指令微调(Instruction Tuning)是一种针对大型预训练语言模型(LLM)的微调技术,旨在通过输入自然语言指令及其对应的输出示例,训练模型理解和遵循多样化的人类指令。其核心目的是增强模型理解和执行特定指令的能力,使模型能够根据用户提供的自然语言指令准确、恰当地生成相应的输出或执行相关任务。
1. 技术原理
指令微调通常在预训练模型的基础上进行,主要通过以下步骤实现:
数据准备:构建包含指令和对应输出的标注数据集。这些数据集可以是人工标注的,也可以通过自动化方法生成。
模型输入构建:将指令和输入文本组合成特定的格式,作为模型的输入。
标签构建:为模型的输出部分创建标签,通常使用 -100 标记输入部分,以确保模型只对输出部分进行学习。
微调训练:使用这些数据对预训练模型进行监督学习,调整模型参数以提高其在特定任务上的表现。
2. 目的
提升指令遵循能力:使模型能够将抽象指令映射为具体任务,如将“翻译”指令映射为生成目标语言文本。
增强零样本和少样本能力:通过多样化指令训练,模型能够在没有额外示例的情况下处理未见任务。
支持多任务泛化:单一模型可处理问答、生成、推理等多种任务,减少针对每项任务单独微调的需求。
对齐人类意图:减少模型生成无关或有害内容的风险,使其更符合用户期望。
3. 方法分类
根据参数更新范围和目标任务类型,指令微调可以分为以下几类:
全量微调(Full Fine-tuning):对整个预训练模型的所有参数进行调整,计算成本高,但可能达到最佳性能。
参数高效微调(Parameter-Efficient Fine-tuning, PEFT):仅调整部分参数,如适配层、低秩矩阵,冻结大部分预训练参数,计算成本低,适合资源受限场景。
4. 数据利用方式
监督微调:使用标准标注数据进行训练。
半监督/自监督:通过对比学习、数据增强等技术利用未标注数据。
指令微调广泛应用于对话模型(如ChatGPT、Claude)和多任务模型,显著提升了模型在理解和执行人类指令方面的能力。例如,通过指令微调,模型可以更好地理解“总结这篇文章”、“用Python写一个函数”等直接指令。大模型指令微调(Instruction Tuning)是一种针对大型预训练语言模型的微调技术,其核心目的是增强模型理解和执行特定指令的能力,使模型能够根据用户提供的自然语言指令准确、恰当地生成相应的输出或执行相关任务。 指令微调特别关注于提升模型在遵循指令方面的一致性和准确性,从而拓宽模型在各种应用场景中的泛化能力和实用性。
这里本文的主要目的是想要以Qwen1.5作为基座大模型,基于新闻语料数据集zh_cls_fudan-news,通过指令微调的方式实现文本分类任务,这里使用到的数据集为zh_cls_fudan-news,地址在这里,如下所示:
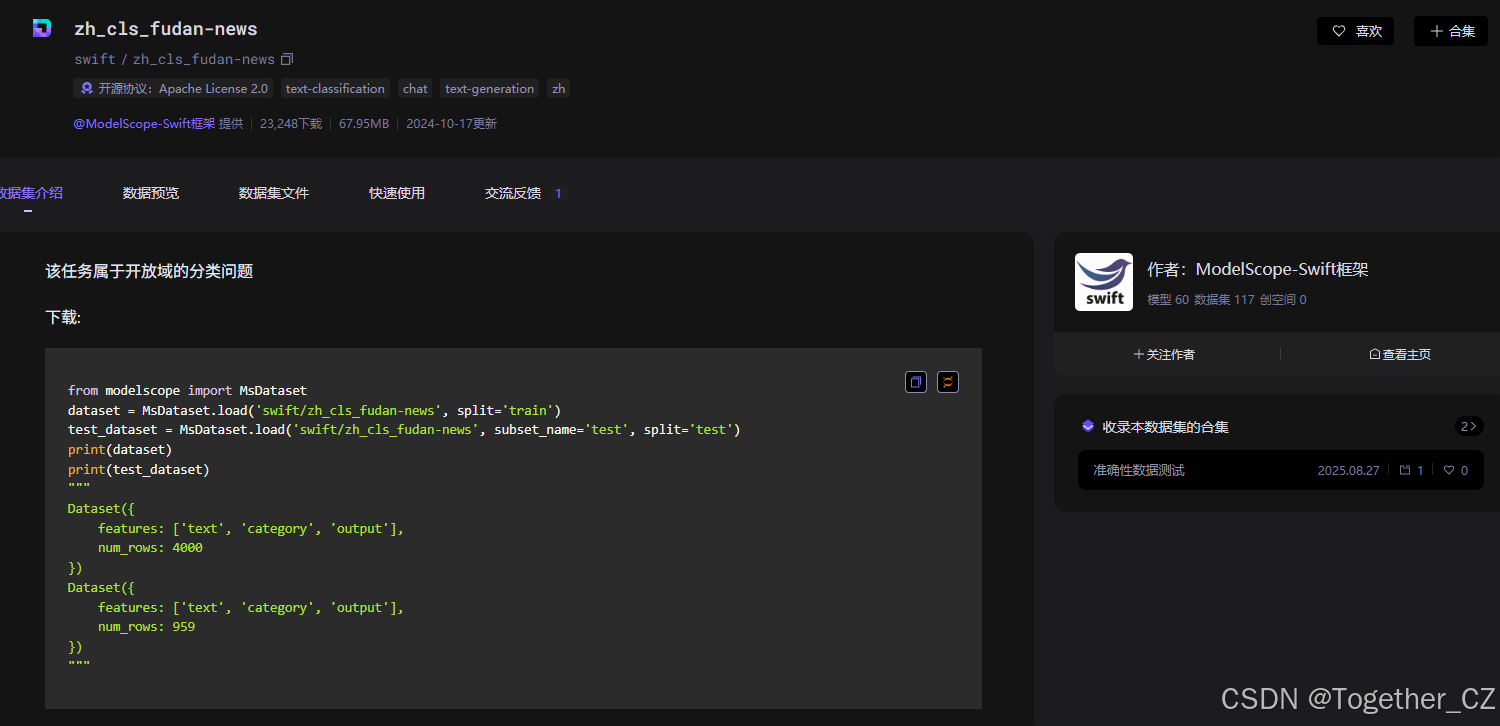
基础环境使用到的核心库介绍如下:
SwanLab
简介:SwanLab是一款开源、轻量的AI模型训练跟踪与可视化工具,提供了一个跟踪、记录、比较和协作实验的平台,面向人工智能研究者,设计了友好的Python API和漂亮的UI界面。
核心特性:
实验指标与超参数跟踪:极简的代码嵌入机器学习pipeline,可跟踪记录训练关键指标,支持云端使用,随时随地查看训练进展,还能记录超参数、日志logging、硬件环境、Git仓库、Python环境、Python库列表、项目运行目录等信息。
全面的框架集成:与PyTorch、HuggingFace Transformers、PyTorch Lightning、LLaMA Factory、MMDetection、Ultralytics、PaddleDetection、LightGBM、XGBoost、Keras、Tensorboard、Weights&Biases、OpenAI、Swift、XTuner、Stable Baseline3、Hydra等30多个框架集成。
硬件监控:支持实时记录与监控CPU、NPU(昇腾Ascend)、GPU(英伟达Nvidia)、内存的系统级硬件指标。
实验管理:通过集中式仪表板,可快速管理多个项目与实验,通过整体视图速览全局。
比较结果:通过在线表格与对比图表比较不同实验的超参数和结果,挖掘迭代灵感。
在线协作:支持团队协作式训练,可将实验实时同步在一个项目下,在线查看团队的训练记录,并基于结果发表看法与建议。
分享结果:复制和发送持久的URL来共享每个实验,方便发送给伙伴或嵌入到在线笔记中。
支持自托管:支持不联网使用,自托管的社区版同样可以查看仪表盘与管理实验。
ModelScope
简介:ModelScope是一个开源社区,旨在加速AI开发。它提供了丰富的模型、数据集和AI应用,用户可以访问计算基础设施以进行模型服务,并使用其开源社区构建自己的模型和应用。
核心特性:
ModelScope Library:提供高效的模型推理、微调和评估功能,是释放各种AI模型潜力的统一入口,涵盖从视觉、语音到LLM的多种模型。
ModelHub:作为开源中心,用于托管AI模型、数据集等。
Popular Studio:ModelScope的Studio为用户提供了一个免费且灵活的AI应用展示空间,用户可以基于ModelScope平台上模型提供的原子能力,自行构建和展示不同的AI应用。
Transformers
简介:由Hugging Face开发的Transformers库是一个流行的开源库,提供了大量预训练的自然语言处理模型,如BERT、GPT等,方便用户进行模型的加载、训练、微调和推理。
核心特性:
丰富的预训练模型:包含了多种类型的预训练模型,覆盖了多种自然语言处理任务,如文本分类、命名实体识别、机器翻译等。
易用性:提供了简洁的API,使得加载和使用预训练模型变得非常简单,用户可以轻松地将这些模型集成到自己的项目中。
微调支持:方便用户对预训练模型进行微调,以适应特定的任务或数据集,提高模型在特定场景下的性能。
社区活跃:拥有庞大的社区和丰富的文档,用户可以方便地获取帮助和资源,同时也可以贡献自己的模型和代码。
Datasets
简介:Datasets库是一个用于加载和处理数据集的工具,它提供了大量的公共数据集,同时也支持用户自定义数据集的加载和处理,方便用户在机器学习和深度学习项目中使用数据。
核心特性:
丰富的公共数据集:集成了众多公共数据集,用户可以直接加载这些数据集进行实验和研究,节省了数据收集和整理的时间。
灵活的数据处理:提供了丰富的数据处理功能,如数据分割、特征提取、数据增强等,用户可以根据自己的需求对数据进行处理和转换。
与Transformers等库集成:与Transformers等库紧密结合,方便用户在使用预训练模型时加载和处理相应的数据集,实现无缝衔接。
Peft
简介:Peft(Parameter-Efficient Fine-Tuning)是一种参数高效的微调方法,旨在在微调预训练模型时减少参数的更新量,从而提高微调的效率和效果。
