- 作者:Xuan Yao1,2^{1,2}1,2, Junyu Gao1,2^{1,2}1,2, Changsheng Xu1,2,3^{1,2,3}1,2,3
- 单位:1^{1}1中科院自动化所多模态人工智能系统国家重点实验室,2^{2}2中国科学院大学人工智能学院,3^{3}3鹏城实验室
- 论文标题:NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments
- 论文链接:https://arxiv.org/pdf/2506.23468
- 代码链接:https://github.com/Feliciaxyao/NavMorph
主要贡献
- 提出了自演化世界模型框架 NavMorph,能够自适应地建模连续环境的潜在表示,从而实现基于预见的决策制定和在线导航中的适应性。
- 设计了世界感知导航器和预见行动规划器,并将其与上下文演化记忆无缝整合,以积累导航见解,实现合理且动态的行动规划。
- 在典型的 VLN-CE基准测试中进行了广泛的实验,结果表明 NavMorph 显著提升了多个模型的性能,验证了其在适应性和泛化能力方面的改进。
研究背景
- 近年来,具身智能(Embodied AI)作为一个跨学科的研究方向,吸引了计算机视觉、自然语言处理和机器人学等领域的广泛关注。其中,视觉语言导航(VLN)任务因其在现实世界中的广泛应用前景而备受关注,例如机器人辅助、自主导航和智能家居系统等。
- VLN 任务要求智能体能够解释自然语言指令,在动态环境中处理视觉信息,并执行一系列动作以到达目标位置。然而,现有的方法在泛化到新环境和适应导航过程中的持续变化方面存在挑战。
