这个博客用来记录在 Nvidia Orin 64 GB DK 设备上本地 ollama 部署并评测主流的几个 20GB 以下模型 gpt-oss:20b、gemma3:27b、qwen3:30b 模型的性能,其中 gpt-oss 是 OpenAI 刚刚开源(2025年08月05日)的模型,距离博客形成时间(2025年08月07日)仅过去 2 天,算是赶了一个大早。
如果你拿到的是一台全新的 Orin 设备,并且手上准备好了一块 M.2 接口的 SSD,那么可以参考我的这篇博客先对设备进行刷机:
首先说几个重要事项:
- 为了能更好的体现模型的真实状态,在测试的时候不提供任何系统提示词,系统提示词会显著影响模型输出token速率;
- Jetson Orin 无法运行 gpt-oss:120b,128GB 显存的 Thor 能否运行我们将在收到货之后进行测试,预计在 09月04日完成评测;
- 在测试过程中发现
qwen3:27b容易出现中文输入一半后突然开始输出英文的情况,并且发生了无限循环输出固定语句的事件,导致该轮测试中断;
Step1. 软硬件确认
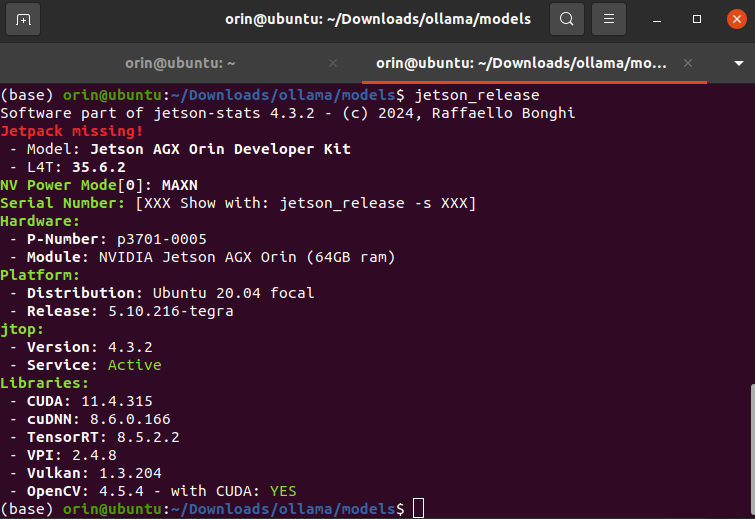
在正式开始之前先确认软硬件配置,特别是 CUDA 和 cuDNN 版本信息,可以通过下面的命令查看相关版本信息:
$ jetson_release
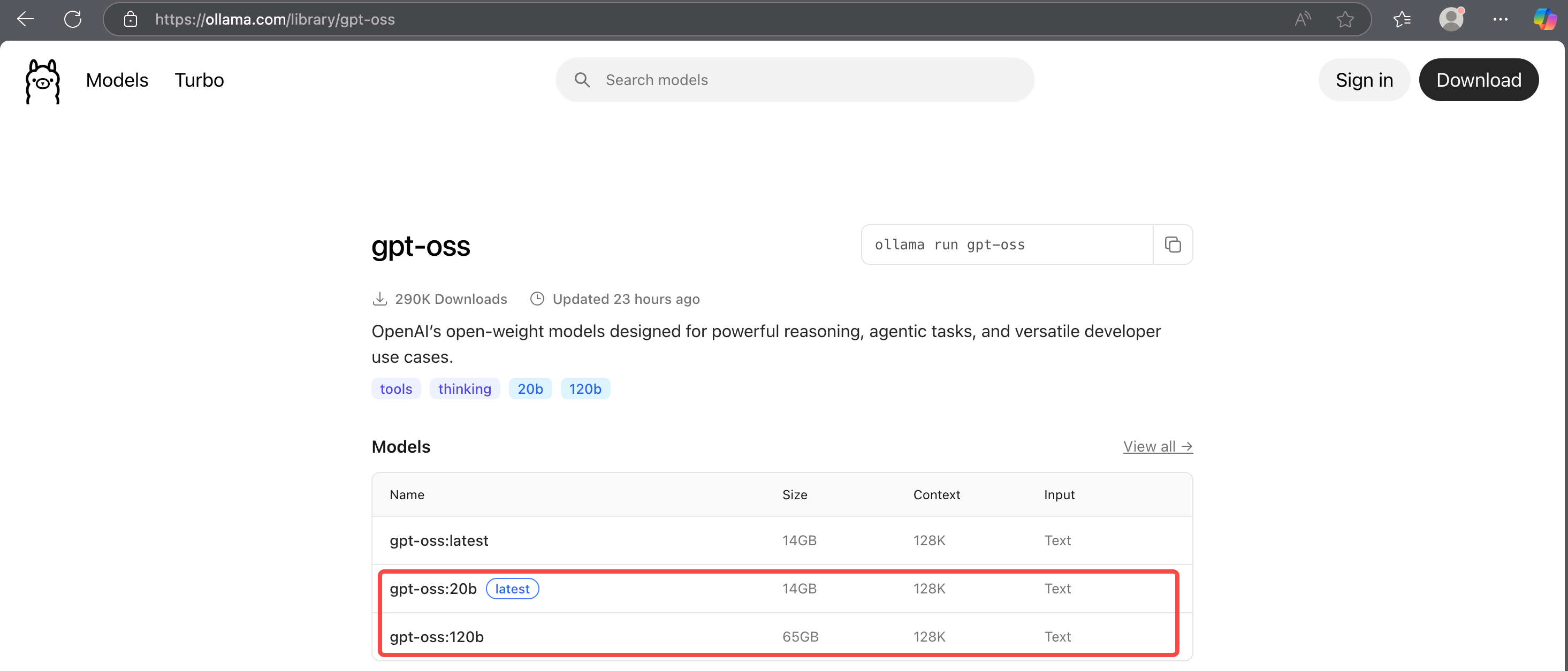
OpenAI 开出来的模型 gpt-oss 目前有 2 个参数总量的版本,Orin 只能运行其中的 20b 参数版本,强行运行 120b 的模型会导致宕机。OpenAI 还提供了 Ollama 的模型格式,可以通过下面的链接进入 Ollama 官网查看模型:
- Ollama - GPT-oss:https://ollama.com/library/gpt-oss
Step2. 安装与更新 Ollama
【Note】:必须使用最新版本的 Ollama,旧版本无法运行;
如果你在之前没有下载过 Ollama,那么可以直接在官网上使用其提供的命令进行下载,亲测 Arm 上也能直接使用:
- Ollama 官方下载页面:https://ollama.com/download/linux
$ curl -fsSL https://ollama.com/install.sh | sh
Step3. [重要] 修改模型默认存放路径
