
💭 写在前面
本系列博客基于著名计算机操作系统教程《操作系统导论》()为基础,进行的笔记整理,加入了个人在阅读过程中的一些见解和理解方式。本章我们将继续讲解超越物理内存的策略部分,我们将介绍几种常见的策略。最后再根据书本的进度,简单介绍一下 抖动、预读等概念。
对了,本系列博客改写作风格了。之前的写的太过于笔记化!缺少个人思考和见解,更像是 (就是)对原书的摘录。所以从本章开始,我将延续《C++要笑着学》专栏的风格去写。其实本书原作者 Remzi 教授在撰写此书时采用的是幽默的写作方式,所以我在记笔记时也想延续他的一些理念,比如 —— 适当加点表情包(当然不会像C++笑着学系列多,精力有限),适当玩一些梗,或者举一些 "比较有趣的例子" 帮助理解一些枯燥的概念,比如 ——

希望大家喜欢~
0x00 引入:更低的页错误率?
上一章我们介绍了页错误,页错误当然是让人讨厌的存在了,我们自然是想要更低的页错误率。
我们现在来讲解一种算法 —— 页面替换算法(Page Replacement Algorithms)
❓ 那么如何知道页错误率是多少呢?
我们可以通过在一串特定的内存引用上运行算法,并计算该字符串上页错误数量来估算该算法的好坏。举个例子,如果我们跟踪一个特定的进程,我们或许能记录到以下的地址序列:

在每页 100 字节的情况下,参考字符串为:
1, 4, 1, 6, 1, 6, 1, 6, 1, 6, 1在第一次引用后,直接引用将不会出现错误。
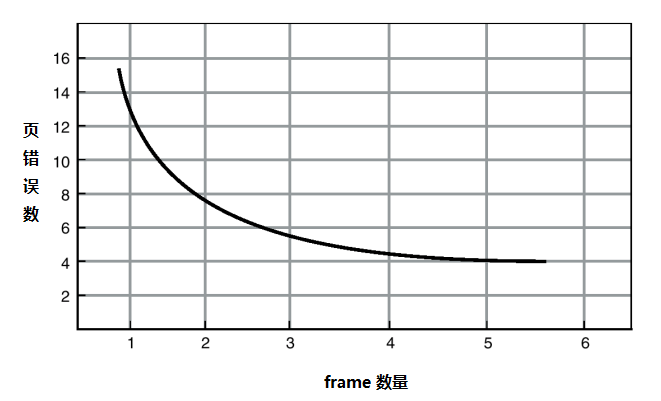
📜 页错误与帧数量的关系:
一般来说,随着帧数量的增加,页错误的数量将会减少,并下降到某个最小的水平线。
0x01 一种简单的策略:FIFO
早期的操作系统采用了一些非常无脑但简单的策略,就比如一些操作系统使用了 。
也就是 "先进先出" 的替换策略:当页进入系统时,将它们推到一个队列里。
 当发生替换时,队列尾部的页 (先进来的页) 将会被叉出去!
当发生替换时,队列尾部的页 (先进来的页) 将会被叉出去!
该策略最大的优势就是 —— 实现起来相当的简单!
它的实现一听就很简单,但是这种策略无法确定帧的重要性。
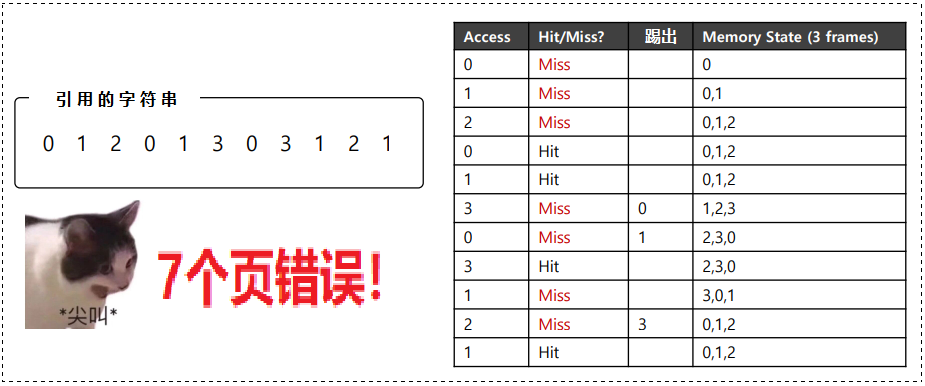
一上来就是 3 个未命中?不要惊讶!因为缓存开始时是空的,这种未命中有时也称为 "冷启动未命中" (cold-start miss),或称为 "强制未命中"。
看到没?即使第0页已经被多次访问,但是 仍然会将其踢出!因为它是第一个进入内存的。
Even though page 0 had been accessed a number of times, FIFO still kicks it out.
0x02 Belady现象(Belady's Anomaly)
Belady —— 最优策略发明者。他和他的同事发现了一个有意思的引用序列。
内存引用顺序是 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5。它们正在研究的替换策略是 。
这时有趣的问题发生了:当缓存大小从 3 变成 4 时,缓存命中率如何优化?
一般来说,当缓存变大时,缓存命中率是会提高的。
但在这种情况下使用 ,命中率反而下降了:
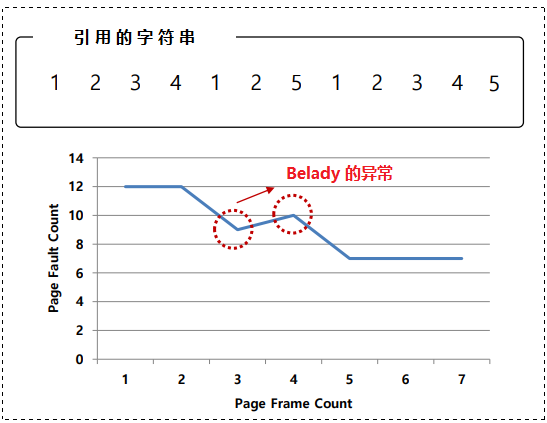
这种奇怪的现象被称为 Belady 的异常 (Belady's Anomaly) 。
0x03 另一种简单地策略:随机(Random)
当内存满了就随机选择一个页进行替换,随即具有类似于 的属性,实现起来很简单。
但是他在挑选替换哪个页时不够智能,我们还是用刚才的例子去看这个策略:
其实,这就是纯纯的是看运气,赌狗必备…… 随机策略完全取决于当时的运气好坏。
The performance of random is sometimes good. It depends on the workload !
0x04 最优策略:OPT 替换策略(OPT Replacement Policy)
看了前面两个简单的策略,现在我们将介绍一位 "重量级" 选手:
OPT 替换策略 (Optimal Replacement Policy)
原来这个策略叫做 MIN,后来改叫做 OPT 了。这样的一种最优策略,是 Belady 大佬多年前开发的。最优替换策略能达到总体未命中数量最少。实现方式是 替换内存中在最远将来才会访问到的页,由此达到缓存未命中率最低 !
- Replace the page that will be accessed furthest in the future.
- Result in the fewest-possible cache misses (no Belady’s anomaly).
你可以想一想,如果你不得不踢出一些页,为什么不踢出在 "最远的将来" 才会访问的页呢?
"車到山前必有路,船到橋頭自然直,活在當下!"
为解决燃眉之急 —— 踢出 "最远的将来" 才会访问的页,这么做是因为缓存中 "所有其他页" 都比这个页重要。道理也很简单:在引用最远将来会访问的页之前,你肯定会引用其它页。
这就叫 "活在当下",先解决这一顿饭,至于下个月甚至是半年后的饭,就到时候再说,正所谓 "车到山前必有路,船到桥头自然直" ,我个人认为这就是这个策略的核心思想。
💭 例子:我们还是追踪一个简单的例子,来理解最优策略:

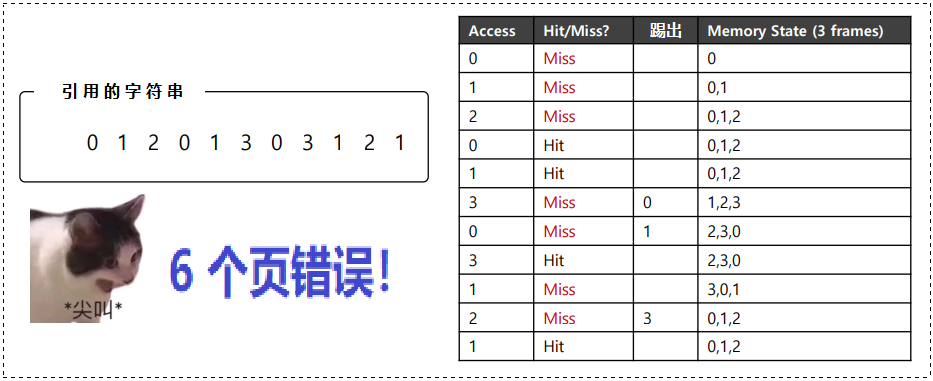
🔑 解析:一上来就是 3 个未命中,这很正常,这个我们刚才说过原因,冷启动未命中嘛……
首先 0,1 都在缓存中,然后页面3 此时又有一个未命中,此时就需要决策到底替换哪个页了。
使用 "活在当下" 的态度 —— OPT 替换策略!我们检查当前缓存中的每个页 (0,1,2) 未来访问情况,可以看到 页0 马上被访问,页1 稍后被访问,页2 在不远的将来被访问。
因此优策略的选择很简单 —— 直接踢出页面2,让页面2爬!!!
结果是缓存中的页面是 0, 1, 3,接下来的 3 个引用是命中的,然后右访问到我们之前踢出的页2,这时有是一个未命中(看图,记得看图!) ,
因此这里的最优策略是 再次检查缓存页 (0,1,3) 中每个页未来被访问的情况,此时图上踢的是 页3,其实此时踢出 页0 都可以,只要不踢出 页1 就行(因为1是即将访问的页,你踢它作甚?)。
How do you know this ? Requires future knowledge !
Can we use history as an approximation of the future ?
0x05 利用历史数据:LRU 策略
 我们前面介绍的
我们前面介绍的 策略和随机策略,都有可能产生一个致命的问题:
它可能会踢出一个重要的页,而这个页马上要被引用!
正如同调度策略所做的那样,为了提高后续命中率,我们再次通过历史的访问情况作为参考。
例如,如果某个程序在过去访问过某个页,则很有可能在不久的将来会再次访问该页。
"以史为鉴,可知兴替"
我们要介绍的 策略(页替换策略),就是利用了历史数据,去分析该踢谁!
页替换策略可以使用的一个历史信息是频率 (frequency),如果一个页被访问了很多次,也许它不应该被替换,因为它显然更有价值。页更常使用的属性是访问的近期性 (recency) ,越近被访问过的页,也许再次访问的可能性也就越大。这一系列给予人们所说的局部性原则,基本上只是对程序及其行为的观察。这个原理简单的说就是程序倾向于频繁访问某些代码 (例如循环) 和 数据结构(例如循环访问的数组)。
因此,我们应该尝试用历史数据来确定哪些页面更重要,并在需要踢出页时将这些页保存在内存中,做到 "心中自有丘壑" 。因此一系列基于 "历史" 的算法诞生了:
- 最不经常使用 (LFU) 策略:替换最不经常使用的页。
- 最少最近使用 (LRU) 策略:替换最少使用的页面。
计数器 (Counter) 的实现:
- 每个页表条目都有一个计数器。每次通过这个条目引用一个页面时,就把(逻辑)时钟复制到计数器中。每一次内存引用,时钟都会被递增。
- 当需要改变一个页面时,看一下计数器,以确定要改变哪个页面。
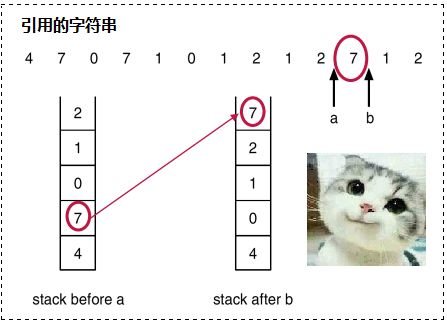
栈的实现:
- 以双链表的形式保存一个页号的栈。
- 每当一个页面被引用,就把它移到顶部;栈的顶部总是最近使用的页面,底部是 LRU 页面。
- 每一次更新都会有一些代价,无搜索替换。
0x06 LRU 近似算法
引用位算法:Reference Bit
从计算开销的角度来看,近似 更为可行,这实际上也是很多现代操作系统的做法。
该想法需要硬件增加一个 引用位 (Reference Bit) ,系统每个页有一个引用位,然后这些使用位存储在某个地方,当页被引用 (即读或写) 时,硬件将引用位设置为 1,但是硬件不会清除该位,取而代之的是将其设置为0 (有操作系统负责) 。如此一来,我们就知道哪些页被引用,哪些页没有被引用了。
这操作是不是很眼熟?这就像我们写代码经常用到的立 Flag 大法,flag = 0,flag = 1。
这种做法在第一个支持分页的系统 Atlas one-level store 中实现。
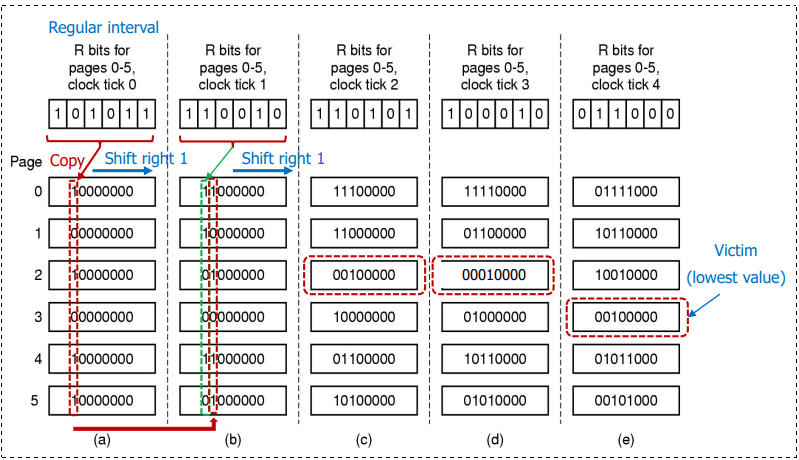
额外引用位算法:Additional Reference Bits Algorithm (Reference Byte Algorithm)
使用多个比特,按固定时间记录引用位。举个例子:
- 在内存中为每个页表保留一个8位字节。
- 在固定的时间间隔内,将参考位移入其8位字节的高阶位,将其他位右移1位,丢弃低阶位。
- 这些8位移位寄存器包含了过去8个时间段内的页使用历史。
- 当页错误发生时,我们将这些8位字节解释为无符号整数,数字最低的页面是LRU页面,它可以被取代。
"我还有机会吗" 算法:Second Chance Algorithm
保持加载在内存中的页面循环列表,当页一开始被加载时,参考位被设置为1。
当需要在页错误处理程序中替换一个页时,我们检查页的引用位:
- 如果值为0,则替换。
- 如果值是1,那么:
- 将引用位设置为0 (给第二次机会看它是否会被再次引用)
- 将该页留在内存中
- 按照时钟顺序检查下一个页面
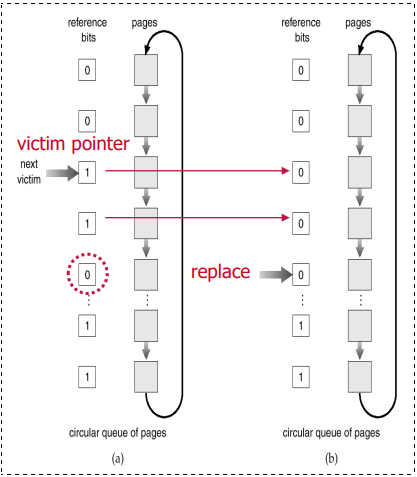
举个例子:引用字符串 a b g a d e a b a d e g d e,帧的数量为 4,页错误数为 10

增强版 "我还有机会吗" 算法:Enhanced Second Chance Algorithm
增强第二机会算法并考虑参考位和修改位。分出四种类型:
-
:最近没有使用过也没有修改过 —— 最佳候选人!
-
:最近没有使用过,但是修改过。
-
:最近使用过,但干净。
-
:最近使用并修改过。
- 当需要替换页时,检查该页所属的类型,并替换在最低的非空类中遇到的第一个页。
- 可能要对循环队列进行多次扫描。
基于计数的算法:Counting-Based Algorithms
- 最不经常使用 (LFU) 策略:替换最不经常使用的页。
- 最少最近使用 (LRU) 策略:替换最少使用的页面。
0x07 Frames 的分配方案
❓ 我们如何在进程之间分配固定数量的自由内存?
- 不能分配超过总的可用帧数。
- 必须至少分配最低数量的帧。
每个进程都需要最少数量的页:
- 由指令集架构定义
- 需要足够的帧来容纳所有不同的页面,任何一条指令都可以引用。
- 例1:1级间接寻址(例如,加载10)需要3个帧。
- 例2:PDP-11需要6个帧来处理 MV from, to 指令。
- 指令是6个字节(比一个字大),可能跨越2个页
- 2页来处理 form
- 2页来处理 to
这存在两种主要的分配方案:平等分配 和 比例分配。
平等分配(Equal allocation):如果有100帧和5个进程,给20页。
比例分配(Proportional allocation):根据进程的大小进行分配。

(对每个进程的分配可能根据多程序化水平而有所不同)
优先级分配 (Priority allocation):使用优先级,而不是按规模的比例分配的一种方案。
0x08 全局替换和局部替换(Global vs. Local Replacement)
如果进程 产生了一个页错误:
- 选择替换它的一个帧。
- 选择一个优先级较低的进程的帧进行替换。
全局替换:Global replacement
- 进程从所有帧的集合中选择一个替换帧;一个进程可以从另一个进程中获取一个帧。
- 不能控制自己的页错误率;同一个进程的表现可能大不相同。
- 一般来说,会产生更大的吞吐量。这是比较常见的方法。
局部替换:Local replacement
- 每个进程只从它自己分配的帧集合中选择一个替换帧。
- 通过不向一个进程提供较少使用的内存页来阻碍它。
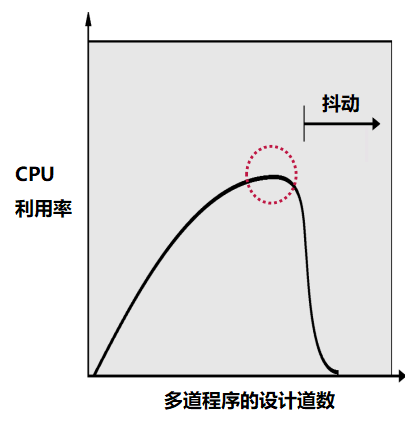
0x09 抖动(Trashing)
我们再来讨论一个问题:当内存被超额请求时,操作系统应该做什么?
这组正在运行的进程的内存需求是否超出了可用物理内存?
当 "需求大于供给" 时,系统将不断地进行换页,这种情况被称之为 抖动(Trashing)。
至于为什么叫抖动,OSTEP 的作者虽然没作解释,但我是这么想的:
"抢劫!不给200就撕票!但你身上只有50,你当然会吓得发抖。"
进程花在换页(换入和换出)上的时间会比执行的时间多:
- Thrashing is a process is spending more time swapping pages in and out than executing.
对于内存抖动问题,局部替换可以缓解这个问题,但不能完全解决……那该如何防抖?
其实有种简单粗暴的解决方案……就是 —— 直 接 撕 票 !
 当内存超额请求时,某些版本的 Linux 会运行 内存不足杀手程序 。
当内存超额请求时,某些版本的 Linux 会运行 内存不足杀手程序 。
即 out-of-memory killer,该守护进程会选择一个内存密集型进程并派遣他去做杀手,把它干掉。
抖是吧?直接把你干掉,就不抖了,物理防抖!(手动滑稽)
0x0A 预读(Prefetching)
预读 (Prefetching):操作系统预测某个页面即将被使用,从而预先将其带入进内存。
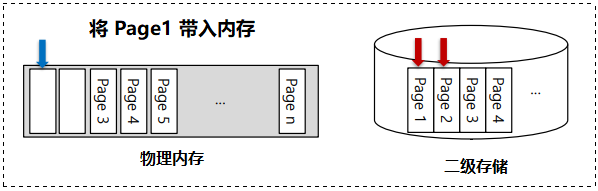
Page2 可能很快被访问,因此也被带入进了内存。
0x0B 群集与分组(Clustering and Grouping)
- Collect a number of pending writes together in memory and write them to disk in one write.
群集:在内存中把一些待写的内容收集到一起,然后一次性把它们写进磁盘。
进行一次 "浩大的" 写操作比多次 "小的" 写操作更有效率!


📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2022.11.15
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!📜 参考资料 Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau, Operating Systems: Three Easy Pieces A. Silberschatz, P. Galvin, and G. Gagne, Operating System Concepts, 9th Edition, John Wiley & Sons, Inc., 2014, ISBN 978-1-118-09375-7. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. |