核心特性:
参数效率:通过只更新模型中的一部分参数,而不是所有参数,减少了微调过程中的计算量和内存占用,使得微调过程更加高效。
多种微调策略:提供了多种参数高效的微调策略,如适配器微调、前缀微调等,用户可以根据自己的需求选择合适的策略进行模型微调。
与Transformers集成:与Transformers库集成,用户可以在使用Transformers加载预训练模型的基础上,方便地应用Peft进行参数高效的微调。
Accelerate
简介:Accelerate库是一个用于加速机器学习模型训练的工具,它可以帮助用户在多种硬件环境下(如CPU、GPU、TPU等)高效地训练模型,同时提供了简单的API来管理训练过程中的各种资源。
核心特性:
硬件加速:支持多种硬件加速器,如GPU、TPU等,能够自动检测和利用可用的硬件资源,加速模型的训练过程。
分布式训练:提供了分布式训练的支持,用户可以轻松地在多台机器上进行模型训练,提高训练效率。
简单易用:提供了简洁的API,用户可以通过简单的配置来管理训练过程中的各种资源,如学习率调度、梯度累积等。
Pandas
简介:Pandas是一个开源的数据分析和处理库,它提供了强大的数据结构和数据分析工具,广泛应用于数据清洗、数据转换、数据分析等领域。
核心特性:
强大的数据结构:提供了DataFrame和Series等数据结构,方便用户对数据进行存储、操作和分析。
数据清洗和转换:提供了丰富的数据清洗和转换功能,如缺失值处理、数据类型转换、数据筛选等,用户可以方便地对数据进行预处理。
数据分析和统计:提供了大量的数据分析和统计功能,如分组聚合、数据透视表、相关性分析等,用户可以快速地对数据进行分析和挖掘。
Addict
简介:Addict是一个轻量级的字典库,它允许用户以点语法访问字典中的键值对,使得字典的操作更加方便和直观。
核心特性:
点语法访问:用户可以通过点语法访问字典中的键值对,而不需要使用传统的中括号和键名的方式,提高了代码的可读性和易用性。
字典操作:支持常见的字典操作,如添加、删除、修改键值对等,同时保持了点语法的一致性。
NLTK
简介:NLTK(Natural Language Toolkit)是一个用于自然语言处理的Python库,它提供了大量的工具和资源,用于文本处理、语言分析、语料库管理等。
核心特性:
文本处理:提供了丰富的文本处理功能,如分词、词性标注、命名实体识别等,用户可以方便地对文本数据进行预处理。
语言分析:支持多种语言分析任务,如句法分析、语义分析等,用户可以使用NLTK提供的工具进行语言分析和研究。
语料库管理:提供了大量的语料库和语言资源,用户可以方便地加载和使用这些语料库进行实验和研究。
数据实例内容如下所示:
| text (Value) | category (Value) | output (Value) |
|---|---|---|
| 中国环境科学CHINA ENVIRONMENTAL SCIENCE1998年 第18卷 第1期 No.1 Vol.18 1998科技期刊一种改进的边界层参数化模式*许丽人 王体健 李宗恺 (南京大学大气科学系,南京 210093)文 摘 在能量平衡方法的基础上提出一套利用常规气象资料求取边界层参数的... 详情 |
["Art","Military","Agriculture","Enviornment","Space","Computer","Electronics"] |
Enviornment |
| 【 文献号 】2-1367 【原文出处】学术研究 【原刊地名】广州 【原刊期号】199904 【原刊页号】47~49 【分 类 号】F13 【分 类 名】社会主义经济理论与实践 【复印期号】199906 【 标 题 】充分认识我国现阶段私营经济的特殊性 【 作 者 】张振宇 【作者简介】中共广东省委... 详情 |
["Electronics","Agriculture","Literature","Sports","Economy","Philosophy"] |
Economy |
| 【 文献号 】2-1188 【原文出处】文艺理论研究 【原刊地名】沪 【原刊期号】199804 【原刊页号】15~28 【分 类 号】J3 【分 类 名】中国现代、当代文学研究 【复印期号】199809 【 标 题 】论金庸小说的艺术价值 【 作 者 】徐岱 【作者简介】徐岱 浙江大学中文系 【 正 文 】 1... 详情 |
["Philosophy","Politics","Law","Transport","Mine","Enviornment","Agriculture","Military","History","Literature","Art","Energy","Electronics","Sports","Economy","Communication","Computer","Space","Education"] |
Art |
| 【 文献号 】2-371 【原文出处】咨询与决策 【原刊地名】武汉 【原刊期号】200005 【分 类 号】F61 【分 类 名】财政与税务 【复印期号】200007 【 标 题 】新经济时代的税务对策:管理创新 【 作 者 】周星/山路 【 正 文 】 今年以来,“新经济”一词频繁见诸报端。那么,... 详情 |
["Electronics","Enviornment","Military","Transport","Education","Literature","Energy","Art","Economy","Computer","Sports","Mine","Medical","History","Space","Communication","Law","Politics","Agriculture"] |
Economy |
| 南已有76人死于艾滋病新华社贝尔格莱德5月23日电南联邦卫生局23日宣布,南斯拉夫至今共发现129名艾滋病患者,其中76人已死亡。南全国检查出艾滋病病毒携带者2000人,但专家们估计,实际上艾滋病病毒携带者至少已超过4000人。为防止艾滋病蔓延... 详情 |
["Literature","History","Transport","Philosophy","Computer","Politics","Military","Education","Sports","Economy","Space","Medical","Agriculture","Enviornment","Communication","Electronics","Energy"] |
Medical |
