🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在 pandas 和 scikit-learn 中使用基于图形的特征
在本章中,我们将利用您对图、图数据库以及可以从图结构中提取的不同类型的信息(节点重要性、社区和节点相似性)所学的知识,并学习如何将这些知识集成到机器中学习管道以根据数据进行预测。我们将从使用包含问卷信息的经典 CSV 文件开始,并以该数据为中心主题回顾数据科学项目的不同步骤。然后,我们将探讨如何将这些数据转换为图形,以及如何使用图形算法来表征该图形。最后,我们将学习如何使用 Python 和 Neo4j Python 驱动程序自动化图形处理。
本章将涵盖以下主题:
- 构建数据科学管道
- 图机器学习的步骤
- 使用基于图形的特征pandas和scikit-learn
- 使用 Neo4j Python 驱动程序自动创建基于图形的特征
技术要求
本章将使用以下工具:
- Neo4j 与 Graph Data Science 插件
- Python(推荐≥3.6)具有以下要求:
- neo4j,Neo4j官方Python驱动(≥4.0.2)
- networkx 用于 Python 中的图形管理(可选)
- matplotlib 以及用于数据可视化 seaborn
- pandas
- scikit-learn
- Jupyter 运行笔记本(可选)
如果您使用的是Neo4j < 4.0 ,那么GDS插件的最新兼容版本是1.1 ,而如果您使用的是Neo4j ≥ 4.0 ,那么GDS插件的第一个兼容版本是1.2 。
构建数据科学项目
机器学习可以定义为算法从数据中学习以便能够提取对某些业务或研究兴趣有用的信息的过程。
即使所有数据科学项目都不同,仍然可以确定一定数量的常见步骤:
- 问题定义
- 数据收集和清理
- 特征工程
- 模型构建和评估
- 部署
即使这些步骤遵循逻辑顺序,该过程也不是线性的,而是由这些不同步骤之间的来回操作组成。例如,在数据收集阶段之后返回问题定义以及根据需要多次返回特征工程和模型评估阶段以达到预期结果可能很有用。下图说明了在项目的不同步骤之间来回移动的想法: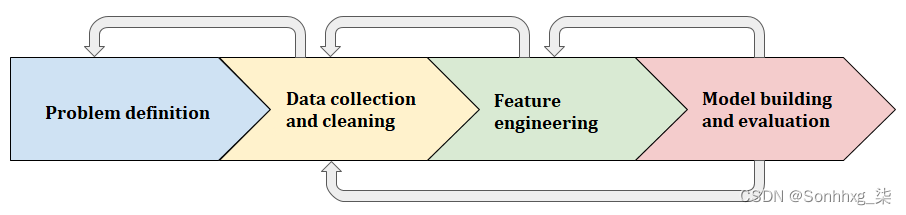
这种项目结构也适用于分析图数据,这就是我们将在本章中详细介绍这些步骤的原因。
问题定义——提出正确的问题
一个项目的成功取决于许多因素。无论是哪种项目,项目负责人从一开始就对目标和范围有一个很好的想法是至关重要的。就连著名的物理学家阿尔伯特·爱因斯坦也谈到了拥有明确目标的重要性:
即使这里的比例被夸大了,也体现了问题定义的重要性:需要解决的问题到底是什么?如果你不知道你在找什么,你就找不到它!这听起来很明显,但人们在开始项目时往往会忘记或忽略这一步。这个错误很容易导致数据科学项目失败。
作为数据分析师或数据科学家,您是该领域专家与算法数学世界之间的桥梁。虽然现场专家对数据和流程有良好的直觉,但作为技术专家,您可以判断项目的可行性,并根据输入(数据)、项目的预期长度和可用的工具(团队、CPU 等)。因此,您从项目规划过程的一开始就扮演着至关重要的角色;确保所有利益相关者了解项目限制是您的工作。例如,您可能需要说明您可以处理数据库中已有的图片,但处理视频需要更多的时间和金钱(用于数据收集、存储、学习如何使用工具等) .
当一个数据科学项目开始时,定义成功标准也很重要,以便以后决定项目是否成功。为此,我们需要定义一个指标,或关键绩效指标 ( KPI )——一个用作基准的量化变量。通常,这个 KPI 已经被经理计算为痛点这导致了项目的想法。重要的是要确保每个人都理解它是如何计算的并且可以被复制。即使您必须帮助定义该指标,也必须知道其初始值,以便衡量使用机器学习提供的改进。从那里,您可以决定一个阈值或最小百分比改进,这将使项目对每个人都真正成功,并且使用最先进的技术是可行的。
不要忘记,作为技术专家,你也有教学的作用,解释什么可以实现,什么不能实现,以及为什么。您将意识到花时间向参与项目的所有人员(从收集数据的人员到最终用户)解释一切简单的工作原理将为您节省数小时的困难,从长远来看,试图解决只是因为别人的误解而出现的问题。
在项目的这个阶段,您应该已经能够了解您需要使用的机器学习算法的类型:
- 有监督或无监督
- 回归或分类
监督学习与无监督学习
将机器学习定义为计算机学习已知观察结果以能够对看不见的数据进行预测的过程可能很诱人。然而,这个定义只反映了机器学习的一个子集,称为监督学习,只有当我们可以访问算法可以从中学习的一些标记数据时才有可能。如果不是这样,我们就不得不依赖无监督学习。
当标记数据存在时,这意味着我们有一些具有已知输出的观察结果。从那里,我们可以训练一个算法来根据观察的其他特征(即特征)来识别这个输出。在此训练阶段之后,算法将调整其参数,以便对训练数据进行最佳预测。然后,这些调整后的参数可用于对看不见的观察结果进行预测——即没有标签的数据。考虑到同一街区其他房屋的销售价格或邮政信封上的手写数字,这就是您可以预测房屋价格的方法。
无监督学习完全不同。当我们无法访问基本事实或某些数据的真实标签时使用它。聚类是无监督学习最著名的例子。在聚类算法中,您尝试找到观察值之间的相似性并创建共享一些共同模式的观察值组,但没有任何东西可以先验地告诉算法它是否正确。
我们在最后两章研究的算法——中心性和图上的社区检测算法——实际上是无监督算法,因为在运行算法之前我们对结果没有任何先验知识。请记住,在我们的 PageRank 实现中,所有节点的分数都是平等地初始化的。类似地,标签传播算法中节点的标签被初始化,使得每个节点都属于自己的社区。只有经过几次迭代,我们才能看到排名和社区出现。
标签传播是一种特殊的算法,因为当一小部分节点已经具有已知标签时,它可以以半监督的方式使用。该知识可用于推断其他节点的标签。
回归与分类
根据我们试图预测的变量的性质——即目标变量——我们可能面临回归或分类问题。如果目标是分类的,这意味着它只能取少量值,那么我们就有分类问题。分类问题的示例包括:
- 癌症检测:查看医学图像并确定肿瘤是癌性还是良性的从业者实际上是在对两类(癌症或非癌症)进行分类。
- 垃圾邮件检测:这是二分类问题的另一个示例(电子邮件要么是垃圾邮件,要么不是)。
- 情绪分析:当试图确定评论是正面的、负面的还是中性的时,我们将其分为三类。
- 手写数字分类:这里,目标值在0和之间9,我们有 10 个可能的类别。
回归问题本质上是不同的,因为目标变量是实数并且可以取无限数量的值。房价预测是回归的一个例子。
介绍本章的问题
在本章中,我们将从使用经典的 CSV 文件开始,我们将使用该文件来回顾机器学习项目的不同步骤,然后对其进行丰富以进行图分析。
上下文如下:在以图表为中心的会议期间,您向与会者提交了一份调查问卷,以了解更多关于他们的信息。在不同的问题中,其中之一是用户是否直接对 Neo4j 做出了贡献。不幸的是,并非所有参与者都回答了这个问题,但您想从给出答案的人中推断出其他人的状态。因此,我们遇到了一个监督分类问题,其目标类别对 Neo4j 有贡献或对 Neo4j没有贡献。
这个问题是否可以用数据和统计模型来解决取决于数据的可用性和质量,我们现在将对其进行量化。
获取和清理数据
如果您在一个组织中工作,您可能已经可以访问 IT 系统使用的一些数据集。然而,获取它们并格式化它们并不是那么简单。需要针对有效数据范围指定一些明确的要求——即可用和/或需要的特征列表。获取可用数据集可能需要与数据提供者进行多次迭代。在每次迭代中,都需要执行一些数据质量检查。当然,这些检查取决于要解决的问题,但其中一些是强制性的。例如,您总是需要询问它是否是优质数据以及您是否需要更多数据。
数据表征
首次查看数据集时,可以执行一定数量的检查。以下是我们需要从给定数据集中提取以便理解它的初步信息的非详尽列表。
量化数据集大小
可能最简单的信息和从数据集中提取的第一件事是它包含的行数或观察值。非常小的数据集可能会阻止某种分析。正如您在以下链接的图表中看到的那样,由scikit-learn开发团队创建,数据集中的观察数量是选择可用于解决问题的机器学习算法的关键因素。例如,根据scikit-learn算法备忘单,开始分析的推荐算法取决于数据集中的观察数量(参见:https ://scikit-learn.org/stable/tutorial/machine_learning_map/index.html )。
因此,让我们通过使用以下方法将 CSV 文件导入 DataFrame 来开始分析数据pandas:
import pandas as pd
data = pd.read_csv("data_ch8.csv")可以使用以下函数找到 DataFrame 的长度:
len(data)上述函数的结果表明我们的数据集包含 596 个观察值。这不是一个特别大的数据集,我们将在其余的处理过程中保持谨慎,不要丢弃观察结果。
标签
一旦知道了数据集的大小,接下来要收集的最重要的信息是数据集是否包含每个观察的标签。标签是算法应该针对您的问题的值。它可以是分类任务上下文中的文本或整数类,也可以是回归问题的实数。如果数据集包含标签,则我们处于监督学习的环境中。否则,我们有两种选择:要么依赖无监督技术,要么尝试从其他来源获取数据标签。
请记住,我们的问题在于确定用户是否对 Neo4j 做出了贡献。因此,我们的数据集确实通过名为 的列具有标签contributed_to_neo4j,因此我们处于监督分类问题中。我们可以使用 Python 包检查这个变量的分布, Python 包是为数据分析而构建seaborn的历史包的包装器。matplotlib例如,需要一行代码(除了导入!)来绘制显示每个类中元素数量的条形图:
import seaborn as sns
sns.countplot(x="contributed_to_neo4j", data=data);<matplotlib.axes._subplots.AxesSubplot at 0x7f67c047e950>
得到的分布如下图所示: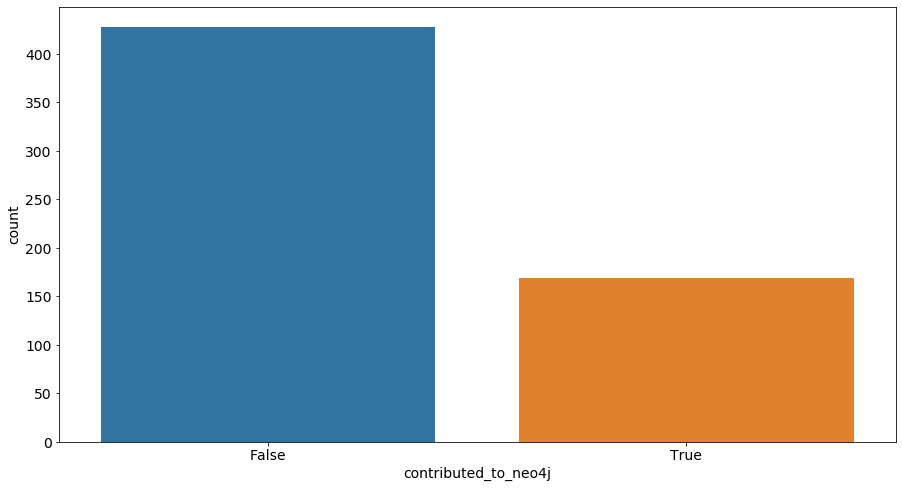
在填写问卷的 596 人中,169 人为 Neo4j 做出了贡献,427 人没有。没有为 Neo4j 做出贡献的用户数量等于为 Neo4j 做出贡献的用户数量的两倍多。这意味着我们在每个目标类之间的观察分布不均匀。据说这个数据集是不平衡的:它在False类别中的观察比带有标签的观察多。这是我们需要牢记的重要信息,因为它将影响结果的分析。True
Columns
数据集中的列包含“自然”特征。这是指在任何特征工程之前存在于初始数据集中的数据特征。
此时,确保特征定义清晰是很重要的。例如,如果数据集包含报告产品价格的列,该价格是否包括增值税?如果价格设置为 0,是否真的意味着它是免费的,或者它是默认值,以防填写数据的人或系统不知道实际价值?所有这些问题都需要回答,并涉及与数据集所有者的大量沟通。
列定义不是唯一需要描述的信息。在更进一步之前,您还必须描述每个特征。有两种可能的定义:
- 数值特征:其值为整数(房屋的楼层数)或浮点数(其表面积)的特征。如果要素表示物理量,例如表面,则必须包含单位(例如,英尺或米)。
- 分类特征:表示离散属性的特征,例如人的性别。它将由全文Male/Female或M/表示F,或编码为数字,例如1男性和2女性。这就是为什么获取功能描述非常重要的原因。分类特征可以从数字特征中创建——例如,将衬衫尺寸定义为Small、Medium等,根据其长度和/或宽度定义。这是特征工程工作的一部分。
pandas提供了两种有用的方法,可用于初步了解 DataFrame 的内容。第一个是info方法:
Columns它为我们的 DataFrame 显示以下结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 596 entries, 0 to 595
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 596 non-null int64
1 followers 594 non-null float64
2 publicRepos 594 non-null float64
3 contributed_to_neo4j 596 non-null bool
dtypes: bool(1), float64(2), int64(1)
memory usage: 14.7 KB该info方法告诉我们很多事情:
- DataFrame 包含 596 行(条目)。
- 它有四列:
- user_id是整数类型,并且永远不会为空。
- followers已被解释为浮点数pandas并且仅包含 594 个非空条目,这意味着两个观察值没有此信息。
- publicRepos也被解释为浮点数,也有两个缺失值。
- contributed_to_neo4j,我们的目标变量,是一个布尔值,永远不会为空。
要获取有关每一列的更多信息,我们可以使用以下describe方法:
data.describe()该方法的结果重现如下:
user_id followers publicRepos
count 596.000000 594.000000 594.000000
mean 3025.988255 93.457912 90.321549
std 5333.331601 525.309949 547.851252
min 1.000000 0.000000 0.000000
25% 188.750000 5.000000 11.000000
50% 337.500000 21.000000 28.000000
75% 486.250000 61.750000 63.750000
max 14599.000000 11644.000000 12670.000000对于所有数字列(int或float),pandas向我们展示了一些关于变量分布的统计信息:
- count(非空条目的数量)
- mean和标准差 ( std)
- min和max值_
- 中位数 ( 50%)
- 第一个和第三个四分位数 (25%和75%)
这些数字可以让我们了解变量可能值的范围。例如,我们已经可以看到我们的一些用户没有任何关注者或公共存储库 ( min=0)。
从这个结果中提取的另一个重要信息是异常值或异常值的存在。虽然 75% 的用户拥有少于 34 个公共存储库,但其中一个拥有 12,670 个!我们将在数据清洗阶段处理这类数据。
followers并且publicRepos似乎具有相似的分布,该describe方法报告的所有指标的值都非常接近。但仅凭这些指标是不够的;为了充分理解数据,我们将不得不制作更多图表。
数据可视化
除了我们可以从 DataFrame 描述中看到的均值、标准差和四分位数之外,我们还需要查看真实的数据分布。下图说明了数据可视化的重要性:
该图显示了两个变量的 13 个数据集:x和y。在每个数据集中,x变量的平均值为 54.26,平均值为y47.83。它们还具有完全相同的标准偏差(高达两位数精度)以及 和 之间的相同相关x性y。但是,形状完全不同,如果您要选择一种算法来预测y,x您可能不会为左下角的数据集(圆圈)选择与十字相同的方法。
我们将继续使用seabornPython 包进行可视化。例如,我们可以使用以下代码行在单个图中可视化每个特征的分布以及它们之间的相关性:
sns.pairplot(data, vars=("followers", "publicRepos"), hue="contributed_to_neo4j");前面的代码行将返回以下输出: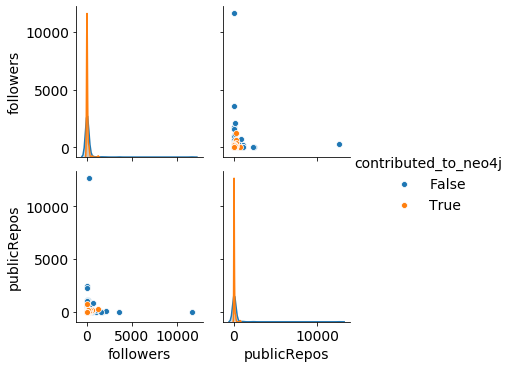
然而,由于我们在上一节中已经确定了异常值,这个图还不是特别有用。因此,让我们继续下一步,包括检查数据质量并在必要时进行一些清理。
数据清洗
现实生活中的数据从来都不是完美的。它可能包含无意的错误,甚至可能包含由于某种原因无法收集信息的数据丢失。
异常值检测
异常值出现在数据集中有两个主要原因:
- 人为错误:如果值是由人输入的,那么这个人很可能会不时犯错。他们可能会在一个数字的末尾输入一个额外的零,或者反转两个数字,这样我们最终的价格是 91 美元,而不是某些产品的 19 美元。
- 罕见的观察:尽管您的几乎所有产品的价格都低于 100 美元,但您可能有一些更昂贵的产品,最高可达 1,000 美元甚至更多。尝试对常见事件和罕见事件进行建模通常很复杂。因此,如果它对您不是特别重要;最好将罕见事件排除在模型之外。
有时,异常值实际上是您试图识别的异常情况——例如,用于网络中的欺诈或入侵检测。有几种方法可以识别异常值并处理它们;有些非常简单,有些更复杂。
在我们的示例中,我们将使用一种过于简化的方法,该方法包括用 value 替换高于 100 的值100:
data["publicRepos"] = data.publicRepos.clip(upper=100)
data["followers"] = data.followers.clip(upper=100)我们现在可以重现我们之前创建的配对图,它现在更具可读性: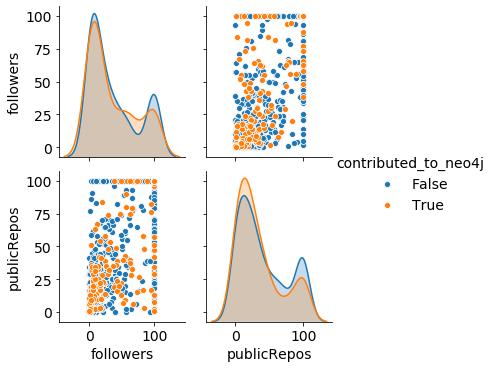
从前面的图中,我们可以看到为 Neo4j 做出贡献的人的公共存储库比其他人略少。下图中显示的箱线图证实了这一点:
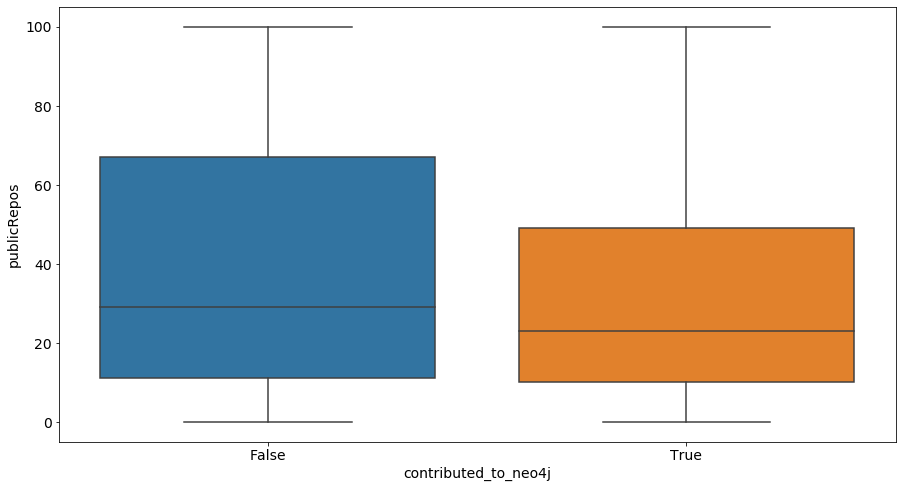
您还可以在以下关于关注者数量的图中看到类似的模式: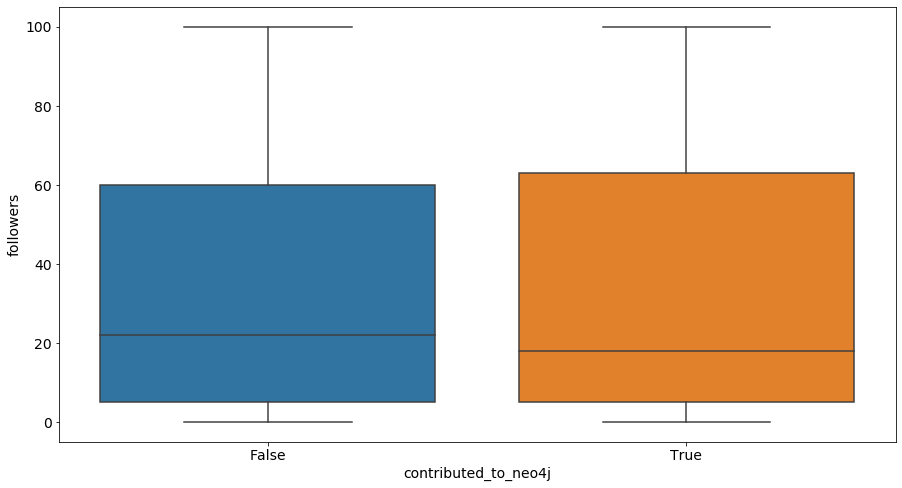
处理完异常值后,我们需要停下来看看缺失的数据。
缺失数据
缺失数据是数据科学家在现实生活中必须处理的另一个话题。由于疏忽、缺乏信息或仅仅因为信息不相关,某些字段可能无法填写。
虽然一些机器学习算法能够处理丢失的数据,但如果您的数据集包含这些值,它们中的大多数将无法正确处理数据并引发错误。因此,找到一种去除它们的方法会更安全。如果您的数据集很大并且缺失的数据量只占其中的一小部分,您可以简单地删除包含不完整信息的观察。但是,在大多数情况下,保留所有信息并尝试弥补丢失的信息是一种很好的做法。这样做的一种方法是使用所有已知观测值的平均值作为缺失数据的观测值的默认值。通过这种方式,观察结果被保留,并且在大多数情况下,假的我们整合到模型中的数据不会对模型预测产生很大影响。
变量之间的相关性
这些检查将使我们能够理解数据,因此检查是问题定义之后的第二个最重要的步骤。这样做将排除一些在某些类型的数据上表现不佳的算法: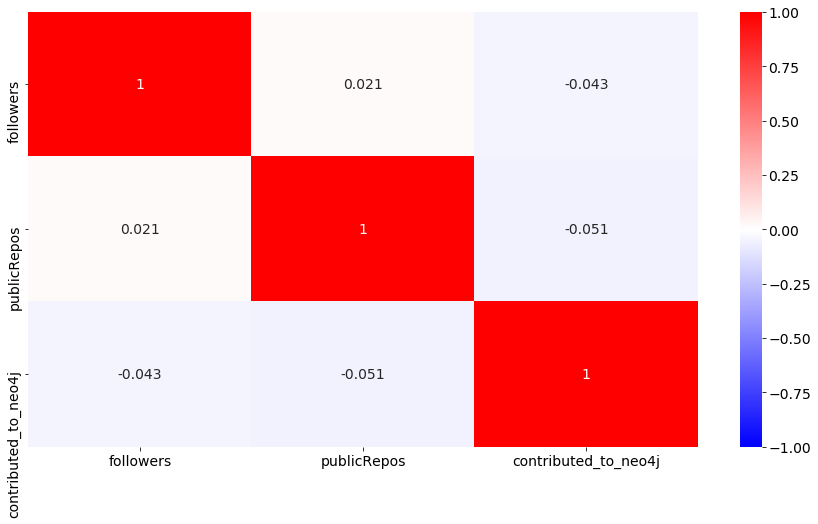
正如前面的矩阵所示,我们的目标变量contributed_to_neo4j和剩余的两个特征publicRepos和之间的相关性followers非常低。对于彼此弱相关的两个特征(0.021)也是如此;这告诉我们,我们可以保留它们并继续下一步。
数据丰富
在这一点上,我们必须解决的主要问题是这些数据是否足以回答问题?我们可能会问,是否缺少重要功能? 我们是否可以考虑另一个数据集以向该数据添加更多信息?
例如,如果您的问题是关于预测房价,并且您的数据包含用户输入的房屋地址,则地址可以写为5th Avenue、Fifth avenue或什至Av. 5。在这种情况下,可能需要一个标准化步骤,以便所有地址具有相同的格式并且可以识别公共地址。此外,地址的位置(以纬度和经度表示)对于计算距离很重要,例如。这意味着需要进行地理编码步骤。
此时,您还可以查看与您的问题相关的开放数据页面。考虑以下:
- 州和国家维护网站以列出官方政府机构发布的所有公开可用的数据集。例如,您可以在 https://data.gov.uk/ 找到来自英国的所有开放数据,在https://www.data.gov找到美国开放数据。您可以在这些网站上找到很多信息,从每个地理区域的居民数量到学校或其他公共服务的位置。
- Google 在https://datasetsearch.research.google.com/上提供搜索公共数据集的服务。
特征工程
特征工程是基于现有“自然”特征为机器学习算法创建新输入变量的过程。在仔细研究观察特征并与领域专家讨论后,您可能想要创建新特征。例如,房地产经纪人可以告诉您,对于给定的表面积,三间卧室的房子比两间卧室的房子要贵。您的数据是否已经包含考虑此信息的功能?如果没有,你能根据平方英尺和卧室的数量来建造它吗?这些是可以在项目的这个阶段回答的问题。
同样重要的是要知道,某些算法只会在标准化特征上表现良好,这意味着特征分布必须是正态的。在运行这些算法之前,您需要转换数据以使分布与预期的分布相匹配。
构建模型
一旦您对项目的目标有了清晰的认识,并且已经收集和清理了数据,就可以开始建模阶段了。
训练/测试拆分和交叉验证
当我们有一个数据集时,最好使用所有可用的观察来训练模型,因为通常,更多的数据会带来更好的性能。然而,通过这样做,我们冒着陷入这样一种场景的风险:模型完全能够对它已经看到的数据进行建模,但对看不见的数据表现得非常糟糕——这被称为过拟合场景。
看看下面的情节: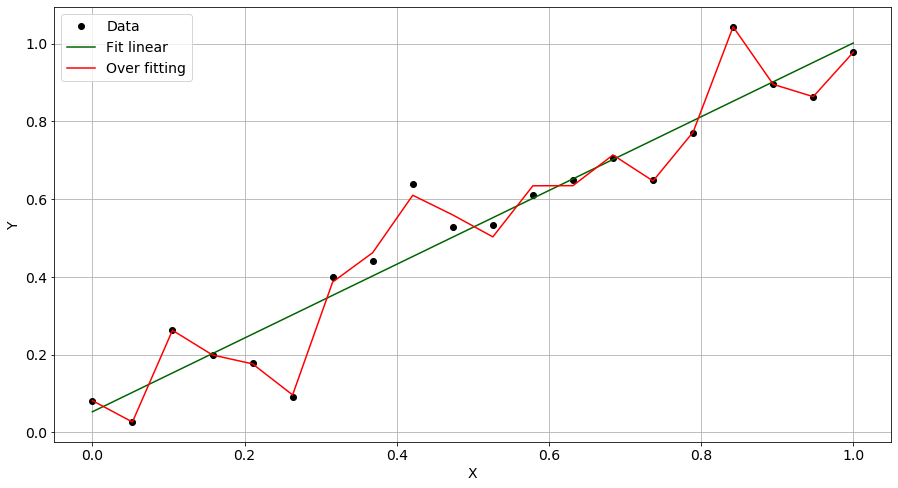
观察结果用黑点绘制,绿线代表基本事实——即真正的基础模型。结果用红线显示的模型在预测观察数据的值方面表现非常好,但在描述看不见的数据方面表现不佳。换句话说,它在训练集上过拟合了。为了避免这种情况,我们需要保留一些模型在训练阶段根本看不到的观察结果。训练完成后,我们将能够在此测试样本上测试模型性能。如果与训练阶段相比,该模型在该样本上的表现不佳,则可能表明过度拟合。
使用 scikit-learn 创建训练和测试样本
将数据拆分为训练集和测试集并不简单。训练集和测试集都必须代表完整的数据集。如果您的数据集包含从 15 到 200 平方米的公寓大小,则使用面积小于 50 平方米的观测值作为训练集并将其余的作为测试集可能不是一个好主意。这是行不通的,因为火车和测试样本都必须包含整个范围内的区域。随机拆分数据通常就足够了,并且可以很好地表示两组中的特征。
然而,有些情况确实需要不同的方法,我们应该考虑到这些——例如,当目标变量(或任何分类特征)不平衡时,这意味着某些类占主导地位。在这种情况下,我们需要确保训练样本和测试样本都遵循相同的类重新分区并包含所有可能的值。这称为分层,可以使用scikit-learn工具来实现。
为此,我们首先需要创建目标变量y和X包含我们感兴趣的特征的数组。到目前为止,我们只有两个特征:关注者的数量和用户的公共存储库的数量。我们可以使用以下命令创建这些变量:
features = ["followers", "publicRepos"]
y = data.contributed_to_neo4j
X = data[features]两者都y需要X拆分为训练样本和测试样本。这是通过以下代码实现的:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3,
random_state=123,
stratify=y
)您可以看到该stratify参数确保训练和测试样本都尊重目标变量的比例contributed_to_neo4j。
训练模型
在本章中,我们将使用一个简单的决策树分类器。可以scikit-learn使用以下方法对其进行训练:
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=123, min_samples_leaf=10)
clf.fit(X_train, y_train)但是,如果您在我们当前的数据集上运行此代码,您将收到一些错误,因为决策树不知道如何处理NaN或丢失数据,并且我们有几行缺少信息。
为了填充这些NaN值,我们将使用一个SimpleImputer模型,该模型将用NaN每个特征的平均值替换这些值。按照scikit-learnAPI,我们需要在我们的训练样本上训练转换器:
from sklearn.impute import SimpleImputer
imp = SimpleImputer(strategy='mean')
imp.fit(X_train)然后,我们需要在训练和测试样本上实际执行转换:
X_train = imp.transform(X_train)
X_test = imp.transform(X_test)一旦数据被转换,就可以进行决策树训练。使用经过训练的模型,我们可以使用以下内容进行预测:
clf.predict(X)但是,在生产环境中使用此模型之前,是时候通过使用我们专门为此保留的测试样本评估模型性能来测试训练质量了。
评估模型性能
根据您的目标,可以使用不同的指标来衡量模型的性能。在处理回归时,常用的度量标准是均方误差( MSE ),它量化了真实值和预测值之间的平均距离。MSE 越低,模型越好。
然而,在分类问题中,使用这个度量是没有意义的,尤其是对于多类问题。
在运行分类器时,我们可能要检查的第一个指标是准确度A,它由正确分类的观察数除以观察总数定义。
scikit-learn我们可以使用以下方法计算准确度:
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)在这里,y_pred使用我们的拟合分类器为测试样本计算:
y_pred = clf.predict(X_test)这个函数会告诉我们,我们的整体准确率为 66%,这对于机器学习模型来说并不是一个了不起的分数——让我们来探索一下细节。
正如我们之前所讨论的,我们的数据集包含两个目标类别之间的类别不平衡,未对 Neo4j 做出贡献的用户数量大约是对其做出贡献的用户数量的两倍。获得有关被决策树错误分类的观察的更精确信息会很有趣。为此,让我们看一下分类器的混淆矩阵:
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(
clf, X_test, y_test,
cmap=plt.cm.Blues,
values_format="d"
);我们的决策树的混淆矩阵在下图中重现:
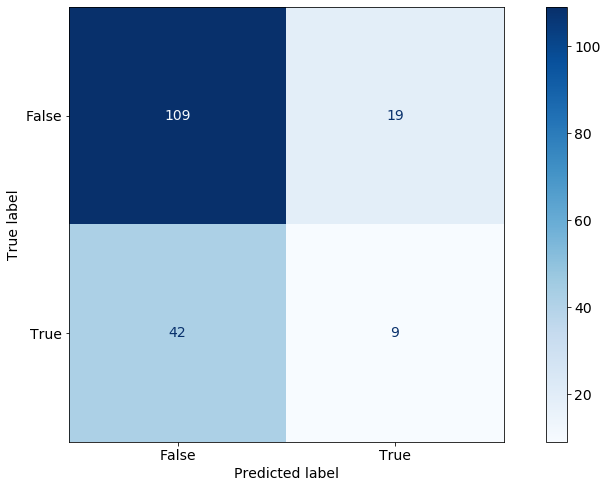
如您所见,没有为 Neo4j 做出贡献的用户的分类相当不错。对于True等于False(未对 Neo4j 做出贡献的用户)的标签,只有 19 个被错误地分类到该True类别中,如顶行所示。False在测试样本中有标签的 128 (109 + 19) 个用户中,有 109 个被正确分类;这意味着这个类的成功率为 85%(这个指标称为召回)。另一方面,我们的模型完全无法识别为 Neo4j 做出贡献的用户;51 个中只有 9 个被确定。
scikit-learn提供另一个有用的功能,将显示更精确的指标,称为classification_report. 它可以通过以下方式使用:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))此报告的快照在此处复制:
precision recall f1-score support
False 0.72 0.85 0.78 128
True 0.32 0.18 0.23 51
accuracy 0.66 179我们可以识别出我们之前计算的 66% 的准确度得分和False测试样本中具有 128 个观察值的标签的 85% 召回率。
虽然召回是衡量模型效率的指标(有多少真实True标签被预测为真实),但精度是衡量结果纯度的指标。测量纯度解决了算法标记的所有观察结果中的问题 True ,有多少实际上有 True 标签?
number_of_users_not_contributing_to_neo4j / number_of_users = 427 / 596 = 72%。
所以,我们可以说我们的模型比虚拟模型还要糟糕——还有很大的改进空间!
现在是时候返回数据收集和/或特征工程步骤了。由于这本书是关于图的,我们将在下一节研究图如何帮助我们在分类任务中获得更好的准确性。
本节非常快速地总结了数据科学项目的不同步骤。如果您不熟悉该主题,请参阅本章末尾的进一步阅读部分。
本节中描述的管道是通用的,并没有明确涉及图形。在不改变整体策略的情况下,现在让我们关注如何将图表逐步集成到这个过程中。
图机器学习的步骤
Neo4j 主要是一个数据库,可以用来获取数据。但是,需要改变视角来将数据表示为图,以及通过使用图算法并将问题表述为图问题来利用这种图结构。
构建(知识)图
当开始从数据集构建图表时,要问的主要问题是这些数据中存在哪些关系?如果我们仅考虑我们在上一节中研究的 CSV 文件,它不包含很多关于关系的信息,因为它只有聚合数据,例如每个用户的关注者数量。
要了解有关数据关系的更多信息,我们将不得不丰富这个数据集。这可以通过两种方式完成。我们可以像第 3 章一样使用外部数据源,使用Pure Cypher 赋能您的业务,或者我们可以改变我们查看关系数据的方式。
从现有数据创建关系
数据可以来自不同类型的数据库。在理想情况下(用于图形分析),它已经存储在 Neo4j 图形中,但大多数时候,您将从更经典格式的数据开始,例如 SQL。在后一种情况下,您仍然可以创建一个图形结构并将这些数据以简单的方式导入到 Neo4j 中。
从关系数据创建关系
可以从现有(关系)数据创建关系。例如,购买相同产品或观看相同电影的客户具有某种形式的关系,即使它不是真正的社会关系。有了这些信息,我们就可以找到这些人之间的联系。这个链接甚至可以加权,这取决于他们购买的产品数量。
让我们考虑一个例子,我们有以下三个表的简化 SQL 模式:
- 具有列 ID 的用户
- 具有列 ID 的产品
- columns user_id带有和的订单product_id
要查找购买相同产品的用户之间的关系,我们可以使用以下查询:
SELECT
u1.id,
u2.id,
count(*) as weight
FROM users u1
JOIN users u2 ON u1.id <> u2.id
JOIN orders o1 ON o1.user_id = u1.id
JOIN orders o2 ON o2.user_id = u2.id AND o1.product_id = o2.product_id此查询的结果可以保存到 CSV 文件中,然后使用 CSV 导入工具(CypherLOAD CSV或 Neo4j 导入工具)导入 Neo4j。
从 Neo4j 创建关系
在观察值之间已经存在某些关系的情况下,相同的数据也可以已经存储在 Neo4j 图中。但是,我们对用户交互感兴趣,除非您的网站具有允许用户相互关注的社交组件,否则我们将不得不以不同的方式在用户之间创建链接。
假设您的图表包含有关用户和产品的信息。简化的图形模式可能如下所示:
(u:User)-[:BOUGHT]->(p:Product)在购买了相同产品的用户之间创建关系就像单个 Cypher 查询一样简单:
MATCH (u1:User)-[:BOUGHT]->(p:Product)<-[:BOUGHT]-(u2:User)
WITH u1, u2, count(p) as weight
CREATE (u1)-[:LINKED_TO {weight: weight}]->(u2)您的图表现在包含一个额外的关系类型,LINKED_TO它包含用户之间的某种虚拟交互,可以帮助您提取更多相关信息。
使用外部数据源
在第 2 章“ Cypher 查询语言”和第 3 章“使用 Pure Cypher 为您的业务赋能”中,我们研究了从不同数据源(例如外部 API(GitHub)或 Wikidata)丰富知识图谱的方法,以便为数据。
我们将在本章中利用这些知识。感谢 GitHub API,我们可以检索每个用户的关注者列表。这个练习在第 2 章,Cypher 查询语言中进行过,这里不再重复。结果在data_ch8.edgelist 文件中可用,我们现在将其导入 Neo4j。
将数据导入 Neo4j
为了将这些数据导入 Neo4j 并创建图表,我们首先必须导入用户的数据(节点),然后从edgelist文件中创建它们之间的关系。将这两个文件复制到 Neo4j 图形的导入文件夹后,您可以使用以下两个查询来导入数据:
- 运行以下命令来导入节点:
LOAD CSV WITH HEADERS FROM "file:///data_ch8.csv" AS row
CREATE (u:User) SET u=row- 运行以下命令来导入关系:
LOAD CSV FROM "file:///data_ch8.edgelist" AS row
FIELDTERMINATOR " "
MATCH (u:User {user_id: row[0]})
MATCH (v:User {user_id: row[1]})
CREATE (u)-[:FOLLOWS]->(v)将数据导入 Neo4j 后,就像我们在上一节中对 CSV 文件所做的那样,我们将对这些数据进行表征。
图表征
正如我们之前对表格数据所做的那样,我们现在将花时间收集一些关于我们的图形数据的通用信息,以便更好地理解它。
节点数和边数
User我们可以使用简单的 Cypher 查询来计算带有标签的节点数:
MATCH (u:User) RETURN count(u)但是,如果您的图表更复杂并且包含多个节点标签和关系类型,则使用 APOC 过程会更有效:
CALL apoc.meta.stats()您将得到的结果将是这样的: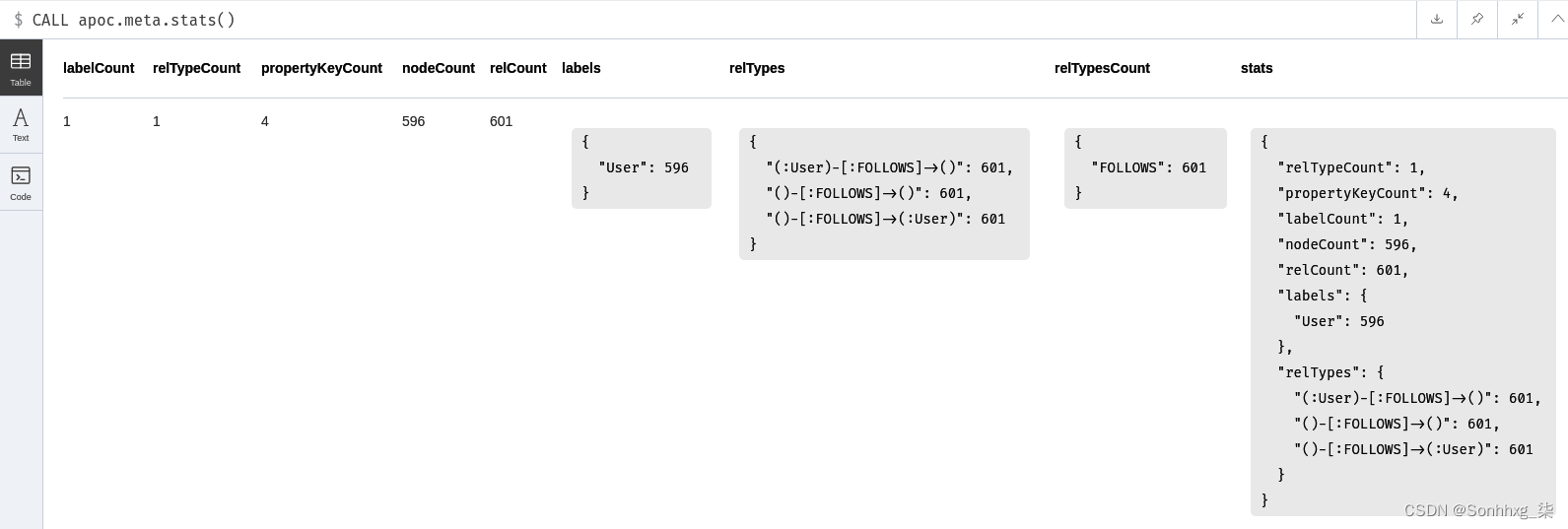
第六列包含每个标签的节点数,而第八列显示每种类型的关系数。
来自同一插件的另一个有趣的过程如下:
CALL apoc.meta.data()我们的图表的此过程的结果在以下屏幕截图中重现: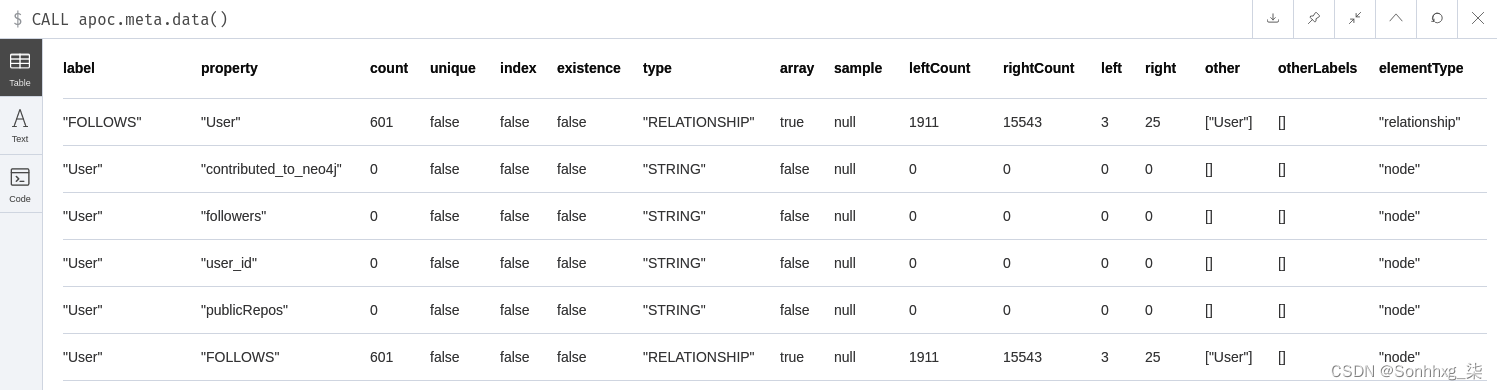
您可以看到,在前面的屏幕截图中,每个节点标签都有一个属性列表。在我们的图中,带有标签的节点User具有四个属性(contributed_to_neo4j、followers、user_id和publicRepos)。
通过这些函数,我们可以了解数据量。为了更准确地了解图结构,我们将不得不依赖图算法,例如我们在上一章(第 7 章,社区检测和相似性度量)中研究过的弱连通分量( WCC )社区检测算法。
组件数量
为了了解图结构,第一个常见步骤是识别图组件或独立子图。为此,我们将使用 GDS 中的 WCC 算法。
在本例中,我们将使用匿名投影图:
CALL gds.wcc.write({
nodeProjection: "User",
relationshipProjection: {
FOLLOWS: {
type: "FOLLOWS",
orientation: "UNDIRECTED",
aggregation: "SINGLE"
}
},
writeProperty: "wcc"
})此过程执行以下所有操作:
- 运行WCC算法。
- wcc通过添加对每个节点调用的属性将结果写回图形。
- User使用带有标签的所有节点和带有FOLLOWS类型的所有关系,忽略关系方向并考虑两个相同节点之间的一条边——如果 A 跟随 B 并且 B 跟随 A 并且图是无向的,我们将在 A 之间有两条边B,添加聚合。该SINGLE参数强制 GDS 只使用其中之一。
我们来分析一下这个算法的结果。以下查询将返回具有最多节点数的组件:
MATCH (u:User)
RETURN u.wcc, count(u) as c
ORDER BY c DESC
LIMIT 5结果的第一行复制如下:
╒═══════╤═══╕
│"u.wcc"│"c"│
╞═══════╪═══╡
│1 │438 │
├───────┼───┤
│30 │31 │
├───────┼───┤
│470 │1 │
├───────┼───┤
│471 │1 │
├───────┼───┤
│0 │1 │
└───────┴───┘如您所见,该图由一个包含 596 个节点中的 438 个节点的大组件组成。它还包含另一个较小的组件,由 31 个节点组成。据我们所知,所有其他用户 (127) 都没有连接到任何其他用户。
为了更深入地了解图结构,我们可以尝试使用例如 Louvain 算法来识别更精细的社区。该算法的结果如下图所示,使用neoviz.js,如前一章所述:
提取基于图的特征
现在我们已经将数据导入 Neo4j 并且我们对图结构有了更好的了解,我们可以开始考虑我们可以创建的基于图的特征类型来改进我们的分类模型。在本节中,我们将通过浏览器创建它们。然后,我们将研究如何使用 Neo4j Python 驱动程序自动执行此步骤。
如上图所示,该图似乎具有清晰的社区结构,并且可以假设为相同存储库做出贡献的用户彼此之间的联系更紧密。因此,使用社区检测算法的结果作为我们分类器的特征可以提高分类性能。
可以从图中提取的另一条信息是节点重要性。由于我们的用户图非常以 Neo4j 为中心,因此假设 Neo4j 贡献者是 PageRank 方面最重要的节点,这将是一个薄弱的假设。
因此,在下文中,我们将运行并保存两种算法的结果:
- 中心性得分的 PageRank
- Louvain 用于更窄的社区检测
为了在生产中使用 GDS 中的算法,建议执行以下三个步骤:
- 定义和创建投影图:投影图仅包含来自完整 Neo4j 图的节点、关系和属性的子集,并且针对图算法进行了优化。
- 在这个投影图上运行一种或几种算法。
- 删除投影图:投影图保存在计算机的实时内存中,因此最好在完成后删除投影图。
如果您已经阅读了前面的章节,那么您应该已经熟悉这些步骤。但是,在检查这些新功能如何改进我们的分类模型之前,我们将在下一节中再次回顾它们。
在 pandas 和 scikit-learn 中使用基于图形的特征
在上一节中,我们创建了一个连接用户的图模型。我们还运行了一些图算法来理解图结构。我们现在将充分利用 GDS 来提取基于图的特征。
从 Neo4j 浏览器中提取基于图形的特征
在原型设计阶段,能够手动运行单个查询并从中提取数据总是好的。在以下小节中,我们将回顾如何在 Neo4j 浏览器中从 GDS 运行图形算法,以及如何将数据提取为我们的数据科学工具可用的格式——即 CSV。
创建投影图
我们可以使用与上一节相同的参数创建一个命名投影图:
nodeProjection: "User",
relationshipProjection: {
FOLLOWS: {
type: "FOLLOWS",
orientation: "UNDIRECTED",
aggregation: "SINGLE"
}
}然而,我们知道我们的图包含几个不连贯的组件,并且在这样的图上运行 PageRank 算法可能会导致令人惊讶的结果。为了避免这种情况,我们将仅在 WCC 算法识别的最大组件上运行我们的两个算法。此选择必须通过 Cypher 查询来实现。在您确定了wcc用户数量最多的社区的属性值之后,您可以使用以下内容:
CALL gds.graph.create.cypher(
"graph",
"MATCH (u:User) WHERE u.wcc = 1 AND v.wcc = 1 RETURN id(u) as id",
"MATCH (u:User)-[:FOLLOWS]-(v:User) RETURN id(u) as source, id(v) as target"
)运行一种或多种算法
创建投影图后,我们可以使用以下命令运行 PageRank 算法:
CALL gds.pageRank.write("graph", {writeProperty: "pr"})我们还可以使用 Louvain 算法:
CALL gds.louvain.write("graph", {writeProperty: "lv"})Louvain 算法的结果显示在上一节末尾的图中。我们将在以下部分分析 PageRank 算法的结果。
删除投影图
一旦算法完成并将特征写入 Neo4j 图中,投影图就不再需要并且可以删除:
CALL gds.graph.drop("graph")这将释放笔记本电脑/服务器上所需的内存。
提取数据
我们的节点现在还有另外三个属性—— wcc、pr和lv—— 我们想要在预先存在的属性之上提取它们。我们可以使用以下 Cypher 代码来做到这一点:
MATCH (u:User)
RETURN
u.contributed_to_neo4j as contributed_to_neo4j,
u.followers as followers,
u.publicRepos as publicRepos,
u.wcc as wcc,
u.pr as pr,
u.lv as lv此查询的结果可以直接从浏览器下载为 CSV。
这在尝试构建模型时很有用;但是,这在生产环境中是不可行的。这就是为什么下一节专门使用 Neo4j Python 驱动程序来自动化这些步骤。
使用 Neo4j Python 驱动程序自动创建基于图形的特征
使用 Cypher 创建我们的功能有利于测试,但是一旦我们进入生产阶段,手动执行此类操作是无法管理的。幸运的是,Neo4j 官方提供了多种语言的驱动程序,包括 Java、.NET 和 Go。在本书中,我们使用 Python,因此我们将在下一节中了解 Python 驱动程序。
发现 Neo4j Python 驱动程序
Python 得到 Neo4j 的正式支持,Neo4j 提供了一个驱动程序,可以在https://github.com/neo4j/neo4j-python-driver上从 Python 连接到 Neo4j 图。
它可以通过pipPython 包管理器安装:
pip install neo4j
# or
conda install -c conda-forge neo4j为了使用这个数据库,第一步是连接定义,它需要活动图 URI 和身份验证参数。bolt是 Neo4j 设计的客户端-服务器通信协议。协议用于活动数据库的端口bolt可以在 Neo4j Desktop 中图表的管理区域的详细信息选项卡中找到:
from neo4j import GraphDatabase driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "<YOUR_PASSWORD>"))- 如果在给定的 URI 上无法访问数据库,则会出现ServiceUnavailable 错误
- AuthError如果提供的身份验证凭据无效
创建驱动程序后,我们现在可以开始发送 Cypher 查询并分析结果。
基本用法
创建连接后,我们需要从该连接创建一个会话对象。这可以通过简单的方式实现:
session = driver.session()所有创建的会话都需要在我们完成后关闭。这可以通过session.close()在我们的代码之后调用来完成,但我们将使用更Pythonic的方法,使用上下文管理器和with语句:
with driver.session() as session:
# code using the session object goes here
pass使用此语法,会话将在退出with块时自动关闭,并且尝试使用session此块之外的对象将引发异常。
现在让我们实际使用会话将一些 Cypher 查询发送到图形并返回结果。最简单的方法是使用自动提交事务:
result = session.run("MATCH (n:Node) RETURN n")要从结果中获取记录,可以使用多种方法。为了看一个例子,我们可以使用.peek()方法:
record = result.peek()然后,我们可以从记录中获取 Cypher 查询返回的每个值。在我们的例子中,我们返回了一个名为 的值n:
node = record.get("n")node是Node类的一个实例。为了访问它的属性,我们可以get再次使用该方法:
node.get("user_id")为了获取结果的所有记录,我们可以遍历它们:
for record in result.records():
print(record.get("n").get("user_id"))交易
Neo4j 还支持事务,这意味着只有在所有操作都成功时才会改变图形的操作块。
想象一下以下情况,您必须执行两条语句:
with driver.session() as session:
session.run(statement_1)
session.run(statement_2)如果一切顺利,没有问题。但是如果执行statement_2失败怎么办?在某些情况下,您最终会在图表中得到不一致的数据,这是您需要避免的。假设您正在保存来自现有客户的新订单。statement_1创建新Order节点,同时创建节点与节点statement_2之间的关系。如果执行失败,您将得到一个节点,您将无法链接到任何节点。为了避免这些令人沮丧的情况,我们可以使用事务来代替。在一个事务中,如果失败,则整个事务块,包括CustomerOrderstatement_2OrderCustomerstatement_2statement_1, 不会在图中持久化。这可确保数据始终保持一致。它还可以更轻松地重试失败的事务,例如,在由于网络错误导致连接丢失的情况下,无需担心哪些操作已成功执行——您只需重新启动所有操作。
使用 Neo4j Python 驱动程序创建事务非常简单:
with driver.session() as session:
# start a new transaction
tx = session.begin_transaction()
# run cypher...
tx.run(statement_1)
tx.run(statement_2)
# push changes to the graph
tx.commit()使用此语法,如果statement_1正确但statement_2失败,则两者statement_1都statement_2不会保留在图中。
现在我们对 Neo4j 的 Python 驱动有了更多的了解,让我们回到最初的任务——以编程方式在我们的管道中添加基于图形的特性。
使用 Python 自动创建基于图形的特征
本部分的代码可在Python_GDS.ipynbJupyter 笔记本中找到。
创建投影图
请记住,我们可以使用原生投影和 Cypher 投影来创建命名投影图。在这里,我们将只关注原生投影。一个非常简单的投影可以写成如下:
CALL gds.graph.create("my_simple_projected_graph", "User", "FOLLOWS")my_simple_projected_graph包含所有带有User标签的节点和所有带有FOLLOWS类型的关系,无需对 Neo4j 图进行修改(特别是保留了关系方向)。但请记住,这样的投影图不包含任何节点或关系属性。要将它们包含在投影图中,我们将不得不使用更复杂的格式来定义投影图,如下所示:
CALL gds.graph.create(
"my_complex_projected_graph",
// node projection:
{
User: {
label: "User",
properties: [
]
}
},
// relationship projection
{
FOLLOWS: {
type: "FOLLOWS",
orientation: "UNDIRECTED",
aggregation: "SINGLE",
properties: [
]
}
}
)即使是更复杂的示例也具有使用键值和列表结构来定义投影的优点,可以在 Python 中使用列表和字典进行复制。上述代码块中定义的节点投影可以用 Python 表示如下:
nodeProj = {
"User": {
"label": "User",
"properties": [],
}
}关系投影将由以下字典定义:
relProj = {
"FOLLOWS": {
"type": "LINKED_TO",
"orientation": "FOLLOWS",
"aggregation": "SINGLE",
}
}为了在 Cypher 查询中使用这些变量,我们将使用参数。需要三个参数:
- 图名(字符串)
- 节点投影定义 ( dict)
- 关系投影定义 ( dict)
我们的 Cypher 查询可以这样写:
cypher = "CALL gds.graph.create($graphName, $nodeProj, $relProj)"为了使用前面代码中定义的参数执行此查询,我们需要运行以下命令:
with driver.session() as session:
result = session.run(
cypher,
graphName="my_complex_projected_graph",
nodeProj=nodeProj,
relProj=relProj
)这段代码执行后,查看 的结果result.data(),我们可以看到与 Neo4j 浏览器中显示的信息相同的信息,这就是查询执行成功的证据:
[{'graphName': 'my_complex_projected_graph', 'nodeProjection': {'User': {'properties': {}, 'label': 'Node'}}, 'relationshipProjection': {'FOLLOWS': {'orientation': 'UNDIRECTED', 'aggregation': 'SINGLE', 'type': 'FOLLOWS', 'properties': {}}},
'nodeCount': 596,
'relationshipCount': 1192,
'createMillis': 8}]现在我们的投影图已创建,尝试从 GDS 运行算法。
调用 GDS 程序
我们将使用 PageRank 过程作为示例,它根据其邻居的重要性为每个节点分配一个重要性分数。有关 PageRank 算法的进一步说明,请参阅第 5 章,节点重要性。
GDS中PageRank过程的签名如下:
gds.pageRank.stream(<graphName>, <algoConfiguratioMap>)所以,让我们首先定义配置映射。如果我们想使用不同于默认值的阻尼因子0.85,我们需要这样指定:
algoConfig = {
"dampingFactor": 0.8,
}与图创建查询类似,我们将构建一个带有参数的查询:
"CALL gds.pageRank.stream($graphName, $algoConfig)"它可以通过以下方式执行:
with driver.session() as session:
result = session.run(
"CALL gds.pageRank.stream($graphName, $algoConfig)",
graphName=graphName,
algoConfig=algoConfig,
)result我们可以在对象上循环检查结果:
for record in result:
print(record.data())打印的结果将如下所示:
{'nodeId': 0, 'score': 0.15}
{'nodeId': 1, 'score': 1.21}
{'nodeId': 2, 'score': 0.94}
{'nodeId': 3, 'score': 0.40}
{'nodeId': 4, 'score': 0.65}为了获得更有意义的结果,我们可以使用辅助过程nodeId从GDS 过程返回的节点中获取节点。Cypher 查询稍微复杂一些,但可以使用完全相同的 Python 代码从中获取结果:gds.util.asNode
with driver.session() as session:
result = session.run(
"""CALL gds.pageRank.stream($graphName, $algoConfig)
YIELD nodeId, score
RETURN gds.util.asNode(nodeId) as node, score
""",
graphName=graphName,
algoConfig=algoConfig,
)
for record in result:
print(record.get("node").get("user_id"), record.get("score"))多亏了 Neo4j Python 驱动程序,我们现在能够创建命名投影图并调用 GDS 程序,例如 PageRank。
将结果写回图表
将结果写回图表时,我们将不得不使用.write过程而不是.stream. 此外,还需要一个额外的强制参数——将添加到每个节点并保存算法结果的属性名称(此处为 PageRank 分数)。这个属性是通过配置来writeProperty配置的,所以我们把它添加到我们的algoConfig字典中:
algoConfig["writeProperty"] = "pr"然后我们可以使用相同的代码来运行这个过程,替换gds.pageRank.stream为gds.pageRank.write:
with driver.session() as session:
result = session.run(
"CALL gds.pageRank.write($graphName, $algoConfig)",
graphName=graphName,
algoConfig=algoConfig,
)如果我们这次检查结果的内容,它只包含一些关于算法执行的统计信息:
>>> result.single().data()
{'nodePropertiesWritten': 596,
'createMillis': 0,
'computeMillis': 132,
'writeMillis': 6,
'ranIterations': 20,
'didConverge': False,
'configuration': {'maxIterations': 20,
'writeConcurrency': 4,
'sourceNodes': [],
'writeProperty': 'pr',
'relationshipWeightProperty': None,
'dampingFactor': 0.85,
'relationshipTypes': ['*'],
'cacheWeights': False,
'tolerance': 1e-07,
'concurrency': 4}}要查看 PageRank 评分的结果,我们必须运行另一个 Cypher 查询。例如,我们可以通过以下查询获得具有最高 PageRank 分数的节点:
MATCH (n:User)
RETURN n.user_id, n.pr
ORDER BY n.pr DESC
LIMIT 1我们还可以检查,正如预期的那样,为 Neo4j 做出贡献的用户具有更高的 PageRank。如下图所示,其中黄色节点代表对 Neo4j 有贡献的用户,其 PageRank 得分约为10,而绿色节点是其他用户,其 PageRank 得分低于1: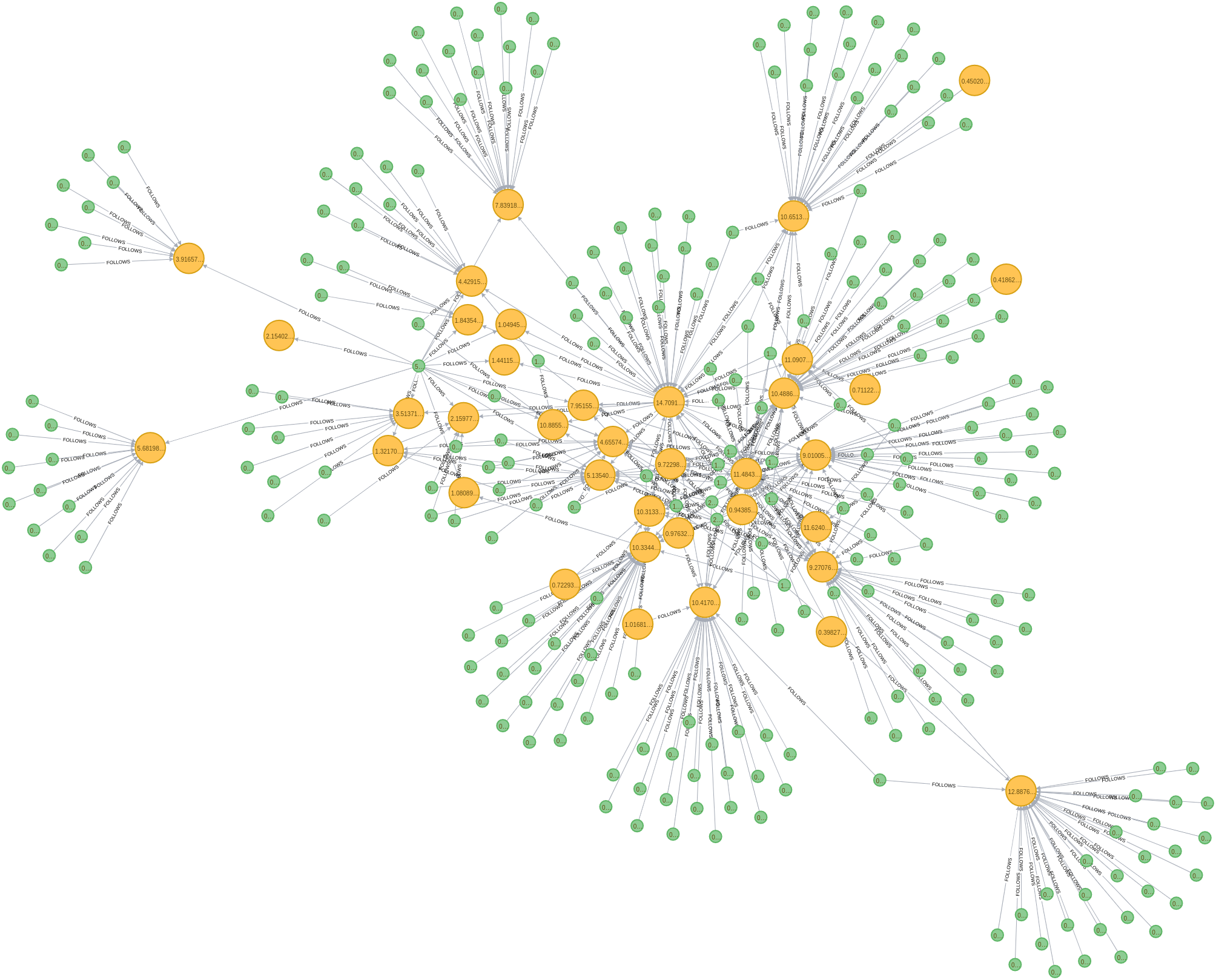
要从 Neo4j 浏览器创建此图像,您可以向具有 的节点添加特定标签contributed_to_neo4j=true,并在图形渲染单元格中更改此新节点标签的大小和颜色:
MATCH (u:User {contributed_to_neo4j: true})
SET u:Contributor我们将在将数据从 Neo4j 导出到 pandas部分中看到,如何使用此结果来提供pandasDataFrame 以进行进一步分析。
然而,在我们开始之前,让我们先谈谈删除投影图的重要步骤。
删除投影图
命名的投影图存储在内存中,可以很大,有很多节点、关系和属性。因此,一旦我们执行了所有操作,删除它们就很重要。
这可以通过以下代码来实现,您现在应该熟悉这些代码:
with driver.session() as session:
result = session.run(
"CALL gds.graph.drop($graphName)",
graphName=graphName,
)回到我们的数据分析管道,我们现在可以直接从 Python 将基于图的特征添加到我们的图中。在下一节中,我们将继续朝这个方向前进,学习如何pandas通过从 Neo4j 读取数据来创建 DataFrame。
将数据从 Neo4j 导出到 pandas
pandas支持多种数据类型,从 CSV 到 JSON 再到 HTML。在这里,我们将使用 Neo4j 在 CSV 文件中的导出功能。
在上一节中,我们学习了如何从 Python 运行 Cypher 查询并获取结果。现在对我们来说最有趣的函数是result.data()函数,它返回一个记录列表,其中每条记录都是一个字典。这很有趣,因为pandas确实有一个简单的方法可以从这个结构创建一个 DataFrame - 使用该pd.DataFrame.from_records函数。
首先,我们来看一个例子,定义一个记录列表,如下:
list_of_records = [
{"a": 1, "b": 11},
{"a": 2, "b": 22},
{"a": 3, "b": 33},
]从此列表创建 DataFrame 非常简单,如下所示:
pd.DataFrame.from_records(list_of_records)
它创建了一个 DataFrame,其中包含两列,名为a和,以及从tob索引的三行:02
a b
0 1 11
1 2 22
2 3 33每一行对应一个节点或一个观察值,每一列对应一个特征或特征。
可以使用相同的方法从通过 Neo4j Python 驱动程序使用以下代码执行的 Cypher 查询的结果创建 DataFrame:
with driver.session() as session:
result = session.run("MATCH (n:Node) RETURN n.name as name, n.pr as pr")
record_data = result.data()
data = pd.DataFrame.from_records(record_data)在这种情况下,data有两列,name和,以及等于图中带有标签pr的节点数的行数。Node
然后,我们可以再次执行数据分析管道的不同步骤。例如,下图再现了显示每个类的每个特征分布的配对图: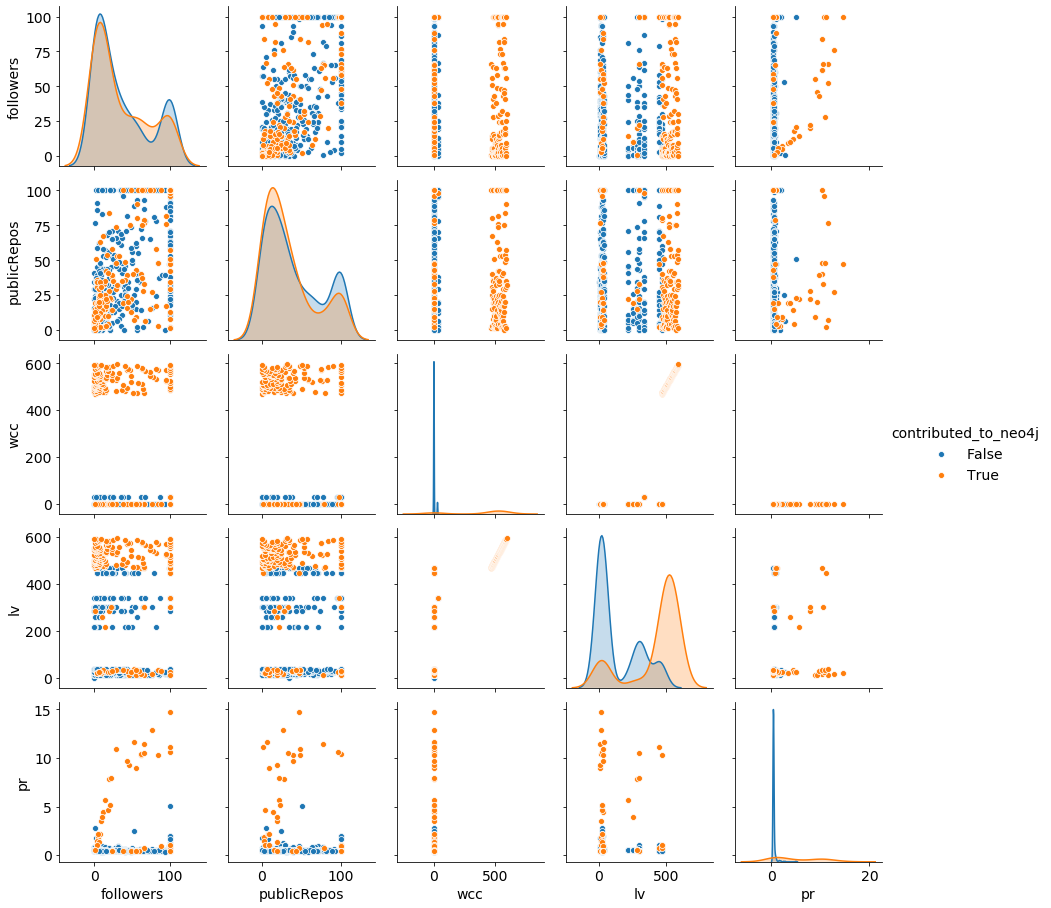
如您所见,新引入的变量 、wcc(lv对于 Louvain 社区)和pr(PageRank 得分)根据目标类具有非常不同的形状。这很可能会使分类器结果更加准确。
训练 scikit-learn 模型
最后,让我们把我们学到的东西结合起来,并尝试在最后一个数据集上运行一个分类器。
本部分的代码可在Data_Analysis_Graph.ipynbJupyter 笔记本中找到。
介绍社区功能
社区特征,无论是wcc还是lv,都是分类特征。让我们假设 nodeA属于 community 1, node Bto community 2, node Cto community 35。我们不能假设节点A和B比节点更相似A,C因为它们的社区数量更接近。我们只知道节点A和B不属于同一个社区,就像Aand Cor Band一样C。
在机器学习中处理分类特征的一种方法是通过 one-hot 编码器对其进行转换。它的作用是将具有N个类别的向量特征转换为N个向量,其值为0或1:
[ [
1, [1 0 0]
2, [0 1 0]
3, [0 0 1]
1, = [1 0 0]
1, [1 0 0]
3 [0 0 1]
] ]但是,由于我们的wcc特征包含 129 个唯一值,这将为我们的模型添加 129 个特征。这太多了,尤其是考虑到我们只有几百个观察值!为了避免维度问题,我们将只考虑至少有两个观察值的社区,但这个数字可以稍后调整。要在wcc向量中创建用于创建 one-hot 编码特征的值列表,我们可以使用以下代码:
wcc_community_distribution = data.wcc.value_counts().sort_values(ascending=False)
wcc_keep = sorted(wcc_community_distribution [ wcc_community_distribution > 1].index)然后我们可以构建管道:
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
pipeline = make_pipeline(
make_column_transformer(
(OneHotEncoder(categories=[wcc_keep], handle_unknown="ignore"), ["wcc",]),
(SimpleImputer(strategy="mean"), ["publicRepos", "followers"]),
# remainder='passthrough'
),
DecisionTreeClassifier(random_state=123, min_samples_leaf=10)
)管道包含两个步骤:
- 数据转换:
- OneHotEncoder对于该wcc功能,仅使用wcc_keep类别
- SimpleImputer从和特征中删除NaN数字publicReposfollowers
- 分类器本身,DecisionTreeClassifier
管道可以用作普通scikit-learn模型,以一次性拟合变压器和模型:
pipeline.fit(X_train, y_train)然后,通过使用拟合的转换器转换数据来进行预测,并predict一次调用模型的方法:
y_pred = pipeline.predict(X_test)通过添加社区信息,我们使用这个新模型获得的混淆矩阵如下所示:
array([[128, 0], [ 22, 29]])与初始模型不同,对 Neo4j 没有贡献的用户都被正确分类(128 个),在对 Neo4j 做出贡献的 51 个用户中,有 29 个被正确识别(而我们的第一个模型中没有使用图的 9 个)基于特征)。
让我们看看我们是否可以通过以下方式进一步改进这个模型:
- 使用 Louvain 算法提供更精细的社区信息
- 节点重要性数据——感谢 PageRank 算法
同时使用社区和中心性功能
按照与上一节完全相同的步骤,使用最拥挤的 Louvain 社区和 PageRank 分数,我们最终得到以下决策树分类器的最终结果:
precision recall f1-score support False 0.91 0.99 0.95 128 True 0.97 0.75 0.84 51 accuracy 0.92 179 macro avg 0.94 0.87 0.90 179 weighted avg 0.93 0.92 0.92 179混淆矩阵在此处复制:
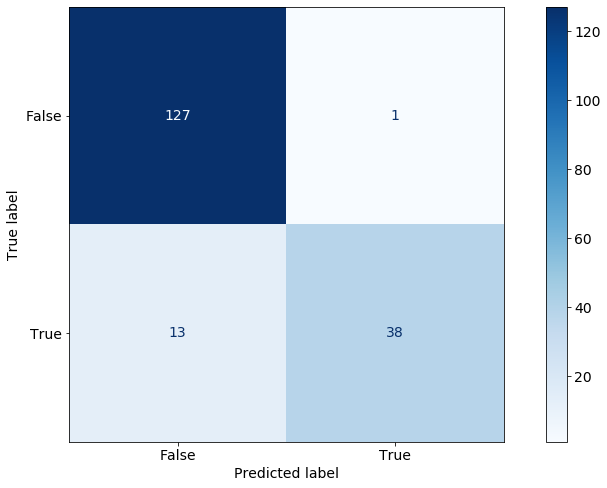
我们的整体准确率从 66% 跃升至 92%。更重要的是,该算法现在能够正确识别出 38 个用户对 Neo4j 做出了贡献,而使用非图形特征的只有 9 个,而仅使用 WCC 信息时只有 29 个。
一项特征重要性研究表明,该模型中影响最大的特征是 PageRank 得分,如下条形图所示: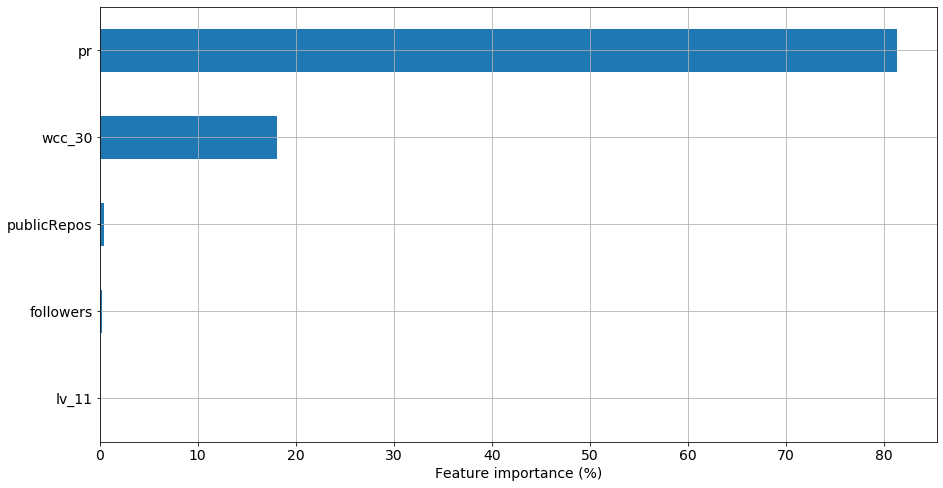
这意味着我们关于 Neo4j 贡献者形成社区的假设并没有真正被我们的图表复制。然而,这些用户在连接和 PageRank 方面显然是最重要的。
概括
本章概述了经典的数据科学管道以及如何将图形数据集成到其中。借助Neo4j Python 驱动程序,您现在可以将 Neo4j 数据导入pandasDataFrame,然后可以在任何其他应用程序中照常使用,例如使用scikit-learn. 您还学习了如何以编程方式从 GDS 运行图形算法并将结果用作模型的新型特征。
在接下来的章节中,我们将继续我们的图分析之旅。在本章中,我们坚持使用经典的机器学习方法,例如决策树。我们现在将继续学习如何使用图结构来回答不同类型的问题,从链接预测问题开始,我们将在下一章解决这个问题。
问题
以下是一些练习,您可以自己尝试,以对本章所涵盖的概念更有信心:
- 使用 Python 创建投影图:修改本章研究的代码以创建 Cypher 投影图。
- PageRank 分数分布:您能解释一下对 Neo4j 没有贡献的用户(标签 = False)的 PageRank 分数分布的形状吗?
还鼓励您尝试从数据中创建图表,并尝试在您自己的管道中包含基于图表的功能。
进一步阅读
- Microsoft Team Data Science Process 生命周期的业务理解阶段:
https ://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/lifecycle-business-understanding