文章目录
1. 以太网数据帧格式
以太网链路传输的数据包称做以太帧,或者以太网数据帧。在以太网中,网络访问层的软件必须把数据转换成能够通过网络适配器硬件进行传输的格式。
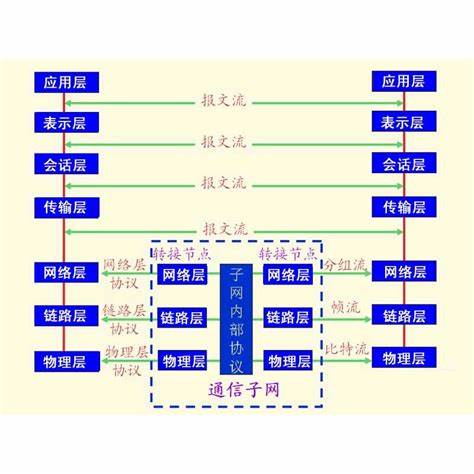
1.1 以太帧的工作机制
当以太网软件从网络层接收到数据报之后,需要完成如下操作:
- 根据需要把网际层的数据分解为较小的块,以符合以太网帧数据段的要求。
以太网帧的整体大小必须在 64~1518 字节之间(不包含前导码)。有些系统支持更大的帧,最大可以支持 9000 字节。 - 把数据块打包成帧。每一帧都包含数据及其他信息,这些信息是以太网网络适配器处理帧所需要的。
- 把数据帧传递给对应于 OSI 模型物理层的底层组件,后者把帧转换为比特流,并且通过传输介质发送出去。
- 以太网上的其他网络适配器接收到这个帧,检查其中的目的地址。如果目的地址与网络适配器的地址相匹配,适配器软件就会处理接收到的帧,把数据传递给协议栈中较高的层。
1.2 以太帧的结构
以太帧起始部分由前同步码和帧开始定界符组成,后面紧跟着一个以太网报头,以 MAC 地址说明目的地址和源地址。以太帧的中部是该帧负载的包含其他协议报头的数据包,如 IP 协议。
以太帧由一个 32 位冗余校验码结尾,用于检验数据传输是否出现损坏。以太帧结构如图所示。
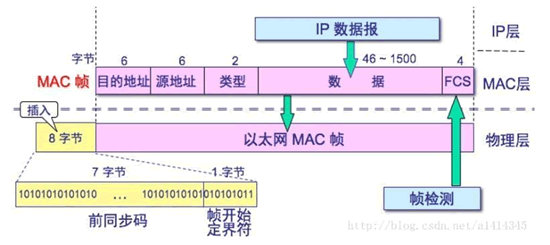
上图中每个字段的含义如下表所示:
| 字段 | 含义 |
|---|---|
| 前同步码 | 用来使接收端的适配器在接收 MAC 帧时能够迅速调整时钟频率,使它和发送端的频率相同。前同步码为 7 个字节,1 和 0 交替。 |
| 帧开始定界符 | 帧的起始符,为 1 个字节。前 6 位 1 和 0 交替,最后的两个连续的 1 表示告诉接收端适配器:“帧信息要来了,准备接收”。 |
| 目的地址 | 接收帧的网络适配器的物理地址(MAC 地址),为 6 个字节(48 比特)。作用是当网卡接收到一个数据帧时,首先会检查该帧的目的地址,是否与当前适配器的物理地址相同,如果相同,就会进一步处理;如果不同,则直接丢弃。 |
| 源地址 | 发送帧的网络适配器的物理地址(MAC 地址),为 6 个字节(48 比特)。 |
| 类型 | 上层协议的类型。由于上层协议众多,所以在处理数据的时候必须设置该字段,标识数据交付哪个协议处理。例如,字段为 0x0800 时,表示将数据交付给 IP 协议。 |
| 数据 | 也称为效载荷,表示去掉以太网头部(目的地址+源地址+类型)和尾部(FCS)剩下的网络数据包的大小交付给上层的数据。以太网帧数据长度最小为 46 字节,最大为 1500 字节。如果不足 46 字节时,会填充到最小长度。最大值也叫最大传输单元(MTU)。 在 Linux 中,使用 ifconfig 命令可以查看该值,通常为 1500。windows输入 netsh interface ipv4 show subinterfaces 可查看该值,通常为1500 |
| 帧检验序列 FCS | 检测该帧是否出现差错,占 4 个字节(32 比特)。发送方计算帧的循环冗余码校验(CRC)值,把这个值写到帧里。接收方计算机重新计算 CRC,与 FCS 字段的值进行比较。如果两个值不相同,则表示传输过程中发生了数据丢失或改变。这时,就需要重新传输这一帧。 |
1.3 以太网帧类型
EtherType 是以太帧里的一个字段,用来指明应用于帧数据字段的协议。根据 IEEE802.3,Length/EtherType 字段是两个八字节的字段,含义两者取一,这取决于其数值。在量化评估中,字段中的第一个八位字节是最重要的。而当字段值大于等于十进制值 1536 (即十六进制为 0600)时, EtherType 字段表示为 MAC 客户机协议(EtherType 解释)的种类。该字段的长度和 EtherType 详解是互斥的。
| EtherType 值 | 协议 |
|---|---|
| 0x0800 | IPV4 |
| 0x0806 | ARP |
| 0x^8864 | PPOE |
| 0x^86DD | IPV6 |
| 0x9000 | LOOPBACK |
1.3.1 IPV4 数据报结构
使用 IP 协议传输数据的包被称为 IP 数据包,每个数据包都包含 IP 协议规定的内容。IP 协议规定的这些内容被称为 IP 数据报文(IP Datagram) 或者 IP 数据报。
IP 数据报文由首部(称为报头)和数据两部分组成。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据报必须具有的。在首部的固定部分的后面是一些可选字段,其长度是可变的。
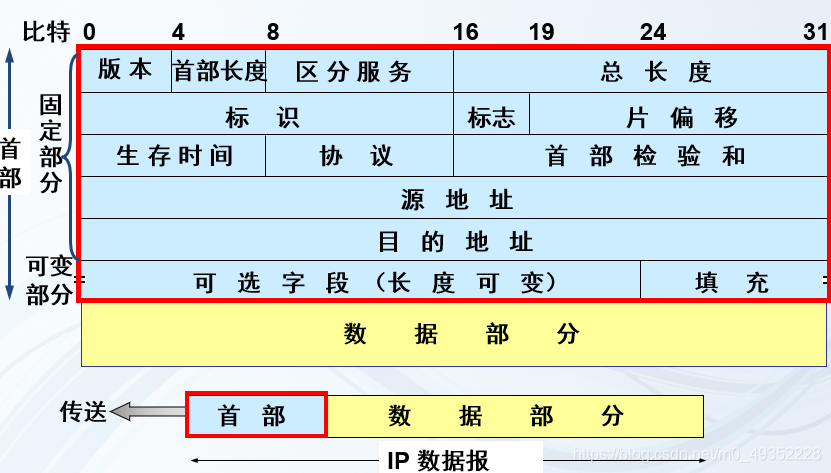
IP 报头的最小长度为 20 字节,上图中每个字段的含义如下:
| 字段 | 位宽(bit) | 解释 |
|---|---|---|
| 版本 | 4 | 表示 IP 协议的版本。通信双方使用的 IP 协议版本必须一致。目前最广泛的是IPv4=4’b0100,相信IPv6=4’b0110 |
| 首部长度 | 4 | 可表示的最大十进制数值是 15。这个字段所表示数的单位是 32 位字长(1 个 32 位字长是 4 字节)。因此,当 IP 的首部长度为 1111 时(即十进制的 15),首部长度就达到 60 字节。当 IP 分组的首部长度不是 4 字节的整数倍时,必须利用最后的填充字段加以填充。 数据部分永远在 4 字节的整数倍开始,这样在实现 IP 协议时较为方便。首部长度限制为 60 字节的缺点是,长度有时可能不够用,之所以限制长度为 60 字节,是希望用户尽量减少开销。最常用的首部长度就是 20 字节(即首部长度为 0101),这时不使用任何选项。 |
| 区分服务(tos) | 8 | 也被称为服务类型,用来获得更好的服务。这个字段在旧标准中叫做服务类型,但实际上一直没有被使用过。1998 年 IETF 把这个字段改名为区分服务(Differentiated Services,DS)。只有在使用区分服务时,这个字段才起作用。每个位的意义如下: 过程字段: 3位,设置了数据包的重要性,取值越大数据越重要,取值范围为:0(正常)~ 7(网络控制) 延迟字段: 1位,取值:0(正常)、1(期特低的延迟) 流量字段: 1位,取值:0(正常)、1(期特高的流量) 可靠性字段:1位,取值:0(正常)、1(期特高的可靠性) 成本字段:1位,取值:0(正常)、1(期特最小成本) 保留字段:1位 ,未使用 |