| 【 文献号 】3-1476 【原文出处】求是 【原刊地名】京 【原刊期号】199919 【原刊页号】41~44 【分 类 号】D2 【分 类 名】中国共产党 【复印期号】200002 【 标 题 】学习江泽民同志关于“讲政治”论述的体会 【 作 者 】刘海藩 【作者简介】刘海藩,中央党校副校长 【 正 ... 详情 |
["Politics","Enviornment","Art","Sports","Agriculture","Mine","Law","Medical"] |
Politics |
| 【 文献号 】2-295 【原文出处】文艺研究 【原刊地名】京 【原刊期号】199403 【原刊页号】024-034 【分 类 号】J1 【分 类 名】文艺理论 【 作 者 】周来祥 【复印期号】199501 【 标 题 】崇高・丑・荒诞 --西方近、现代美学和艺术发展的三部曲【 正 文 】 一 丑的升起从古... 详情 |
["Electronics","Art","Law","Transport","Literature","Sports","Medical","Politics","Military","Mine","Education","Agriculture","Communication"] |
Art |
| 【 文献号 】3-2104 【原文出处】《幼儿教育》 【原刊地名】杭州 【原刊期号】199801 【原刊页号】21 【分 类 号】G51 【分 类 名】幼儿教育 【复印期号】199806 【 标 题 】奇妙的小路 ――大班体育活动设计及评析【 作 者 】周红/郑艺 【作者简介】上海 周红设计 郑艺评析 【 ... 详情 |
["Sports","Communication","Military","Electronics","Philosophy"] |
Sports |
| (兼晚报)我国邮集首次在世界邮展上获金奖新华社北京5月15日电(记者李玫)我国著名集邮家沈曾华的《华东人民邮政邮集》日前在伦敦举行的世界邮展上获金奖。这是我国自1984年参加世界邮展以来首次获金奖。沈曾华是一位新四军老干部。他从小喜欢集邮。在战火... 详情 |
["Communication","Art","Politics","Medical","Education","Economy","Sports","Military","Law","Electronics","Philosophy"] |
Art |
| 【 文献号 】7-464 【原文出处】世界经济与政治 【原刊地名】京 【原刊期号】200009 【原刊页号】5~8 【分 类 号】D7 【分 类 名】国际政治 【复印期号】200012 【 标 题 】当前国际关系研究中的若干重点问题(注:这是钱其琛同志在2000年5月26日举行的北京大学国际关... 详情 |
["Education","Politics"] |
Politics |
可以看到:每一行表示一个样本,每个样本共有5个属性。分别如下:
text (Value):文本内容
category (Value):类别
output (Value):输出
数据集文件详情如下所示:
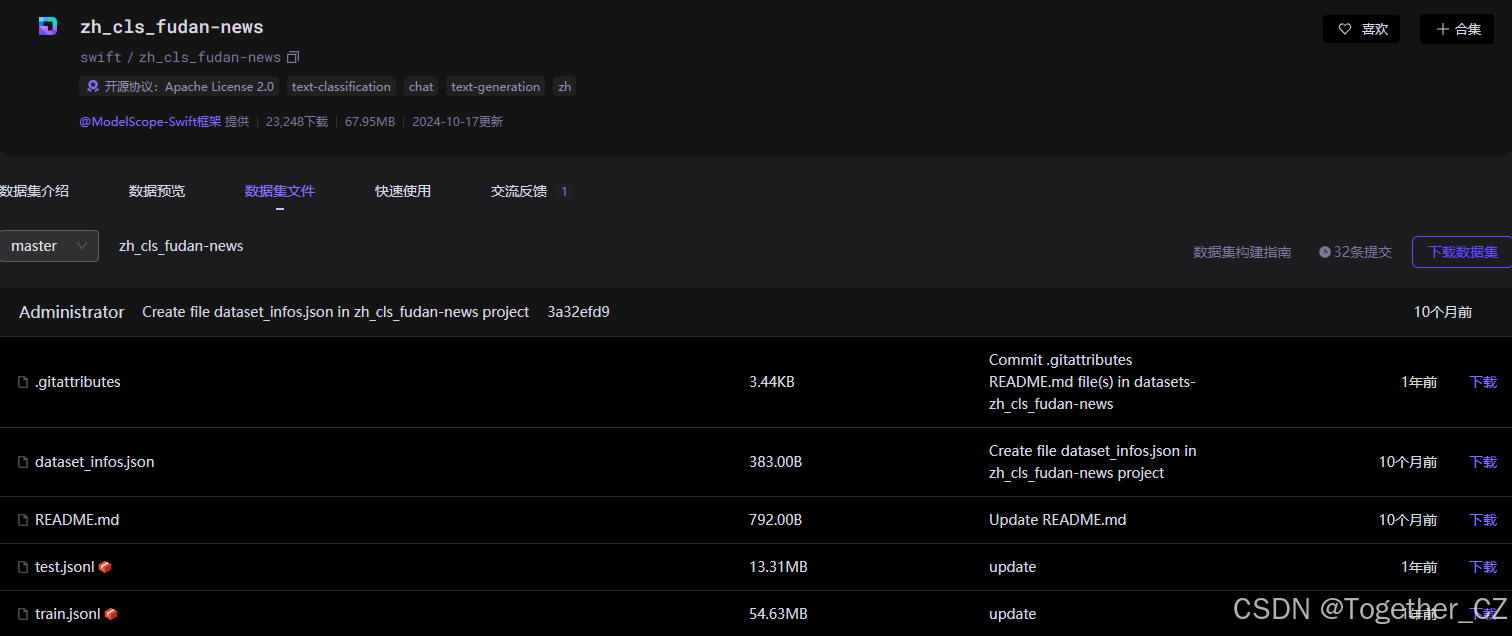
加载解析使用代码很简洁,如下所示:
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('swift/zh_cls_fudan-news', subset_name='default', split='train')
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('swift/zh_cls_fudan-news', subset_name='test', split='test')接下来需要对初步得到的数据集进行解析成处理得到可用于模型微调训练的数据集格式,概括来说主要做三点操作:
1、加入instruction指令信息
2、将text的内容和category内容拼接用作模型的input字段内容
3、将output字段内容用作微调模型的输出output字段的内容
代码实现如下所示:
def dataset_jsonl_transfer(origin_path, new_path):
"""
将原始数据集转换为大模型微调所需数据格式的新数据集
"""
messages = []
# 读取旧的JSONL文件
with open(origin_path, "r") as file:
for line in file:
# 解析每一行的json数据
data = json.loads(line)
context = data["text"]
catagory = data["category"]
label = data["output"]
message = {
"instruction": "你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型",
"input": f"文本:{context},类型选型:{catagory}",
"output": label,
}
messages.append(message)
# 保存重构后的JSONL文件
with open(new_path, "w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False) + "\n")之后需要对训练语料数据集进行Tokenizer处理,代码实现如下:
def process_func(example):
"""
将数据集进行预处理
"""
MAX_LENGTH = 384
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
f"<|im_start|>system\n你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n",
add_special_tokens=False,
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = (
instruction["attention_mask"] + response["attention_mask"] + [1]
)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels} 输出结果实例如下所示:
原始内容:
{
'instruction': '你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型',