由于 Orin 64 GB 版本在完成刷机之后就只剩下 30 GB 左右,而本次测试至少需要有 超过 50 GB 的硬盘空间用来存储模型,因此强烈建议在执行模型拉取之前先修改 Ollama 默认存储路径。如果你之前是按照我的刷机博客完成的刷机并扩充了硬盘,那么这一步 仍然需要作,因为 ollama 模型的默认存储位置是在 /usr/share/ollama/.ollama/models,这个路径并没有挂载到硬盘上。
- 停止 olama 服务,这一步很重要否则不会生效:
$ sudo systemctl stop ollama.service
- 创建一个保存模型的文件夹并修改权限,这里以
Downloads/ollama为例:
$ cd Downloads
$ mkdir -p ollama/models
$ sudo chown -R root:root /home/orin/Downloads/ollama/models
$ sudo chmod -R 777 /home/orin/Downloads/ollama/models
- 修改
/etc/systemd/system/ollama.service文件:
$ sudo vim /etc/systemd/system/ollama.service
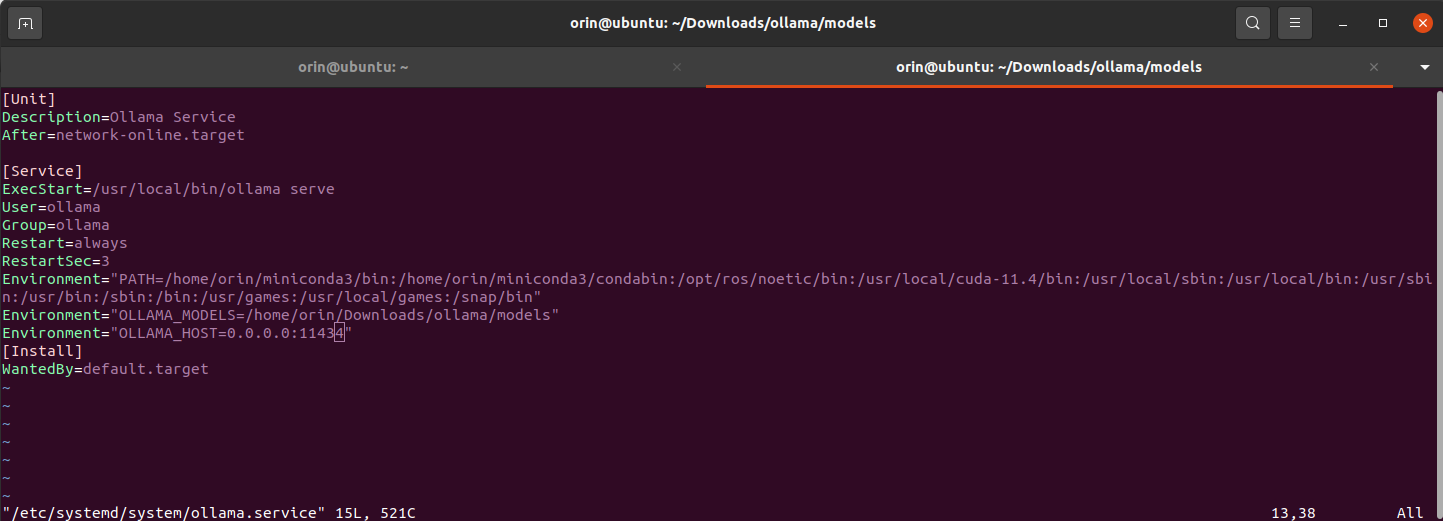
在 [Service] 部分添加以下内容并修改 User 与 Group:
User = root
Group = root
Environment="OLLAMA_MODELS=/home/orin/Downloads/ollama/models"
Environment="OLLAMA_HOST=0.0.0.0:11434"
效果如下:
Step4. [可选] 安装 ChatBox
ChatBox 是一个用户友好的可视化软件,使用该工具也能调用本地 ollama 模型。
【注意】:实验发现官网最新的软件无法运行,会报错 libsql 库缺失,我们在网盘中存放了一个可使用的版本,如果你从官网下载的版本可以运行则优先使用官网稳定版:
- ChatBox 官网下载页面:https://chatboxai.app/en#download
- 网盘:https://pan.baidu.com/s/14C2z23Ia0cqI5nwp4efI8w?pwd=6uit
下载好后赋予可执行权限后运行:
$ chmod +x Chatbox-1.15.2-alpha.0-arm64