- 为了解决这些问题,研究者们受到人类认知能力的启发,提出了世界模型的概念,通过模拟动作及其对世界状态的影响来显式建模环境动态。尽管已有研究展示了世界模型在导航中的潜力,但在 VLN 中的应用仍处于探索阶段,尤其是在处理连续空间和动态环境适应性方面。
研究方法
任务定义
- VLN-CE(连续环境中的视觉语言导航)任务利用 Habitat Simulator 渲染 Matterport3D 数据集的环境观测,为智能体提供 RGB-D 视觉输入。
- 每个导航任务(episode)开始时,智能体接收指令和初始视觉观测,任务结束条件是智能体选择“停止”动作或达到最大步数限制。
- 智能体在每个时间步预测导航路径上的点,这些点随后被转换为低层次的控制动作。观测序列 o1:to_{1:t}o1:t 表示从初始时刻到当前时刻 ttt 的所有观测,而 a1:t−1a_{1:t-1}a1:t−1 表示到 t−1t-1t−1 时刻的所有导航动作。
框架概述

NavMorph 模型旨在通过在结构化的潜在空间中学习和适应连续环境的时空动态,从而在在线测试期间促进有效的推理和行动规划。该框架由两个主要组件构成:
- 世界感知导航器(World-Aware Navigator,推理网络):负责从历史上下文和当前观测中推断环境动态,并在潜在空间中构建环境表示。
- 预见行动规划器(Foresight Action Planner,预测网络):利用潜在表示来预测未来状态,从而促进有效的策略学习和战略导航。
世界感知导航器
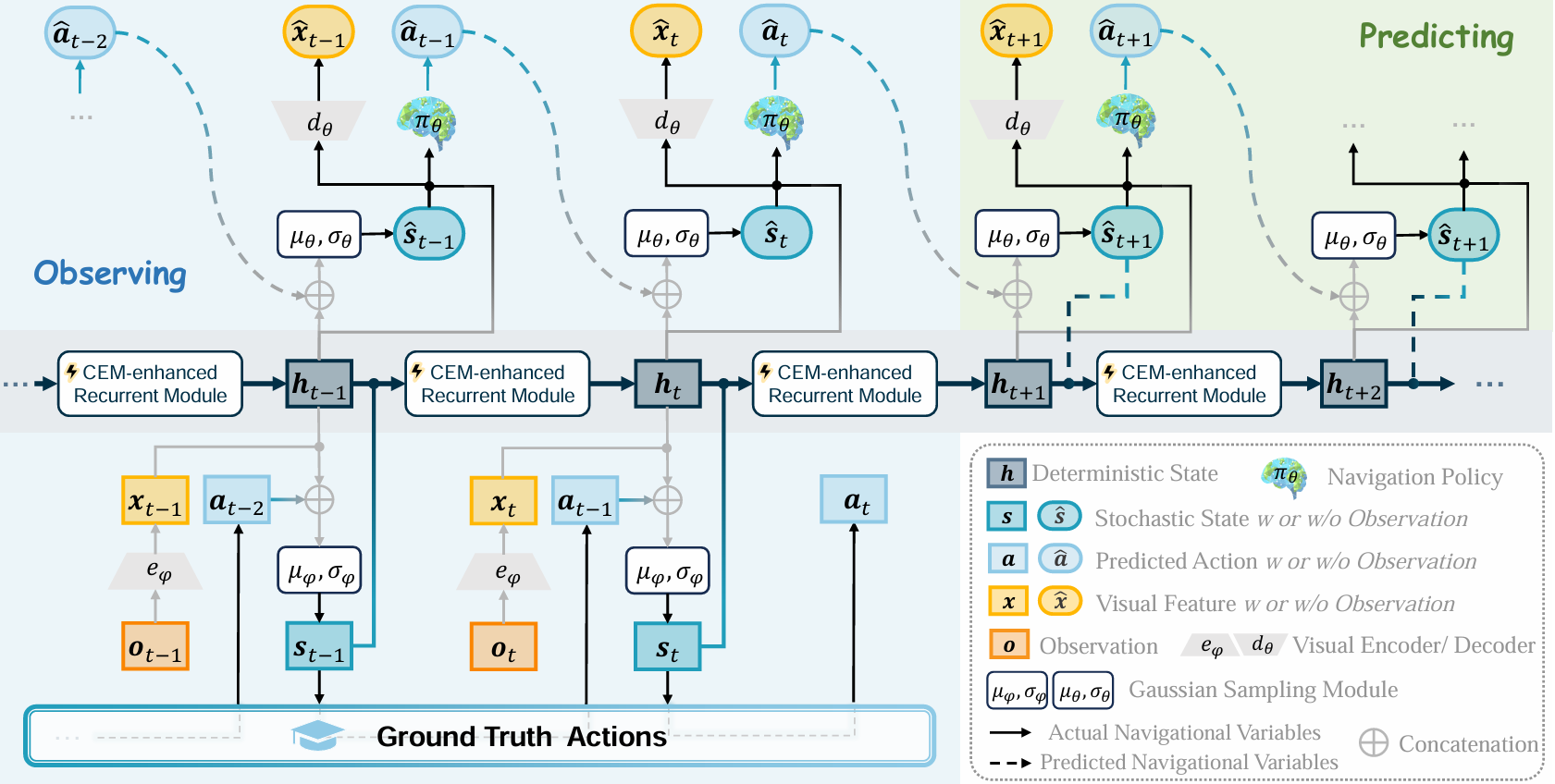
该部分是基于 RSSM(Recurrent State-Space Model)的策略型智能体,旨在将跨模态输入映射到一系列动作上。具体步骤如下:
- 视觉表示:使用视觉编码器 eϕe_{\phi}eϕ 处理观测 oto_tot,得到视觉特征 xtx_txt。
- 初始潜在确定性状态:h1h_1h1 从零初始化。
- 递归模型:将前一时刻的确定性状态 ht−1h_{t-1}ht−1 和随机状态 st−1s_{t-1}st−1 输入到递归模块 fff,得到当前时刻的确定性状态 hth_tht。
- 动态转换模型:根据历史观测和动作,推断当前时刻的随机状态 sts_tst,遵循高斯分布 qϕ(st∣o1:t,a1:t−1)q_{\phi}(s_t|o_{1:t},a_{1:t-1})qϕ(st∣o1:t,a1:t−1)。
此外,为了增强智能体保留和利用历史导航见解的能力,引入了上下文演化记忆(CEM)。CEM 维护一系列场景上下文特征,通过动态更新这些特征,使模型能够适应新场景,同时保留关键的视觉语义信息。具体来说:
- CEM 的增强机制:在训练和在线测试过程中,CEM 通过前馈更新机制动态整合场景上下文信息,而不是依赖于基于梯度的反向传播。这种机制确保了模型能够快速适应新环境,同时保持对过去经验的利用。
- CEM 的更新过程:通过计算当前状态与记忆中特征的相似度,选择最相关的特征进行更新,从而在保留关键信息的同时,避免了过时信息的干扰。
预见行动规划器
该部分赋予智能体预测环境变化的能力,基于世界感知导航器学到的潜在状态表示,通过在潜在空间中想象潜在场景来执行未来规划。具体步骤如下:
- 初始潜在随机状态:s1s_1s1 从标准正态分布初始化。
- 随机状态模型:根据当前的确定性状态和前一时刻的随机状态,预测下一时刻的随机状态 s^t\hat{s}_ts^t,遵循高斯分布 pθ(s^t∣ht,s^t−1)p_{\theta}(\hat{s}_t|h_t,\hat{s}_{t-1})pθ(s^t∣ht,s^t−1)。
- 视觉解码器:将预测的随机状态 s^t\hat{s}_ts^t 转换为预测的视觉嵌入 x^t\hat{x}_tx^t,为行动预测提供丰富的语义信息。
- 行动解码器:根据预测的视觉嵌入和确定性状态,预测下一时刻的行动 a^t\hat{a}_ta^t。
此外,为了增强模型对未来状态的预测能力,引入了一个重建任务,通过视觉解码器 dθd_{\theta}dθ 重建输入观测的视觉嵌入,而不是直接进行像素级别的图像重建。这种重建目标有助于模型学习有用的潜在表示,并提高规划的准确性。
预训练目标
NavMorph 通过最大化数据对数似然的变分下界来训练,涉及最小化视觉重建损失、动作预测损失以及后验和先验状态分布之间的散度。具体来说:
- 损失函数 LWL_WLW:包括过去和未来状态的视觉重建损失、动作预测损失,以及后验和先验分布之间的 Kullback-Leibler(KL)散度损失。
- 正则化项:为了确保预测的导航轨迹与实际轨迹的时间一致性和对齐,引入了基于归一化动态时间规整(NDTW)的正则化项。
- 完整损失函数:将世界模型损失 LWL_WLW 与模仿学习目标 LILL_{IL}LIL 结合,形成完整的损失函数 L=LW+LILL = L_W + L_{IL}L=LW+LIL。