'input': "文本:【 文献号 】4-2054\t【原文出处】史学月刊\t【原刊地名】开封\t【原刊期号】199804\t【原刊页号】118~120\t【分 类 号】K5\t【分 类 名】世界史\t【复印期号】199809\t【 标 题 】正确评价世界近代史上的历史人物\t【 作 者 】秦元春\t【作者简介】作者秦元春,1964年生,淮南师范专科学校历史系讲师。淮南,232001\t【 正 文 】\t历史科学是一门准确而严谨的科学。正确了解和评价各个时期的历史人物及其所从事的活动,是历史研究的一个重要组成部分。在世界历史的长河中,有许多类别不同的历史人物,由于特定的条件和环境,具有比较复杂的特性。因此,遵循马克思历史唯物主义的观点,正确评价历史人物,在历史研究与教学过程中尤为重要。一 正确评价资产阶级革命中的各种头面人物世界近代史是资本主义发生、发展的历史。资本主义社会如同封建社会一样,都是人类社会历史发展过程中的必然阶段。17世纪至18世纪欧美发生的早期资产阶级革命,用资本主义制度战胜了封建制度,显示了资本主义制度比封建制度的巨大优越性。当时,最先出来领导革命并执掌政权的总是上层金融资产阶级。这是不足为怪的。因为它是最有经济实力、政治上最成熟的阶层,由它建立统治权在客观上是历史的必然。因此,正确评价早期资产阶级革命中具有开拓性的历史人物,必须根据当时时代的特点。《共产党宣言》中说:“资产阶级在历史上曾经起过非常革命的作用。”马克思的这一观点,尤应引起我们的重视。如何评价克伦威尔?首先,克伦威尔是一个处于世界从封建社会开始向资本主义社会转变的历史时期的人物,他在当时是能够顺应世界从封建社会向资本主义社会转变这一历史潮流的。他的历史任务就是在英国推翻封建制度,建立资本主义制度。克伦威尔基本上完成了历史所赋予的时代任务。在革命一开始,他就参加了反对斯图亚特王朝的斗争;后来,在审讯查理一世的过程中态度坚决,他又始终参加了对国王的审判。正是由于他的坚持,国王才被推上断头台,英国才宣布为“共和国和自由国家”。无疑,克伦威尔促进了英国社会的变革与向前发展。其次,克伦威尔领导了多次重大战役,具有卓越的军事才能。克伦威尔不愧为英国资产阶级的开国元勋、杰出的资产阶级革命家。我觉得,评价克伦威尔应从总体上观察他是否顺应了历史发展的要求,不能简单地因为克伦威尔谋求私利、权欲大、征服爱尔兰而否定他,更不能因为克伦威尔有其时代和阶级的局限性而苛求他。对华盛顿的评价,现在已基本上纠正了过去在“左”的思想影响下的只给予抽象肯定的做法。分歧比较大的是对法国大革命中一些头面人物的评价。实际上,法国大革命无论在深度上还是在广度上都超过了英国资产阶级革命和美国独立战争。雅各宾专政是法国大革命最深入、最彻底的阶段。罗伯斯庇尔这个历史人物对法国大革命贡献是最大的,也是最突出的。革命风暴前夕,罗伯斯庇尔全力投入反对封建专制制度的政治斗争。三级会议选举前,罗伯斯庇尔发表了《致阿多瓦人》的革命小册子。革命初期,罗伯斯庇尔以一位公认的群众领袖的身份主办《宪法保卫者》周刊。1992年8月10日起义后,他被选入巴黎公社和国民公会,领导雅各宾派,坚决主张处死国王路易十六和抗击普奥干涉军。1793年5月31日到6月2日起义后,罗伯斯庇尔领导雅各宾派政府――公安委员会,废除封建土地所有制,平定吉伦特派的反革命叛乱,粉碎欧洲君主国的武装干涉,在保卫和推动法国大革命向前发展中起过很大的作用。罗伯斯庇尔虽有其时代和阶级的局限性,犯有严重过错,但他不失为法国大革命之中有胆略的资产阶级革命家。至于拉法叶特,过去在苏联和我国史学著述中却几乎无例外地对他作出了否定的结论。这就有必要进行重新研究。事实上,法国大革命爆发后,拉法叶特被巴黎各区推举为刚刚组成的巴黎国民自卫军司令。他担任这一军事要职一直到1791年11月。拉法叶特对这支新型武装力量的发展无疑有着重要影响。作为法国大革命时期君主立宪派首领之一,他在摧毁封建专制的国家机构,初步建立资本主义的国家体制,使法国革命沿着上升路线发展,发挥了其应有的作用。尽管他的政治生涯中有着无法克服的污点和罪行,但这不能影响我们认识和肯定他在法国大革命初期所起的作用。同样,对于法国大革命时期的布里索也不应该一棍子打死。布里索作为吉伦特派的主要领导人,在革命初期,创办过《法兰西爱国者报》,作好了迎接革命的准备。大革命爆发后,布里索积极赞同革命,并倾向君主立宪派。在吉伦特派执政时期,布里索作为该派领导人,在进一步打击封建制度、宣布成立共和国、抗击欧洲干涉军、保证资本主义经济自由发展等方面,作了一些好事。布里索虽然反对革命深入发展,企图逃走而未遂,但他仍属于有所贡献的资产阶级共和派领导人。对于丹东的评价,解放以来几乎照搬苏联史学观点,说他宽容、投降,逐渐变成颠覆共和国的危险敌人,等等。年仅35岁的丹东,后期虽有过政治上的失节,但不能因此一笔抹煞他的历史功绩。丹东参加过1792年8月10日起义。当时凡尔登失陷的消息传来,丹东在祖国存亡、危在旦夕的时刻,发表了著名的演说,号召人民拿起武器,保卫祖国。可以说,1792年夏秋是丹东革命生涯之中最光辉的一页。在早期资产阶级革命时期,每个开拓性的历史人物都在历史上有其应有的地位与作用,应该给以应有的肯定。至于后期各国的资产阶级革命中的著名人物,如俾斯麦、林肯、加富尔、拿破仑三世等人,我们既不能以其功而掩盖其曾有之过,也不能以其过而否定其曾有之功,而应力求给予恰如其分的科学的肯定。列宁指出:“无产阶级敌视一切资产阶级和资本主义制度的一切表现,但是这种敌视并没有解除它应对资产阶级人士在历史上的进步和反动加以区别的责任。”(注:《列宁全集》第8卷,第34页。)二 正确评价国际工人运动中各种派别的头面人物在19世纪中叶至20世纪初叶的国际工人运动中,马克思主义者代表了运动的发展方向和未来,但在这个运动中也出现了与马克思主义者相敌对的各种机会主义的派别。对这些派别的头面人物的研究,应将其思想发展的过程和各个阶段分析得比较细致一些,尽可能做到具体而生动地再现每个历史人物的全貌。拉萨尔是德国工人运动历史上一个重要人物,也是一个充满矛盾的人物。他的活动和思想意识均带有两重性。在1848年德国革命期间,他响应马克思的号召,投身革命斗争,并为此坐了牢,但他同时对旧法统与旧法制抱有幻想。60年代初,他曾帮助工人摆脱自由资产阶级的影响,在建立德国工人独立政治组织中立下了汗马功劳;同时,他却千方百计地暗中勾结俾斯麦,妄想把全德工人联合会变成普鲁士王朝的御用工具。尽管如此,对于拉萨尔在1848年德国革命和10年(1858-1869)反动统治时期的表现,我们应该基本上予以肯定。巴枯宁是俄国历史上和国际工人运动史上深有影响的人物,素有“无政府主义之父”之称。然而,对巴枯宁早期曾经是一个民主主义者的历史事实,人们却未予重视。1842年10月,巴枯宁就开始在卢格主编的《德国年鉴》上以茹尔・埃利扎尔的笔名发表了《德国的反动。法国人编纂的文集片断》一文。在这篇文章中,他以法国民主主义者的身份鼓吹自由、平等和博爱,从而标志着他的民主主义思想的形成。1843年6月,巴枯宁发表在《瑞士共和主义者报》上的《论共产主义》一文,说明了他的民主主义思想有了新的发展。