最近看了李沐老师的机器学习教程,在课中提到了weight&bias这个调参工具,但是在网上查教程时,找到的大多是官方文档的翻译或者是看不懂的教程,所以有了这个教程。
本教程主要也是讲解一下官方的例子,通过在mnist数据集上训练,让大家了解一下基础操作和实际效果,想要了解高级操作的话可以直接搜wandb库的使用,weight&bias官网地址https://wandb.ai/home
第一章 注册与安装
注册的话直接点击官网右上角的sign up,我这里选择了用微软账号注册,主要是为了省事,实际使用效果都一样。
注册完成之后还会让你指定组名、拉成员之类的,这里就不介绍了。
点击这里,教你怎么安装。(用Tensorflow的同学可以点Keras)
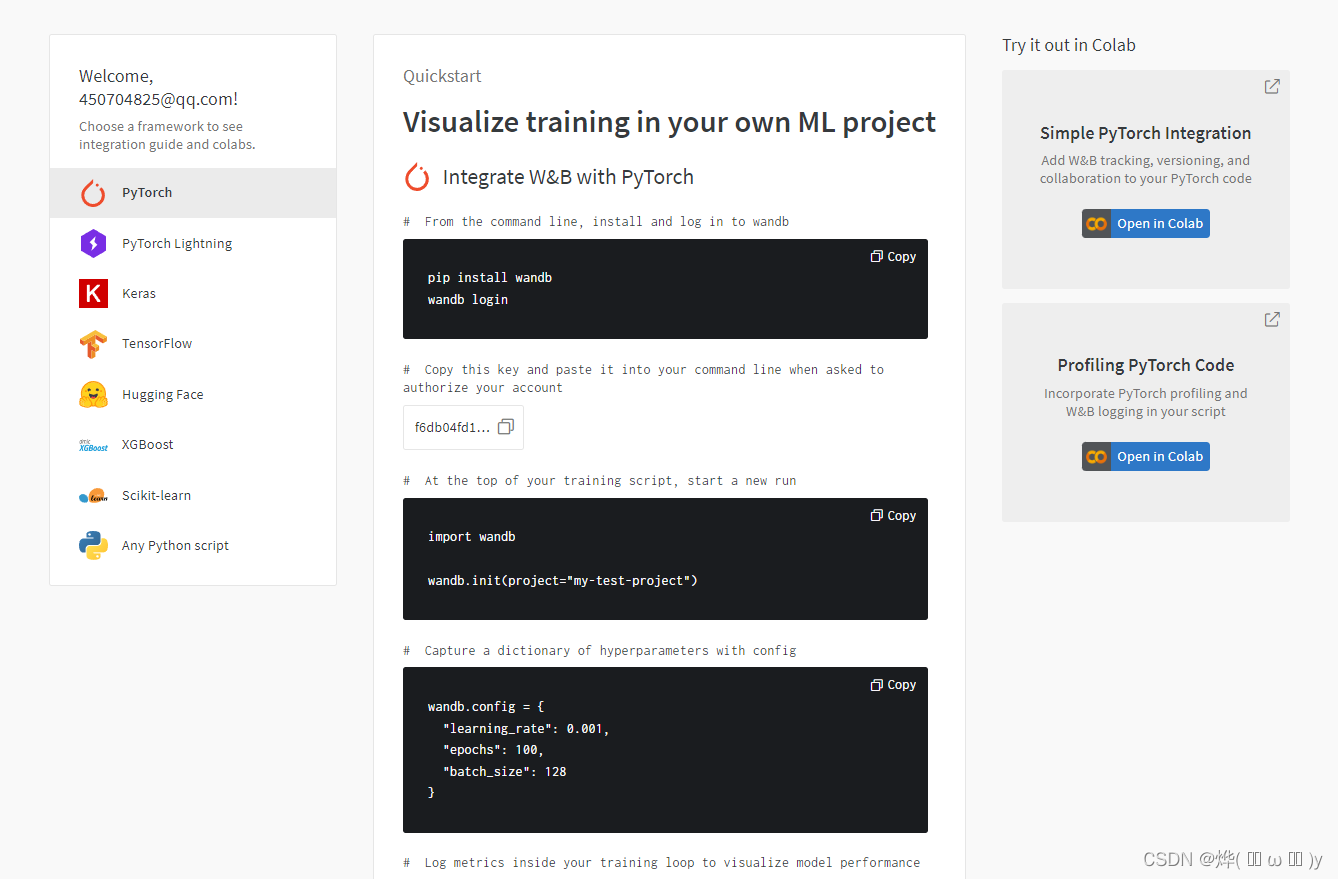
首先打开cmd,输入指令。
pip install wandb
wandb login然后在官网复制密钥。
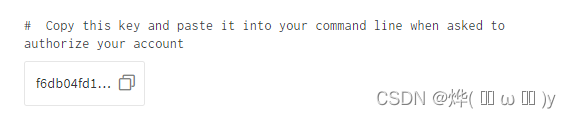
此时你的cmd界面应该是这样。
点击鼠标右键粘贴到cmd,我这里已经注册过所以会报错。

第二章 基础操作
这里我们根据官方例子进行讲解,主要是一些项目的初始化和训练过程中数据的上传,想看官方版的也有链接,或者点图里的位置也行,不过都需要挂梯子。https://colab.research.google.com/github/wandb/examples/blob/master/colabs/intro/Intro_to_Weights_%26_Biases.ipynb
2.1 上传数据
然后开始代码部分,首先初始化一下,创建一个进程
import wandb
#entity个人名称
run=wandb.init(project="test-project",name="test1", entity="cty_train_module",reinit=True)然后上传100个数,结束进程,之后在weight&bias官网就能看到我们的项目运行结果,或者你也可以点击程序运行结束后生成的链接。
for i in range(100):
wandb.log({'metric':i})
run.finish()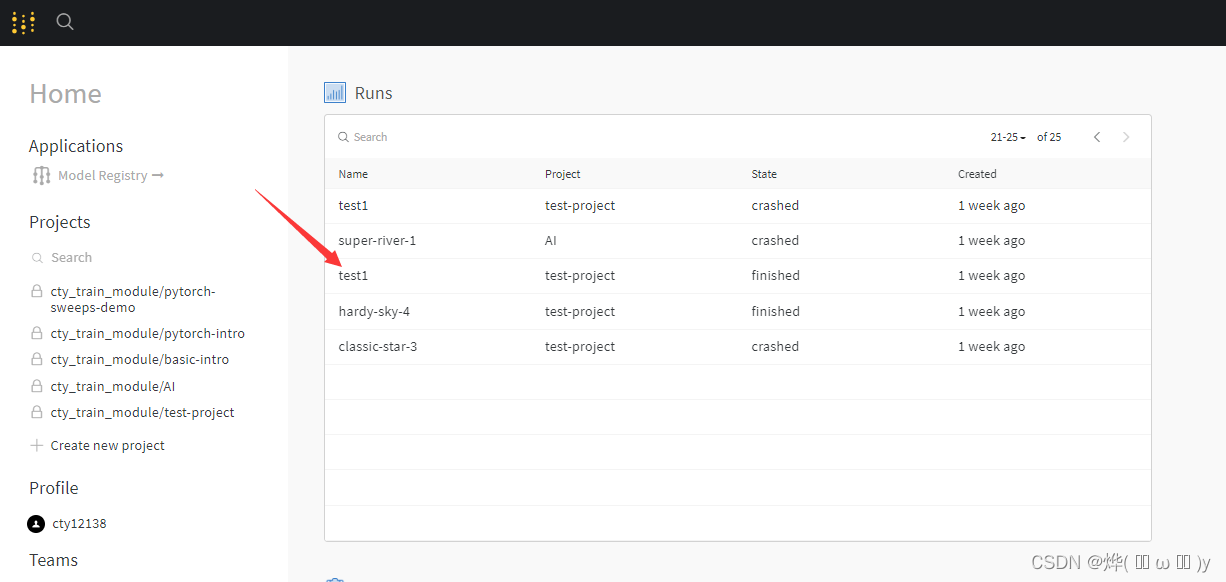
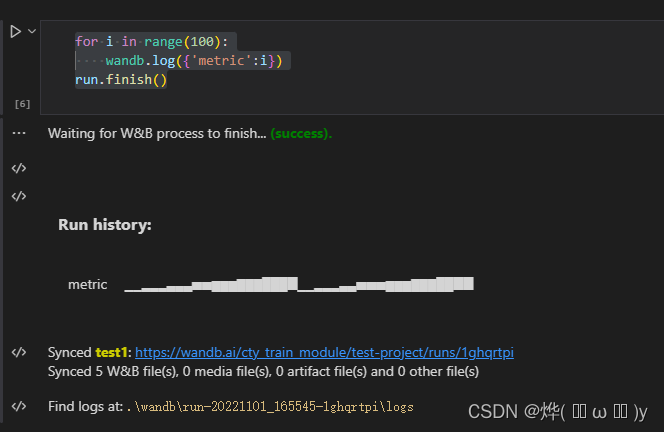
可以看到自动帮我们生成了一张表,表名是metric。我这个程序运行了两次,所以有2次0-100的数据
2.2 创建多个项目
在这里创建5个项目,每次上传一些acc和loss,代码比较简单这里就不细讲了。
import random
import wandb
#进行5次实验
total_runs = 5
for run in range(total_runs):
# 🐝 1️⃣ Start a new run to track this script
wandb.init(
# 给你的项目一个名字
project="basic-intro",
# 你项目每次运行的名字,一般是 experiment_+编号 ,不给的话会随机初始化一个(otherwise it’ll be randomly assigned, like sunshine-lollypop-10)
name=f"experiment_{run}",
# 跟踪超参数
# Track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
#模拟了一个训练过程
# This simple block simulates a training loop logging metrics
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
#通过wandb.log把一个字典类型数据上传到weight&bias
# 🐝 2️⃣ Log metrics from your script to W&B
wandb.log({"acc": acc, "loss": loss})
#结束进程
# Mark the run as finished
wandb.finish()在weight&bias看到结果如下:
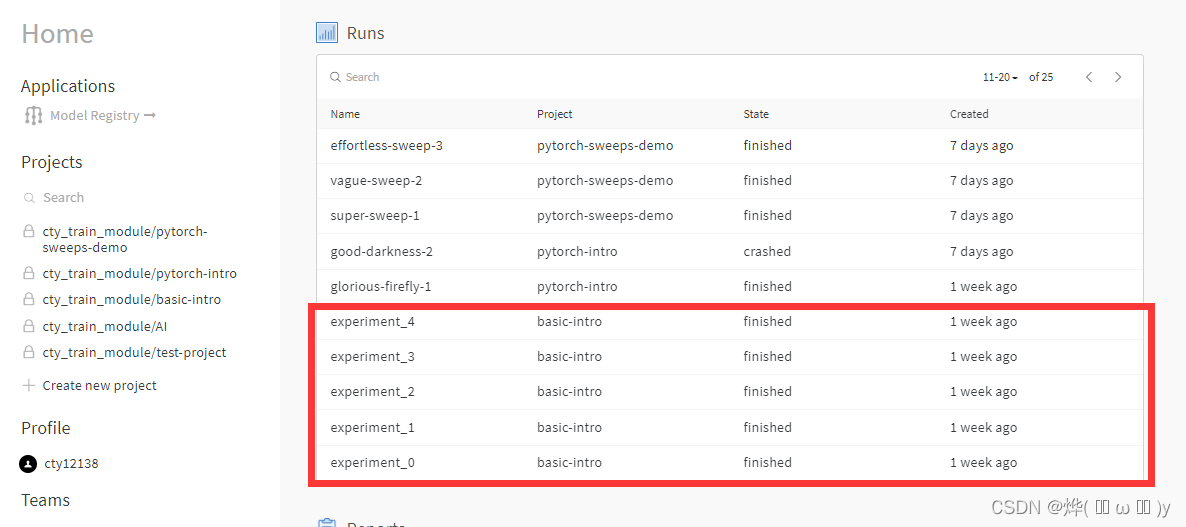
2.3 使用mnist数据集测试
下面首先是一些我们在训练时通用的操作(导入数据、定义网络架构等)这里就不讲了,直接复制就好。
#@title
import wandb
import math
import random
import torch, torchvision
import torch.nn as nn
import torchvision.transforms as T
device = "cuda:0" if torch.cuda.is_available() else "cpu"
def get_dataloader(is_train, batch_size, slice=5):
"Get a training dataloader"
full_dataset = torchvision.datasets.MNIST(root="./data", train=is_train, transform=T.ToTensor(), download=True)
#获取指定序列对应的子数据集 从MNIST开始到结束,每5个取一个
sub_dataset = torch.utils.data.Subset(full_dataset, indices=range(0, len(full_dataset), slice))
loader = torch.utils.data.DataLoader(dataset=sub_dataset,
batch_size=batch_size,
shuffle=True if is_train else False,
pin_memory=True, num_workers=2)
return loader
def get_model(dropout):
"A simple model"
model = nn.Sequential(nn.Flatten(),
nn.Linear(28*28, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(256,10)).to(device)
return model
#验证模型
def validate_model(model, valid_dl, loss_func, log_images=False, batch_idx=0):
"Compute performance of the model on the validation dataset and log a wandb.Table"
#在验证集上计算模型的表现
model.eval()
val_loss = 0.
#torch.inference_mode() 禁用梯度
with torch.inference_mode():
correct = 0
for i, (images, labels) in enumerate(valid_dl):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
val_loss += loss_func(outputs, labels)*labels.size(0)
# Compute accuracy and accumulate
#得到特征维最大的那个数的索引0~9
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
# Log one batch of images to the dashboard, always same batch_idx.
#上传一个指定batch的图片、预测结果、标签、模型输出
if i==batch_idx and log_images:
log_image_table(images, predicted, labels, outputs.softmax(dim=1))
return val_loss / len(valid_dl.dataset), correct / len(valid_dl.dataset)在上面的validate_model里有一个函数log_image_table,在这个函数中,首先通过wandb.Table函数指定表格的列,然后把一个batch(这里batchsize=256)的数据先放到cpu,转为numpy格式,最后放到表中上报。效果如下:
def log_image_table(images, predicted, labels, probs):
"Log a wandb.Table with (img, pred, target, scores)"
# 🐝 Create a wandb Table to log images, labels and predictions to
#创建一个表格,由image、预测结果、标签以及模型输出的10个数组成
table = wandb.Table(columns=["image", "pred", "target"]+[f"score_{i}" for i in range(10)])
for img, pred, targ, prob in zip(images.to("cpu"), predicted.to("cpu"), labels.to("cpu"), probs.to("cpu")):
table.add_data(wandb.Image(img[0].numpy()*255), pred, targ, *prob.numpy())
wandb.log({"predictions_table":table}, commit=False)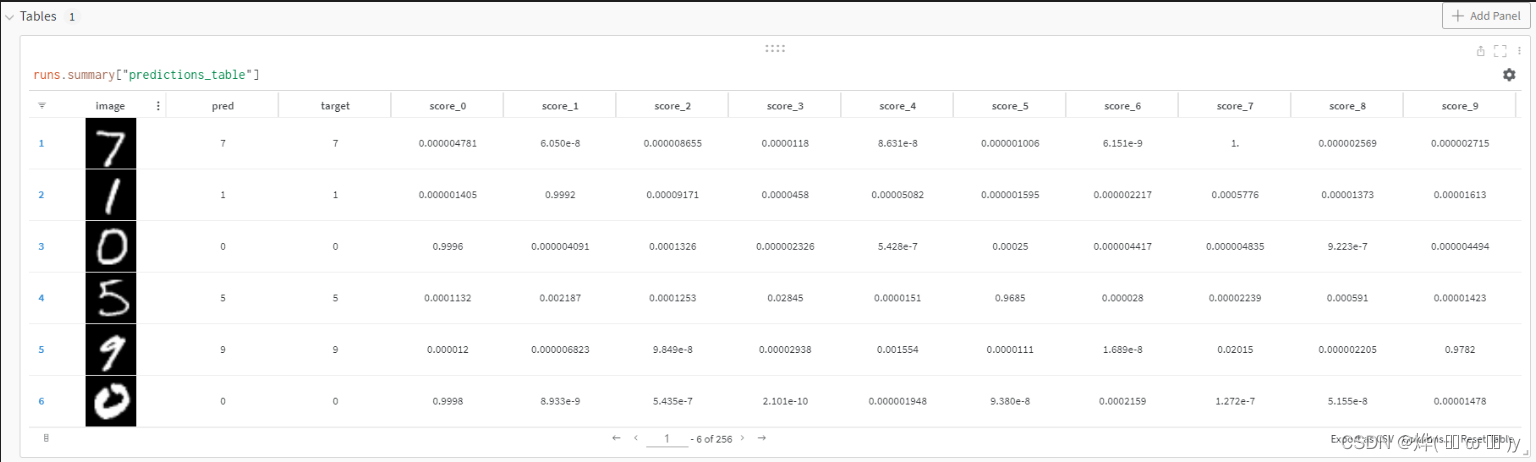
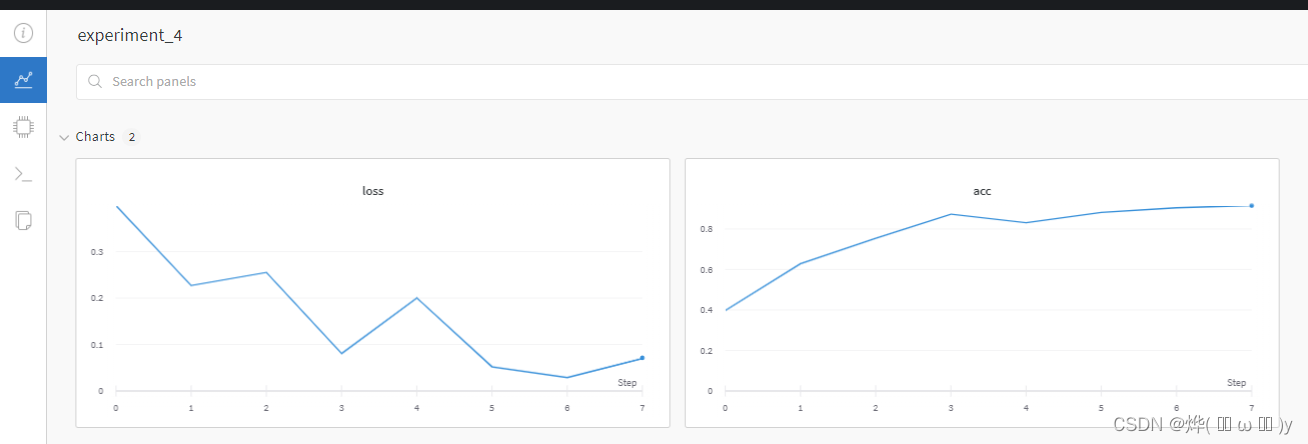
下面是训练部分的代码,这里训练了5种网络,通过wandb.init中的config指定超参数,5种网络中不同的只有dropout。每个batch上报损失值等,每个epoch验证一次,同样上报损失和准确率。效果如下:
# Launch 5 experiments, trying different dropout rates
#尝试5种不同的dropout进行训练
for _ in range(5):
# 🐝 initialise a wandb run
wandb.init(
project="pytorch-intro",
config={
"epochs": 10,
"batch_size": 128,
"lr": 1e-3,
#(0.01, 0.80)生成一个随机数
"dropout": random.uniform(0.01, 0.80),
})
# Copy your config
#复制wandb中的config
config = wandb.config
# Get the data
#获取数据集
train_dl = get_dataloader(is_train=True, batch_size=config.batch_size)
valid_dl = get_dataloader(is_train=False, batch_size=2*config.batch_size)
#math.ceil返回一个最接近的整数
n_steps_per_epoch = math.ceil(len(train_dl.dataset) / config.batch_size)
# A simple MLP model
#实例化我们之前定义的简单模型
model = get_model(config.dropout)
# Make the loss and optimizer
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)
# Training
example_ct = 0
step_ct = 0
for epoch in range(config.epochs):
model.train()
for step, (images, labels) in enumerate(train_dl):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss_func(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
example_ct += len(images)
metrics = {"train/train_loss": train_loss,
#总共训练了多少个epoch
"train/epoch": (step + 1 + (n_steps_per_epoch * epoch)) / n_steps_per_epoch,
#总共训练了多少张图片
"train/example_ct": example_ct}
if step + 1 < n_steps_per_epoch:
# 🐝 Log train metrics to wandb
#上传metrics
wandb.log(metrics)
step_ct += 1
#每个epoch用验证集测试一下
#log_images=(epoch==(config.epochs-1))是不是最后一个epoch,如果是才会上table
val_loss, accuracy = validate_model(model, valid_dl, loss_func, log_images=(epoch==(config.epochs-1)))
# 🐝 Log train and validation metrics to wandb
#上传验证集的损失和精度
val_metrics = {"val/val_loss": val_loss,
"val/val_accuracy": accuracy}
wandb.log({**metrics, **val_metrics})
print(f"Train Loss: {train_loss:.3f}, Valid Loss: {val_loss:3f}, Accuracy: {accuracy:.2f}")
# If you had a test set, this is how you could log it as a Summary metric
#设置一个总结值。目前不是很懂
wandb.summary['test_accuracy'] = 0.8
# 🐝 Close your wandb run
wandb.finish()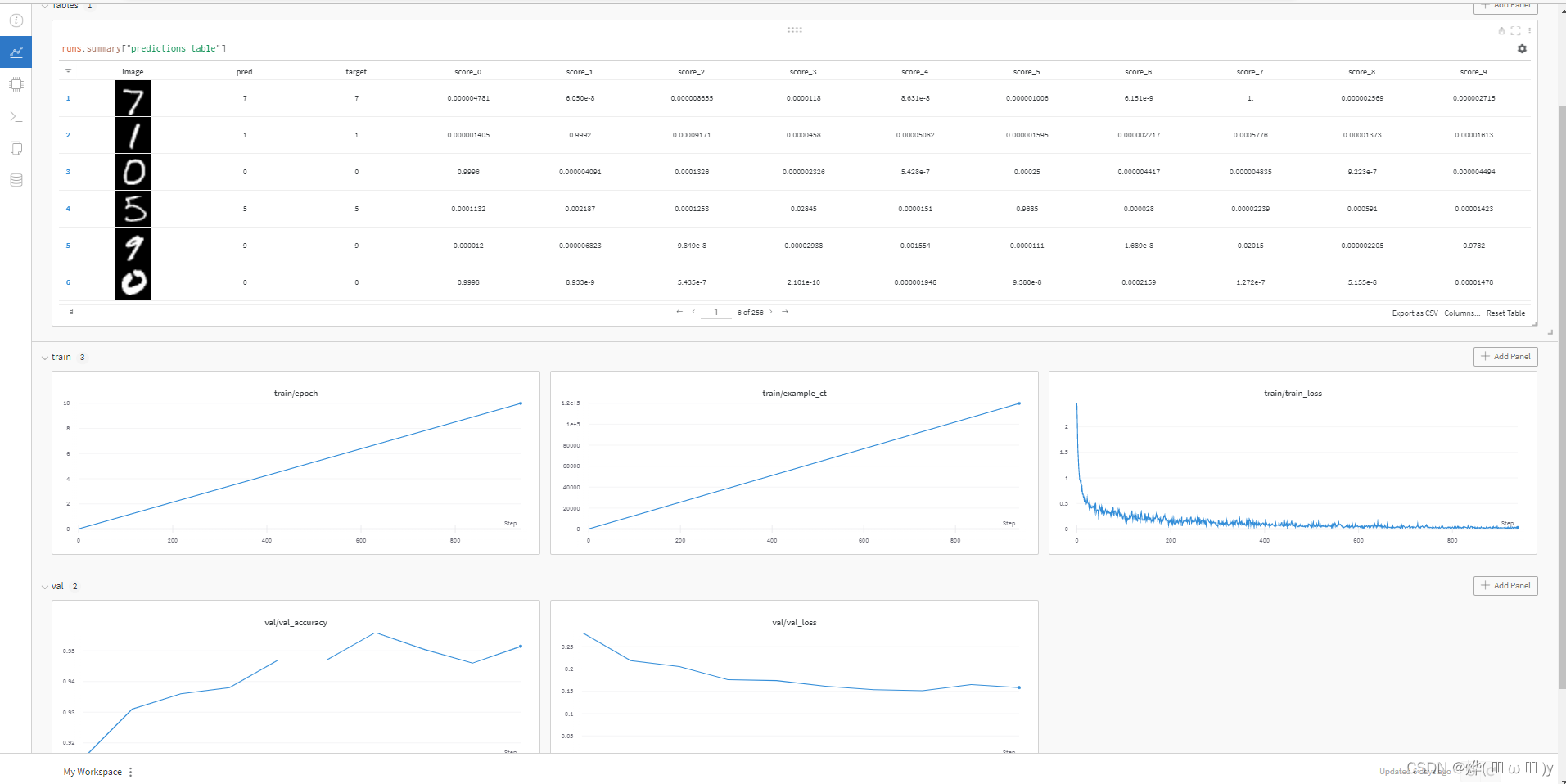
第三章 调参部分
在这一部分我们要使用一个叫sweep的东西,首先建立一个字典类型数据,‘method’指超参数的搜索方法。
#可选择的参数有grid,random ,bayesi
#grid迭代每种组合 random随机选择 bayesi贝叶斯搜索,适用于少量连续参数
sweep_config = {
'method': 'random'
}通过以下形式向字典中添加其他项。
#如果使用贝叶斯搜索,你还需要知道指定超参数的名字,这样我们才能在模型输出中找到它,我们需要知道你的目标是最小化它(例如,如果它是平方误差)还是最大化它(例如,如果它是精度)。
metric = {
'name': 'loss',
'goal': 'minimize'
}
sweep_config['metric'] = metric#定义一些超参数可选择的范围
parameters_dict = {
'optimizer': {
'values': ['adam', 'sgd']
},
'fc_layer_size': {
'values': [128, 256, 512]
},
'dropout': {
'values': [0.3, 0.4, 0.5]
},
}
sweep_config['parameters'] = parameters_dict要更新一个键值对时,可以使用以下方法:
#需要添加时可以选择update
parameters_dict.update({
'epochs': {
'value': 1}
})
parameters_dict.update({
'learning_rate': {
#在0到0.1平均分布
'distribution': 'uniform',
'min': 0,
'max': 0.1
},
'batch_size': {
# integers between 32 and 256
#均匀分布的log
'distribution': 'q_log_uniform_values',
'q': 8,
'min': 32,
'max': 256,
}
})最后看一下都有些什么
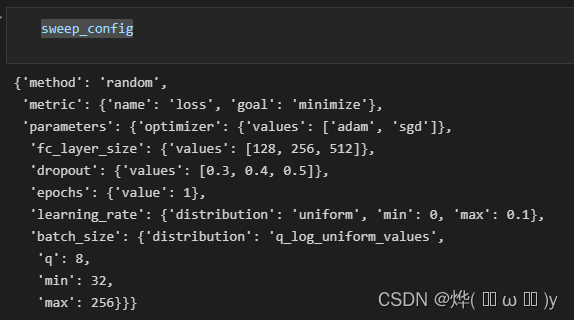
然后初始化wandb:
import wandb
#得到一个sweep_id,我们稍后将使用它向该Controller分配代理。
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")接下来开始定义训练程序:
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torchvision import datasets, transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def build_dataset(batch_size):
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# download MNIST training dataset
dataset = datasets.MNIST("./data/", train=True, download=True,
transform=transform)
sub_dataset = torch.utils.data.Subset(
dataset, indices=range(0, len(dataset), 5))
loader = torch.utils.data.DataLoader(sub_dataset, batch_size=batch_size)
return loader
def build_network(fc_layer_size, dropout):
network = nn.Sequential( # fully-connected, single hidden layer
nn.Flatten(),
nn.Linear(784, fc_layer_size), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(fc_layer_size, 10),
nn.LogSoftmax(dim=1))
return network.to(device)
def build_optimizer(network, optimizer, learning_rate):
if optimizer == "sgd":
optimizer = optim.SGD(network.parameters(),
lr=learning_rate, momentum=0.9)
elif optimizer == "adam":
optimizer = optim.Adam(network.parameters(),
lr=learning_rate)
return optimizer
def train_epoch(network, loader, optimizer):
cumu_loss = 0
for _, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# ➡ Forward pass
loss = F.nll_loss(network(data), target)
cumu_loss += loss.item()
# ⬅ Backward pass + weight update
loss.backward()
optimizer.step()
wandb.log({"batch loss": loss.item()})
return cumu_loss / len(loader)
最后还要定义一个训练函数
def train():
# Initialize a new wandb run
with wandb.init():
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
loader = build_dataset(config.batch_size)
network = build_network(config.fc_layer_size, config.dropout)
optimizer = build_optimizer(network, config.optimizer, config.learning_rate)
for epoch in range(config.epochs):
avg_loss = train_epoch(network, loader, optimizer)
wandb.log({"loss": avg_loss, "epoch": epoch}) 接下来开始训练,通过agent函数,指定id和训练函数入口,count指定训练次数。
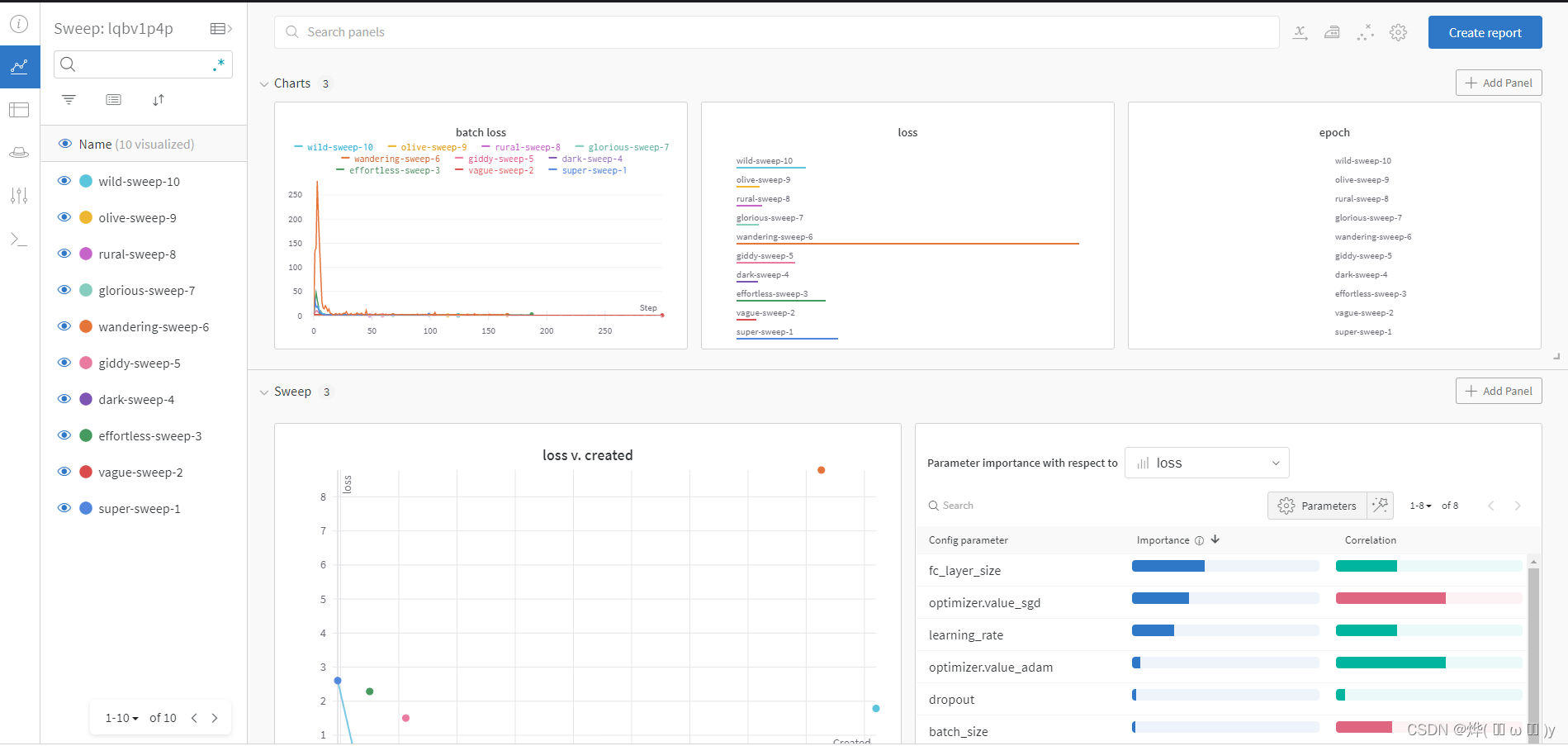
wandb.agent(sweep_id, train, count=5)我们来看下实际效果,同样通过生成的链接跳转
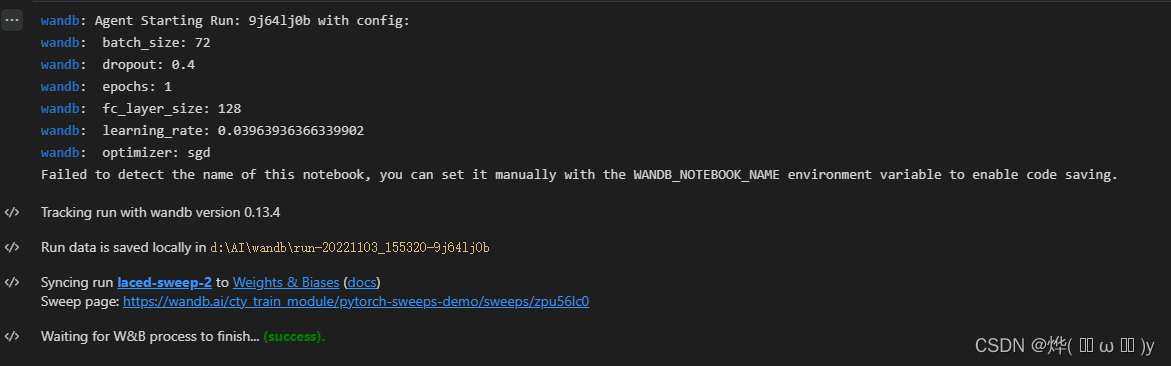
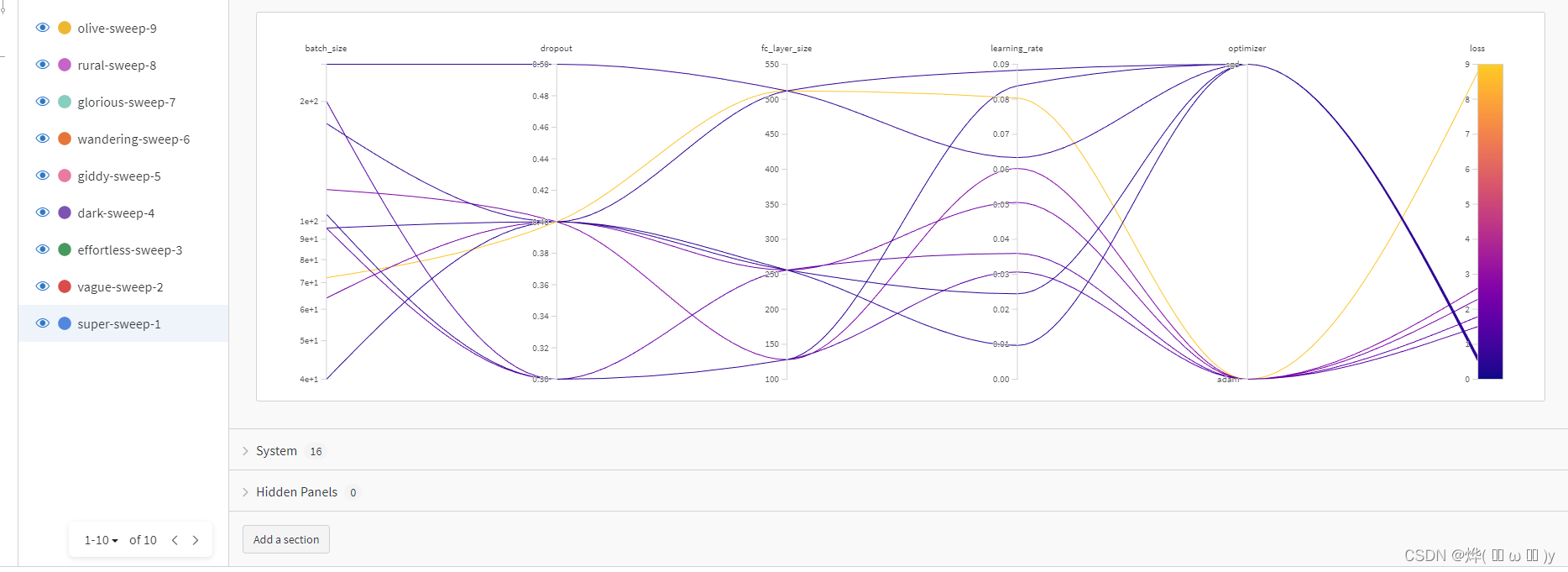
这里除了我们指定上报的消息,还根据sweep自动生成了超参数相关性的图表。