工作模式
NavMorph 在训练和测试阶段以两种不同的模式运行:
- 训练阶段:模型通过未来状态预测来学习环境的潜在动态,处理观测序列和相应的动作,通过优化损失函数来更新模型参数。
- 测试阶段:自演化世界模型通过演化机制持续适应环境变化。递归模块在测试过程中以在线方式更新 CEM,使模型能够保留最近观测的有用信息,同时调整对测试场景的理解,从而保持对周围环境的丰富且最新的理解。
实验
实验设置
数据集
- R2R-CE:包含5,611条最短路径轨迹,分为训练、验证和测试集。每条轨迹配有约3条英文指令,平均路径长度为9.89米,指令长度为32词。该数据集中的智能体具有0.10米的底盘半径,可在导航时沿障碍物滑动。
- RxR-CE:规模更大且更具挑战性,提供多种语言(英语、印地语和泰卢固语)的指令,平均指令长度为120词。智能体的底盘半径为0.18米,不能沿障碍物滑动,因此更容易发生碰撞。
评估指标
采用标准的VLN-CE评估指标,包括轨迹长度(TL)、导航误差(NE)、成功率(SR)、路径长度加权成功率(SPL)、归一化动态时间规整(NDTW)和成功加权NDTW(SDTW)。
实现细节
- 对于全景设置,每个位置由12个RGB-D图像表示,每30度拍摄一次。
- 在单目设置中,采用VLN-3DFF模型,利用预训练的3D特征场模型进行部署。
- 所有实验均使用PyTorch框架在单个NVIDIA RTX 3090 GPU上进行。
与最新VLN模型的比较
R2R-CE 数据集
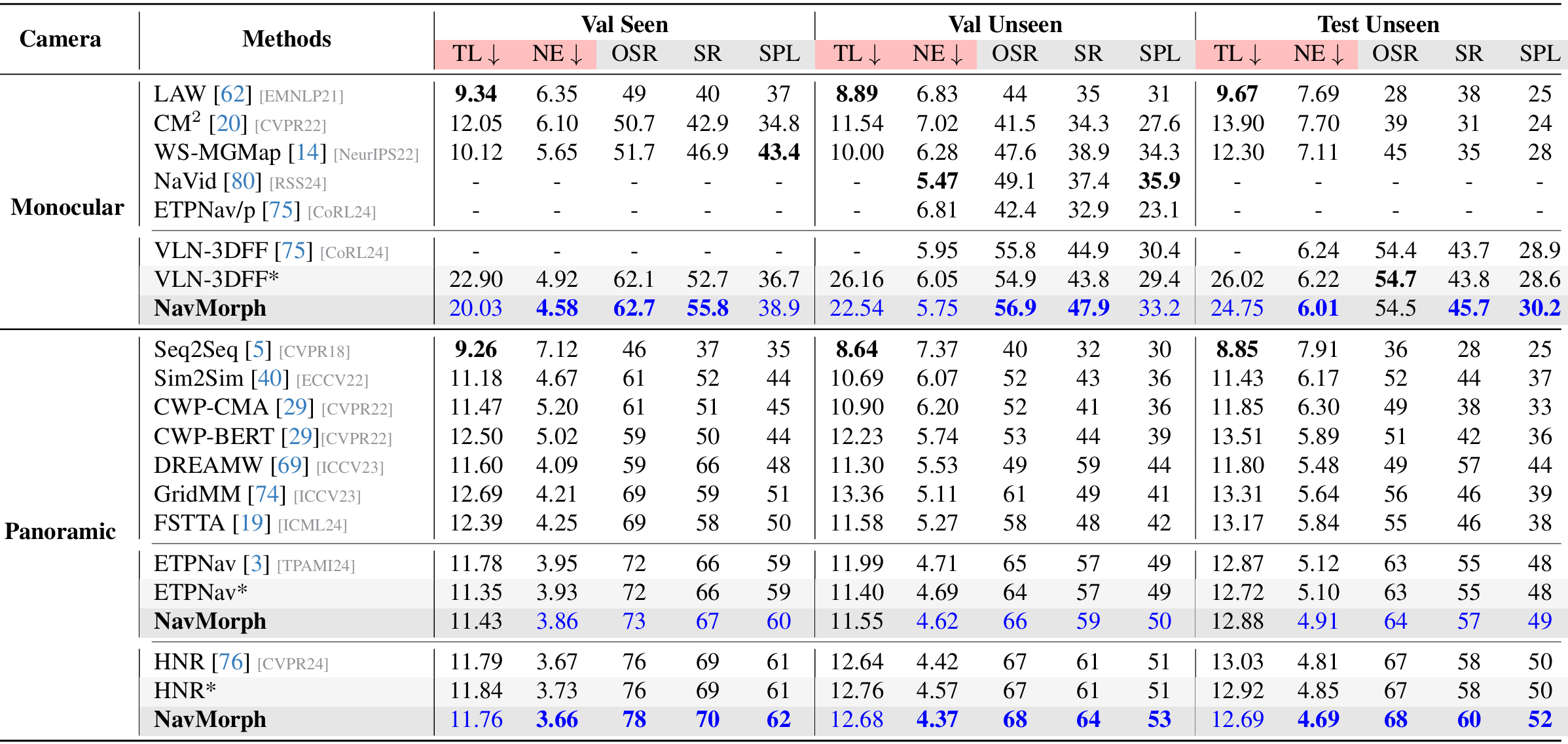
- 单目设置:NavMorph在多个指标上优于其他单目方法,尤其在未见环境中表现突出。例如,在Val Unseen分割上,NavMorph的SR和SPL分别比基线VLN-3DFF提高了超过4%。在Test Unseen分割上,NavMorph的SPL比VLN-3DFF提高了1.6%,SR提高了约2%。
- 全景设置:NavMorph在全景设置中也表现出色,与ETPNav和HNR等专门的全景方法相比具有竞争力。例如,在Test Unseen分割上,NavMorph的SPL为62,SR为70%,表现优异。
RxR-CE 数据集
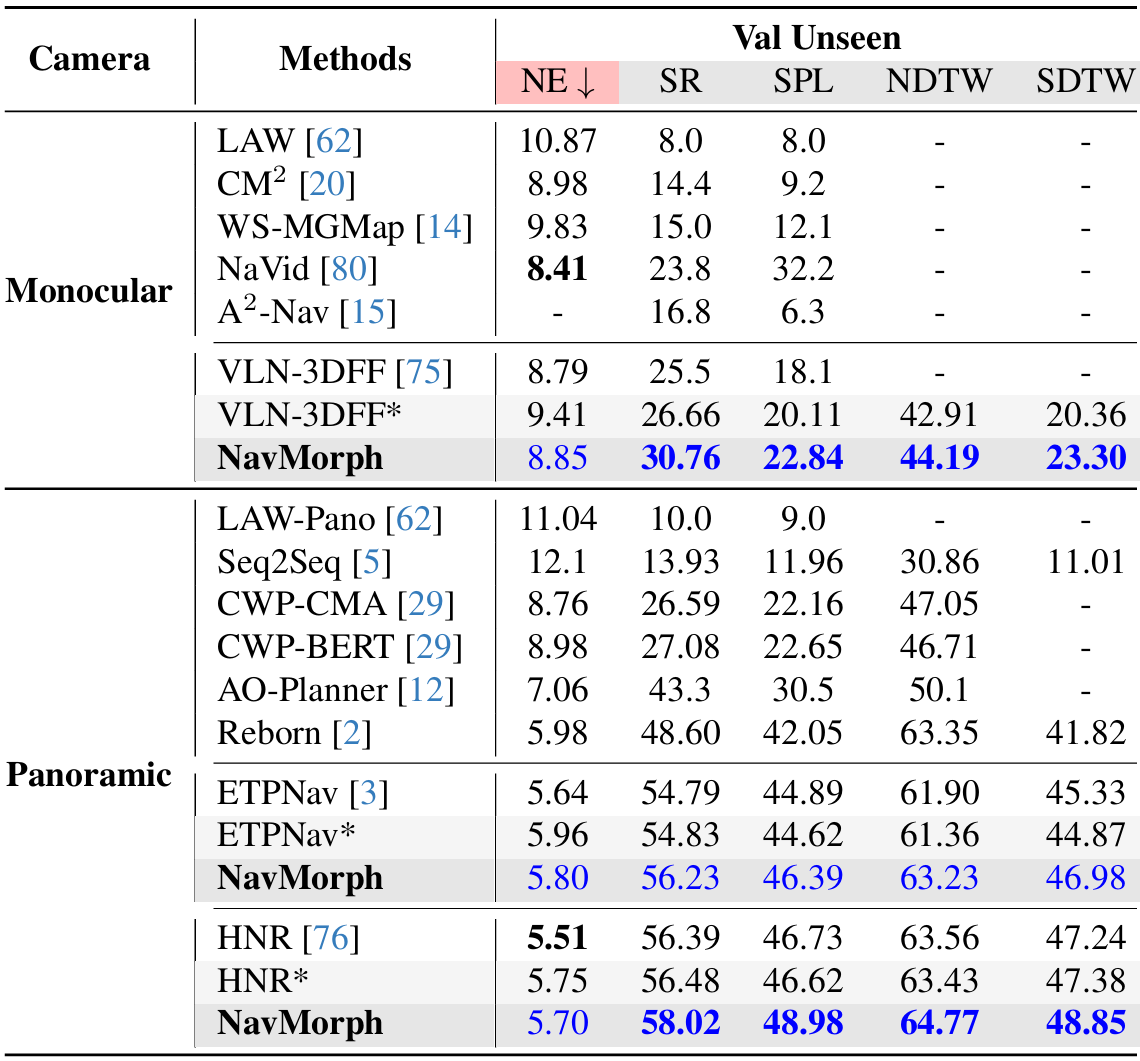
- 单目设置:NavMorph在单目设置中显著优于之前的最佳方法VLN-3DFF,SR提高了4.1%,SPL提高了2.73%。此外,在NDTW和SDTW指标上也表现出色,分别达到64.77和48.85,表明NavMorph能够忠实地遵循指令并保持路径保真度。
- 全景设置:NavMorph在全景设置中也表现出色,SR为58.02%,SPL为48.98%,与ETPNav和HNR等方法相当。
消融研究与进一步分析
世界模型的消融研究
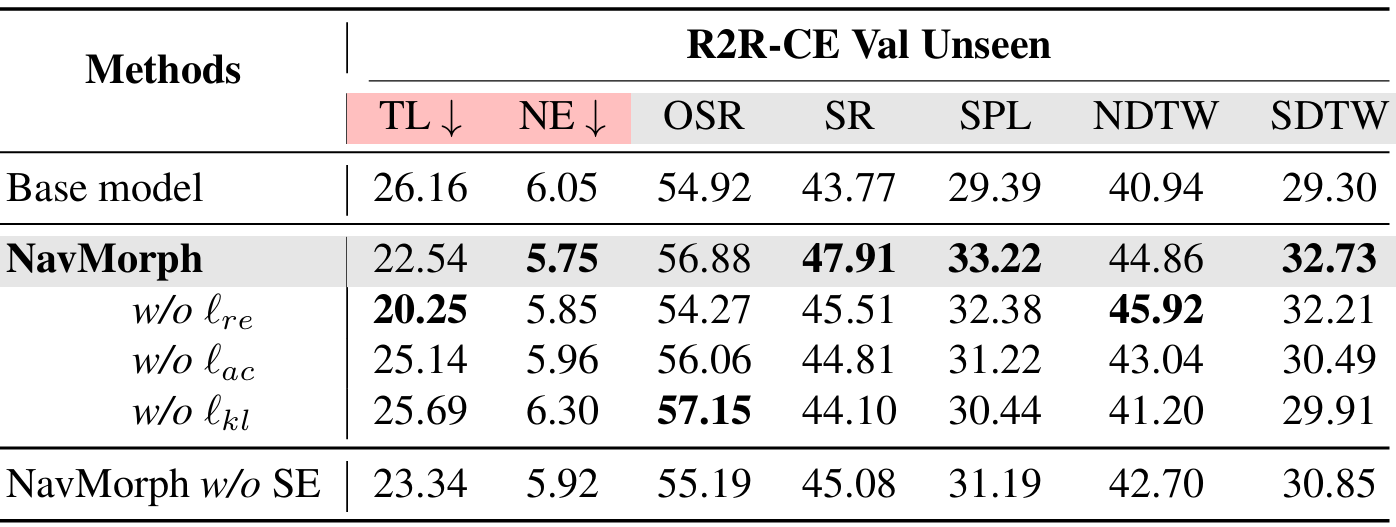
- 移除个别损失项会导致性能适度下降,这强调了这些损失项在捕捉世界模型潜在动态中的集体重要性。例如,移除视觉嵌入重建损失 ℓre\ell_{re}ℓre 会导致路径长度缩短(22.54→20.25)和OSR降低(56.88%→54.27%),这突出了视觉一致性在维持周围环境时间稳定表示中的作用。同样,省略动作预测损失 ℓac\ell_{ac}ℓac 会降低多个指标,因为对预测动作序列的约束支持有效的策略学习。
