
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨
前面我们已经学习了系统的前置知识【冯诺依曼模型/操作系统】,这一篇博客我们开始系统的核心解析——进程!准备好了吗~我们发车去探索进程的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
进程概念😍
通俗概念:执行中的程序😝
一般教材里面对于进程是这样定义的——“运行起来的程序,加载到内存的程序”; “程序的一个执行实例,正在执行的程序”~
这是最直观的理解。一个安静的、躺在磁盘上的可执行文件(如 a.out)只是一个程序(Program)。而当你双击运行它,系统将其代码和数据加载到内存并开始执行时,它就成为了一个进程(Process)。
关键区别: 程序是静态的(就像一本食谱),而进程是动态的(就像你按照食谱做饭的整个过程)。
内核观点:系统资源的分配实体😄
从内核来看,进程是“担当分配系统资源(CPU时间,内存)的实体。”
这是操作系统的视角,操作系统对下的主要工作是管理软硬件资源,而进程就是操作系统进行资源分配的基本单位。每个进程在运行时,都需要被分配内存来存放其代码和数据,需要占用CPU时间来执行指令,操作系统就像一个经理,而进程就是需要资源来完成工作的员工。
我们上一篇博客提到操作系统进行管理的时候是先描述再组织~那么对于大量进程的管理也是一样的~
核心本质:PCB(进程控制块)😜
操作系统如何管理这么多复杂的进程?答案就是:“先描述,再组织”。
先描述(Describe): 操作系统为每一个进程创建一个名为PCB【进程控制块】(Process Control Block) 的数据结构(在Linux中具体叫 task_struct)。这个结构体就像是进程的“简历”或“身份证”,包含了进程的所有属性信息,例如:
进程ID(PID): 唯一标识一个进程的数字。
进程状态(运行、睡眠、停止等)。
程序计数器(PC): 指向下一条要执行的指令地址。
内存指针: 指向代码和数据的地址。
文件描述符表: 记录该进程打开的文件。
优先级、上下文数据等。
再组织(Organize): 操作系统将所有进程的PCB(task_struct)通过链表等数据结构组织起来。这样,对进程的管理(如创建、销毁、调度、切换)就变成了对这条PCB链表的增删改查操作。
因此,一个进程的实体 = 对应的代码和数据 + 对应的PCB数据结构。
进程排队与调度😎
由前面的概念我们可以知道,进程排队本质其实就是让对应的PCB节点进行排队。CPU的数量是远少于进程的数量,因此进程需要排队等待CPU资源。进程排队不是整个程序本身去排队,而是它的PCB去排队。操作系统调度器只关心PCB链表,它从运行队列中选中一个PCB,也就找到了这个进程的所有信息,从而能够恢复并执行它~
总结:进程是正在执行的程序,它是操作系统进行资源分配的基本单位,一个进程的实体 = 对应的代码和数据 + 对应的PCB数据结构。操作系统通过一个叫做PCB(Linux中为
task_struct)的数据结构来描述进程,并通过管理所有PCB组成的链表来高效地组织和管理所有进程。
task_struct😘
前面我们提到了操作系统为每一个进程创建一个名为PCB【进程控制块】(Process Control Block) 的数据结构(在Linux中具体叫 task_struct),包含了进程的所有属性信息。那么我们来看看Linux中task_struct具体会包含些什么呢?