1847年11月,巴枯宁在巴黎纪念1831年波兰起义大会上发表的反对沙俄专制主义的演说,反映了他的民主主义思想的成熟。1848年3月,巴枯宁发表在巴黎《改革报》上的《宣言》,以“共和万岁”和“民主万岁”的激情口号结束,表现了他对欧洲资产阶级民主革命胜利的信心。正是在这种思想意识的指导之下,他投身于1848-1849年的欧洲革命高潮之中。从法兰西兵营到德累斯顿的街垒,都留下了他的足迹。不久之后,巴枯宁由民主主义者向无政府主义者蜕变。这是巴枯宁的个人悲剧所在。尽管巴枯宁发展成为一个把“骗子、强盗、暴发户、复仇主义者、奸商的特点”集中于一身的人物,但是,对他早期民主主义阶段还应给予肯定。众所周知,伯恩施坦是修正主义的鼻祖。伯恩施坦作为苏黎世“三人团”的成员和《社会主义的前提和社会民主党的任务》发表前后的历史,都是人们有目共睹的。但是,对伯恩施坦主编《社会民主党人报》期间的活动,则往往被人们所忽视。事实上,伯恩施坦和考茨基一样,在整个80年代和在90年代前期,都是革命的社会民主党人,都是马克思主义者(注:有关新的探讨可参阅彭树智:《伯恩斯坦与“社会民主党人报”》,载《西北大学学报》,1981年第4期。)。从伯恩施坦的全部演变史来看,他一生的演变经历了一个曲线的过程:由青年民主主义者下降线发展到“苏黎世三人团”的一员,再沿上升线发展到革命的社会民主党人,即马克思主义者的阶段,最后又沿着下降线发展下去,成为修正主义者、社会帝国主义者。这个发展过程表现了他与考茨基有着不同的特点。考茨基前期是民主主义者,中期是马克思主义者,后期成为修正主义者、无产阶级革命的叛徒。从这个意义上说,伯恩施坦是比考茨基更为复杂的历史人物。普列汉诺夫同样是国际共产主义运动史上比较复杂的头面人物。早期,他是个民粹主义者,后来与查苏利奇、阿克雪里罗德等人在日内瓦创立“劳动解放社”,翻译和介绍了大量马克思、恩格斯的著作,积极宣传唯物史观和科学社会主义理论,并同伯恩施坦、施米特等人的哲学修正主义展开了原则的斗争。这时的普列汉诺夫已经成为著名的马克思主义者。1903年以后,他在策略和组织问题上摇摆于布尔什维克和孟什维克之间,总的倾向则是充当了孟什维克的思想领袖的角色。1914-1918年第一次帝国主义战争期间,他成为社会沙文主义者,与考茨基一起鼓吹资产阶级“保卫祖国”的口号,终于彻底背叛了马克思主义和无产阶级革命事业。列宁不仅对普列汉诺夫一生的功过采取实事求是的分析的态度,在坚持原则斗争的同时,照样肯定其历史功绩,而且对普列汉诺夫生平的某个阶段,例如1903年至1914年,也采取具体分析的态度。列宁指出:“从1903年以来,普列汉诺夫就在策略和组织的问题上极可笑地动摇着:(1)1903年8月是一个布尔什维克;(2)1903年11月(《火星报》第25号),主张同‘机会主义者’孟什维克建立和平;(3)1903年12月是一个孟什维克,而且是一个热烈的孟什维克;(4)1905年春天,布尔什维克胜利以后,争取‘敌对的兄弟们’的‘统一’;(5)1905年年底到1906年年中是一个孟什维克;(6)从1906年年中开始,有时离开孟什维克,在1907年伦敦代表大会上斥责孟什维克(切列万宁已经承认)‘组织上的无政府主义’;(7)1908年同取消派决裂;(8)1914年又重新转为取消派。”(注:《列宁全集》第20卷,第359-360页。)列宁认为,普列汉诺夫由于这种政治上的摇摆不定态度,他根本不可能组织起一个“流派”,最多“只能搅起一些浪花”。可是,列宁在这样说的同时还指出:“普列汉诺夫个人的功绩在过去是很大的。在1883-1903年的20年间,他写了很多卓越的著作,特别是反对机会主义、马赫主义者和民粹主义者的著作。”(注:《列宁全集》第20卷,第359页。)1918年5月,即普列汉诺夫逝世3个月后,列宁提议出版普列汉诺夫的哲学著作。1921年1月,列宁更发出号召:若不研究普列汉诺夫的全部哲学著作,就不能成为一个觉悟的真正的共产主义者。1922年,列宁提议出版普列汉诺夫文集,搜集流散在国外的普列汉诺夫的文稿、藏书。所以说,即使反面人物,也需要将他放到特定的社会历史环境中考察其历史活动,从而判定其功与过。列宁对普列汉诺夫所作的实事求是的评价与豁达的态度为我们树立起了马克思主义者评价复杂历史人物的典型。【责任编辑】池豫\t,类型选型:['Electronics', 'Politics', 'Economy', 'Military', 'Art', 'Law', 'Computer', 'Energy', 'Agriculture', 'Philosophy', 'Mine', 'Literature', 'History', 'Education', 'Communication']",
'output': 'History'
}
Tokenizer内容:
{
'input_ids': [151644, 8948, 198, 56568, 101909, 108704, 70538, 104799, 101057, 3837, 102762, 29077, 104381, 104383, 108704, 33108, 100204, 106362, 9370, 70538, 109487, 37945, 66017, 108704, 43815, 9370, 88991, 31905, 151645, 198, 151644, 872, 198, 108704, 25, 10904, 53040, 100060, 17992, 220, 10958, 19, 12, 17, 15, 20, 19, 197, 10904, 103283, 103714, 10958, 99497, 47764, 9754, 100296, 197, 10904, 52129, 100296, 29490, 13072, 10958, 112491, 197, 10904, 52129, 100296, 22704, 17992, 10958, 16, 24, 24, 23, 15, 19, 197, 10904, 52129, 100296, 18538, 17992, 10958, 16, 16, 23, 21216, 16, 17, 15, 197, 10904, 17177, 69674, 26853, 115, 10958, 42, 20, 197, 10904, 17177, 69674, 61105, 10958, 99489, 99497, 197, 10904, 110704, 22704, 17992, 10958, 16, 24, 24, 23, 15, 24, 197, 10904, 51461, 229, 220, 18137, 95, 246, 220, 10958, 88991, 103964, 99489, 110414, 99497, 101913, 100022, 104013, 197, 