据库的核心;
- 局部概念层:描述各场地本地数据的逻辑结构(如本地关系模式);
- 局部内层:描述各场地数据的物理存储结构(如本地数据文件、索引);
- 层间映射:实现不同层级数据的转换(如全局数据→本地数据、逻辑结构→物理结构),保障场地透明性。
2) 分布式数据库的应用领域
分布式数据库广泛应用于需跨地域、跨系统数据管理的场景,典型包括:
- 分布式计算(如分布式任务调度中的数据共享);
- Internet应用(如电商平台的区域化数据存储);
- 数据仓库(跨部门、跨地区的海量数据整合分析);
- 数据复制(多场地数据同步,提升可用性);
- 全球联网查询(如跨国企业的全球数据统一查询);
- 典型产品:Sybase公司的Replication Server(分布式数据复制与同步系统)。
3. 常用数据库管理系统
随着计算机技术发展,数据库管理系统(DBMS)不断进化,可分为小型关系DBMS和大型关系DBMS两类,典型产品如下:
| 类别 | 代表产品 |
|---|---|
| 小型关系DBMS | MySQL(原属MySQL AB公司,2009年被Oracle收购)、Microsoft Access(桌面级DBMS) |
| 大型关系DBMS | Oracle(Oracle公司)、Microsoft SQL Server(微软公司)、IBM DB2(IBM公司) |
1) Oracle
Oracle是适用于大、中、微型计算机的高性能关系DBMS,核心特性包括:
- 结构完整:涵盖数据库内部结构、外存储结构、内存储结构和进程结构,不仅包含物理数据,还集成DBMS处理程序;
- 语言支持:使用PL/SQL(Procedural Language/SQL)语言执行数据操作,支持过程化编程;
- 功能扩展:Oracle 8及以上版本支持面向对象结构(如抽象数据类型);
- 产品体系:包括数据库服务器、开发工具(如PL/SQL Developer)、连接产品三类,还提供逻辑备份工具(Export/Import)等辅助工具。
2) IBM DB2
DB2是IBM推出的分布式关系DBMS,核心特性包括:
- 跨源查询:支持在同一条SQL语句中查询不同Database甚至不同DBMS的数据;
- 功能全面:支持面向对象编程、多媒体应用、备份恢复、存储过程与触发器、SQL查询、异构分布式访问、数据复制;
- 跨平台:采用多进程多线索体系结构,可运行于Windows、Linux、UNIX等多种操作系统;
- 开发工具:配套Visualizer、Visualage、Visualgen等设计与开发工具。
3) Sybase
Sybase是20世纪80年代中期推出的首款基于客户机/服务器(C/S)结构的关系DBMS,核心组成包括:
- Sybase SQL Server:联机关系DBMS,负责数据库管理与维护;
- Sybase SQL Toolset:前端开发工具集,支持数据库应用系统搭建;
- Sybase OpenClient/OpenServer:接口组件,实现异构环境下的软件与数据连接;
- 核心产品:Adaptive Server Enterprise(企业级高性能DBMS)、EAServer(电子商务应用服务器)、PowerDesigner(系统分析设计工具)、PowerBuilder(应用开发工具)。
4) Microsoft SQL Server
SQL Server是微软推出的典型关系DBMS,核心特性包括:
- 跨平台:可运行于Windows、Linux等操作系统;
- 语言支持:使用Transact-SQL(T-SQL)语言完成数据操作;
- 核心组件:包括Open Data Services(开放数据服务)、MS SQL Server(数据库核心服务)、SQL Server Agent(自动化任务调度)、MSDTC(分布式事务协调);
- 数据平台工具:涵盖关系型数据库、复制服务、通知服务、集成服务(ETL)、分析服务(OLAP)、报表服务、管理工具(如SSMS)和开发工具(如Visual Studio)。
4. 大型数据库管理系统的特点
大型DBMS(如Oracle、SQL Server、DB2)针对企业级应用设计,核心特点可概括为7点:
- 网络环境适配:支持C/S(客户机/服务器)和B/S(浏览器/服务器)两种架构,满足分布式应用需求;
- 大规模应用支撑:可支持数千并发用户、上百万事务/秒的处理能力,以及数百GB甚至PB级的数据容量;
- 并发控制高效:提供自动锁功能,确保多用户并发访问时的数据安全性与效率(避免脏读、不可重复读等问题);
- 安全性高:具备多层安全防护(如用户认证、权限控制、数据加密、审计日志),保障数据不泄露、不被篡改;
- 数据可靠性强:提供灵活的备份恢复方法(如全量/增量/差异备份)、设备镜像功能,结合操作系统容错机制,最大限度减少意外故障导致的数据丢失;
- 完整性保障:支持多种数据完整性约束(实体完整性、域完整性、参照完整性、用户自定义完整性),防止无效数据录入;
- 分布式处理便捷:内置分布式数据管理功能,支持跨场地数据访问、分布式事务处理,降低跨系统数据整合难度。
2.3.4 文件系统
在操作系统中,文件系统是实现文件统一管理的核心模块,负责抽象硬件存储细节、提供便捷的文件存取接口,并保障文件的安全性与可用性。以下从文件与文件系统的定义、文件分类、结构组织、存取与存储管理、共享与保护五个维度展开详细说明:
1. 文件与文件系统
1.1 文件(File)
文件是具有符号名、在逻辑上完整的一组相关信息项的集合,例如源程序、文档、图片、数据表格等均可视为文件。它是操作系统提供的“抽象机制”,核心作用是:
- 隐藏硬件存储细节(如磁盘物理地址、读写指令),用户无需了解存储原理,仅通过文件名即可存取信息;
- 实现信息的长期保存与复用,将数据稳定存储于外存(如硬盘、U盘)中。
一个完整的文件包含两部分:
- 文件体:文件的实际内容(如文档的文字、程序的代码);
- 文件说明(文件控制块/FCB):操作系统管理文件的元信息,包括:
- 标识信息:文件名、文件内部唯一标识;
- 存储信息:文件存储地址(外存物理块号)、文件长度;
- 管理信息:文件类型(如文本、可执行)、访问权限(只读/读写)、建立时间、最后访问时间。
1.2 文件系统
文件系统是操作系统中负责文件管理的一组软件、数据结构(如目录、索引表)的集合,其核心功能是为用户和应用程序提供高效、安全的文件操作能力,具体包括:
- 按名存取:用户通过文件名访问文件,无需记忆物理存储地址(区别于“按地址存取”);
- 统一用户接口:在不同存储设备(如硬盘、U盘)上提供一致的操作接口(如
read()/write()函数),简化编程与使用; - 并发访问控制:支持多道程序同时访问文件,通过锁机制避免数据冲突(如防止两个程序同时修改同一文件);
- 安全性控制:为不同用户分配不同访问权限(如文件主可读写、其他用户仅可读),防止未授权操作;
- 性能优化:通过缓存、索引等技术提升文件存储效率、检索速度与读写性能;
- 差错恢复:验证文件完整性(如校验和),并提供故障恢复能力(如断电后恢复未保存的文件数据)。
2. 文件的类型
文件分类的目的是优化管理效率、适配不同使用场景。常见分类方式如下:
| 分类维度 | 具体类型 | 说明 |
|---|---|---|
| 1. 性质与用途 | 系统文件、库文件、用户文件 | - 系统文件:操作系统核心文件(如Windows的kernel32.dll),仅系统可修改;- 库文件:预编译的函数库(如C语言的 stdio.h),供程序调用;- 用户文件:用户创建的文件(如文档、代码)。 |
| 2. 保存期限 | 临时文件、档案文件、永久文件 | - 临时文件:程序运行中临时生成,退出后自动删除(如浏览器缓存); - 档案文件:长期归档的重要数据(如企业财务报表); - 永久文件:需长期保存的用户数据(如个人照片)。 |
| 3. 保护方式 | 只读文件、读写文件、可执行文件、不保护文件 | - 只读文件:仅允许读取,禁止修改(如系统配置文件); - 可执行文件:可直接运行的程序(如 .exe文件);- 不保护文件:无访问限制(风险较高,较少使用)。 |
| 4. UNIX系统特殊分类 | 普通文件、目录文件、设备文件(特殊文件) | - 普通文件:文本、二进制等常规文件; - 目录文件:存储目录项(文件名与FCB的映射); - 设备文件:将硬件设备抽象为文件(如 /dev/sda代表硬盘),通过文件操作控制设备。 |
| 5. 常用文件系统类型 | FAT、VFAT、NTFS、Ext2、HPFS | - FAT/VFAT:早期Windows/DOS的文件系统,支持容量较小(如FAT32最大支持2TB); - NTFS:Windows主流文件系统,支持权限管理、加密、大容量(最大支持256TB); - Ext2:Linux早期主流文件系统,无日志功能; - HPFS:OS/2系统的文件系统,支持长文件名。 |
3. 文件的结构和组织
文件的结构分为“逻辑结构”(用户视角)和“物理结构”(实现视角),两者共同决定文件的存取效率与管理方式。
3.1 文件的逻辑结构(用户视角)
逻辑结构是用户感知到的文件组织形式,用户仅需通过文件名即可访问,无需关注物理存储。分为两类:
1) 有结构的记录式文件
由一个或多个“记录” 构成,每个记录对应一个实体的信息(如“学生记录”包含学号、姓名、年龄)。
- 按记录长度分类:
- 定长记录:所有记录长度相同(如每个学生记录占32字节),存取效率高;
- 不定长记录:记录长度不同(如不同学生的备注信息长度不同),灵活性高但管理复杂。
- 适用场景:数据需结构化管理的场景(如数据库表、员工信息表)。
2) 无结构的流式文件
由一串连续的字节流构成,不划分记录(如文本文件、二进制文件)。
- 特点:文件长度以字节为单位,访问时通过“读写指针”定位下一个操作位置;
- 适用场景:大多数普通文件(如
.txt文档、.jpg图片、.exe程序),可视为“记录式文件的特例”(仅含一个记录)。
3.2 文件的物理结构(实现视角)
物理结构是文件在外存物理块上的存放方式,决定了“逻辑块号→物理块号”的映射关系,直接影响文件存取速度。常见物理结构如下:
| 物理结构 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 1. 连续结构(顺序结构) | 逻辑连续的文件信息,依次存放在连续的物理块中(如文件占物理块10、11、12)。 | 存取速度快(可连续读取,减少磁头移动);实现简单。 | ① 需预先分配连续空间,易产生“碎片”(如磁盘剩余空间总和足够,但无连续块); ② 文件长度难以动态扩展。 |
长度固定、访问频繁的文件(如系统引导文件)。 |
| 2. 链接结构(串联结构) | 逻辑连续的文件信息,存放在不连续的物理块中,每个物理块含“指针”指向next块。 | ① 无需连续空间,利用率高; ② 文件长度可动态扩展。 |
① 只能顺序存取(需从第一个块开始遍历指针),随机访问效率低; ② 指针损坏会导致文件断裂。 |
顺序访问的大型文件(如日志文件)。 |
| 3. 索引结构 | 逻辑块存放在不连续物理块中,系统为文件建立索引表(记录逻辑块号→物理块号的映射),索引表起始地址存于FCB中。 | ① 支持随机访问(直接查索引表找物理块); ② 无碎片问题,文件易扩展。 |
① 需额外存储索引表,占用磁盘空间; ② 小文件的索引表开销占比高。 |
需随机访问的文件(如数据库文件、办公文档)。 |
| 4. 多个物理块的索引表 | 当文件过大,索引表需占用多个物理块时,采用“链接文件”或“多重索引”组织索引表: - 链接文件:索引块间用指针串联; - 多重索引:一级索引指向二级索引,二级索引指向物理块(如UNIX的i节点)。 |
支持超大文件(如GB级、TB级)存储。 | 多重索引需多次查找(如三级索引需查3次),开销略高。 | 超大文件(如视频文件、大型数据库)。 |
4. 文件存取的方法和存储空间的管理
4.1 文件的存取方法
存取方法是指读写外存物理块的方式,分为两类:
- 顺序存取:按文件逻辑顺序依次读写(如从文件开头→结尾),适用于流式文件、链接结构文件(如播放视频、读取日志);
- 随机存取(直接存取):可按任意次序读写指定物理块(如直接修改文件第100行内容),适用于索引结构文件(如数据库查询、编辑文档)。
4.2 文件存储空间的管理
外存(如硬盘)空间需统一管理,核心是记录“空闲块”与“占用块”,并高效分配/回收空间。常用管理方法如下:
| 管理方法 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
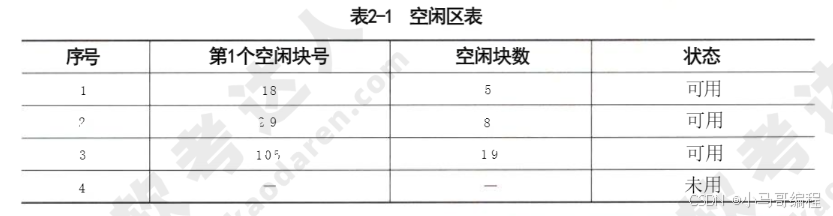
| 1. 空闲区表 | 将连续的未分配区域(空闲区)记录在“空闲区表”中,每个表项含:空闲区序号、起始块号、块数、状态。 | 实现简单,适合连续结构文件的空间分配。 | ① 需遍历表查找满足需求的空闲区; ② 易产生碎片。 |
连续结构文件系统(如早期FAT)。 |
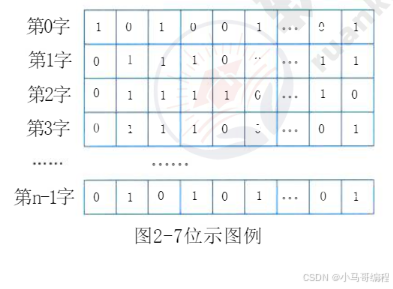
| 2. 位示图 | 用“位”表示物理块状态:1=占用,0=空闲(如32位字长的计算机,1个字可表示32个物理块)。 | ① 占用空间小(如1TB硬盘仅需128MB位示图); ② 查找空闲块高效(位运算快速定位); ③ 适配所有物理结构。 |
需将位示图加载到内存,内存开销随磁盘容量增加。 | 各类文件系统(如NTFS、Ext2)。 |
| 3. 空闲块链 | 所有空闲块用“指针”串联成链表,头指针存于系统管理块中;分配时取头块,回收时插入链表。 | ① 无需额外数据结构(无空闲区表/位示图); ② 分配/回收效率高。 |
① 只能顺序查找空闲块,大块分配慢; ② 链表断裂会丢失空闲块。 |
链接结构文件系统(如早期UNIX)。 |
| 4. 成组链接法 | UNIX系统采用:将空闲块分成若干组(如每组100块),每组第1块记录“下一组块号”和“本组块数”;最后一组的“下一组块号”为0。 | ① 结合空闲块链与索引的优点,分配/回收高效; ② 支持大块分配。 |
实现较复杂。 | 大型文件系统(如UNIX、Linux)。 |
5. 文件共享和保护
5.1 文件的共享
文件共享是指不同用户/进程使用同一文件,可节省存储空间、减少复制开销。核心是通过“目录链接”实现,常见方式有两种:
| 共享方式 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|
| 1. 硬链接 | 两个文件目录项(文件名)指向同一个索引结点(i节点),即“不同文件名对应同一文件实体”。 | ① 共享效率高(无数据复制); ② 删除一个文件名不影响文件实体(需删除所有硬链接才回收空间)。 |
① 不能跨文件系统(索引结点是文件系统内唯一的); ② 文件主删除文件需先关闭所有硬链接,否则会导致其他用户“指针悬空”。 |
| 2. 符号链接(软链接) | 新建一个“符号链接文件”,内容是原文件的路径名;访问时,系统通过路径名找到原文件。 | ① 可跨文件系统(甚至跨网络); ② 原文件删除后,符号链接仅提示“文件不存在”,无悬空问题。 |
① 访问需额外解析路径(效率略低); ② 符号链接文件本身占用少量空间。 |
5.2 文件的保护
文件保护是防止未授权访问或误操作,核心是“存取控制”,常用方法如下:
| 保护方法 | 核心原理 | 特点 | 适用场景 |
|---|---|---|---|
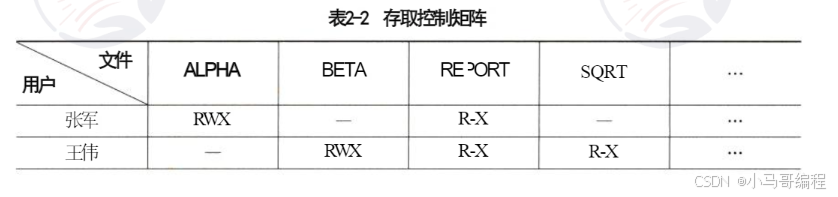
| 1. 存取控制矩阵 | 二维矩阵:行=用户,列=文件,矩阵元素=用户对文件的权限(如R=读、W=写、X=执行)。 | 理论完整,但矩阵过大(如1000用户×10万文件=1亿元素),无法实际存储。 | 仅用于理论分析,不落地实现。 |
| 2. 存取控制表 | 按文件分组,为每个文件建立“存取控制表”,记录“用户组→权限”(如UNIX将用户分为:文件主、同组用户、其他用户)。 | ① 简化矩阵(仅记录相关用户组); ② 实现灵活。 |
主流文件系统(如UNIX、Linux、NTFS)。 |
| 3. 用户权限表 | 按用户分组,为每个用户建立“权限表”,记录“文件→权限”(相当于存取控制矩阵的一行)。 | 查找效率高(用户访问文件时直接查自己的权限表)。 | 多用户系统(如大型主机)。 |
| 4. 密码保护 | 创建文件时用户设置密码,文件存储时加密;读取时需输入密码解密。 | 实现简单,安全性高(仅知密码者可访问)。 | ① 密码丢失则无法访问; ② 加密/解密有性能开销。 |
2.3.5 网络协议
在计算机网络中,不同设备(如计算机、路由器)间要实现数据交换与资源共享,必须遵循统一的“通信规则”,这一规则即网络协议。
协议的定义
协议是指网络中实体(设备/进程)通信时必须遵循的约定,明确规定了:
- 数据格式(如报文的字段结构、编码方式);
- 传输时序(如“先发请求、后发响应”的顺序);
- 控制信息(如差错校验码、确认信号);
- 应答机制(如接收方收到数据后需反馈“ACK”)。
常用网络协议分类
根据网络覆盖范围与功能,常用协议可分为:
- 局域网协议(LAN):用于局域网内设备通信,如Ethernet(以太网协议)、Wi-Fi(802.11协议);
- 广域网协议(WAN):用于跨地域网络通信,如PPP(点对点协议)、Frame Relay(帧中继协议);
- 无线网协议:用于无线设备通信,如Bluetooth(蓝牙协议)、5G NR(5G新空口协议);
- 互联网协议簇(TCP/IP):互联网的核心协议,包含TCP(传输控制协议,可靠传输)、IP(网际协议,路由选择)、HTTP(超文本传输协议,网页访问)、DNS(域名系统,域名解析)等。
2.3.6 中间件
一、中间件的定义与核心价值
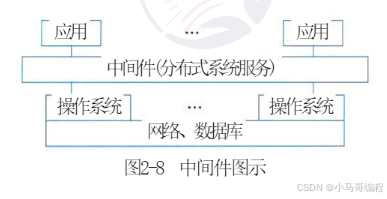
1. 定义
中间件(Middleware)是一类介于应用软件与系统软件(操作系统、网络、数据库)之间的基础软件,通过提供标准化编程接口和协议,实现“承上启下”的衔接作用。
2. 核心价值
- 降低开发成本:避免应用软件为适配不同操作系统/硬件单独开发版本,使开发脱离对具体底层环境的依赖;
- 实现跨平台兼容:确保应用软件在不同系统(如Windows、UNIX、Linux)上能运行并实现相同功能;
- 属于可复用基础软件:部分观点认为中间件可归为操作系统的延伸,但主流认知中其是独立的基础软件类别,定位在系统软件之上、应用软件之下。
二、中间件的分类(按分布式系统职责划分)
根据在分布式系统中承担的核心任务,中间件可分为8大类,各类别功能、类比说明及代表产品如下:
| 类别 | 核心功能 | 类比说明(帮助理解) | 代表产品/技术 |
|---|---|---|---|
| 1. 通信处理(消息)中间件 | 实现跨平台、可靠、高效的实时数据传输,解决分布式系统中不同模块的通信问题 | 类似“交通红绿灯+交通管理规则”,保障数据传输“畅通有序” | BEA eLink、IBM MQSeries、TongLINK;Windows等网络OS已包含部分基础功能 |
| 2. 事务处理(交易)中间件 | 管理分布式事务(如跨多服务器的订单支付),确保事务原子性(全成/全败);支持并发调度、负载均衡、故障自动恢复,保障系统“永不停机” | 类似“交通调度中心”,监控运输状态、处理拥堵/故障,确保运输高效可靠 | BEA Tuxedo(核心代表,在OLTP场景中广泛应用) |
| 3. 数据存取管理中间件 | 统一管理分布式系统中异构数据(关系型、文档型、加密/压缩多媒体数据),提供虚拟缓冲存取、格式转换、解压等便捷操作 | 类似“数据中转站”,适配不同格式数据的“装卸与转换” | 无明确单一代表产品,多为各厂商针对特定数据场景开发的专用组件 |
| 4. Web服务器中间件 | 弥补浏览器缺陷(会话能力差、不擅长数据写入、HTTP协议限制多),扩展Web交互功能 | 类似“浏览器功能增强插件”,提升Web端与后端的交互能力 | SilverStream公司相关产品 |
| 5. 安全中间件 | 解决军事、政府、商务等敏感领域的网络安全问题(如加密、认证、权限控制),需使用国产产品规避外部安全风险 | 类似“网络安全门禁”,阻挡未授权访问、保护数据隐私 | 无明确通用代表,多为国内厂商开发的专用安全组件(如国密算法适配中间件) |
| 6. 跨平台和架构中间件 | 集成分布式系统中不同平台(Windows/UNIX/Linux)、不同版本的构件,实现架构级兼容 | 类似“多语言翻译器”,让不同平台的“组件”能相互协作 | CORBA(跨任意平台,功能强但庞大)、JavaBeans(灵活轻量,适合浏览器,效率待提升)、COM+(仅适配Windows,桌面端广泛使用) |
| 7. 专用平台中间件 | 为特定领域(如电子商务、网站建设)设计参考模式与架构,配置专用构件库,支撑领域关键任务的开发与运行 | 类似“行业专用生产线”,为特定场景提供“定制化生产工具” | 无通用代表,多为针对电商、政务等领域的垂直化中间件(如电商交易流程中间件) |
| 8. 网络中间件 | 涵盖网络管理、接入控制、网络测试、虚拟社区、虚拟缓冲等功能,是当前热门研发方向 | 类似“网络基础设施维护工具集”,保障网络基础功能正常运行 | 无明确单一代表,多为网络设备厂商或OS厂商开发的配套组件(如网管软件、虚拟缓冲插件) |
三、主流中间件产品介绍
1. IBM MQSeries(消息处理中间件核心产品)
核心定位
工业级消息传输系统,用于集成分布式系统的多个分支应用,通过“消息传递”完成整个工作流程。
核心组成
- 信息传输系统:负责消息的存储、路由与分发;
- 应用程序接口(API):提供标准化调用方式;
- 核心资源:消息(数据载体)、队列(消息暂存容器)。
关键功能
- 可靠传输:即使网络不稳定或应用故障,也能保证消息不丢失、不阻塞(基于异步消息处理技术);
- 多平台兼容:支持所有主流计算平台与通信模式,适配Internet、Java等技术;
- 生态对接:提供与Lotus Notes、SAP/R3等主流产品的连接接口。
2. BEA Tuxedo(事务处理中间件核心产品)
核心定位
电子商务交易专用平台,专注解决分布式交易的完整性、高可用性与高效性问题。
关键功能
- 事务完整性保障:支持跨多数据库的协调更新,确保交易原子性;
- 故障自动恢复:持续监视应用、交易、网络、硬件状态,故障时自动排除故障构件并执行恢复步骤;
- 智能负载均衡:根据系统负载自动启停应用服务,均衡资源占用;
- 灵活路由与异步协作:通过DDR(数据依赖路由)按消息上下文选路;支持交易队列,实现“少连接”异步协同;
- 安全与兼容:LLE安全机制保障数据保密;提供50+硬件/OS的统一API;
- 便捷管理:基于网络的图形界面,简化电子商务系统的部署与运维。
2.3.7 软件构件
一、软件构件的定义与核心特性
1. 定义
软件构件(又称组件)是自包容、可复用的程序集,可以源程序或二进制代码形式存在,对外提供统一访问接口——外部只能通过接口调用功能,无法直接操作内部逻辑。
2. 核心特性
- 自包容性:构件内部逻辑独立,无需依赖外部非标准资源;
- 可复用性:可在不同系统或场景中重复调用,降低开发成本。
二、软件构件的组装模型
1. 核心思路
采用“搭积木”式开发:先通过需求分析定义软件功能,再设计构件组装结构(划分构件集合、明确构件间关系),最后独立开发/重用/采购构件,通过接口实现构件协作。
2. 开发过程
需经历“需求分析→构件结构设计→构件获取(开发/重用/采购)→构件组装→系统测试”流程(具体参考图2-9)。

3. 优缺点
| 类别 | 具体内容 |
|---|---|
| 优点 | 1. 扩展性强:构件自包容,新增/替换构件无需改动整体系统; 2. 成本低:可重用已有构件,减少重复开发; 3. 开发灵活:可拆分任务,团队并行开发不同构件。 |
| 缺点 | 1. 设计门槛高:需经验丰富的架构师设计构件结构,否则难以复用; 2. 性能妥协:为追求复用性,可能牺牲部分性能; 3. 学习成本高:开发人员需熟练掌握构件接口与使用规则; 4. 质量风险:第三方构件质量不可控,可能影响整体系统稳定性。 |
三、商用构件的标准规范
主流规范主要有三类,分别面向跨平台、Java生态、Windows平台,核心差异体现在适配场景与技术架构:
| 规范名称 | 发起方 | 核心架构与功能 | 关键组成/技术点 |
|---|---|---|---|
| CORBA | OMG(对象管理组织) | 跨任意平台的分布式构件规范,通过“软总线”实现异构系统互操作,分三层架构: 1. 底层ORB(对象请求代理):定义接口与语言映射,实现对象通信; 2. 中间公共服务:提供并发、名字、事务、安全等基础服务; 3. 上层公共设施:定义构件框架,提供业务协作协定。 |
核心是CORBA CCM(构件模型),包含: 1. 抽象构件模型:描述构件结构与互操作规则; 2. 构件容器:提供运行/管理环境,集成安全、事务等服务; 3. 配置打包规范:管理构件二进制代码、多语言版本与配置文档。 |
| J2EE | Sun公司 | 基于Java的企业级分布式应用规范,支持跨平台,适配多层架构,核心解决服务器端构件开发问题。 | 1. 通信协议:支持RMI(远程方法调用)、IIOP(互联网ORB协议); 2. 服务器端形式:Servlet(处理请求)、JSP(生成页面)、EJB(业务逻辑,分会话Bean-维护会话、实体Bean-处理事务); 3. 定位:EJB是业务逻辑层中间件,与Servlet、JSP共同构成应用服务器标准。 |
| DNA 2000 | Microsoft | 基于Windows平台的分布式计算架构,扩展自Windows 2000,融合事务处理、集群、异步消息等技术,适配微软生态。 | 1. 核心技术:DCOM/COM/COM+(构件对象模型),从桌面OLE扩展到分布式应用; 2. 服务器端支持:ASP(动态网页)、Cluster(集群); 3. COM+增强:集成负载均衡、对象池、事务服务(MTS),统一COM、DCOM功能,面向服务器端业务逻辑。 |
2.3.8 应用软件
一、应用软件的定义
应用软件是为解决特定领域问题、满足用户具体需求而设计的程序集合,建立在系统软件(操作系统、数据库等)之上,可分为个人用户与企业用户两类场景。
二、应用软件的分类(按开发方式与适用范围)
1. 通用软件
定义
面向大众通用需求开发,可在不同用户、不同场景中直接使用,无需定制。
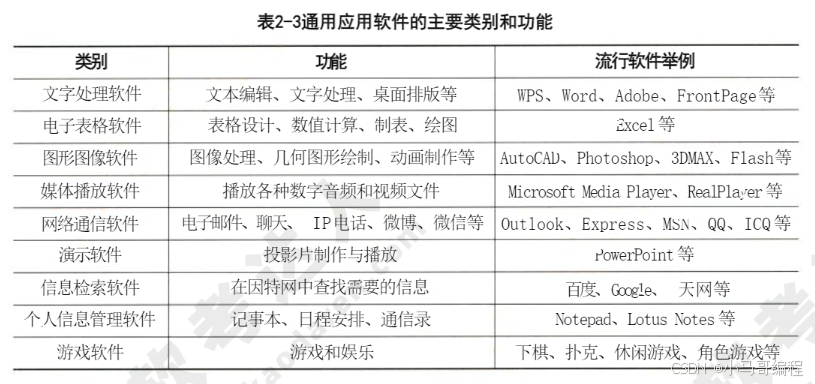
常见类型(见表2-3)
特点
- 易用性强:设计精巧,用户无需培训即可上手;
- 普及性高:覆盖大众高频需求,是计算机普及的核心支撑。
2. 专用软件(定制软件)
定义
按特定领域用户的个性化需求定制开发,仅适配单一机构或场景。
常见案例
- 超市:销售管理与市场预测系统;
- 制造业:汽车厂集成制造系统;
- 教育:大学教务管理系统;
- 医疗:医院信息管理系统;
- 服务业:酒店客房管理系统。
特点
- 专用性强:功能与用户业务深度绑定,无法通用;
- 成本高:定制开发周期长、投入大,价格远高于通用软件;
- 用户群体:以企业、机构用户为主,个人用户极少使用。
三、应用软件的共同特点
所有广泛使用的应用软件,均具备以下核心价值:
- 替代与优化:可替代现实工具(如文字处理替代纸笔、电子表格替代纸质报表),且使用更便捷、效率更高;
- 能力扩展:能完成现实工具难以实现或无法实现的任务(如大数据分析、3D建模),延伸用户的工作与创作能力。