- 此外,后验和先验分布之间的一致性对于维持学习到的潜在动态与实际导航场景之间的一致性至关重要,确保潜在表示的校准良好。
- 为了更好地评估自演化的贡献,评估了不进行自演化的NavMorph(记为NavMorph w/o SE),结果表明,即使没有自演化,世界模型架构本身也能带来显著的性能提升,而CEM支持的自演化进一步增强了导航效果。
CEM的消融研究
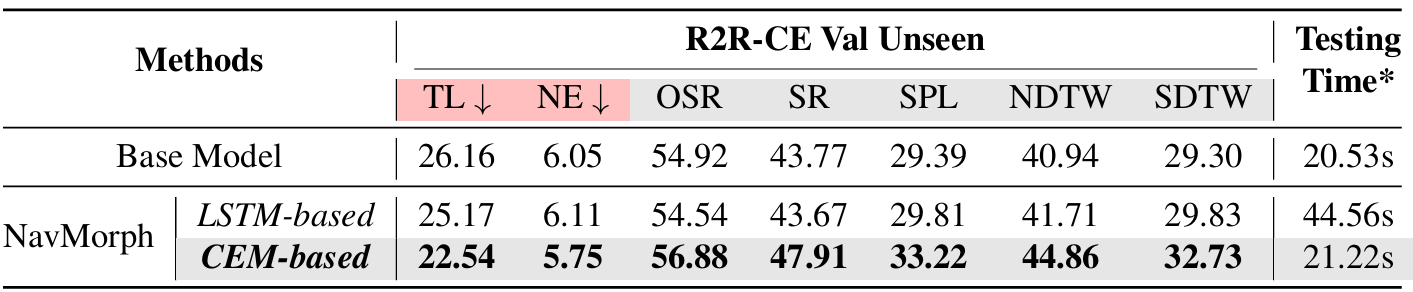
- CEM作为自演化的核心模块,使智能体能够保留和提炼历史场景信息,以提高导航任务中的适应性。与依赖于梯度反向传播进行在线测试适应的传统循环架构(例如RNN、LSTM)不同,CEM采用前馈迭代更新机制,能够高效地整合新观测,而无需承担过多的计算成本。
- 通过在相同的评估设置下进行消融研究,比较基于CEM的自演化机制与基于LSTM的替代方案。结果表明,基于CEM的NavMorph在所有关键指标上均优于基于LSTM的方法,这表明CEM在未见环境中具有更强的适应性。值得注意的是,尽管两种方法都通过自演化提高了泛化能力,但基于LSTM的方法由于依赖于梯度优化,在测试时的计算成本增加了2.1倍。
上下文演化记忆的大小
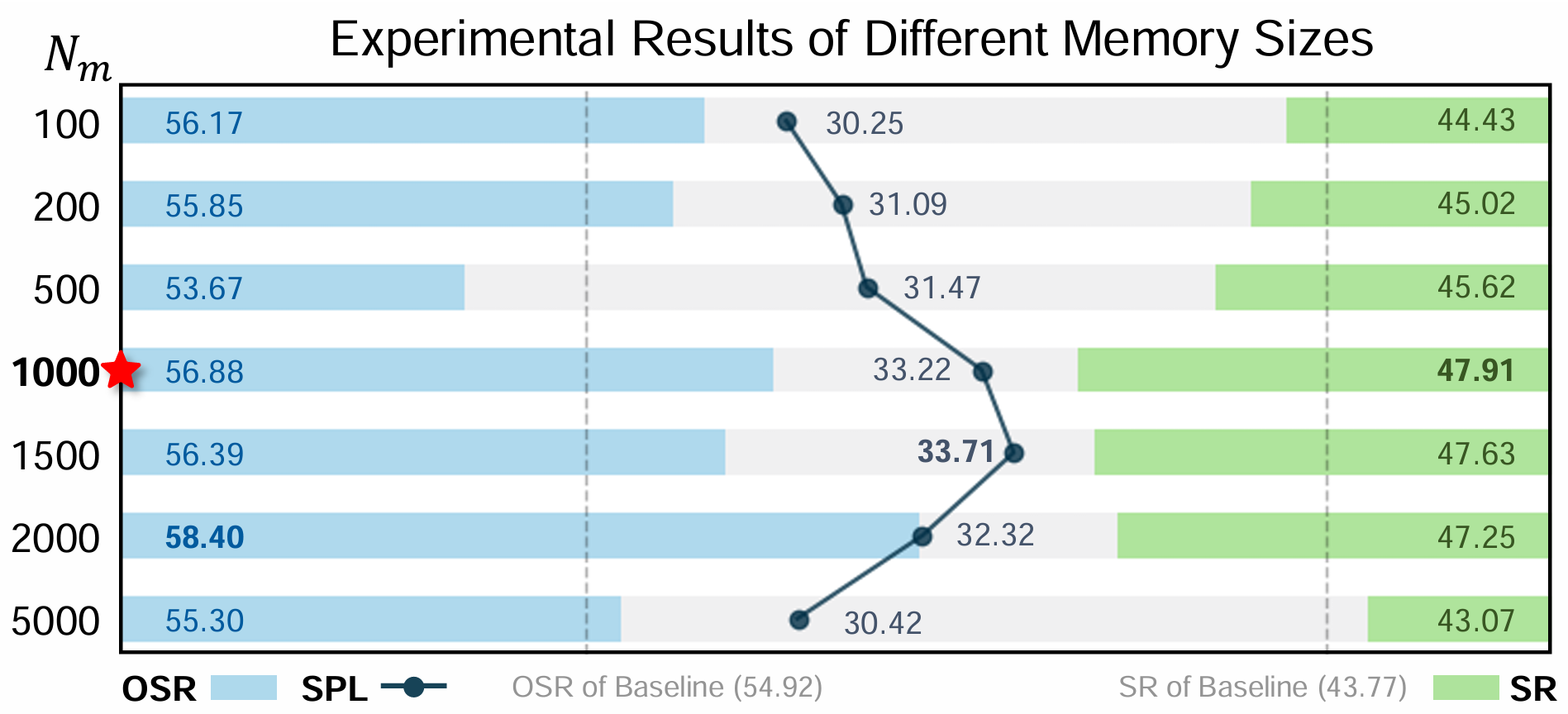
- 通过改变CEM中的记忆大小 NmN_mNm 进行了全面的消融研究。结果表明,当 Nm=1000N_m = 1000Nm=1000 时,模型达到了最佳性能,SR达到47.91%,OSR达到56.88%,SPL达到33.22%。较小或较大的记忆大小都会导致性能下降。
- 这表明,记忆容量不足会限制模型存储关键上下文信息的能力,而过大的记忆可能会引入噪声和冗余,从而干扰有效的决策制定。实验结果验证了在CEM中设置1000的记忆大小是上下文保留和适应性之间的最佳平衡,增强了智能体的导航鲁棒性。
与最新在线VLN方法的比较

- NavMorph的自演化世界模型在在线测试时会积累来自测试环境的场景特定信息,并将其存储为记忆信息。尽管这种记忆机制在测试样本的地面真实动作不可用的情况下运行,但它可能会引发关于评估公平性的担忧。然而,最近的研究已经建立了在线测试时适应在VLN任务中的实际意义,证明了其在现实世界部署中的价值,因为智能体必须不断适应新环境。
- 与基于梯度的测试时适应方法FSTTA相比,NavMorph在导航准确性和效率方面均显著优于FSTTA。此外,消融研究结果也表明,NavMorph能够有效地利用积累的信息进行高效适应,同时保持稳健的性能。
结论与未来工作
- 结论:
- NavMorph 通过其自演化世界模型框架,在连续环境中的视觉语言导航任务中实现了显著的性能提升。
- 该模型通过建模环境动态并利用上下文演化记忆,有效地适应了新环境,提高了导航的准确性和效率。
- 未来工作:
- 尽管 NavMorph 在 VLN-CE 任务中取得了良好的效果,但仍存在一些挑战和改进方向。
- 例如,设计一个直接从真实环境中学习的导航奖励函数,以更好地平衡任务目标与环境约束,从而增强长期决策能力。
- 此外,开发一个具有标准化组件的模块化世界模型框架,将有助于通过系统化的模块抽象来灵活组合和演化智能体的能力。