10904, 220, 19403, 220, 8908, 222, 227, 220, 10958, 101141, 23305, 99528, 197, 10904, 57421, 102335, 10958, 57421, 101141, 23305, 99528, 3837, 16, 24, 21, 19, 7948, 21287, 3837, 118044, 103176, 95411, 99891, 99307, 100022, 38176, 113311, 1773, 118044, 3837, 17, 18, 17, 15, 15, 16, 197, 10904, 71928, 96, 220, 53040, 220, 10958, 197, 100022, 99891, 99639, 64689, 102188, 68536, 108487, 9370, 99891, 1773, 88991, 99794, 33108, 103964, 101284, 100728, 104754, 104013, 104204, 31838, 101193, 9370, 99600, 3837, 20412, 100022, 99556, 104111, 99335, 106889, 1773, 18493, 99489, 100022, 9370, 45861, 99469, 15946, 3837, 107273, 107975, 101970, 100022, 104013, 3837, 101887, 105149, 9370, 76095, 33108, 99719, 3837, 100629, 99792, 106888, 105539, 1773, 101886, 3837, 106466, 113825, 100022, 100473, 52853, 100091, 107518, 3837, 88991, 103964, 100022, 104013, 96050, 100022, 99556, 57218, 100384, 101925, 118900, 1773, 14777, 220, 71928, 96, 33956, 103964, 99814, 110283, 104073, 101047, 100646, 64355, 27091, 104013, 99489, 110414, 99497, 20412, 116339, 99726, 5373, 104174, 100022, 1773, 116339, 99328, 102694, 112391, 99328, 101891, 3837, 100132, 103971, 99328, 100022, 99185, 100178, 101047, 102309, 100385, 1773, 16, 22, 101186, 56137, 16, 23, 101186, 107054, 106806, 105184, 99814, 110283, 104073, 3837, 11622, 116339, 100637, 106561, 34187, 112391, 100637, 3837, 54021, 34187, 116339, 100637, 56006, 112391, 100637, 109906, 108566, 33071, 1773, 101075, 3837, 114809, 99898, 99728, 104073, 62926, 99645, 99933, 110394, 9370, 104014, 17447, 99371, 100015, 99814, 110283, 1773, 100346, 102004, 17714, 100224, 9370, 1773, 108884, 104890, 18830, 99346, 101157, 5373, 101091, 17447, 31235, 108208, 110870, 3837, 67071],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'labels': [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100]
}
之后就可以开始模型微调训练了,核心代码实现如下所示:
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1, # Dropout 比例
)
model = get_peft_model(model, config)
args = TrainingArguments(
output_dir="./output/Qwen1.5",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=2,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="none",
)
swanlab_callback = SwanLabCallback(project="Qwen-fintune", experiment_name="Qwen1.5-7B-Chat")
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback],
)
trainer.train()训练日志输出如下所示:
{'loss': 7.6124, 'grad_norm': 22.37488555908203, 'learning_rate': 9.82e-05, 'epoch': 0.04}
{'loss': 0.0399, 'grad_norm': 0.43564164638519287, 'learning_rate': 9.620000000000001e-05, 'epoch': 0.08}
{'loss': 5.2448, 'grad_norm': 0.03180307522416115, 'learning_rate': 9.42e-05, 'epoch': 0.12}
{'loss': 0.5174, 'grad_norm': 1.6594655513763428, 'learning_rate': 9.22e-05, 'epoch': 0.16}
{'loss': 0.2535, 'grad_norm': 0.09797690808773041, 'learning_rate': 9.020000000000001e-05, 'epoch': 0.2}
{'loss': 1.2552, 'grad_norm': 0.01588798128068447, 'learning_rate': 8.82e-05, 'epoch': 0.24}