标示符(PID)
作用:每个进程独一无二的身份证号。
说明:通过这个ID,系统内核和用户(通过命令)才能精确地找到并操作某一个特定的进程。
状态
作用:描述进程当前的生命周期状态(如:运行中、睡眠中、停止、僵尸状态等)。
说明:这是进程调度的关键依据。操作系统根据状态决定是否给这个进程分配CPU资源。
优先级
作用:决定进程获取CPU资源执行的先后顺序。
说明:优先级高的进程会更容易被CPU调度,从而获得更多的执行时间。
程序计数器
作用:保存着这个进程即将要执行的下一条指令的内存地址。
说明:当进程被CPU切换出去又切换回来时【调度切换】,就靠这个值来恢复到上次的执行现场,继续运行。
内存指针
作用:指向该进程的代码、数据以及与其他进程共享的内存区域。
说明:这些指针定义了进程在内存中的“地盘”,确保了进程能正确地访问自己的指令和数据。
上下文数据
作用:保存进程在CPU寄存器中的数据(当进程被切换出CPU时)。
说明:这是实现进程切换的核心。进程被换下CPU前,必须把当前所有寄存器的值保存到它的task_struct中;当它再次被调度时,再把这些值重新加载到寄存器,就能毫不停顿地继续执行。就像大学生参军入伍需要办理休学把学习进度都记录下来,回来时才能接着学~
I/O状态信息
作用:记录进程占用的I/O设备、发出的I/O请求以及打开的文件列表。
说明:用于管理进程的所有输入输出操作,确保资源被正确分配和释放。
记账信息
作用:统计进程使用的CPU时间、资源情况等。
说明:用于系统监控、性能分析和计费。
其他信息(后续博客会继续介绍)
查看进程😁
通过前面我们知道了什么是进程?现在我们来看看查看进程~首先我们了解一下getpid() 和 getppid()这两个在 Linux/Unix 系统编程中用于获取进程标识符(Process ID)的基础函数~
| 特性 | getpid() |
getppid() |
|---|---|---|
| 功能 | 获取当前进程的 PID | 获取当前进程的父进程的 PID |
| 头文件 | #include <unistd.h> |
#include <unistd.h> |
| 返回值 | pid_t(当前进程的 PID) |
pid_t(父进程的 PID) |
| 关键点 | 唯一标识一个进程 | 可能变化(如果父进程先结束) |
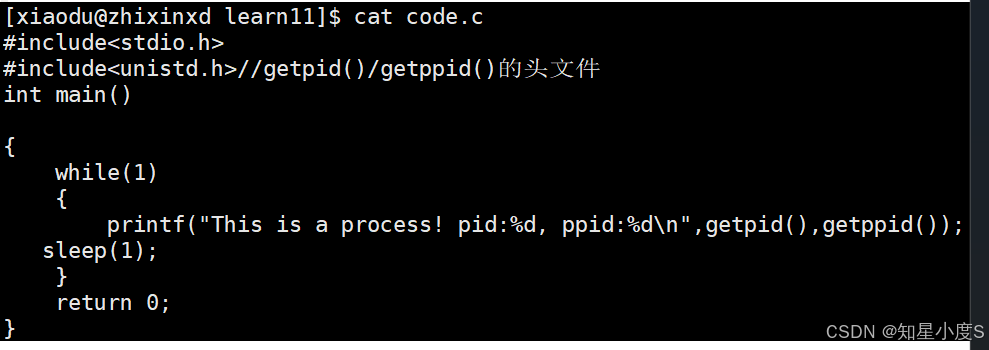
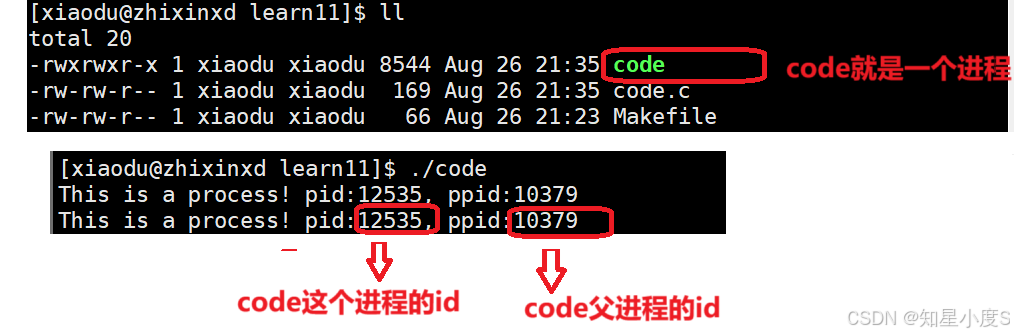
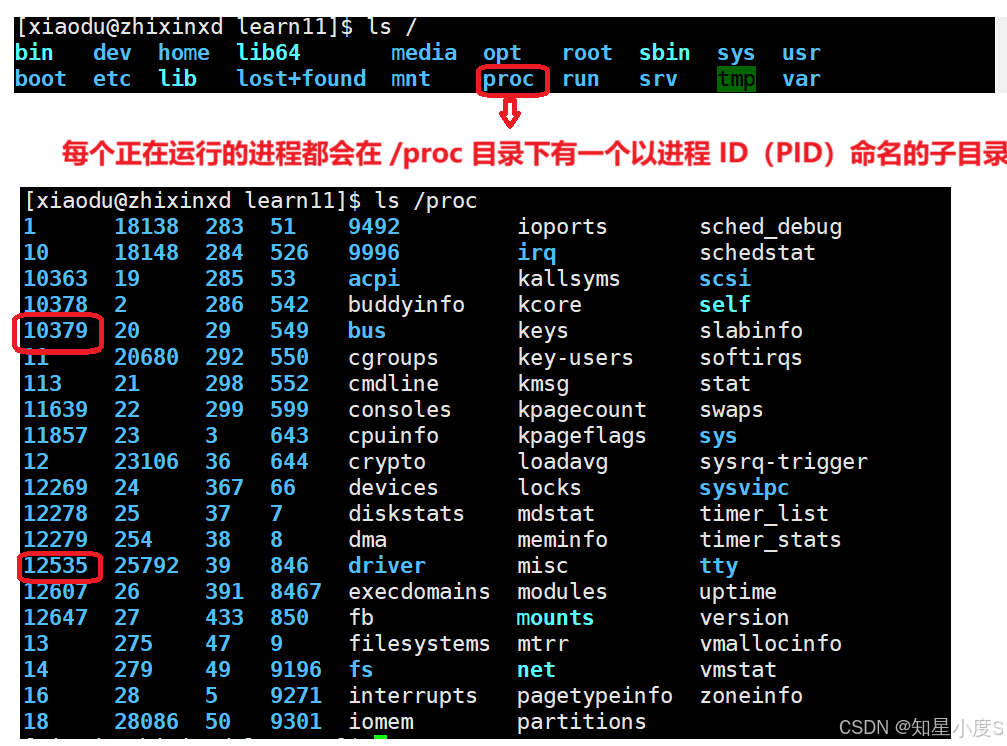
📌 通过
/proc文件系统查看进程信息在 Linux 中,每个正在运行的进程都会在
/proc目录下有一个以进程 ID(PID)命名的子目录,其中包含该进程的详细信息。
除此之外,我们一般还会使用ps 命令用法,用于查看与特定关键词相关的进程信息~
📌 命令行输入
ps ajx | head -1 ; ps ajx | grep "code"这个命令实际上由两个独立命令组成,用分号 ; 分隔:
ps ajx | head -1
ps ajx: 使用 BSD 风格的选项显示详细的进程信息
a: 显示所有用户的进程
j: 显示作业格式(包含 PGID、SID 等信息)
x: 显示没有控制终端的进程
| head -1: 只保留输出结果的第一行(即标题行)
ps ajx | grep "code"
再次运行 ps ajx 获取所有进程信息
使用 grep "code" 过滤出包含 "code" 字符串的进程
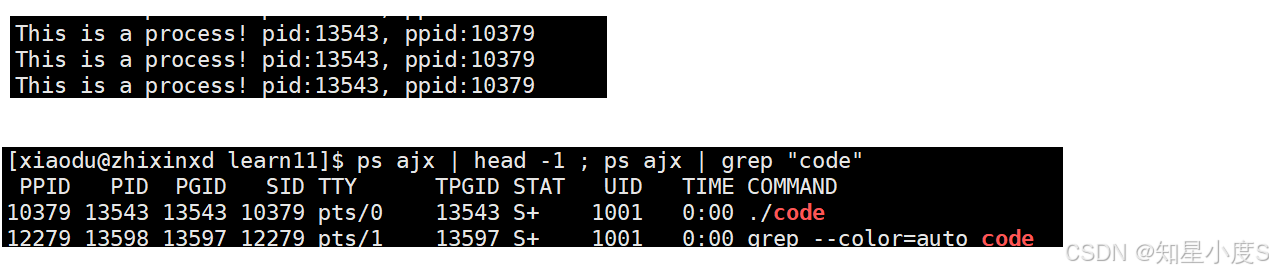
命令执行后显示了两部分结果:
标题行(来自第一个命令):
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND对于各列的含义,我们先简单了解一下:
PPID: 父进程ID
PID: 进程ID
PGID: 进程组ID
SID: 会话ID
TTY: 控制终端
TPGID: 终端前台进程组ID
STAT: 进程状态
UID: 用户ID
TIME: 累计CPU时间
COMMAND: 命令名称
匹配的进程(来自第二个命令):
10379 13543 13543 10379 pts/O 13543 S+ 1001 0:00 ./code
12279 13598 13597 12279 pts/1 13597 S+ 1001 0:00 grep --color=auto code第一行是名为 ./code 的进程,第二行是 grep 命令本身(因为它也包含 "code")~
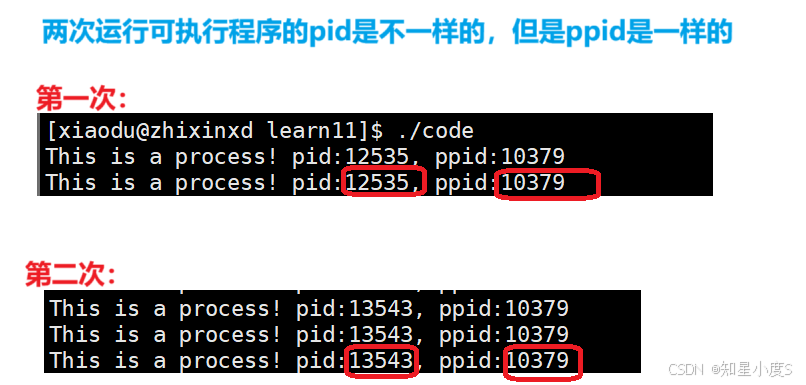
我们可以发现重新生成可执行程序,两次运行可执行程序的pid是不一样的,但是ppid是一样的~
为什么pid每次都不一样?
pid(进程ID)是操作系统为每个新进程分配的唯一标识符, 每次运行程序时,系统都会创建一个新的进程实例。操作系统使用pid来管理和区分不同的进程。由于pid是动态分配的,且系统需要保证唯一性,所以每次运行程序时都会获得一个不同的pid。
为什么ppid两次都一样?
ppid(父进程ID)表示创建当前进程的父进程的ID。ppid始终是10379,这意味着两次运行都是在同一个父进程中启动的。当我们在终端中执行./code命令时,终端Shell(bash)会创建子进程来运行程序。因此,无论运行多少次,这些子进程的父进程都是同一个Shell进程(pid: 10379)。
我们来验证一下父进程的身份,命令行输入:
ps ajx | head -1 && ps axj | grep 10379
所以我们在命令行中启动命令/程序的时候都会变成进程,该进程的父进程是bash!由子进程来运行命令/程序~
那么我们可以知道Linux系统是通过父进程创建子进程的方式来增多进程!!!
创建进程😀
我们知道Linux系统是通过父进程创建子进程的方式来增多进程!那么父进程是怎么创建子进程的呢?通过前面我们知道进程= 代码和数据 + PCB。创建进程我们就需要介绍一个Linux系统中的系统调用fork()~
我们可以使用man fork来简单看一下:
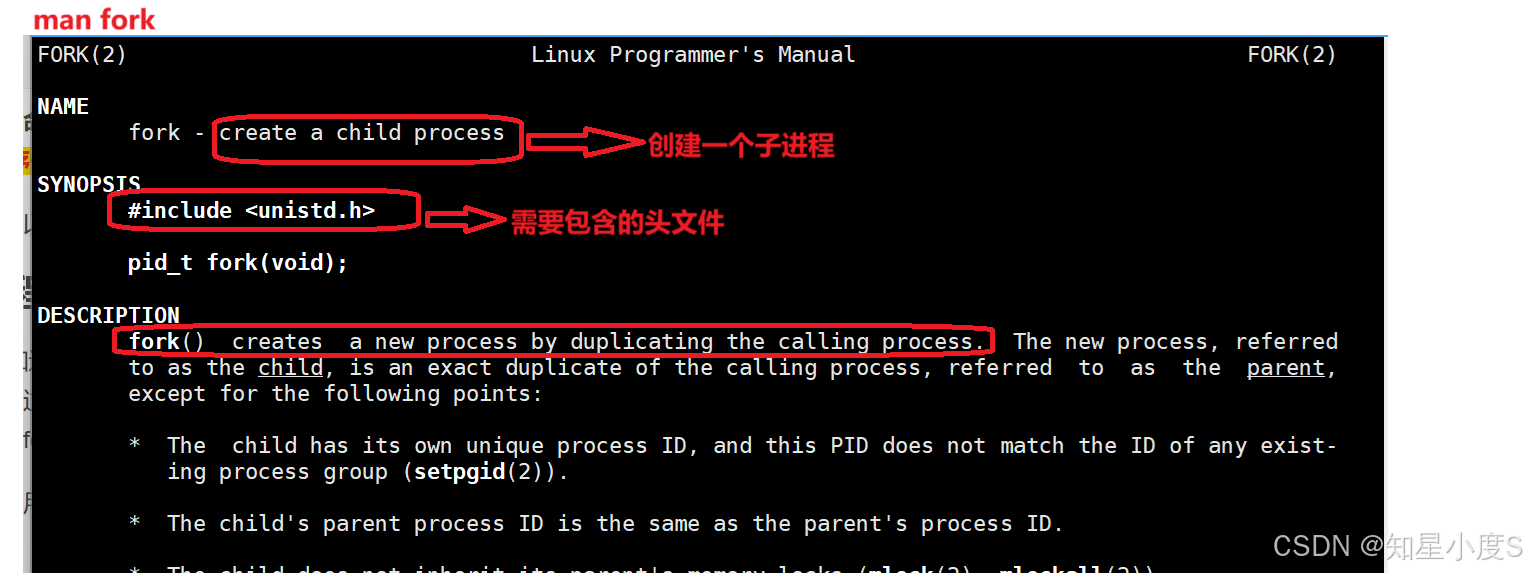
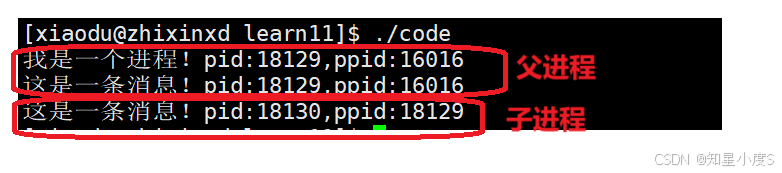
我们首先试用一下fork(),来看下面一段代码:

你们可以猜测到运行结果是什么吗?
见证奇迹的时刻到了,我们可以发现打印了两次这是一条消息~接下来我们慢慢分析
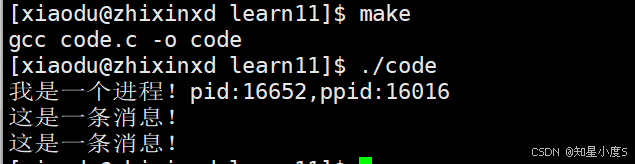
fork之后,打印了两次这是一条消息,说明不仅仅是一个进程执行了这条语句,一个是父进程,那么另外一个就是我们的子进程~
fork() 系统调用(system call)的核心思想:复制自己
当一个进程(我们称之为父进程)调用 fork() 时,操作系统会做这样一件事:几乎原封不动地复制当前进程,从而创建一个新的进程(我们称之为子进程)。
这个“复制”包括:
代码段:和父进程一模一样。
数据段:堆、栈、初始化的数据等,内容相同但位于不同的物理内存中。
进程上下文:打开的文件描述符、信号处理方式、进程状态等。
我们来验证一下:修改代码
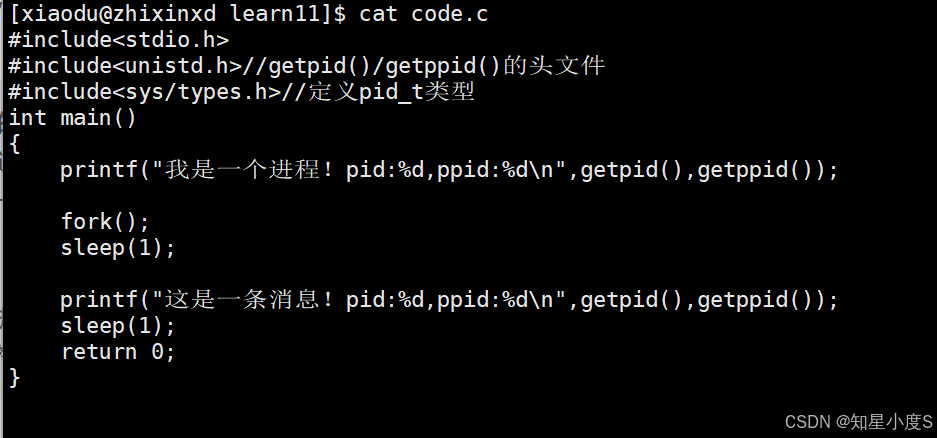
代码运行结果:
同时fork()系统调用还有一个核心特性:
一次调用,两次返回
这是 fork 最神奇也最容易让人困惑的地方(怎么会有两个返回值呢):
在父进程中,fork() 调用返回的是新创建的子进程的进程ID(PID)(一个大于0的数字)。
在子进程中,fork() 调用返回 0。
通过返回值,程序可以判断自己当前是父进程还是子进程,从而执行不同的分支代码。
我们同样可以通过一段代码来验证一下:
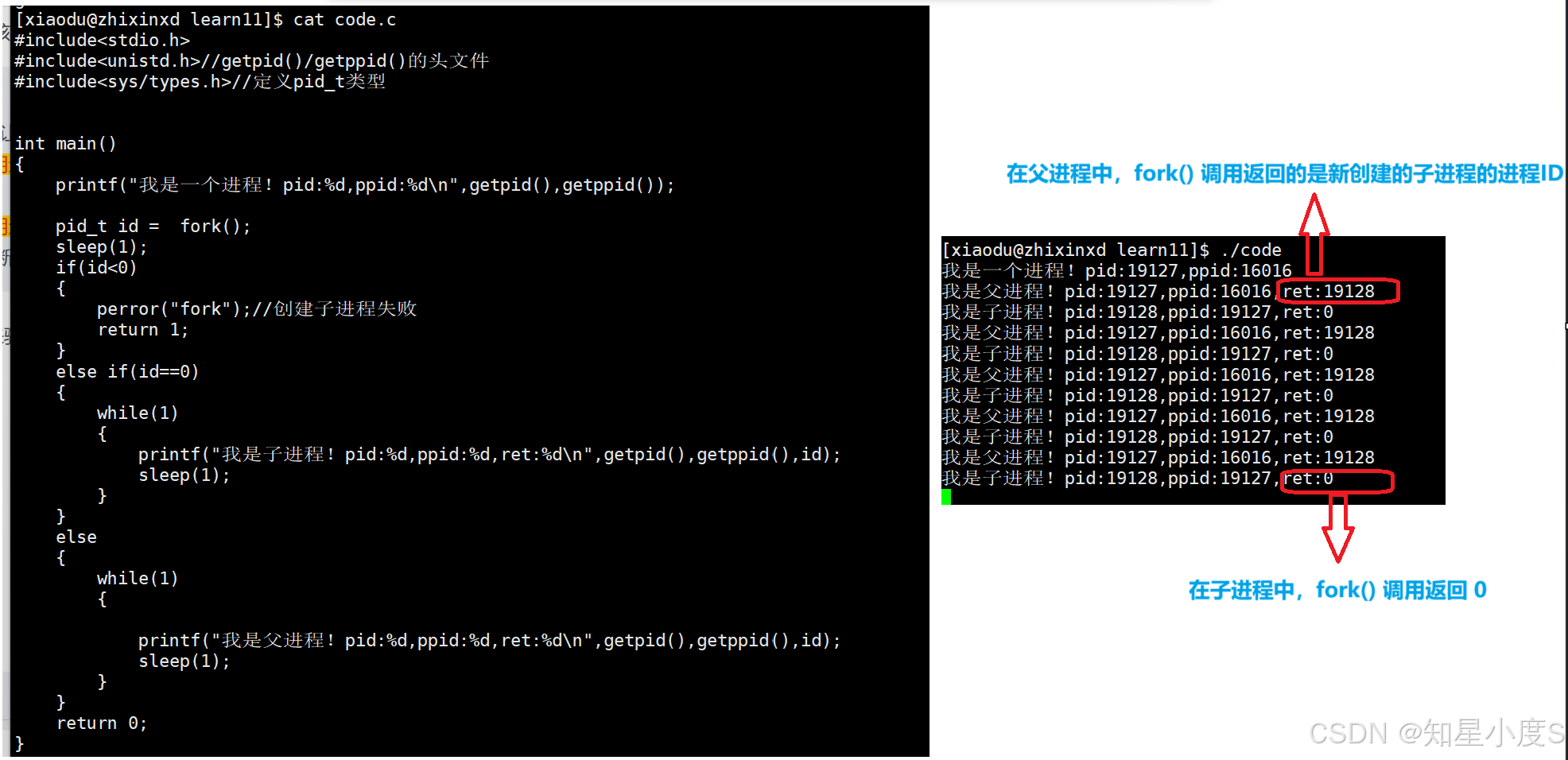
果不其然,结果确实如此~
这不禁让人困惑,怎么会有两个返回值呢?
事实上不是“一个函数返回两次”,严格来说,fork() 系统调用只执行了一次(创建子进程),但它的返回过程发生了两次——分别在两个不同的进程中。
return 的本质是写入,当函数执行到return的时候,主体功能已经完成了,从内核返回用户态的本质,就是将内核准备好的“返回值”写入到用户空间那个等待接收返回值的变量(id)中,操作系统为两个进程写入了不同的值。
| 特性 | 父进程 | 子进程 |
|---|---|---|
| 诞生方式 | 由用户启动 | 由 fork() 系统调用创建 |
fork() 返回值 |
子进程的 PID (>0) | 0 |
| 执行起点 | 从 fork() 调用之后继续执行 |
从 fork() 调用之后开始执行 |
| 关系 | 调用者 | 被创建者 |
神奇的“分身术”比喻:
可以把 fork() 调用点想象成一个“分身点”。父进程执行到此处,喊了一声“分身!”(系统调用)。
操作系统内核施展分身术,创造了一个一模一样的子进程。
法术完成后:
父进程听到耳边传来一句话:“你的分身ID是 1234”。
子进程一诞生,听到的第一句话是:“你是分身,你的编号是0”。
然后,父子两人都从“分身!”这句话之后开始继续各自的人生(执行后续代码),并且都记住了自己听到的那句话(不同的返回值)。
现在我们只是创建了一个子进程,如果我现在创建更多的子进程呢?
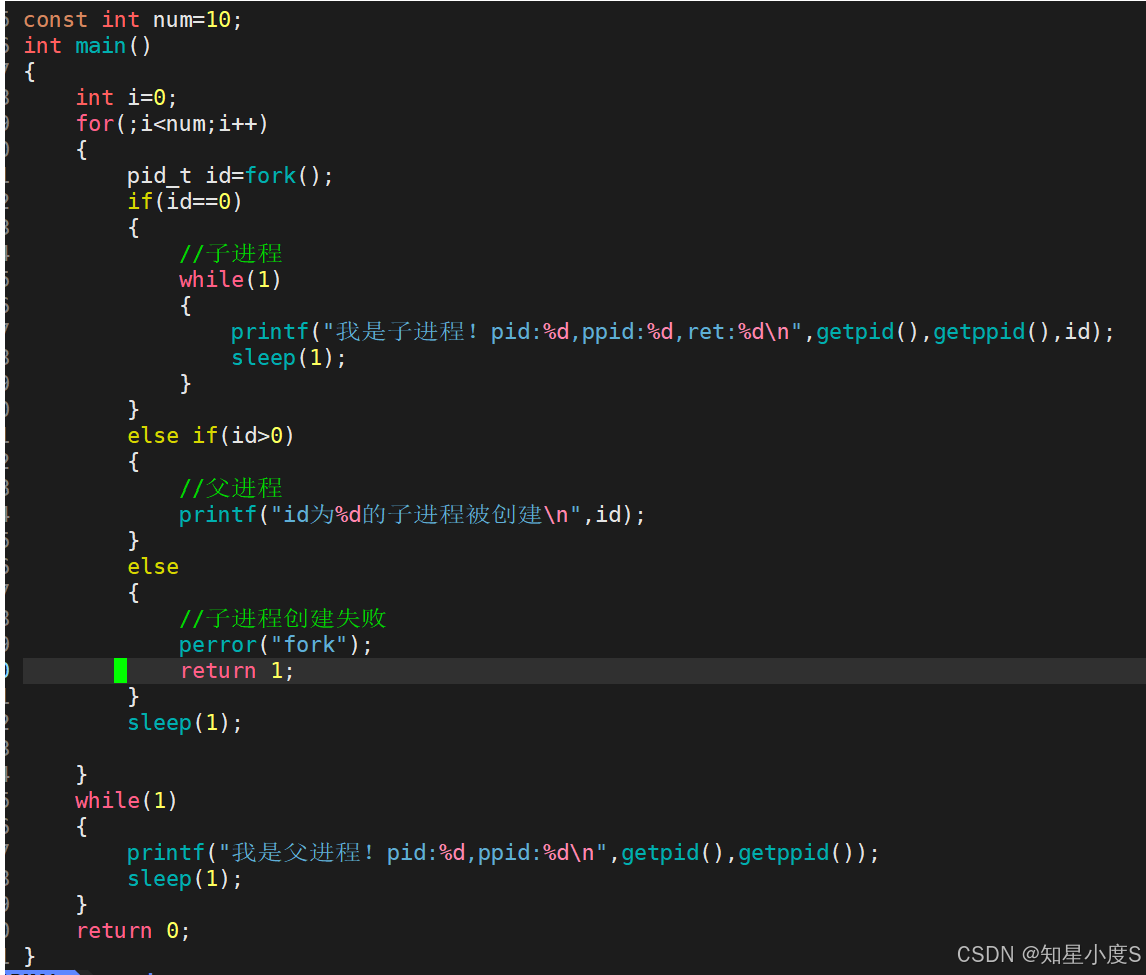
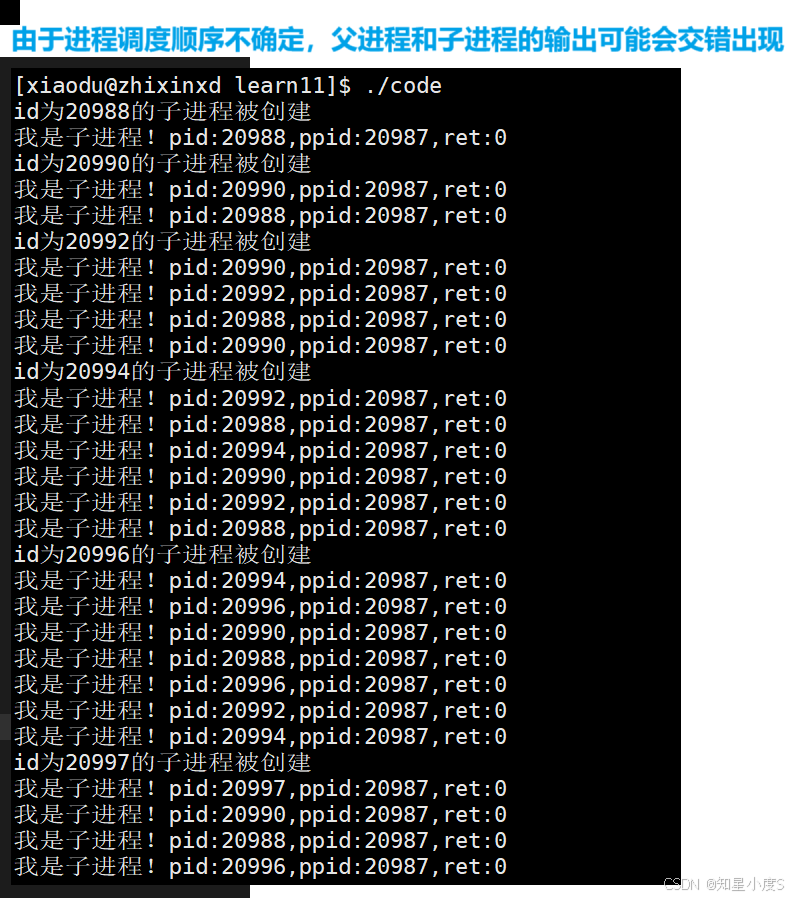
事实上,由于进程调度顺序不确定,父进程和子进程的输出可能会交错出现,也就是父子进程的运行顺序是不确定的~
总结:
fork是Unix/Linux创建新进程的核心系统调用。其核心机制是“复制父进程”:内核以父进程为模板,初始化子进程的控制结构(task_struct),并默认通过“写时复制”(Copy-On-Write)技术让父子进程高效共享相同的代码和数据页,仅在需要修改时才创建副本,从而保证进程数据独立性。fork的神奇之处在于“一次调用,两次返回”:在父进程中返回子进程的PID,在子进程中返回0。通过判断返回值,父子进程可执行不同代码分支,这是实现并发任务和“fork+exec”执行新程序的基础。它高效地实现了进程隔离与资源共享的平衡。
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