$ ./Chatbox-1.15.2-alpha.0-arm64

在窗口右侧添加你的本地 ollama 模型即可。
Step5. 拉取模型
使用下面的命令拉取 gpt-oss:20b 、gemma3:27b、qwen3:30b 模型:
$ ollama pull gpt-oss:20b
$ ollama pull gemma3:27b
$ ollama pull qwen3:30b
Step6. 模型测试脚本
受到资源限制,这里只对以下几个指标进行测试,重点考察模型的推理效率和响应速度。
- 首字延迟 (Time to First Token, TTFT);
- 生成速度 (Tokens Per Second, TPS);
- 推理延迟 (Latency);
- 吞吐量 (Throughput);
建议新建一个 conda 环境并安装 ollama 后进行测试:
(base) $ conda env create -n ollama python=3.12
(base) $ conda activate ollama
(ollama) $ pip install ollama requests
测试内容
prompts.jsonl:
{"id": 1, "prompt": "请用Python编写一个函数,该函数接收一个未排序的整数列表,并使用归并排序(Merge Sort)算法将其排序。请在代码中加入详细的注释,解释算法的关键步骤。"}
{"id": 2, "prompt": "假设有三个盒子,一个装满了金币,另外两个是空的。每个盒子上都贴着一张标签,分别写着“金币在这里”、“金币不在这里”、“金币在第二个盒子”。但你被告知,这三张标签全部都是错的。请问,金币到底在哪个盒子里?请详细说明你的推理过程。"}
{"id": 3, "prompt": "以“当最后一个星系的光芒熄灭时,宇宙的图书管理员合上了他的书。”为开头,写一个不超过500字的科幻短篇故事。"}
{"id": 4, "prompt": "请解释什么是“黑洞信息悖论”(Black Hole Information Paradox)?这个悖论的核心矛盾是什么?目前物理学界有哪些主流的理论或假说试图解决这个悖论?"}
{"id": 5, "prompt": "你现在是一位经验丰富的市场策略师。一家新兴的电动汽车公司准备进入竞争激烈的北美市场,他们的主要卖点是创新的电池技术和可持续的生产理念。请为这家公司制定一份市场进入策略(Go-to-Market Strategy),包括目标客户群体、品牌定位、营销渠道和关键的头三个月行动计划。"}
{"id": 6, "prompt": "比较并对比两种现代编程语言:Go 和 Rust。请从以下几个方面进行分析:内存管理、并发模型、性能、生态系统和最适合的应用场景。"}
{"id": 7, "prompt": "请将以下这首李白的《月下独酌·其一》翻译成具有诗意的英文。不仅要翻译字面意思,还要尽可能传达原诗的意境和情感。\n\n花间一壶酒,独酌无相亲。\n举杯邀明月,对影成三人。\n月既不解饮,影徒随我身。\n暂伴月将影,行乐须及春。\n我歌月徘徊,我舞影零乱。\n醒时同交欢,醉后各分散。\n永结无情游,相期邈云汉。"}
{"id": "8", "prompt": "对于一个完全没有编程基础的成年人,如果他想在一年内转行成为一名前端开发工程师,请为他设计一个为期12个月的详细学习路线图。请将路线图按季度划分,并列出每个季度需要学习的关键技术栈、建议的实践项目和评估学习成果的方法。"}
{"id": 9, "prompt": "请以通俗易懂的方式,向一名高中生解释什么是“零知识证明”(Zero-Knowledge Proof)。可以举一个具体的例子,比如“阿里巴巴的洞穴”或者其他类似的例子来帮助理解。"}
{"id": 10, "prompt": "分析自动驾驶汽车在面临“电车难题”(Trolley Problem)时的道德和伦理困境。例如,当不可避免的碰撞发生时,汽车应该优先保护乘客,还是优先保护行人?如果需要做出选择,它的决策依据应该是什么?讨论一下当前业界和学术界对这个问题的不同观点。"}
测试脚本
benchmark.py
import ollama
import json
import time
import statistics
# --- 配置 ---
MODEL_NAME = "gpt-oss:20b"
PROMPTS_FILE = "prompts.jsonl"
def benchmark_model_with_library():
"""
使用官方 ollama 库进行基准测试。
这个版本更健壮,并解决了之前遇到的所有问题。
"""
results = []
print(f"🚀 开始对模型 '{MODEL_NAME}' 进行基准测试 (使用 ollama 库)...")
print(f"🔄 从文件 '{PROMPTS_FILE}' 加载 prompts...")
try:
with open(PROMPTS_FILE, 'r', encoding='utf-8') as f:
prompts = [json.loads(line) for line in f]
except FileNotFoundError:
print(f"❌ 错误: prompts文件 '{PROMPTS_FILE}' 未找到。")
return
except json.JSONDecodeError:
print(f"❌ 错误: '{PROMPTS_FILE}' 文件格式不正确。")
return
print(f"✅ 成功加载 {len(prompts)} 个 prompts。\n")
for i, item in enumerate(prompts):
prompt_id = item.get("id", i + 1)
prompt_text = item.get("prompt")
if not prompt_text:
print(f"⚠️ 警告: 第 {prompt_id} 个prompt为空,已跳过。")
continue
print(f"--- [ Prompt {prompt_id}/{len(prompts)} ] ---")
print(f"🤔 输入: {prompt_text[:80]}...")
print(f"\n模型输出: ", end="")
messages = [{'role': 'user', 'content': prompt_text}]
try:
start_time = time.time()
first_token_time = None
last_token_time = None
token_count = 0
is_first_chunk = True
# 使用 ollama.chat 进行流式请求
stream = ollama.chat(
model=MODEL_NAME,
messages=messages,
stream=True,
)
for chunk in stream:
# 记录首个Token时间
if is_first_chunk:
first_token_time = time.time()
is_first_chunk = False
# 流式打印内容
content = chunk['message']['content']
print(content, end='', flush=True)
# 记录最后一个Token的时间点
last_token_time = time.time()
# 检查是否是最后一个数据块,并从中获取最终的token计数
if chunk.get('done'):
# 'eval_count' 是Ollama返回的生成token数量
token_count = chunk.get('eval_count', 0)
end_time = time.time()
print("\n") # 换行
if token_count == 0 or first_token_time is None:
print("⚠️ 模型没有生成任何有效的token。")
continue
# --- 指标计算 ---
ttft = first_token_time - start_time
e2e_latency = end_time - start_time
# 因为我们现在有了准确的token_count,所以ITL和TPS的计算会更精确
if token_count > 1:
# ITL 使用 last_token_time 更精确,因为它代表最后一个内容块的时间
itl = (last_token_time - first_token_time) / (token_count - 1)
else:
itl = 0.0
tps = token_count / e2e_latency
result = {
"id": prompt_id, "ttft": ttft, "e2e_latency": e2e_latency,
"itl": itl, "tps": tps, "token_count": token_count
}
results.append(result)
print(f"✅ 完成! 生成了 {token_count} 个 tokens。")
print(f" - TTFT (首个Token生成时间): {ttft:.4f} 秒")
print(f" - E2E Latency (端到端延迟): {e2e_latency:.4f} 秒")
print(f" - ITL (Token间延迟): {itl * 1000:.4f} 毫秒/token")
print(f" - TPS (每秒生成Token数): {tps:.2f} tokens/秒\n")
except Exception as e:
print(f"\n❌ 在处理过程中发生未知错误: {e}")
continue
# --- 汇总结果 (这部分无需改动) ---
if results:
print("\n--- 📊 基准测试汇总报告 ---")
avg_ttft = statistics.mean([r['ttft'] for r in results])
avg_e2e_latency = statistics.mean([r['e2e_latency'] for r in results])
avg_itl = statistics.mean([r['itl'] for r in results])
avg_tps = statistics.mean([r['tps'] for r in results])
total_tokens = sum([r['token_count'] for r in results])
print(f"测试模型: {MODEL_NAME}")
print(f"测试数量: {len(results)} 个 prompts")
print(f"生成总数: {total_tokens} 个 tokens")
print("\n--- 平均性能指标 ---")
print(f"平均 TTFT: {avg_ttft:.4f} 秒")
print(f"平均 E2E Latency: {avg_e2e_latency:.4f} 秒")
print(f"平均 ITL: {avg_itl * 1000:.4f} 毫秒/token")
print(f"平均 TPS: {avg_tps:.2f} tokens/秒")
print("--------------------------\n")
if __name__ == "__main__":
benchmark_model_with_library()
执行测试
为了正确体现模型的性能,避免从硬盘加载模型耗时被错误统计进来,你可以先使用下面的脚本 single_test.py 先激活测试模型:
from ollama import chat
from ollama import ChatResponse
stream = chat(
model='gpt-oss:20b',
messages=[{'role': 'user', 'content': '为什么天空是蓝色的?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
(ollama) $ python load_model_demo.py
用 jtop 命令查看 GPU 显存的使用状态,执行后在键盘上敲击数字 2 即可查看显存的动态加载情况:
$ jtop
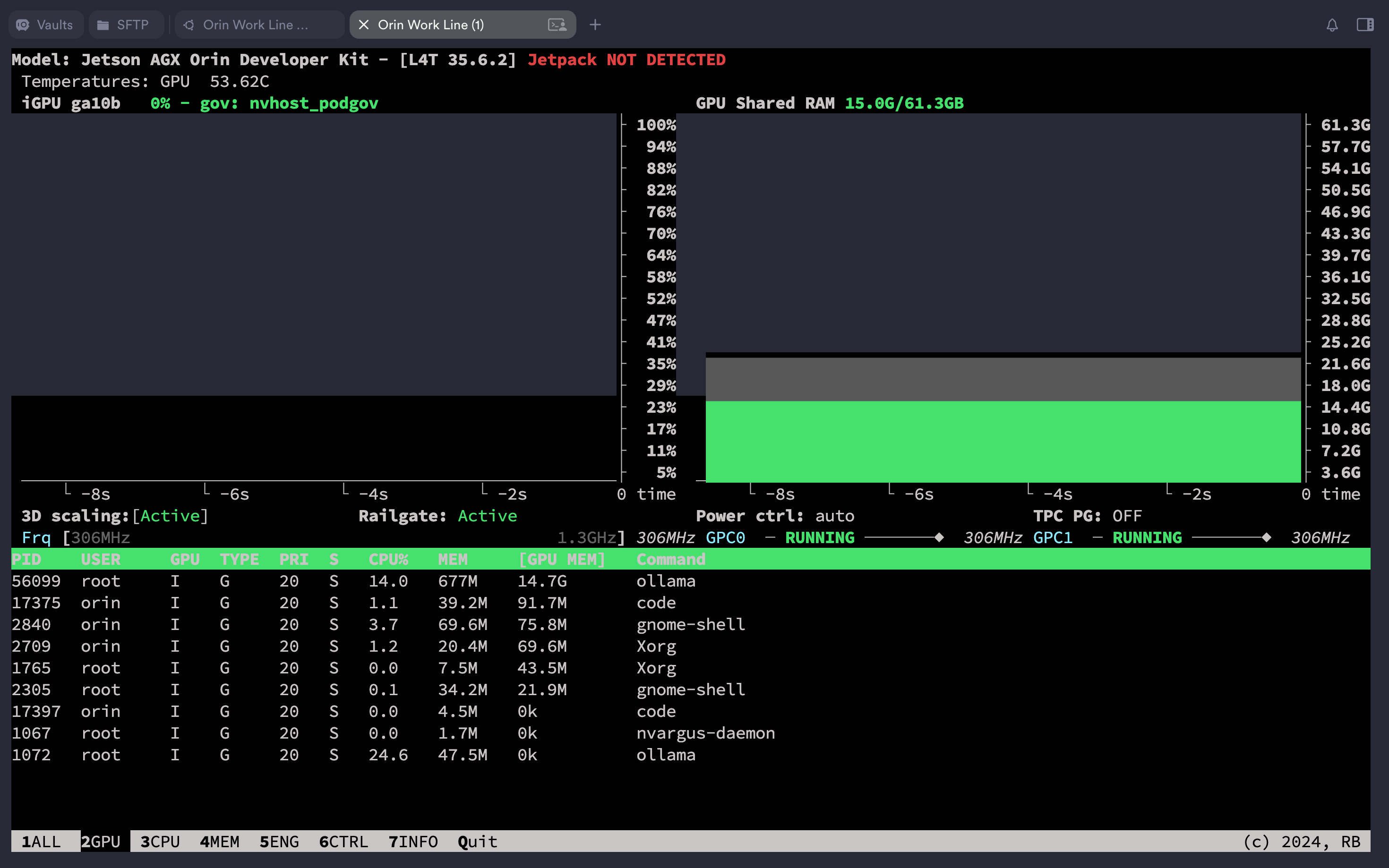
在确认模型已经加载后执行测试脚本:
(ollama) $ python benchmark.py

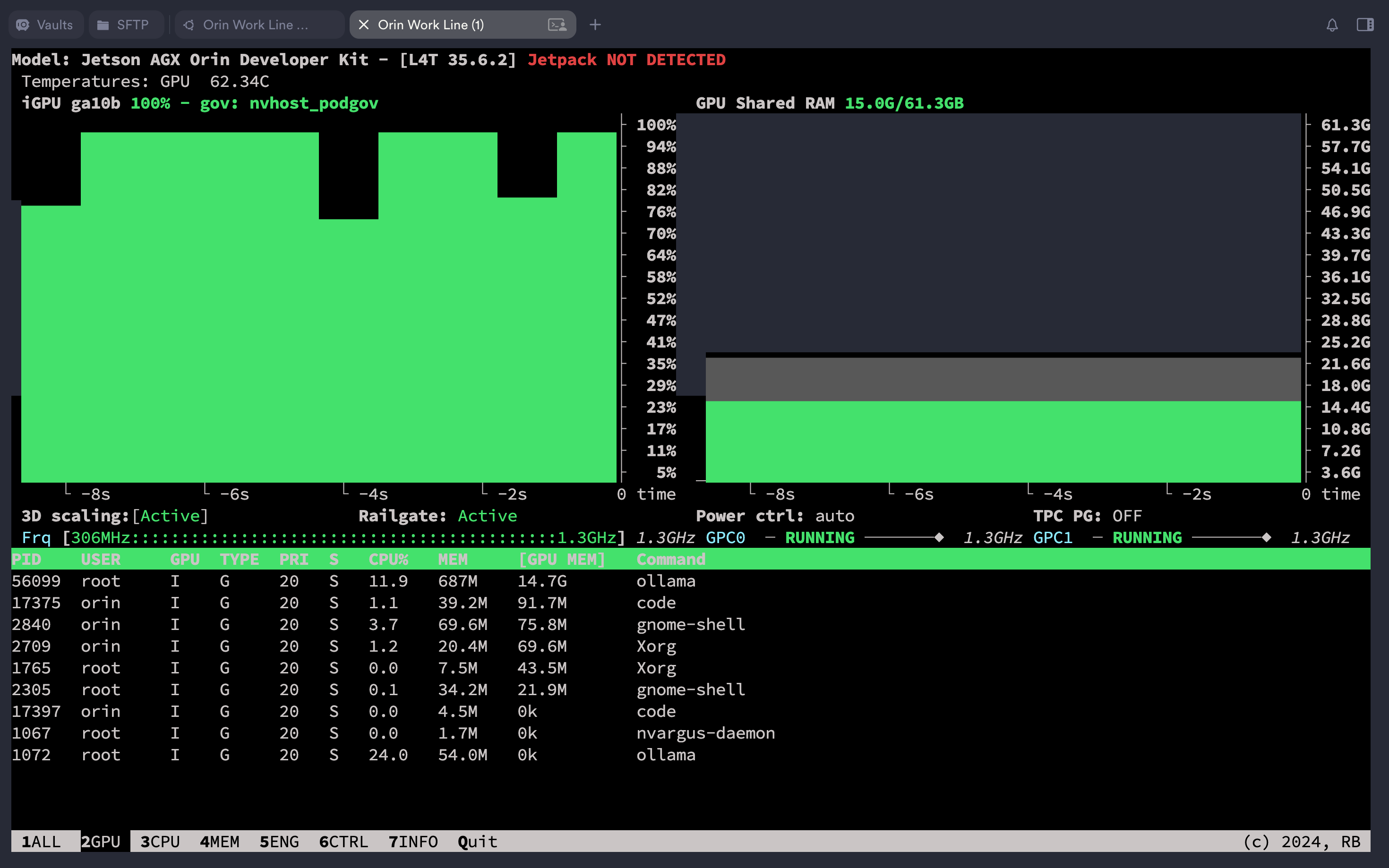
测试结果
单一模型测试
| 测试指标 | gpt-oss:20b | gemma3:27b | qwen3:30b |
|---|---|---|---|
| TTFT (首个Token生成时间) | 1.3572 秒 | 1.6511 秒 | 0.5238 秒 |
| E2E Latency (端到端延迟) | 215.4739 秒 | 165.4303 秒 | 170.5114 秒 |
| ITL (Token间延迟) | 86.2675 毫秒/token | 141.8144 毫秒/token | 43.1018 毫秒/token |
| TPS (每秒生成Token数) | 11.48 tokens/秒 | 6.99 tokens/秒 | 23.16 tokens/秒 |
横向评测
这部分选择了 qwen3:30b(19GB)和 gpt-oss:20b(14GB)进行了对比,询问了以下问题,并将两个模型回答结果发送给 Gemini 2.5 Pro在线模型进行打分(0~10分),同时要求给出理由:
为 Gemini 2.5 Pro 模型的系统提示词如下:
你是一个客观公正的大语言模型质量评判专家,我需要你你对多个本地模型输出的内容质量进行打分(0-10分)并给出理由,由于模型之间的参数量相当,因此他们的回答可能比较接近,你需要从更抽象层面出发进行评判。我将以文件的形式为你提供不同模型的回答。
- 问题一:
请用Python编写一个函数,该函数接收一个未排序的整数列表,并使用归并排序(Merge Sort)算法将其排序。请在代码中加入详细的注释,解释算法的关键步骤。
- 问题二:
假设有三个盒子,一个装满了金币,另外两个是空的。每个盒子上都贴着一张标签,分别写着“金币在这里”、“金币不在这里”、“金币在第二个盒子”。但你被告知,这三张标签全部都是错的。请问,金币到底在哪个盒子里?请详细说明你的推理过程。
- 问题三:
以“当最后一个星系的光芒熄灭时,宇宙的图书管理员合上了他的书。”为开头,写一个不超过500字的科幻短篇故事。
- 问题四:
请解释什么是“黑洞信息悖论”(Black Hole Information Paradox)?这个悖论的核心矛盾是什么?目前物理学界有哪些主流的理论或假说试图解决这个悖论?
- 问题五:
你现在是一位经验丰富的市场策略师。一家新兴的电动汽车公司准备进入竞争激烈的北美市场,他们的主要卖点是创新的电池技术和可持续的生产理念。请为这家公司制定一份市场进入策略(Go-to-Market Strategy),包括目标客户群体、品牌定位、营销渠道和关键的头三个月行动计划。
所有测试样本与评判结果都保存在了网盘中:
https://pan.baidu.com/s/14C2z23Ia0cqI5nwp4efI8w?pwd=6uit
Gemini 2.5 Pro 评判分结果如下:
| gpt-oss:20b - 13GB | gemma3:27b - 17GB | qwen3:30b - 18GB | |
|---|---|---|---|
| 问题一 | 9.7 | 8.0 | 9.2 |
| 问题二 | 9.5 | 7.5 | 3.0 |
| 问题三 | 9.8 | 8.6 | 6.5 |
| 问题四 | 9.8 | 7.8 | 8.5 |
| 问题五 | 9.6 | 7.2 | 8.8 |