{'loss': 0.364, 'grad_norm': 3.6485328674316406, 'learning_rate': 8.620000000000001e-05, 'epoch': 0.28}
{'loss': 0.6956, 'grad_norm': 1.771950364112854, 'learning_rate': 8.42e-05, 'epoch': 0.32}
{'loss': 0.3075, 'grad_norm': 0.01094999723136425, 'learning_rate': 8.22e-05, 'epoch': 0.36}
{'loss': 1.9185, 'grad_norm': 0.0, 'learning_rate': 8.020000000000001e-05, 'epoch': 0.4}
20%|█████████████████████▍ | 100/500 [07:53<30:01, 4.50s/it]/opt/miniconda3/envs/v13/lib/python3.11/site-
{'loss': 1.059, 'grad_norm': 0.5624350309371948, 'learning_rate': 7.82e-05, 'epoch': 0.44}
{'loss': 0.101, 'grad_norm': 0.01450284756720066, 'learning_rate': 7.620000000000001e-05, 'epoch': 0.48}
{'loss': 0.0401, 'grad_norm': 0.29775163531303406, 'learning_rate': 7.42e-05, 'epoch': 0.52}
{'loss': 0.0174, 'grad_norm': 0.15098552405834198, 'learning_rate': 7.22e-05, 'epoch': 0.56}
{'loss': 0.6713, 'grad_norm': 43.16622543334961, 'learning_rate': 7.02e-05, 'epoch': 0.6}
{'loss': 0.0499, 'grad_norm': 0.07492603361606598, 'learning_rate': 6.82e-05, 'epoch': 0.64}
{'loss': 0.3148, 'grad_norm': 0.02868025004863739, 'learning_rate': 6.620000000000001e-05, 'epoch': 0.68}
{'loss': 0.003, 'grad_norm': 0.004959884565323591, 'learning_rate': 6.42e-05, 'epoch': 0.72}
{'loss': 0.0014, 'grad_norm': 0.01758139207959175, 'learning_rate': 6.220000000000001e-05, 'epoch': 0.76}
{'loss': 0.4409, 'grad_norm': 1.9896174669265747, 'learning_rate': 6.02e-05, 'epoch': 0.8}
40%|██████████████████████████████████████████▊ | 200/500 [15:55<24:11, 4.84s/it]/opt/miniconda3/envs/v13/lib/python3.11/site-
{'loss': 0.0978, 'grad_norm': 0.028909606859087944, 'learning_rate': 5.82e-05, 'epoch': 0.84}
{'loss': 0.0155, 'grad_norm': 11.9714937210083, 'learning_rate': 5.620000000000001e-05, 'epoch': 0.88}
{'loss': 0.0003, 'grad_norm': 0.010097901336848736, 'learning_rate': 5.420000000000001e-05, 'epoch': 0.92}
{'loss': 0.0007, 'grad_norm': 0.008554279804229736, 'learning_rate': 5.22e-05, 'epoch': 0.96}
{'loss': 0.3968, 'grad_norm': 0.0014622771413996816, 'learning_rate': 5.02e-05, 'epoch': 1.0}
{'loss': 0.0693, 'grad_norm': 0.0, 'learning_rate': 4.82e-05, 'epoch': 1.04}
{'loss': 0.1025, 'grad_norm': 0.07963917404413223, 'learning_rate': 4.6200000000000005e-05, 'epoch': 1.08}
{'loss': 0.0052, 'grad_norm': 0.0, 'learning_rate': 4.4200000000000004e-05, 'epoch': 1.12}
{'loss': 0.0036, 'grad_norm': 1.604474663734436, 'learning_rate': 4.22e-05, 'epoch': 1.16}
{'loss': 0.1487, 'grad_norm': 27.99481964111328, 'learning_rate': 4.02e-05, 'epoch': 1.2}
60%|████████████████████████████████████████████████████████████████▏ | 300/500 [23:58<16:03, 4.82s/it]/opt/miniconda3/envs/v13/lib/python3.11/site-
{'loss': 0.0771, 'grad_norm': 0.0013868745882064104, 'learning_rate': 3.82e-05, 'epoch': 1.24}
{'loss': 0.0153, 'grad_norm': 17.594120025634766, 'learning_rate': 3.62e-05, 'epoch': 1.28}
{'loss': 0.0082, 'grad_norm': 0.01603170670568943, 'learning_rate': 3.4200000000000005e-05, 'epoch': 1.32}
