Disentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth
解释无监督多帧弹幕深度估计的物体运动和遮挡
知识点:成本量构建,由于我本身不做立体匹配,所以开始理解的时候较为困难,也比较难区分单帧深度估计和多帧深度估计,查阅文献后,总结如下,立体匹配的成本量,其实就是相邻帧特征图的视差,最后经过上采样取到数后得到深度图,而立体匹配在推理时是必须要多帧输入的,我们常做的模型在训练结束后,只需要单帧图像即可得到深度信息。
0 Abstract
传统的自监督单目深度估计是基于静态世界的假设所建立的,所以运动物体会导致深度估计精度下降。现有的方法尽在训练损失级别上解决了运动物体的失配问题,而本文提出了一种新颖的多帧单目深度估计方法,通过动态运动解释模块(DOMD)来解决适配问题,并设计了新的遮挡感知成本体积和再投影损失。在cityspaces和kitti上效果良好。
1 Introduction
单目深度估计由于无需昂贵的传感器或标记数据,所以工业界和研究界被广泛的使用。但常规的单目深度估计采用重投影损失来计算相邻帧之间的几何一致性,但他们无法预测网络中水平帧的几何一致性,这限制了他们的性能。
现实世界中存在大量时间和空间连续的图像,近年来,基于时间图像的多帧单目深度预测方法被研究人员广泛关注。但是这些方法大多是基于静态世界假设,这使得运动物体的深度估计总是存在误差。
最近的一些方法,例如对运动物体进行语义分割、momo2里面直接剔除、对运动物体进行单独的位姿计算等这些方法试图优化运动物体的深度估计,但他们任然存在以下几个问题。1.他们仅在损失函数方面解决了失配问题,无法通过时间框架来推理运动物体。2.运动物体导致的遮挡任未解决。3.冗余对象预测网络对非刚性物体的运动不起作用,增加了模型的复杂度。本文的总体贡献如下:
- 提出了运动对象解释模块DOMD,该模块利用出事深度预测来解决最终深度预测中的运动物体失配问题。
- 设计了一种新的动态对象周期一致的训练方案,来相互加强先验深度和最终深度预测。
- 设计了一种可感知遮挡的成本量,即使在运动对象区域也可以进行跨帧几何推理。
- cityspaces和kitti上效果良好。
2 Related work
从单帧,多帧,运动物体感知等三个方面来介绍当前工作。
由于标记数据的可用性有限,自监督单目深度估计方法变得越来越流行,momo2提供了良好的单目深度估计框架,PackNet探索了新的网络框架,但上述方法都存在一个问题,即静态世界假设,而我们的模型可能很好的解决这个问题。
上述的一些方法仅在训练损失函数时使用时间约束,模型本身不将任何时间信息作为推理的输入,而一种有前途的方法是在输入和预测阶段利用时间信息,早期的一些方法采用循环网络(循环网络多用于NLP或者语音处理,其独特的网络结构适合处理带有时间序列的数据),但循环网络要耗费巨大的计算量,,并且在预测过程中没有采用明确编码和推理几何约束,最近一些方法例如Manydepth和MonoRec利用立体匹配的成本量(即修改后的特征图),以在推理过程中实现基于几何的推理,但是成本量的构建依然依赖静态世界的假设。最近一些方法例如SGDepth采用语义分割来对运动物体进行单独建模,还有一些方法对运动物体进行单独的位姿估计,但这些问题还是存在一些缺陷。1.采用单帧输入使得模型无法使用时域信息。2.明确预测运动物体需要添加额外的模块。3.这些方法只关注了重投影问题,而没有解决遮挡问题。而我们的模型剔除的运动物体解释模块在成本量(即在模型中使用时序信息)和损失函数上都齐了作用,解决了重投影问题,同时,在推理过程中通过时间框架实现几何推理的显式运动物体预测,此外,提出了可感知遮挡的成本体积和可感知的再投影损耗,解决了遮挡问题。
3 Method
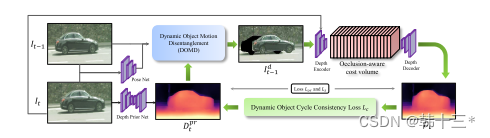
本文的整体框架如图所示,输入图像为It和It-1,首先采用深度先验网络得到Dprt,采用先验深度Dprt和posenet得到的位姿关系计算正确投影的物体图像,将计算后的运动物体直接替换到It-1,原来的运动物体剔除(即为上述黑色部分)得到Idt-1,将It和Idt-1送入网络中进行成本量构建,这里其实就是将两张图片的每个通道的特征图进行损失计算,下面会详细接受,最后再进行上采样得到最终的深度图Dt,并且这里设计了以这个动态对象循环一致性损失来相互增强Dt和Dprt具体方法也会在下面讲到。
以下讲解运动物体解释模块DOMD的原理。
由于静态世界假设,即在重投影计算过程中,只计算静态的物体,例如下图中的车辆C来说在图像It是Ct,在图像It-1是Ct-1,如果该车辆静止的话从Ct上计算的重投影应该和Ct-1,反过来同理,但对于运动物体不能这样计算,这是由于运动物体在连续帧之间会发生自我,采用原来的方式会导致投影错误,这是mono2当初剔除运动像素的原因,本文提出了DOMD就是从帧间几何来推理正确的运动物体位置Cdt-1。
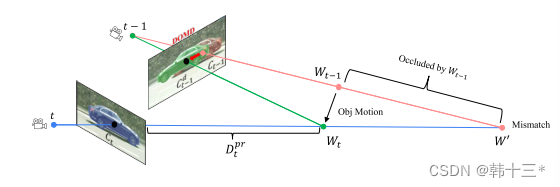
从公式上来说比较简单,Sa是一个动态物体标签,用于从图像中提取运动物体,π是重投影操作符,用于从3D到2D,取决于相机内参,π-1是反向重投影操作符,用于从2D到3D,取决于相机内参和该像素点的坐标和深度信息,当我们要计算图像It中的运动物体Ct在It-1中的正确投影Cdt-1时,首先采用深度先验网络计算Ct的深度信息Dprt,下图中的第二个公式,第一次反变换将Ct投影为三维坐标中的实际物体Wt,第二次变换将其投影到It-1中得到Cdt-1,最后将It-1中的物体Ct-1直接替换为Cdt-1最终得到Idt-1。
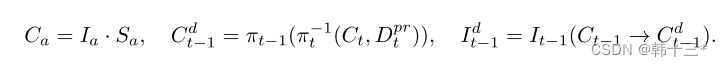
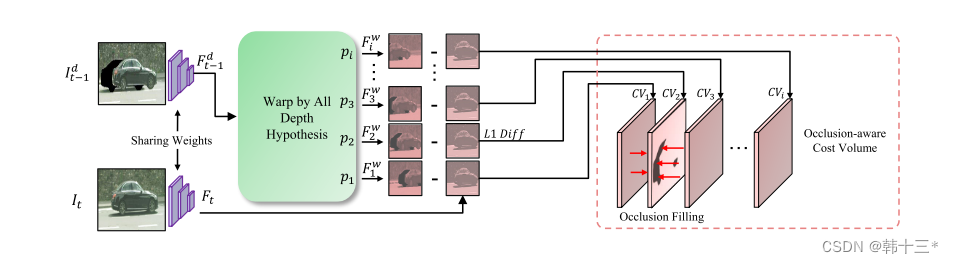
下面解释带有时间序列的遮挡感知成本量。
我们将图像Idt-1和It送入相同的编码器进行特征提取,得到多通道的特征图Fdt-1和Ft,这里采用了一个预定义的假设深度Pi(查阅相关文献没有详细解释,我个人理解就是该特征图对应的深度,有前面的Dprt获得),通过Fdt-1采用两次投影和假设深度Pi得到了扭曲后的特征图Fwt,将其和Ft进行简单的L1损失计算得到遮挡感知成本量,将其中的黑色部分替换为周边区域,以避免污染成本分布。
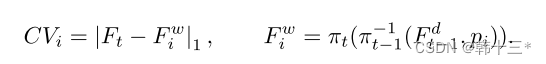
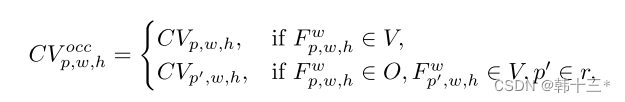
动态对象周期一致性损失,用来约束最终的深度Dt和Dprt和先验深度的相似性。其中S是动态物体分割掩码。
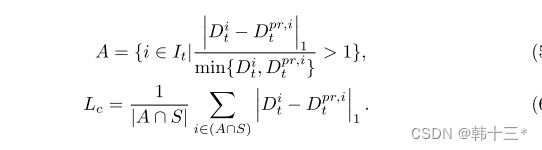
遮挡感知重投影损失。原先的重投影损失例如mono2中在处理遮挡问题中是选择相邻帧中光度损失的最小值来进行计算(在这之前是平均),后面大多数都采用了这种方法,而本文在处理遮挡的时候总是选择为发生遮挡的相邻帧来进行光度损失计算,都发生遮挡的时候就剔除。
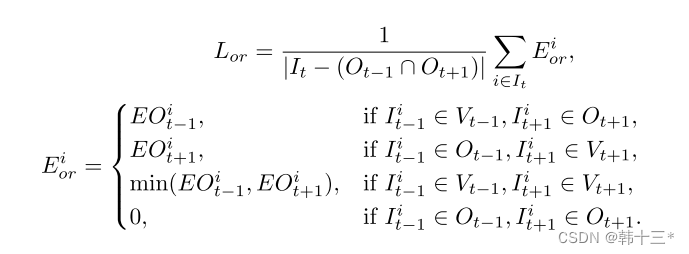
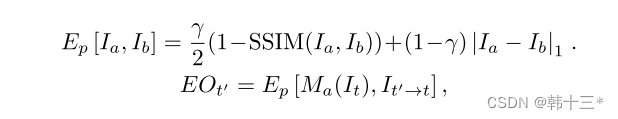
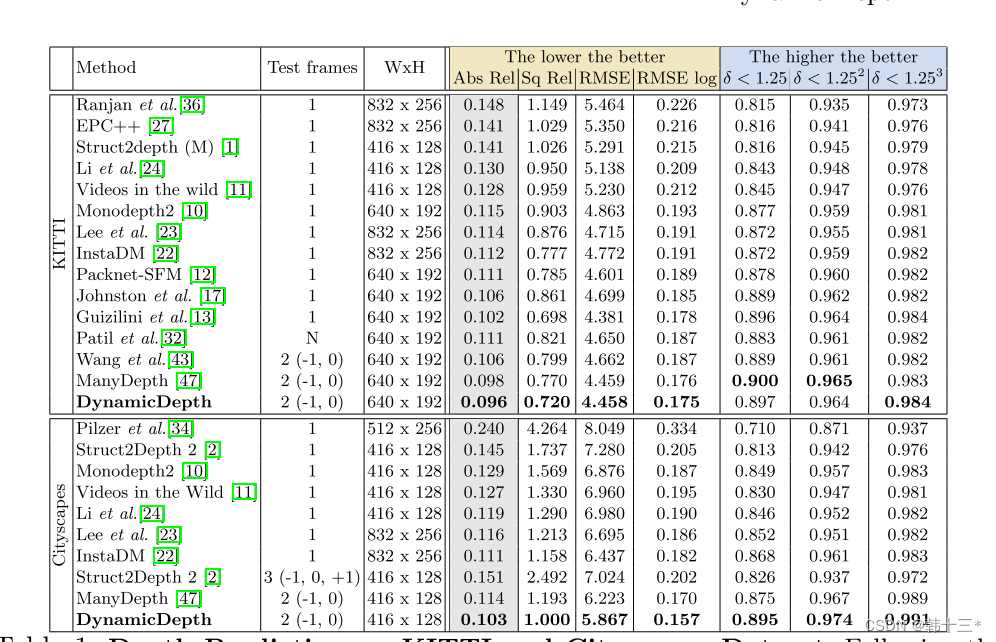
4 Experiments
KITTI结果。