| 总长度(totlen) | 16 | 首部和数据之和,单位为字节。总长度字段为 16 位,因此数据报的最大长度为 2^16-1=65535 字节。 |
| 标识(identification) | 16 | 用来标识数据报,占 16 位。IP 协议在存储器中维持一个计数器。每产生一个数据报,计数器就加 1,并将此值赋给标识字段。 当数据报的长度超过网络的 MTU,而必须分片时,这个标识字段的值就被复制到所有的数据报的标识字段中。具有相同的标识字段值的分片报文会被重组成原来的数据报。 |
| 标志(flag) | 3 | 第一位未使用,其值为 0。第二位称为 DF(不分片),表示是否允许分片。取值为 0 时,表示允许分片;取值为 1 时,表示不允许分片。第三位称为 MF(更多分片),表示是否还有分片正在传输,设置为 0 时,表示没有更多分片需要发送,或数据报没有分片。 |
| 片偏移(offsetfrag) | 13 | 当报文被分片后,该字段标记该分片在原报文中的相对位置。片偏移以 8个字节为偏移单位。所以,除了最后一个分片,其他分片的偏移值都是 8 字节(64 位)的整数倍。 |
| 生存时间(TTL) | 8 | 表示数据报在网络中的寿命,占 8 位。该字段由发出数据报的源主机设置。其目的是防止无法交付的数据报无限制地在网络中传输,从而消耗网络资源。 路由器在转发数据报之前,先把 TTL 值减 1。若 TTL 值减少到 0,则丢弃这个数据报,不再转发。因此,TTL 指明数据报在网络中最多可经过多少个路由器。TTL 的最大数值为 255。若把 TTL 的初始值设为 1,则表示这个数据报只能在本局域网中传送。 |
| 协议 | 8 | 表示该数据报文所携带的数据所使用的协议类型,占 8 位。该字段可以方便目的主机的 IP 层知道按照什么协议来处理数据部分。不同的协议有专门不同的协议号。例如,TCP 的协议号为 6,UDP 的协议号为 17,ICMP 的协议号为 1。 |
| 首部检验和(checksum) | 16 | 用于校验数据报的首部,占 16 位。数据报每经过一个路由器,首部的字段都可能发生变化(如TTL),所以需要重新校验。而数据部分不发生变化,所以不用重新生成校验值。 |
| 源地址 | 32 | 表示数据报的源 IP 地址,占 32 位。 |
| 目的地址 | 32 | 表示数据报的目的 IP 地址,占 32 位。该字段用于校验发送是否正确。 |
| 可选字段 | 40byte | 该字段用于一些可选的报头设置,主要用于测试、调试和安全的目的。这些选项包括严格源路由(数据报必须经过指定的路由)、网际时间戳(经过每个路由器时的时间戳记录)和安全限制。 |
| 填充 | 8/16/24 | 由于可选字段中的长度不是固定的,使用若干个 0 填充该字段,可以保证整个报头的长度是 32 位的整数倍。 |
| 数据部分 | – | 表示传输层的数据,如保存 TCP、UDP、ICMP 或 IGMP 的数据。数据部分的长度不固定。 |
1.3.1.1 TCP数据包
TCP报文由首部和数据两部分组成。首部一般由20-60字节(Byte)构成,长度可变。其中前20B格式固定,后40B为可选。
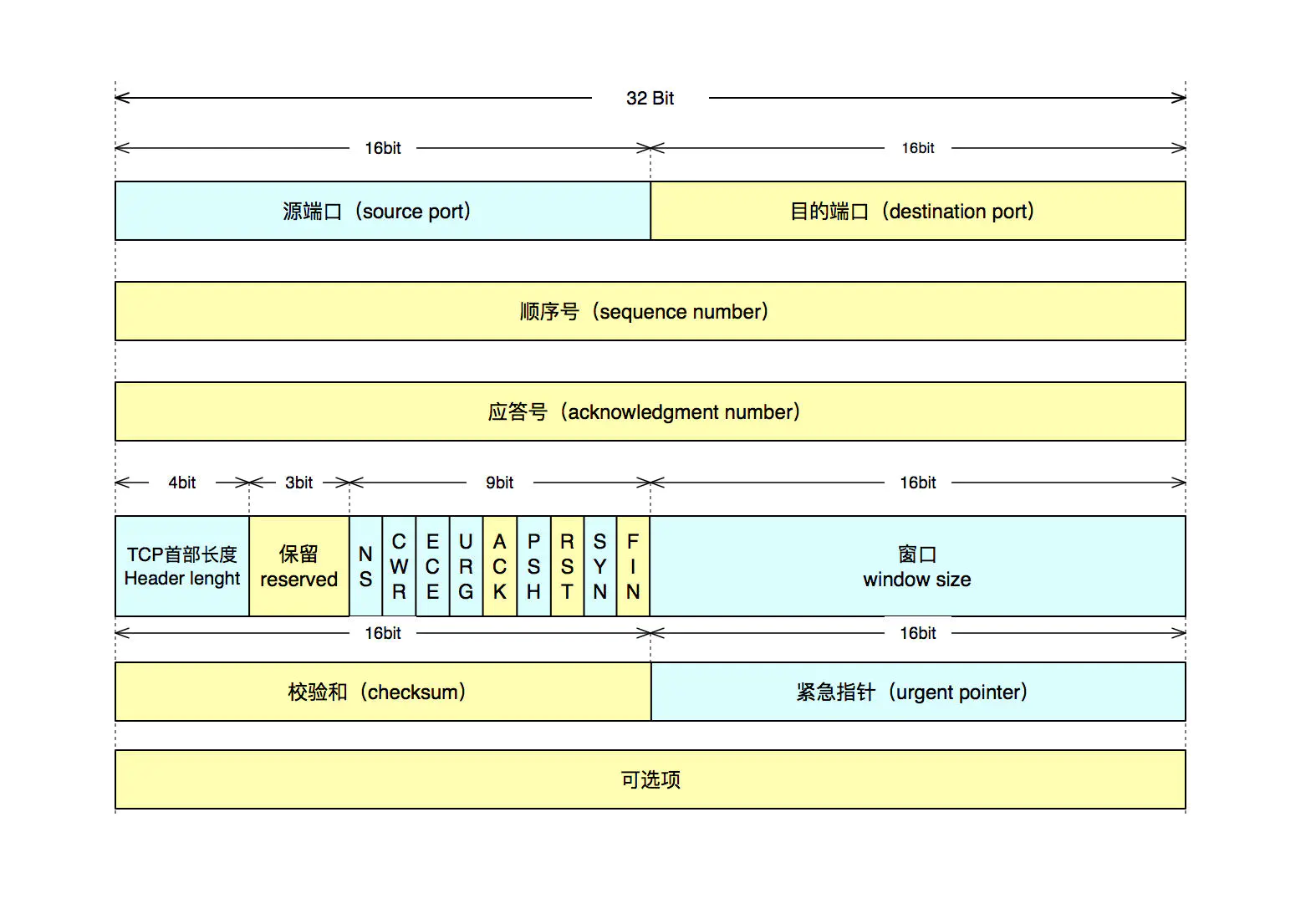
源端口:发送数据源设备端口号
目的端口:接收端目的设备端口号
顺序号:该数据报第一个数据字节的序号(分片前在整体中的序号),即字节流的计数。在建立连接时通常由计算机生成一个随机数作为序列号的初始值。
应答号(ACK NUMBER):占 4 个字节,表示期望收到对方下一个报文段的序号值。 TCP 的可靠性,是建立在每一个数据报文都需要确认收到的基础之上的。
就是说,通讯的任何一方在收到对方的一个报文之后,都要发送一个相对应的「确认报文」,来表达确认收到。 那么,确认报文,就会包含确认号。 例如,通讯的一方收到了第一个 25kb 的报文,该报文的 序号值=0,那么就需要回复一个确认报文,其中的确认号 = 25600.
数据偏移(TCP首部长度):标明TCP协议报头长度,单位是32bit即4个字节,其最小值为5(5 x 4 = 20 byte,这个长度是除去可选项的长度),从上图中看出,其规定头部长为 4 bit,所以最大值为 15, 15 x 4 = 60 byte可以算出可选项长度大为40个字节(60 byte - 20 byte = 40 byte)
保留位:保留字段长度为3位,必须全置为0
标记:
| 标志位简写 | 全写 | 含义 |
|---|---|---|
| NS | Nonce | 有效排除潜在的ECN滥用 |
| CWR | Congestion Window Reduced | 拥塞窗口减少标志 |
| ECE | ECN-Echo | CN标志 |
| URG | Urgent | 紧急指针有效性标志 |
| ACK | Acknowledgment | 确认序号有效性标志,一旦一个连接建立起来,该标志总被置为1 |
| PSH | Push | ush标志(接收方应尽快将报文段提交至应用层) |
| RST | Reset | 重置连接标志 |
| SYN | Synchronization | 同步序号标志(建立连接时候使用) |
| FIN | Fin | 传输数据结束标志(断开连接时使用) |
窗口:表示发送方还可以接受数据大小,防止对方发送数据大于自己的缓冲数据区,从应答字段的顺序号开始计。
效验和:效验和覆盖整个TCP报文段,强制字段,由发送端计算存储,接收端进行验证
紧急指针:当Urgent标志置1时,紧急指针才有效
TCP三次握手
所谓三次握手(Three-way Handshake),是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。三次握手的目的是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号并交换 TCP 窗口大小信息。
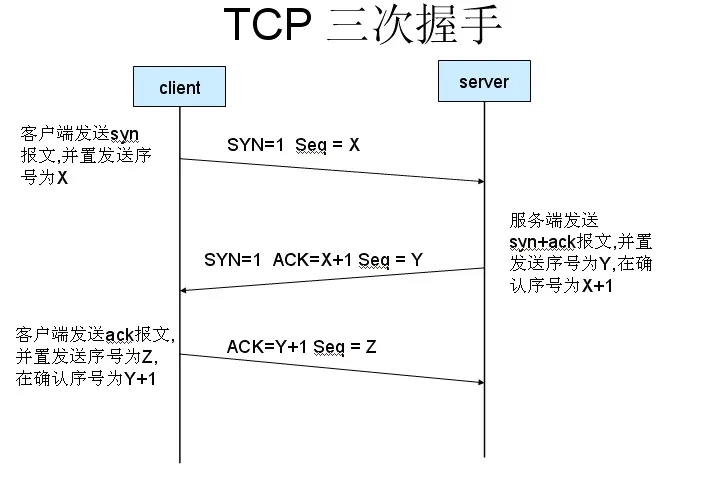
Wireshark 抓包工具抓取到三次握手信息如下图所示:

第1次握手
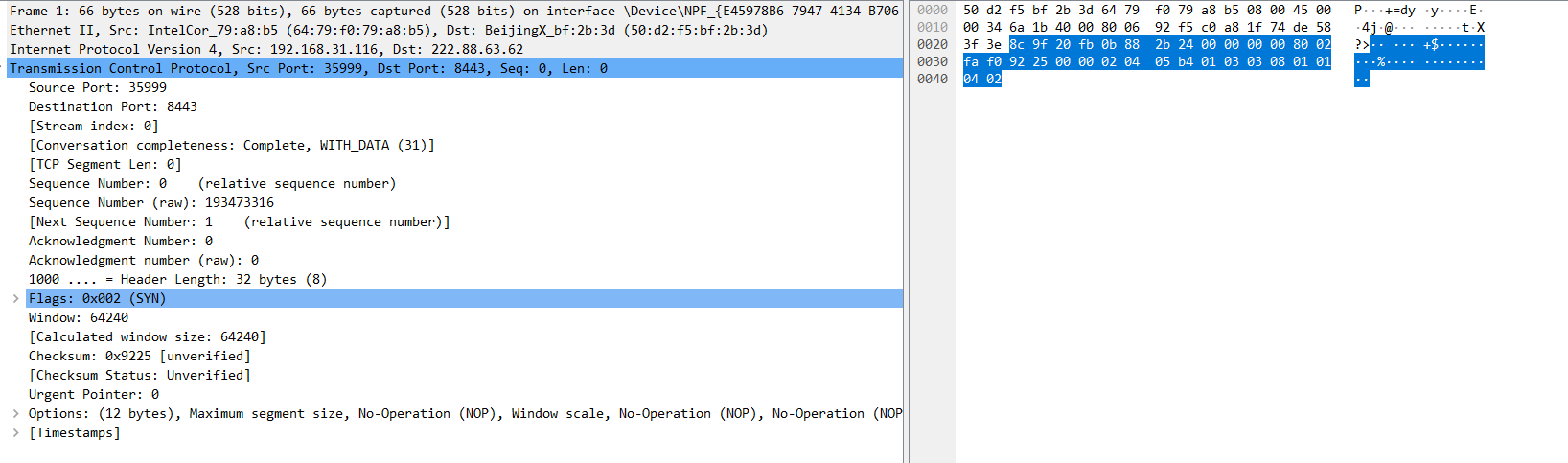
第2次握手
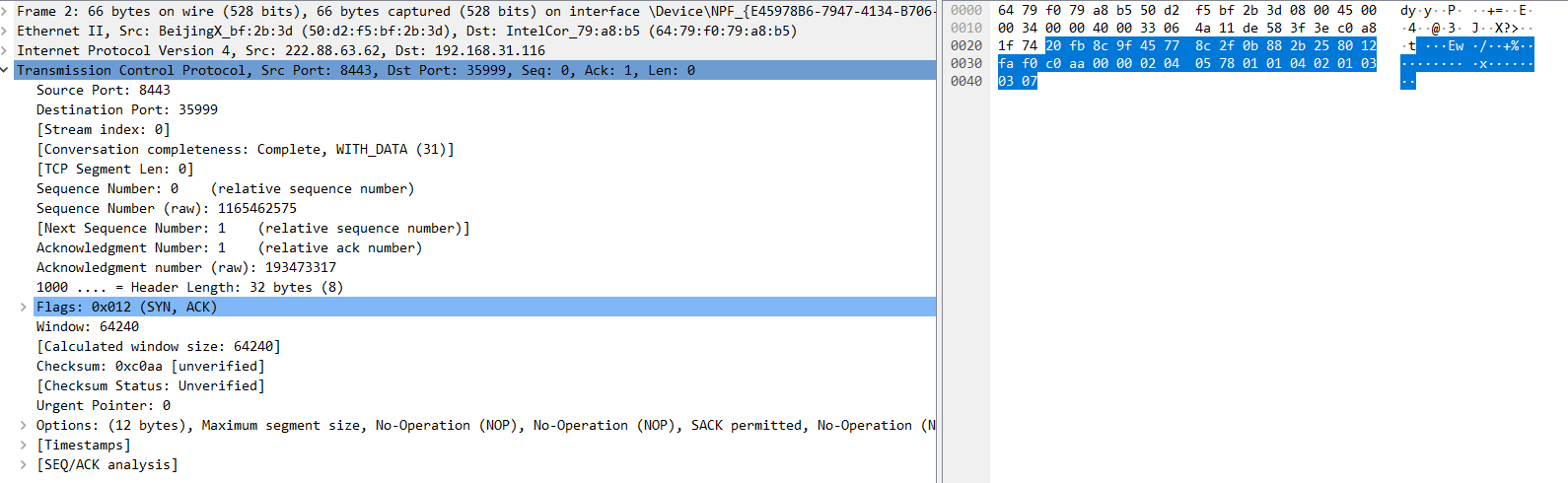
第3次握手
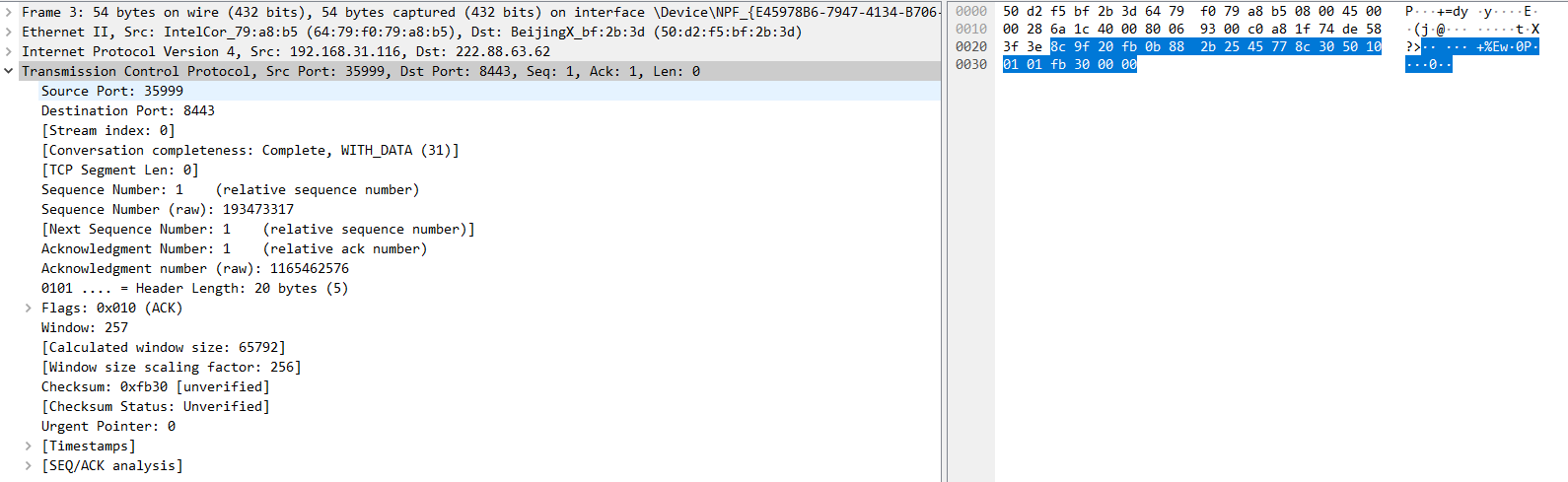
1.3.1.2 UDP数据包
UDP协议是IP协议上层的另一个重要协议,他是面向无连接的、不可靠的数据报传输协议,他仅仅将要发送的数据报传送至网络,并接受从网络上传来的数据报,而不与远端的UDP协议模块建立连接。UDP协议为用户的网络应用程序提供服务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GN5y3xNK-1667968449328)(udp.webp)]
- 源端口: 源端口号。在需要对方回信时选用。不需要时可用全0。
- 目的端口: 目的端口号。这在终点交付报文时必须要使用到。
- 长度: UDP用户数据报的长度,其最小值是8(仅首部)单位为byte。
- 校验和: 检测UDP用户数据报在传输中是否有错。有错就丢弃。该字段是可选的,当源主机不想计算校验和,则直接令该字段全为0.
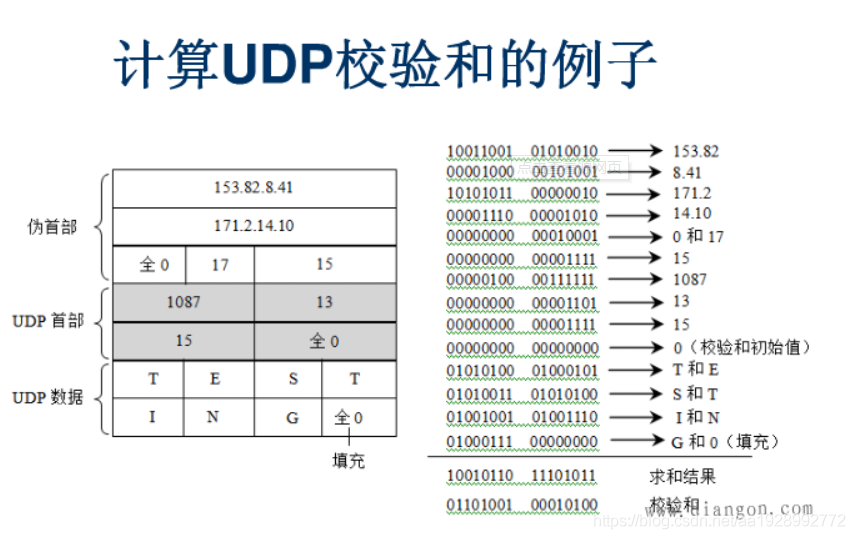
UDP检验和计算
DP计算校验和的方法和IP数据报首部校验和的方法相似。不同的是:IP数据报校验和只校验IP数据报的首部,但UDP的校验和是把首部和数据部分一起都检验。
UDP的校验和需要计算UDP首部加数据荷载部分,但也需要加上UDP伪首部。这个伪首部指,源地址、目的地址、UDP数据长度、协议类型(0x11),协议类型就一个字节,但需要补一个字节的0x0,构成12个字节。伪首部+UDP首部+数据一起计算校验和。
UDP检验和的计算方法是:
- 在 UDP 首部前添加 12 字节的伪首部
- 将首部校验和部分置零为 0x0000
- 按每16位求和得出一个32位的数
- 如果这个32位的数,高16位不为0,则高16位加低16位再得到一个32位的数
- 重复第4步直到高16位为0,将低16位取反,得到校验和。
- 将校验结果填充到 UDP 首部
1.3.3 ARP 报文
ARP 协议包(ARP 报文)主要分为 ARP 请求包和 ARP 响应包,本节将介绍 ARP 协议包的格式。
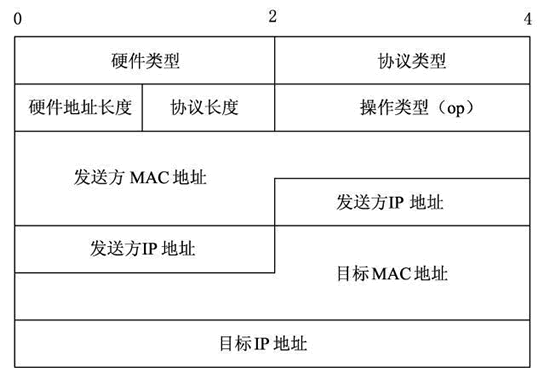
ARP 报文总长度为 28 字节,MAC 地址长度为 6 字节,IP 地址长度为 4 字节。
其中,每个字段的含义如下。
- 硬件类型:指明了发送方想知道的硬件接口类型,以太网的值为 1。
- 协议类型:表示要映射的协议地址类型。它的值为 0x0800,表示 IPV4 。
- 硬件地址长度和协议长度:分别指出硬件地址和协议的长度,以字节为单位。对于以太网上 IP 地址的ARP请求或应答来说,它们的值分别为 6 和 4。
- 操作类型:用来表示这个报文的类型,ARP 请求为 1,ARP 响应为 2,RARP 请求为 3,RARP 响应为 4。
- 发送方 MAC 地址:发送方设备的硬件地址。
- 发送方 IP 地址:发送方设备的 IP 地址。
- 目标 MAC 地址:接收方设备的硬件地址。
- 目标 IP 地址:接收方设备的IP地址。
ARP 数据包分为请求包和响应包,对应报文中的某些字段值也有所不同。
ARP 请求包报文的操作类型(op)字段的值为 request(1),目标 MAC 地址字段的值为 Target 00:00:00_00:00:00(00:00:00:00:00:00)(广播地址)。
ARP 响应包报文中操作类型(op)字段的值为 reply(2),目标 MAC 地址字段的值为目标主机的硬件地址。
1.4 以太帧FCS计算
FCS是 802.3帧和Ethernet帧的最后一个字段(4字节)
帧校验序列(FCS) 是指特别的检测码字符被添加到在一个通信协议中的帧中进行检错和纠错。发送主机在整个帧中有一个检测码随着发送。接收主机在整个帧中的检测码使用相同的运算法则,并将它与接收到的 FCS 相比较。这样,它能够探测是否任何数据在运输中丢失或被改变。它可能当时丢失这个数据,和请求错误帧的重传。一个循环冗余码校验(CRC) 常被用来估算 FCS (CRC-32校验)。
循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种信道编码技术,主要用来检测或校验数据传输或者保存后可能出现的错误。它是利用除法及余数(按位异或) 的原理来作错误侦测的。
CRC算法参数模型解释:
NAME:参数模型名称。
WIDTH:宽度,即CRC比特数。
POLY:生成项的简写,以16进制表示。例如:CRC-32即是0x04C11DB7,忽略了最高位的"1",即完整的生成项是0x104C11DB7。
INIT:这是算法开始时寄存器(crc)的初始化预置值,十六进制表示。
REFIN:待测数据的每个字节是否按位反转,True或False。
REFOUT:在计算后之后,异或输出之前,整个数据是否按位反转,True或False。
XOROUT:计算结果与此参数异或后得到最终的CRC值。
| CRC算法名称 | 多项式公式 | 宽度 | 多项式 | 初始值 | 结果异或值 | 输入反转 | 输出反转 |
|---|---|---|---|---|---|---|---|
CRC-8 |
8 | 07 | 00 | 00 | false | false | |
CRC-8/ITU |
8 | 07 | 00 | 55 | false | false | |
CRC-8/ROHC |
8 | 07 | FF | 00 | true | true | |
CRC-8/MAXIM |
8 | 31 | 00 | 00 | true | true | |
CRC-16/IBM |
16 | 8005 | 0000 | 0000 | true | true | |
CRC-16/MAXIM |
16 | 8005 | 0000 | FFFF | true | true | |
CRC-16/USB |
16 | 8005 | FFFF | FFFF | true | true | |
CRC-16/MODBUS |
16 | 8005 | FFFF | 0000 | true | true | |
CRC-16/CCITT |
16 | 1021 | 0000 | 0000 | true | true | |
CRC-16/CCITT-FALSE |
16 | 1021 | FFFF | 0000 | false | false | |
CRC-16/X25 |
16 | 1021 | FFFF | FFFF | true | true | |
CRC-16/XMODEM |
16 | 1021 | 0000 | 0000 | false | false | |
CRC-16/DNP |
16 | 3D65 | 0000 | FFFF | true | true | |
CRC-32 |
32 | 04C11DB7 | FFFFFFFF | FFFFFFFF | true | true | |
CRC-32/MPEG-2 |
32 | 04C11DB7 | FFFFFFFF | 00000000 | false | false |
1.4.1 CRC并行计算原理
这里推荐一篇文章CRC查询表及其并行矩阵生成方法,里面详细介绍了CRC并行计算的数学推到原理,以下是对该文章推到过程简单描述与并行矩阵求取;
这里理解一个概念,假设用一个8位多项式(CRC8),求取N bit数据的CRC校验和,可以将 N N Nbit 分成多个8bit数据 a 1 , a 2 , a 3 , . . . , a n a_1,a_2,a_3,...,a_n a1,a2,a3,...,an,进行叠加计算CRC,计算当前8bit的CRC校验和时,只与之前数据的校验和及当前数据相关,这里不再说明,可以看下CRC计算原理,第一个8bit数据的校验和计算需要用到多项式初始值
单bit CRC计算
单bit实现,从 x ( t ) x(t) x(t) 到 x ( t + 1 ) x(t+1) x(t+1), ( x 0 , x 1 , … , x m − 1 ) ( x_0 , x_1 , … , x_{m−1}) (x0,x1,…,xm−1) 是当前要与被除数 poly: ( p 0 , p 1 , … , p m − 1 , p m ) ( p_0 , p_1 , … , p_{m−1} , p_m ) (p0,p1,…,pm−1,pm) 相异或的数据, b ( t ) b(t) b(t) 是刚进入的新的bit。


多bit CRC计算
多bit实现,从 x ( t ) x(t) x(t)到 x ( t + w ) x (t + w ) x(t+w)这样我们就能一次实现 w w w个bit的CRC值.

m位多项式poly的系数 ( p 0 , p 1 , p 2 , . . . , p m − 1 ) (p_0,p_1,p_2,...,p_{m-1}) (p0,p1,p2,...,pm−1) 我们是知道的,这样可以计算出 F w F^w Fw,再根据上述公式计算出CRC值.
利用matlab求解时 F w = m o d ( F w , 2 ) F^w = mod(F^w,2) Fw=mod(Fw,2)
以CRC8 为例子: 数据输入位宽为8
poly多项式 G ( x ) = x 8 + x 2 + x + 1 {G(x)=x^8 + x^2 + x + 1} G(x)=x8+x2+x+1
F = [ 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 ] F 8 = [ 1 1 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 1 1 1 0 0 1 0 0 0 1 1 1 0 0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 1 1 1 0 0 0 0 0 1 ] F= \begin{bmatrix} 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 & 0 & 0 & 1 & 0 \\ 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \\ 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix} F^8= \begin{bmatrix} 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 1 & 1 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 1 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 1 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 & 1 & 1 & 1 & 0 \\ 0 & 1 & 0 & 0 & 0 & 1 & 1 & 1 \\ 0 & 1 & 0 & 0 & 0 & 0 & 1 & 1 \\ 1 & 1 & 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix} F=⎣ ⎡0000011110000000010000000010000000010000000010000000010000000011⎦ ⎤F8=⎣ ⎡1000100111000111111000000111000000111000000111000000111000000111⎦ ⎤
系数为1的位为(最高位对应F^8第一行):
第7行:$ bit0 => 7,6,0 $
第6行:$ bit1 => 6,1,0$
第5行:$ bit2 => 6,2,1,0$
第4行:$ bit3 => 7,3,2,1$
第3行:$ bit4 => 4,3,2$
第2行:$ bit5 => 5,4,3$
第1行:$ bit6 => 6,5,4$
第0行:$ bit7 => 7,6,5$
实现代码:
assign crcOut[0] = (crcIn[0] ^ crcIn[6] ^ crcIn[7] ^ data[0] ^ data[6] ^ data[7]);
assign crcOut[1] = (crcIn[0] ^ crcIn[1] ^ crcIn[6] ^ data[0] ^ data[1] ^ data[6]);
assign crcOut[2] = (crcIn[0] ^ crcIn[1] ^ crcIn[2] ^ crcIn[6] ^ data[0] ^ data[1] ^ data[2] ^ data[6]);
assign crcOut[3] = (crcIn[1] ^ crcIn[2] ^ crcIn[3] ^ crcIn[7] ^ data[1] ^ data[2] ^ data[3] ^ data[7]);
assign crcOut[4] = (crcIn[2] ^ crcIn[3] ^ crcIn[4] ^ data[2] ^ data[3] ^ data[4]);
assign crcOut[5] = (crcIn[3] ^ crcIn[4] ^ crcIn[5] ^ data[3] ^ data[4] ^ data[5]);
assign crcOut[6] = (crcIn[4] ^ crcIn[5] ^ crcIn[6] ^ data[4] ^ data[5] ^ data[6]);
assign crcOut[7] = (crcIn[5] ^ crcIn[6] ^ crcIn[7] ^ data[5] ^ data[6] ^ data[7]);
1.5 待补充
后续视情况补充