{'loss': 0.0002, 'grad_norm': 0.004378035198897123, 'learning_rate': 3.2200000000000003e-05, 'epoch': 1.36}
{'loss': 0.151, 'grad_norm': 0.0010229707695543766, 'learning_rate': 3.02e-05, 'epoch': 1.4}
{'loss': 0.0033, 'grad_norm': 0.0508929081261158, 'learning_rate': 2.8199999999999998e-05, 'epoch': 1.44}
{'loss': 0.1286, 'grad_norm': 0.005642883945256472, 'learning_rate': 2.6200000000000003e-05, 'epoch': 1.48}
{'loss': 0.0043, 'grad_norm': 0.0064104096964001656, 'learning_rate': 2.4200000000000002e-05, 'epoch': 1.52}
{'loss': 0.0021, 'grad_norm': 0.004222138784825802, 'learning_rate': 2.22e-05, 'epoch': 1.56}
{'loss': 0.5728, 'grad_norm': 0.003742243628948927, 'learning_rate': 2.0200000000000003e-05, 'epoch': 1.6}
80%|█████████████████████████████████████████████████████████████████████████████████████▌ | 400/500 [31:33<07:25, 4.45s/it]/opt/miniconda3/envs/v13/lib/python3.11/site-
{'loss': 0.1794, 'grad_norm': 29.71537208557129, 'learning_rate': 1.8200000000000002e-05, 'epoch': 1.64}
{'loss': 0.0009, 'grad_norm': 0.0028969631530344486, 'learning_rate': 1.62e-05, 'epoch': 1.68}
{'loss': 0.0078, 'grad_norm': 0.0028255439829081297, 'learning_rate': 1.42e-05, 'epoch': 1.72}
{'loss': 0.2443, 'grad_norm': 0.0032071759924292564, 'learning_rate': 1.22e-05, 'epoch': 1.76}
{'loss': 0.0008, 'grad_norm': 0.0019909152761101723, 'learning_rate': 1.02e-05, 'epoch': 1.8}
{'loss': 0.0005, 'grad_norm': 0.003456676611676812, 'learning_rate': 8.200000000000001e-06, 'epoch': 1.84}
{'loss': 0.0003, 'grad_norm': 0.0, 'learning_rate': 6.2e-06, 'epoch': 1.88}
{'loss': 0.0011, 'grad_norm': 0.3211739659309387, 'learning_rate': 4.2000000000000004e-06, 'epoch': 1.92}
{'loss': 0.0031, 'grad_norm': 0.0, 'learning_rate': 2.2e-06, 'epoch': 1.96}
{'loss': 0.0003, 'grad_norm': 0.00825373362749815, 'learning_rate': 2.0000000000000002e-07, 'epoch': 2.0}
{'train_runtime': 2340.6843, 'train_samples_per_second': 3.418, 'train_steps_per_second': 0.214, 'train_loss': 0.46298501745192333, 'epoch': 2.0}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 500/500 [38:58<00:00, 4.68s/it]基于训练好的模型随机选取样本进行推理测试,代码实现如下所示:
test_df = pd.read_json("new_test.jsonl", lines=True)[:10]
test_text_list = []
for index, row in test_df.iterrows():
instruction = row['instruction']
input_value = row['input']
messages = [
{"role": "system", "content": f"{instruction}"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
print("response: ", response)
messages.append({"role": "assistant", "content": f"{response}"})
result_text = f"{messages[0]}\n\n{messages[1]}\n\n{messages[2]}"
test_text_list.append(swanlab.Text(result_text, caption=response))
print("test_text_list: ", test_text_list)结果输出如下所示:

训练过程指标可视化如下所示:
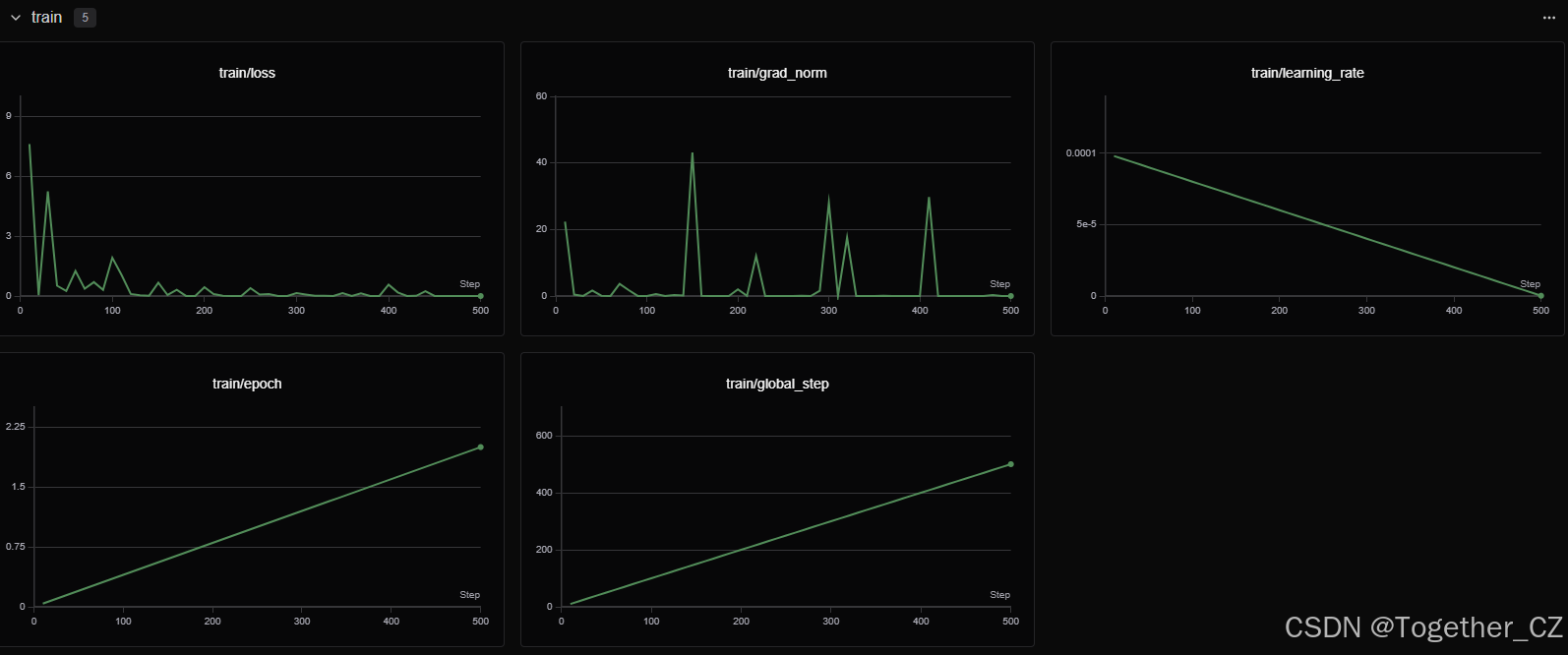
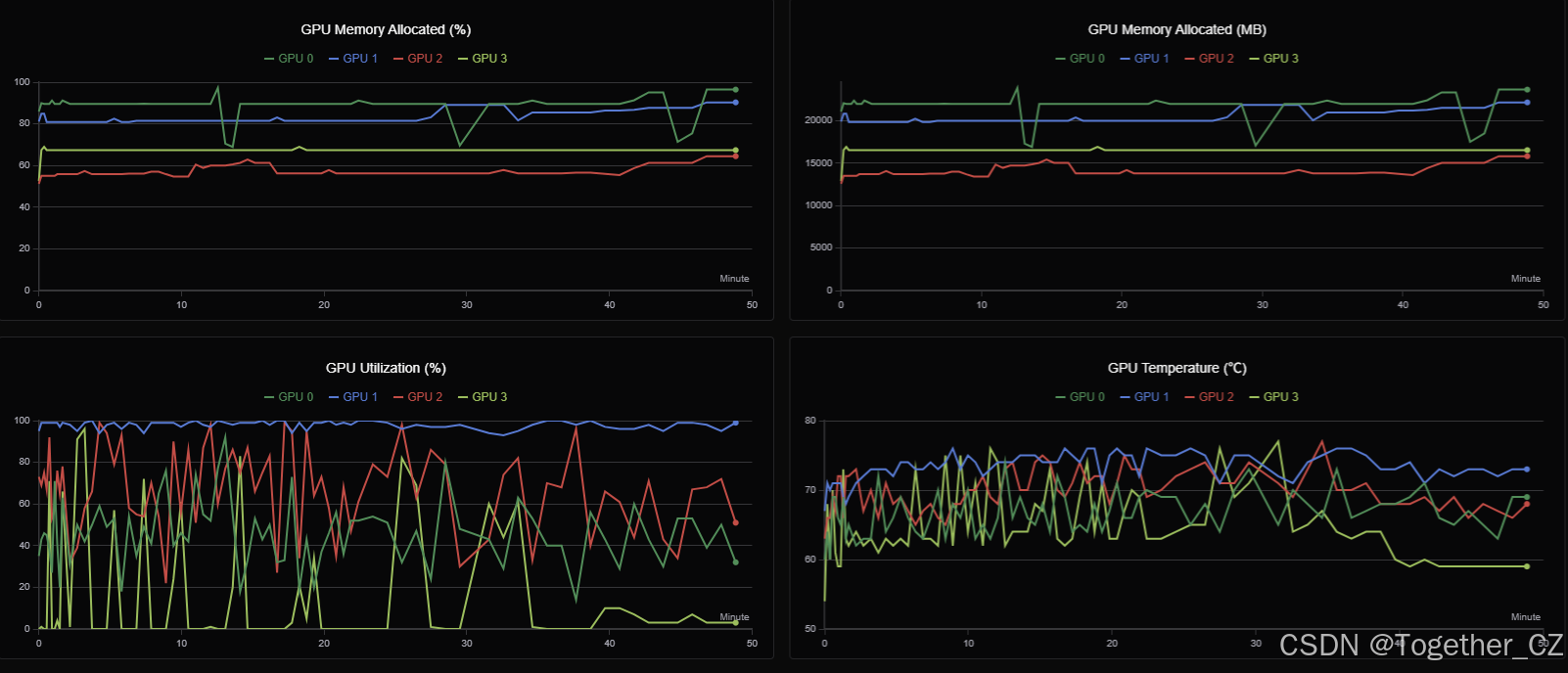
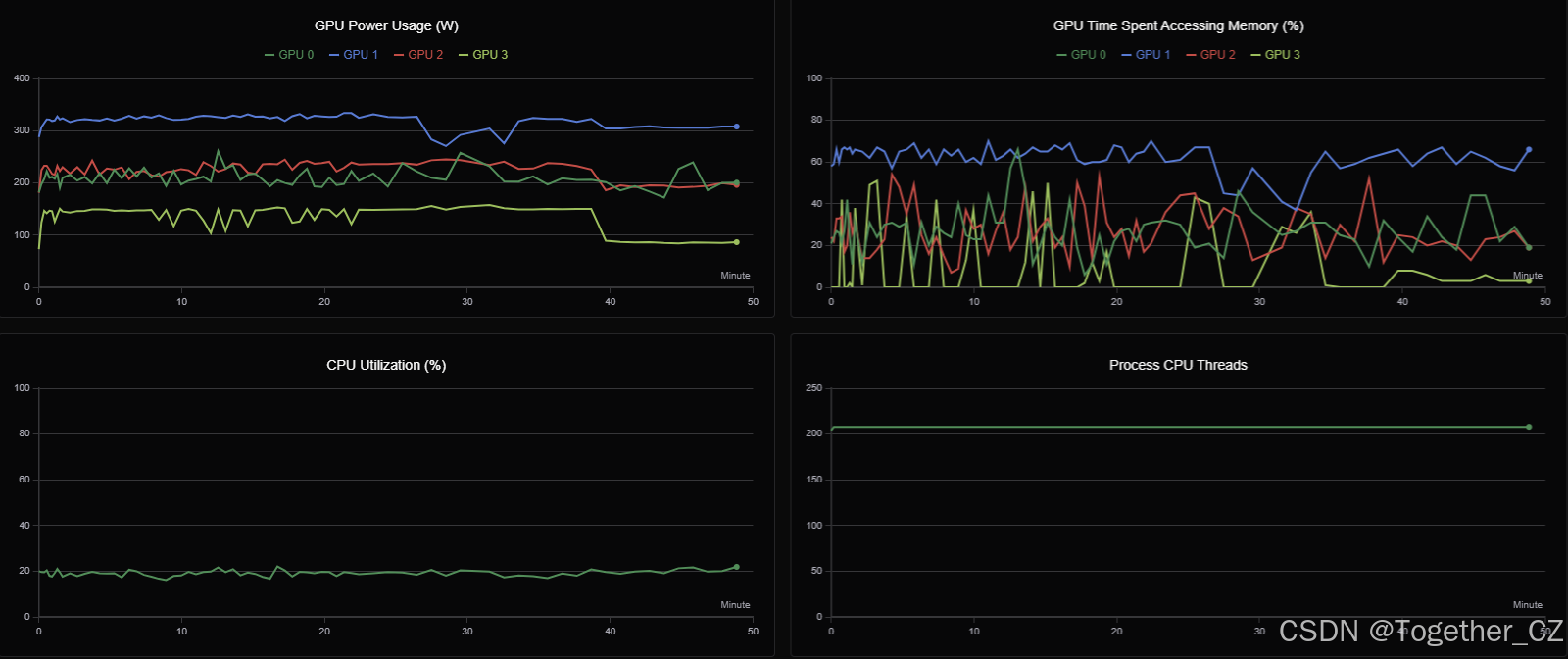
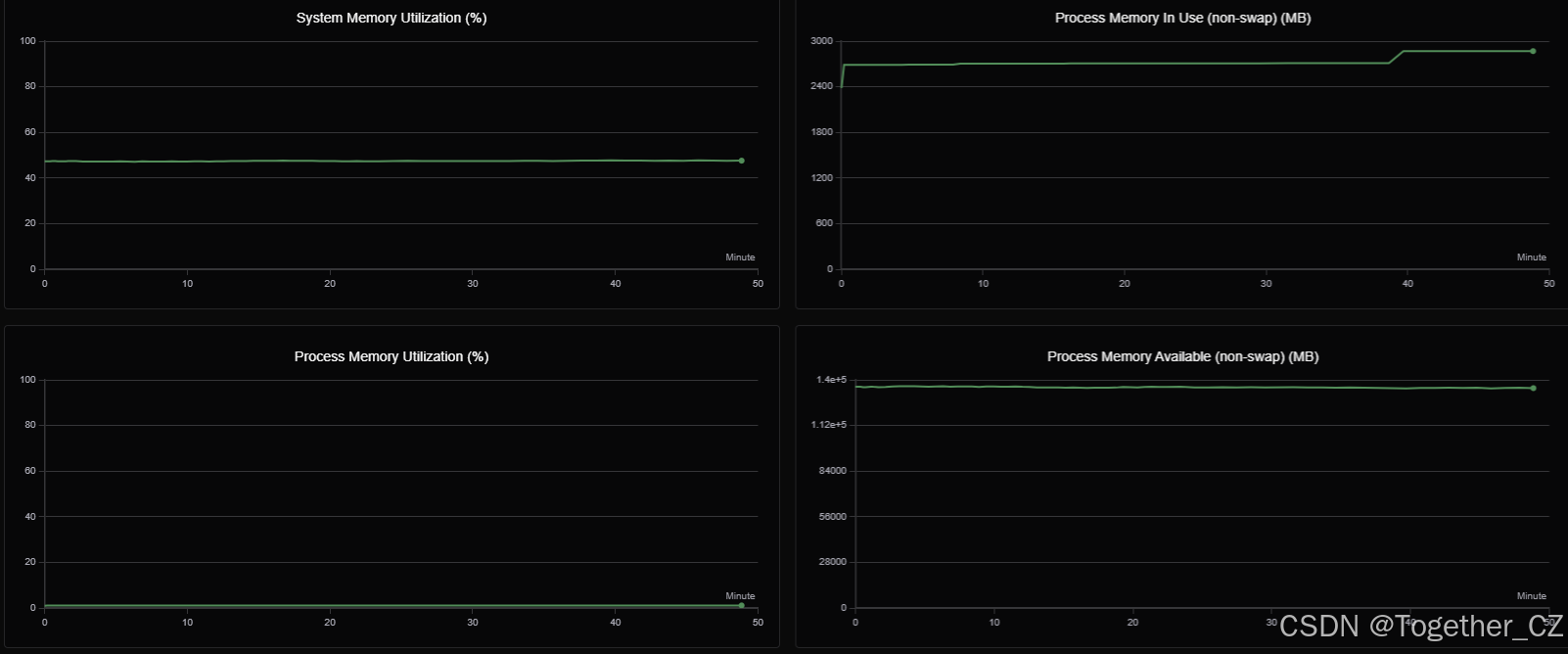
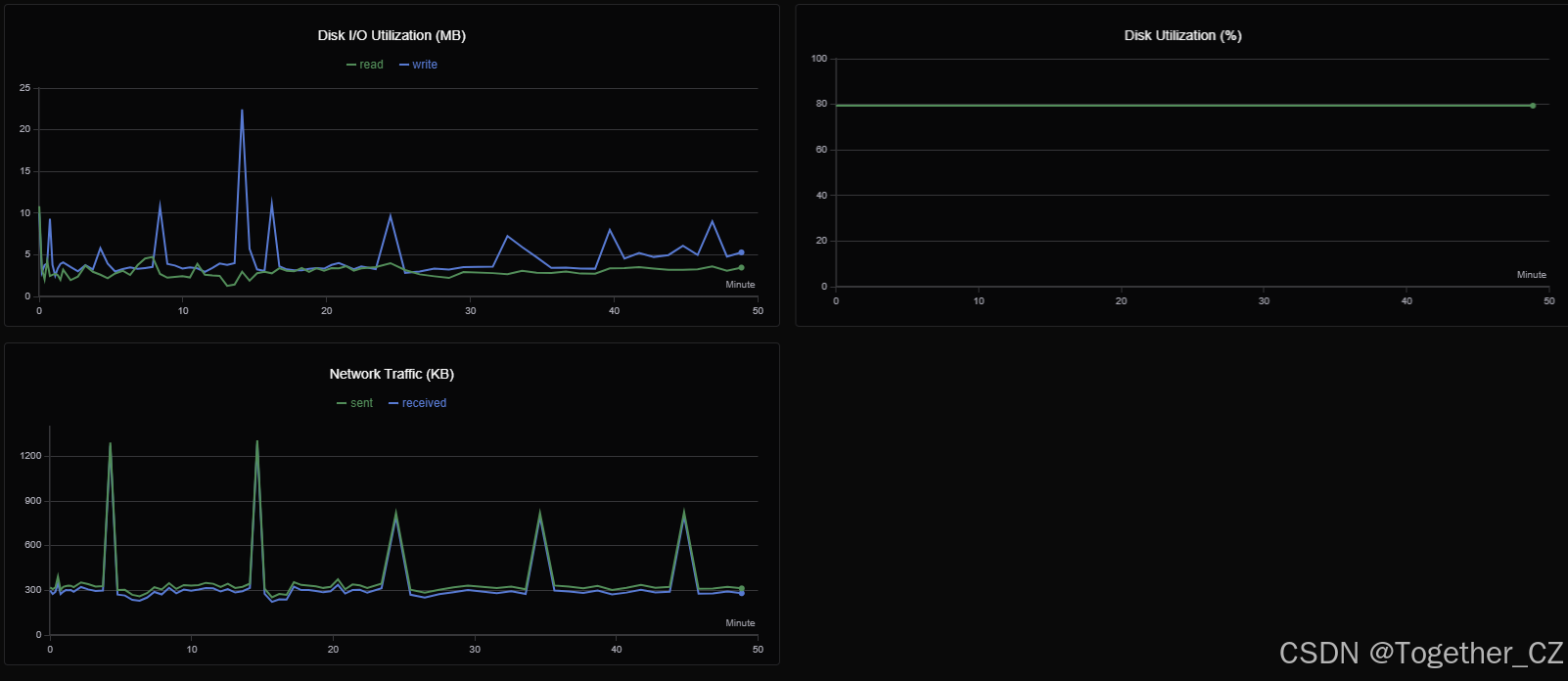
训练过程GPU硬件详情可视化如下所示: