1. 什么是套接字
在现在的英特网当中,传输层及以下的部分所采用的都是通用的优秀解决方案,无需我们这些普通程序员再去插足。
我们所做的无非就是在应用层上实践应用层协议,开发网络应用层协议。自然,与我们直接相关,也是我们在编程中主要使用的就是传输层提供的服务。
套接字就是操作系统为我们提供的,使用传输层服务的接口。
套接字(Socket)是计算机网络编程中用于实现不同设备或进程之间网络通信的一种抽象概念,它提供了一套标准化的接口,让应用程序能够通过网络发送和接收数据。
简单来说,套接字可以理解为网络通信的 "端点"—— 就像现实中电话的插口,两台设备要通过网络通信,就需要各自创建套接字,然后通过这些 "端点" 建立连接、传输数据。
因为套接字是传输层的接口,所以就需要我们提供端到端的地址,即 "IP地址+端口号"。一个完整的套接字标识由两部分组成:
- IP 地址:标识网络中具体的设备(如计算机、服务器);
- 端口号:标识设备上的具体应用程序(一个设备可以同时运行多个网络程序,端口号用于区分它们,范围通常是 0-65535)。
例如,192.168.1.1:8080 就表示 IP 为192.168.1.1的设备上,端口号为8080的套接字。
2. TCP和UDP
传输层有两套最为常用的协议:TCP协议(Transmission Control Protocol)和UDP协议(User Datagram Protocol)。
自然,套接字就有两种类型:基于TCP的流式套接字(SOCK_STREAM)和基于UDP的数据报套接字(SOCK_DGRAM)。
下面,我们将简要介绍这两种协议的特点与不同。
2.1 TCP协议
TCP 是一种面向连接、可靠、有序的传输协议,其设计核心是确保数据准确无误地到达目的地,类似现实中 "打电话"—— 需要先建立连接,再持续沟通,最后礼貌挂断。
核心特点:
- 面向连接:通信前必须通过 "三次握手" 建立连接,通信结束后通过 "四次挥手" 断开连接,确保双方状态同步。
- 三次握手:客户端请求连接→服务器确认→客户端回应,完成连接建立。
- 四次挥手:一方请求断开→另一方确认→另一方准备好断开→最终确认,完成连接关闭。
- 可靠性:通过多种机制保证数据不丢失、不重复、不乱序:
- 确认机制:接收方收到数据后必须返回确认(ACK),发送方未收到确认则重传。
- 序号与校验:每个数据段都有序号,接收方按序号重组;数据带校验和,可检测传输错误。
- 重传机制:发送方超时未收到确认,会重新发送数据。
- 流量控制:通过滑动窗口机制,控制发送速度,避免接收方处理不及导致数据溢出。
- 拥塞控制:检测网络拥堵时(如丢包),主动降低发送速度,避免网络瘫痪。
- 开销较大:连接建立 / 断开、确认、重传等机制会增加额外数据传输和延迟。
2.2 UDP协议
UDP 是一种无连接、不可靠、无序的传输协议,其设计核心是快速传输数据,类似现实中 "写信"—— 无需提前联系,直接发送,不保证对方一定收到,也不关心顺序。
核心特点:
- 无连接:通信前无需建立连接,发送方直接封装数据为 "数据报"(Datagram)发送,接收方收到后直接处理。
- 不可靠:没有确认、重传机制,数据可能丢失、重复或乱序,也没有流量控制和拥塞控制。
- 速度快、开销小:省去了连接管理和可靠性保障的额外操作,数据传输延迟低,适合对实时性要求高的场景。
- 数据报边界:UDP 会保留数据的边界(发送方一次发送的数据,接收方会完整接收),而 TCP 是流式传输(数据无边界,需应用层自行划分)。
2.3 区别对比
| 特性 | TCP | UDP |
| 连接性 | 面向连接(需建立 / 断开连接) | 无连接(直接发送) |
| 可靠性 | 可靠(不丢失、不重复、有序) | 不可靠(可能丢失、乱序) |
| 传输速度 | 较慢(因可靠性机制开销) | 较快(无额外开销) |
| 适用场景 | 需可靠传输的场景 | 需实时性 / 低延迟的场景 |
| 典型应用 | HTTP/HTTPS、FTP、邮件、文件传输 | 视频通话、直播、DNS、游戏 |
| 数据传输单位 | 字节流(无边界) | 数据报(有边界) |
| 拥塞 / 流量控制 | 支持 | 不支持 |
3. 网络字节序
网络字节序(Network Byte Order)是网络通信中统一规定的数据字节存储顺序标准,用于解决不同计算机因硬件架构差异导致的字节序不兼容问题。
不同计算机的字节序可能不同: 多数 PC(如 x86/x86_64 架构)采用小端字节序; 部分嵌入式设备、网络设备可能采用大端字节序。
如果直接将主机的本地字节序数据通过网络传输,接收方会因字节序不同而解析出错误数据(例如发送方的 0x1234 可能被接收方解读为 0x3412)。
因此,TCP/IP 协议规定:所有网络传输的数据必须使用统一的字节序 —— 大端字节序,这就是 "网络字节序"。
在网络编程中,需要通过标准函数在主机字节序(Host Byte Order) 和网络字节序(Network Byte Order) 之间转换。
以 C 语言为例,常用转换函数(定义在 <arpa/inet.h> 中):
- htons():host to network short(16 位整数,主机序→网络序)
- htonl():host to network long(32 位整数,主机序→网络序)
- ntohs():network to host short(16 位整数,网络序→主机序)
- ntohl():network to host long(32 位整数,网络序→主机序)
4. Socket API介绍
在 Linux 系统中,Socket API 是一套用于网络编程的系统调用接口,基于 TCP/IP 协议栈,允许应用程序通过网络与其他设备或进程通信。它抽象了底层网络细节,提供了统一的接口用于创建、连接、传输和关闭网络连接。
4.1 核心数据结构
在使用 Socket API 时,需要用到一些关键的数据结构来描述网络地址和套接字属性: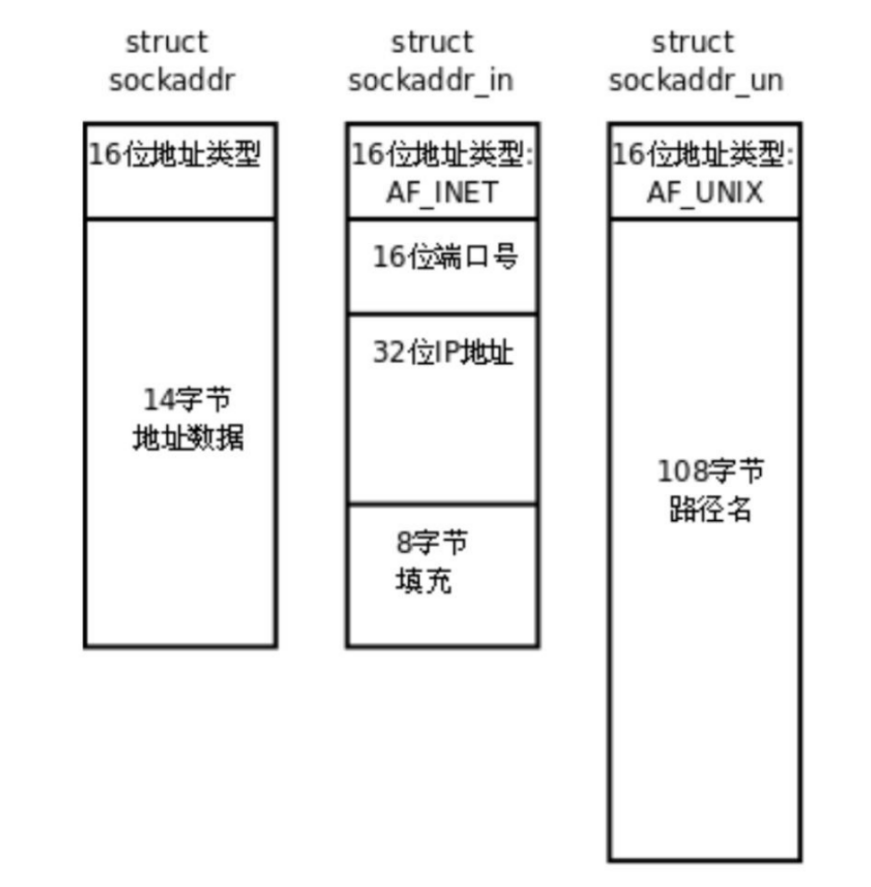
- struct sockaddr:通用地址结构(抽象基类),用于兼容不同协议族(如 IPv4、IPv6)。Socket API接口要求传入地址信息和套接字属性时,就是以[struct sockaddr*]的方式传入(将另外两种类型对象的指针强转为该类型的指针):
struct sockaddr { sa_family_t sa_family; // 地址族(如AF_INET表示IPv4) char sa_data[14]; // 地址数据(具体内容因协议族而异) }; - struct sockaddr_in:IPv4 专用地址结构(更常用),定义在<sys/in.h>:
struct sockaddr_in { sa_family_t sin_family; // 地址族(必须为AF_INET) in_port_t sin_port; // 端口号(需转换为网络字节序) struct in_addr sin_addr; // IPv4地址(需转换为网络字节序) unsigned char sin_zero[8]; // 填充字段(通常设为0) }; struct in_addr { uint32_t s_addr; // IPv4地址(32位无符号整数) }; - struct sockaddr_un:IPv6 专用地址结构,定义在 <sys/un.h>:
struct sockaddr_un { sa_family_t sun_family; // 地址族,必须为 AF_UNIX 或 AF_LOCAL char sun_path[108]; // UNIX 域套接字的路径名(以 null 结尾) };
详细接口的介绍: